2025年4月初,OpenAI正式发布了GPT-Image-1 API,这是支持ChatGPT-4o图像生成功能的强大模型。与此同时,ComfyUI也迅速推出了对这一尖端技术的支持,通过API节点(Beta)让用户能够在熟悉的节点界面中调用这一最先进的图像生成能力。本文将带你全面了解如何在ComfyUI中设置、使用和优化GPT-Image-1
GPT-Image-1与传统模型的核心区别
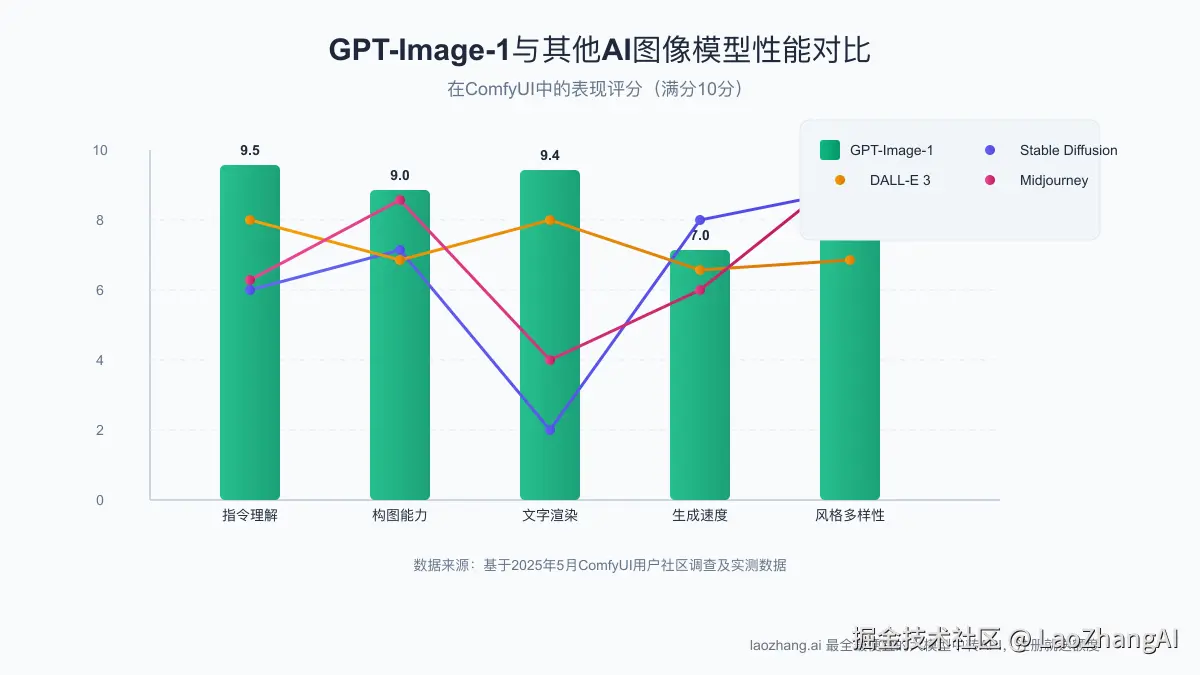
在探索ComfyUI中的GPT-Image-1之前,我们需要理解这一模型与传统扩散模型(如Stable Diffusion)之间的根本差异。这种认知将帮助我们更有效地利用它的独特优势。
GPT-Image-1采用了全新的生成范式,与扩散模型的工作方式有着本质区别:
- 生成方法:GPT-Image-1使用自回归生成方法,类似于大语言模型预测文本的方式来预测图像的视觉令牌,而非通过迭代去噪过程
- 指令理解能力:具备卓越的提示词理解能力和上下文推理能力,能够准确执行复杂的视觉指令
- 构图能力:在处理多对象场景、空间关系和全局一致性方面表现出色
- 文字渲染:能够生成清晰可读的文本,这是传统扩散模型的主要弱点之一
- 训练数据规模:基于远超传统模型的数据规模训练,视觉理解能力更接近人类
这些特性使GPT-Image-1特别适合于需要精确布局、复杂场景和高质量文字的商业应用场景。理解这些差异将帮助我们更好地结合ComfyUI的节点系统,充分发挥这一革命性模型的潜力。
准备工作:ComfyUI环境配置
在开始使用GPT-Image-1之前,我们需要确保ComfyUI环境正确配置。无论是新安装还是更新现有安装,以下步骤将帮助你做好准备工作。
1. 获取最新的ComfyUI开发版本
GPT-Image-1 API节点目前在"开发版本"(Nightly版本)中提供,要访问此功能,请确保使用最新版本:
bash
# 如果你是新安装
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
pip install -r requirements.txt
# 如果你需要更新现有安装
cd ComfyUI
git pull
pip install -r requirements.txt --upgrade旧版ComfyUI可能缺少必要的API节点支持,因此更新至最新版本至关重要。
2. 确认API节点支持
启动ComfyUI后,确认API节点框架已正确加载:
- 打开ComfyUI界面(通常是http://localhost:8188)
- 在节点浏览器中搜索"OpenAI"或"API"
- 确认你能看到"OpenAI GPT-Image-1"节点
如果节点不可见,可能需要重启ComfyUI或检查安装日志中的错误信息。
3. ComfyUI账户与额度管理
使用GPT-Image-1节点需要ComfyUI账户和API额度,设置步骤如下:
- 在ComfyUI界面中,点击右上角的设置图标
- 导航到"User"选项卡并创建/登录账户
- 在"Credits"选项卡查看和管理你的API额度
基础使用:GPT-Image-1节点详解
掌握GPT-Image-1节点的参数设置至关重要,这将直接影响生成图像的质量、速度和成本。让我们深入了解这个节点的关键参数及其最佳配置方案。
核心参数解析
GPT-Image-1节点提供了多种参数选项,用户可以根据需求进行调整:
| 参数名称 | 可选值 | 说明 | 推荐设置 |
|---|---|---|---|
| prompt | 文本输入 | 描述要生成的图像内容 | 详细、具体的描述 |
| seed | 0-2147483647 | 用于控制生成结果的随机种子 | 0(随机生成) |
| quality | low/medium/high | 图像质量设置,影响成本和生成时间 | medium(平衡质量与成本) |
| background | opaque/transparent | 返回图像是否有背景 | 根据用例选择 |
| size | auto/1024x1024/1024x1536/1536x1024 | 生成图像的尺寸 | 根据用途选择 |
