
标题:<LODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering>
主页:https://lodge-gs.github.io/
来源:Google、CTU in Prague、Google DeepMind
文章目录
- 摘要
- 一、引言
- 二、相关工作
-
- 1.新视角合成
- [2.大场景 3D 重建](#2.大场景 3D 重建)
- [3.Level-of-detail 3DGS](#3.Level-of-detail 3DGS)
- 三、预备知识
- [四、LOD(Level of Detail ) 表示](#四、LOD(Level of Detail ) 表示)
-
- [4.1 构建LoD表示](#4.1 构建LoD表示)
- [4.2 选择深度阈值](#4.2 选择深度阈值)
- [4.3 通过基于chunk的渲染,减少内存。](#4.3 通过基于chunk的渲染,减少内存。)
- [4.4 可见性过滤。](#4.4 可见性过滤。)
- [4.5 不透明混合:平滑的跨区块过渡](#4.5 不透明混合:平滑的跨区块过渡)
- 实验
-
- [1.Hierarchical 3DGS数据对比](#1.Hierarchical 3DGS数据对比)
- [2.Zip-NeRF dataset 数据对比](#2.Zip-NeRF dataset 数据对比)
- 3.消融实验
- 4.移动端与低功耗设备渲染性能测试
- 补充材料
摘要
本研究提出了一种创新的3D Gaussian Splatting 的细节层次(LOD)方法,可在内存受限设备上实现实时渲染大规模场景 。该方法通过迭代选择基于相机距离的最优高斯子集构建分层LOD表示,显著降低渲染时间和GPU内存占用。具体实现中,我们采用深度感知三维平滑滤波器构建每个LOD层级,随后通过重要性剪枝与微调保持视觉保真度。为进一步优化内存开销,将场景划分为空间块并动态加载相关高斯子集,同时运用不透明度混合机制避免块边界处出现视觉伪影。该方法在户外(Hierarchical 3DGS)和室内(Zip-NeRF)数据集上均取得业界领先效果,以更低的延迟和内存需求呈现高质量渲染效果。
一、引言
新型视图合成是计算机视觉领域的核心研究方向,其应用广泛涉及增强现实/虚拟现实(AR/VR)、游戏开发、交互式地图构建等领域。随着神经辐射场(NeRFs)21和三维高斯喷洒技术(3DGS)9的问世,该领域近年来备受瞩目------后者通过实现实时渲染功能,进一步拓展了应用场景。随着NeRFs和3DGS技术的普及,业界对将这些方法应用于更复杂、更大规模场景的兴趣与日俱增26,10,4。然而,传统方法在处理这类大规模环境时存在明显短板10,17。