🚀 DeepSeek:中国AI推理领域的破局者与开源革命引领者
------ 重新定义大模型的效率与深度思考
2025年,全球大模型竞技场迎来一位颠覆者:DeepSeek。它用"极致推理"打破技术壁垒,以"开放生态"重塑行业规则,更以"国产算力"宣告中国AI的独立突围。
🔍 一、DeepSeek是谁?
中国AI初创公司"深度求索"(DeepSeek)成立于2023年,仅用两年时间便凭借 DeepSeek-V3 和 DeepSeek-R1 两大王牌模型跻身全球顶级AI阵营。其定位鲜明:
- V3:通用高效型 ------面向日常对话、长文本生成、多语言翻译等场景,以 混合专家架构(MoE) 实现低成本、高吞吐(API成本仅$0.14/百万token);
- R1:推理专家型 ------专注数学、代码、逻辑等复杂任务,首创 "思维链(CoT)"输出 ,在AIME数学竞赛准确率达 87.5%(2025年新版),逼近OpenAI o1与Google Gemini 2.5 Pro。
📊 二、DeepSeek 与主流模型对比总结(截至2025年7月)
🧠 性能表现
- 编码与调试能力
DeepSeek R1 在 Codeforces 编程任务中表现优异(96.3 百分位),调试准确率 90%,超过 GPT‑o1 的 80% 和 Claude Sonnet 的 75% (Bind AI IDE)。
ArXiv 比较显示 DeepSeek‑R1 在多数分类与推理任务上优于 Gemini、GPT 与 LLaMA,但略逊于 Claude (arXiv)。 - 数学与推理水平
Elephas.blog 报告 DeepSeek 在 MATH‑500 测试中得分 90.2%,远高于 Claude 的 78.3% (elephas.app)。
Bentoml 资料指出,R1 的 MMLU 约为 0.849,智力指数指数为 68 (人工分析)。 - 与 GPT o1 & Gemini 对比
在 Hugging Face、PromptHub 以及 Medium 上,R1 的数学、逻辑和代码能力全面接近或略优于 GPT‑o1,部分评测甚至超越 Gemini 2.5 Pro (Medium)。
⚙️ 模型效率 & 成本优势
- 训练成本
Wikipedia 页面指出 DeepSeek-V3(R1 的基础)训练成本仅为 ~600 万美元,相对 OpenAI GPT‑4 的 1 亿美元成本低近 10 倍 (维基百科)。 - 推理与 API 成本
Bentoml 报告 R1 约 0.96 美元 /百万 token,DeepSeek 输入成本 ~0.55 /M,输出 2.19/M,而 GPT‑o1 为 15 USD,Claude Sonnet 为 3 USD (BentoML, 人工分析)。 - 开源授权与部署自由度
DeepSeek 模型开源(MIT 许可),可本地部署,较 GPT、Claude 完全免费而灵活 (维基百科)。
🌍 实际应用场景与社区反馈
- 社区测试显示 DeepSeek v3/vR1 性能优于 GPT-4o、Claude 在推理和数学任务上,但在大型项目编码上还有提升空间 (Reddit)。
- 临床应用研究(Nature 等学术论文)表明 DeepSeek‑R1 与 GPT‑4o 在医学决策支持上性能相当,但在安全与偏见方面仍需改进 (Nature)。
截至2025年7月20日,DeepSeek-R1的最新版本为DeepSeek-R1-0528,该版本于2025年5月28日正式发布,并于5月29日全面开放使用。以下是关于该版本的详细升级亮点与功能总结:
🔍 三、DeepSeek-R1-0528
- 版本号:DeepSeek-R1-0528
- 发布时间:2025年5月28日(小版本升级)
- 基座模型 :基于2024年12月发布的DeepSeek V3 Base模型,但通过增强后训练算力显著优化推理能力。
- 开源性质:仍为开源模型,支持128K上下文长度(需通过第三方平台调用),官方渠道默认上下文为64K。
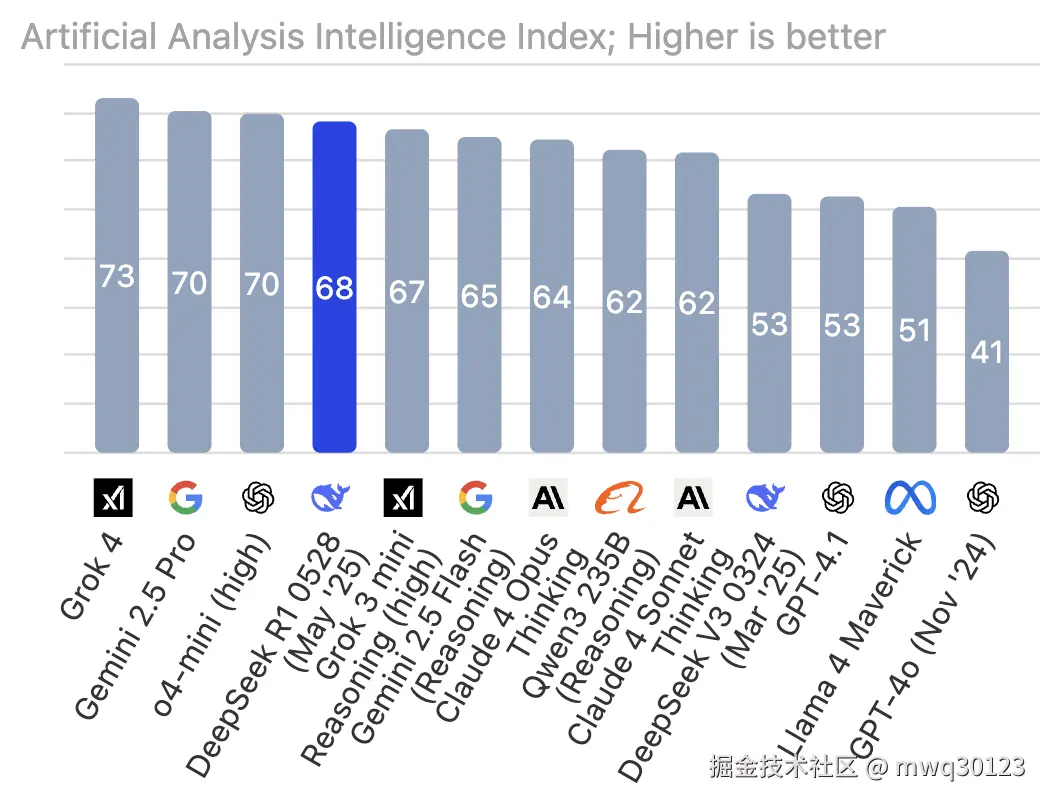
