首先是视频
依旧是随机打开个视频查看f12刷新一下(这边建议你先登录)
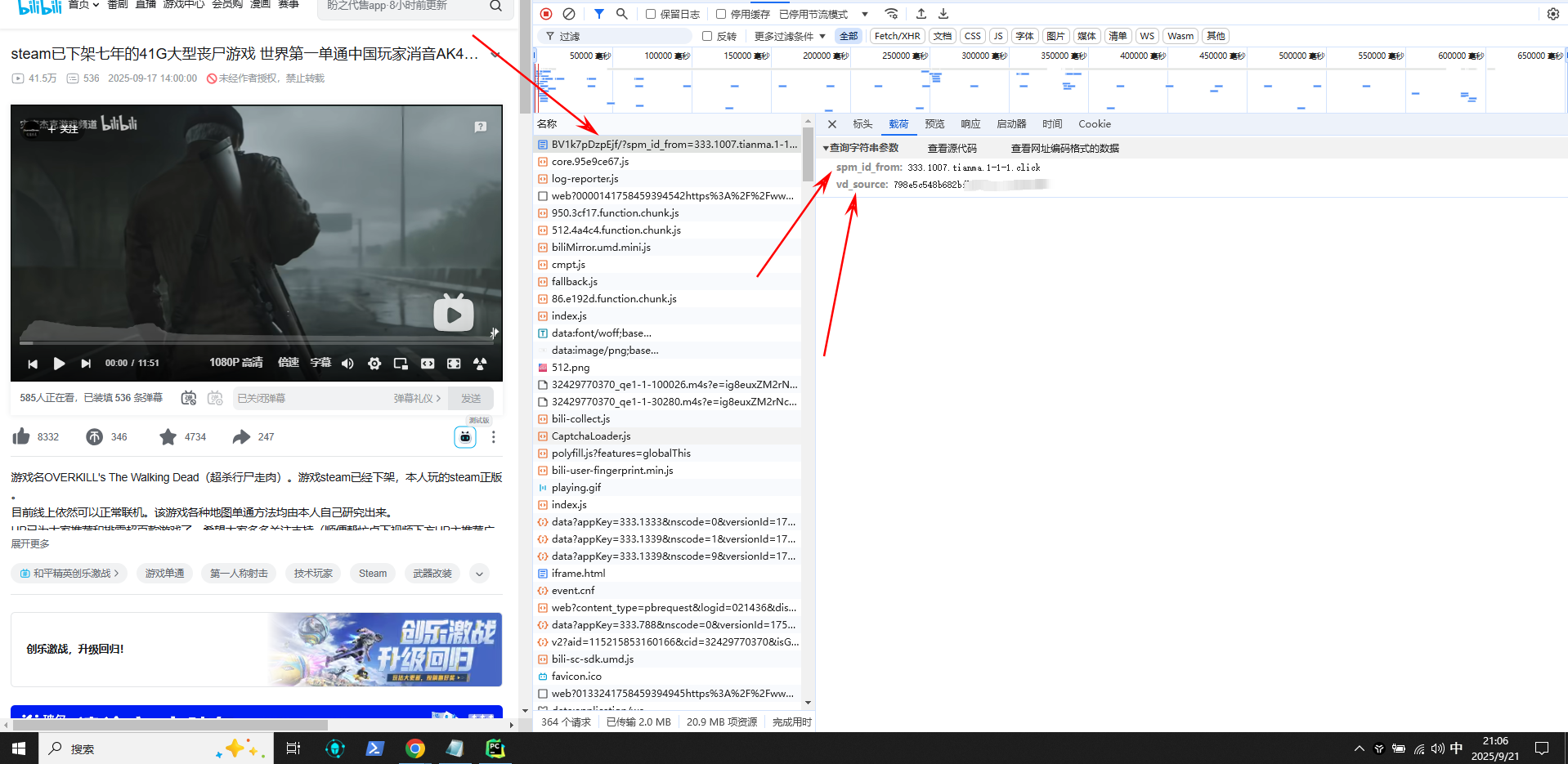
注意这两个字段:vd_source,spm_id_from这是作为请求体中的两个重要参数。这是b站的防盗链反爬机制,所以要放在请求体的params中。这里我直接先放出代码
import time
from tqdm import tqdm
import requests
import json
import re, os
# from moviepy.editor import AudioFileClip, VideoFileClip, CompositeVideoClip
import subprocess
cookies = {
这里是你自己的cookies
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Referer": "https://www.bilibili.com"
}
params = {
'spm_id_from': '333.1007.tianma.1-1-1.click',
'vd_source': '用上面图片中的找到填入',
}
def sanitize_filename(name):
"""把 Windows 不允许的字符替换掉"""
return re.sub(r'[\\/:*?"<>|]', "_", name)
def download_file(url, output_path, title):
os.makedirs(os.path.dirname(output_path), exist_ok=True)
response = requests.get(url, headers=headers, stream=True)
total_size = int(response.headers.get('content-length', 0))
block_size = 1024
progress_bar = tqdm(total=total_size, unit='iB', unit_scale=True, desc=f"正在下载 {title}")
with open(output_path, 'wb') as file:
for data in response.iter_content(block_size):
progress_bar.update(len(data))
file.write(data)
progress_bar.close()
return output_path
def merge_audio_video(video_file, audio_file, output_file):
try:
cmd = [
r"I:\ffmpeg\ffmpeg-8.0-essentials_build\ffmpeg-8.0-essentials_build\bin",
"-i", video_file,
"-i", audio_file,
"-c:v", "copy",
"-c:a", "copy",
output_file,
"-y"
]
result = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
if result.returncode != 0:
