部署LVS模式集群
1.实验环境准备
2.nat模式环境设定
1.先配置环境
四个虚拟机
1个LVS 1个client 1个rs1 1个rs2
注意:
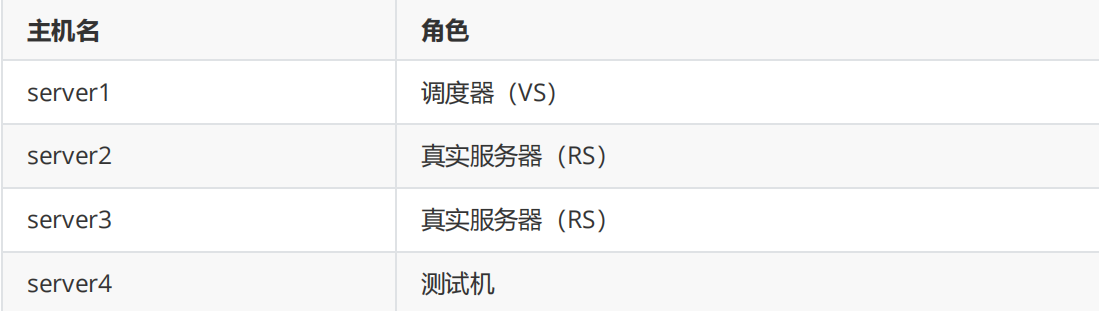
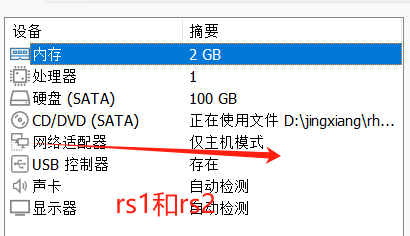
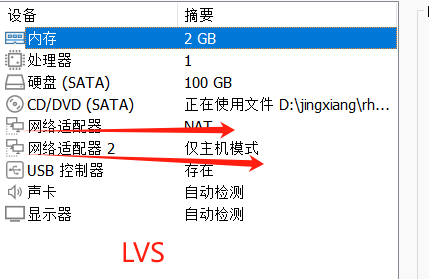
网络适配器:
LVS->nat+仅主机
client->nat
两台server->仅主机
RS1和RS2:
LVS:
1.使用ipvsadm工具
创建虚拟服务器
添加、删除服务器节点
查看群集及节点情况
保存负载分配策略
1.1 ipvasdm工具选项
-A:添加虚拟服务器
-D:删除整个虚拟fuwq
-s:指定负载调度算法(轮询,加权轮询,最少连接,加权最少连接,wlc)
-a:表示添加真实服务器(节点服务器)
-d:删除某一个节点
-t:指定VIP地址及TCP端口
-r:指定RIP地址及TCP端口
-m:表示使用NAT群集模式
-g:表示使用DR模式
-i:表示使用TUN模式
-w:设置权重(权重为0时表示暂停节点)
-p60:表示保持长连接60秒
-l:列表查看LVS虚拟服务器(默认为查看所有)
-n:以数字形式显示地址,端口等信息,常与"-l"选项组合使用
2.修改主机IP地址实施步骤
client

lvs(两个网卡)


RS1

RS2

环境搭建完成。
2.实验
1.NAT模式
实施步骤:
1.网络配置
LVS:

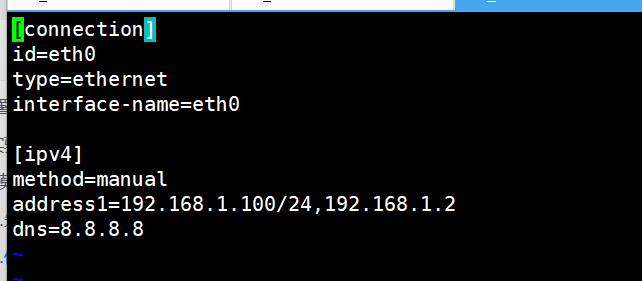
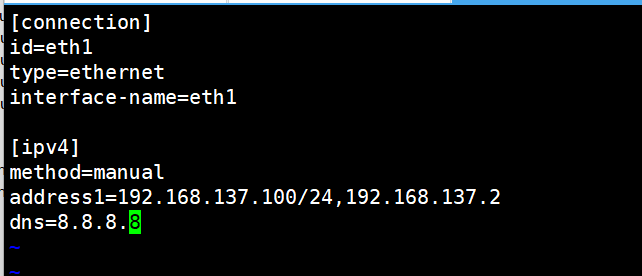
命令:
root@lvs system-connections# cd /etc/NetworkManager/system-connections
root@lvs system-connections# vi eth0.nmconnection
root@lvs system-connections# vi eth0.nmconnection
注意:网关和ip要在同一个网段,否则可能会不通。
RS1:
激活网卡