问题的核心在于数据表征方式:要捕捉精细细节,需要使用大量高斯函数进行建模。因此,即使场景中距离较远的区域,也会被密集分布的高斯函数所填充,这些高斯函数代表着对最终渲染图像贡献甚微的细粒度几何元素。这会导致渲染过程出现严重低效问题,因为系统会处理大量远距离高斯函数,而这些函数实际上对画面影响微乎其微。此外,内存限制也带来了额外挑战:并非所有高斯函数都能同时存入GPU内存,这对内存资源极度紧张的移动设备或低端机型而言尤为棘手。
在计算机图形学领域,这一问题已得到广泛研究。针对基于网格的渲染技术,业界主要采用细节层次(LOD)策略来有效解决。该技术通过离相机较远时渲染低分辨率资源,随着摄像机靠近逐步替换为高分辨率版本。尽管已有针对大规模场景中三维几何体(3DGS)的LOD方案CityGaussian、A hierarchical 3d gaussian representation for real-time rendering of very large datasets,但这些方法主要侧重提升渲染速度 ,未限制GPU内存中加载的高斯分布数量,导致小型设备的渲染面临挑战。这类方法往往需要在每帧新画面重新计算需渲染的高斯分布子集,增加了渲染开销。更重要的是,所有不同LOD层级的高斯分布(甚至超过3DGS9中的数量)都必须始终驻留在GPU内存中。最后,现有LOD方案Octree-GS、FLoD需要针对每个场景进行参数精细调校,才能兼顾良好画质与性能表现。
LODGE旨在同时提升大规模场景的渲染速度,并通过减少内存中高斯分布的数量来适配嵌入式设备的应用需求。与现有的LOD(局部化)方法类似,我们采用多组具有不同细节层次的高斯分布来呈现场景。但与现有方法不同的是,我们提出在聚类中心周围定义空间区域。每个区域会从预计算的LOD中激活一组固定的高斯分布,从而避免不同帧之间的计算开销。我们的创新贡献可概括为以下几点:
- 提出一种针对3D几何图形的新型LOD表示方法,无需每帧重新计算高斯分布列表,从而实现加速与紧凑化设计,使得即使在移动设备上也能渲染大规模场景。
- 进一步设计了自动选择LOD分割最优超参数的策略,而大多数其他方法仍需手动调整每个3D场景的超参数。
- 为进一步加速渲染,将场景划分为多个chunk,并预先计算每个chunk的活跃高斯分布集合。
- 最后,引入一种创新的不透明度插值方案 ,既能生成视觉效果更佳的渲染结果,又能消除chunk间过渡时产生的伪影。
二、相关工作
1.新视角合成
2.大场景 3D 重建
3.Level-of-detail 3DGS
三、预备知识

