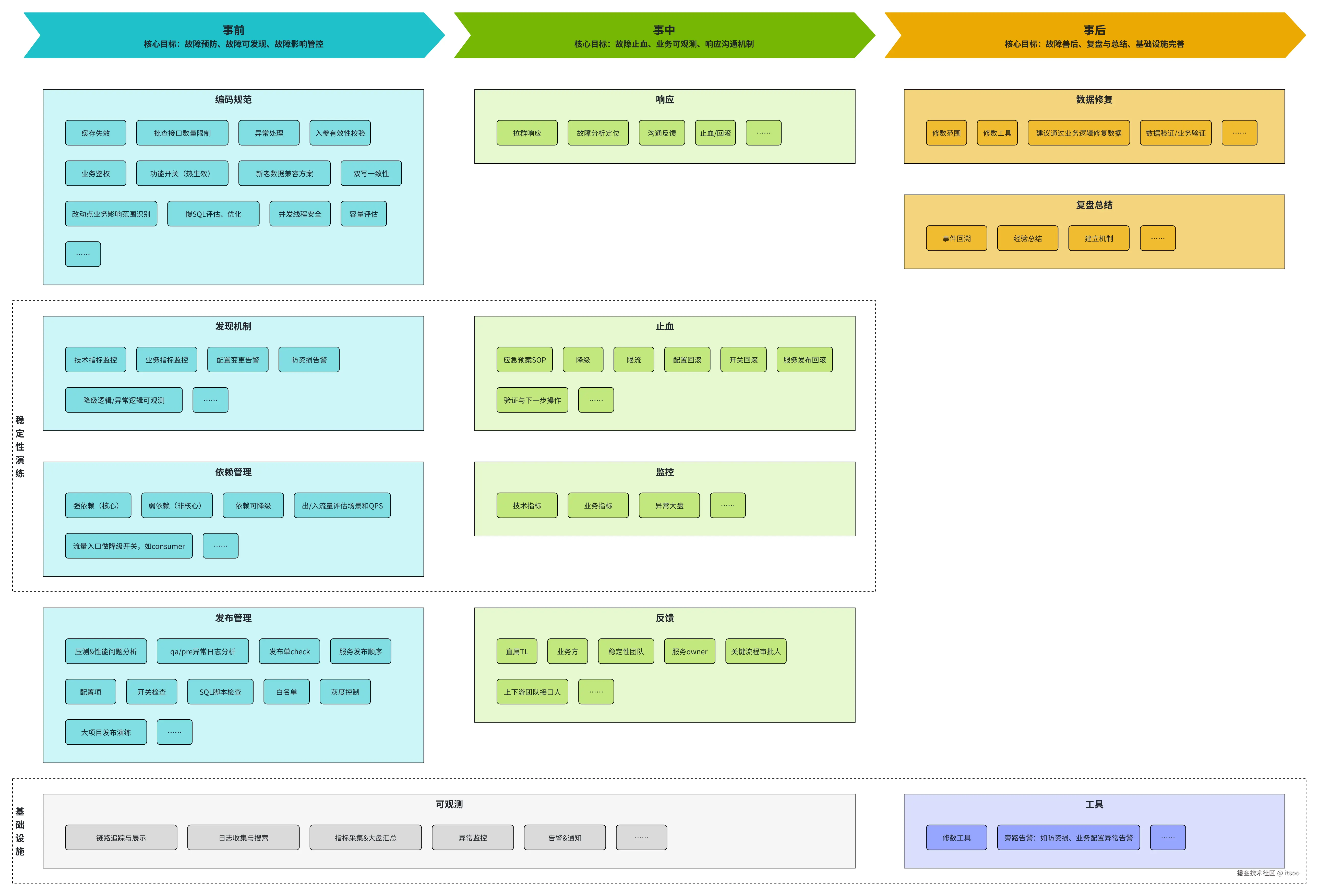
写在前面
近几年互联网公司对稳定性越来越敏感或者说越来越焦虑,我想这个问题的背后是存量市场下,日益重要的用户体验和业务连续性的更高要求。在这样的背景下,研发作为交付的最后一环、线上业务的支撑者,有必要问自己一个问题:稳定性该怎么做?
在讨论稳定性要怎么做之前,我们先来看看稳定性的定义是什么?维基百科的解释:稳定性是数学或工程上的用语,判别一系统在有界的输入是否也产生有界的输出。若是,称系统为稳定;若否,则称系统为不稳定。简单理解,系统稳定性本质上是系统的确定性应答。
那么怎样衡量系统稳定性的好坏呢?在工程侧,我们通常基于时间来定义服务的可用性,即:可用性 = 系统正常运行时间 / (系统正常运行时间 + 停机时间) ,通常被称作 "几个 9",9 越多代表服务全年正常运行时间越长、停机时间越短,服务可用性越高。其中,"停机时间" 主要指因故障导致的业务不可用时间,计划范围内的停机维护通常是不算在内的。
故障从何而来?变更是故障之源。怎么理解变更?业务策略改变,生产环境改变。
举个例子:你负责一个系统,该系统提供了一个下单接口,该接口正常工作的 TPS 为 200。平时也没什么事,然而,有一天运营搞活动,下单接口的 QPS 飙升到 2000,然后你发现系统宕机了!大量用户无法下单。故障紧急,你第一时间选择扩容,加机器,重启!业务逐渐恢复,你也可以松口气了。事后,主管要求你对本次故障写一份报告,但如何定责呢?现在让我们帮你分析分析:由于业务策略发生了改变,所带来的流量远超以往,超过了服务器所能承载的极限,最终导致故障发生。简单理解,业务策略变更,导致生产环境变更,导致故障发生。 此刻你对 "变更是故障之源" 深有体会。
如果你没啥 "体会",那一定是我的问题。嘿嘿。
好了。在进入正文之前呢,我先简单交代一下正文部分的阅读思路:
-
本文开篇的大图,总结了关于稳定性各阶段相关的事项。目标是站在全局视角指导稳定性建设
-
正文部分讲具体要做的一件件事,过程中会配合举例进行说明。目标是落地具体的稳定性事项
发现机制管理
解决问题最重的能力是什么?是发现问题、定位问题的能力。
这一类问题通常在基础建设阶段完成,能力体现在基础设施中,贯穿于稳定性完整的生命周期,是支撑稳定性建设的重要基石。基础设施的核心目标之一就是建设系统的可观测性,我们知道可观测性的三要素是:指标、日志、链路追踪。那可观测性在稳定性建设中发挥着怎样的作用呢?
我拿 "指标" 来举两个例子:
- 通过指标排查数据延迟问题
线上有一个复杂条件的列表查询,你们团队最终的技术选型是将数据库同步至 ES,这条数据同步链路为:canal 将 binlog 发送到 kafka,再由数据同步服务监听 kafka 将数据写入到 ES,这条链路不算长,上线后也没发现什么问题,直到有一天,业务反馈数据查询结果不对。
已知:数据同步链路很久没有发布了,且写入 ES 的字段经过测试和线上验证,不存在字段映射错误的情况。
经过思考后,你决定从数据库捞一条最新的数据到 ES 验证是否是数据错误,然而你发现最新的这条数据 ES 中竟然没有?难道是服务宕机了?并没有,那是消息积压了?有可能,怎么证明消息积压了?什么时候开始积压的?你需要这个指标,此刻它非常重要。
- 通过指标排查服务响应耗时高的问题
早上刚到公司,就有压测同学找到你,说昨晚的线上稳定性压测,接口的耗时和失败率比较高,需要你来排查一下都是什么问题。
已知:最近接口确实有需求改动,但都是纯内存计算,不涉及新增 IO 等耗时操作。压测流量是线上的 2-3 倍。
真是一个头两个大,压测时候的服务器负载情况如何?接口失败的时间点 JVM 在干什么?你怀疑是压测流量过大,导致服务器压力大频繁 GC,从而影响到接口的整体耗时增加和超时失败。但是你怎么证明自己的猜测呢?你需要这个指标,此刻它非常重要。
通过前面两个不太严谨的小例子,你已经知道了指标对于稳定性是多么重要。同理,日志、链路追踪对我们分析线上问题,提升稳定性也都有莫大帮助。今天这里不讲观测平台怎么建设(后面有机会单独开个坑),假设你已经具备了这样的基础设施,你要如何在其上层构建有效的监控&告警体系。
监控&告警
两个视角建设监控&告警体系:技术视角主要监控运行时环境是否健康,业务视角主要监控当前业务是否健康。
- 技术视角:监控&告警
基于日志分析的告警体系:
- 0 容忍异常告警,比如:抛出
NPE、NumberFormatException等异常立即告警 - 业务打点的特殊日志,比如:
[ALERT] xxxx告警内容,遇到这样的日志会被统计并告警,适用场景:- 代码走到了降级逻辑或异常逻辑的,需要按规范打印日志,核心逻辑可观测
- 强依赖场景或强校验场景下,校验不通过的打印异常日志
- 正确使用日志类型,业务场景允许或技术兜底场景的用 warn 代替 error,减少噪音
- 日志信息未脱敏告警,比如:用户姓名、手机号、身份证号等
基于指标统计的告警体系:
- JVM 相关的告警,比如:1 小时内 FullGC 超过 1 次,进行告警
- JVM 内存超过 80% 进行告警
- CPU 使用率超过 90% 的,进行告警
- 带宽出入流量环比涨超 30% 告警
- 接口的 QPS 环比涨超 30% 告警
- 接口调用量跌 0 告警等
基于链路追踪的告警体系:
- span 耗时超过最大阈值的,比如:A 调用 B 超时告警,或 A 调用 B 超过 300ms 告警
- trace 过长的,比如:一个 trace 内的 span 超过 20 个的需要告警,等等......
