口诀:
读多写少用旁路,先更库再删缓存;
强一致选写透,缓存代理更库走;
性能优先用写回,异步批量有风险;
高并发加双删,延迟兜底防旧残;
强一致用锁串,并发虽低稳如山。
一、核心方案及适用场景
1. Cache Aside Pattern(缓存旁路模式)
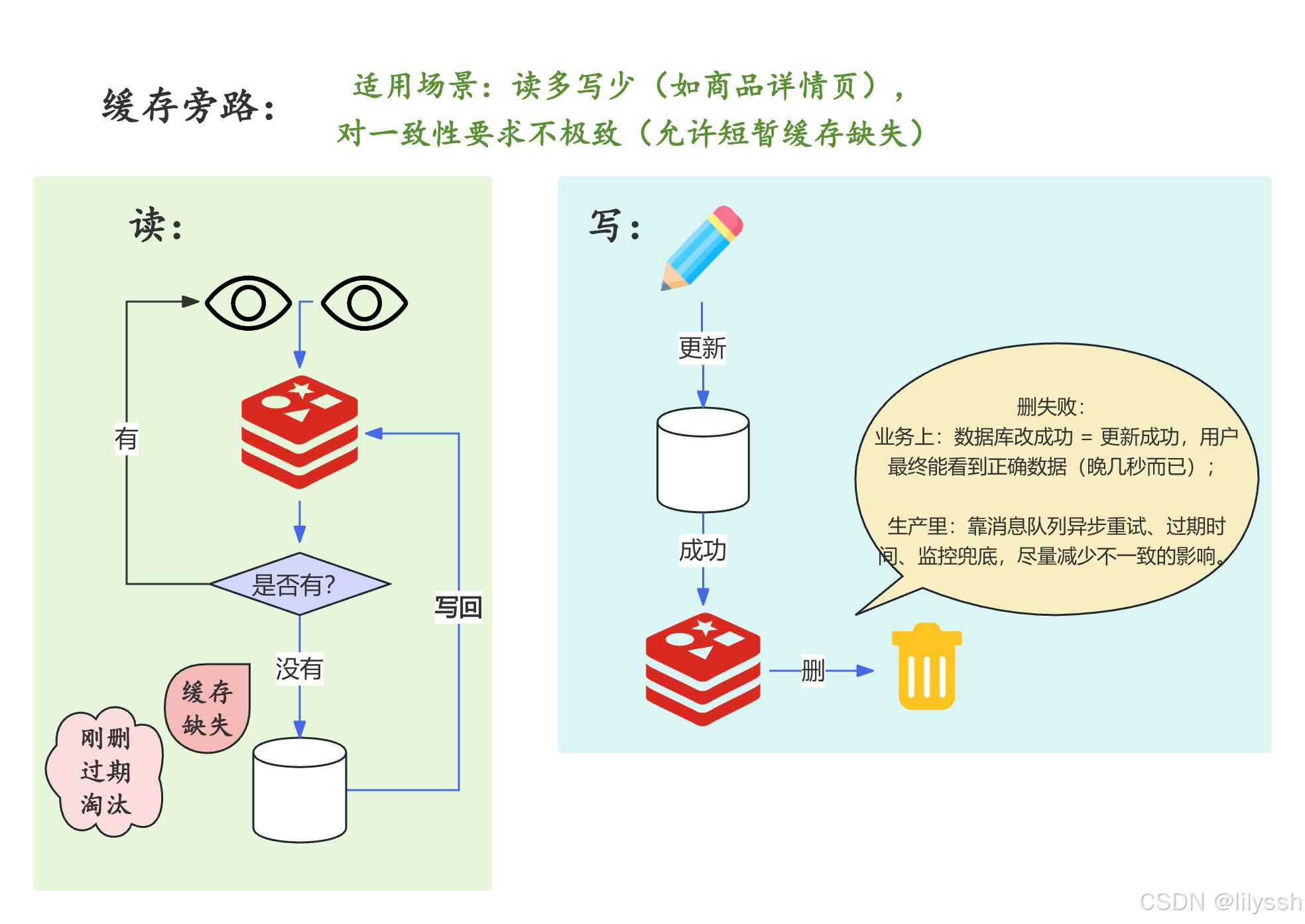
"旁路" 的意思是 "侧面辅助"。
流程:
读操作:先查缓存,命中则返回;未命中则查数据库,再将数据写入缓存。
写操作:先更新数据库,再删除缓存(而非更新缓存)。
为什么删缓存而非更新?