重要性剪枝 。改进了RadSplat 24中提出的重要性剪枝方法。在3DGS训练过程中,当高斯基元的不透明度降低或其前方的高斯分布变得不透明时,许多高斯分布的可见度会显著下降。虽然3DGS会定期移除低不透明度的高斯分布,但无法清除被遮挡的高斯(即隐藏在其他场景几何体之后的高斯)。RadSplat 24通过计算每个高斯基元对所有训练相机中任意像素的贡献值(即alpha混合中的渲染权重)的最大值来评估其重要性(重要性分数 τ i τ_i τi) 。通过移除所有重要性分数低于阈值的高斯分布,剪枝对渲染影响微乎其微的高斯分布。这不仅提升了渲染速度,还减少了内存占用------这对于使用低端设备的场景尤为重要。我们沿用24的方法,在训练过程中进行两次剪枝操作。
四、LOD(Level of Detail ) 表示
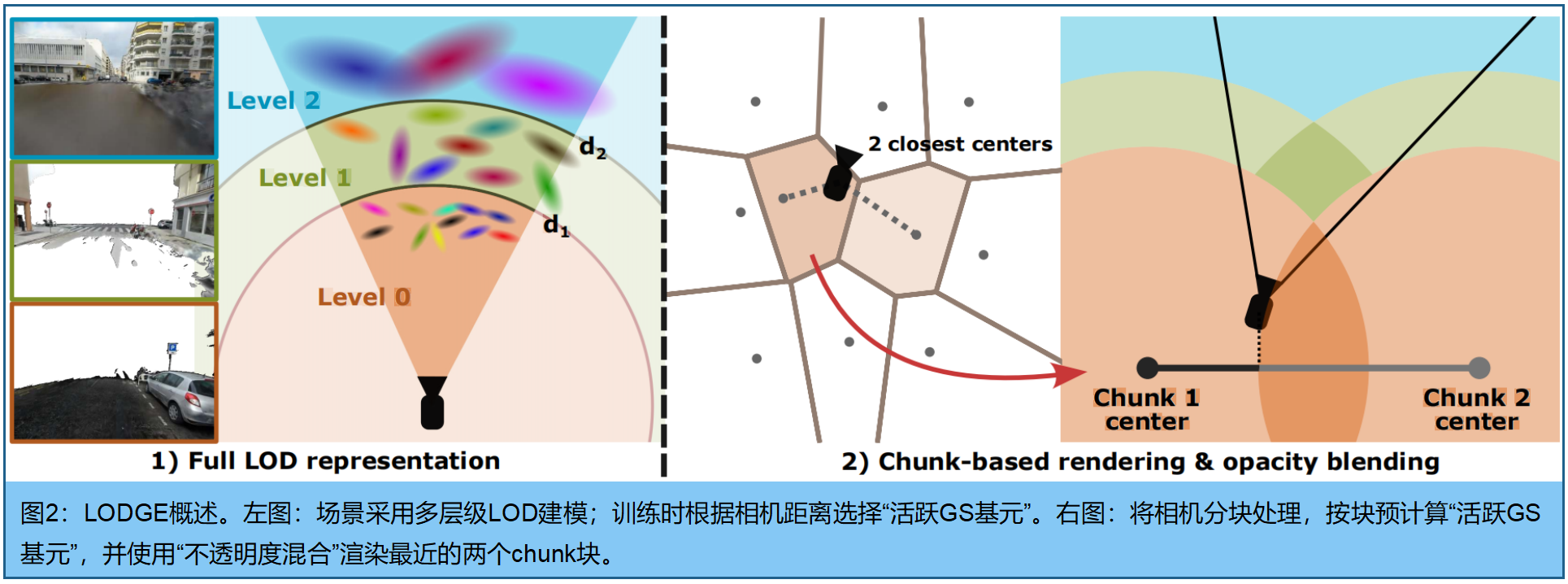
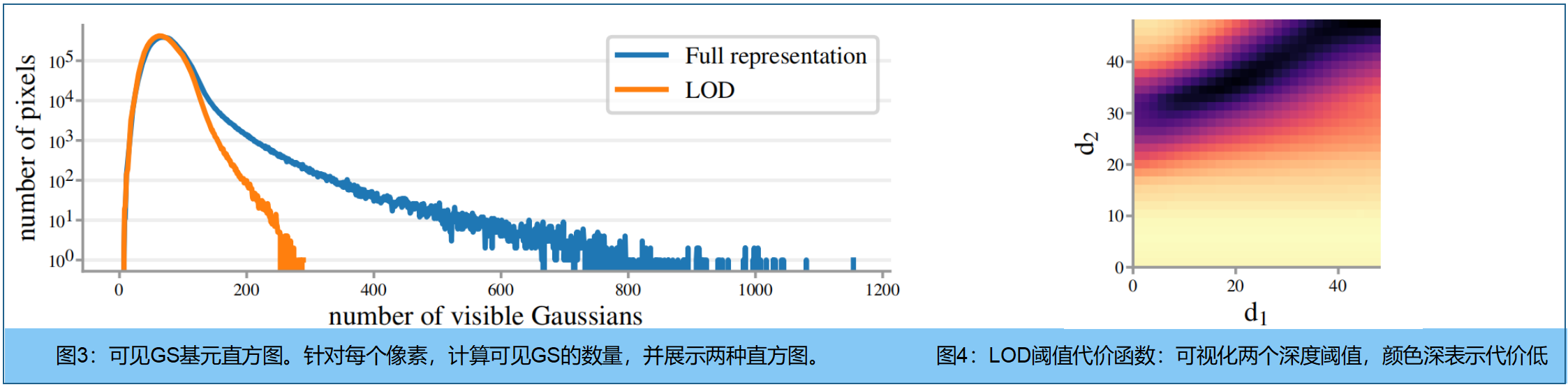
LODGE将三维场景表示为多组GS,对应不同LOD(如图2)。场景远处区域的大量GS对渲染贡献甚微,导致内存占用和计算量过大,用16×16像素块的处理,会降低渲染速度。LODGE了减少具有大量可见高斯分布的像素数量,如图3。
远距离区域 用细节较少的GS集合表示,邻近区域 用细节较多的GS集合。 定义多个LOD层级: G ( l ) G^{(l)} G(l); L > l > 0 L>l>0 L>l>0 , G ( 0 ) G^{(0)} G(0)表示最精细的集合,由原始图像集优化获得。假设每个LOD层级 G ( l ) G^{(l)} G(l)构建方式:从至少 d l d_l dl的距离外观察时,能够达到足够的渲染质量。使用相机位姿做LOD渲染时,会从每个LOD层级中选取一组GS(称为"活跃高斯",见图2)。对于相机中心 c c c,定义为:
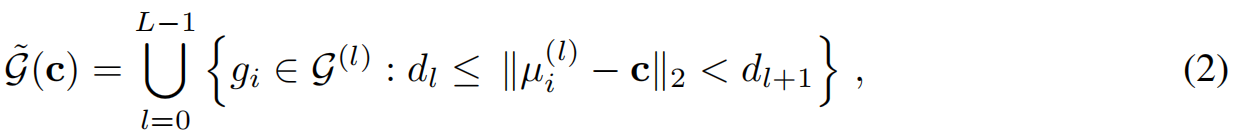
d 0 = 0 d_0 = 0 d0=0, d L = ∞ d_L =∞ dL=∞,且 μ ( i , l ) μ(i,l) μ(i,l)是第 l l l level 的高斯 g i g_i gi的均值。如图3,LOD通过减少每个像素可见GS的长尾效应,从而加快了渲染。
4.1 构建LoD表示
构建每个LOD level G ( l ) G^{(l)} G(l),使得从至少 d l d_l dl外观察时能达到足够的渲染质量。为此,我们借鉴了MipSplatting 35提出的三维滤波器设计思路。如该方案所述,虽然渲染图像是由高斯分布构成的连续三维场景的二维投影,但图像本身实际上是一个网格结构------每个像素坐标都对应着从连续三维信号中采样的位置。当屏幕空间中的采样间隔为1时,深度d处三维世界空间中的像素间距可表示为T=f/d,其中f为焦距。
