文章目录
- 一、监督学习
-
- [1.1 什么是监督学习](#1.1 什么是监督学习)
- [1.2 监督学习的应用实例](#1.2 监督学习的应用实例)
- [1.3 监督学习的两种类型](#1.3 监督学习的两种类型)
-
- [1.3.1 回归 (Regression)](#1.3.1 回归 (Regression))
- [1.3.2 分类 (Classification)](#1.3.2 分类 (Classification))
- [1.4 总结](#1.4 总结)
- 二、无监督学习
-
- [2.1 监督学习 vs 无监督学习](#2.1 监督学习 vs 无监督学习)
- [2.2 聚类 (Clustering)](#2.2 聚类 (Clustering))
-
- [2.2.3 聚类的应用实例](#2.2.3 聚类的应用实例)
- [2.3 其他无监督学习算法](#2.3 其他无监督学习算法)
- [2.4 小结与思考](#2.4 小结与思考)
- 三、线性回归模型
-
- [3.1 回顾:什么是回归问题](#3.1 回顾:什么是回归问题)
- [3.2 模型的专业术语](#3.2 模型的专业术语)
- [3.3 模型的表示 (Model Representation)](#3.3 模型的表示 (Model Representation))
- [3.4 总结](#3.4 总结)
- 四、代价函数:如何衡量模型的好坏
-
- [4.1 理解模型的参数 w 和 b](#4.1 理解模型的参数 w 和 b)
- [4.2 定义代价函数 J(w, b)](#4.2 定义代价函数 J(w, b))
- [4.3 直观理解代价函数](#4.3 直观理解代价函数)
-
- [4.3.1 简化情况:b = 0](#4.3.1 简化情况:b = 0)
- [4.3.2 一般情况:`w` 和 `b`](#4.3.2 一般情况:
w和b) - [4.3.3 可视化工具:等高线图 (Contour Plot)](#4.3.3 可视化工具:等高线图 (Contour Plot))
视频链接
吴恩达机器学习p1-p9
一、监督学习
1.1 什么是监督学习
什么是监督学习(Supervised learning)呢?
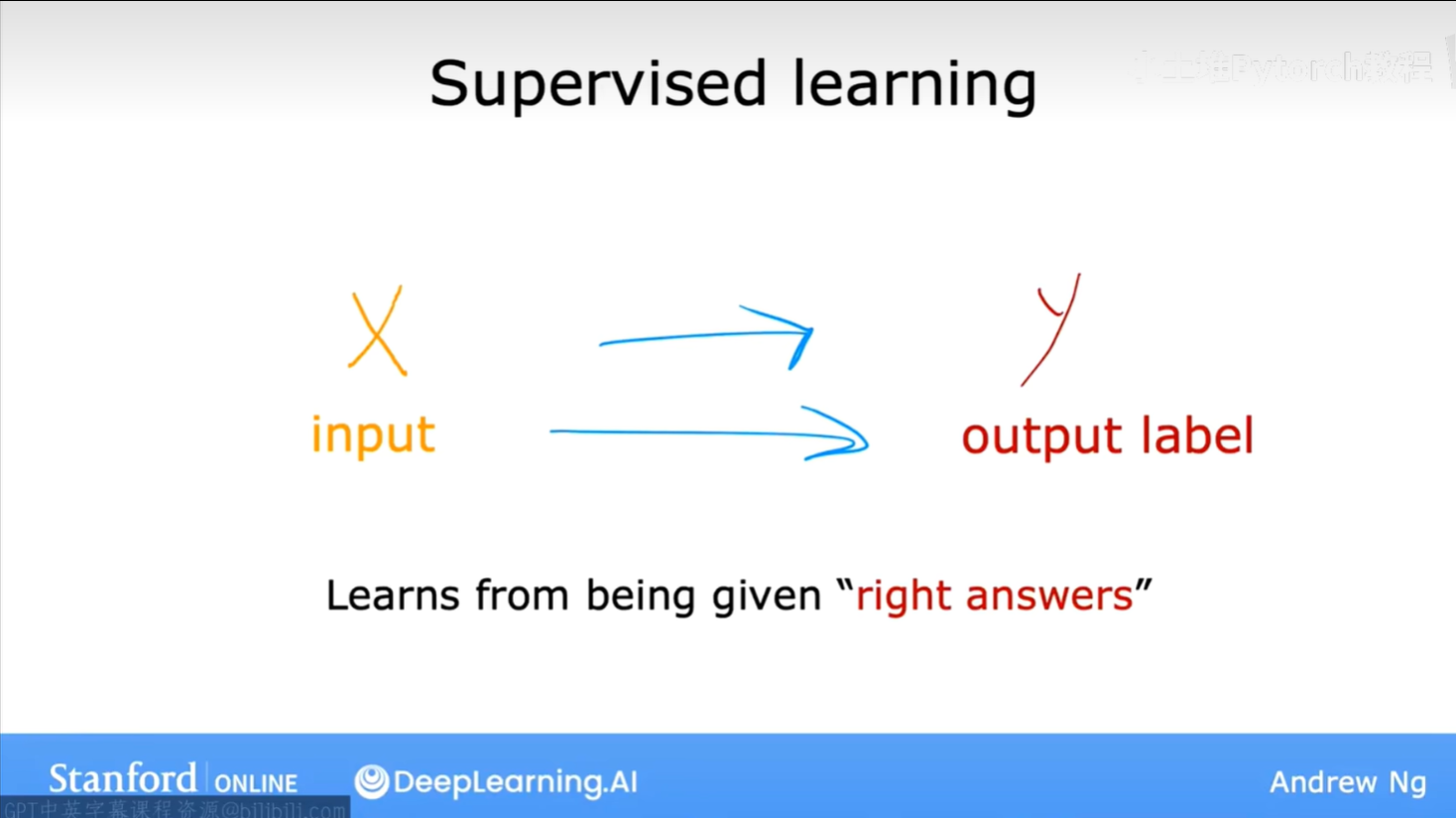
简单来说,监督学习就是我们给算法一个数据集,其中包含了"正确答案"。算法的任务就是学习输入与输出之间的映射关系,以便对新的、未知的数据进行预测。
就像下图展示的,我们有输入(X),通过某种学习算法,映射到输出标签(Y)。整个过程的核心思想是,我们通过提供一系列带有"正确答案"的样本来"监督"算法进行学习。
