一、Stable Diffusion 基础原理
图像生成领域有多种机器学习架构,例如生成对抗模型 GAN、Transformer架构、Diffusion Transformer等。Stable Diffusion是最近几年比较热门的一种。
1.1 Stable Diffusion 主要架构
Stable Diffusion 本身并不是一个模型,而是一个由多个模块和模型组成的系统架构。是由 Stability AI 公司于2022年8月由 CompVis、Stability AI 和 LAION 的研究人员在 Latent Diffusion Model 的基础上创建并推出的。
它由三大核心部件组成,每个组件都是一个神经网络系统:  一、文本编码器Text Encoder(CLIPText):用于文本编码:
一、文本编码器Text Encoder(CLIPText):用于文本编码:
- Input:输入文本(提示词 Prompt,左图例子中提示词paradise cosmic beach);
- Output:77 token embeddings vectors,每个 token 向量有 768 个维度;
二、图像生成器Image Infomation Creator(U-Net + Scheduler ):用于逐步处理/扩散被转化到潜空间中的信息:
- Input:文本嵌入和由噪点组成的起始多维矩阵;
- Output:处理后的信息矩阵;
三、图像解码器Image Decoder(AutoEncoder Decoder,主要是一个VAE:Variational AutoEncoder):使用处理后的信息矩阵解码绘制出最终图像,把潜空间的运算结果解码成实际图片维度:
- Input:处理后的信息矩阵,维度:4, 64, 64;
- Output:生成的图像,维度:3, 512, 512 即 RGB三个通道、和两维像素尺寸。
其他概念:
- 潜在空间 Latent Space :解决了原始 Diffusion 模型效率低下的问题,极大地降低了内存消耗和计算的复杂度。
- VAE编码器 :将 512x512 像素的图像压缩成更小的潜在空间64x64 。
- VAE解码器 :将潜在空间恢复为 512x512 像素的图像。
1.2 详细流程
Stable Diffusion 的数据会在像素空间(Pixel Space )、潜在空间(Latent Space )、条件(Conditioning )三部分之间流转,其算法逻辑大概分这几步: 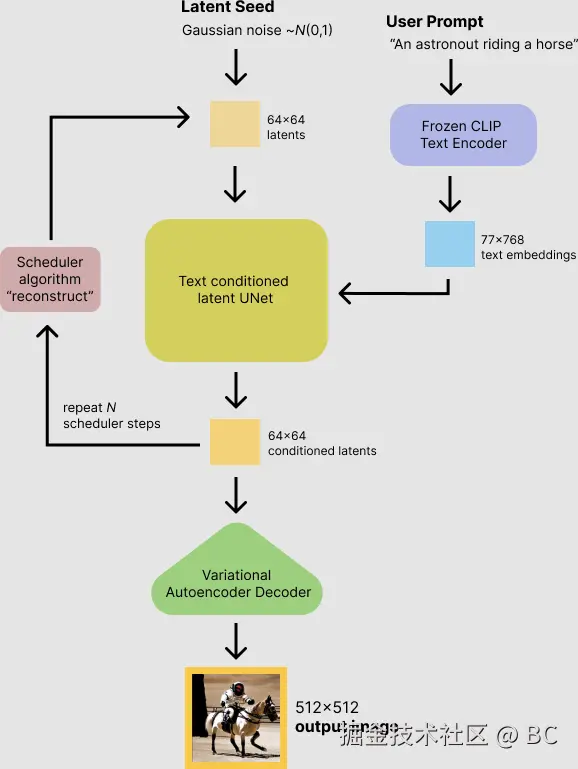
- 根据用户输入的prompt,用Text Encoder提取text embeddings,作为后续迭代的条件。
- 初始化一个潜在空间高斯噪音Latent Seed(512x512图像对应的潜在空间维度是64x64)。
- 扩散模型UNet以text embeddings为条件(Conditioning ),迭代地对噪音图像表示进行去噪。 (注意,噪点并不是直接在像素维度加到图片上的,而是在潜空间中加到图片的潜空间数据矩阵中的。这里的噪点图只是为了方便大家理解。)
- 迭代完成后,潜在空间图像就由variational Autoencoder的图片解码器解码,将图像从潜在空间转换回像素空间,得到生成的图片。
参考文档:huggingface.co/blog/stable...
