概述
2025.6.6,通义千问团队发布了 Qwen3-Embedding 和 Qwen3-Reranker 系列。
两组模型一块训练发布,本文侧重于前者进行分析和测试。

开源地址:github.com/QwenLM/Qwen...
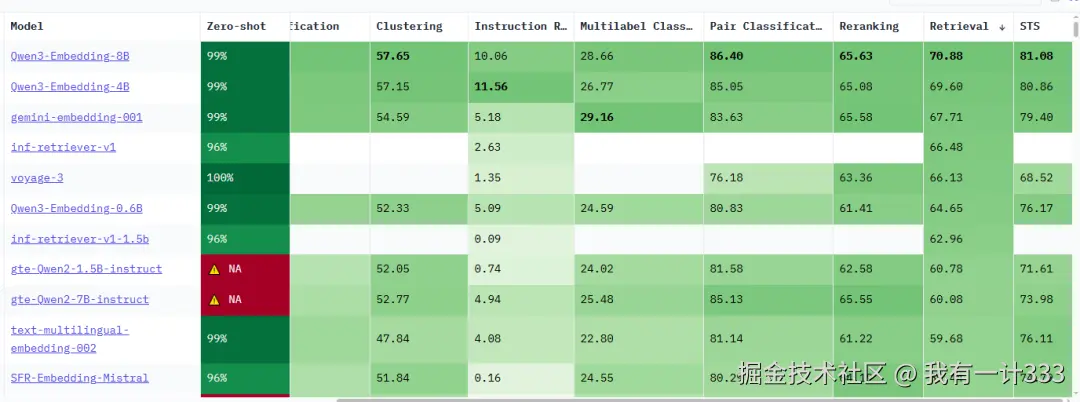
截至目前,在 METB Leaderboard 中,以检索任务(Retrieval)进行排名,Qwen3-Embedding 位居榜首。作为参考,之前常用的 bge-m3 模型排第30位。
技术原理
技术报告:github.com/QwenLM/Qwen...
技术报告标题:Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
看这个标题大概就能猜到,Qwen3-Embedding 取得比较强的结果主要得益于基座模型(Foundation Models),即 Qwen3。
1. 模型结构
Qwen3-Embedding 的模型输入输出如下,报告中,没有具体说明其内部结构,估计和 Qwen3 基座模型本身保持一致。
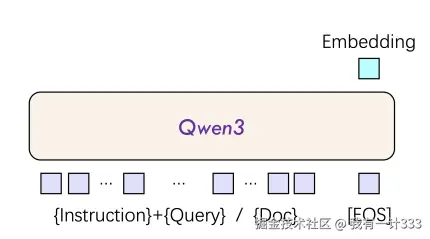
输入包含四部分:
- Instruciton:任务指令,比如"根据查询找到相关文档"
- Query:查询信息,即用户的输入内容,比如"LLM的应用"
- Doc:待评估的文档内容,分成两个两个部分,相关的和不相关的
- EOS:序列结束标记(End-of-Sequence)
2. 训练过程
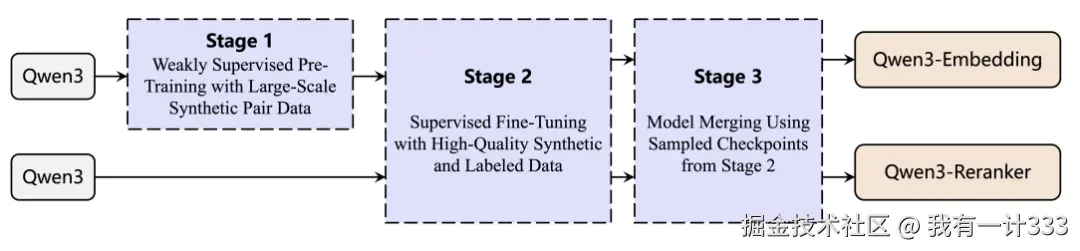
采用三阶段的训练过程:
- 第一阶段:通过Qwen3生成了超大规模(1.5亿)弱监督数据,对模型进行对比学习预训练;
- 第二阶段:基于高质量标注数据进行监督训练(SFT),具体方式是在第一阶段的数据中进行筛选,筛选出1200完对高质量数据。
- 第三阶段:采用了一种基于球面线性插值(slerp, spherical linear interpolation)的模型合并技术,合并在微调过程中保存的多个模型。
3. 模型信息
Qwen3-Embedding系列模型共包括以下三种型号:
- Qwen3-Embedding-0.6B
- Qwen3-Embedding-4B
- Qwen3-Embedding-8B
不同型号模型的具体参数如下表所示。

其中,MRL Support 表示模型能够生成多粒度嵌入向量,即同一文本可以输出不同维度的嵌入表示,保持语义一致性。
Instruction Aware (指令感知)表示模型能够根据用户提供的自然语言指令动态调整其输出或行为,以适应不同的任务需求。
4. 性能评估
在MTEB-Eng(英文),CMTEB(中文),MTEB(代码)三类数据上进行实验,结果如下表所示:
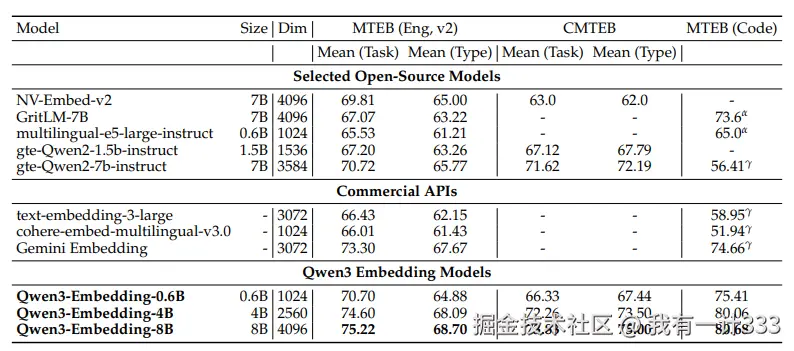
从这张表中,可以读到三点信息:
- 1.同系列模型,参数量越大的嵌入模型分数越高,但 Qwen3-Embedding-0.6B 可以超过其它 7B 参数模型的性能。
- 2.Qwen3-Embedding相比于Qwen2模型(gte-qwen)代码方面大幅提升,中英文提升的不多。
- 3.Qwen3-Embedding-4B 相较于 0.6B,提升较为明显,但 8B 相较于4B,提升效果很小,边际效用递减**。
实验测试
榜单排名靠前就一定代表效果好吗?不一定,主要有两个原因:
- 榜单是多语言的任务的平均水平,Qwen3增强了多语言的能力,但在中文方面的表现未知。
- 榜单的测试集是公开的,非盲测榜单,不能排除新模型对榜单数据进行针对调优。
下面不测榜单,用实际数据进行测试。
1.下载模型
在 modelscope 上下载模型,以下载Qwen3-Embedding-8B为例,下载命令:
css
modelscope download --model Qwen/Qwen3-Embedding-8B --local_dir ./Qwen3-Embedding-8B2. 统计测试
使用 vllm 框架进行推理测试,用AI生成了几个示例数据,核心任务是进行检索,看模型是否能通过相似度,在候选数据中,把最接近原义的句子找出来。
脚本如下:
python
import torch
import vllm
from vllm import LLM
import time
