目录
[(1) 以 "文件路径" 形式出现:物理路径映射](#(1) 以 “文件路径” 形式出现:物理路径映射)
[(2)以 "路由" 形式出现:逻辑路径映射](#(2)以 “路由” 形式出现:逻辑路径映射)
一、概念
网络爬虫,简称 爬虫 (Spider),是一种按照一定规则,自动地抓取互联网信息的 程序 或者脚本。
二、相关知识背景
(一)浏览器工作原理
1.网址
观察每一次访问操作,总是先更新网址,然后刷新出网址对应的网页内容。所以,要想获取网页内容中的信息,离不开对网址的分析。
"网址"的全名叫"统一资源定位符",即URL(Uniform Resource Locator),用于标识资源在网络上的地址,主要由以下几个部分组成:
- 网络协议类型(Protocol),它决定了客户端与服务器之间具体以什么样的方式进行通信,常见的有 HTTP、HTTPS、FTP 等;
- 域名(Domain Name) ,比如百度的域名是
www.baidu.com; - **资源在服务器中的位置(Path),**有时会以文件路径形式出现(适用与静态资源),有时位置则会以路由形式出现(适用与动态资源)。
2.浏览网页实际发生了什么
- 我们在浏览器输入 网址(URL);
- 浏览器根据网址,调用我们设备的网络能力,找到域名对应的服务器,向服务器 请求(request)获取某某资源;
- 服务器收到请求后会作出 响应(response),在内部翻箱倒柜找出相应资源,把资源交给浏览器;
- 浏览器加载资源,把内容呈现到我们面前。
3.两种Path
这里扩展解释一下"网址"小节提到的两种path,辅助理解浏览网页时实际发生了什么。
(1) 以 "文件路径" 形式出现:物理路径映射
这种形式是早期 Web 服务器(如静态网站)的典型处理方式,URL 路径直接对应服务器文件系统中的实际文件位置。
- 原理:服务器收到请求后,会将 URL 路径当作 "文件系统路径",直接去服务器的硬盘中查找对应的文件。
- 例子 :
当访问https://example.com/static/blog/2023.html时,服务器会在自身文件系统中寻找路径为./static/blog/2023.html的文件,找到后直接读取文件内容(如 HTML 代码),返回给客户端。 - 特点 :
- URL 路径与服务器文件系统的物理路径严格对应;
- 适用于静态资源(如 HTML、CSS、图片等),内容固定,无需动态生成;
- 缺点:URL 暴露服务器文件结构,灵活性低(比如想修改 URL 格式,必须同步修改文件存放位置)。
(2)以 "路由" 形式出现:逻辑路径映射
随着动态网站(如电商、社交平台)的发展,URL 路径不再绑定物理文件,而是通过 "路由规则" 映射到服务器的处理逻辑(如函数、模块)。
- 原理:服务器收到请求后,会通过 "路由系统" 解析 URL 路径,根据预设的规则(如路径中的关键词、参数),匹配到对应的处理函数,由函数动态生成响应内容(而非直接读取文件)。
- 例子 :
当访问https://example.com/user/123时,服务器的路由规则可能是:/user/:id映射到getUserById(id)函数。服务器解析出id=123,调用该函数从数据库查询 ID 为 123 的用户数据,动态生成包含用户信息的 HTML/JSON,返回给客户端。
此时,服务器文件系统中并不存在 "user/123" 这样的文件,URL 路径是 "逻辑上的资源标识",与物理文件无关。 - 特点 :