print("ffmpeg 合并失败:")
print(result.stderr)
else:
print(f"合并完成: {output_file}")
# 删除原始视频和音频
if os.path.exists(video_file):
os.remove(video_file)
if os.path.exists(audio_file):
os.remove(audio_file)
except Exception as e:
# print(f'ffmpeg -i "{video_file}" -i "{audio_file}" -c:v copy -c:a copy "{output_file}" -y')
print("出错啦!",e)
import os
def print_ffmpeg_command(video_file, audio_file):
"""
自动生成并打印 ffmpeg 合并命令
video_file: 视频文件路径
audio_file: 音频文件路径
"""
# 自动提取视频文件名(不带路径和后缀)
base_name = os.path.splitext(os.path.basename(video_file))[0]
# 输出文件路径
output_file = os.path.join(os.path.dirname(video_file), f"{base_name}_合并.mp4")
# 拼接 ffmpeg 命令
cmd = f'ffmpeg -i "{video_file}" -i "{audio_file}" -c:v copy -c:a copy "{output_file}" -y'
print(cmd)
return cmd
# 获取视频和音频真实地址
def get_video_url(bvid, cid):
playurl = f"https://api.bilibili.com/x/player/playurl?bvid={bvid}&cid={cid}&fnval=4048"
resp_play = requests.get(playurl, headers=headers, cookies=cookies).json()
if resp_play["code"] != 0:
raise Exception(f"获取播放地址失败: {resp_play}")
play_data = resp_play["data"]["dash"]
video_url = play_data["video"][0]["baseUrl"]
audio_url = play_data["audio"][0]["baseUrl"]
return video_url, audio_url
# 下载并合并单个分 P
def download_one_page(bvid, cid, page_title, main_title):
video_url, audio_url = get_video_url(bvid, cid)
safe_title = sanitize_filename(f"{main_title}_{page_title}")
video_path = download_file(video_url, f"result/{safe_title}_video.mp4", safe_title + " 视频")