import psutil
import gc
import numpy as np
from typing import List, Dict
import json
# 模型路径配置
models_config = {
"BGE-M3": "/home/zxy/model_zoo/bge-m3",
"Qwen3-0.6B": "/home/zxy/model_zoo/Qwen3-Embedding-0.6B",
"Qwen3-4B": "/home/zxy/model_zoo/Qwen3-Embedding-4B",
"Qwen3-8B": "/home/zxy/model_zoo/Qwen3-Embedding-8B"
}
def get_detailed_instruct(task_description: str, query: str) -> str:
returnf'指令: {task_description}\n查询: {query}'
def prepare_hard_chinese_test_data():
"""准备高难度中文测试数据,包含各种语义陷阱"""
task = '根据给定的搜索查询,检索最相关的段落来回答问题'
# 设计8类挑战性查询
queries = [
# 1. 同音异义词混淆
get_detailed_instruct(task, '银行的利率政策对经济发展的影响'),
# 2. 上下文依赖语义
get_detailed_instruct(task, '苹果公司的创新技术在手机行业的地位'),
# 3. 成语典故理解
get_detailed_instruct(task, '画龙点睛在文学创作中的重要作用'),
# 4. 专业术语跨领域
get_detailed_instruct(task, '神经网络在人工智能和生物学中的不同含义'),
# 5. 近义词细微差别
get_detailed_instruct(task, '学习和求学在教育理念上的区别'),
# 6. 反义关系理解
get_detailed_instruct(task, '保守投资与激进投资策略的根本差异'),
# 7. 隐喻和比喻
get_detailed_instruct(task, '时间是金钱这一理念在现代社会的体现'),
# 8. 语言风格差异
get_detailed_instruct(task, '正式场合发言与日常聊天的表达方式差异'),
]
# 对应的文档包含正确答案和多个干扰项
documents = [
# 正确匹配的文档
"中央银行的货币政策工具主要包括利率调控、存款准备金率等手段,通过调节市场流动性来影响经济增长速度、通胀水平和就业状况。利率作为资金成本的重要指标,其变动直接影响投资决策和消费行为。",
"苹果公司凭借其iOS系统的封闭生态和持续的技术创新,在智能手机市场占据领先地位。从iPhone的工业设计到芯片研发,苹果建立了完整的技术壁垒,影响着整个行业的发展方向。",
"画龙点睛出自唐代传说,指张僧繇画龙后点上眼睛,龙便飞走。在文学创作中,这个成语比喻在关键处用上精辟的笔墨,使整篇作品更加生动传神,是创作技巧中的重要手法。",
"神经网络在计算机科学中是一种模拟生物神经元连接的数学模型,用于机器学习和人工智能;而在生物学中,神经网络是指真实的神经元通过突触连接形成的信息传递系统,负责生物体的感知和控制功能。",
"学习通常指获取知识和技能的过程,强调实用性和效果;而求学更侧重于追求学问的态度和精神,体现了对知识的渴望和探索精神,两者在教育理念上体现了不同的价值取向。",
"保守投资策略注重资本保全,选择低风险、稳定收益的投资品种,追求长期稳健增长;激进投资策略则愿意承担更高风险,追求更大收益,投资于高风险高回报的产品,两者在风险偏好上截然不同。",
"时间是金钱这一理念体现了现代社会对效率的极度重视。在商业活动中,时间成本被量化为经济价值,快节奏的生活方式使得时间管理成为个人和企业成功的关键因素。",
"正式场合的发言需要使用标准的书面语,注重逻辑结构和措辞准确性,避免俚语和方言;而日常聊天更加随意自然,可以使用口语化表达、网络用语和情绪化词汇,体现了语域的不同。",
# 高相似度干扰文档(语义相近但不是最佳答案)
"河岸边的银行大楼里,工作人员正在处理客户的存贷款业务。银行业务的数字化转型正在改变传统金融服务模式,为客户提供更便捷的金融服务体验。",
"超市里新上架的苹果品种丰富,有红富士、金帅等多个品种。这些苹果不仅口感好,营养价值也很高,富含维生素和膳食纤维,是健康饮食的重要组成部分。",