注意: 技术监控为了反映服务运行时环境相关的健康状态,并在必要的时候(服务不健康)及时告警,如果能做到自动隔离问题容器并保留现场,那就更好了。
- 业务视角:监控&告警
我们仍然可以沿用像建设技术监控&告警体系一样,从业务指标出发,建设一套业务告警体系,关于业务指标的定义与收集,我们先不展开。这里具体聊聊什么样的业务指标应该纳入到业务告警体系中。
首先,定义 "业务方" 是谁?通常情况告警指标是由研发、运维负责配置或建设的,所以自然而然的业务方就被理解为是研发同学,可事实上是这样的吗?告警体系和指标虽然是研发层面提出建设的,但本质上业务方仍然是运营或产品,这一点没有变化!所以,业务指标应该具备以下特点:
- 业务指标通常来说是和 "量" 挂钩的,比如:订单量、GMV、在线司机数等
- 业务指标和技术实现无关
- 能反映业务本身的健康状态,比如:司机在线数下降 20%,很可能是司机无法正常上线,业务出了问题导致的
- 如果某个指标异常了,你反馈给老板、业务方,对方能立马理解并重视
注意: 千万不要把业务告警做成了技术告警,除非你的接口指标和业务指标完全契合,通常业务关注的指标会出现在 BI 报表中,你可以顺着这个思路梳理业务告警的指标范围。
异常大盘
这里所说的异常大盘是以服务为维度,在单位时间窗口内统计异常数量的监控面板,作用是能直观的体现异常波动,给研发判断故障源提供线索。
这么说也许不好理解,我还是先举个例子。下面是 "异常大盘示意图": 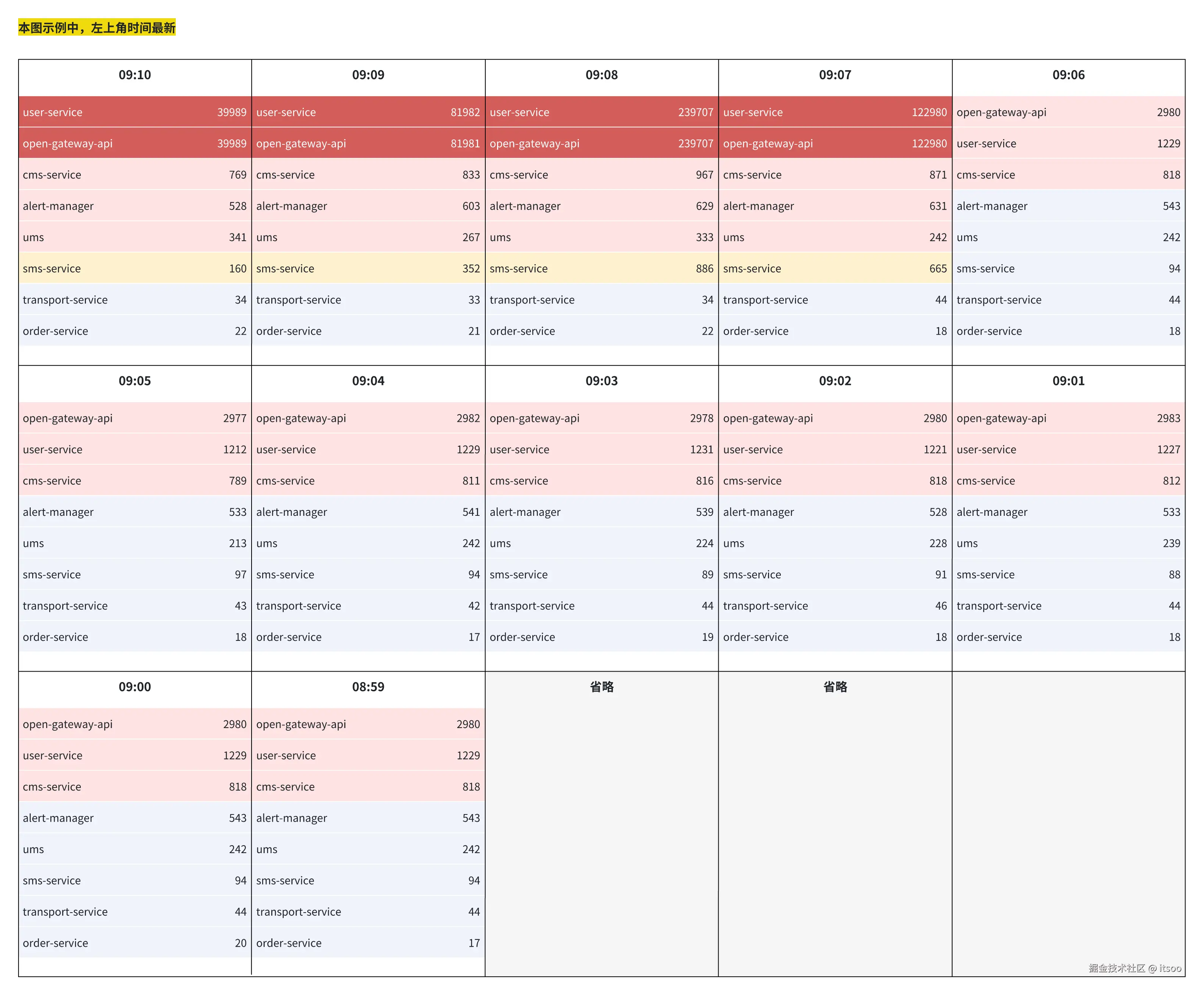
先交代下 "异常大盘示例图" 中各元素的含义:
- 每个格子为 1 分钟时间窗口,其中每横行代表该服务在这个时间窗口内共产生了多少异常
- 异常严重程度根据异常数和异常波动体现,通过颜色显式区分:
- 红色底代表异常来自自身或强依赖,异常数量最多且异常数波动最大
- 粉色底代表异常来自强依赖,异常数量较多但异常波动不大
- 黄色底代表异常来自弱依赖,与异常数量和波动没有关系
- 蓝色底代表异常不多,包含自身、强依赖、弱依赖的异常
- 其中这个异常量多与不多,以每个服务自己配置的阈值为准,如果没有配置则大盘给个默认值;波动则由大盘统一管理,比如:1 个时间窗口异常上涨 20%,或 2 个时间窗口异常上涨 30%
再交代一下示例图中出现的各服务间的关系:
- open-gateway-api 对外提供 REST 接口,自身没什么逻辑,主要做接口的聚合转发,强依赖 user-service
- user-service 为用户中心服务,是核心服务,无依赖
- cms-service 提供客服相关的业务能力,强依赖 user-service
- alert-manager 旁路告警系统,依赖 open-gateway-api 的审计日志
- sms-service 短信与推送服务,弱依赖 user-service
- transport-service 履约服务,核心服务,不依赖 user-service
- order-service 订单服务,核心服务,不依赖 user-service
好了,接下来我们就分析一下这个异常大盘到底说明了什么问题:
- 从 09:07 开始红盘,在此之前没有红盘,说明在 09:07 左右可能发生了线上变更
- 红盘的服务为 user-service 和 open-gateway-api 两个服务,其中红盘之前 open-gateway-api 的异常数大于 user-service,而红盘后则几乎与 user-service 持平,初步判断为 user-service 故障
- 09:08 时 user-service 异常数达到高峰,但是 cms-service 与 alert-manager 异常波动并不大,仍然是粉盘,可能有两点原因:
- 该故障场景下,两个服务对 user-service 和 open-gateway-api 调用量并不大
- 两个服务本身的调用量基数小
- 09:09 开始,异常数量开始明显下降,说明此时已经由技术团队介入,故障正在恢复中
- sms-service 的异常波动明显,同时自身对 user-service 是弱依赖,所以从 09:07 故障开始持续处于黄盘中,再次佐证故障源是 user-service
- 旁路系统不分析
- transport-service、order-service 不依赖 user-service,所以不受故障影响,仍然是蓝盘
异常大盘对于发现问题有非常大的帮助,通过时间窗口可以快速判断问题大概出现在什么时间,通过警示色可以判断哪些服务受问题影响最大,结合依赖关系可以判断故障源是哪个服务。
在稳定性建设中,建议结合自身业务实际情况,建立相应的异常大盘监控机制。
发布&变更告警
如题所示,本小节关注的发现机制主要两块内容:服务发布与配置变更,线上环境中二者任一发生了变化,都需要及时告警出来,目的是为了发生故障时提供回溯线索,帮助定位问题。核心点就是拿到发布和变更的事件,然后由变更告警平台统一收集、告警。所以,第一步就是我们如何拿到相对应的变更事件。
服务发布: 软件行业经过多年的发展,已经具备相当成熟的 DevOps 解决方案,当我们使用 DevOps 平台来管理发布流程时,自然也可以通过配置 webhook 等方式获取到服务发布事件。
配置变更: 配置内容具体指的是技术配置和业务配置,比如:通过配置中心管理的研发配置,和通过运营管理后台配置的运营策略等。这两者配置内容最终都会影响线上环境的变更。
拿到技术配置变更事件,我们可以利用中间件的回调接口,实现上比较简单。而拿到业务配置变更事件,实现起来就稍微有点复杂了,我这里提供两个方案:
- 业务系统嵌入变更告警平台提供的 SDK,将变更事件主动上报给变更告警平台
- 变更告警平台通过监听内网网关审计日志,获取关心的业务变更事件
这两个方案各有利弊:
- SDK 的方案拿到的变更事件更准确,但是各业务系统需要耦合变更事件上报的逻辑,改造范围大、成本高
- 监听审计日志的方式可以有效与各业务系统解耦,但是收集的事件可能不够准确。比如:实际的业务配置是根据入参和读取其它配置,经过逻辑计算后得到的,这种情况审计日志是拿不到准确的变更事件及变更内容的
拿到变更事件后,下一步就是区分哪些事件的变更需要告警出来,所以该平台还需要可配置的告警策略,比如:基础定价系数低于阈值的进行告警,P0 级服务发布的进行告警等。还有,我们要向谁发送告警消息呢?这些要和对应的告警策略一同可配置。
小结一下:变更告警平台核心价值是及时发现线上变更;核心能力是统一收集变更事件,根据自定义策略筛选出有价值的变更事件,并及时做出告警。
最后,我这里也给出一个变更告警平台的示例原型图:
变更告警平台原型图中,并没有给出 "变更事件配置" 页面的设计,这里提供思路,读者可以自行设计,锻炼一下(那肯定不是我懒,hhhh)。
思路: "变更事件配置" 中主要关注的是过滤什么事件,所以我们需要对变更内容进行提取和条件配置,比如:
$.priceRatio < 0.9或$.publish.serverLevel = P0。代码实现上可以借助支持完整表达式计算的规则引擎,也可以自己运用策略模式写一个简版的,支持简单的取值和计算即可。
编码规范管理
编码规范要不要纳入到稳定性管理中,我之前是纠结的。现在把它放进来理由也很简单:不少线上故障是因为编码不规范、不严谨导致的,这个 "不少" 不是危言耸听,我建议你可以查查过往经历的线上问题中,看看这个 "不少" 的占比是不是比较大。
还是先拿两个案例来说:
- 缓存雪崩导致的服务宕机故障
我们的业务场景是用户打车先进行预估询价,再下单叫车。价格是根据呼叫的车型来计算的,一次预估通常会查询多个车型及其对应的计费规则。为了提升预估接口的性能,计费规则会根据联合主键组成 key 放入 Redis(过期时间 5 分钟)。
遇到的问题是,在一次需求中计费规则的联合主键发生变更,这直接导致了缓存中的 key 在代码发布后全部失效,发生了缓存雪崩!缓存雪崩后导致数据库也承受不住压力宕机,整个业务变成了不可用的状态。止血过程耗时很长,我们先对流量进行限流,然后重启数据库,等缓存预热后才慢慢放开流量,完全恢复业务。
分析: 故障的根因是详细设计工作不到位,主键变更未识别到缓存失效问题,最终导致缓存雪崩、引发故障。
- 批量查询未做数量限制引发的故障
该案例的业务场景是三方乘客来我司下单,其中换仓业务模式的订单在发生了变更行程时,需要将该乘客的全部进行中订单发送给风控。
但是三方的代码有 bug,换仓会始终给一个固定的 uid,这就导致了在变更行程的时候,我们查到了大量的进行中订单,然后批量查询订单的时候存储压力大,服务的 CPU 也非常高(大量的反序列化),引发核心服务的性能劣化、单量下跌。
分析: 该问题虽然主因是三方问题,但我们自己的服务也暴露出批量查询未做数量限制的缺陷,不符合防御性编程思维。
上面的两个案例值得引起共鸣,在生产环境中,为了避免这样或那样的问题,我们往往要进行很多额外的设计,这些与业务功能无关的设计,就是我们常说的非功能性设计,它包括但不限于:性能优化、异常管理、开关控制、数据兼容等。这些设计大多是为稳定性做出的努力,接下来我就从编码层面上聊聊和稳定性相关的事。
合理利用缓存
我们在什么情况下需要考虑使用缓存呢?主要考量的有两点:接口的访问量与数据的时效性。
先来讲讲接口访问量大面临的问题:
假设我们服务一共有 3 台机器,每台机器 tomcat 线程池为 200 个,队列 28000 个,我们的业务场景对外只提供 1 个接口,该接口的 RT 是 200ms。刨除其它因素的影响,我们可以每秒钟对外提供 3000 次请求的处理(TPS = 3000),如果外部的流量变大,先耗尽 200 个线程,然后占满 28000 个队列,如果流量更大则触发拒绝策略(429 Too many requests)。
更糟的是服务器的资源还会飙高,CPU 飙高主要是因为线程数过多,频繁的上下文切换、以及 YGC。内存的飙高主要是因为连接队列对内存的消耗,以及每个线程所占用的本地内存空间。如果请求压力持续变大,队列则不会空余出来,经过多次 YGC 之后,连接对象进入老年代,然后触发 FGC,大量的、长时间的 FGC 仍然回收不掉内存的,最终会导致 OOM,是不是很可怕。
所以,我们需要优化服务性能以避免最坏的情况发生,但是在不改变服务器配置的前提下,我们如何提升系统的吞吐呢?这个时候就可以考虑使用缓存了,缓存什么内容呢?计算逻辑复杂的或 IO 耗时高的,我们将最终结果或过程结果通过唯一标识缓存起来,当下一次请求的时候可以直接从缓存中获取,从而减少接口的 RT。
再来讲讲数据的时效性面临的问题:
假设我们有一个定价策略的配置数据,该数据访问量很大且不经常被改动,所以我们将其加入到缓存中来缓解 DB 和服务器的压力,因为这个配置数据非常热点,所以采用了更新 DB 后同步更新缓存。同时提供一个定时任务每 5 分钟查询 DB,并将最新结果覆盖到缓存中,来兜底更新缓存失败的场景。这样运行了很长时间,也没什么问题。
直到有一天,业务上需要对这个定价策略结合实时运力情况做出动态调整,算法团队负责计算最新定价策略,但由于种种原因只能将最新数据写到 DB 中,而你的缓存并不会感知到这一变化。此时面临的问题是:缓存中存在的依然是旧数据。那么,这个问题要怎么解决呢?