二、扩散Diffusion模型
2.1 核心功能
以上流程中,Stable Diffusion的核心是扩散模型的迭代运行。扩散模型有两个主要功能:(1)前向扩散,(2)反向扩散。
| 模型训练过程-前向扩散 | 训练过程&结果 | 文生图过程-反向扩散 | |
|---|---|---|---|
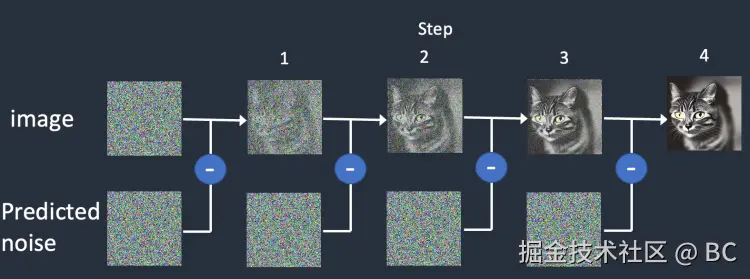
| 说明 | 前向扩散就是将图片转化为噪点图的过程。假设我们有了一张照片(下图中1),并额外生成了一些随机噪点(下图中2),然后在若干噪点强度中选择其中某一个强度级别(下图中3),然后将这个特定强度级别的噪点加到图片中(下图中4)。 | 在如此巨大的数据集上训练出的强大的噪点预测器 U-Net ,便有"能力"在 Diffusion 的反向生图过程中,将噪点图逐步迭代去噪,转化为一张完美的图像。U-Net 的训练过程:①从庞大的数据集中选择一个训练样本,通常为某一个噪点强度级别下的图像样本。②通过 U-Net 预测该噪点和噪点级别。③与实际图片中的噪点做对比。④反馈给 U-Net 第三步中的噪点对比差异。以便让 U-Net 调整参数后提高预测能力。这是一种典型的"监督学习"过程。 | 反向扩散是前向扩散的逆过程。它从一个完全随机的噪点图开始,通过神经网络来预测并去除噪点,迭代多次最终恢复为一张清晰的图片。这个过程中的神经网络在Stable Diffusion中被称为噪点预测器(noise predictor),其本质是一个U-Net模型。 |