"艺术创作需要技巧和灵感的结合。一幅好的画作不仅需要扎实的绘画功底,更需要创作者在关键位置运用巧妙的手法,使作品达到理想的艺术效果。",
"网络连接在现代信息系统中发挥着重要作用。计算机网络通过各种协议实现数据传输,而生物体内的神经连接则负责信息的感知和处理,两者都体现了连接的重要性。",
"教育的目标是培养人才。无论是学校教育还是自主学习,都要注重知识的积累和能力的提升。现代教育理念强调个性化学习和全面发展。",
"投资理财需要根据个人情况制定合适的策略。不同年龄段和风险承受能力的投资者应该选择不同的投资组合,平衡收益和风险的关系。",
"现代社会生活节奏加快,人们越来越重视效率。合理安排时间,提高工作效率,已经成为现代人必备的生活技能。",
"不同场合需要不同的交流方式。良好的沟通能力包括能够根据场合调整自己的表达方式,既要准确传达信息,又要考虑听众的接受程度。",
# 反义或对立概念的干扰文档
"央行降低利率刺激经济增长,但过度宽松的货币政策可能导致通胀风险,因此政策制定需要在促进增长和控制通胀之间找到平衡点。",
"华为、小米等国产手机品牌正在快速崛起,凭借高性价比和本土化服务优势,在与苹果的竞争中逐渐缩小差距,改变着全球智能手机市场格局。",
"文学创作中的败笔往往出现在细节处理不当,过度雕琢反而会破坏作品的整体美感,有时简单朴素的表达更能打动读者的心。",
# 无关领域文档
"今天的天气特别好,阳光明媚,微风徐徐。这样的天气最适合户外活动,可以去公园散步或者进行体育锻炼,有益身心健康。",
"中医理论认为,人体的健康与阴阳平衡密切相关。通过针灸、中药等传统治疗方法,可以调节人体机能,达到防病治病的目的。",
"烹饪是一门艺术,不同的食材搭配可以创造出丰富多样的美味。中华料理博大精深,各地都有独特的风味和烹饪技巧。"
]
# 正确答案索引(前8个文档对应前8个查询)
correct_matches = [0, 1, 2, 3, 4, 5, 6, 7]
return queries, documents, correct_matches
def get_gpu_memory_usage():
"""获取GPU显存使用情况(GB)"""
if torch.cuda.is_available():
return torch.cuda.memory_allocated() / 1024 / 1024 / 1024
return0
def get_total_gpu_memory():
"""获取GPU总显存(GB)"""
if torch.cuda.is_available():
return torch.cuda.get_device_properties(0).total_memory / 1024 / 1024 / 1024
return0
def calculate_similarity_scores(queries_embeddings, docs_embeddings):
"""计算相似度分数"""
# 标准化向量
queries_embeddings = queries_embeddings / torch.norm(queries_embeddings, dim=1, keepdim=True)
docs_embeddings = docs_embeddings / torch.norm(docs_embeddings, dim=1, keepdim=True)
# 计算余弦相似度
scores = queries_embeddings @ docs_embeddings.T
return scores
def warm_up_model(model, sample_texts: List[str], num_warmup: int = 2):
"""模型预热,排除首次推理的缓存影响"""
print(f"正在进行模型预热({num_warmup}次)...")
for i in range(num_warmup):
_ = model.embed(sample_texts[:2]) # 只用前两个文本预热
print(f"预热 {i+1}/{num_warmup} 完成")
def evaluate_model_performance(model_name: str, model_path: str, queries: List[str], documents: List[str], correct_matches: List[int]) -> Dict:
"""评估单个模型的性能"""
print(f"\n{'='*60}")
print(f"正在测试模型: {model_name}")
print(f"{'='*60}")
# 清理内存
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
# 记录初始显存
initial_memory = get_gpu_memory_usage()
total_memory = get_total_gpu_memory()
try:
# 1. 加载模型
print("正在加载模型...")
load_start_time = time.time()
model = LLM(model=model_path, task="embed")
load_time = time.time() - load_start_time
# 记录加载后显存
after_load_memory = get_gpu_memory_usage()
memory_usage = after_load_memory - initial_memory
memory_usage_percent = (memory_usage / total_memory) * 100if total_memory > 0else0
print(f"✓ 模型加载完成")
print(f" - 加载耗时: {load_time:.2f} 秒")
print(f" - 显存占用: {memory_usage:.2f} GB ({memory_usage_percent:.1f}%)")
# 2. 模型预热
all_texts = queries + documents
warm_up_model(model, all_texts)
# 3. 测试推理速度(多次测试取平均值)
print("\n正在测试推理性能...")
inference_times = []
num_runs = 5
for i in range(num_runs):
gc.collect() # 每次测试前清理内存
start_time = time.time()
outputs = model.embed(all_texts)
inference_time = time.time() - start_time
inference_times.append(inference_time)
# 计算速度指标
texts_per_second = len(all_texts) / inference_time
print(f" 第{i+1}次: {inference_time:.3f}秒 ({texts_per_second:.1f} texts/sec)")
# 计算统计指标
avg_inference_time = np.mean(inference_times)
std_inference_time = np.std(inference_times)
min_inference_time = np.min(inference_times)
max_inference_time = np.max(inference_times)
avg_texts_per_second = len(all_texts) / avg_inference_time
print(f" 平均推理时间: {avg_inference_time:.3f}±{std_inference_time:.3f}秒")
print(f" 处理速度: {avg_texts_per_second:.1f} texts/sec")
# 4. 获取embeddings并计算相似度
print("\n正在计算相似度...")
embeddings = torch.tensor([o.outputs.embedding for o in outputs])
queries_embeddings = embeddings[:len(queries)]
docs_embeddings = embeddings[len(queries):]
# 计算相似度分数
similarity_scores = calculate_similarity_scores(queries_embeddings, docs_embeddings)
# 5. 评估准确性
print("正在评估匹配准确性...")