| n | 1-8 | 要生成的图像数量 | 1(单次测试)或2-4(多样性探索) |
提示词优化策略
GPT-Image-1对提示词的响应方式与传统扩散模型有显著不同。以下是专为GPT-Image-1优化的提示词策略:
- 自然语言描述:使用完整句子而非关键词列表,如"一只橙色的猫坐在窗台上,阳光透过窗户"
- 明确空间关系:清晰描述对象之间的位置关系,如"一杯咖啡放在书的右侧,笔记本位于左边"
- 风格描述:直接描述所需的艺术风格,如"使用印象派风格绘制的海滩日落场景"
- 避免过多反向提示:GPT-Image-1更擅长理解正面指令,较少需要反向提示
实践案例:
bash
# 有效提示词示例
"一个现代简约风格的客厅,有一个灰色沙发,木质咖啡桌,墙上挂着抽象画,大窗户透进自然光,地上铺着米色地毯。"
# 对比传统SD提示词
"modern minimalist living room, gray sofa, wooden coffee table, abstract painting on wall, large windows, natural light, beige carpet, 8k, detailed, realistic"GPT-Image-1对自然语言的理解能力远优于关键词堆砌,实验表明,使用更自然的语言描述可以获得更好的结果。
进阶工作流:图像编辑与混合
除了基本的文本到图像生成,GPT-Image-1节点还支持强大的图像编辑功能,结合ComfyUI的节点系统,可以构建复杂而灵活的工作流。
图像修改工作流
ComfyUI中的GPT-Image-1支持通过蒙版进行图像编辑(类似于inpainting),以下是创建基本图像编辑工作流的步骤:
- 添加"Load Image"节点加载基础图像
- 使用内置的MaskEditor创建编辑蒙版(白色区域将被替换)
- 将图像连接到GPT-Image-1节点的"image"输入
- 将蒙版连接到"mask"输入
- 添加描述新内容的提示词
注意事项:
- 蒙版和图像必须具有相同尺寸
- 输入大图像时,节点会自动将图像调整为适当大小
- 白色区域表示要修改的部分,黑色区域将保持不变
多图像输入工作流
GPT-Image-1还支持处理多个输入图像,通过"Batch Images"节点可以实现:
- 添加多个"Load Image"节点加载不同图像
- 使用"Batch Images"节点将它们合并
- 将批处理图像连接到GPT-Image-1的"image"输入
- 提供能够理解和融合多图像上下文的提示词

高级应用:混合工作流设计
ComfyUI的强大之处在于能够构建混合工作流,将GPT-Image-1与其他模型和节点结合使用,创造出更加复杂和精细的创作流程。
GPT-Image-1与SD模型的协同工作流
我们可以构建一个强大的混合工作流,利用GPT-Image-1的布局和概念能力,结合SD模型的风格化能力:
- 使用GPT-Image-1生成基础图像,专注于复杂布局和对象关系
- 将生成的图像通过"Load Image"节点导入
- 使用ControlNet节点(如canny或depth)保留布局和结构
- 应用SD模型进行风格化或细节增强
这种混合方法充分利用了两种模型的优势:GPT-Image-1的卓越布局能力和SD模型的风格化能力。
批量处理与自动化流程
对于需要生成大量相关图像的场景,可以构建批量处理工作流:
- 创建包含多个提示词变体的文本文件
- 使用ComfyUI的"Load Text"节点加载提示词列表
- 配置循环结构,将每个提示词传递给GPT-Image-1节点
- 添加"Save Image"节点,配置自动命名逻辑
- 运行工作流,自动生成并保存一系列图像
此类自动化流程特别适合电商产品图、营销素材集和设计概念探索等场景。
实战案例:商业级应用工作流
为了展示GPT-Image-1在ComfyUI中的实际应用价值,以下是三个具体的商业应用工作流案例,包括完整的节点设置和提示词策略。
电商产品展示图生成
这个工作流专为创建专业的产品展示图而设计:
-
添加GPT-Image-1节点,设置quality为"high"
-
输入产品描述提示词,例如:
arduino"一款极简主义设计的黑色皮革钱包放置在白色背景上,从45度角俯视,展示产品细节和质感,专业产品摄影风格,柔和照明" -
