在AI对话应用中,聊天记忆功能让对话系统能够记住之前的交流内容,从而实现更自然的连续对话。就像你和朋友聊天时,朋友会记得你之前说过的话一样。
之前零基础使用didy里面,大模型里面有个聊天记忆的选项。那么这个功能spring ai alibaba怎么实现的呢。
为什么需要聊天记忆?
大语言模型(LLM)本身就像金鱼一样只有7秒记忆------每次提问它都会"忘记"之前的对话。如果你第一次告诉它"我叫张三",接着问"我是谁?",它无法回答"你是张三",因为它不记得之前的内容。
聊天记忆功能就是解决这个问题的,它让AI能:
- 理解对话上下文(知道你们在聊什么)
- 提供个性化回答(记住你的偏好和之前提供的信息)
- 保持对话连贯性(像真人聊天一样)
Spring AI Alibaba的实现方式
Spring AI Alibaba通过"聊天记忆"(ChatMemory)功能来实现这一点,其核心思想很简单:把之前的对话内容保存下来,下次提问时一起发给大模型。
基本工作原理
- 存储对话历史:系统会把用户和AI的每轮对话都记录下来
- 关联对话:通过一个"对话ID"(conversationId)来区分不同用户的聊天记录
- 上下文拼接:下次提问时,自动把之前的对话记录和新的问题一起发给AI
这就像你和一个新朋友聊天时,每次对话都记在小本本上,下次聊天前先复习一下之前的记录,这样就能保持对话连贯了。
具体实现组件
Spring AI Alibaba中主要由以下几个部分协作实现聊天记忆:
- MessageWindowChatMemory:负责管理要保留哪些对话记录
- ChatMemoryRepository:实际存储对话记录的地方
- MessageChatMemoryAdvisor:自动把历史对话添加到新问题中的"小助手"
三种配置方式
Spring AI Alibaba提供了几种不同的配置方法:
1. 简单内存存储(适合开发测试): 这是最简单的实现方式,对话记录保存在程序内存中
2. 数据库存储(适合生产环境): 对于正式上线的应用,通常会使用数据库来持久化存储对话记录
3. 分布式存储(适合大型应用): 对于需要高可用性的场景,可以使用Redis这样的分布式存储
