Redis完全指南:从基础到实战(含缓存问题、布隆过滤器、持久化及Spring Boot集成)
一、Redis基础与核心概念
1.1 什么是Redis?
Redis(Remote Dictionary Server)是一款开源的内存数据结构存储系统 ,支持多种数据类型(字符串、哈希、列表、集合、有序集合等),兼具高性能、持久化、分布式等特性。它常被用作缓存、数据库、消息中间件,凭借亚毫秒级响应速度 和丰富的数据结构,成为高并发场景的核心组件。
1.2 Redis的核心用途
(1)缓存(最常用场景)
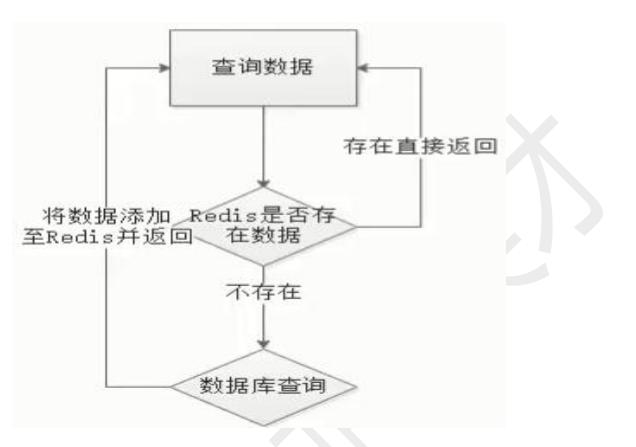
- 原理:将热点数据(如数据库查询结果、用户会话)存储在内存中,减少磁盘IO,提升访问速度。
- 示例:电商商品详情页缓存,用户重复访问时直接从Redis获取,无需查询数据库。
(2)非缓存场景扩展
-
分布式锁 :利用
SETNX命令实现,确保分布式系统中资源的互斥访问(如秒杀库存扣减)。bash# 获取锁(不存在则创建,有效期10秒) SET lock:order:1001 1 NX EX 10 -
计数器 :通过
INCR/DECR实现原子性计数(如文章阅读量、点赞数)。java// 文章阅读量+1 redisTemplate.opsForValue().increment("article:read:1001", 1); -
排行榜 :基于有序集合(ZSet)实现实时排名(如游戏积分、商品销量)。
bash# 玩家A积分+10 ZINCRBY ranking:game 10 player:A # 获取Top10玩家 ZREVRANGE ranking:game 0 9 WITHSCORES -
消息队列 :利用列表(List)的
LPUSH/BRPOP实现简单的异步通信(如订单异步处理)。bash# 生产者发送消息 LPUSH queue:order "order1001" # 消费者阻塞获取消息 BRPOP queue:order 0
二、Redis线程模型:单线程为何如此快?
2.1 核心线程模型(Redis 6.0前)
- 单线程执行命令 :所有客户端命令由主线程顺序执行,避免多线程上下文切换和锁竞争。
- I/O多路复用 :通过
epoll(Linux)/kqueue(BSD)监听多个Socket连接,实现非阻塞I/O,高效处理并发请求。 - 后台线程辅助 :持久化(RDB/AOF)、大Key删除等耗时操作由子进程/线程执行,不阻塞主线程。
2.2 Redis 6.0+的多线程优化
-
多线程I/O :网络数据读写(Socket读写、协议解析)由I/O线程池处理,命令执行仍由主线程单线程完成,提升吞吐量(从10万QPS增至20万+)。
-
配置方式 :
conf# redis.conf中开启多线程 io-threads 4 # I/O线程数(建议为CPU核心数的50%-75%) io-threads-do-reads yes # 读操作也使用多线程
2.3 性能优势总结
| 特性 | 说明 |
|---|---|
| 内存存储 | 数据读写基于内存,速度比磁盘快10⁵倍(纳秒级vs毫秒级)。 |
| 单线程无锁 | 避免多线程锁竞争和上下文切换开销,命令执行原子性。 |
| 高效数据结构 | 底层采用哈希表、跳表等结构,支持O(1)或O(logN)操作(如ZSet排序)。 |
三、Redis持久化:数据安全的双保险
Redis数据默认存储在内存中,需通过持久化机制防止宕机数据丢失。提供RDB 、AOF 、混合持久化三种方案。
3.1 RDB(Redis Database):快照持久化
(1)原理
- 定时快照 :满足触发条件时(如
save 60 10000表示60秒内1万次写操作),将内存数据全量写入二进制文件 (dump.rdb)。 - 触发方式 :
- 自动触发:配置文件
save规则; - 手动触发:
SAVE(阻塞主线程)或BGSAVE(fork子进程异步执行)。
- 自动触发:配置文件
(2)优缺点
| 优点 | 缺点 |
|---|---|
| 二进制文件,体积小,恢复速度快 | 可能丢失最后一次快照后的数(如宕机) |
| 不影响主线程(BGSAVE) | 大数据量时fork子进程可能阻塞服务 |
(3)核心配置
conf
dbfilename dump.rdb # 文件名
dir /var/lib/redis # 存储路径
save 900 1 # 900秒内1次写操作触发
save 300 10 # 300秒内10次写操作触发3.2 AOF(Append Only File):命令日志持久化