- URL 路径是 "逻辑语义化" 的(如
/user/123清晰表示 "用户 ID=123 的资源"); - 适用于动态资源(内容随数据变化,如用户信息、商品列表);
- 优势:隐藏服务器文件结构,URL 格式灵活(可随时修改路由规则而不影响文件存放),支持复杂参数传递(如分页、筛选条件)。
- URL 路径是 "逻辑语义化" 的(如
(二)开发者工具
这里以夸克浏览器为例,在边栏找到"开发者工具",点开
本小节主要讲爬虫最常用的面板------Network(负责分析请求与响应)
常用以下三个部分
- 功能区 ,这里我们重点关注类似 🚫 标志的 清除(clear) 按钮,以及 保留记录(Preserve log) 选项;
- 筛选区 ,该功能区可以快速筛选出符合条件的请求,这里我们主要关注以 所有(All) 开始直到 其它(Other) 结束的类型标签,未来我们将用它来快速筛选指定类型请求;
- 请求列表区,当开发者工具捕捉到发生在页面中的新请求时,会按请求发生顺序陈列在区域中。

借助 Network 面板,我们能清晰地观察到,当我们继续课程时,浏览器向服务器发送了什么请求,知道它们的 请求名(name) 、请求状态(status) 、请求类型(type) 等信息
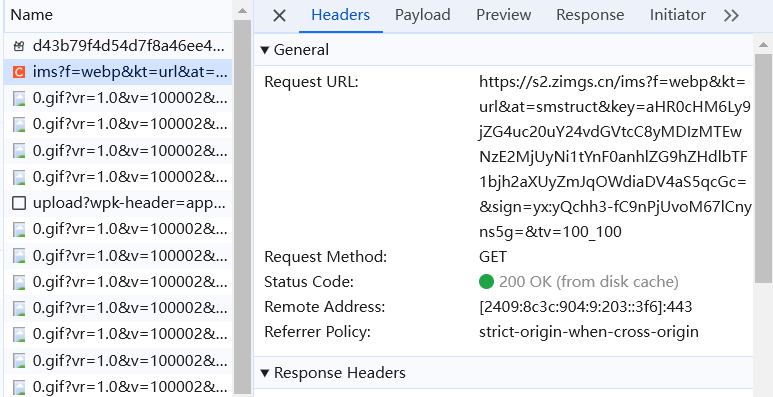
我们点击任意一条请求,查看该请求详情,能够在 Headers(请求头) 面板的 General(总体) 信息中看到 该请求的 URL(Request URL) 、请求方法(Request Method) 、状态码(Status Code) 等信息。General 下方则是响应头和请求头信息。
 响应状态码主要能够分为五类:
响应状态码主要能够分为五类:
- 代码
100~199:信息响应,这是服务器在表明,"我收到你的请求了,不过处理起来有点麻烦,你接着发其它请求吧,我干完活了告诉你一声"; - 代码
200~299:成功,表示服务器成功接收、理解、处理了请求; - 代码
300~399:重定向,一般用于 URL 重定向,你可以理解为资源已经搬家了,服务器帮你把请求 URL 改成了资源所在的新地址; - 代码
400~499:客户端错误,也就是我们请求获取资源的方式不对,比如 URL 输入错误,或者没有登录等等; - 代码
500~599:服务器错误,表明服务器由于某些原因,现在无法作出响应。
(我们最常见的响应状态码是客户端错误中的 404(not found),表示用户可以正常访问服务器,但服务器找不到 URL 对应的资源)
三、爬虫工作原理
相较于手动访问页面、收集信息;使用爬虫程序自动收集信息时,爬虫实际上是充当了浏览器的功能,向服务器发送请求、获取服务器的响应。与使用浏览器浏览网页不同的是,爬虫程序无需将响应内容呈现出来,而是根据我们设定的规则去提取需要的数据,处理数据,最终将数据保存起来。
一个完整的爬虫包含下面三个步骤:
- 第一步:获取数据,爬虫根据我们提供的 URL,向服务器发送请求获取响应内容;
- 第二步:处理数据,处理分为两步,一是解析响应内容,把它整理成 Python 中的数据格式,二是从中提取出所需数据;
- 第三步:存储数据,将处理后的数据保存起来,便于后续的使用和分析等。
就此你已经对爬虫有了初步的认识,下一节我们将进一步认识网页,为后续爬虫打基础
我们下一节见~