1.2 监督学习的应用实例
监督学习在现实世界中有着非常广泛的应用。吴恩达老师在课程中也为我们列举了很多生动的例子:
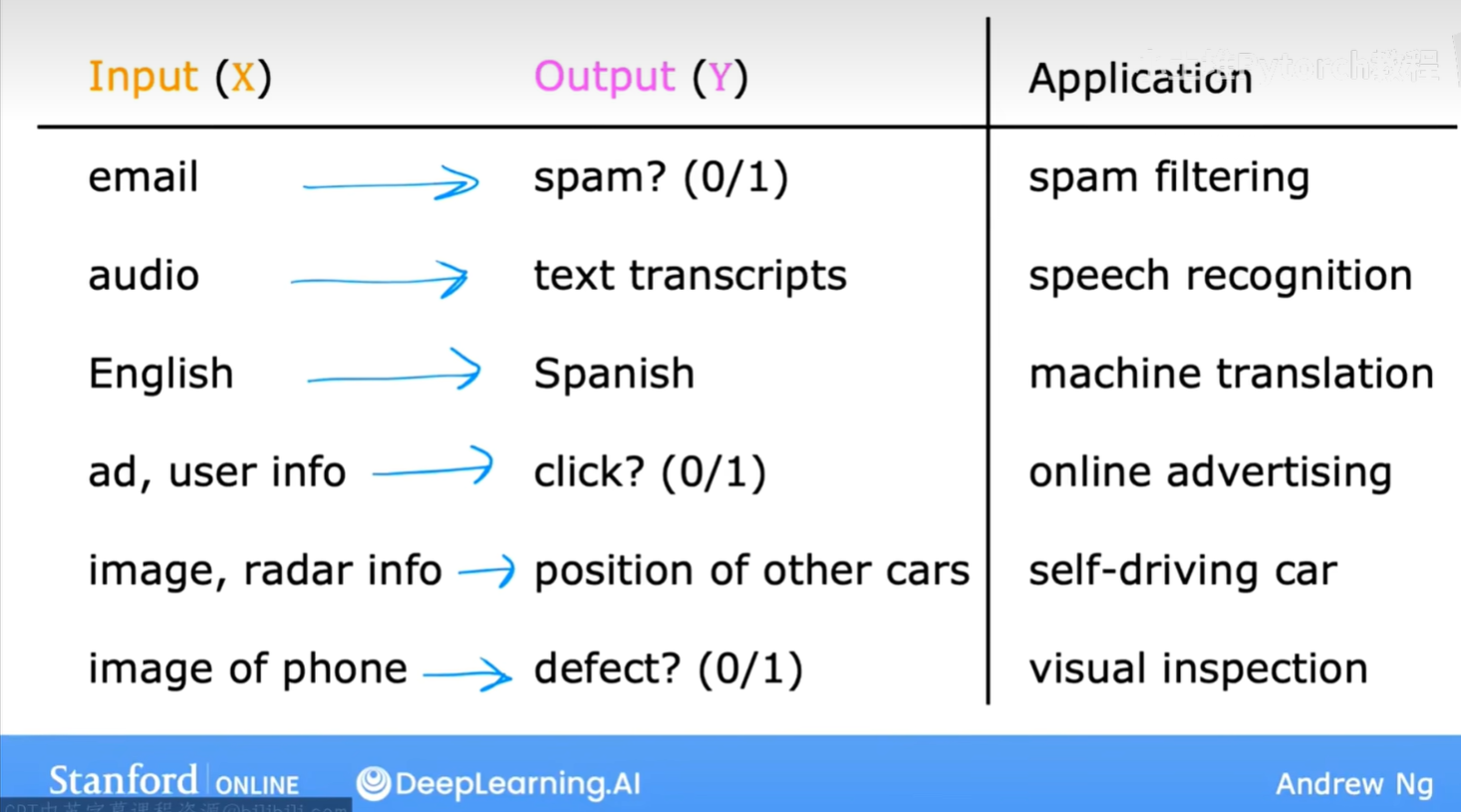
从上图中我们可以看到:
- 垃圾邮件过滤 (Spam filtering):输入是邮件内容,输出是判断这封邮件是否为垃圾邮件(通常用0/1表示)。
- 语音识别 (Speech recognition):输入是音频片段,输出是对应的文字记录。
- 机器翻译 (Machine translation):输入是一种语言的文本(比如英语),输出是另一种语言的文本(比如西班牙语)。
- 在线广告 (Online advertising):输入是广告信息和用户信息,输出是用户是否会点击这个广告(0/1)。
- 自动驾驶 (Self-driving car):输入是汽车的图像、雷达信息等,输出是路面上其他车辆的位置。
- 视觉检测 (Visual inspection):输入是产品的图片(比如手机),输出是判断产品是否存在缺陷(0/1)。
这些例子都遵循着从输入X到输出Y的模式,并且都是通过学习大量已知答案的数据集来实现的。
1.3 监督学习的两种类型
在监督学习内部,我们通常会根据输出(Y)的类型,将其分为两大类:回归(Regression) 和 分类(Classification)。