(1)原理
- 记录写命令 :将所有写操作(如
SET、HSET)以文本格式追加到appendonly.aof文件,重启时重放命令恢复数据。 - 同步策略 :
appendfsync always:每条命令同步(最安全,性能最低);appendfsync everysec:每秒同步(默认,最多丢失1秒数据);appendfsync no:由操作系统决定(性能最高,安全性最低)。
(2)AOF重写
-
问题 :AOF文件会随命令增多而膨胀(如多次
INCR同一Key)。 -
解决 :通过
BGREWRITEAOF命令生成精简版AOF (合并冗余命令,如INCR x 3替代3次INCR x)。 -
自动触发配置 :
confauto-aof-rewrite-percentage 100 # 文件大小增长100%触发 auto-aof-rewrite-min-size 64mb # 最小文件大小64MB
(3)优缺点
| 优点 | 缺点 |
|---|---|
| 数据安全性高(最多丢失1秒数据) | 文件体积大,恢复速度慢 |
| 文本格式,可读性强 | 写命令追加开销略高于RDB |
3.3 混合持久化(Redis 4.0+推荐)
-
原理 :AOF重写时,先以RDB格式写入当前数据,再追加后续增量命令,兼顾RDB的快速恢复和AOF的数据安全性。
-
配置开启 :
confaof-use-rdb-preamble yes # 开启混合持久化
四、Redis事务:批量操作的原子性保障
Redis事务通过命令队列 实现批量操作,支持MULTI(开启事务)、EXEC(执行事务)、DISCARD(取消事务)、WATCH(乐观锁)命令。
4.1 核心命令与流程
MULTI:标记事务开始,后续命令进入队列(返回QUEUED)。EXEC:执行队列中所有命令,返回结果列表。DISCARD:清空队列,取消事务。WATCH key...:监视Key,若事务执行前Key被修改,则事务失败(乐观锁)。
4.2 实战示例:银行转账
bash
# 初始化账户余额
SET account:A 1000
SET account:B 500
# 开启事务(监视账户A和B)
WATCH account:A account:B
MULTI
DECRBY account:A 200 # A账户减200
INCRBY account:B 200 # B账户加200
EXEC # 执行事务(若A/B未被修改,返回结果;否则返回nil)4.3 注意事项
- 无回滚机制:事务中某条命令执行失败(如语法错误),其他命令仍会执行,需业务层处理异常。
- 弱原子性:仅保证命令按顺序执行,不保证全部成功或全部失败(区别于MySQL事务)。
五、Key过期策略:内存管理的艺术
Redis通过惰性删除 +定期删除 +内存淘汰机制组合,实现过期Key的高效清理。
5.1 过期删除策略
(1)惰性删除
- 触发时机 :客户端访问Key时检查是否过期,过期则删除并返回
nil。 - 优点 :无额外CPU开销;缺点:过期Key长期未访问会浪费内存。
(2)定期删除
-
触发时机 :后台线程每秒执行10次(
hz 10),随机抽查部分过期Key并删除。 -
配置参数 :
confhz 10 # 每秒执行次数(1-500,建议默认10) active-expire-effort 1 # 清理强度(1-10,值越大越激进)
5.2 内存淘汰机制(maxmemory-policy)
当内存达到maxmemory限制时,Redis会按策略淘汰Key:
| 策略 | 说明 | 适用场景 |
|---|---|---|
volatile-lru |
淘汰设置过期时间的Key中最近最少使用的 | 缓存场景(仅淘汰临时数据) |
allkeys-lru |
淘汰所有Key中最近最少使用的 | 通用场景(内存紧张时优先保留热点) |
volatile-lfu |
淘汰设置过期时间的Key中最不常使用的 | 高频访问数据优先保留 |
noeviction |
禁止淘汰,写请求返回错误 | 数据不允许丢失的场景 |
配置示例:
conf
maxmemory 16gb # 最大内存限制
maxmemory-policy volatile-lru # 优先淘汰过期的LRU Key六、缓存三大问题与解决方案
6.1 缓存穿透:查询不存在的数据
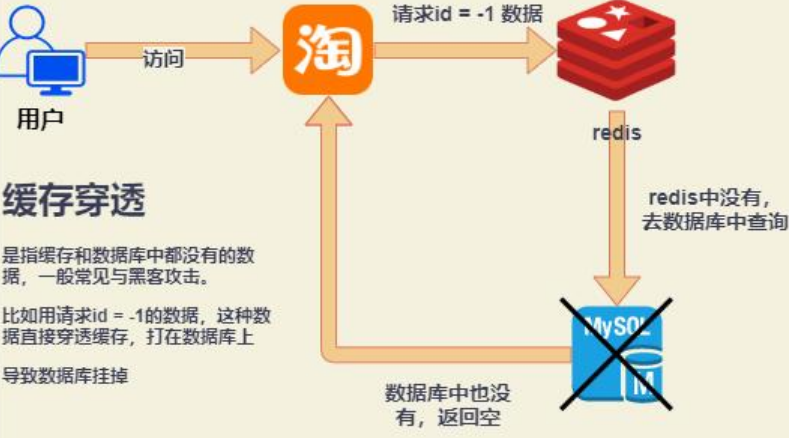
- 问题 :恶意请求查询不存在的Key(如
ID=-1),穿透缓存直击数据库,导致压力过大。 - 解决方案 :
