这个属于是一个比较钻牛角尖的问题,主要是自己比较好奇,也刚好看到了一些文章。
不过,现代ide已经足够智能,它会自动提醒我们该用什么样的方法。但是个中缘由,似乎没有很多人能正确的指出。
后面会将toArray(new T[0])简称为zero,toArray(new T[size])简称为sized。 并且,如果没有特别提到的话,jmh都是运行在jdk1.8上的。
首先看到toArray方法的源码:
java
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}那么就是两种情况:
toArray(new T[0])走的是(T\[\])Arrays.copyOf(elementData, size, a.getClass())toArray(new T[size])走的是System.arraycopy(elementData, 0, a, 0, size)
Arrays.copyOf这个方法长这样:
java
@IntrinsicCandidate
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}也是依赖于arraycopy的。
所以,区别在于:
toArray(new T[0])依赖于jdk帮我们创建数组toArray(new T[size])需要手动创建数组
并且看到,copyOf里还会有反射操作,那么一般来说,比起弯弯绕绕的zero,当然是sized的性能会更好了。
那么既然会有这篇文章,那就说明并不是。而是zero的性能会更好。
那么先说结论: zero这条路经上的方法可以被jvm或者说jit进行特殊优化。jvm创建数组的时候,可以去掉在创建数组时的元素初始化这一步;并且,会有一些特殊手段来避免反射带来的性能损耗。
反射
众所周知,反射是一种很敏感的操作,大家都知道它会损耗性能,那么其实是为什么呢?
实际上,jvm是这么实现反射的:
- method.invoke会借助jni来实现。那么此时就涉及到java代码和本地代码的切换,这就是overhead
- 动态生成class,也就是字节码。有一个叫GeneratedMethodAccessor的东西,在每个method instance中都会有一个method accessor的字段,在jni形式调用这个method足够多次之后,vm会动态生成这么一个类,然后放到这个method instance中,后面会直接通过这个accessor来调用方法,而不是jni。那么此时,这个accessor就可以享受jit带来的优化来提高反射调用的性能。但是,问题就在于,当反射的方法足够多的时候,生成的accessor就多,此时需要在runtime进行验证、链接字节码这种compile时期的工作,并且还需要占用部分的heap,这也是overhead
也可以直接看:stackoverflow.com/questions/1...
上面也说到,vm首先会通过jni来调用方法,后面就会改成动态生成类来调用,这一个过程被称为reflection inflation。 那么,这里关联到几个system property。 一个是-Dsun.reflect.inflationThreshold,默认为15。也就是jni调用15次之后会触发这么一个inflation来优化这个射调用。 另一个是sun.reflect.noInflation,默认为false,意味着是否跳过jni,直接生成类。
但是,事情发生了一些变化。
在jdk18之后,合并了jep416,这个提案将这一套反射方案给改掉了。jdk team用上了MethodHandle,也就是从jdk1.7开始就存在的东西,改写了reflection的实现。
但是,这么做的目的并不是为了提升性能,而是为了偷懒,或者说历史代码遗留问题。至于具体的细节,可以去自行查看jep416。总之,在jdk18之后,上面两个参数就gone了。
又但是,由于底层实现的切换,很容易给一众javaer带来意想不到的upgrade issue,所以jdk team贴心的留下了一个参数:-Djdk.reflect.useDirectMethodHandle,把这个设置为false,又可以继续沿用旧的inflation了。
跑题跑的厉害,那这个跟我们的主题有什么关系呢。
既然都说反射对性能有影响,那我们测试一下试试,不如就拿这个Arrays.newInstance来试试,看一下会差多少。
那么写个简单的jmh:
java
@Warmup(iterations = 10, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 10, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(value = 3, jvmArgsAppend = {"-XX:+UseParallelGC", "-Xms1g", "-Xmx1g", "-XX:+UnlockDiagnosticVMOptions", "-XX:DisableIntrinsic=_newArray"})
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Benchmark)
public class ArrayReflectionBench {
@Param({"0", "1", "10", "100", "1000"})
int size;
@Benchmark
public Foo[] lang() {
return new Foo[size];
}
@Benchmark
public Foo[] reflect() {
return (Foo[]) Array.newInstance(Foo.class, size);
}
}跑出来的结果让人非常的意外:
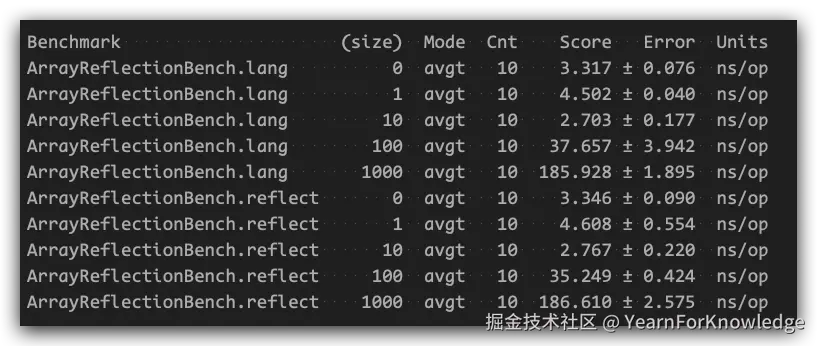 居然性能是一样的,那是不是意味着反射是没有额外开销的?