样例代码一探究竟
因为样例代码srping-ai-alibaba-chat-memory-example模块启动依赖redis和mysql,我们可以直接运行docker-compose文件夹下面的mysql和redis。
为了测试方便,windows可以安装docker desktop后启动容器后直接测试。
 启动好容器后,修改模块aoolication.yml里面的redis和mysql配置即可进行测试。
启动好容器后,修改模块aoolication.yml里面的redis和mysql配置即可进行测试。
样例代码提供了四个接口: InMemoryController、MysqlMemoryController、RedisMemoryController、SqliteMemoryController,文章就不做重复搬运工作了,我们可以分别调用接口里面的/call接口发送消息,/messages获取历史消息。其中mysql和redis存储的数据格式如下:
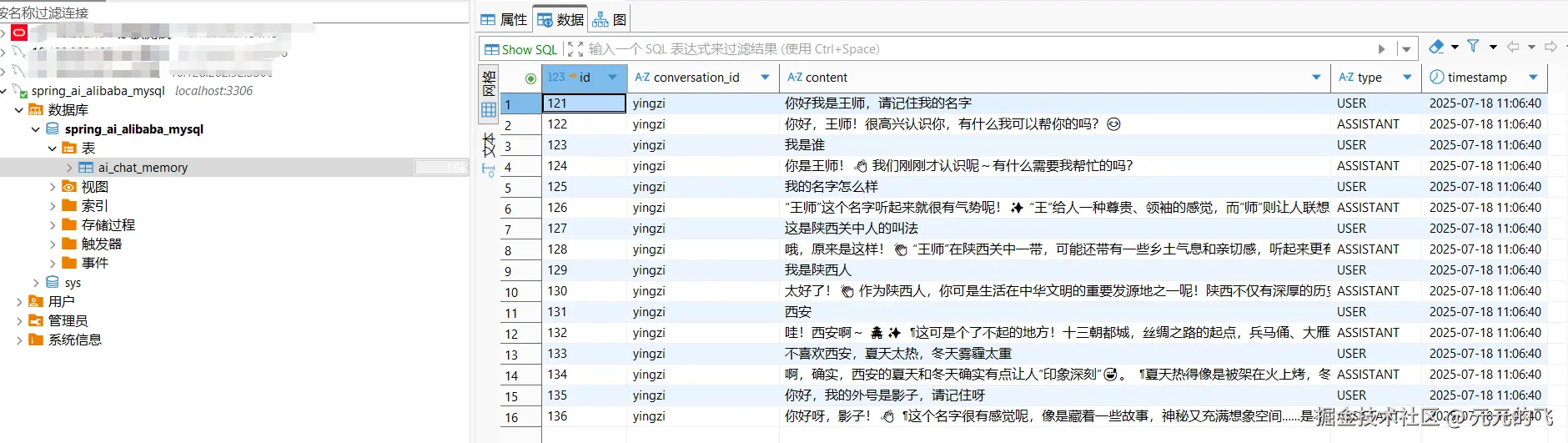 这里的
这里的conversationId就像是聊天室的房间号,系统通过它找到对应的历史记录。
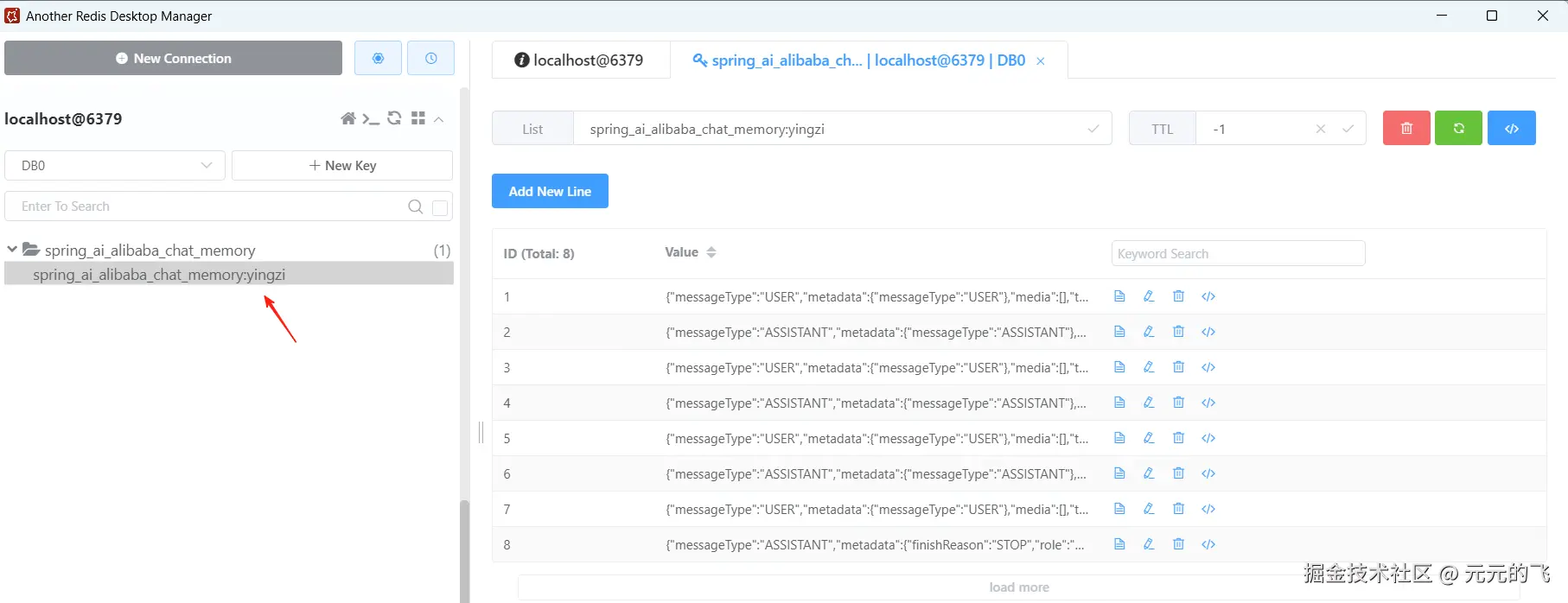 redis存储的key末位为
redis存储的key末位为conversationId可直接查到所有的历史记录。
注意事项
- 记忆长度:不要设置太大,否则会消耗太多token(大模型按token收费)
- 记忆清理:长时间不用的对话可以设置过期时间
- 系统消息:系统消息(如AI角色设定)不会被自动清理
总结
Spring AI Alibaba的聊天记忆功能通过记录和重用历史对话,让AI对话更加自然连贯。无论是简单的内存存储还是复杂的分布式数据库,框架都提供了开箱即用的解决方案。选择适合你业务场景的实现方式,就能轻松为你的AI应用添加"记忆力"。
实际开发中,可以从简单的内存存储开始,随着业务增长再迁移到更稳定的数据库方案。Spring AI的模块化设计让这种升级变得非常简单