| 图示 | 不同噪点强度的图片(最后,数据集中有大量不同噪点强度的图片)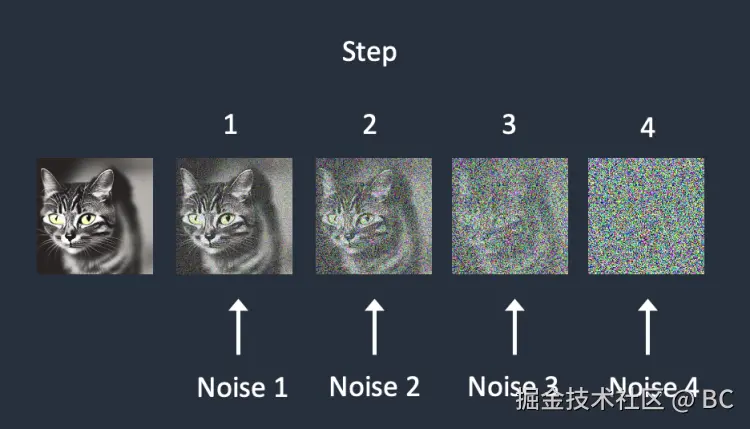 |
训练过程: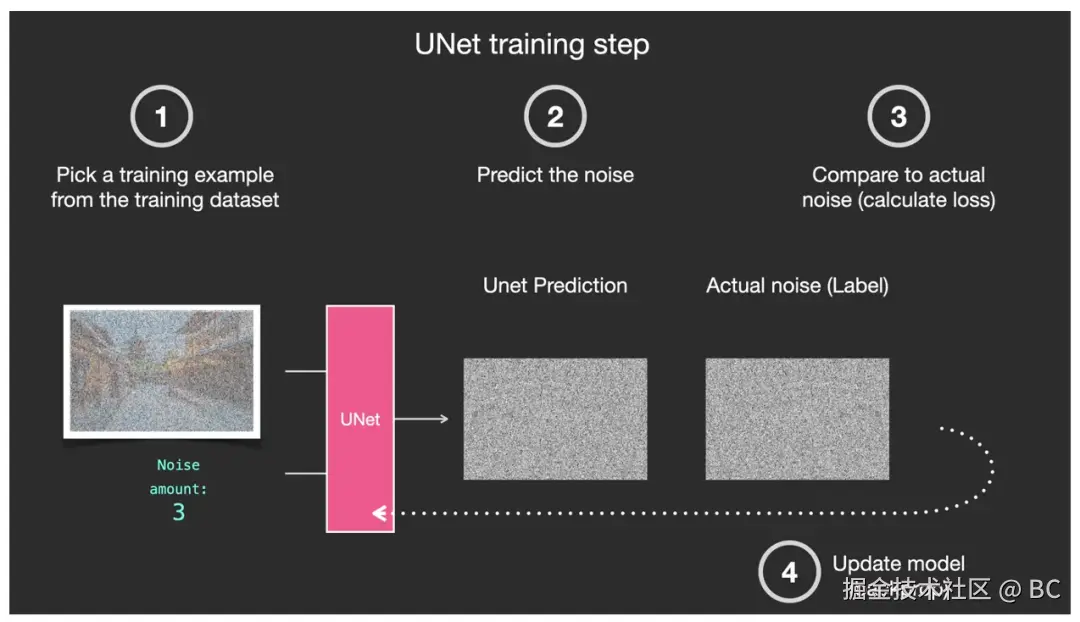 训练结果: 训练结果: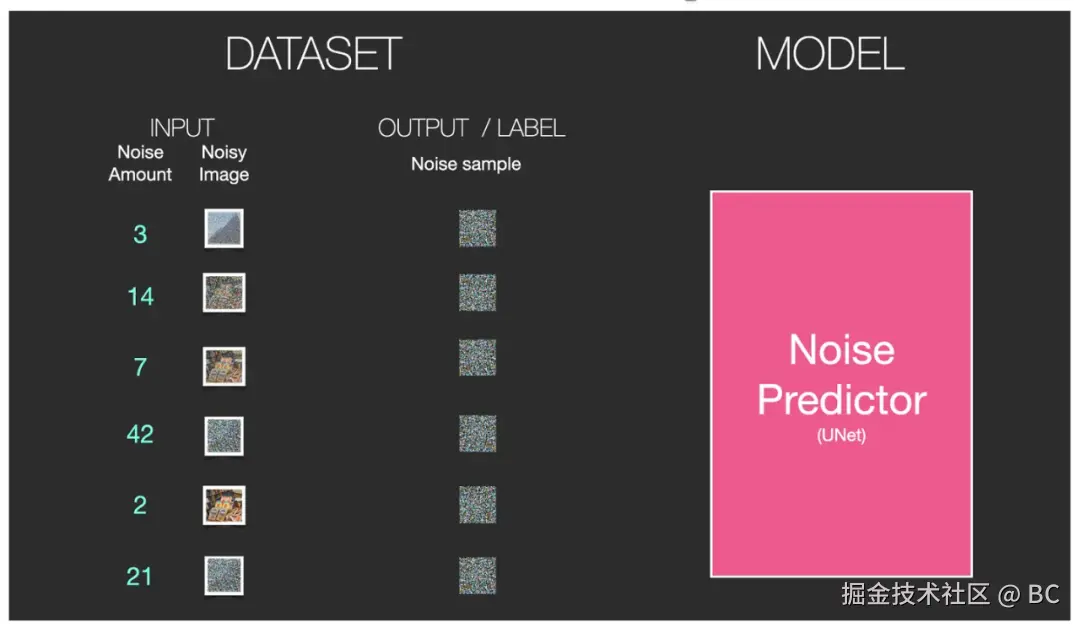 |
|
2.2 Stable Diffusion基础模型
Stable Diffusion基础模型Foundation Model,就是指将大量数据导入具有数亿甚至万亿级参数的模型中,通过人工智能算法进行训练。Stable Diffusion v1.x、FLUX 1.x等模型都属于基础模型,这类大模型普遍的特点是参数多,训练时间长,具备泛化性、通用性、实用性,适用于各种场景的绘图。常见的基础模型一般在2GB以上,有两种文件类型:
| 文件格式 | 说明 |
|---|---|
| .ckpt文件 | 即checkpoint,是TensorFlow/pytorch中用于保存模型参数的格式,记录了训练过程中在所有中间节点上保存的模型的名称,通常与 .meta 文件一起使用,以便恢复训练过程并继续优化。 |
| .safetensors文件 | huggingface 推出的新的模型存储格式,专门为Stable Diffusion模型设计。这种格式的文件只保存模型的权重,而不包含优化器状态或其他信息,这也就意味着它通常用于模型的最终版本。 |
基础模型及微调模型都可以去Hugging Face下载:huggingface.co/models?pipe...