root@RS1 \~# nmcli connection up eth1-dhcp
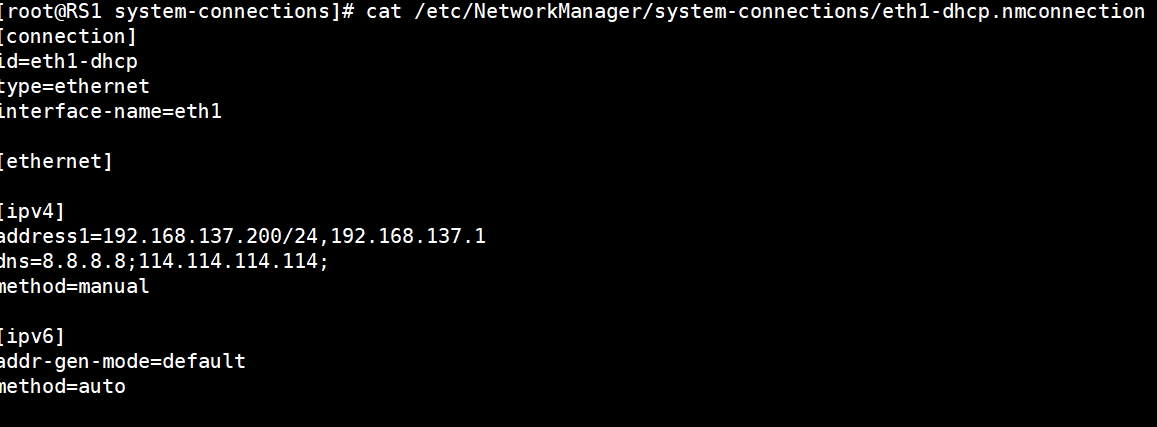
root@RS1 system-connections# cat /etc/NetworkManager/system-connections/eth1-dhcp.nmconnection
RS2:
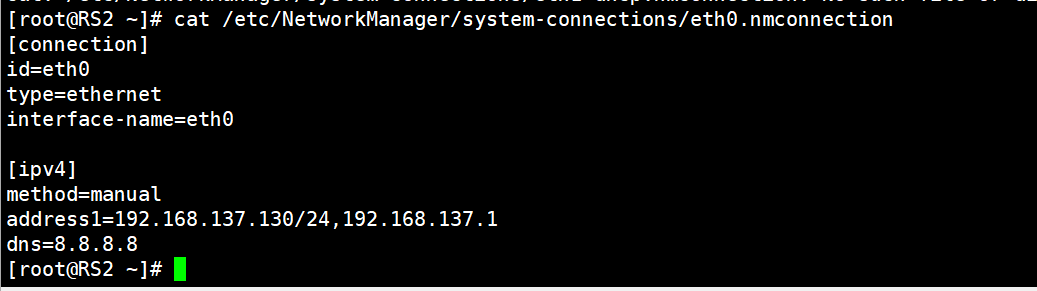
root@RS2 \~# cat /etc/NetworkManager/system-connections/eth0.nmconnection
2.启用内核路由
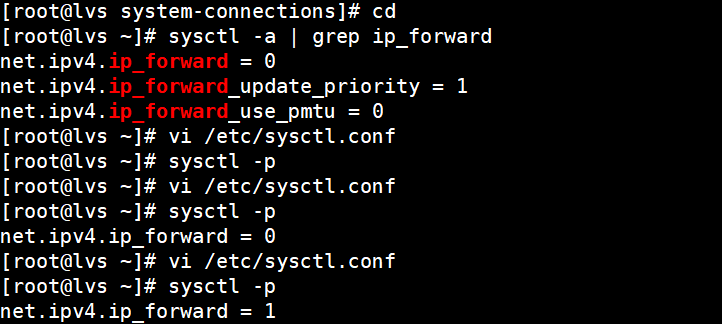
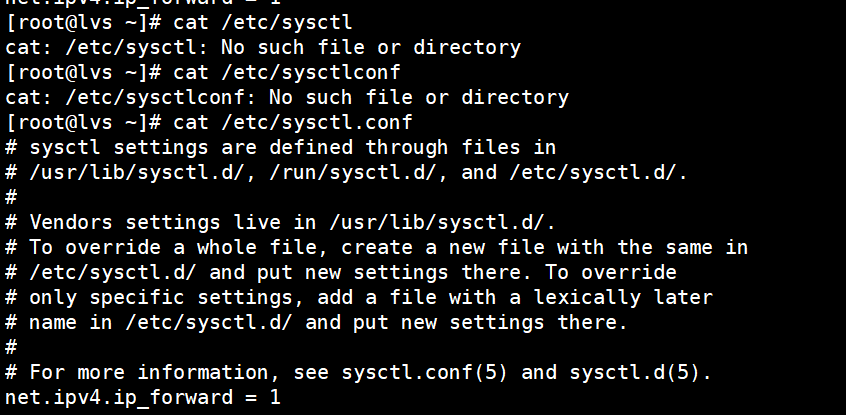
命令:
root@lvs \~# sysctl -a | grep ip_forward
net.ipv4.ip_forward = 0
net.ipv4.ip_forward_update_priority = 1
net.ipv4.ip_forward_use_pmtu = 0
root@lvs \~# vi /etc/sysctl.conf
root@lvs \~# sysctl -p
root@lvs \~# vi /etc/sysctl.conf
root@lvs \~# sysctl -p
net.ipv4.ip_forward = 0
root@lvs \~# vi /etc/sysctl.conf
root@lvs \~# sysctl -p
net.ipv4.ip_forward = 1
root@lvs \~# cat /etc/sysctl
cat: /etc/sysctl: No such file or directory
root@lvs \~# cat /etc/sysctlconf
cat: /etc/sysctlconf: No such file or directory
root@lvs \~# cat /etc/sysctl.conf
sysctl settings are defined through files in
/usr/lib/sysctl.d/, /run/sysctl.d/, and /etc/sysctl.d/.
Vendors settings live in /usr/lib/sysctl.d/.
To override a whole file, create a new file with the same in
/etc/sysctl.d/ and put new settings there. To override
only specific settings, add a file with a lexically later
name in /etc/sysctl.d/ and put new settings there.
For more information, see sysctl.conf(5) and sysctl.d(5).
net.ipv4.ip_forward = 1
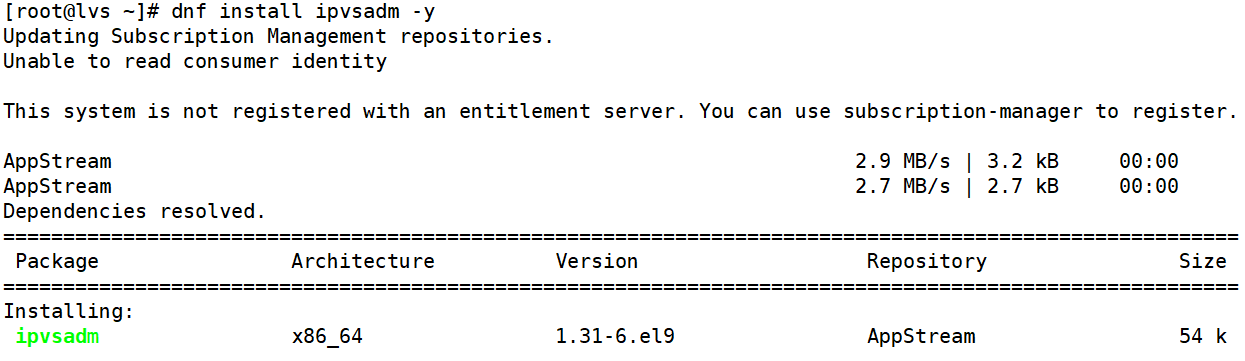
3.安装ipvsadm
root@lvs \~# dnf install ipvsadm -y
4.添加调度策略
root@lvs \~# ipvsadm -A -t 192.168.1.100:80 -s rr
root@lvs \~# ipvsadm -a -t 192.168.1.100:80 -r 192.168.137.200:80
root@lvs \~# ipvsadm -a -t 192.168.1.100:80 -r 192.168.137.200:80 -m
Destination already exists(这个已经存在,不需要重复添加)
root@lvs \~# ipvsadm -a -t 192.168.1.100:80 -r 192.168.137.130:80 -m
root@lvs \~#

root@lvs \~# ipvsadm -Ln(查看策略)