-
布隆过滤器:预先将所有合法Key存入过滤器,不存在则直接拦截(见6.4节详细讲解)。
-
缓存空值 :查询返回空结果时,缓存空值(如
null)并设置短过期时间(如5分钟)。javaObject data = redisTemplate.opsForValue().get(key); if (data == null) { data = db.query(key); // 查询数据库 if (data == null) { redisTemplate.opsForValue().set(key, null, 5, TimeUnit.MINUTES); // 缓存空值 } else { redisTemplate.opsForValue().set(key, data, 30, TimeUnit.MINUTES); } }
-
6.2 缓存击穿:热点Key过期
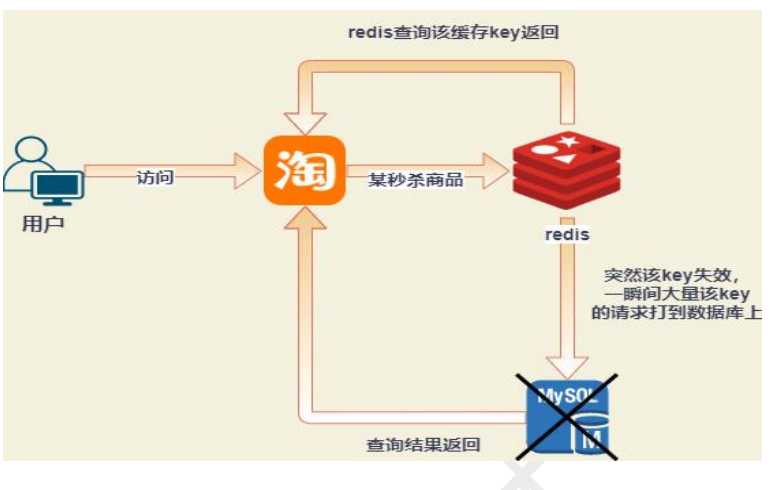
- 问题:热点Key(如秒杀商品)过期瞬间,大量请求同时访问数据库。
- 解决方案 :
-
互斥锁 :缓存失效时,通过分布式锁保证只有一个线程查询数据库,其他线程等待重试。
javaString lockKey = "lock:" + key; Boolean locked = redisTemplate.opsForValue().setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS); if (Boolean.TRUE.equals(locked)) { try { // 查询数据库并更新缓存 Object data = db.query(key); redisTemplate.opsForValue().set(key, data, 30, TimeUnit.MINUTES); } finally { redisTemplate.delete(lockKey); // 释放锁 } } else { Thread.sleep(100); // 等待后重试 return getCacheData(key); } -
热点Key永不过期:物理上不设置TTL,通过后台线程定期更新缓存。
-
6.3 缓存雪崩:大量Key同时过期

- 问题:缓存中大量Key设置相同过期时间,同时失效导致数据库压力骤增。
- 解决方案 :
-
随机过期时间 :在基础过期时间上增加随机值(如30±5分钟),避免同时失效。
javaint baseTTL = 30 * 60; // 基础30分钟 int random = new Random().nextInt(600); // 随机0-10分钟 redisTemplate.opsForValue().set(key, data, baseTTL + random, TimeUnit.SECONDS); -
多级缓存:本地缓存(如Caffeine)+ Redis缓存,Redis失效时本地缓存兜底。
-
6.4 布隆过滤器:穿透防御的终极武器
(1)底层原理
- 数据结构 :由位数组(bit array) 和多个哈希函数 组成。
- 添加元素:通过k个哈希函数计算元素的k个位置,将位数组对应位置置为1。
- 查询元素:若k个位置均为1,则"可能存在";若有一个为0,则"一定不存在"。
- 误判率公式 :
P = (1 - e^{-kn/m})^k
其中,(n)为元素数,(m)为位数组长度,(k)为哈希函数个数。最优(k = (m/n) \ln 2)。
·布隆过滤器的底层核心就是一个巨大的二进制数组 (也叫 "位数组" 或 "bit 数组"),这是它实现高效空间利用的关键。
具体来说:
数组类型 :这个数组的每个元素只能是 0 或 1(二进制位),所以叫 "位数组"。比如一个长度为 m 的位数组,总共只需要 m/8 字节的存储空间(1 字节 = 8 位),空间效率极高。
"巨大" 的含义 :数组的长度 m 通常需要根据实际需求(比如预期插入的元素数量、可接受的误判率)来设计,可能是几万、几十万甚至更大。长度越大,相同条件下误判率越低(但空间开销也会增加)。
核心作用:数组中的每个 "位"(0 或 1)用于标记 "某个哈希映射位置是否被占用"。当插入元素时,会通过哈希函数计算出几个位置,将这些位置的位设为 1;查询时,通过检查这些位置的位是否全为 1 来判断元素 "可能存在" 或 "一定不存在"。
举个直观的例子:
如果一个布隆过滤器的位数组长度是 100 万,那么它实际占用的存储空间只有 100 万 / 8 = 12.5 万字节(约 122KB),却能大致记录几十万甚至上百万元素的 "存在痕迹",这就是它 "用极小空间做大量判断" 的核心原因 ------ 底层的二进制数组功不可没。
.先理解「存储时做了什么」
布隆过滤器底层是一个巨大的二进制数组(全是 0),比如长度为 1000 的数组,初始全是 0。
当你想把一个元素(比如 "苹果")存进去时:
用多个不同的哈希函数对 "苹果" 计算,得到多个数字(比如哈希 1 算出来是 100,哈希 2 算出来是 200,哈希 3 算出来是 300)。
把数组中这几个位置(100、200、300)的 0 改成 1。
再看「检查时怎么做」
当你想判断 "苹果" 是否存在时:
还是用之前那几个哈希函数对 "苹果" 计算,得到同样的位置(100、200、300)。
检查数组中这几个位置:
如果有任何一个位置是 0:说明 "苹果" 一定没存过(因为存过的话这几个位置肯定都是 1)。
如果所有位置都是 1:只能说明 "苹果可能存过"(因为可能有其他元素,比如 "香蕉",经过哈希后也刚好把这几个位置改成了 1,导致误判)。
总结
"不在就一定不在":只要有一个哈希位置是 0,就绝对没存过,因为存过的话所有位置都会被改成 1。
"在可能在":所有位置都是 1 时,可能是目标元素存过,也可能是其他元素 "碰巧" 占了这些位置,所以不能 100% 确定。
(2)RedisBloom模块实战
-
安装 :通过Docker快速部署集成RedisBloom的Redis:
bashdocker run -d --name redis-bloom -p 6379:6379 redislabs/rebloom:latest -
核心命令 :
bash# 创建过滤器(容量100万,误判率0.01%) BF.RESERVE productFilter 0.001 1000000 # 添加元素 BF.ADD productFilter product1001 # 查询元素 BF.EXISTS productFilter product1001 # 返回1(可能存在) BF.EXISTS productFilter product9999 # 返回0(一定不存在) -
Java集成 :
java@Autowired private RedissonClient redissonClient; // 初始化布隆过滤器 RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter("productFilter"); bloomFilter.tryInit(1000000, 0.001); // 容量100万,误判率0.01% // 添加商品ID bloomFilter.add("product1001"); // 拦截非法请求 if (!bloomFilter.contains("product9999")) { return "商品不存在"; }
七、Spring Boot集成Redis:从配置到实战
7.1 环境准备
(1)引入依赖
xml
<!-- Spring Data Redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 连接池(默认Lettuce,如需Jedis需排除Lettuce并引入Jedis) -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>(2)配置Redis连接
yaml
# application.yml
spring:
redis:
host: localhost
port: 6379
password: # 无密码可不填
database: 0 # 默认数据库
timeout: 3000ms # 连接超时
lettuce: # 连接池配置
pool:
max-active: 8 # 最大连接数
max-idle: 8 # 最大空闲连接
min-idle: 2 # 最小空闲连接
max-wait: 2000ms # 获取连接最大等待时间7.2 RedisTemplate配置(自定义序列化)
默认RedisTemplate使用JDK序列化,可读性差,需自定义为JSON序列化:
java
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
// Key使用String序列化
template.setKeySerializer(new StringRedisSerializer());