屏幕空间变化 d x = 1 d_x=1 dx=1 像素时,对应的世界空间变化为:
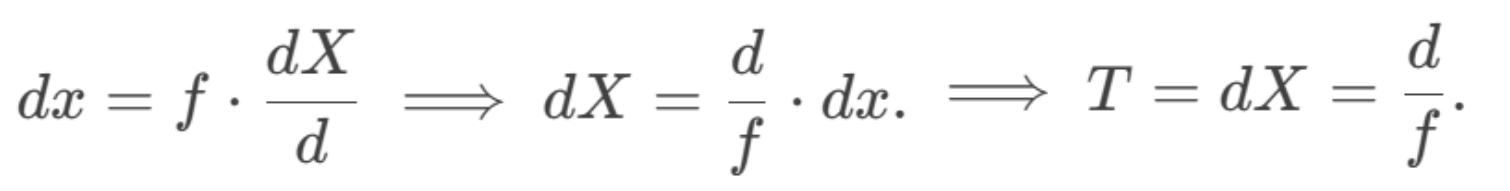
根据奈奎斯特定理25,29,35,信号成分只有在采样间隔小于2T时才能被重建。因此,小于2T的高斯分布不仅会产生混叠伪影35,还会增加内存占用和渲染时间。为确保高斯分布尺寸大于 2 T 2T 2T,沿用Mip-Splatting 的方法,将每个高斯分布与平滑的三维滤波器进行卷积运算 。对均值 μ μ μ、协方差 Σ Σ Σ且深度为 d d d的高斯基元,其变换后的函数( s s s为超参数):
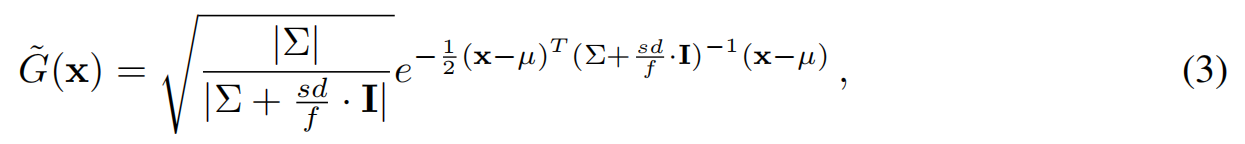
为了构建在距离 d l d_l dl以上观察的低细节表征 G ( l ) G^{(l)} G(l),我们从 G ( 0 ) G^{(0)} G(0)中复制GS,并为深度 d l d_l dl添加平滑的三维滤波器(公式(3))。虽然单独添加平滑三维滤波器并不会直接减少GS的数量,但大量GS会变得冗余,从而降低其在alpha合成中的贡献。最终,通过使用RadSplat的重要性评分,迭代地剔除未使用的GS(始终采用少量微调步骤,修正因剔除GS而引入的误差)。微调使用LOD渲染,其层级数可提升至当前优化的LOD级别。
4.2 选择深度阈值
关键问题:如何选择深度阈值 d l d_l dl,才能最大化渲染性能?渲染器以16×16 tiles的像素块为单位进行处理,渲染效果主要取决于同一tiles 内处理的GS数量。每个像素块内的所有线程需要处理所有可见高斯分布的并集,并且必须等待最慢线程完成光栅化。
虽然很难从理论上分析阈值对处理的GS数量的影响,但可以通过不同阈值来估计这个数量(代价):通过渲染训练视图的一个子集,并选择使每个tiles中的GS平均数量最小化的选项。
图4展示了深度 d 1 d_1 d1和 d 2 d_2 d2处两个LOD层级的代价分布情况。可以发现,在集合{ ( x , a x + b ) : x ∈ R (x,ax+b):x∈R (x,ax+b):x∈R }中,最小值的数值具有相似性。这使我们采用一种简单的贪心策略------从 d 1 d_1 d1开始,逐步增加更多阈值。通过这种方式,搜索问题的复杂度被简化为线性级数。
4.3 通过基于chunk的渲染,减少内存。