5.保存并启动
root@lvs \~# ipvsadm -Sn > /etc/sysconfig/ipvsadm
root@lvs \~# systemctl start ipvsadm.service

6.设置web
mkdir -p /var/www/html
echo "RS2 192.168.137.130" > /var/www/html/index.html
cat /var/www/html/index.html
RS2:


RS1:

7.测试
要把你的RS1和RS2,两个标箭头的要对应。
root@client \~# for i in {1..10}; do curl 192.168.1.12; done
RS2 - 192.168.137.200
RS1 - 192.168.137.130
RS2 - 192.168.137.200
RS1 - 192.168.137.130
RS2 - 192.168.137.200
RS1 - 192.168.137.130
RS2 - 192.168.137.200
RS1 - 192.168.137.130
RS2 - 192.168.137.200
RS1 - 192.168.137.130
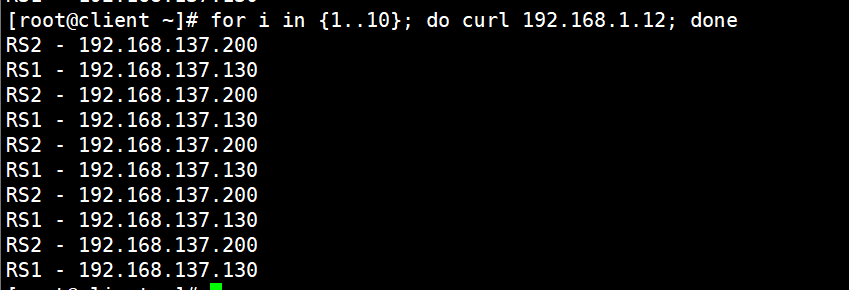
至此nat模式完成实验!
2.DR模式
1.DR模式环境设定
5个虚拟机
1个LVS 1个client 1个rs1 1个rs2 1个route
注意:
网络适配器:
LVS->仅主机
client->nat
两台server->仅主机
route->nat+仅主机
大差不差,和nat模式一样配置环境即可

2.实施步骤:
1.LVS配置
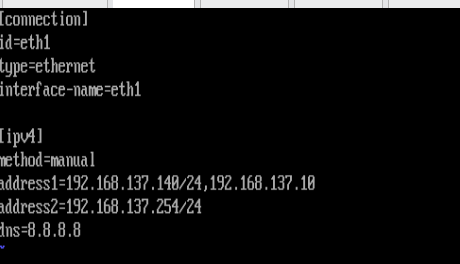
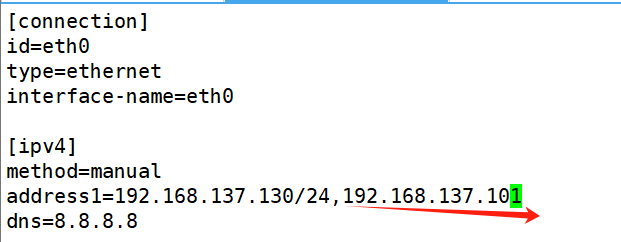
root@lvs \~# cat /etc/NetworkManager/system-connections/eth0.nmconnection
2.route配置
忘记改名字

root@rhel9 \~# vim /etc/sysctl.conf
root@rhel9 \~# vim /etc/sysctl.conf
root@rhel9 \~# sysctl -p
net.ipv4.ip_forward = 1
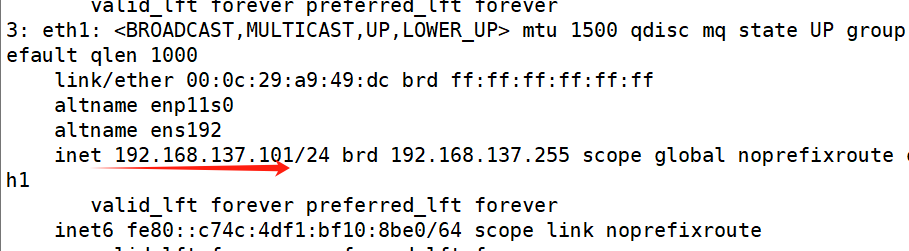
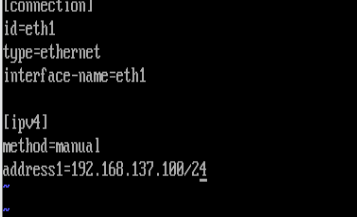
root@rhel9 \~# cat /etc/NetworkManager/system-connections/eth1.nmconnection
connection
id=eth1
type=ethernet
interface-name=eth1
ipv4
method=manual
address1=192.168.137.140/24,192.168.1.2
dns=8.8.8.8
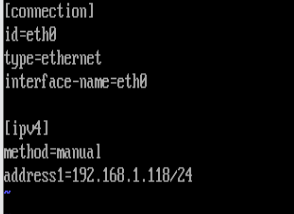
root@rhel9 \~# cat /etc/NetworkManager/system-connections/eth0.nmconnection
connection
id=eth0
type=ethernet
interface-name=eth0
ipv4
method=manual
address1=192.168.1.11/24,192.168.1.2
dns=8.8.8.8
3.client配置
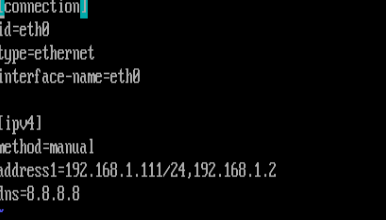
root@client \~# cat /etc/NetworkManager/system-connections/eth0.nmconnection
connection
id=eth0
type=ethernet
interface-name=eth0
ipv4
method=manual
address1=192.168.1.111/24,192.168.1.2
dns=8.8.8.8
4.RS1和RS2配置
cp -p eht0.nmconnectin lo.nmconnection(要改,其他和nat模式一样)
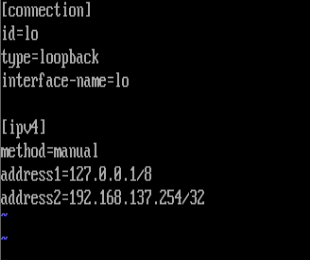
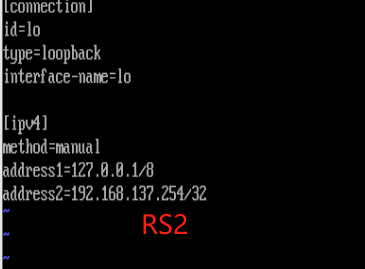
5.调节RS1和RS2(设定lo不对外响应)
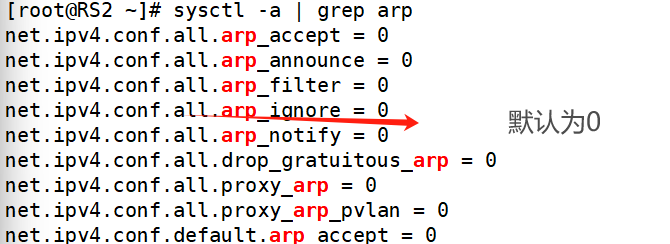