两种方式:
- 通过定时任务(周期短:x 秒钟,x 分钟)拉 DB 数据,刷入缓存;优点是架构简单只在代码层面增加一个旁路定时器即可,缺点是时效性较低,需要一定程度的业务容忍度
- 监听 binlog 消息将数据刷入到缓存;优点是数据实时性高,缺点是架构相对复杂,需要额外引入 canal 和消息中间件,降低集群整体的可用性,需要一定程度的稳定性容忍度
聊完了上面的两个问题,读者对为什么引入缓存、什么时候引入缓存,以及引入缓存会带来什么问题,应该有了更直观理解,最后我再简单介绍下缓存更新的主要方式(缓存一致性问题非常重要,后面单独开个坑来讲):
- Cache Aside Pattern(旁路缓存模式)
- 操作方式:查询线程先读缓存,缓存命中直接返回,未命中查 DB 后回写缓存;更新线程直接删除缓存
- 数据一致性问题:高并发情况下很容易出现数据不一致的问题。比如:两个查询线程回写缓存时,存在时序问题,最终导致缓存中的是旧值
- Read/Write Through Pattern(读写穿透模式)
- 操作方式:缓存和数据库整合为一个服务,由该服务来维护一致性。查询线程只需要调用该服务接口
- 数据一致性问题:这种方式可以保证数据的强一致性,但复杂度高且缓存服务容易成为单点
- Write Behind Caching Pattern(写后缓存模式)
- 操作方式:查询线程只读缓存,由其他线程异步地将数据库数据刷入缓存(上面示例中讲过了)
- 数据一致性问题:数据一致性可以保证,但时效性较低
注意: 本小节介绍的都是将 DB 数据更新到缓存中,数据一致性也是以这种使用方式得出的结论,有些以缓存数据为主,异步更新到 DB 的非主流方案不在讨论范围内。
缓存不可能无限扩展,所以缓存中的数据一定要设置过期时间。此外,还有大 key 的问题尤其要重视。
做好接口容量控制
评估接口容量的本质就是评估接口执行代价的大小。 如果一个接口的执行代价较大,那这个接口就不应该被随便访问,要么控制访问权限,要么控制访问频率。
控制访问权限:
- 开放给公司内部访问的二方接口,需要接入内网网关,通过且仅能通过内网访问
- 开放给合作方访问的三方接口,需要配置访问白名单,或通过接口签名认证等方式进行访问权限控制
- 开放给互联网用户访问的接口,需要接入公网网关,通过用户身份认证等方式进行访问权限控制
控制访问频率:
- 接入 sentinel 等流控组件,对接口的请求频率做限制,通常该方式所控制的流速限制在单个服务节点上
- 利用 redis 来实现分布式环境下,对接口整体的流速控制,常采用滑动窗口算法实现
开放给二方的接口,一定需要多问一句调用方的使用场景是什么,QPS 大概有多少,避免因接入新的流量导致接口或服务的性能裂化。如果公司有统一的 SLA 管理平台,接入方发起 SLA 签订申请,由服务 owner 或 TL 进行评估审批,审批通过后才可以正常调用接口,否则接口调用失败。这样的方式可以更规范服务方对调用方的管理,研发团队规模越大收益越大,在稳定性层面也可以规避很多扯皮的问题。
批量查询接口,一定要在底层做好数量限制,不能无限制的大批量查询。这里说的 "底层" 指的是真正处理批量查询的逻辑,比如我要根据行程单批量查询行程列表,那这个底层查询逻辑是必须要对入参数量进行限制的,不能说传 20 条就查 20 条,传 100 条就查 100 条。保护存储层就是在保护服务的可用性,通常来说没有哪种业务对存储层都可以是弱依赖的,对吧。
现在,我们已经具备了接口的访问控制能力,接下来就分析分析接口执行代价的大小,要通过什么维度、怎么衡量。简单理解,接口所做的事对资源的消耗是大是小。
- 计算:即代码在执行过程中是不是 CPU 密集型的,体现在序列化、反序列化,循环次数,动态解析(如反射、正则表达式、规则引擎等),一般我们可以结合火焰图来分析接口对 CPU 的消耗情况
- 内存:接口执行过程中有没有生成临时大对象,比如文件对象,流,数据库连接等。其中,涉及到网络 IO 的部分还可能产生堆外内存开销,对容器整体内存利用率有多大,内存的申请和释放是否频繁
- 带宽:刚提到的网络 IO 部分是典型的带宽资源依赖,服务收发的包体越大,对带宽的消耗越大,严重的话很可能发生网络拥塞,影响集群整体的吞吐
- 存储:是否存在慢 SQL,是否存在大 key 等
注意: 管理好自身接口的容量,就是对接口执行代价进行评估,并对评估结果做相应管理。对外开放的接口需要同时做好访问权限控制,和访问频率控制。裸奔的接口稳定性隐患非常大。
有效处理异常
大多数情况下,一个业务逻辑的触发是从接口被调用的那一刻开始的,对接口入参有效性检查的目的是:允许正常业务执行,拦截异常业务执行。
入参包括显式入参(查询参数、请求体等),和隐式入参(经过网关转换后的用户信息等),一般情况下:显式入参是业务执行的必须参数,隐式入参是数据鉴权、业务鉴权的必须参数。
还是举个例子来讲,下面一段伪代码表示用户只能访问自己的订单详情:
java
@RestController
@RequestMapping("/order")
public class OrderController {
@Autowaried
private OrderService orderService;
@PostMapping("/detail")
public Response<OrderDetailDTO> detail(@RequestBody QueryOrderDetailReq req) {
//! 入参有效性校验
AssertUtils.notNull(req, "查询订单详情,请求为空");
AssertUtils.notBlank(req.getOrderId(), "查询订单详情,订单id为空");
OrderModel orderModel = orderService.getOrderModel(req.getOrderId());
return Response.success(OrderConverter.INSTANCE.model2Dto(orderModel));
}
}
@Service
public class OrderServiceImpl implements OrderService {
@Autowaried
private OrderAbility orderAbility;
public OrderModel getOrderModel(String orderId) {
UserInfo user = RequestUtils.getContext().getUserInfo();
AssertUtils.notNull(user, "查询订单详情,用户信息为空");
OrderModel orderModel = orderAbility.getOrderModel(orderId);
String uid = orderModel.getUserInfo().getUid();
//! 进行业务鉴权
AssertUtils.equals(user.getUid(), uid, "查询订单详情,订单不存在");
// 业务代码,省略......
}
}这段示例代码中,断言工具对参数无效或不满足业务鉴权时会抛出异常,以达到拦截异常业务执行的目的,代码逻辑清晰简单,不再赘述。值得注意的是通过异常来控制正常流程与异常流程,所以这就引出下面要讲的内容,异常必须做处理,严禁直接吃掉异常。
什么是异常处理?异常要怎么处理?这两个问题我纠结了一下,不太好用一句话描述,所以呢,我决定直接上代码,通过举例子,让读者更直观的理解异常处理。
提问:下面 3 个代码片段中,哪个是有效的异常处理?
java
// 依赖用户中心 RPC 接口
@RPC
private UserService userService;
// 片段1
public UserDTO getUserInfo(String uid) {
try {
return userService.getUserInfo(uid);
} catch (Exception e) {
return null;
}
}
// 片段2
public UserDTO getUserInfo(String uid) {
try {
return userService.getUserInfo(uid);
} catch (Exception e) {
log.error("查询用户中心接口异常", e);
throw e;
}
}
// 片段3
public UserDTO getUserInfo(String uid) {
try {
return userService.getUserInfo(uid);
} catch (Exception e) {
log.error("查询用户中心接口异常", e);
return null;
}
}我这里分析一下:
- 片段1:不是有效的异常处理,虽然捕捉了异常,但是直接返回 null,导致上层调用方不知道是 RPC 接口返回 null,还是异常后返回的 null,也没有打印日志,相当于把异常给吃了,反例!
- 片段2:不是有效的异常处理,虽然捕捉了异常,也打印了错误日志,但是异常仍然向上抛出了,这导致调用方在处理异常时会纠结要不要打印异常,相当于把异常处理又丢给了调用方
- 片段3:是有效的异常处理,不仅捕捉了异常,也打印了错误日志,同时在异常时返回给调用方默认值,当调用方拿到 null,是可以通过异常日志判断是 RPC 接口返回的 null,还是异常返回的 null
请读者结合示例代码及业务场景,体会下入参校验和异常处理,应该怎么用,要怎么用好。
业务幂等
不知道你在工作中有没有遇到这样的情况,你提供出去的接口,调用方会问你:这个接口是幂等的吗?一开始你可能会不以为意,直到有一天,你调用别人的接口超时了,而你并不知道对方的处理是否成功了,恰恰这个接口对你的业务又十分重要,这时候你才开始纠结该怎么办?