虽然LOD渲染(前文所述)通过减少可见高斯分布的数量来加快光栅化速度,但所有高斯分布仍需加载到GPU内存中。此外,"活跃GS"需要持续重新计算,导致额外的计算开销。对于内存有限的小型设备而言,这种开销可能难以承受。为解决这一问题,我们提出 将场景划分为称为"chunk"的不同区域 ,每个chunk存储一组固定的"活跃GS"。在渲染图像时,光栅化器只需使用最近区块预先计算的"活跃GS"即可 。我们通过在训练相机位置上执行K均值聚类将场景划分为区块(细节见补充材料)。对于每个中心为 c c c的区块,其"活跃GS"由公式(2)定义,该公式是在区块中心(而非相机位置)计算得出,深度 d l d_l dl会根据区块半径(即到最近相邻区块中心的距离)进行偏移,从而确保区块内所有相机位置都能获得足够的分辨率。
4.4 可见性过滤。
基于LOD层级块数据,我们通过筛选每个层级块的GS集合来进一步加速渲染过程。在RadSplat 24算法基础上,我们对每个层级块实施重要性剪枝操作------即计算各高斯分布的重要性评分,并剔除所有重要性评分低于预设阈值的分布。为增强鲁棒性,我们通过在现有训练视图中添加随机扰动来生成额外视角。具体实现时,保留原始相机位置,同时采样随机的旋转。
4.5 不透明混合:平滑的跨区块过渡
构建这些chunk后,最直接的做法是直接渲染块中心的"活跃GS"。虽然这种方法能提升渲染速度并节省内存,但在渲染摄像机轨迹的动态视频时(见图7),会产生剧烈的视觉突变。这些伪影本质上源于移动过程中"活跃GS"的突变,而transition中未使用任何平滑滤波器 。为解决这一问题,我们提出了一种基于最近两个数据块的平滑策略(见图2)。在图像渲染时, 首先确定最近两个数据块的中心点,分别提取其对应的活跃高斯函数集合并进行合并。随后,对不在两组活跃高斯函数交集中的高斯函数,通过调节其不透明度来实现过渡效果。
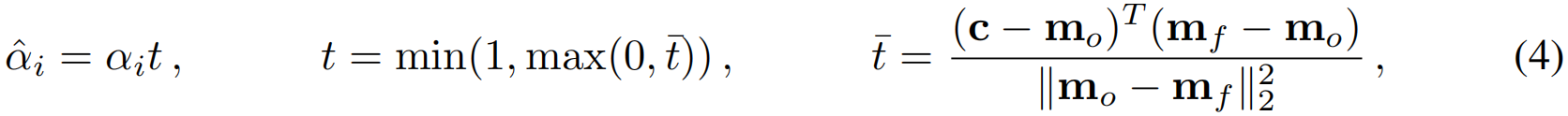
其中 c c c表示当前相机位置, m f m_f mf是高斯 i i i 所属的块中心, m o m_o mo则是另一个不含高斯 i i i 的块 。需要注意的是, t ~ \tilde{t} t~是 ( c − m o ) (c−m_o) (c−mo)在连接两个块中心的直线上的投影长度归一化值。我们采用投影长度而非欧氏距离,以便即使相机未穿过块中心也能实现平滑过渡。基于两组修改透明度的活动高斯分布的并集,我们继续执行标准光栅化步骤。但需注意,只需将两个块的并集加载到内存中,并且在每次渲染过程中,我们只需更新两个活动高斯集合对称差的透明度。实际操作中,LOD分割的重新加载可由后台进程完成,不会影响渲染器的运行时性能。
实验
硬件配置。所有基准测试方法及本研究均采用单块NVIDIA A100 SXM4 40GB显卡进行训练与评估。在移动设备实验中,我们使用了两部iPhone(13 Mini和15 Pro)以及两台配置普通显卡的低端笔记本电脑(MacBook Air M3和惠普Chromebook)
数据集与对比基准。两个大规模数据集:Hierarchical 3DGS数据集的两个户外场景,和Zip-NeRF数据集中的三个室内场景。每个场景包含约1000至2000张图像。