root@RS2 \~# echo net.ipv4.conf.all.arp_ignore >> /etc/sysctl.conf
root@RS2 \~# echo net.ipv4.conf.all.arp_announce=2 >> /etc/sysctl.conf
root@RS2 \~# echo net.ipv4.conf.all.arp_ignore=1 >> /etc/sysctl.conf
root@RS2 \~# echo net.ipv4.conf.lo.arp_ignore=1 >> /etc/sysctl.conf
root@RS2 \~# echo net.ipv4.conf.lo.arp_announce=2 >> /etc/sysctl.conf

6.在lvs 和 rs 中设定vip
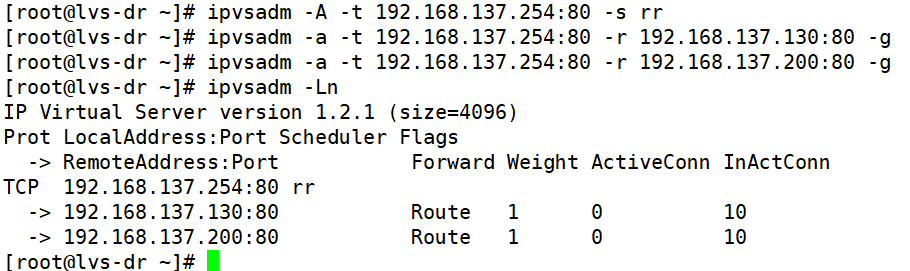
root@lvs-dr \~# ipvsadm -A -t 192.168.137.254:80 -s rr
root@lvs-dr \~# ipvsadm -a -t 192.168.137.254:80 -r 192.168.137.130:80 -g
root@lvs-dr \~# ipvsadm -a -t 192.168.137.254:80 -r 192.168.137.200:80 -g
root@lvs-dr \~# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.137.254:80 rr
-> 192.168.137.130:80 Route 1 0 10
-> 192.168.137.200:80 Route 1 0 10
7.测试
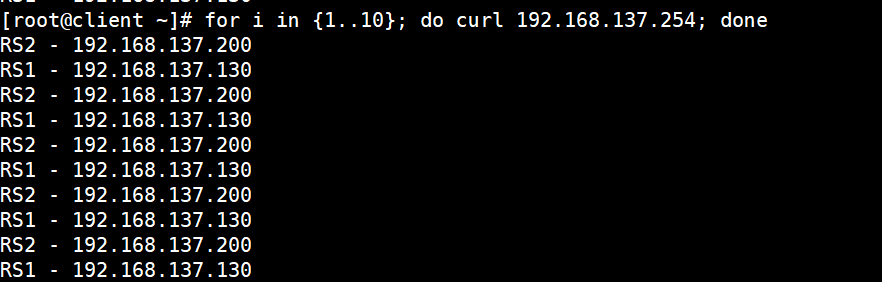
root@client \~# for i in {1..10}; do curl 192.168.137.254; done
RS2 - 192.168.137.200
RS1 - 192.168.137.130
RS2 - 192.168.137.200
RS1 - 192.168.137.130
RS2 - 192.168.137.200
RS1 - 192.168.137.130
RS2 - 192.168.137.200
RS1 - 192.168.137.130
RS2 - 192.168.137.200
RS1 - 192.168.137.130