怎么办?一个简单的法子:对方的接口做成幂等的,这样对于调用方来说,不管是不是超时导致的调用失败,只需重新再调一次接口即可。(PS:超时这个场景当然有其它办法解决,但不在本小节的讨论范围)
先梳理下幂等的定义:幂等性接口是指执行多次和执行一次的效果相同的接口。 简单理解,无论调用多少次该接口,其结果都是相同的。
对于数据来说,最终的操作都是 CRUD,其幂等特点,如下图: 
通过上图我们可以看到 "新增" 和 "修改" 并不是幂等操作,那我们就聊聊要如何在接口维度上进行设计,以保证 "新增" 和 "修改" 的操作幂等。
新增:
- 利用数据库的唯一性约束,如唯一索引或主键(描述为业务主键),来避免插入重复数据。该方式需要调用方生成业务主键,比如 Snowflake 生成全局 ID 的方式,为每个操作请求预分配业务主键
- 通过 token 方式对新增进行授权。比如调用方在调用新增接口之前,需要先调用授权接口获取 token,然后需要带着该 token 请求新增接口,校验通过后才被执行
这么描述比较单薄,为了搞清楚这两种方式各自针对的场景是什么,还是举例子来说,下图是下单接口对幂等性的实现逻辑: 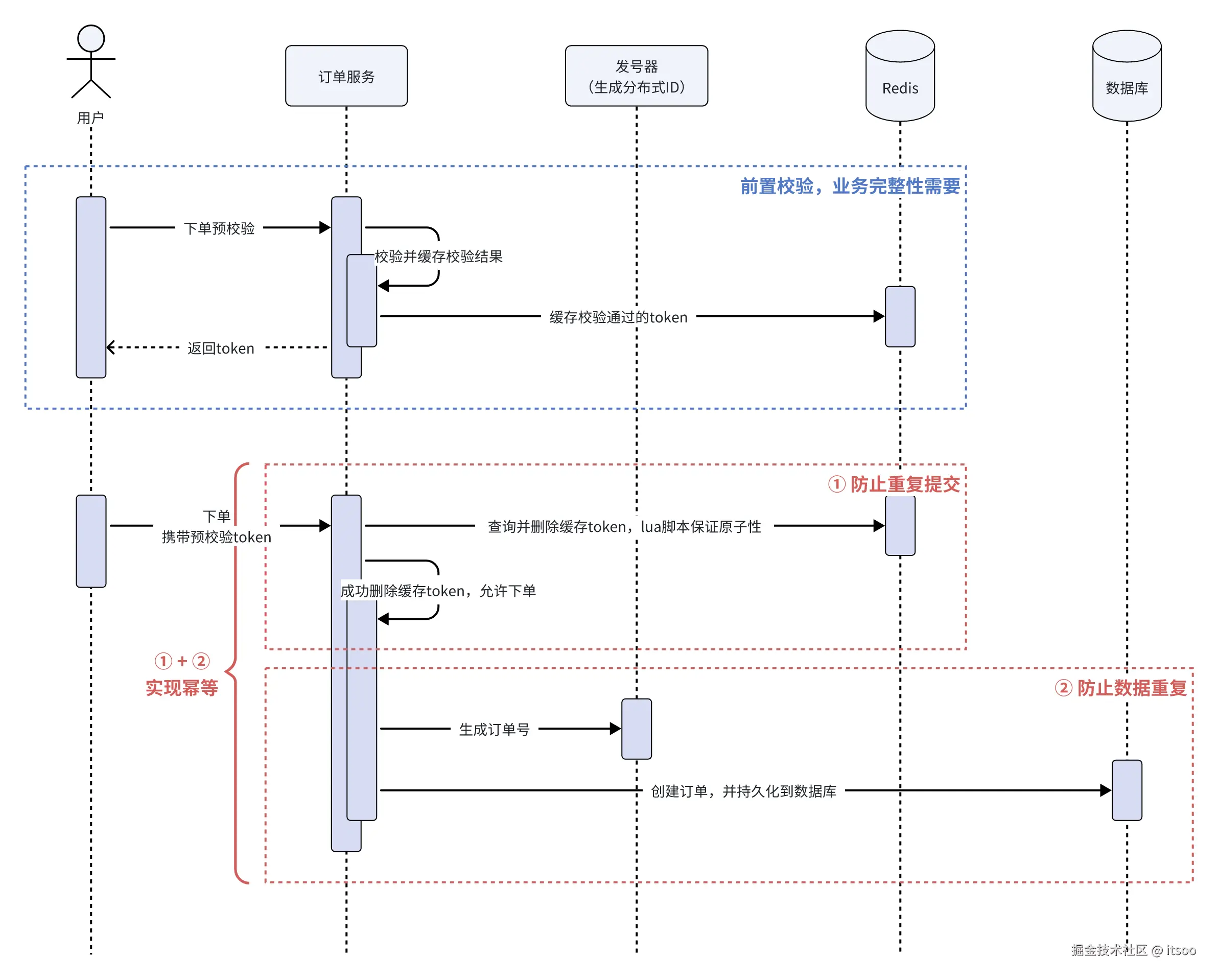
修改:
- 使用状态机来管理状态转换,只有当状态符合预期时才执行操作,从而保证幂等性。代码实现上需要遵循 "一锁二判三更新" 的原则,防止状态被击穿。的确,该方式会牺牲一点接口性能,但凡事有取舍,数据正确的重要性远大于接口吞吐的重要性
- 在更新操作中使用版本号,只有当版本号匹配时才执行更新,否则拒绝更新,以此保证幂等性。简单理解,就是利用乐观锁的原理,实现数据修改时的幂等
还是举例子来说,下图场景是货主发货、司机接单流程中,更新订单保证幂等的实现: 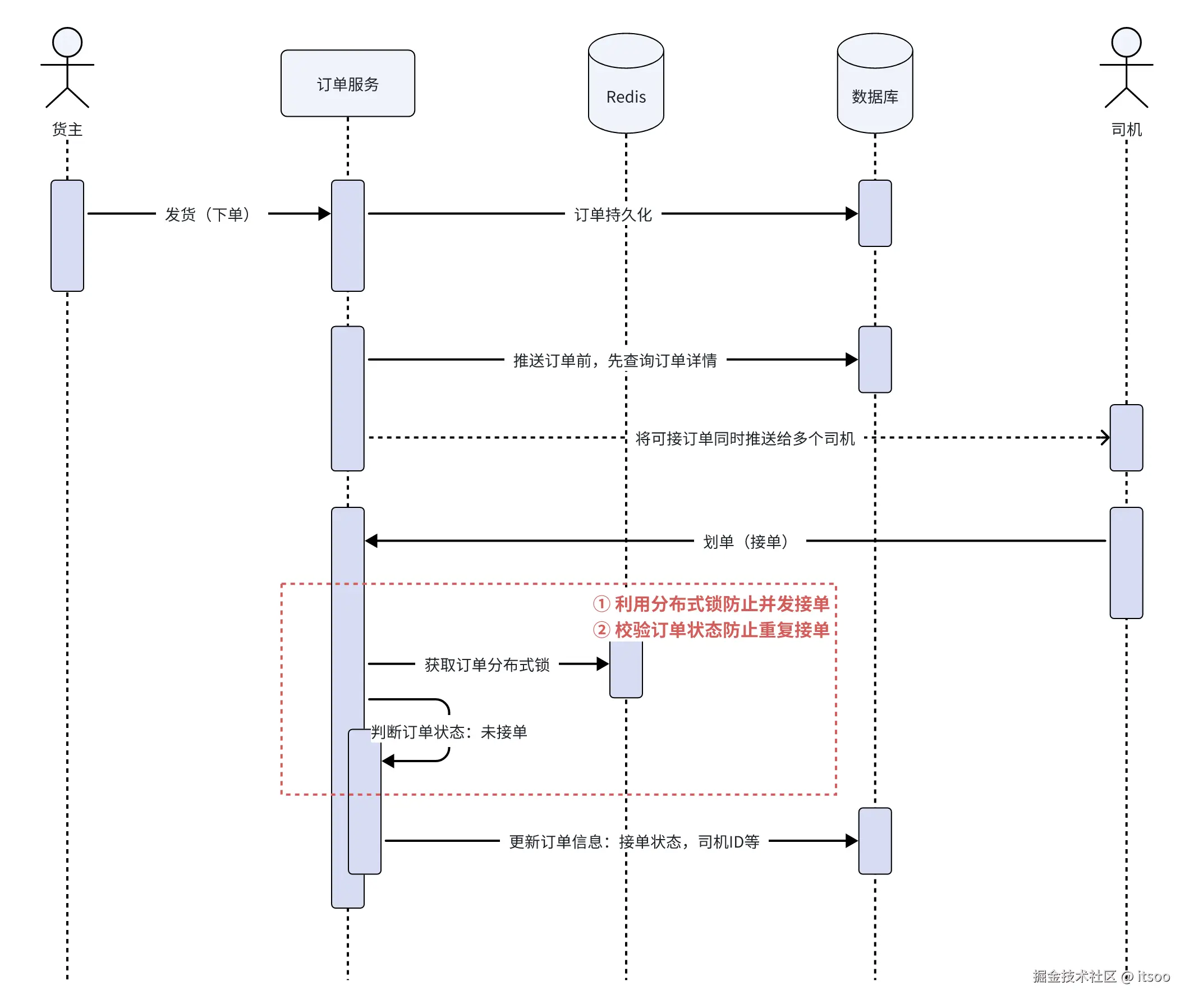
正确的降级处理
本小节所讲的 "降级",指的是通过开关控制的新老业务流程,为啥会存在这样的场景呢?我们在开发业务需求的时候,往往不是从 0 开始新写一套代码的,大多数情况下都是在原有流程上面做改造,那就带来了一个问题,就是如果新需求或新代码有问题怎么办?为了能应问题并快速恢复业务,往往我们会选择通过开关控制,在关键节点甚至整个流程上面做切换。
大致流程如下:
- 需求 → 开发 → 发布 → 开关切换新流程 → 没有问题 → 走新流程
- 需求 → 开发 → 发布 → 开关切换新流程 → 发现问题 → 回滚开关 → 走老流程
所以,这里面需要注意什么呢?
- 开发阶段:
- 改造范围识别,即哪些业务节点对数据的影响是一致的,比如接单、改派都会更新司机信息,如果需要改动涉及司机信息变化的,两处肯定是一起改
- 开发阶段都涉及哪些服务?新老流程的开关各自加在哪?开关配置能不能统一收口?
- 发布阶段:
- 先发服务还是先切开关?数据和流程一致性保证?
- 新流程需要可观测、可验证
这一小节的内容不多,通过开关的方式实现业务降级(或回滚)的优缺点,简单分析一下:
优点:一旦发现问题需要回滚时,往往只需要变更下开关,操作路径短且立即生效,对于线上止血场景操作非常友好
缺点:代码耦合度太高,新老流程基本会并存较长的时间,需要定期清理老版本代码,不然影响工程整体的可维护性
依赖管理
依赖管理的本质就是对核心场景和非核心场景的资源管理。业务上,我们有核心业务链路,也有支撑类的非核心业务链路,我们要做的就是尽可能的提升核心链路的可用性,必要的时候切断非核心链路,避免服务雪崩。
那怎么管理好核心接口的可用性?梳理清楚核心依赖(强依赖)、与非核心依赖(弱依赖)是前提。
强弱依赖如何区分?
从接口功能层面进行梳理,完成自身业务需要最少做完哪些事? 以此做为判断依据,梳理接口能力中的强、弱依赖是什么。
还是举几个例说明:
- 乘客叫车,系统为其创建需求单,需求单持久化到 DB 是否为核心依赖?从技术视角出发,需求单持久化失败等同于叫车失败,因为我的数据就没有保存下来,所以该接口对 DB 是强依赖
- 打车场景下,乘客上车时购买承运人保险,那购买保险是否为核心依赖?从业务视角出发,购买保险失败乘客就不能上车了吗,肯定不是的,所以该接口对购买保险是弱依赖
- 接下来从存储介质 ES 出发,对两种场景的依赖强弱进行分析:
- 司乘的列表查询走 ES,因为 ES 的数据同步链路存在不稳定性问题,当 ES 不可用时,我们将手动降级到 DB 查询,所以我们说列表查询对 ES 是弱依赖
- 与此相对的,数据同步服务监听 binlog 解析并写入到 ES 中,在这个场景下 ES 的依赖应该是强是弱呢?是强依赖!因为这条链路就是做数据同步的,如果不能成功同步,就应该捕获并处理异常场景
强弱依赖的判断是要 "具体情况具体分析" 的,同一个依赖源,不同场景下的关注点不同,自然强弱程度也就不同。所以,我们自身提供出去的接口需要区分核心或非核心,我们引入的依赖同样需要区分核心或非核心,这就是对依赖的管理。
既然依赖有强弱,那么管理的时候各自侧重点是什么?我这里简单总结:
强依赖: 当依赖的接口异常时,等同于自身接口异常、阻断业务,所以强依赖的接口应该关注成功率,比如:
- 接口超时,在有限时间内没能等到依赖方的返回,解决该问题的话,我们需要关注依赖接口的 99 线,按耗时的 2-3 倍设置超时时间,如有必要也可适当延长
- 返回值与预期不符,遇到该问题通常需要我们先自查请求参数是否正确,错误的请求肯定不会得到正确的响应。如果自身入参没问题,则需要下游排查,可能的因素有:代码 bug、接口降级返回兜底值等
弱依赖: 当依赖的接口异常时,不影响自身业务的执行结果,所以弱依赖接口应该关注降级逻辑是什么,比如:
-
业务场景对兜底值不敏感的,可以在代码层面写死一个默认值,当接口调用失败时,返回该值即可
-
兜底值具有一定的业务属性,需要经过业务逻辑计算出相应的兜底值,此时需要我们写降级逻辑的代码,并在接口失败时执行降级逻辑
-
下游数据不经常变的,我们可以做一层本地缓存,当下游接口成功时更新缓存,当下游接口失败时从缓存获取并返回(备选方案,通常降级逻辑越简单越好)
如何快速降级依赖?