2.3 微调技术
(1)Stable Diffusion基础模型的使用上有一定局限性,直接使用预训练模型可能无法满足特定任务的需求,例如无法满足对细节控制或特定人物特定绘图风格的绘图需要。
(2)训练一个Stable Diffusion基础模型需要强大的计算资源及高昂的成本(例如Stable DiffusionV1.5 模型是在几百个英伟达 Nvidia A100 GPU 上,用了23亿张图片耗时几十万个 GPU 小时训练出来)。
于是,针对这些大模型的微调技术应运而生。为了达到绘制特定人物或特定风格,我们不需要重新训练大模型,只需要提供训练数据集训练出微调模型(几个小时就可以实现,也是个人开发者常训练的模型),将微调模型和基础模型结合使用。常见的微调技术有Embedding、Hypernetwork、Dreambooth、Lora、ControINet等。
| 模型类型 | 详细说明 |
|---|---|
| Embedding模型 | Embedding模型也称为textual inversion,即文本反转。在Stable Diffusion中,Embedding模型使用了嵌入技术以将一系列输入提示词打包成一个向量,从而提高图片生成的稳定性和准确性。Embedding对于复杂的词汇的调整结果并不太好,定义人物需要的关键词少,所以适用于对人物的训练。 |
| VAE模型 | VAE全称Variational auto enconder,变分自编码器。Stable Diffusion在训练时会有一个编码(Encoder)和解码(Dncoder)的过程,我们将编码和解码模型称为VAE模型。预训练的模型,如官网下载的Stable Diffusion模型,一般都是内置了训练好的VAE模型的,不用我们再额外挂载。但有些大模型并不内置VAE模型,或者VAE模型经过多次训练融合不能使用了,就需要额外下载,并在Stable Diffusion Web UI 中添加设置。如果不添加,出图的色彩饱和度可能会出问题,发灰或变得不清晰。 |
| Lora模型 | LoRA(Low-Rank Adaptation of large Language Models)是由微软研究员开发的一种用于微调大模型的技术。该技术建议冻结预训练模型的权重,并在每个 Transformer 块中注入可训练层,从而在保持大部分参数不变的情况下,调整局部的一些模型参数。由于不需要重新计算模型的权重参数的梯度,这大大减少了需要训练的计算量,并降低了 GPU 的内存要求。 使用 LoRA 模型进行微调可以为我们提供更自由、更便捷的微调模型的方式。例如,它使我们能够在基本模型的基础上进一步指定整体风格、指定人脸等等。此外,LoRA 模型本身非常小,即插即用,非常方便易用。 |
| Hypernetwork模型 | Hypernetwork是作用在UNET网络上的,UNET神经网络相当于一个函数,内部有非常多的参数, Hypernetwork 通过新建一个神经网络,称之为超网络。超网络的输出的结果是UNET网络的参数。超网络不像UNET,它的参数少,所以训练速度比较快,因此Hypernetwork能达到以较小时间空间成本微调模型的目的。Hypernetwork 会影响整个UNET的参数生成,理论上更适合风格的训练。 |
| Controlnet模型 | Controlnet模型是一种神经网络结构,通过添加额外的条件来控制基础扩散模型,从而实现对图像构图或人物姿势的精细控制。结合文生图的操作,它还能实现线稿转全彩图的功能。 |
2.4 模型迭代历史
Stable Diffusion稳定扩散模型在短短两年内已经发布了多个版本。其中最著名的版本是1.5和SDXL。
| 模型名 | 发布日期 | 发布者 | 说明 | 连接 |
|---|---|---|---|---|
| Latent Diffusion | 2022/7/1 | CompVis | 最初的模型称为 Latent Diffusion,由 CompVis 开发,包含文本到图像和inpainting功能。 | github.com/CompVis/lat... |
| Stable Diffusion 1.1 | 2022/8/1 | CompVis | 2022 年 8 月,CompVis 相继发布了四个版本的稳定扩散软件。随后的每个版本都增加了训练步骤,从而提高了输出质量。 | huggingface.co/CompVis/sta... |
| Stable Diffusion 1.2 | 2022/8/1 | CompVis | huggingface.co/CompVis/sta... | |
| Stable Diffusion 1.3 | 2022/8/1 | CompVis | huggingface.co/CompVis/sta... | |
| Stable Diffusion 1.4 | 2022/8/1 | CompVis | huggingface.co/CompVis/sta... | |
| Stable Diffusion 1.5 | 2022/10/1 | RunwayML | RunwayML 于 2022 年 10 月发布了稳定版 Diffusion 1.5,该版本成为最广泛使用的微调版本。 | huggingface.co/runwayml/st... |
| Stable Diffusion 1.6 | 2023/11/1 | Stability AI | Stable Diffusion 1.6 是一个相对陌生的版本,因为它不是一个开源模型。它于 2023 年 11 月在 Stability AI 开发者平台发布。它只能通过 Stability AI 开发者平台的 v1 API 使用(最新的 API 版本为 v2)。 | platform.stability.ai/docs/api-re... |