template.setHashKeySerializer(new StringRedisSerializer());
// Value使用JSON序列化
Jackson2JsonRedisSerializer<Object> serializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper mapper = new ObjectMapper();
mapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
mapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL);
serializer.setObjectMapper(mapper);
template.setValueSerializer(serializer);
template.setHashValueSerializer(serializer);
template.afterPropertiesSet();
return template;
}
}7.3 基础操作示例
(1)String类型
java
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 设置值(过期时间5分钟)
redisTemplate.opsForValue().set("user:1001", new User("张三", 20), 5, TimeUnit.MINUTES);
// 获取值
User user = (User) redisTemplate.opsForValue().get("user:1001");(2)Hash类型(存储对象属性)
java
// 存储用户信息
HashOperations<String, String, Object> hashOps = redisTemplate.opsForHash();
hashOps.put("user:1001", "name", "张三");
hashOps.put("user:1001", "age", 20);
// 获取用户所有属性
Map<String, Object> userMap = hashOps.entries("user:1001");7.4 缓存注解实战(@Cacheable等)
(1)开启缓存支持
java
@SpringBootApplication
@EnableCaching // 开启缓存注解
public class RedisDemoApplication {
public static void main(String[] args) {
SpringApplication.run(RedisDemoApplication.class, args);
}
}(2)使用注解缓存数据
java
@Service
public class ProductService {
@Autowired
private ProductDao productDao;
// 查询商品时缓存结果(key为商品ID)
@Cacheable(value = "product", key = "#id")
public Product getProduct(Long id) {
return productDao.findById(id).orElse(null);
}
// 更新商品时更新缓存
@CachePut(value = "product", key = "#product.id")
public Product updateProduct(Product product) {
return productDao.save(product);
}
// 删除商品时清除缓存
@CacheEvict(value = "product", key = "#id")
public void deleteProduct(Long id) {
productDao.deleteById(id);
}
}八、总结与最佳实践
- 缓存设计:热点数据永不过期+随机过期时间,结合布隆过滤器防穿透。
- 持久化选择 :生产环境推荐混合持久化(RDB快速恢复+AOF数据安全)。
- 线程模型:Redis 6.0+开启多线程I/O提升吞吐量,线程数设为CPU核心数的50%-75%。
- 内存管理 :合理设置
maxmemory和淘汰策略(如volatile-lru),避免OOM。 - Spring Boot集成 :自定义
RedisTemplate使用JSON序列化,通过注解简化缓存操作。