1.3.1 回归 (Regression)
当我们要预测一个连续的数值时,这类问题就被称为回归问题。
最经典的例子就是房价预测。如下图所示,我们可以根据房屋的面积(House size)来预测其价格(Price)。在这个例子中,价格是一个连续变化的数值,理论上可以有无限多种可能的输出。
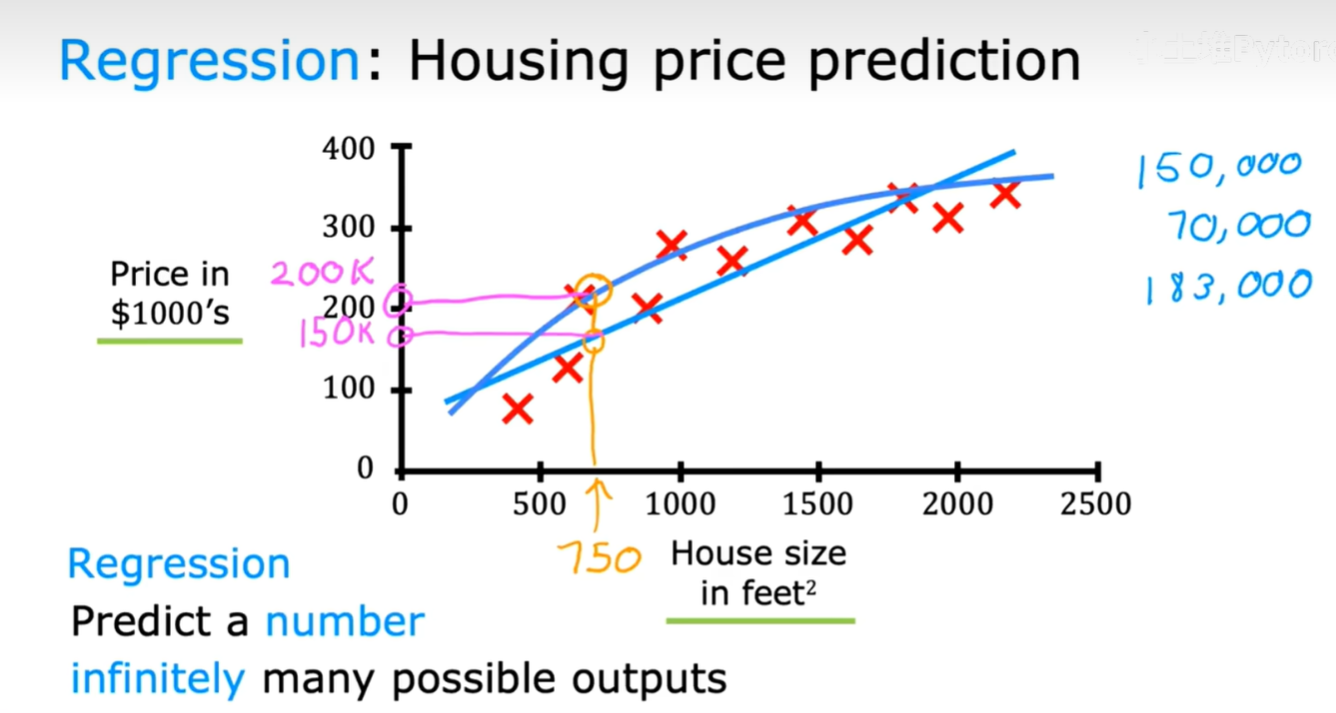
我们的模型(图中的直线或曲线)会尝试去拟合这些数据点。当我们有一个新的输入(比如房屋面积为750平方英尺),模型就能给出一个预测的价格(比如15万美元)。这就是一个典型的回归问题,其目标是预测一个数字。
1.3.2 分类 (Classification)
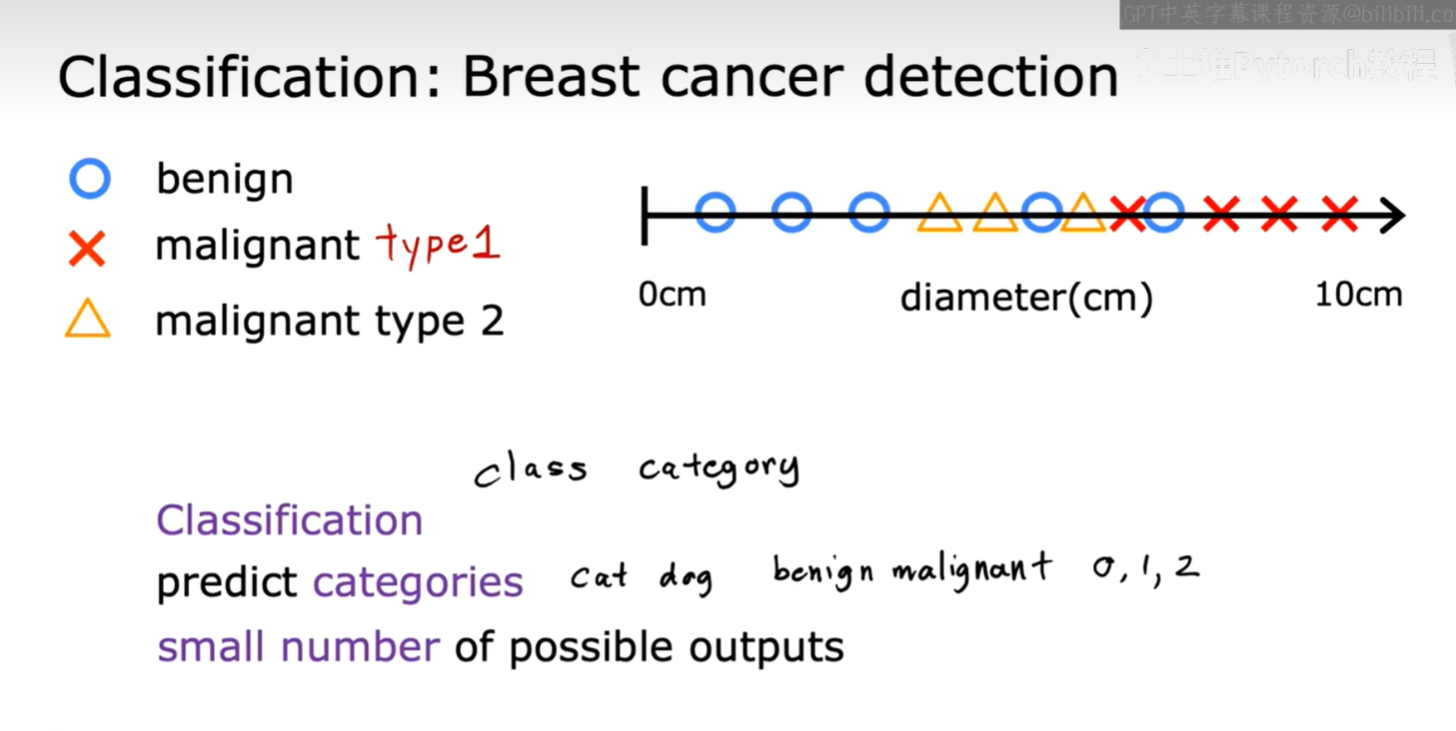
与回归不同,当我们要预测的输出是一个离散的、有限的类别时,这类问题被称为分类问题。
课程中以乳腺癌检测为例。如下图所示,我们根据肿瘤的大小(Tumor size)来判断它是良性的(benign)还是恶性的(malignant)。这里的输出只有两个明确的类别(良性/恶性),我们可以用0和1来代表。
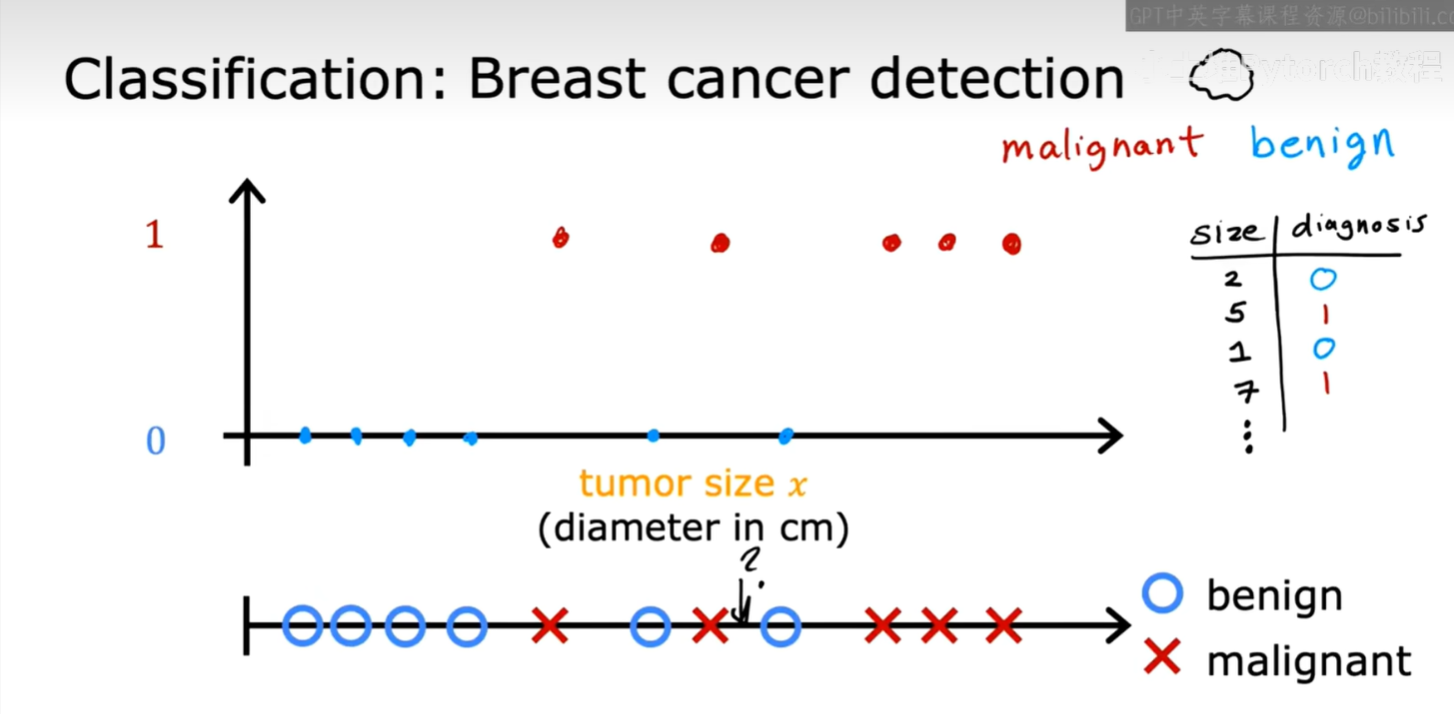