| Stable Diffusion 2.0 | 2022/11/1 | Stability AI | Stability AI 发布了 Stable Diffusion 2.0,12 月又发布了 2.1。尽管规模更大,但这些模型的受欢迎程度不如 1.5,而且扩展支持有限。 | huggingface.co/stabilityai... |
| Stable Diffusion 2.1 | 2022/11/1 | Stability AI | huggingface.co/stabilityai... | |
| Stable Diffusion XL 0.9 | 2023/6/1 | Stability AI | SDXL 擅长生成高达 1024x1024 像素的图像,并支持 LoRA 和 ControlNet。 | huggingface.co/stabilityai... |
| Stable Diffusion XL 1.0 | 2023/7/1 | Stability AI | huggingface.co/stabilityai... | |
| Stable Diffusion XL beta 2.2.2 | 2023/11/1 | Stability AI | platform.stability.ai/docs/api-re... | |
| Stable Image Core | 2024/3/1 | Stability AI | platform.stability.ai/docs/api-re... | |
| Stable Diffusion XL Turbo | 2023/11/1 | Stability AI | 2023 年 11 月,SDXL Turbo 推出,利用潜在一致性模型(LCM)将生成步骤从通常的 30 |
huggingface.co/stabilityai... |
| Stable Diffusion Turbo | 2023/11/1 | Stability AI | huggingface.co/stabilityai... | |
| Stable Video Diffusion | 2023/11/1 | Stability AI | Stability AI 公司于 2023 年 11 月推出了 SVD,可从单张图像生成短动画,且不会出现闪烁问题。 | huggingface.co/stabilityai... |
| Stable Video Diffusion XT | 2023/11/1 | Stability AI | huggingface.co/stabilityai... | |
| Stable Zero123 | 2023/12/1 | Stability AI | Stable Zero 123 于 2023 年 12 月发布,主要功能是通过单张图像生成 3D 物体,并提供包括物体背面在内的多个视图。 | huggingface.co/stabilityai... |
| Stable Diffusion Cascade | 2024/2/1 | Stability AI | 2024 年 2 月,Stability AI 推出了 Stable Diffusion Cascade,它采用三阶段生成流程(ABC 阶段),以更高的效率生成高质量图像。 | huggingface.co/stabilityai... |
| SDXL Lightning | 2024/2/1 | ByteDance | huggingface.co/ByteDance/S... | |
| Stable Diffusion 3 | 2024/2/1 | Stability AI | Stable Diffusion 3 生成的图片在质量上有了很大改进,支持多主题提示,文字书写效果更好(文字不再乱码)。采用了与 Sora 相同的 DiT(Diffusion Transformer)架构。由于文本嵌入和图像嵌入的不同,因此 SD3对两种模态使用两套不同的权重:多种模态MMDiT。 | platform.stability.ai/docs/api-re... |
| Stable Diffusion 3 Turbo | 2024/2/1 | Stability AI | platform.stability.ai/docs/api-re... | |
| Stable Video 3D | 2024/3/1 | Stability AI | huggingface.co/ByteDance/S... | |
| Cos Stable Diffusion XL 1.0 | 2024/4/1 | Stability AI | huggingface.co/stabilityai... | |
| Cos Stable Diffusion XL 1.0 Edit | 2024/4/1 | Stability AI | huggingface.co/stabilityai... |
以上只是Stable Diffusion系列模型的发展历史,并不是所有文生图应用都用了一样的基础模型,很多公司都有自己的基础模型,有的模型也会开源在huggingface上。
此外,FLUX系列模型最近也很热门,是由Stable Diffusion创始团队,Black Forest Labs公司推出的开源AI图像生成模型。
三、Stable Diffusion 编程
本节介绍如何使用Hugging Face推出的diffusers库(hugging-face.cn/docs/diffus...)进行编程,暂不介绍更复杂的底层实现。
Diffusers 是一个值得首选用于生成图像、音频甚至 3D 分子结构的,最先进的预训练扩散模型库。diffusers使用pipeline类封装各个模块,以及安排其中的调用顺序和输出。
- diffusers库:github.com/huggingface...