基线对比模型:Zip-NeRF(训练速度较慢且不具备实时渲染功能);3DGS 、Mip-Splatting 和ScaffoldGS ;基于LOD的方法------H3DGS(在分层3D生成系统数据集上表现最佳)、FLOD 和Octree-GS 。 (H3DGS、Octree-GS和FLOD分别经过45K、40K和100K次迭代训练,而我们的模型仅训练了36K次迭代。FLOD采用3-4-5层级渲染,H3DGS则使用其默认参数设置(参数值为6))
1.Hierarchical 3DGS数据对比
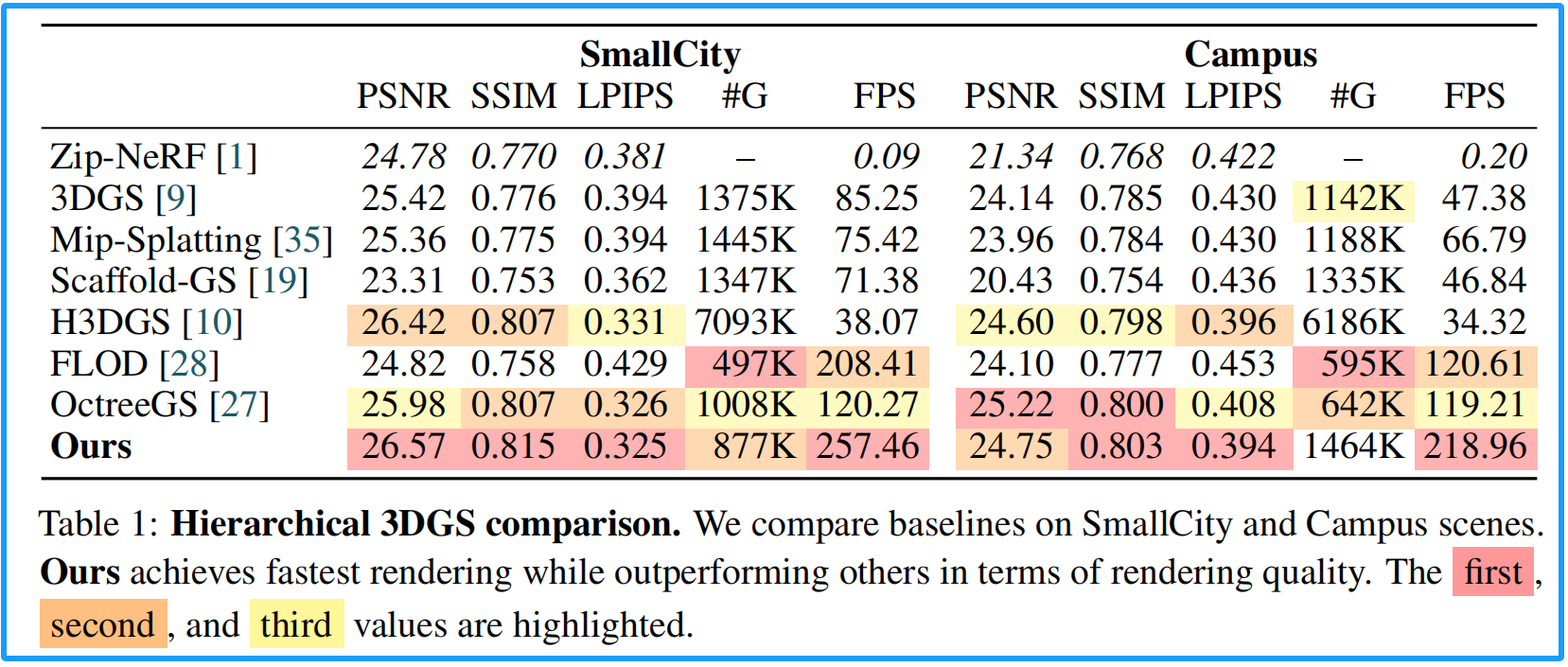
表1所示:Zip-NeRF在这些大型场景中表现不佳,尽管其训练耗时更长(20万次迭代对比我们的3.6万次)。这可能源于其采用有限分辨率的连续场景表示方式,而3DGS仅稀疏编码已占用空间。在非LOD基线方法中,3DGS 9和Mip-Splatting 35展现出与之竞争的质量和渲染速度,而Scaffold-GS 19则因大规模场景下密集度不足而落后。H3DGS 10虽获得高视觉保真度,但每帧LOD分割和大量高斯函数带来的显著开销使其速度逊色于其他方法。FLOD由于采用从粗到细的训练方案,在早期丢弃细节后难以后期恢复,即便其训练迭代量是同类方法的三倍,仍无法生成足够多的高斯函数。对于Octree-GS 27,我们的方法整体质量更高。有趣的是,Octree-GS在PSNR指标上优于校园场景,但在SSIM和LPIPS指标上表现欠佳。我们认为这是由于其基于MLP的设计虽然对曝光变化更具鲁棒性,但在保持感知相似性方面效果较差。综上所述,我们的方法在所有场景中均保持最佳性能,同时维持卓越的渲染效率。通过定性对比(图5),我们选取近景和远景区域进行评估,以考察局部细节与远距离保真度。总体而言,我们的方法在近处和远处区域都能提供更清晰的重建效果。相比之下,Octree-GS在近距离区域显得较为模糊,并且在远距离时会出现颜色偏移现象;而H3DGS则常呈现锯齿状几何结构,这可能与其深度监督机制有关。

2.Zip-NeRF dataset 数据对比
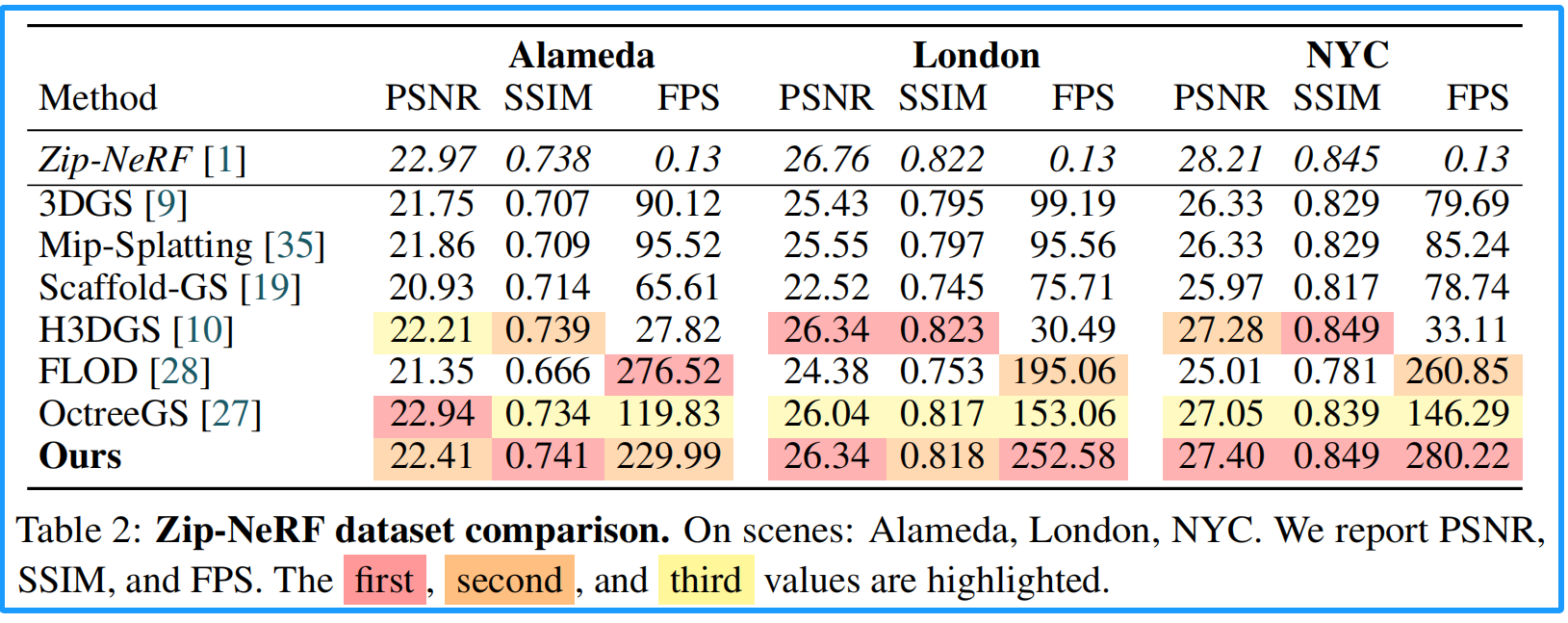
表2所示,Zip-NeRF虽然准确率最高,但需要长达20万次迭代的训练周期且不支持实时渲染,我们仍将其作为参考。在具备实时渲染能力的方法中,我们的方案在质量与速度之间取得了最佳平衡:FLOD 28虽渲染速度快,但由于粗到细训练阶段的过早剪枝导致细节丢失;H3DGS 10保持高保真度但显著拖慢速度,需处理超过1000万个高斯分布和逐帧LOD图割;Octree-GS 27兼具良好画质与适中速度,但因采用逐帧多层感知评估而略逊一筹;最后,Scaffold-GS 19在画质与速度方面均落后于其他非LOD基线方法。