居然性能是一样的,那是不是意味着反射是没有额外开销的?
当然不是了。如果我们仔细看看,这个Array.newInstance是一个静态方法,而我们熟悉的clazz.newInstance是一个实例方法,并且从源码来看,clazz.newInstance最终会借助constructor来使用方法,而Array.newInstance则是直接使用jni。
如果我们去到它的方法签名,会看到这样:
java
public static Object newInstance(Class<?> componentType, int length)
throws NegativeArraySizeException {
return newArray(componentType, length);
}
@IntrinsicCandidate
private static native Object newArray(Class<?> componentType, int length)
throws NegativeArraySizeException;可以看到它并不是一个传统意义上的反射操作,虽然它也位于reflect包,但是它实际上执行的是一个jni。
并且,这又是一个@IntrinsicCandidate方法,前面的copyOf也是被这个注解标注了的。那么这个注解肯定是有一些奇怪的作用的。
不过到这里,我们已经知道了,对于toArray这个方法,默认情况下,反射是不会对它的性能造成影响的。
@IntrinsicCandidate
在jdk16之前,它的名字是@HotSpotIntrinsicCandidate。它的作用,根据javadoc,简而言之就是被这个注解标注的方法,可以被hotspot vm(或者说jit compiler)以可能更加高效的compiler intrinsics(直译过来就是:编译器内在函数,不知道该怎么解释,直接理解成特殊的机器码吧)给替换掉。
而它可以被替换掉,意味着可能实际存在一个文件,用来存放所谓的compiler intrinsics,在hotspot vm中,这个文件为vmIntrinsics.hpp。可以通过这个链接直达: github.com/openjdk/jdk...
可以看到这个:

一般来说,intrinsic分为两类;
- library intrinsics 会被特殊的intrinsics给替换掉
- bytecode intrinsics 不会被替换掉,但是会有一些特殊的优化手段
从上面的vmIntrinsics中可以查到,newArray属于是library,所以它是会直接被特殊的机器码给替换掉来提升性能。
而这种intrinsics优化是可以被关闭的,compiler(比如c1、c2)会检查几个条件:
cpp
virtual bool is_intrinsic_available(const methodHandle& method, DirectiveSet* directive) {
return is_intrinsic_supported(method) && !directive->is_intrinsic_disabled(method) && !vmIntrinsics::is_disabled_by_flags(method);
}那么在Java层面,可以通过-XX:+UnlockDiagnosticVMOptions和-XX:+PrintIntrinsics,让vm打印所有当前已被intrinsics优化过的方法。
比如我用当前的openjdk24,通过一个简单的程序,打印结果为:
 可能会觉得很奇怪,为什么这里只有
可能会觉得很奇怪,为什么这里只有equals,因为我们前面已经至少看到了copyOf和newArray都是应该要被特殊处理的方法,是不是我的vm出了什么问题?