- 基础课程:github.com/huggingface...
3.1 安装
- 安装diffusers库及依赖库
python
%pip install -qq -U diffusers datasets transformers accelerate ftfy pyarrow==9.0.0- 登录huggingface,用于从huggingface中下载托管的模型文件
python
%pip install -qq -U diffusers datasets transformers accelerate ftfy pyarrow==9.0.0- 安装Git LFS,用于大文件管理(Git LFS 是Git 的扩展,它可提供用于描述提交到存储库中的大型文件的数据。 它会将二进制文件内容存储在单独的远程存储中。)。
python
%%capture
!sudo apt -qq install git-lfs
!git config --global credential.helper store- 初始化界面显示的一些函数
python
import numpy as np
import torch
import torch.nn.functional as F
from matplotlib import pyplot as plt
from PIL import Image
def show_images(x):
"""Given a batch of images x, make a grid and convert to PIL"""
x = x * 0.5 + 0.5 # Map from (-1, 1) back to (0, 1)
grid = torchvision.utils.make_grid(x)
grid_im = grid.detach().cpu().permute(1, 2, 0).clip(0, 1) * 255
grid_im = Image.fromarray(np.array(grid_im).astype(np.uint8))
return grid_im
def make_grid(images, size=64):
"""Given a list of PIL images, stack them together into a line for easy viewing"""
output_im = Image.new("RGB", (size * len(images), size))
for i, im in enumerate(images):
output_im.paste(im.resize((size, size)), (i * size, 0))
return output_im
# Mac users may need device = 'mps' (untested)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")3.2 下载模型并初始化
- 使用diffusers库中的StableDiffusionPipeline,并进行初始化:
python
from diffusers import StableDiffusionPipeline
# Check out https://huggingface.co/sd-dreambooth-library for loads of models from the community
model_id = "sd-dreambooth-library/mr-potato-head"
# Load the pipeline
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to(
device
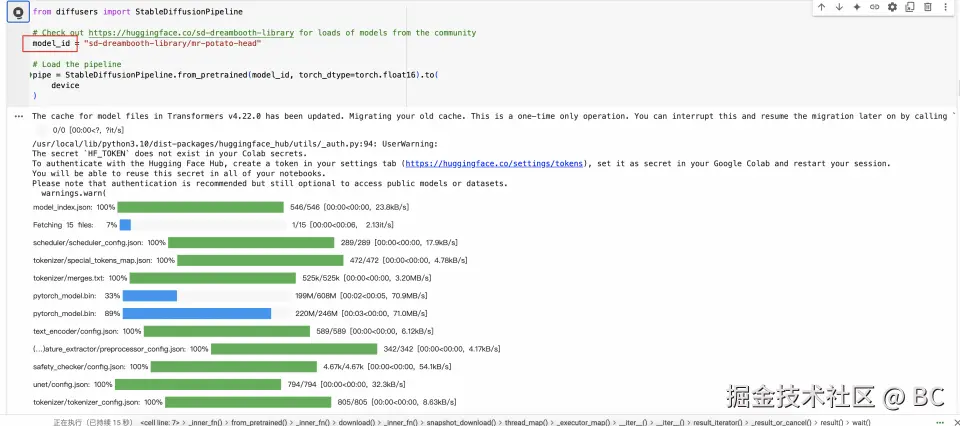
)- 可以看到会从huggingface下载模型的进度:
- 模型id就是huggingface上的id:huggingface.co/sd-dreamboo...