从定性评估(图6)可见,FLOD生成结果常出现模糊现象且频繁遗漏远处细节(如第二行灯具),Octree-GS在近距离锐度表现上较我们的方法逊色(如第一行栏杆)。远距离区域表现相当,但我们的模型能更好地保留高频高光(如伦敦场景),而Octree-GS因基于多层感知的设计,在曝光变化时会略微降低色彩伪影。综上所述,我们的方法既能实现更清晰的近景重建,又能在远距离区域保持同等或更优的保真度,同时保持更快的渲染速度。

3.消融实验
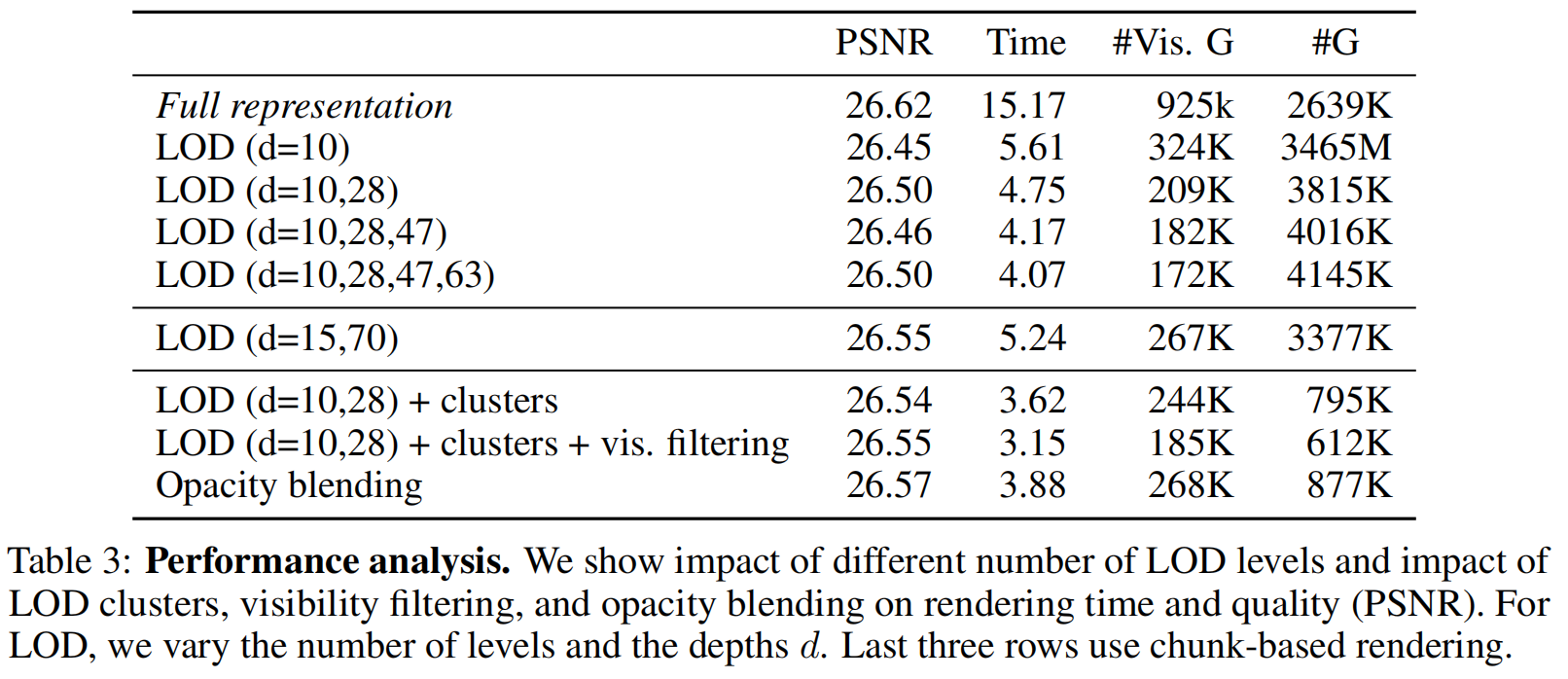
在SmallCity场景中开展消融实验,评估方法关键组件对渲染质量和速度的影响。定量结果如表3所示,包含PSNR、渲染时间、可见高斯数量及内存使用情况。由于高斯在块边界处的加载是异步处理的,因此未计入时间计算。定性结果详见图7 。我们首先采用基础方法("全表征"),该方法包含重要性剪枝但不采用LOD技术。增加至四个LOD层级显著提升渲染速度(单层可提升3倍),同时因更激进的剪枝策略,PSNR和锐度仅略有下降。随着层级增加收益递减,我们决定在所有实验中始终采用两个LOD层级以实现速度与质量的平衡。阈值通过自动选择确定(详见第3节"深度阈值选择"),实验表明手动设置(15米和70米)的性能较自动选择的"LOD(d=10,28)"有所下降。

最后三行测试了基于chunk的渲染方案。通过聚类相机位置并根据块半径调整深度阈值,虽然提升了质量('LOD(d=10,28)+聚类'),但因LOD分辨率更高导致高斯计数增加。可见性过滤('+可见性过滤')进一步减少了可见和加载的高斯数量,从而缩短渲染时间。然而仅使用块中心的活跃高斯会导致块边界处出现视觉伪影,表现为锐度不连续现象(图7右二列)。为解决此问题,我们在相邻块间引入透明度混合(最后一行),使过渡更加平滑。尽管这会略微增加渲染时间和高斯计数,但相比非块基LOD方案,其运行速度更快且更节省内存,尤其适合内存受限的移动设备。
4.移动端与低功耗设备渲染性能测试
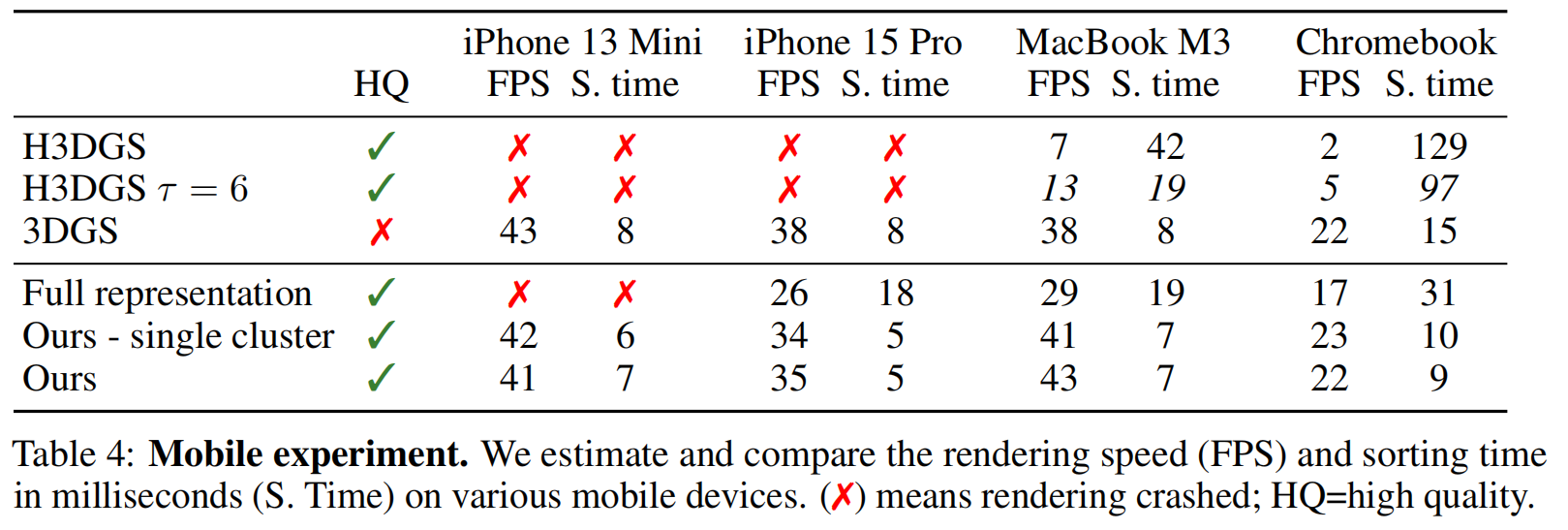
最终在四款设备上进行渲染速度基准测试:iPhone 13 Mini、iPhone 15 Pro、惠普Elite Dragonfly Chromebook以及13英寸MacBook Air。测试采用Mark Kellogg 8开发的基于Web的3DGS渲染器(3d gaussian splatting for three.js. 链接:https://github.com/mkkellogg/GaussianSplats3D, 2025.),该引擎通过异步高斯排序与光栅化并行运行实现渲染。