audio_path = download_file(audio_url, f"result/{safe_title}_audio.mp3", safe_title + " 音频")
output_file = f"result/{safe_title}.mp4"
merge_audio_video(video_path, audio_path, output_file)
print_ffmpeg_command(video_path, audio_path)
# 获取视频分 P 列表
def get_video_pages(bvid):
info_url = f"https://api.bilibili.com/x/web-interface/view?bvid={bvid}"
resp_info = requests.get(info_url, headers=headers, cookies=cookies).json()
if resp_info["code"] != 0:
raise Exception(f"获取视频信息失败: {resp_info}")
data = resp_info["data"]
pages = data["pages"]
return pages, data["title"]
# 下载整个 BV 视频(支持多 P)
def download_bv_video(bvid):
pages, main_title = get_video_pages(bvid)
for i, page in enumerate(pages, start=1):
cid = page["cid"]
page_title = page["part"] or f"P{i}"
print(f"\n正在下载 {main_title} - {page_title}")
download_one_page(bvid, cid, page_title, main_title)
if __name__ == '__main__':
start_time = time.time()
bv = "BVXXXXXXXX" # 视频的BV号
download_bv_video(bv)
end_time = time.time()
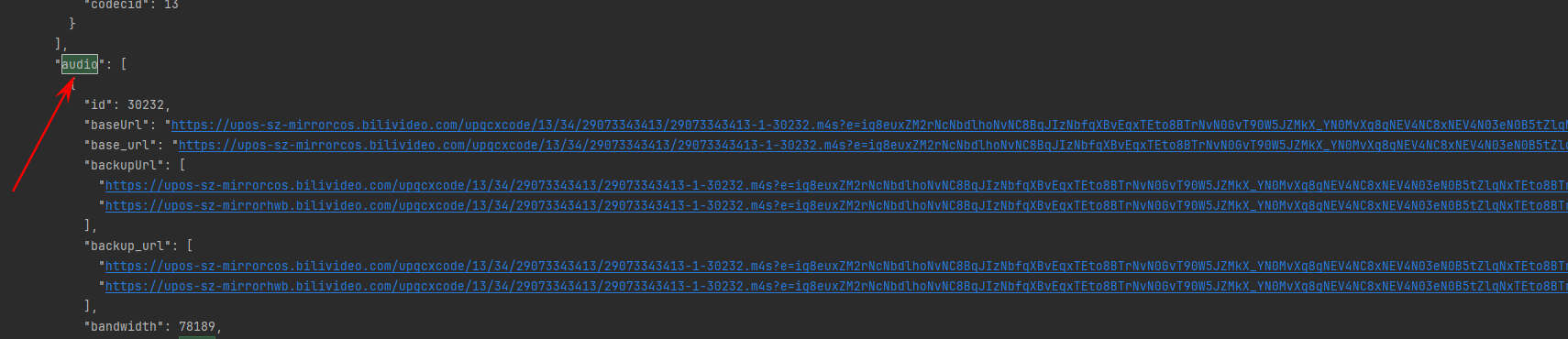
print("总耗时:", round(end_time - start_time, 1), "秒")b站的视频和音频是分类播放的,在我标出的位置是视频的切片,可以自己写出一个请求然后自己print(requests.json)看看返回体.

返回体:id=80是视频清晰度,剩下两个是视频的真实链接。audio是视频的音频。剩下的找个ffmpng工具合并一下就行了。

评论抓取
搜索关键字段wbi/main,可以看到评论的响应体
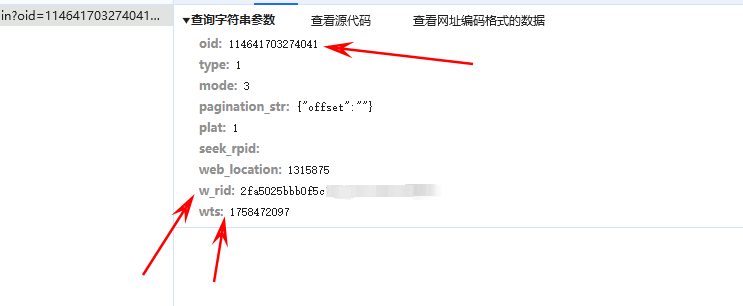
点击载荷我要说明一下这个3个字段:oid是bv号的base58得到的(这里就不多解释了)
关键字段:w_rid和wts两个
拿到 imgKey 和 subKey拼接后按指定顺序打乱,取前 32 位 → 得到盐值 s,请求参数里加上时间戳 wts,参数按 key 排序,拼成 query string,拼上 s,做 MD5 → 得到 w_rid.