至此DR模式完成实验!
3.LVS-DR数据抓包
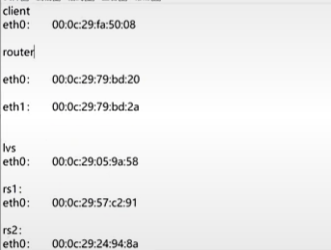
通过使用Wireshark进行抓包:
对 vmware network adapter vmnet1进行抓包(因为Vm8只有客服端到路由器,所以对Vm1进行抓包)
刚开始没有,访问之后就有了
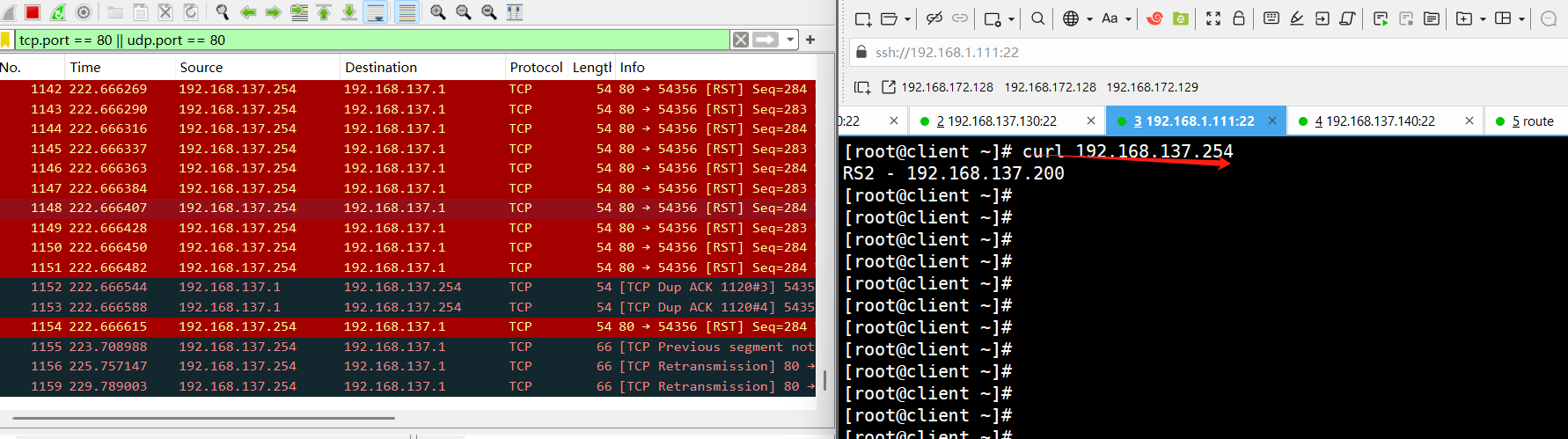
而且这个正是通过路由器route转发访问的mac地址
所以综上所述,我们可以得到结论:
1.客户端发送数据帧给vs调度主机帧中内容为客户端IP+客户端的MAC+VIP+VIP的MAC
2.VS调度主机接收到数据帧后把帧中的VIP的MAC该为RS1的MAC,此时帧中的数据为客户端IP+客户端 的MAC+VIP+RS1的MAC
3.RS1得到2中的数据包做出响应回传数据包,数据包中的内容为VIP+RS1的MAC+客户端IP+客户端IP的 MAC
4.LVS-TUN模式(隧道模式)
转发方式:不修改请求报文的IP首部(源IP为CIP,目标IP为VIP),而在原IP报文之外再封装一个IP首部
(源IP是DIP,目标IP是RIP),将报文发往挑选出的目标RS;RS直接响应给客户端(源IP是VIP,目标IP 是CIP)
TUN模式数据传输过程传输过程图:
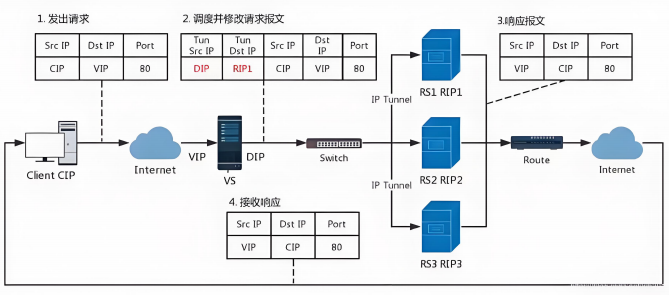
1.客户端发送请求数据包,包内有源IP+vip+dport
2.到达vs调度器后对客户端发送过来的数据包重新封装添加IP报文头,新添加的IP报文头中包含
TUNSRCIP(DIP)+TUNDESTIP(RSIP1)并发送到RS1
3.RS收到VS调度器发送过来的数据包做出响应,生成的响应报文中包含SRCIP(VIP)+DSTIP(CIP) +port,响应数据包通过网络直接回传给client
TUN 模式特点
1.DIP, VIP, RIP都应该是公网地址
2.RS的网关一般不能指向DIP
3.请求报文要经由Director,但响应不能经由Director
4.不支持端口映射
5.RS的OS须支持隧道功能
5.LVS-fullnet 模式
fullnet模式数据传输过程传输过程图:
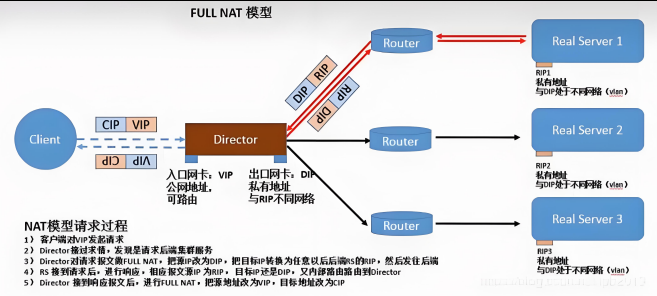
fullnat:通过同时修改请求报文的源IP地址和目标IP地址进行转发
CIP --> DIP
VIP --> RIP
1.VIP是公网地址,RIP和DIP是私网地址,且通常不在同一IP网络;因此,RIP的网关一般不会指向DIP
2.RS收到的请求报文源地址是DIP,因此,只需响应给DIP;但Director还要将其发往Client
3.请求和响应报文都经由Director
4.支持端口映射
注意:此类型kernel默认不支持
6.LVS-13种算法
lvs 调度算法类型
ipvs scheduler:根据其调度时是否考虑各RS当前的负载状态被分为两种:静态方法和动态方法
静态方法:仅根据算法本身进行调度,不考虑RS的负载情况
动态方法:主要根据每RS当前的负载状态及调度算法进行调度Overhead=value较小的RS将被调度
lvs 静态调度算法
1、RR:roundrobin 轮询 RS分别被调度,当RS配置有差别时不推荐
2、WRR:Weighted RR,加权轮询根据RS的配置进行加权调度,性能差的RS被调度的次数少
3、SH:Source Hashing,实现session sticky,源IP地址hash;将来自于同一个IP地址的请求始终发往第一次挑中的RS,从而实现会话绑定
4、DH:Destination Hashing;目标地址哈希,第一次轮询调度至RS,后续将发往同一个目标地址的请求始终转发至第一次挑中的RS,典型使用场景是正向代理缓存场景中的负载均衡,如:宽带运营商
lvs 动态调度算法
主要根据RS当前的负载状态及调度算法进行调度Overhead=value较小的RS会被调度
1、LC:least connections(最少链接发)
适用于长连接应用Overhead(负载值)=activeconns(活动链接数) x 256+inactiveconns(非活动链接数)
2、WLC:Weighted LC(权重最少链接)
默认调度方法Overhead=(activeconns x 256+inactiveconns)/weight
3、SED:Shortest Expection Delay,
初始连接高权重优先Overhead=(activeconns+1+inactiveconns) x 256/weight
但是,当node1的权重为1,node2的权重为10,经过运算前几次的调度都会被node2承接
4、NQ:Never Queue,第一轮均匀分配,后续SED
5、LBLC:Locality-Based LC,动态的DH算法,使用场景:根据负载状态实现正向代理
6、LBLCR:LBLC with Replication,带复制功能的LBLC,解决LBLC负载不均衡问题,从负载重的复制到负载轻的RS
在 4.15 版本内核以后新增调度算法
1.FO(Weighted Fai Over)调度算法:常用作灰度发布
在此FO算法中,遍历虚拟服务所关联的真实服务器链表,找到还未过载(未设置IP_VS_DEST_F
OVERLOAD标志)的且权重最高的真实服务器,进行调度
当服务器承接大量链接,我们可以对此服务器进行过载标记(IP_VS_DEST_F OVERLOAD),那么vs调度器就不会把链接调度到有过载标记的主机中。
2.OVF(Overflow-connection)调度算法基于真实服务器的活动连接数量和权重值实现。将新连接调度到权重值最高的真实服务器,直到其活动
连接数量超过权重值,之后调度到下一个权重值最高的真实服务器,在此OVF算法中,遍历虚拟服务相关联的真实服务器链表,找到权重值最高的可用真实服务器。一个可用的真实服务器需要同时满足以下条件:
1.未过载(未设置IP_VS_DEST_F OVERLOAD标志)
2.真实服务器当前的活动连接数量小于其权重值
3.其权重值不为零
7.火墙标记解决多端口轮询错误
轮询规则中可能会遇到的错误
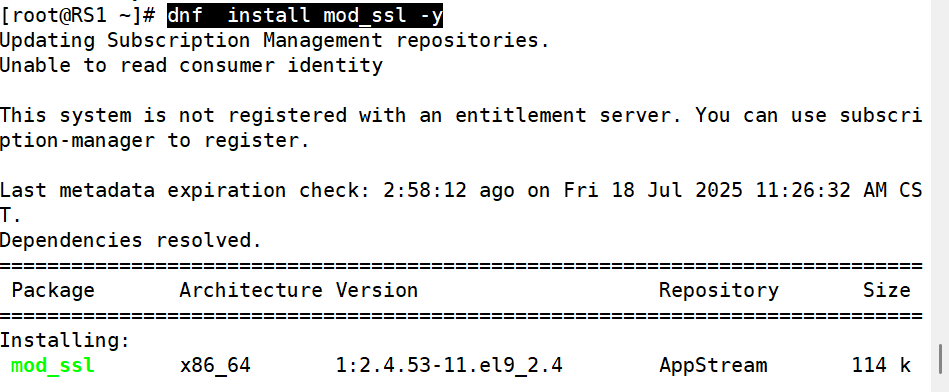
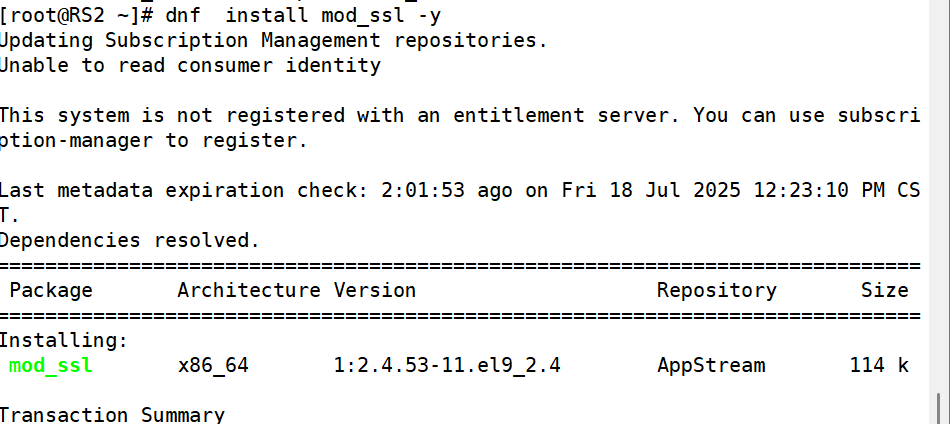
1.在RS1和RS2中安装mod_ssl并重启apache
]#dnf install mod_ssl -y
]# systemctl restart httpd