表4中展示了帧率(仅光栅化模式)和排序时间(秒级)数据。针对H3DGS 10模型,我们同时展示了完整模型(τ = 0)和默认配置(τ = 6)。基础版3DGS因高斯计数较低而渲染速度快,但画质较差(参见表1;PSNR值为25.42,而我们的模型达到26.57)。H3DGS在iPhone上因内存限制无法实现实时渲染,而在笔记本电脑上同样存在此问题。值得注意的是,由于屏幕尺寸较小,iPhone 13 Mini在帧率表现上优于iPhone 15 Pro。我们的方法在所有设备上均能高效运行,并在笔记本电脑上取得最佳性能。
补充材料
LOD结构优化步骤 。给定一系列深度阈值 d l d_l dl,从最精细到最粗略层级构建LOD集合 G ( l ) G^{(l)} G(l)。从初始集合 G ( 0 ) G^{(0)} G(0)开始,通过迭代方式逐步增加层级。在第 l l l层时,我们通过对 G ( 0 ) G^{(0)} G(0)中所有高斯函数应用三维平滑滤波器来构建 G ( l ) G^{(l)} G(l)集合。需要特别说明的是,平滑滤波器仅作用于高斯函数本身,其参数保持不变。因此优化过程不会使高斯函数尺寸小于三维滤波器的尺寸。随后,我们使用重要性评分剪枝法对 G ( l ) G^{(l)} G(l)中的所有高斯函数进行筛选,并执行1 000次优化迭代。优化过程沿用前一节所述的LOD渲染流程(最高层级为 l l l),但将深度阈值dl替换为从均匀分布 U ( 0.7 d l , 1.3 d l ) U(0.7d_l,1.3d_l) U(0.7dl,1.3dl)中随机抽取的数值。这种调整使模型对训练轨迹外的相机具有更强鲁棒性。我们沿用标准优化方案中的损失函数(DSSIM+L1),但仅更新Gl集合中高斯函数的参数。整个剪枝与微调过程共重复三次,重要性评分阈值分别为0.2γ、0.6γ和超参数γ。因此,最终需要完成Nlevels·3·1 000次优化迭代。
选择chunk中心。在训练摄像机位置上执行K均值聚类,将场景分割成多个块。聚类数量 N c l u s t e r s N_{clusters} Nclusters设置:
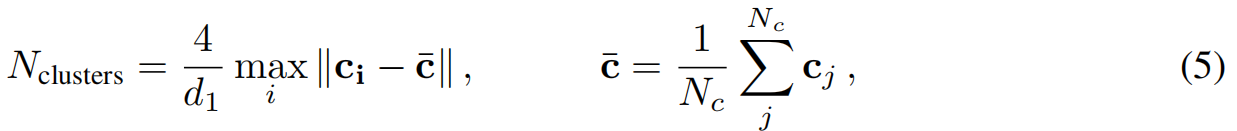
其中 N c N_c Nc是训练相机数量,ci代表相机位置,d1是第一个LOD深度阈值。对于户外场景,这大致对应(根据经验)为5米的聚类尺寸。
#pic_center =50%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏ a b c \sqrt{abc} abc ∑ a b c \sum{abc} ∑abc
/ $$