依赖能否被降级,取决于依赖的重要程度(#3.1 强弱依赖如何区分?# 所讲的核心依赖和非核心依赖。核心依赖在业务层面没办法做降级(即业务兜底逻辑),但是如果核心依赖服务劣化而不加处理,最终会导致调用方请求发生堆积,从而影响服务器集群整体的稳定性,甚至发生 "服务雪崩"。
如下图,Service D 的超时最终会导致 Service G、Service F、Service A、Service B 的请求堆积。 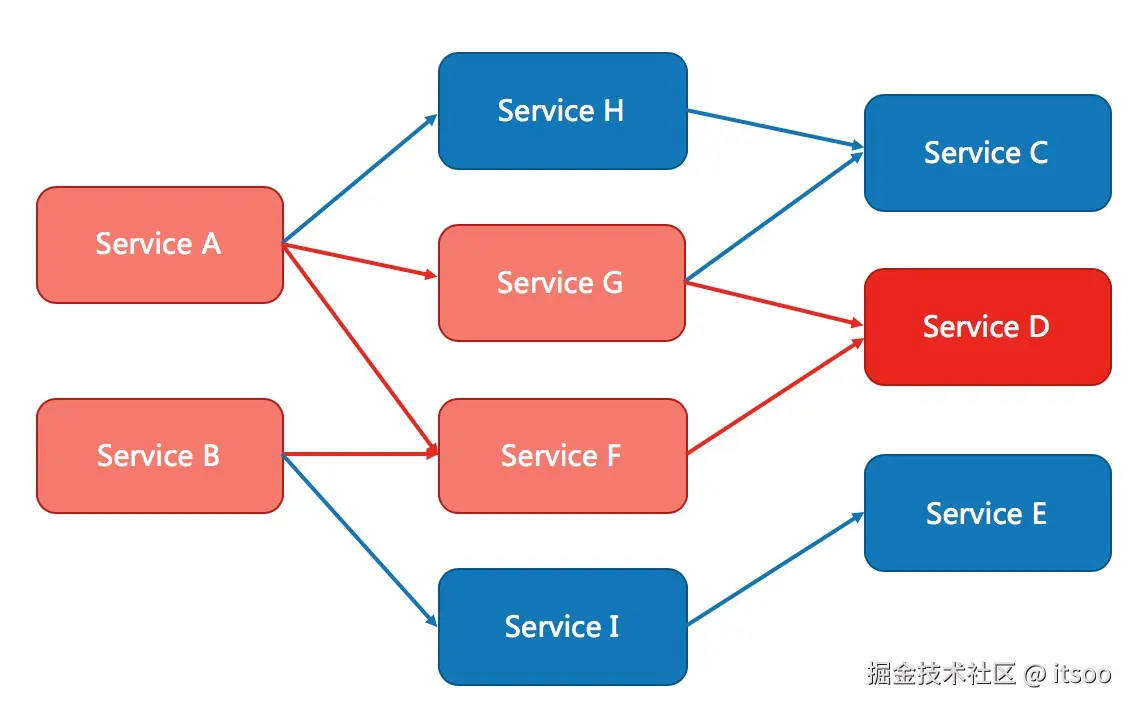
所以,我们需要一种手段,当服务的调用发生不稳定时,能够实现 fail-fast。下面就讲讲两种实现方式:
基于 Sentinel 实现:
在 Sentine 中有个非常重要的概念叫 "资源",它标注了调用的服务、接口、数据源等。降级也是通过对资源的控制实现的,使用起来不复杂:
- 集成 Sentinel 控制台: 没啥好说的,要使用人家的能力肯定先去集成
- 定义资源和降级规则: 通过
@SentinelResource注解,在代码中定义需要 Sentinel 保护的资源,指定资源名称和降级处理方法 - 使用数据源扩展: 集成配置中心(比如 Nacos、Zookeeper、Apollo 等),以实现规则的持久化和动态更新
- 动态配置规则: Sentinel 控制台提供了可视化页面,可进行规则的配置
- 客户端监听配置变化: 当 Sentinel 控制台对资源的访问规则进行变更时,这些变更会实时通知到各个节点中,并动态应用这些规则,实现动态的资源访问控制
因为官方文档已经很全面且详细了,本文就不拿具体代码举例了,借用官网一张图,描述下生产环境通过集成配置中心,而实现动态更新规则的整体工作流程: 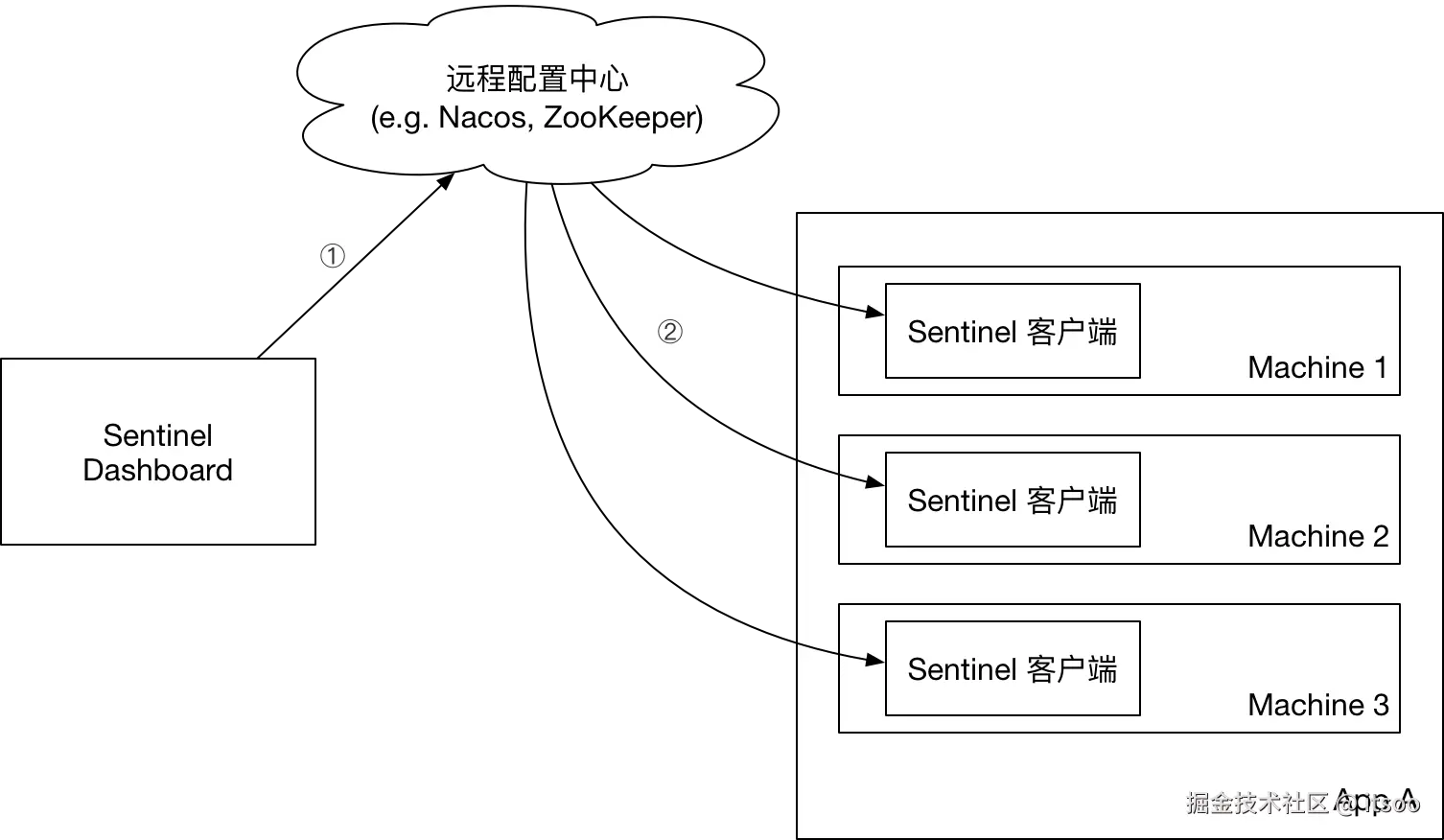
参考官方 wiki:github wiki - 在生产环境中使用 Sentinel
基于配置中心实现:
我们也可基于配置中心自行实现对降级逻辑的控制,核心思路:
- 要能实时感知到配置中心的 key 发生了变化
- 通过切面对依赖资源进行包装,包装的前置逻辑为检查当前依赖是否处于降级状态
下面通过伪代码来举例说明:
- 降级逻辑能力提供
java
/**
* 资源描述注解
*/
@Documented
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface DependencyResource {
/**
* 资源名称
*/
String name();
/**
* 资源强弱标识
*/
DependencyTypeEnum type();
/**
* 降级方法名
*/
String blockMethod();
}
/**
* 依赖强弱标识
*/
public enum DependencyTypeEnum {
/**
* 强依赖
*/
STRONG,
/**
* 弱依赖
*/
WEAK;
}
/**
* 切面进行降级逻辑实现
*/
@Slf4j
@Aspect
@Component
public class DependencyResourceHandler {
@Around("@annotation(me.itsoo.DependencyResource)")
public Object handle(ProceedingJoinPoint jp) throws Throwable {
MethodSignature signature = (MethodSignature) jp.getSignature();
Method method = signature.getMethod();
DependencyResource dr = method.getAnnotation(DependencyResource.class);
if (!this.hasDependencyKey(dr.name())) {
try {
return jp.proceed();
} catch (Throwable e) {
log.error("【发生异常】日志可以更详细描述,比如切点信息", e);
return this.fullback(jp, dr);
}
}
return this.fullback(jp, dr);
}
/**
* 降级逻辑
*
* @param jp 切点
* @param dr 资源描述
* @param e 异常
* @return obj
* @throws Throwable Throwable
*/
private Object fullback(ProceedingJoinPoint jp, DependencyResource dr, Throwable e) throws Throwable {
MethodSignature signature = (MethodSignature) jp.getSignature();
// fail-fast 强依赖抛出异常,防止调用方堆积
if (DependencyTypeEnum.STRONG.equals(dr.type())) {
if (e != null) {
throw e;
}
throw new RejectedExecutionException(dr.name() + "资源被降级");
}
// 弱依赖降级逻辑
Method blockMethod = signature.getDeclaringType().getDeclaredMethod(dr.blockMethod());
return blockMethod.invoke(jp.getTarget(), jp.getArgs());
}
/**
* 当前资源是否被降级
*
* @param key 资源名
* @return true降级,false未降级
*/
private boolean hasDependencyKey(String key) {
// 此处通过配置中心API,获取是否存在该配置
return false;
}
}- 降级逻辑能力调用
java
/**
* 模拟调用用户中心RPC
*/
@Repository
public class DemoUserRepoImpl implements DemoUserRepo {
@Override
@DependencyResource(
name = "user-center/me.itsoo.UserService#getUserById(String)",
type = DependencyTypeEnum.WEAK,
blockMethod = "getUserInfoBlock")
public UserInfo getUserInfo(String uid) {
// 这里是RPC调用
return null;
}
private UserInfo getUserInfoBlock(String uid) {
UserInfo emptyUserInfo = new UserInfo();
return emptyUserInfo;
}
}上面的伪代码实现了简单的降级逻辑处理,可根据实际情况进行调整,本文主要介绍思路。
核心逻辑不复杂:依赖资源正常的情况,就正常调用返回。一旦发生异常,按强弱依赖分别进行处理:
- 强依赖:抛出异常,调用异常或主动降级的 reject 异常,主动降级目的为了防止调用方堆积
- 弱依赖:执行兜底逻辑,即自定义的降级方法
应急预案 SOP
我们往往在稳定性层面上准备了很多,但当故障来临的时候还是会手忙脚乱,为什么?因为我们需要判断故障特征,需要定位问题,需要确认止血方案,需要业务方拍板。这中间有太多的环节在侵占时间,在分散我们的精力,于是乎,我们不禁要发出疑问:有没有什么办法能够帮助我们显著减少止血时间?