2.lvs中设置调度
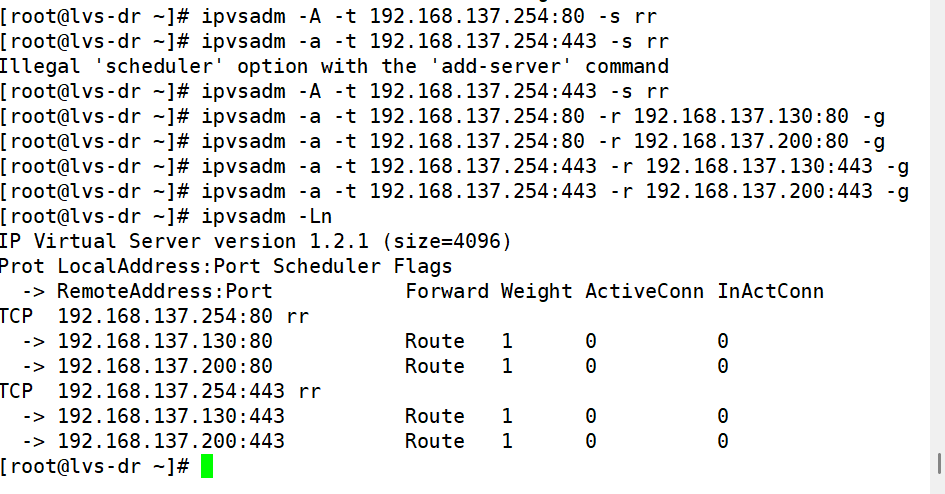
因为我们要调度80和443两个端口所以我们需要设定两组策略

root@lvs-dr \~# ipvsadm -A -t 192.168.137.254:80 -s rr
root@lvs-dr \~# ipvsadm -A -t 192.168.137.254:443 -s rr
root@lvs-dr \~# ipvsadm -a -t 192.168.137.254:80 -r 192.168.137.130:80 -g
root@lvs-dr \~# ipvsadm -a -t 192.168.137.254:80 -r 192.168.137.200:80 -g
root@lvs-dr \~# ipvsadm -a -t 192.168.137.254:443 -r 192.168.137.130:443 -g
root@lvs-dr \~# ipvsadm -a -t 192.168.137.254:443 -r 192.168.137.200:443 -g
root@lvs-dr \~# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.137.254:80 rr
-> 192.168.137.130:80 Route 1 0 0
-> 192.168.137.200:80 Route 1 0 0
TCP 192.168.137.254:443 rr
-> 192.168.137.130:443 Route 1 0 0
-> 192.168.137.200:443 Route 1 0 0
测试问题