correct_predictions = 0
similarity_details = []
for i, correct_idx in enumerate(correct_matches):
if i >= len(queries):
break
scores_for_query = similarity_scores[i]
best_match_idx = torch.argmax(scores_for_query).item()
best_score = scores_for_query[best_match_idx].item()
expected_score = scores_for_query[correct_idx].item() if correct_idx < len(scores_for_query) else0
is_correct = best_match_idx == correct_idx
if is_correct:
correct_predictions += 1
similarity_details.append({
'query_idx': i,
'predicted_idx': best_match_idx,
'correct_idx': correct_idx,
'predicted_score': best_score,
'correct_score': expected_score,
'is_correct': is_correct,
'score_diff': best_score - expected_score
})
accuracy = correct_predictions / len(correct_matches) * 100
# 计算其他指标
avg_similarity = torch.mean(similarity_scores).item()
max_similarity = torch.max(similarity_scores).item()
min_similarity = torch.min(similarity_scores).item()
# 计算前k准确率
top3_correct = 0
top5_correct = 0
for i, correct_idx in enumerate(correct_matches):
if i >= len(queries):
break
scores_for_query = similarity_scores[i]
top_indices = torch.topk(scores_for_query, k=min(5, len(scores_for_query)))[1]
if correct_idx in top_indices[:3]:
top3_correct += 1
if correct_idx in top_indices[:5]:
top5_correct += 1
top3_accuracy = top3_correct / len(correct_matches) * 100
top5_accuracy = top5_correct / len(correct_matches) * 100
results = {
'model_name': model_name,
'load_time': load_time,
'memory_usage_gb': memory_usage,
'memory_usage_percent': memory_usage_percent,
'avg_inference_time': avg_inference_time,
'std_inference_time': std_inference_time,
'min_inference_time': min_inference_time,
'max_inference_time': max_inference_time,
'texts_per_second': avg_texts_per_second,
'top1_accuracy': accuracy,
'top3_accuracy': top3_accuracy,
'top5_accuracy': top5_accuracy,
'avg_similarity': avg_similarity,
'max_similarity': max_similarity,
'min_similarity': min_similarity,
'embedding_dim': embeddings.shape[1],
'similarity_details': similarity_details,
'num_parameters': 'Unknown'# 需要额外获取
}
# 6. 显示详细结果
print(f"\n📊 {model_name} 性能报告:")
print(f"{'─' * 50}")
print(f"🔧 模型信息:")
print(f" - 嵌入维度: {embeddings.shape[1]}")
print(f" - 加载时间: {load_time:.2f} 秒")
print(f" - 显存占用: {memory_usage:.2f} GB ({memory_usage_percent:.1f}%)")
print(f"\n⚡ 推理性能:")
print(f" - 平均推理时间: {avg_inference_time:.3f}±{std_inference_time:.3f} 秒")
print(f" - 最快推理时间: {min_inference_time:.3f} 秒")
print(f" - 处理速度: {avg_texts_per_second:.1f} texts/sec")
print(f"\n🎯 准确性指标:")
print(f" - Top-1 准确率: {accuracy:.1f}%")
print(f" - Top-3 准确率: {top3_accuracy:.1f}%")
print(f" - Top-5 准确率: {top5_accuracy:.1f}%")
print(f"\n📈 相似度统计:")
print(f" - 平均相似度: {avg_similarity:.4f}")
print(f" - 最高相似度: {max_similarity:.4f}")
print(f" - 最低相似度: {min_similarity:.4f}")
print(f"\n🔍 详细匹配分析:")
query_categories = [
"同音异义词", "上下文依赖", "成语典故", "专业术语",
"近义词差别", "反义关系", "隐喻比喻", "语言风格"
]
for detail in similarity_details:
status = "✅"if detail['is_correct'] else"❌"
category = query_categories[detail['query_idx']] if detail['query_idx'] < len(query_categories) elsef"Q{detail['query_idx']}"
print(f" {status} {category}: 预测D{detail['predicted_idx']} "
f"(分数:{detail['predicted_score']:.4f}) vs 正确D{detail['correct_idx']} "
f"(分数:{detail['correct_score']:.4f}) 差值:{detail['score_diff']:.4f}")
return results
except Exception as e:
print(f"❌ 模型 {model_name} 测试失败: {str(e)}")
returnNone
finally:
# 清理内存
if'model'in locals():
del model
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
def print_comparison_table(all_results: List[Dict]):
"""打印对比表格"""
ifnot all_results:
return
print(f"\n{'='*80}")
print("🏆 模型性能对比总结")
print(f"{'='*80}")
# 表头
print(f"{'模型':<15} {'显存(GB)':<10} {'加载(s)':<8} {'推理(s)':<10} {'速度(t/s)':<10} {'Top-1%':<8} {'Top-3%':<8} {'维度':<8}")
print(f"{'-'*80}")
# 数据行
for result in all_results:
print(f"{result['model_name']:<15} "
f"{result['memory_usage_gb']:<10.2f} "
f"{result['load_time']:<8.2f} "
f"{result['avg_inference_time']:<10.3f} "
f"{result['texts_per_second']:<10.1f} "
f"{result['top1_accuracy']:<8.1f} "
f"{result['top3_accuracy']:<8.1f} "
f"{result['embedding_dim']:<8}")
print(f"{'-'*80}")
# 性能排名
print(f"\n🥇 性能排名:")
# 按不同指标排序
metrics = [
('速度最快', 'texts_per_second', True),
('显存最少', 'memory_usage_gb', False),
('最准确', 'top1_accuracy', True),
('加载最快', 'load_time', False)
]
for metric_name, metric_key, descending in metrics:
sorted_results = sorted(all_results, key=lambda x: x[metric_key], reverse=descending)
print(f" {metric_name}: {sorted_results[0]['model_name']} ({sorted_results[0][metric_key]:.2f})")
# 分析难点
print(f"\n🔍 难点分析:")
categories = ["同音异义词", "上下文依赖", "成语典故", "专业术语", "近义词差别", "反义关系", "隐喻比喻", "语言风格"]
for i, category in enumerate(categories):
category_correct = sum(1for result in all_results
for detail in result['similarity_details']
if detail['query_idx'] == i and detail['is_correct'])
total_models = len(all_results)
success_rate = category_correct / total_models * 100if total_models > 0else0
difficulty = "🔴困难"if success_rate < 30else"🟡中等"if success_rate < 70else"🟢简单"
print(f" {category}: {success_rate:.1f}% {difficulty}")
def main():
"""主函数"""
print("🚀 高难度中文语义理解模型对比测试")
print(f"PyTorch版本: {torch.__version__}")
print(f"vLLM版本: {vllm.__version__}")
print(f"CUDA可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU设备: {torch.cuda.get_device_name()}")
print(f"GPU总显存: {get_total_gpu_memory():.1f} GB")
# 准备高难度测试数据
queries, documents, correct_matches = prepare_hard_chinese_test_data()
print(f"\n📋 测试数据信息:")
print(f"- 查询数量: {len(queries)}")
print(f"- 文档数量: {len(documents)}")
print(f"- 正确匹配数量: {len(correct_matches)}")
print(f"- 测试难度: 极高 (包含8类语义挑战)")
print(f"- 挑战类型: 同音异义词、上下文依赖、成语典故、专业术语、近义词差别、反义关系、隐喻比喻、语言风格")
# 存储所有模型的结果
all_results = []
# 测试每个模型
for model_name, model_path in models_config.items():
result = evaluate_model_performance(model_name, model_path, queries, documents, correct_matches)
if result:
all_results.append(result)
# 每个模型测试完后等待一下
time.sleep(2)
# 显示对比结果
if all_results:
print_comparison_table(all_results)
print(f"\n💡 优化建议:")
print(f"- 如果准确率普遍较低,说明这些语义挑战确实有效")
print(f"- 可以针对表现差的类别进行专门的数据增强")
print(f"- Top-3和Top-5准确率可以看出模型的召回能力")
print(f"- 显存和速度数据有助于生产环境部署决策")
print(f"\n✅ 高难度测试完成!")
if __name__ == "__main__":
main()比较四个模型,结果如下:
| 模型 | 显存(GB) | 推理(s) | 速度(t/s) | Top-1% | Top-3% | 维度 |
|---|---|---|---|---|---|---|
| BGE-M3 | 1.06 | 0.020 | 1496.5 | 100.0 | 100.0 | 1024 |
| Qwen3-0.6B | 1.12 | 0.019 | 1611.4 | 87.5 | 100.0 | 1024 |
| Qwen3-4B | 7.55 | 0.073 | 412.0 | 87.5 | 100.0 | 2560 |
| Qwen3-8B | 14.10 | 0.122 | 246.0 | 100.0 | 100.0 | 4096 |
结果说明,bge-m3在以上中文常见场景中,性能已足够使用,模型参数量越大,显存占用越多,速度越慢,结果不一定会更好。
因此,盯着榜单去下结论是草率的,实际的模型性能需要根据语言、任务、使用场景进行具体判断。当然,本测试用的数据比较少,结果存在偶然性,有进一步讨论空间。