分类问题的目标是预测一个类别。这个类别可以是两个(比如良性/恶性),也可以是多个。
例如,在乳腺癌检测中,我们甚至可以有更细分的类别,比如良性、恶性1型、恶性2型。这些都是离散的、数量有限的输出。
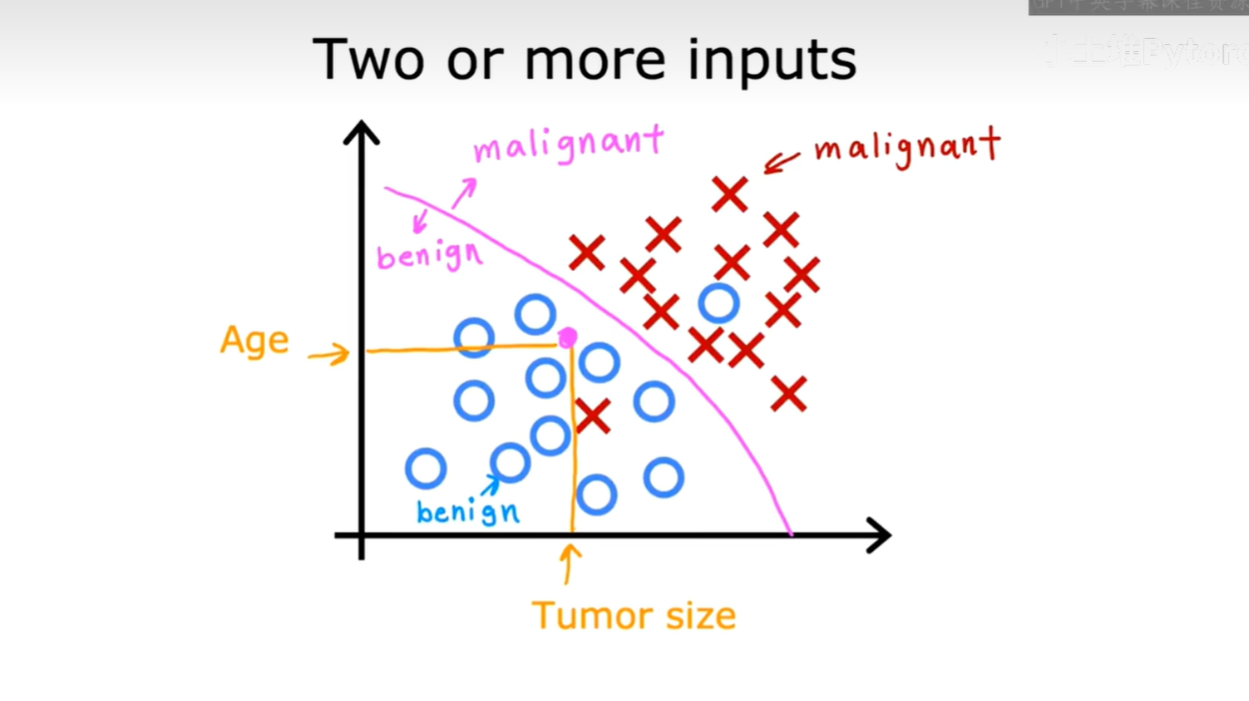
当我们的数据有多个特征(输入)时,分类模型会尝试找到一个决策边界,来区分不同的类别。如下图所示,我们可以同时根据"年龄(Age)"和"肿瘤大小(Tumor size)"这两个特征来判断肿瘤的性质。图中那条紫色的曲线就是一个决策边界的例子,它能够将良性肿瘤(蓝圈)和恶性肿瘤(红叉)区分开来。
1.4 总结
好了,今天我们初步认识了监督学习,总结一下核心要点:
- 监督学习:通过带有"正确答案"的数据集进行学习,让机器找到从输入X到输出Y的最佳映射关系。
- 回归:预测一个连续的数值,例如房价、气温。
- 分类:预测一个离散的类别,例如邮件是否是垃圾邮件、肿瘤是良性还是恶性。
二、无监督学习
上一节我们讨论了监督学习,其核心是使用带有明确"正确答案"的数据进行训练。然而,在很多现实场景中,我们拥有的数据并没有标签。这时,就轮到无监督学习(Unsupervised Learning)大显身手了。
2.1 监督学习 vs 无监督学习
让我们再次直观地对比一下这两种学习方式。
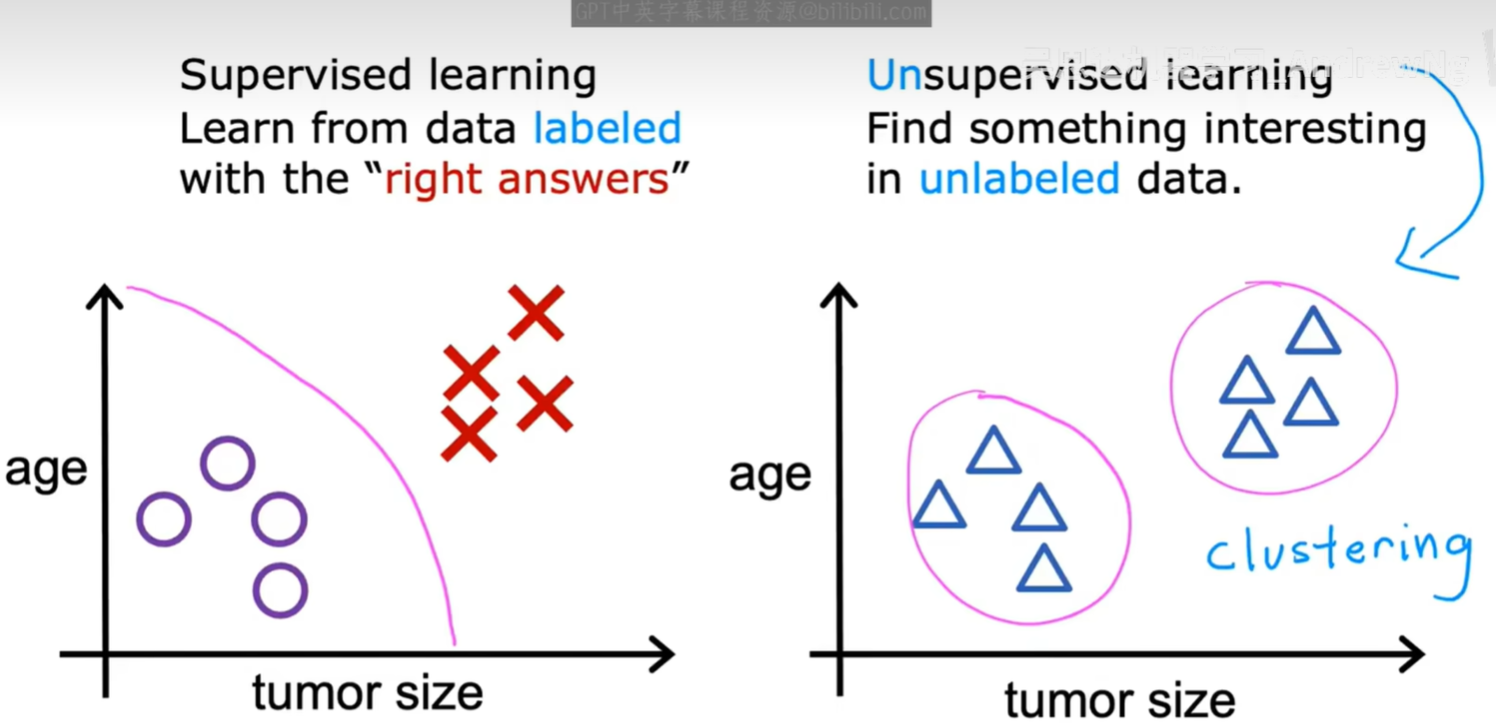