有,答案是《应急预案 SOP》,那这又是个什么东西呢?"应急" 指手册收录的问题特征中存在,有标准的止血操作流程,可以在第一时间指导 "已知" 故障的处理,从而减少研发的心智负担和止血时间。
现在你知道了有这么个东西存在,但是似乎很少有人真正实操或纳入到流程规范中呢?是的,这个应急预案手册看上去很美好,逻辑上也说得通,但是光这个 "已知" 就会让很多人望而却步,下面我来说说它的不足:
- 全面性不足:收录的问题,要么在技术方案初期已经考虑到异常场景,要么就只有线上遇到了问题才可能被收录,所以问题的来源、全面性很受限
- 时效性很难保证:不是说不能保证,只是代价会很大,日常需求中如果改动到了 SOP 涉及的部分,就必须及时维护,这对研发熟知 SOP 提出了更高的要求
- 业务的多变性:通常来说,降级方案对业务都是有损的,所以 SOP 提供的降级方案是与业务方达成一致的结果,但业务的变化或业务方的变化,都可能导致原降级方案不再适用
所以,SOP 不能说是一无是处吧,但至少也是完全没用。
⬆️ 上面这句是屁话,开个玩笑,hhhh。
聊聊我们在工作中要怎么解这个问题,SOP 本身很重不容易落地,但其指导思想却非常重要,在可预见的异常场景中,我们必须拿出有效的应对手段,所以,我们需要在技术方案中体现异常降级的设计:异常流程是什么?降级降在哪?开关有哪些?回滚能否解决问题(比如数据的兼容,不一定是回滚服务就能解决的问题)?
但仅仅有技术方案还做不到 SOP 的闭环,我们还需要发布方案来协调(发布方案要包含哪些内容,我将在 #发布流程管理# 一节来讲),简单理解,技术方案设计异常场景的降级,发布方案提供 SOP。 我们看看这对搭档能解决《应急预案 SOP》的哪些问题:
- 全面性:技术方案加发布方案仅包含本次发布的应急预案,所以全面性问题解决不了
- 时效性:每次的发布都是最新的内容,所以时效性完全有保障
- 多变性:不管业务历史如何变化,本次发布的降级预案都是与业务方达成一致且最新的,所以可以解决业务多变性的问题
你看,并没有额外花费更多的成本,却解决了 2/3 的主要问题。如果让你来做决策,要不要采用技术方案加发布方案的方式来管理应急预案 SOP 呢。
发布流程管理
我们通常说的研发流程是什么?我的理解,一个从产品需求提出到发布上线的过程,就是完整的研发流程。
发布方案
发布流程作为需求落地的最后一环,自然很重要。为此我们需要提前准备好发布方案,那么,发布方案到底是什么呢?简单理解,发布方案是为发布过程做指导,可以按步骤执行并最终完成发布过程的文档。 有效的发布方案,是随便拉来一个人也能按照文档一步一步完成发布过程,他不需要参与其中的需求或发布方案的编写,能看懂、可执行就是 "有效"。
我整理了一下,有效的发布方案,至少需要包括以下内容:
- 服务列表:登记待发布的所有服务,跨团队时需要标注外部服务及接口人
- 发布分支:服务对应的 release 代码分支,以及是否合入最新 master,避免遗漏
- 发布顺序:体现服务的依赖关系,需要先发谁、后发谁,如果是蓝绿发布且在同一个发布单的,可以一起发
- 版本号:服务自身及依赖的版本号,比如需要 to-maven 的 jar 包等
- 配置项检查:技术侧的配置中心,业务侧的后台管理,上线前是否需要提前配置好,值应该是什么
- 脚本检查:SQL 脚本,刷数据或表结构变更等,这一块通常在服务发布之前执行完成
- 开关状态,降级逻辑:业务上的或技术上的降级准备,通常在技术方案时设计,在发布方案时做好 SOP
- 需求单列表:本次发布的服务所涉及的需求,及对应的 feature 分支,方便回溯问题
- 切量逻辑:比如按城市、按人群,灰度放量节奏
有了发布方案也不能保证一定不出问题,所以我们还需要注意以下几点:
-
其中,异常降级、回滚的部分内容,应在开关配置的位置进行说明或单独一个模块进行说明,什么样的异常特征应该操作哪个开关或回滚发布
-
此外,发布方案应提前与有关的研发对齐并确认,发布过程中,对应的研发同学需要同步做好监控及指导,发布团队应该具备有效的沟通机制
-
发布方案虽然由 PM 拉齐整理、登记,但具体到发布细节中还需要各个模块明确负责人,明确责任是为了保障发布方案的有效,不给别人埋坑、也不给自己埋坑
发布上线演练
服务多、跨团队的大项目在上线前一定要进行发布演练,演练能有效暴露问题,比如:我曾经负责一个超过 3600 人天的大型项目,该项目涉及改造的服务非常多,为了确保能顺利发布,我们在线下进行了完整的发布演练,为了让读者更有体感,我简单表述下过程:
- 确认演练方案:因公司规定线上发布当天灰度 1%,第二天切全量,所以我们演练模拟的节奏是,发布灰度 1%,然后 40 分钟内切量到 100%
- 人员到位:提前整理好发布方案,并和各方确认发布演练的时间(比如中台团队、中长途平台团队),演练当天核心服务发布负责人拉到会议室,其他支撑团队拉到线上会议
- 配置检查:线上线下发布人员,同步检查配置、脚本,锁定发布版本,并明确给出确认的反馈
- 发布节奏管理:
- 通过表格管理待发布服务、负责人、计划发布时间、实际发布时间、计划切流时间、实际切流时间
- 当到达计划发布时间时,与对应负责人确认操作是否完成,收到反馈后维护表格实际发布时间
- 当到达计划切流时间时,与对应负责人确认操作是否完成,收到反馈后维护表格实际切流时间
- 按此方式,第一批外部支撑服务发完,组织第二批核心服务发布,依然从第 3 步开始重复发布过程,检查配置、脚本,锁定发布版本
- 发布验证:服务端发完后,通知端上研发打新包,测试回归主链路,当冒烟通过后才算发布成功,演练结束
- 问题记录:演练过程中发现任何的卡阻问题,都要重点记录并确认解决方案,务必在上线前解决
这一 Part 没什么特别需要总结的,凡事预则立,不预则废。就是这个道理。
性能压测
性能压测(Performance Testing)是一种软件测试,旨在评估系统在不同负载下的性能表现,以确保系统在实际运行中能够满足预定的性能要求。性能压测的流程和目标:
流程:
- 制定压测目标,即接口预期需要达到什么样的性能指标
- 压测数据准备,尽量靠拢生产环境的业务场景,尽量准备不同的数据样本
- 压测脚本的准备与执行
- 过程监控,监控性能指标,比如 CPU、内存、RT 等
- 压测报告分析,生成压测报告,并分析可能存在的性能问题
- 性能调优与回归测试
目标:
- 验证性能是否达到预期
- 识别系统瓶颈,比如 CPU 飙高、内存占用高、慢 SQL 等
- 评估系统容量,根据单节点的吞吐评估集群整体可以应对的并发数,是否需要扩容等
- 发现是否存在稳定性隐患,比如长时间的高负载压力下,服务假死或对下游服务影响过大的
除了上面目标提到的几个问题以外,压测还可以帮助我们发现并发安全的问题,为啥单独拎出来讲,因为我实际经历过并记忆犹新。没错,这次拿出的案例我是主角。😭
由于内容比较长,我单独拆了一篇文章:并发问题导致kafka consumer全部掉线
异常分析
为了保障服务能够稳定发布上线,我们可以给发布流程再加上一道保险:报错日志的捞取和分析。具体执行如下:
- 限定在预生产环境,因为预生产部署的通常都是即将发布的代码
- 日志时间范围通常为近一天,或待上线分支最近执行测试的 x 小时内
测试通过工具捞取完异常之后,由研发进行缺陷确认:是否存在问题,是否需要处理。有问题就修复问题并回归验证,没问题就直接准备发布了。
这个流程不要太简单,没有啥特别需要介绍的,但执行效果确实不错,可以避免 NPE 等低级问题。
稳定性演练
最近在 B 站上看到一句话很流行:"先问是不是,再问为什么?"关于本小节的内容,我也参照这样的范式提出问题:互联网研发团队要不要做稳定性演练?怎么做稳定性演练?
先回答 "是不是" 的问题:我可以很旗帜鲜明的告诉你,互联网行业的研发团队一定要做稳定性演练!
再回答 "为什么" 的问题:
- 制定演练计划
- 确定目标和范围:明确演练要达到的目标,比如非核心组件故障,不能影响核心链路(参考 #依赖管理# 对强弱依赖进行梳理)。同时确定演练的范围,包括涉及的系统模块、网络环境、中间件等。比如在货运平台的场景下,可以将范围锁定在货源模块、订单模块、费用模块及其对应的存储层
- 安排时间和人员:选择合适的时间进行演练(比如晚上 10 点之后),尽量避免对正常业务造成影响。至少需要安排开发、测试、运维等人员参与演练,并明确职责。比如,开发负责对出现问题的代码进行修复,测试负责记录问题及验证修复结果,运维负责监控系统资源、故障注入等
- 制定流程:将演练步骤罗列出来,包括什么时间点注入什么故障,研发&运维需要执行什么操作止血或恢复,监控告警数据是否正确,如何验证步骤和操作流程等
- 准备演练环境
- 搭建压测环境:建立一个与生产环境相似的稳定性压测环境,区别于日常的功能性测试环境,具备独立的服务和存储的一整套链路的环境部署
- 配置工具和资源:安装压测工具如 JMeter、故障注入工具 Chaos Monkey、备份恢复工具等。同时准备好演练所需的测试数据等
- 执行演练
- 按照计划实施:然后就是按照计划一步一步的严格执行操作步骤,期间做好检查项的记录(不管是通过的,还是不通过的),有问题的记录问题,并保存好排查问题的必要现场
- 沟通与协调:参与线上演练的成员最好在一个会议室,以便与发现任何问题都能及时沟通
- 总结与改进
- 收集数据和反馈:记录过程中的各种数据,包括监控数据、问题记录、告警信息等。向参与演练的人员收集反馈,了解演练过程中遇到的问题和建议
- 分析问题和原因:对收集到的数据和反馈进行分析,找出系统的稳定性问题及原因,总结过程中的问题及改进措施。最后,还需要负责人跟踪解决
补充:读者可结合文章开头的 #稳定性事项总览# 大图进行理解,和设计稳定性演练的具体内容,稳定性演练的核心目标是:
- 验证发现机制是否可靠
- 验证依赖梳理是否正确
- 验证止血动作是否有效
- 验证监控告警是否全面
稳定性响应机制
线上发生问题,及时的响应到底有多重要?