当然不是。
前面说到,intrinsics优化是和jit有关的,所以,如果只是简单的启动一个helloworld程序,在配置好vm options的情况下是看不到什么东西的。必须是要让程序预热过,让jit给运转起来,才能看出一些端倪。
比如,我想要看到newArray是否正确的被intrinsics优化,那么需要预热好我的程序,比如:
java
public static void main(String[] args) throws Exception {
// jit threshold
for(int i = 0; i < 20_000; i++) {
methodCall();
}
// hang the app
TimeUnit.SECONDS.sleep(3);
}
public static void methodCall() {
int[] nums = (int[])Array.newArray(int.class, 1024);
}这时候,再使用上述的vm option运行,就可以看到有intrinsic被输出,大致像:
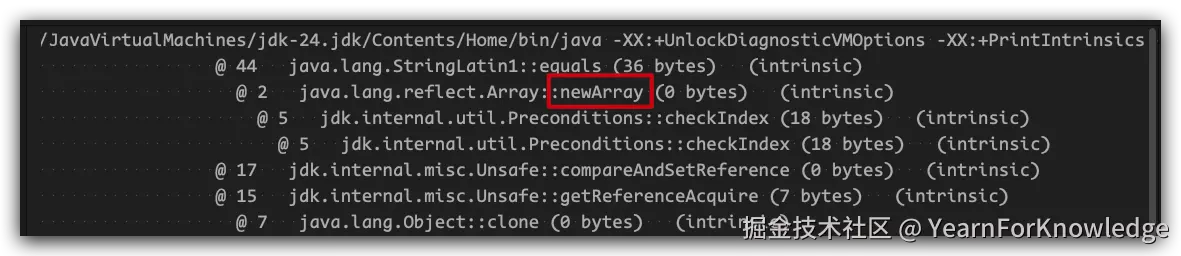 可以看到,这里还会有一些其他的方法也被intrinsic优化掉了,这里提一嘴的就是,有一些是0bytes,有一些不是,这是因为0bytes的方法都是native方法,vm预估不了它的intrinsic大小。
可以看到,这里还会有一些其他的方法也被intrinsic优化掉了,这里提一嘴的就是,有一些是0bytes,有一些不是,这是因为0bytes的方法都是native方法,vm预估不了它的intrinsic大小。
而一些intrinsics也是可以被手动关闭的,通过这样的一个命令可以打印出可以被关闭的intrinsic优化:
shell
java -XX:+PrintFlagsFinal -XX:+UnlockDiagnosticVMOptions -version | grep Intrinsic那么,如果我们将前面的newArray intrinsic给关闭掉(-XX:DisableIntrinsic=_newArray),再进行一次jmh测试,会得到什么结果呢:
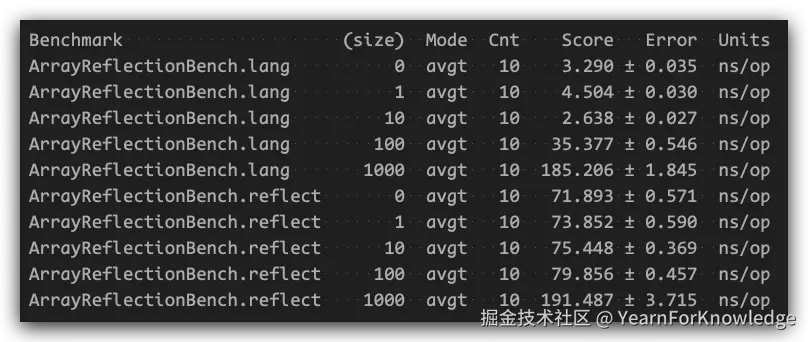 得到的结果大致如图,那么此时就可以看到,如果没有intrinsic,反射对于应用性能的损耗是非常显著的。
得到的结果大致如图,那么此时就可以看到,如果没有intrinsic,反射对于应用性能的损耗是非常显著的。
而此时看到,关闭intrinsic之后,似乎当大小为0、1、10、100时,性能似乎没什么变化?
这是因为,当关闭intrinsic的时候,就会走正常的jni路径,而这个过程涉及到一个显著且固定的overhead:
- 栈帧切换:vm需要保存当前的Java栈帧,并切换到native
- 参数传递:将Java参数传递给native代码,并且可能还需要进行必要的检查
- 线程状态切换:在vm层面,需要切换线程的状态
- 结果处理:native处理完之后,需要创建一个jni句柄来引用结果,并将其返回给Java代码,然后恢复栈帧
而对于toArray这个方法,当数组大小比较小时,通常,创建数组这个操作本身的overhead,相比于前面的jni开销就比较小,那么此时就不会有很显著的差别。
这里还想提一点就是,众所周知,Java数组创建可以简单分为两步:
- 分配内存
- 内存清零 重点在于,内存清零这一步,就是数组在分配内存之后,必须要对里面的元素逐个初始化,比如对int数组,就需要每个值都先改为0。
那么关于这一个东西,我也查了一些资料,在vm中也是有应用的,比如说toArray会使用到的arraycopy,简单来说就是,如果vm感知到,这个数组在创建之后,不会被其他任何地方使用,并且后续有对这个数组的==所有 ==元素赋值,那么此时就会去掉数组元素初始化这一步,来减少数组创建的开销。可以看这一个issue:bugs.openjdk.org/browse/JDK-...
综上,intrinsic也算是一个很关键也很隐蔽的优化。
常数还是表达式
在zero和sized两种模式上,还有一个特别明显的区别,那就是zero中的数组是一个固定为0的大小的数组。而sized中,通常我们会使用collection.size()这样的表达式,不过一般来说,.size()可以直接被内联为对一个size变量的访问。
众所周知,Java中有一个很常见的优化叫做常量折叠,虽然和这里没什么关系。但是,可以预测一下,这一个在编译期间就可知的0,是否也有一些特殊的优化手段呢?