- 监督学习 (Supervised learning) :处理的是有标签 (labeled) 的数据。就像左图所示,我们提前为数据点标记好了类别(紫色圆圈和红色叉),算法的目标是学习如何区分它们,并画出一条决策边界。
- 无监督学习 (Unsupervised learning) :处理的是无标签 (unlabeled) 的数据。如右图所示,我们只有一堆数据点,没有任何关于它们类别的信息。算法的目标是在这些数据中自主地发现有趣的结构或模式。最常见的任务之一就是将数据分成不同的簇(cluster),这个过程也叫做聚类 (Clustering)。
简单来说,无监督学习的数据只有输入X,没有输出标签Y。算法必须靠自己去数据中寻找内在的结构。
2.2 聚类 (Clustering)
聚类是无监督学习中最核心、最广泛应用的技术之一。它的目标是将相似的数据点归到同一个组(或簇)里。
2.2.3 聚类的应用实例
吴恩达老师在课程中列举了几个非常经典的聚类应用:
-
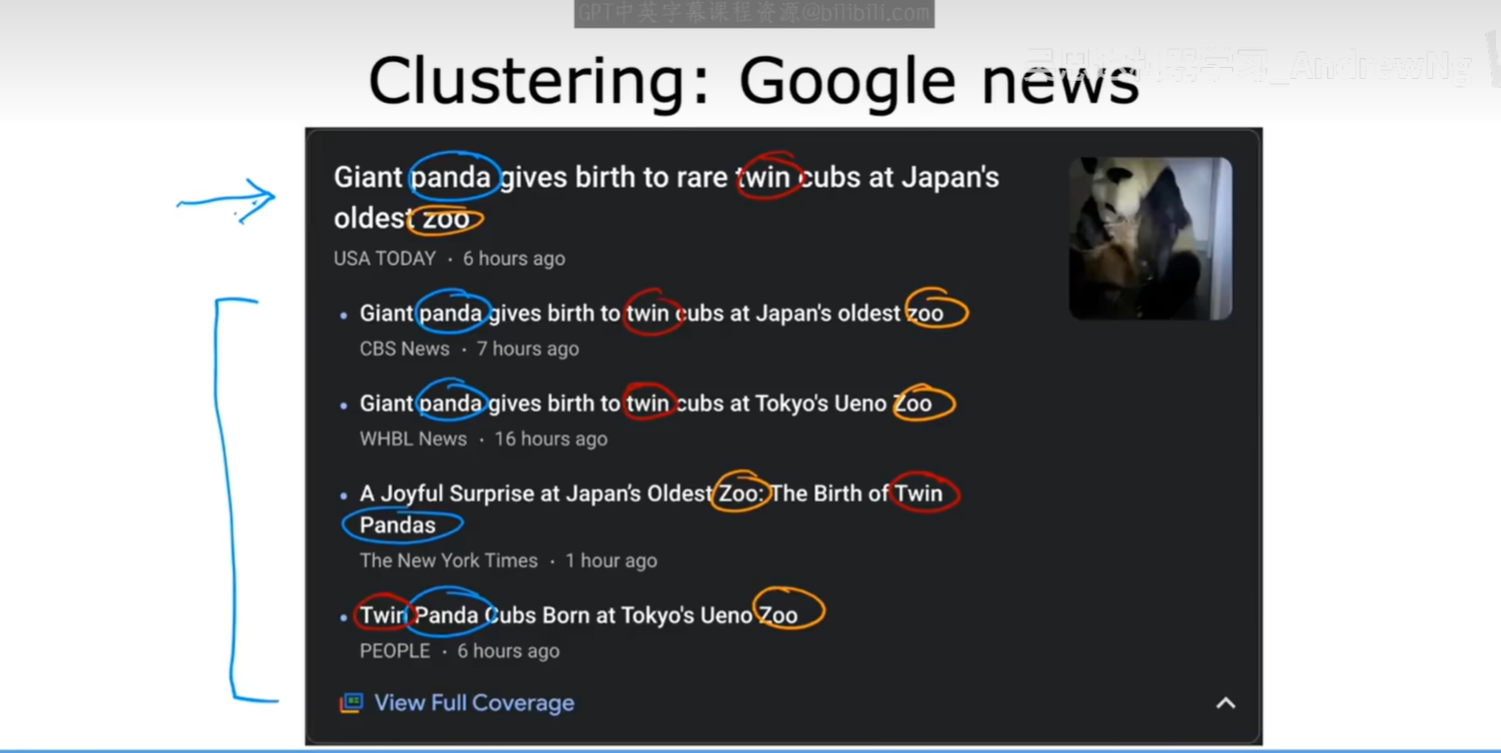
谷歌新闻 (Google News)
每天,互联网上都会涌现出成千上万篇关于同一事件的新闻报道。谷歌新闻的一个核心功能就是自动将这些报道聚合在一起,形成一个新闻专题。这就是一个典型的聚类应用:算法自动分析文章内容,将讲述同一个故事的文章聚集到一起。