避免 "并发写" 导致的不一致:比如请求 1 更新数据库后正要更新缓存,请求 2 已修改数据库并更新了缓存,此时请求 1 的旧数据会覆盖新数据。删除缓存可让下次读请求重新从数据库加载最新数据。
适用场景:
读多写少(如商品详情页),对一致性要求不极致(允许短暂缓存缺失)。
2. Write Through(写透模式)
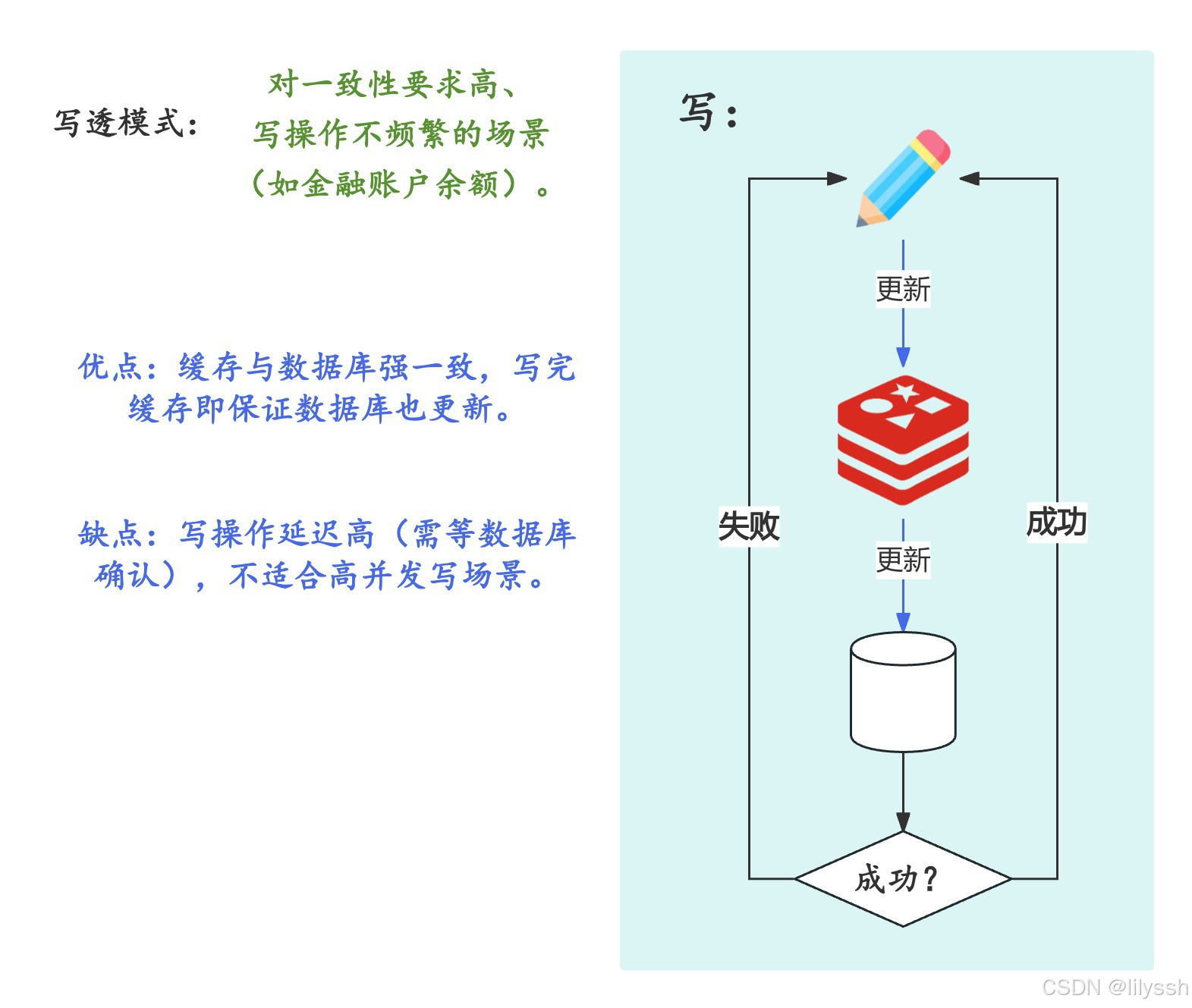
写透:写操作时,数据会 "穿透" 缓存直接到达数据库。
流程:
写操作时,先更新缓存,再由缓存同步更新数据库(缓存作为数据库的 "代理")。
优点:
缓存与数据库强一致,写完缓存即保证数据库也更新。
缺点:
写操作延迟高(需等数据库确认),不适合高并发写场景。
适用场景:
对一致性要求高、写操作不频繁的场景(如金融账户余额)。
3. Write Back(写回模式)
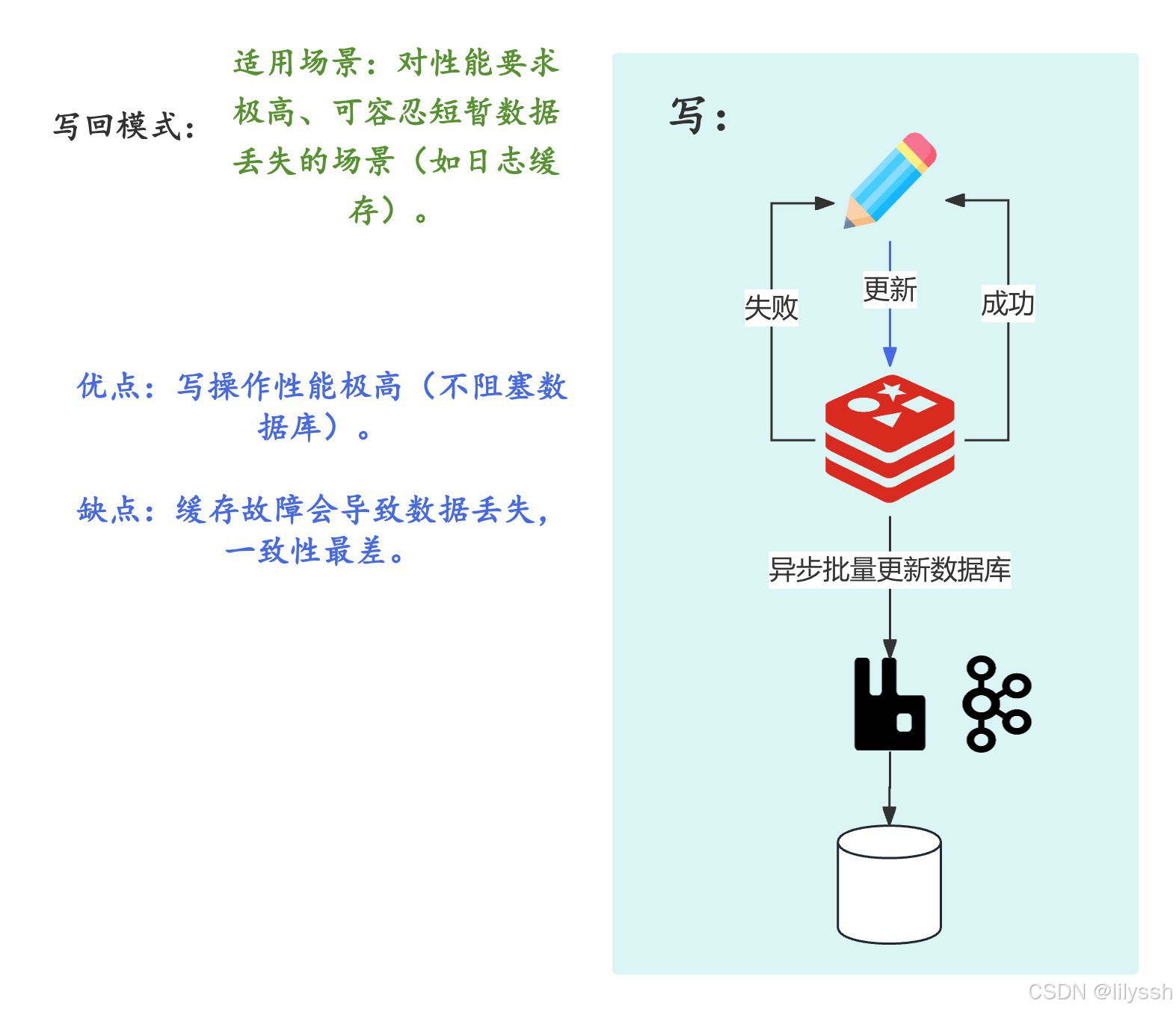
流程:
写操作时只更新缓存,缓存异步批量更新数据库(如设置定时刷新)。
优点:
写操作性能极高(不阻塞数据库)。
缺点:
缓存故障会导致数据丢失,一致性最差。
适用场景:
对性能要求极高、可容忍短暂数据丢失的场景(如日志缓存)。
写入缓存失败 怎么办:
先自救(重试)→ 再兜底(降级)→ 最后根治(监控修复)
(一)重试机制
(二)同步写数据库(降级为写穿模式)