同样,做一个简单的jmh就可以知道:
java
@Warmup(iterations = 10, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 10, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(value = 3, jvmArgsAppend = {"-XX:+UseParallelGC", "-Xms1g", "-Xmx1g"})
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Benchmark)
public class EmptyArrayBench {
int v1 = 1;
// vN = N, N区间为8, 64, 128, 256
@Benchmark
public Foo[] field_v1() {
return new Foo[v1];
}
// field_v8, field_v64, field_v128, field_v256
@Benchmark
public Foo[] const_1() {
return new Foo[1];
}
// const_8, const_64, const_128, const_256
}主要就是对比,当大小分别为1、8、64、128、256的时候,通过field访问(后续简称为field)以及直接指定数字(后续简称为const)这两种方式的数组创建性能是否有区别。
我跑出来的是:
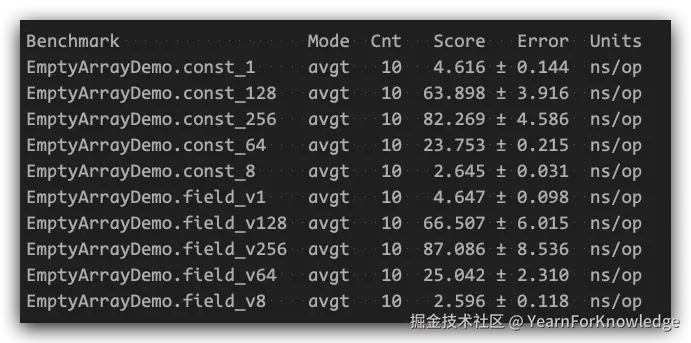 所以,虽然硬要说,还是直接指定大小更快一丢丢,但也只是一丢丢而已,直接忽略不计即可。
所以,虽然硬要说,还是直接指定大小更快一丢丢,但也只是一丢丢而已,直接忽略不计即可。
回到主题
那么,在了解了这些前置内容之后,直接写个jmh来测试一下性能对比,来找到最终的答案:
java
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(value = 3, jvmArgsAppend = {"-XX:+UseParallelGC", "-Xms1g", "-Xmx1g"})
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Benchmark)
public class ToArrayBench {
@Param({"0", "1", "10", "100", "1000"})
int size;
@Param({"arraylist"})
String type;
Collection<Foo> coll;
@Setup
public void setup() {
coll = new ArrayList<Foo>();
for (int i = 0; i < size; i++) {
coll.add(new Foo(i));
}
}
@Benchmark
public Foo[] zero() {
return coll.toArray(new Foo[0]);
}
@Benchmark
public Foo[] sized() {
return coll.toArray(new Foo[coll.size()]);
}
public static class Foo {
private int i;
public Foo(int i) {
this.i = i;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Foo foo = (Foo) o;
return i == foo.i;
}
@Override
public int hashCode() {
return i;
}
}
}在我的macos上运行的结果大致如下:
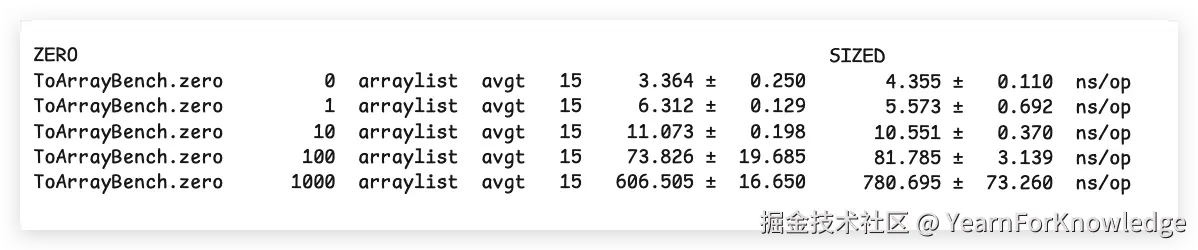 可以看到,可以说zero比sized快非常多,特别是在元素个数多的情况下,也印证了开头说的结论。
可以看到,可以说zero比sized快非常多,特别是在元素个数多的情况下,也印证了开头说的结论。
总结
总的来说,主要的性能差异就在于: zero模式,依赖于intrinsic的newArray方法为我们更高效的创建dst数组。 sized模式,则是我们手动创建数组,此时并不能享受到优化。
这就是这两个方法在性能上区别最大的地方。所以,像现在的ide,也会推荐我们使用zero这种写法。