-
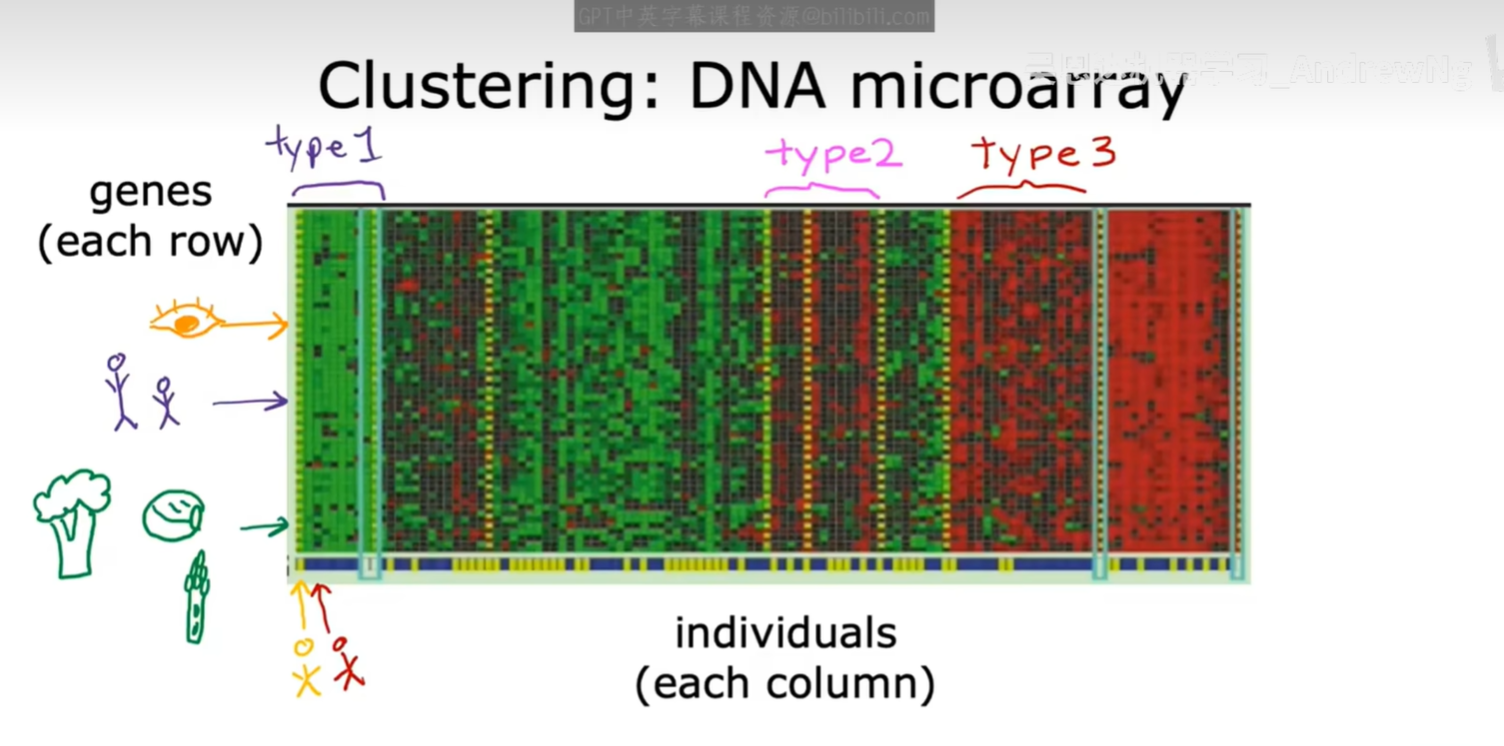
基因芯片 (DNA Microarray)
在生物信息学领域,研究人员可以使用基因芯片技术测量成千上万个基因在不同个体中的表达水平。通过聚类算法,我们可以根据基因表达的相似性将不同的个体进行分组,这可能帮助我们识别出不同的疾病亚型或发现具有特定生物学意义的基因模式。
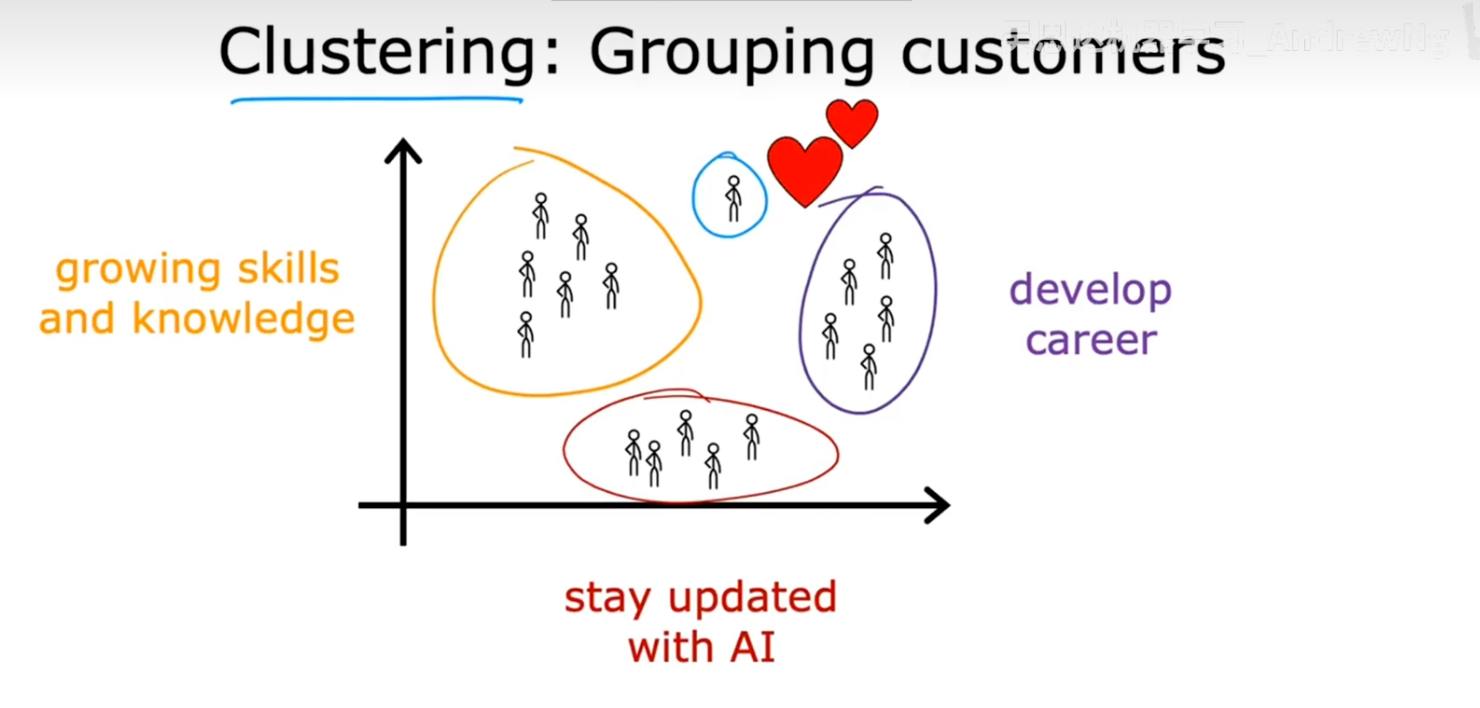
- 客户细分 (Grouping Customers)
在市场营销中,企业拥有大量的客户数据。通过对这些数据进行聚类,可以将客户分成不同的细分市场(Market Segments)。例如,可以根据用户的学习行为、兴趣偏好等,将他们分为"追求技能提升"、"关注职业发展"或"希望了解AI前沿"等不同群体,从而为不同群体提供更加个性化的服务和产品推荐。
2.3 其他无监督学习算法
除了聚类,无监督学习还包含其他一些重要的算法类型,例如:

- 降维 (Dimensionality reduction):在保留数据最重要特征的前提下,减少数据的变量个数(维度)。
- 异常检测 (Anomaly detection):从数据中识别出那些与正常数据模式显著不同的"异常点"或"离群点"。