3.3 输入提示词并运行
输入提示词prompt,然后生成图片。
python
prompt = "an abstract oil painting of sks mr potato head by picasso"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image生成结果: 
3.4 源码
上面的例子中用到了diffusers库的StableDiffusionPipeline,有兴趣可以看下源码,便于更好理解StableDiffusion的推理流程:
python
# 1. Check inputs. Raise error if not correct 检查输入
self.check_inputs(prompt,)
# 2. Define call parameters 定义调用的batch,device以及classifier-free的监督系数
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# 3. Encode input prompt 对输入的文字prompt进行encoding
lora_scale = (self.cross_attention_kwargs.get("scale", None) if self.cross_attention_kwargs is not None else None)
# 4. Prepare timesteps 准备scheduler中的时间步数
timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps, sigmas)
# 5. Prepare latent variables 准备初始噪声图latent
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(batch_size * num_images_per_prompt,num_channels_latents,height,width,prompt_embeds.dtype,device,generator,latents,)
# 6. Prepare extra step kwargs. 额外的去噪参数
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7. Denoising loop 循环去噪
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order备注:一些其他diffusion库:github.com/openai/guid...
四、Stable Diffusion UI界面
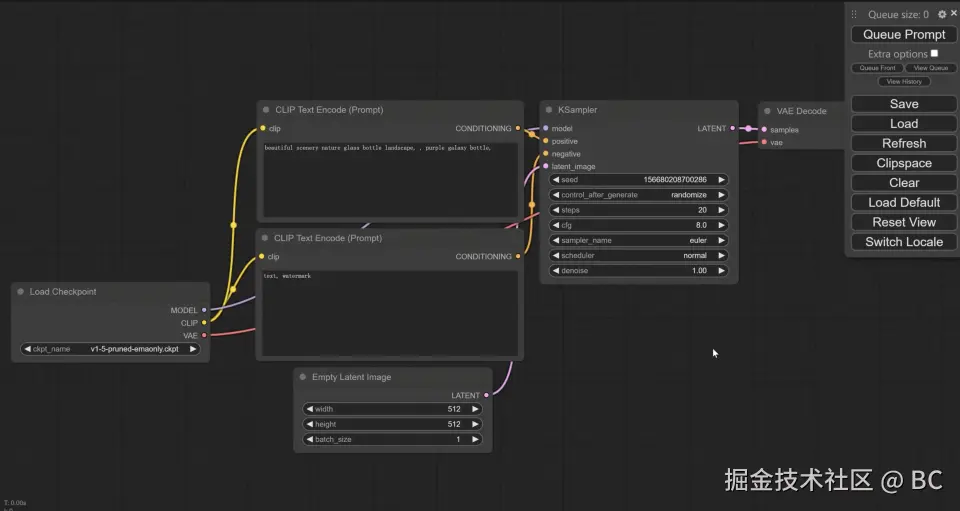
Stable Diffusion 用户界面,指用图形化的界面展示出Stable Diffusion的工作流程,并在内部提供模型的加载及运行,不需要开发者编写python代码,可以让开发者专注于模型的效果上。 目前使用比较多的有三类:Stable-Diffusion WebUI、ComfyUI、商业化产品。
| Stable-Diffusion WebUI | ComfyUI | 商业化产品-Sora、Midjourney等 | |
|---|---|---|---|
| 产品形态 | 传统产品形态,交互为模块化输入框、按钮 | 新型工作流形态,交互为流程化输入框、连线 | 封装好的交互形态,更易上手 |
| 自由度 | 中,可以设定参数,但无法自由搭建 | 高,可以根据自己的需求搭建适合的工作流,甚至开发并改造某个节点。(comfyUI节点流程可以参照第一章的原理对照理解) | 低,产品都是封装好的,只能使用所提供的功能 |
| 生图效果 | 用户可以自定义接入模型,依据接入模型的效果 | 用户可以自定义接入模型,依据接入模型的效果 | 取决于产品所接入的模型效果,用户无法干预 |
| 适用人群 | 1、对AI图像生成有一定要求2、喜欢深度研究与学习3、设计师等专业人士 | 1、对AI图像生成有较高要求2、喜欢新事物喜欢挑战3、设计师等专业人士 | 1、日常简单使用2、AI 绘画初学者 |

4.1 Stable-Diffusion WebUI
Stable-Diffusion WebUI和ComfyUI都可以在本地部署,也可以在云端部署。本地部署流程如下:
- 安装python及git
- 从github上下载本体:下载源码:github.com/AUTOMATIC11...