举个例子:你在某电商平台准备下单购买新款手机,正在开开心心完成付款的时候,页面弹出 "系统异常请稍后重试",你有点恍惚、有点气愤,因为你明明支付成功了,此刻的订单却仍然是待支付状态!钱去哪了?做为用户来讲此刻非常着急,因为钱没了嘛,第一时间反馈给客服,等待平台处理。你想想如果这个过程中没有任何给用户的反馈,客户有没有可能会报警,说平台欺诈(偷笑)。
建立有效的响应机制的目的是:为了确保业务的连续性,能够快速响应和解决问题。这要求即使是非工作时间,也要有人能第一时间介入问题的排查中来,所以,可以通过值班&巡检的制度来落实稳定性响应机制,具体措施如下:
- 明确值班职责: 定义清晰的值班职责和流程,包括问题响应、记录和交接等
- 合理排班: 考虑工作量和个人情况,公平合理的安排值班(避免忙的忙死、闲的闲死)。当然如果临时有事的,也可以私下换班
- 通过工单系统跟踪: 这里说的工单系统不局限于研发流程工单系统,也可以是来自客服的工单,主要目的是避免技术直接对接用户带来的干扰。通过客服或技术支持过滤非紧急问题,减轻研发负担、同时也为了更高效的排查问题(因为问题有优先级了嘛)
- 业务熟练度: 尽量让熟悉相关业务的研发人员参与到值班,以便快速解决问题,这里说的参与是熟悉的研发可以给值班人员提供帮助。另外核心场景做好沉淀和自动化,收录过的问题能快速给出结论,而不必每次都人工介入排查,思路参考 #应急预案 SOP#
- 问题记录: 通常由技术侧引发的问题需要有记录,以便做好经验总结和流程改进,参考 #故障复盘#,记录工作可以交给技术支持或稳定性管理团队,但一般需要研发提供问题根因和解决方案
- 值班巡检: 值班人员在值班当天需要完成线上巡检,具体工作可以包括:核心服务日志巡检、业务巡检,服务器指标巡检,接口耗时是否异常、是否有突刺等。然后判断问题的严重程度,如何跟进(比如,因外部服务抖动影响我方业务的)
- 应急响应流程规范: 建立一套标准来规范值班人员的响应动作,比如下图:
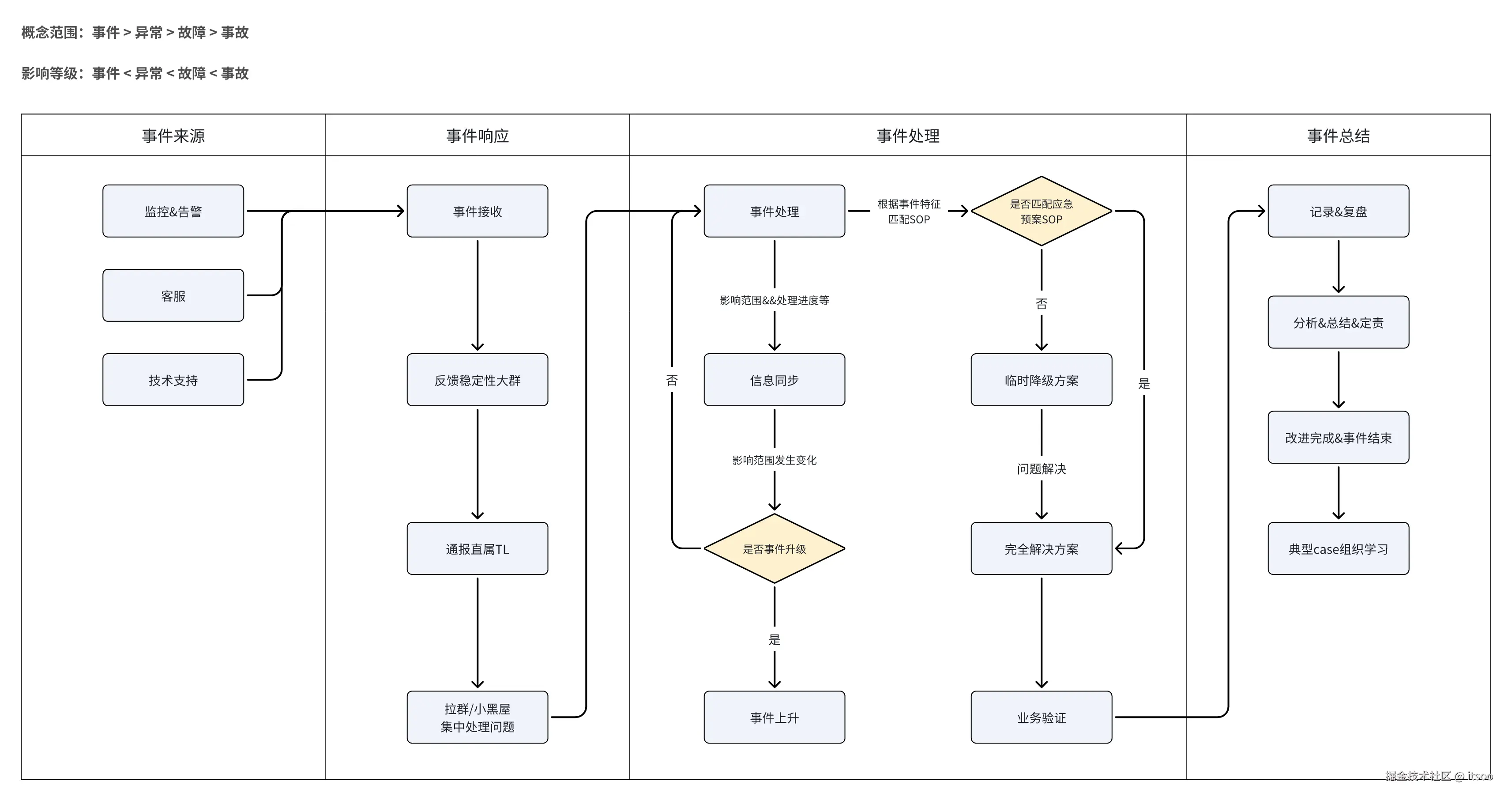
一套标准的应急处理流程,就是为了让值班人员知道该干什么,怎么干,从而做到训练有素,缩短故障时长。在整个流程规范中,有几点需要注意的:
-
事件来源:清晰的问题描述有助于排查问题,所以,有必要提供反馈问题的标准模板,对客服、技术支持等进行培训,建立高效的问题反馈源
-
事件响应:一定是先通报问题(反馈稳定性团队、反馈直属 TL 等),然后才是处理问题,尽可能让更多的相关方知晓问题
-
事件处理:首先止血,然后定位问题是什么。定位问题思路:模拟复现,找相关数据,分析完整请求链路。定位问题仍往往是最耗时、最复杂的任务
-
事件总结:先回溯事件,过程完整不要遗漏,然后分析问题,总结经验
数据修复
数据修复属于事后的一环,主要为了处理故障期间产生的问题数据(影响业务流程的、卡单的、费用异常的)。数据修复主要有几种方式:
| 方案 | 直接 SQL 变更,进行数据的修复 | curl 请求内网后门接口,对数据再进行一次业务触发 | job 定时对账,与数据补偿 |
|---|---|---|---|
| 优点 | 1. 最简单直接 | 1. 修复动作简单 |
- 可以应对经过业务逻辑加工过的数据修复 | 1. 自动执行释放人工 check 成本
- 可以应对经过业务逻辑加工过的数据修复 | | 不足 | 1. 脚本准备复杂且容易出错
- 不好应对经过业务逻辑加工过的数据修复
- 不利于修复操作的审计 | 1. 业务系统开后门不利于安全合规
- 接口上下游必须保证幂等
- 不利于修复操作的审计 | 1. 需要依赖 job 中间件
- 数据往往以系统身份进行修复,不利于修复操作的审计 |
这几种方式各有利弊,但是都有一个共同的问题,不利于修复操作的审计。那有没有一种方案可以兼顾以上的优点,同时规避不足呢?有,开发一套数据修复的工具平台(属于基础设施),由工具平台统一管理修复数据的业务场景、修数逻辑、及修复操作的审计。
通过平台的建设(一次性投入),研发同学可以在页面修复数据(长期使用),即可以避免脚本出错,又可以降低业务理解和沉淀给数据修复带来的额外成本。那接下来我讲讲修数平台的设计思路:
- 需求分析和规划
- 业务理解:确定有哪些必要的业务场景,及其修复目标是什么,比如 "卡单 - 一键完单" 或 "卡单 - 取消订单" 这样的场景
- 异常定义:什么样的数据算异常数据?比如长时间未完单的(长时间是多长时间,同样需要定义),哪些数据是必须的(缺失就会计算异常)
- 修复方式:确定哪些异常可以自动修复,哪些异常必须手动修复(人工修复意味着数据重要,通常需要经过审批后才能变更数据)
- 异常数据发现
- 实时发现异常:业务系统在完成领域内动作的时候,发出一个事件出来(比如司机接单事件),修数平台收到该事件校验行程当前状态,是否为期望的司机已接单状态,如果不是则数据异常
- 定时发现异常:每个任务周期(比如 10 分钟)会检查停留在进行中状态的行程,比如第 1 轮任务周期行程 A 的状态为 "接乘中",第 2 轮任务周期行程 A 的状态仍为 "接乘中",则数据异常(只是举个例子,实际情况可能要根据接乘的导航预估时间去算)