适合 "业务绝对不能丢数据" 的场景(如金融交易记录、订单关键信息)。
(三)临时落本地文件,后续定时任务重试。
适合 "数据很重要,但当前所有存储都故障" 的极端情况。
(四)监控与告警
通过监控系统(如 Prometheus)统计 "缓存写入失败次数",超过阈值(如 1 分钟内失败 10 次)触发告警,通知运维抢修。
所有降级逻辑都是 "临时补丁",核心是让问题暴露并被修复。
4. 延迟双删(解决缓存删除延迟问题)
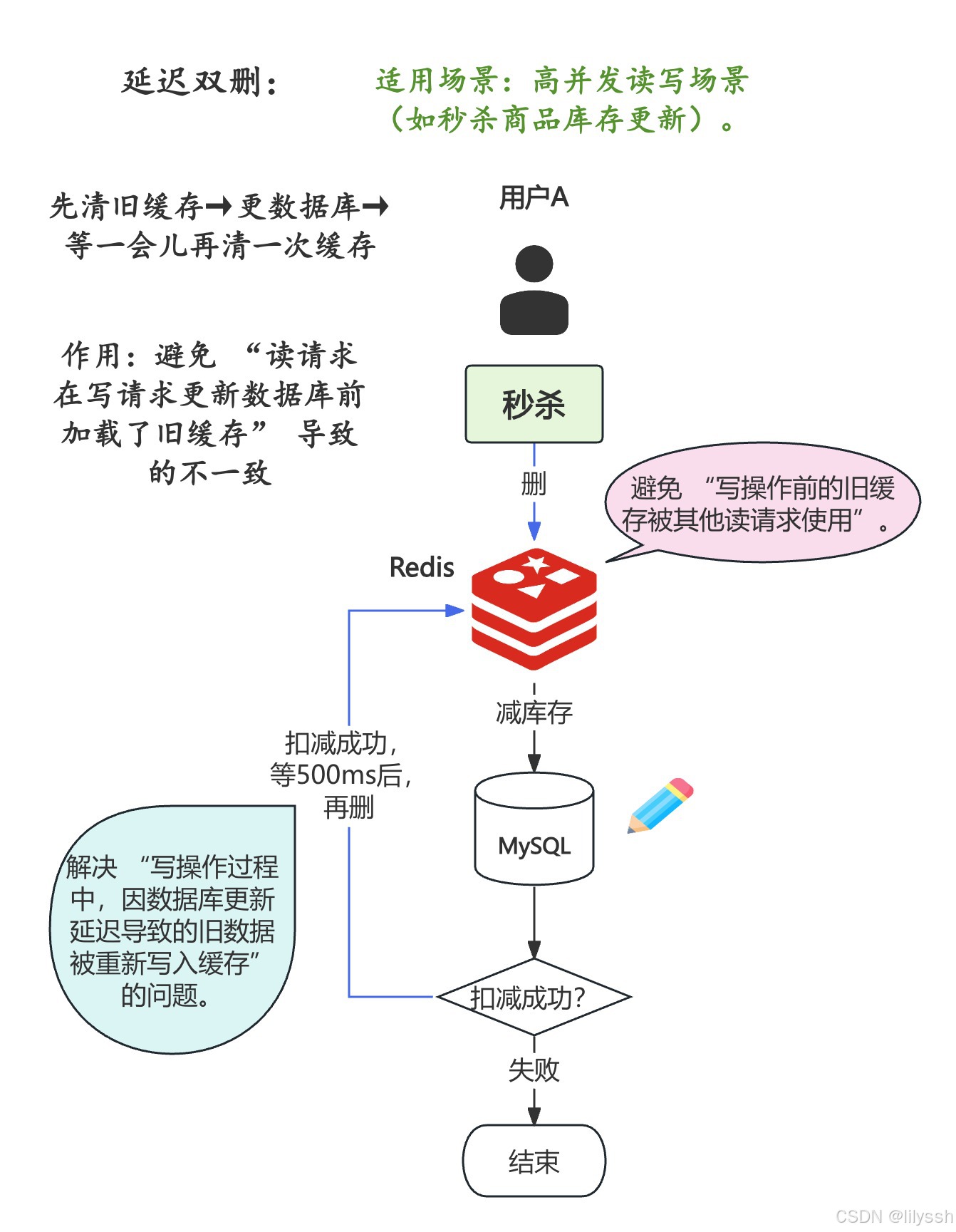
流程:
写操作时,先删除缓存,再更新数据库;
延迟一段时间(如 500ms),再次删除缓存。