防火墙标记解决轮询调度问题
FWM:FireWall Mark
MARK target 可用于给特定的报文打标记,
--set-mark value
其中:value 可为0xffff格式,表示十六进制数字借助于防火墙标记来分类报文,而后基于标记定义集群服务:可将多个不同的应用使用同一个集群服务进行调度
3.实现方法
在Director主机打标记:
iptables -t mangle -A PREROUTING -d vip -p proto -m multiport --dports
portl,port2,..-i MARK --set-mark NUMBER在Director
主机基于标记定义集群服务:
ipvsadm -A -f NUMBER options
示例如下:
在vs调度器中设定端口标签,人为80和443是一个整体
root@lvs-dr \~# iptables -t mangle -A PREROUTING -d 192.168.137.254 -p tcp -m multiport --dports 80,443 -j MARK --set-mark 6666(按需更改)
root@lvs-dr \~# ipvsadm -A -f 6666 -s rr
root@lvs-dr \~# ipvsadm -a -f 6666 -r 192.168.137.200 -g
root@lvs-dr \~# ipvsadm -a -f 6666 -r 192.168.137.130 -g
测试:


至此为火墙标记的问题!
8.LVS-session会话保持优化方案
问题:
在我们客户上网过程中有很多情况下需要和服务器进行交互,客户需要提交响应信息给服务器,如果单纯的进行调度会导致客户填写的表单丢失,为了解决这个问题我们可以用sh算法,但是sh算法比较简单粗暴,可能会导致调度失衡
解决:
在进行调度时,不管用什么算法,只要相同源过来的数据包我们就把他的访问记录在内存中,也就是把这个源的主机调度到了那个RS上
如果在短期(默认360S)内同源再来访问我仍然按照内存中记录的调度信息,把这个源的访问还调度到同一台RS上。
如果过了比较长的时间(默认最长时间360s)同源访问再次来访,那么就会被调度到其他的RS上。
ipvsadm -AlE -tlulf service-address -s scheduler -p \[timeout]默认360秒
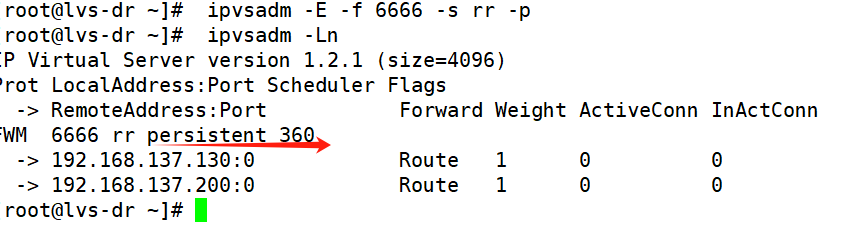
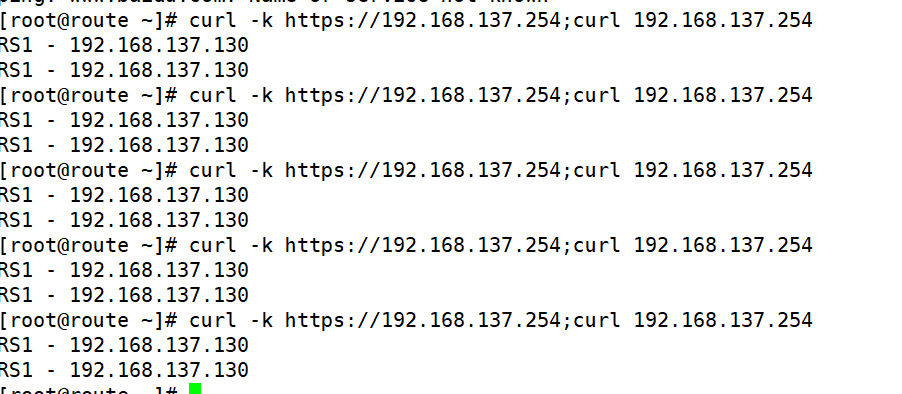
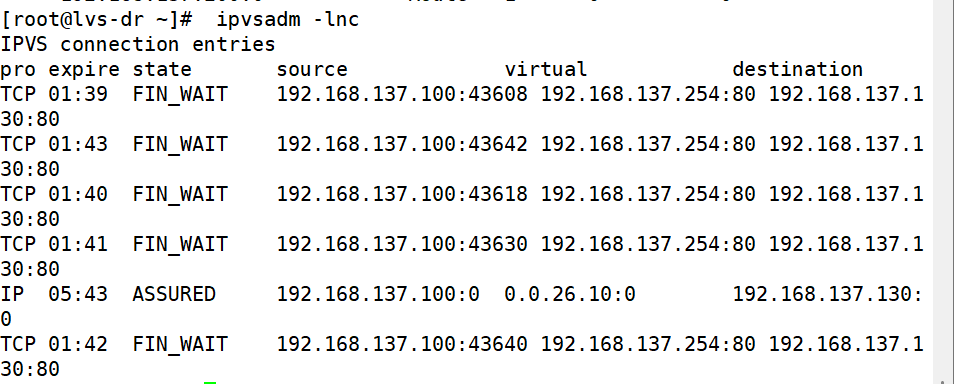
在lvs调度器中设定
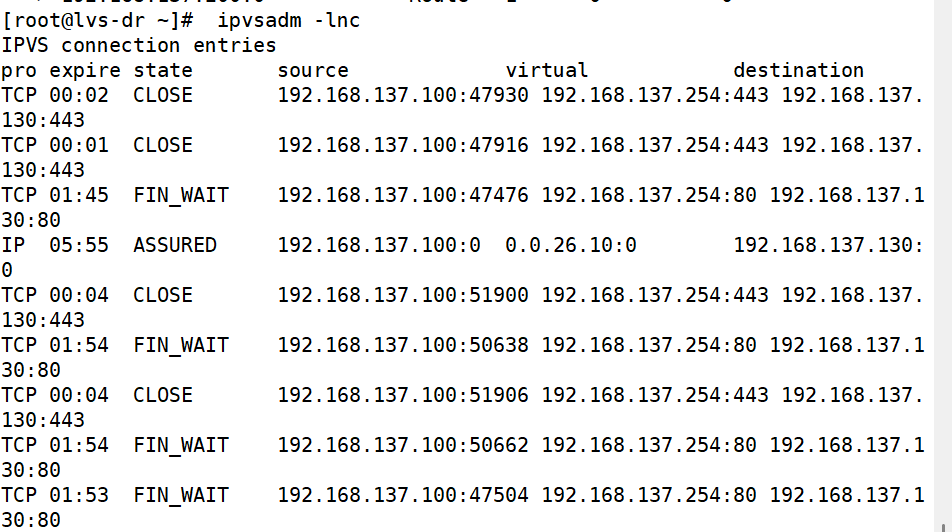
root@lvs \~# ipvsadm -E -f 6666 -s rr -p 多少(假设300)