- 异常告警:异常数据被发现之后,需要根据自动修复或手动修复决定是否告警,以便及时发现异常数据,并对数据的修复动作进行审计日志记录(即使是自动修复也需要留痕)
- 用户界面
- 异常数据列表,包括:异常原因,业务场景等字段的展示,提供 "一键修复" 等按钮(一键修复会弹出修复方案列表,让用户选择,比如前面举例的 "卡单 - 一键完单")
- 告警配置,指哪些异常需要告警、告警时机、告给谁,这样的配置项
- 审批配置,哪些修数场景需要经过审批才能执行的
- 修复记录列表,对数据修复操作的全部记录,不仅仅是用户操作记录,也包括系统操作记录
下面我也给出修复工具的设计原型稿(基础版): 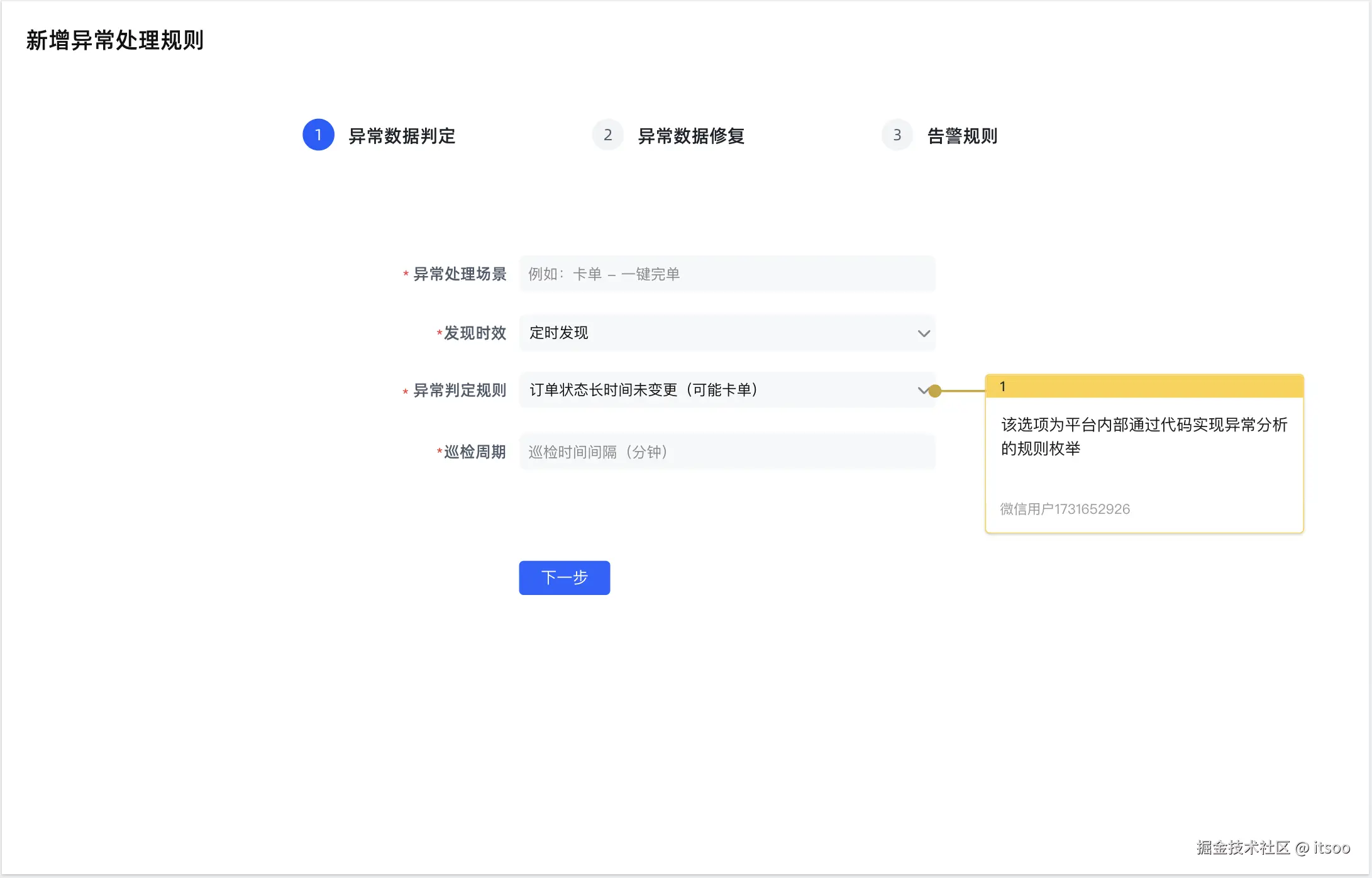
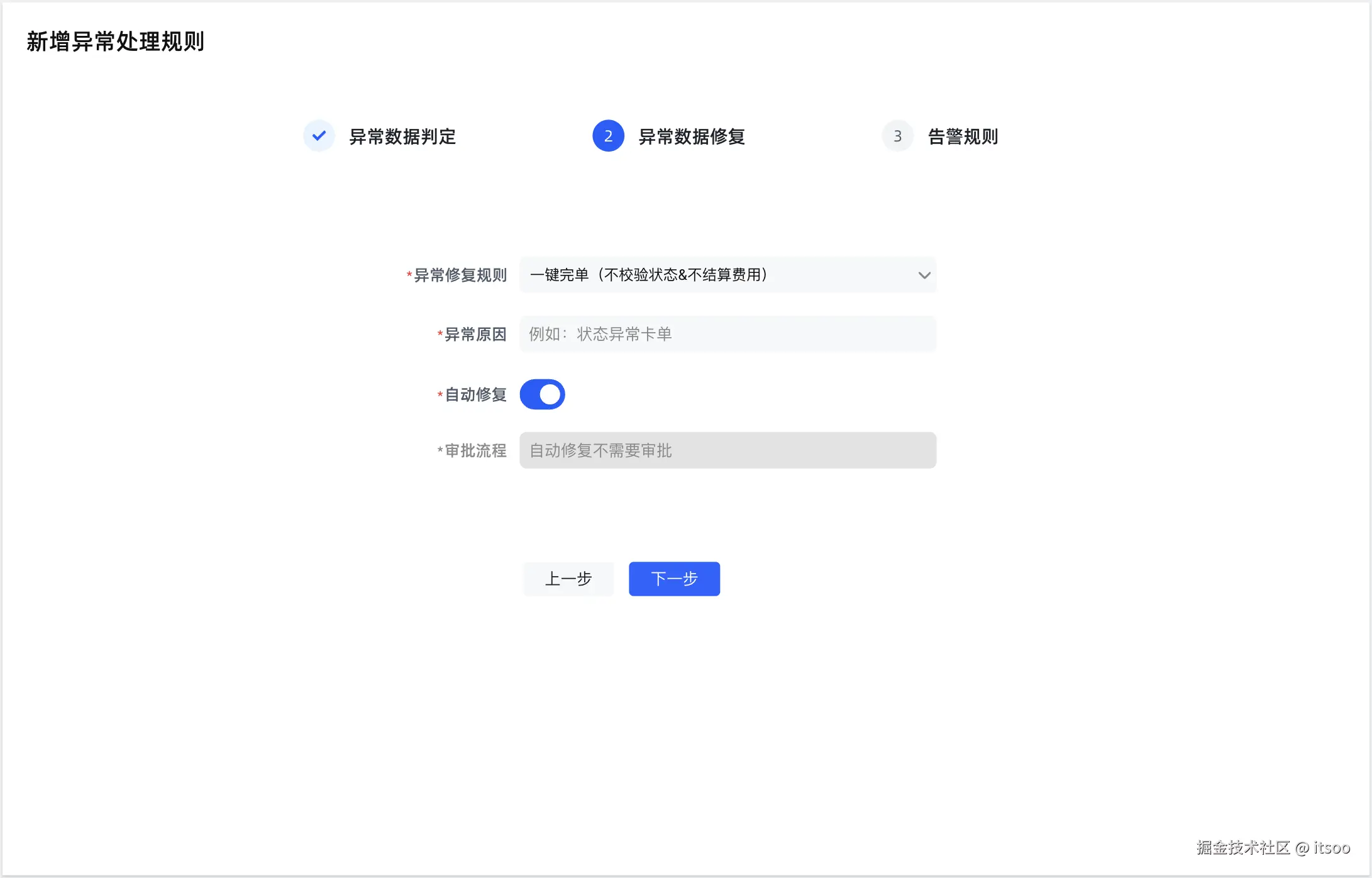
说明:原型图中给出的配置比较简单,读者可以根据实际情况进行设计,核心思路是:通过代码实现异常数据的判定,通过代码实现修复数据的逻辑,判定&修复本来就是两个维度的事情,所以,很可能不同的异常数据对应同一个异常修复方案。
此外,原型稿中还省略了异常数据列表,该列表提供手动的 "一键修复" 按钮,点击该按钮触发弹窗后选择异常修复规则,并执行。
故障复盘
复盘是事后的分析总结,是学习和改进的必要过程。复盘会虽然有必要给业务方和老板一个交代,但是也千万别把复盘会开成了甩锅大会。😂
有效的复盘应该首先确认什么情况需要开会,什么情况只需要做好通报(不管开不开会都需要通报)。开会意味着需要严肃复盘,此类问题往往具有比较典型的特征,如下:
- 未遵守流程规范: 违规操作(比如随意切流,未做好发布监控,私自变更等),流程规范是既有经验的总结,不遵守流程规范是不敬畏生产、是无视规章制度的行为,该情况一定需要开会且明确通报
- 低级错误: 比如测试环境很容易复现或已经复现的问题,不重视、不整改仍然坚持发布上线的,此类问题与不遵守研发流程规范一样恶劣,必须严肃复盘且明确通报
- 典型问题: 该类型的故障不一定造成多大的业务影响,但很容易形成经验,有必要开会组织大家学习,避免以后的踩坑
- 产生重大影响的: 重大事故(P0 级、P1 级),对业务产生明显、严重或重大损失的故障,需要开会复盘,此类事故往往需要拉齐多方定责
复盘&通报形式:
- 开会复盘:严重问题或业务关注度高的问题,需要组织复盘文档、开复盘会、明确责任(故障定级)并邮件抄送相关人员(业务方、产研团队、稳定性团队、责任相关方等)
- 邮件复盘:影响面不大或在业务可接受范围内的(提前与业务方沟通并确认),组织复盘文档、邮件抄送直接相关方,由产研内部复盘
- 文档复盘:影响很小的,组织复盘文档、团队(通常指研发团队、小组为单位的)内部复盘
无论问题是否严重,复盘文档都是必要的,有效的复盘文档至少需要包含以下内容:
- 基本信息:故障标题、故障级别、故障时间、责任人、故障说明
- 影响面:
- 实际产生的业务损失,比如资损 xx 元,单量下跌 xx%,用户在线时长下跌 xx% 等
- 可衡量业务损失的故障指标,比如故障时长、异常数据量(可修复的数据与不可修复的数据)等
- 事件回溯:详细描述过程,谁在什么时间做了什么操作,按照时间线客观的描述问题、不遗漏
- 分析与总结:分析问题的根因,制定后续 Action 闭环问题,沉淀经验或流程规避下次产生类似问题
复盘流程:
- 产研团队主导故障复盘会议
- 确定会议人员和时间,发送会邀
- 准备复盘材料
- 做好会议纪要,并按流程进行故障通报,参考上面的 #复盘&通报形式#
事后处理环节很重要,请一定谨慎对待,往往很多事情 "不上称没有四两重,上了称,一千斤也打不住"。
你品,你细品 🙈
总结
稳定性的建设是一个长期且艰巨的任务,需要考虑的点即多且杂,这篇文章我整理和准备了很长时间,希望能对读者有所帮助。
本文主要从稳定性建设的全局视角梳理了:事前、事中、事后各阶段要做什么准备、做什么操作,有些细节正文没有体现。正文部分对于稳定性事项先解释了为啥要做,然后通过举例还原场景,并给出怎么做的方案。
核心内容为:
- 如何建设发现问题的机制
- 哪些事项或问题需要纳入规范管理
- 遇到问题时如何响应:稳定性响应机制、应急预案 SOP 等
- 基础工具类的平台怎么建设
- 如何控制故障影响范围:强弱依赖、降级恢复、稳定性演练
在稳定性各种事项中,不少是有关联的,比如稳定性演练就需要关注:发现机制、依赖管理、止血和监控;尤其是基础设施部分,贯穿了稳定性的生命周期。所以,读者应根据自身实际情况、基础设施的完善程度,对稳定性整体事项作出取舍,哪些在当前稳定性管理中是痛点问题、需要重点关注的,哪些可以放到后面再搞。
简单理解,没有银弹!满足自身所处的阶段需要,以最小的代价实现稳定性管理,就是优秀的解决方案。
这个文档也许只是个开篇,后续也可能继续完善,我也希望能通过这种形式总结自己、帮助别人。最后开个新坑,下一篇文章对代码和架构进行思考和总结,题目就叫《什么是好代码?什么是好架构?》。
See U!