作用:
避免 "读请求在写请求更新数据库前加载了旧缓存" 导致的不一致(第一次删缓存可能因网络延迟没生效,第二次删除兜底)。
适用场景:
高并发读写场景(如秒杀商品库存更新)。
5. 分布式锁 + 串行化(强一致性保障)
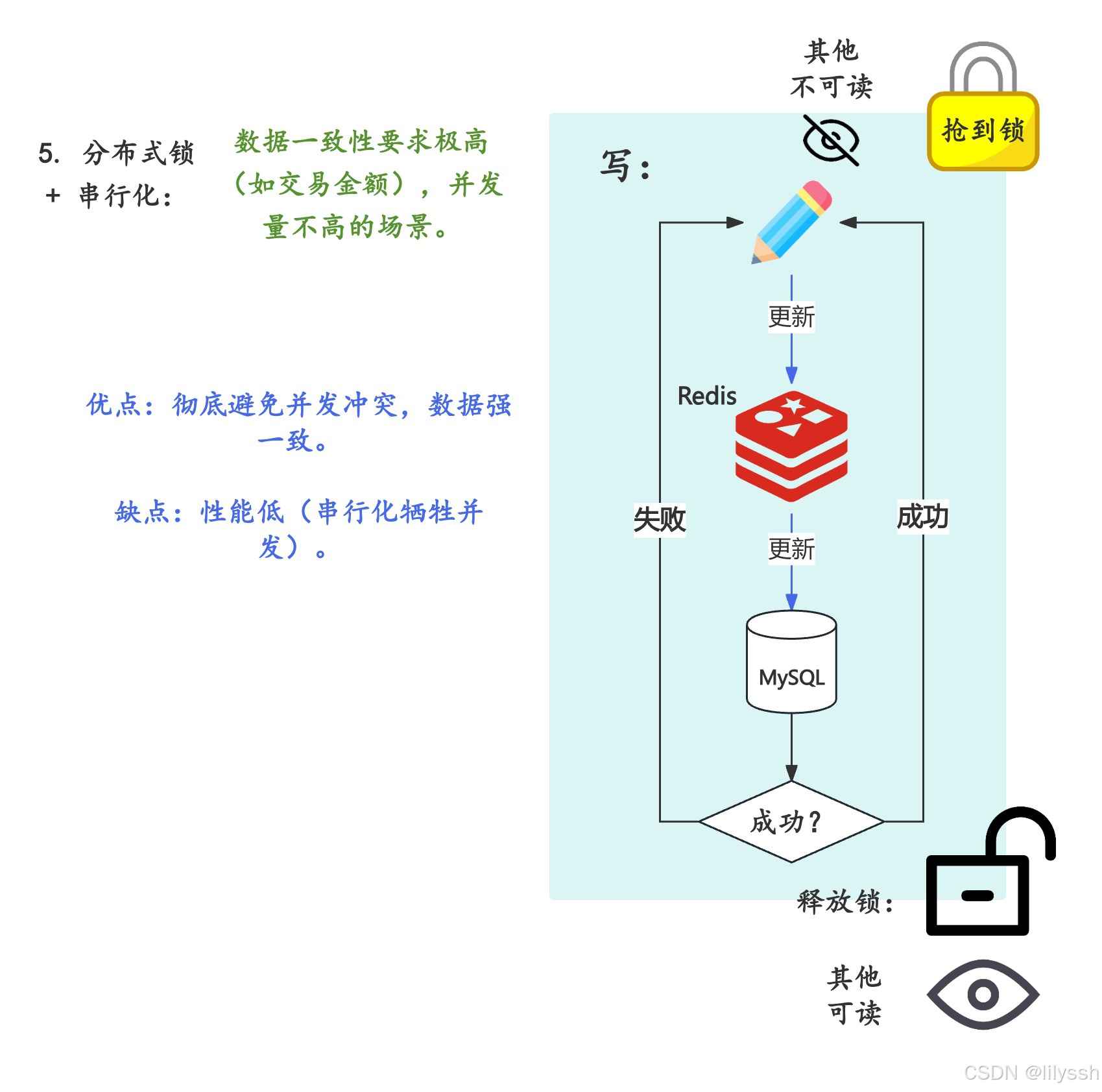
流程:
读写操作都加分布式锁,确保同一数据的读写串行执行(先完成写操作,再允许读操作加载新数据)。
优点:
彻底避免并发冲突,数据强一致。
缺点:性能低(串行化牺牲并发)。
适用场景:数据一致性要求极高(如交易金额),并发量不高的场景。
如有需完善的地方,也请大家不吝赐教!感谢!

点赞多,会持续更新!