root@lvs \~# ipvsadm -LnC
9.LVS多模式脚本实现
示例:
用于管理网络地址转换(NAT)和直接路由(Direct Routing,简称 DR)的配置脚本
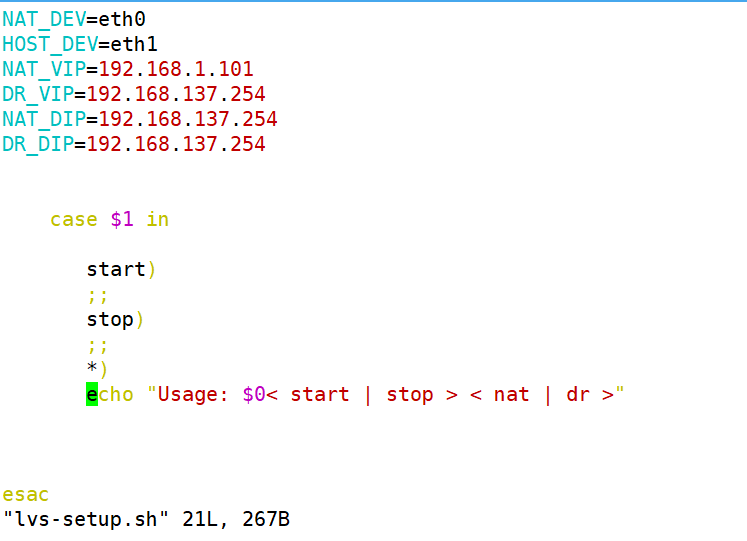
变量定义
NAT_DEV 和 HOST_DEV:分别定义了用于NAT的网络设备和主机的网络设备,这里分别是 eth0 和 eth1。
NAT_VIP 和 DR_VIP:分别定义了NAT虚拟IP和直接路由虚拟IP,这里都是 192.168.1.101 和 192.168.137.254。
NAT_DIP 和 DR_DIP:分别定义了NAT的外部IP和直接路由的外部IP,这里都是 192.168.137.254。
脚本逻辑
脚本接受一个参数,这个参数决定了要执行的操作(启动或停止)以及要配置的模式(NAT或DR)。
case 语句用于根据传递给脚本的第一个参数($1)来执行不同的操作。
操作选项
start:这个选项应该用于启动NAT或DR配置,但当前脚本中没有实现具体的逻辑。
stop:这个选项应该用于停止NAT或DR配置,同样,当前脚本中没有实现具体的逻辑。
*:如果传递的参数不是 start 或 stop,脚本会打印一个用法提示。
测试:

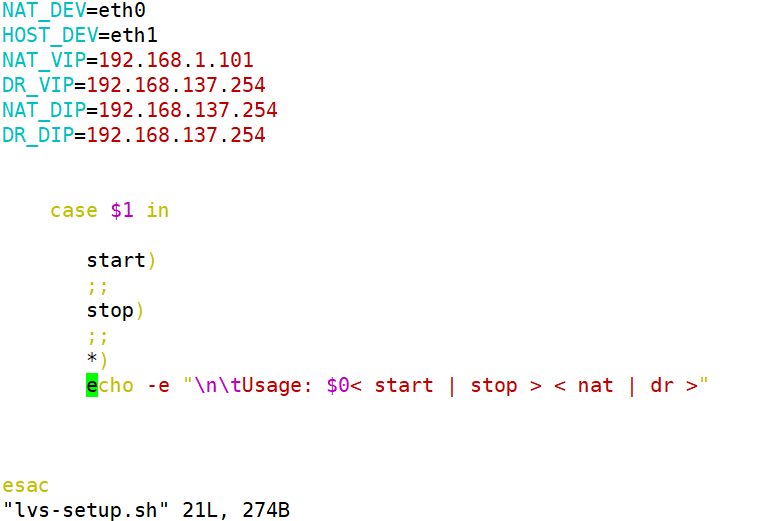

也可以将RS1和RS2加进去,根据自己需求去改写脚本即可。
至此为多模式脚本实现!
以上为整个实验的过程和详细解析!!!
但需要注意的是:
3.实验注意事项
1.网络规划
IP地址分配:确保NAT和DR使用的IP地址不会产生冲突,合理规划IP地址段。
子网划分:正确划分子网,以支持不同的网络需求和设备。
2. 设备配置
路由器/防火墙配置:正确配置路由器或防火墙设备,以支持NAT和DR的规则。
交换机配置:确保交换机配置正确,能够处理来自不同源的流量。
3. 安全性
访问控制:设置访问控制列表(ACLs)来限制不必要的访问,增强网络安全。
火墙规则:配置防火墙规则以防止未授权访问和潜在的攻击。
4. 测试和验证
连通性测试:使用 ping、traceroute 等工具测试网络连通性。
服务测试:确保通过NAT和DR可以访问目标服务,如HTTP、HTTPS等。
5. 日志和监控
日志记录:启用设备和服务器的日志记录功能,以便于问题追踪和分析。
网络监控:使用网络监控工具来监控流量和性能,及时发现并解决问题。
6. 故障排除
错误分析:当出现问题时,分析错误日志和配置,找出问题根源。
逐步排查:从网络的最外层开始,逐步排查到内层,找到问题所在。
7. 文档记录
配置记录:记录所有配置的详细信息,包括IP地址、子网掩码、路由规则等。
操作记录:记录实验过程中的关键操作和更改,便于回溯和复现问题。
8. 实验环境
隔离实验环境:在隔离的实验环境中进行NAT和DR配置,避免影响生产环境。
备份配置:在进行任何更改之前,备份当前的配置文件。
9. 性能考虑
负载均衡:在需要时配置负载均衡,以优化资源使用和提高性能。
QoS配置:根据需要配置服务质量(QoS),确保关键业务的流量优先级。
10. 法规遵从
数据保护:确保实验过程中遵守相关的数据保护法规和政策。
合规性检查:定期检查配置和操作是否符合行业标准和法规要求。
注意:如果感觉自己成功不了,切记保存快照,以便回滚!!!