添加"Save Image"节点保存结果
-
可选:添加后处理节点进行背景移除或色彩校正
这种工作流特别适合电商平台、产品目录和营销素材创建。GPT-Image-1在创建逼真的产品展示图方面表现出色,尤其是在准确呈现材质和细节方面。
UI/UX设计原型快速生成
为设计师创建的工作流,用于快速生成UI/UX设计概念:
-
设置GPT-Image-1节点,quality为"medium",size为"1024x1024"
-
提供详细的设计描述,例如:
arduino"一个现代化的移动应用主页界面设计,使用深蓝色和白色作为主色调,顶部有搜索栏,中间是三个水平滚动的内容卡片,底部有导航栏,整体风格简洁优雅,适合金融应用" -
将生成的图像导入设计工具进行细化
GPT-Image-1在创建UI设计原型方面表现出色,能够理解复杂的布局指令和设计元素关系,大大加快设计概念验证阶段。
市场营销和社交媒体内容创作
针对社交媒体内容创作的工作流:
-
配置GPT-Image-1节点,size设置为"1024x1536"(适合垂直社交平台)
-
输入策划的场景描述,例如:
arduino"一杯精致的拿铁咖啡放在木质桌面上,旁边有一本打开的笔记本和一支钢笔,温暖的晨光从窗户斜射进来,营造舒适的工作氛围,生活方式摄影风格" -
添加"Load Image"节点和MaskEditor以便进行微调
-
使用"Save Image"节点导出最终结果
这种工作流程特别适合品牌故事讲述、社交媒体营销和内容创作,GPT-Image-1能够创建具有情感共鸣和故事性的图像,有效提升用户互动。
常见问题与疑难解答
在使用ComfyUI的GPT-Image-1节点过程中,用户可能会遇到各种问题。以下是一些常见问题及其解决方案。
无法找到API节点
问题 :在ComfyUI中搜索"OpenAI"或"GPT-Image-1"时找不到相关节点。 解决方案:
- 确认是否使用最新的ComfyUI开发版本,而非稳定版
- 检查启动日志中是否有相关错误信息
- 尝试重新启动ComfyUI服务器
- 如果问题持续,可以尝试在ComfyUI目录执行
git pull命令更新到最新版本
授权和登录问题
问题 :配置API后仍然提示需要登录或授权。 解决方案:
- 确认是否已在设置中成功登录ComfyUI账户
- 检查API密钥是否正确输入,无多余空格
- 如果使用中转服务,确认API基础URL是否正确
- 在某些网络环境中,可能需要配置代理才能访问API服务
图像生成质量问题
问题 :生成的图像质量不符合预期。 解决方案:
- 尝试提高quality参数从"low"到"medium"或"high"
- 改进提示词,使用更详细和具体的描述
- 指定所需的艺术风格和细节水平
- 尝试不同的随机种子值
性能和延迟问题
问题 :图像生成过程非常缓慢。 解决方案:
- 对于测试阶段,使用"low"质量设置以加快速度
- 确保网络连接稳定,特别是使用API中转服务时
- 对于批量处理,考虑在非高峰时段运行
- 如果可能,使用较小的图像尺寸进行初步测试
未来展望与发展趋势
随着GPT-Image-1和ComfyUI的持续发展,我们可以期待这一集成带来的更多可能性和机会。
GPT-Image-1的功能演进
根据OpenAI的发展路线,我们可以预见GPT-Image-1将会有以下发展趋势:
- 分辨率提升:支持更高分辨率的图像生成,可能达到4K或更高
- 视频生成能力:整合类似Sora的视频生成功能
- 更精细的编辑控制:提供更多图像编辑和操控参数
- 专业领域优化:针对特定行业(如医疗、建筑、时尚)的专业版本
ComfyUI集成的未来展望
ComfyUI团队也在不断改进API节点功能,预计将推出:
- 更多定制参数:暴露更多GPT-Image-1的高级参数
- 更紧密的跨模型集成:改进GPT-Image-1与其他模型的协同工作流
- 批处理性能优化:提高大规模图像生成的效率
- 本地化功能:减少对外部API的依赖
总结:开始你的ComfyUI GPT-Image-1之旅
GPT-Image-1在ComfyUI中的集成代表了AI图像生成领域一个重要的里程碑,将OpenAI强大的图像生成能力与ComfyUI灵活的节点系统相结合,为创作者提供了前所未有的创作可能性。