- 启动及运行
- windows上通过webui-user.bat启动运行后会自动安装必备环境python库,并下载基础模型v1-5-pruned-emaonly.safetensors文件(huggingface.co/stable-diff... )到对应目录
- 安装完成后会自动启动,打开一个127.0.0.1:xxxx本地H5页面。
- 输入提示词,就可以生成结果了。但是效果比较差,因为我们只使用了一个基础模型。如果需要更好的效果,可以下载并切换其他基础模型,并且结合其他微调模型(即第一章提到的Embedding、Hypernetwork、Dreambooth、Lora、ControINet等模型)。
- 生成的结果可以在本地stable-diffusion-webui的output目录下看到。
- 效果及优化。例如:
- (1)基础模型:例如替换成SDXL(或者其他自己喜欢的模型):huggingface.co/stabilityai... ,下载后放到models/Stable-diffusion/目录下
- (2)微调模型:例如下载lora模型huggingface.co/stabilityai... 、VAE模型huggingface.co/stabilityai... ,下载后放到对应models/lora、models/lvae目录下。
- (3)重新运行Stable-Diffusion WebUI,并在对应模块选择刚下载的模型。
- 其他:Stable-Diffusion WebUI汉化插件:github.com/VinsonLaro/...
4.2 ComfyUI
ComfyUI的本地部署流程如下:
- 安装python及git
- 从github上下载本体:下载源码:github.com/AUTOMATIC11...
- 启动及运行
- windows上通过run_nvidia_gpu.bat(建议gpu)、run_cpu.bat运行(2)安装完成后会自动启动,打开一个127.0.0.1:xxxx本地H5页面。
- 安装完成后会自动启动,打开一个127.0.0.1:xxxx本地H5页面。
- 输入提示词,就可以生成结果了。但是效果比较差,因为我们只使用了一个基础模型。如果需要更好的效果,可以下载并切换其他基础模型,并且结合其他微调模型(即第一章提到的Embedding、Hypernetwork、Dreambooth、Lora、ControINet等模型)。
- 效果及优化。例如:
- (1)基础模型:例如替换成FLUX.1-dev(或者其他自己喜欢的模型):huggingface.co/black-fores... ,下载后放到models/unet/文件夹下。
- (2)微调模型:例如下载VAE模型huggingface.co/black-fores... ,下载后放到models/vae/文件夹下。
- (3)重新运行comfyUI,并在对应节点选择刚下载的模型。
- 其他:comfyUI汉化包:github.com/AIGODLIKE/A...
4.3 其他部署方式
Stable-Diffusion WebUI、ComfyUI本地部署都对计算机性能有一定要求(一般模型都会列出需要的gpu等条件),如果不想自己部署,也可以使用 百度AI Studio、LibLib在线工作流等在线部署方式。简化了部署流程,只需要关注模型选择即可。
五、模型选择
5.1 Hugging Face
Hugging Face 是一个专注于 人工智能(AI)模型的开放平台和社区,最初以自然语言处理(NLP)著称,后来扩展到图像、音频、多模态等多个领域。Hugging Face有以下几个模块:
| 模块 | 说明 | |
|---|---|---|
| Models | 各种模型,包括Text Classification、Text-to-Image、Text-to-Video、Text-to-Speech 等等 | huggingface.co/models |
| Datasets | 训练数据集,包括3D,Audio、Image、Text、Video等 | huggingface.co/datasets |
| Spaces | 1.机器学习应用程序的创建和托管,不需要自己搭建就可以在线体验到别人的模型效果。2.可以搭建托管自己的应用,不同机器根据小时收费。 | 例如:FLUX.1-dev的Space huggingface.co/spaces/blac... |
5.2 Civitai
Civitai 是一个开放、功能强大的 AI 图像模型社区,支持模型分享、下载、在站内/本地生成艺术作品。可以查看其他用户分享的模型,提示、生成效果等,选择自己喜欢的模型下载及使用。
5.3 Liblib
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。