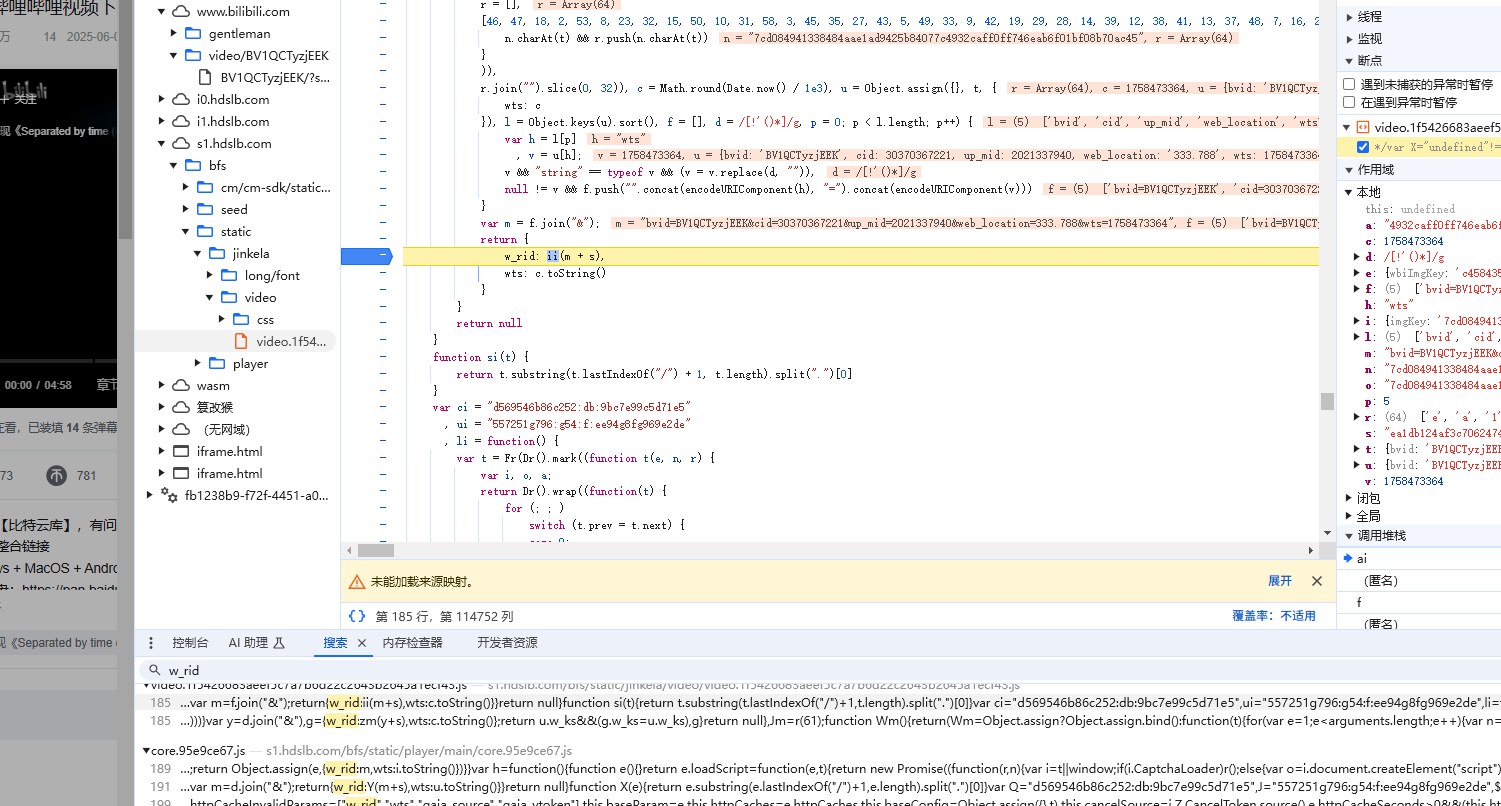
imgKey 和 subKey的位置:
搜索nav就会出现,其实就是两个png链接的名称,对就是这么简单(所以我会先建议你们登陆一下)
脱机算法
def generate_w_rid(params, imgKey, subKey):
# 1. 生成混淆密钥 a
t = imgKey + subKey
index_list = [
46, 47, 18, 2, 53, 8, 23, 32, 15, 50, 10, 31, 58, 3, 45, 35,
27, 43, 5, 49, 33, 9, 42, 19, 29, 28, 14, 39, 12, 38, 41, 13,
37, 48, 7, 16, 24, 55, 40, 61, 26, 17, 0, 1, 60, 51, 30, 4,
22, 25, 54, 21, 56, 59, 6, 63, 57, 62, 11, 36, 20, 34, 44, 52
]
a = "".join([t[i] for i in index_list if i < len(t)])[:32]
# 2. 添加时间戳 wts
wts = str(int(time.time()))
params_with_wts = params.copy()
params_with_wts["wts"] = wts
# 3. 排序 & 过滤特殊字符 & URL encode
encode_items = []
for key in sorted(params_with_wts.keys()):
value = params_with_wts[key]
if isinstance(value, str):
value = value.replace("!", "").replace("'", "").replace("(", "").replace(")", "").replace("*", "")
if value is not None:
encode_items.append(f"{urllib.parse.quote(str(key))}={urllib.parse.quote(str(value))}")
query_string = "&".join(encode_items)
# 4. MD5 生成 w_rid
w_rid = hashlib.md5((query_string + a).encode("utf-8")).hexdigest()
return w_rid, wts