1. 推理能力显著跃升
- 数学与逻辑突破 :
- 在AIME 2025测试中,准确率从旧版70% 提升至 87.5%(接近OpenAI o1-high水平)。
- 解题思维深度增强:平均每题消耗token从12K增至23K,支持更复杂推理链条。
- 编程能力优化 :
- 在Live CodeBench等平台表现媲美OpenAI o3模型,代码生成逻辑更严谨。
2. 幻觉率大幅降低
- 在摘要、改写、阅读理解等任务中,幻觉率降低45%-50%,输出更可靠。
3. 创意写作能力增强
- 针对议论文、小说、散文等文体优化,可生成结构更完整、篇幅更长(万字级)且更贴近人类风格的内容。
4. 生态扩展:模型蒸馏与小模型突破
- 基于R1-0528的思维链蒸馏训练出小模型 DeepSeek-R1-0528-Qwen3-8B,性能超越原Qwen3-8B达10%,甚至媲美Qwen3-235B。
5. 新旧版本性能对比(关键指标)
| 能力维度 | 旧版R1 | 新版R1-0528 | 提升幅度 |
|---|---|---|---|
| 数学推理(AIME) | 70%准确率 | 87.5%准确率 | ↑17.5% |
| 单题思考深度 | 平均12K tokens | 平均23K tokens | ↑91.7% |
| 幻觉率 | 较高 | 降低45%-50% | 可靠性显著增强 |
| 长文本生成 | 结构较松散 | 结构完整、人类偏好强 | 内容质量大幅优化 |
DeepSeek-R1-0528 是当前国产开源模型中推理能力最强的版本之一,特别适合:
- 🔬 科研/教育:数学竞赛、代码生成、学术论文分析;
- 📊 企业场景:金融量化、法律合同摘要、长报告撰写;
- 💻 开发者:通过开源模型蒸馏训练行业小模型。
🏆 四、行业影响:落地场景与用户选择
据PPIO平台2025上半年数据,DeepSeek与阿里Qwen共同占据国内开源模型 90%+调用量:
| 模型 | 适用场景 | 用户占比 | 代表案例 |
|---|---|---|---|
| DeepSeek-V3 | 文案生成、客服、多语翻译 | 全平台60%+ | 美妆品牌文案点击率↑32% |
| DeepSeek-R1 | 数学竞赛、金融量化、代码生成 | 科研/教育领域 | 量化策略回报率↑18% |
用户真实反馈:
- "R1解数学题像学霸附体,代码能力碾压Qwen3!"
- "V3生成万字报告仅需同类1/3时间,成本直降40%。"
🔮 五、未来展望:R2多模态与"全民AI"普惠
DeepSeek下一代模型 R2 已蓄势待发,将实现三大跃迁:
- 跨模态深度推理:支持文本+图像+视频联合分析(如家电故障视频→维修方案);
- 自驱动学习框架:融合生成式奖励建模(GRM)与自原则批判调优,训练成本再降40%;
- 硬件无感部署:模型压缩至终端可运行(如手机、汽车、护理机器人),走进千家万户。
斯坦福教授李飞飞评价:
"DeepSeek-R2有望成为负责任的多模态推理标杆------不仅高精度,更要可解释、无偏见。"
💎 结语:DeepSeek重新定义AI价值
当硅谷巨头还在追逐千亿参数军备竞赛时,DeepSeek用"效率革命+开源平权"证明:
"以小搏大"可撼动全球AI霸权,"技术普惠"才是智能未来的终极答案。
无论是开发者、企业,还是教育科研机构,DeepSeek正以开放之姿,邀请世界共建下一代智能生态。而这场由中国力量主导的技术突围,才刚刚开始。
延伸阅读:
- DeepSeek V3 vs R1:大模型之争,谁才是你的最佳AI伙伴?
- 黄仁勋盛赞国产开源大模型:DeepSeek与通义千问如何比肩GPT-4?
- DeepSeek R1 最新版本模型,排名第三🥉
- DeepSeek与ChatGPT的全面对比
- 商汤与DeepSeek在2025年最新大模型评测并列第一
- 深度对比|DeepSeek与ChatGPT,谁才是AI大模型的新王者?
本文基于2025年7月公开技术资料撰写。
可通过官网或腾讯系产品免费体验升级版能力,感受深度思考的进化! 🚀