我们会在后续的课程中对这些算法进行更详细的探讨。
2.4 小结与思考
为了检验大家是否理解了监督学习与无监督学习的区别,可以看看下面这个小问题:
问题:在下列的例子中,哪些适合使用无监督学习算法来解决?

- A: 给定一批已标记为"垃圾邮件"或"非垃圾邮件"的邮件,学习一个垃圾邮件过滤器。
- B: 从网络上获取大量新闻文章,将关于同一个故事的文章分组。
- C: 给定一个客户数据库,自动发现不同的市场细分并对客户进行分组。
- D: 给定一个已诊断为"患糖尿病"或"未患糖尿病"的患者数据集,学习如何对新患者进行分类。
答案解析:
- A 和 D 属于监督学习。因为它们的数据集都带有明确的标签("垃圾邮件/非垃圾邮件","患病/未患病"),我们的目标是学习一个分类器。
- B 和 C 属于无监督学习。在这两个场景中,我们没有预先定义的标签。我们的目标是从数据本身发现结构,无论是将新闻分组(B),还是将客户分群(C),都属于聚类的范畴。
三、线性回归模型
在前面的内容中,我们已经知道,像房价预测这类问题属于监督学习 中的回归问题。现在,让我们深入探讨如何构建一个模型来解决这类问题。我们将从最基础的线性回归(Linear Regression模型开始。
3.1 回顾:什么是回归问题
我们再来看一下这张熟悉的房价预测图。
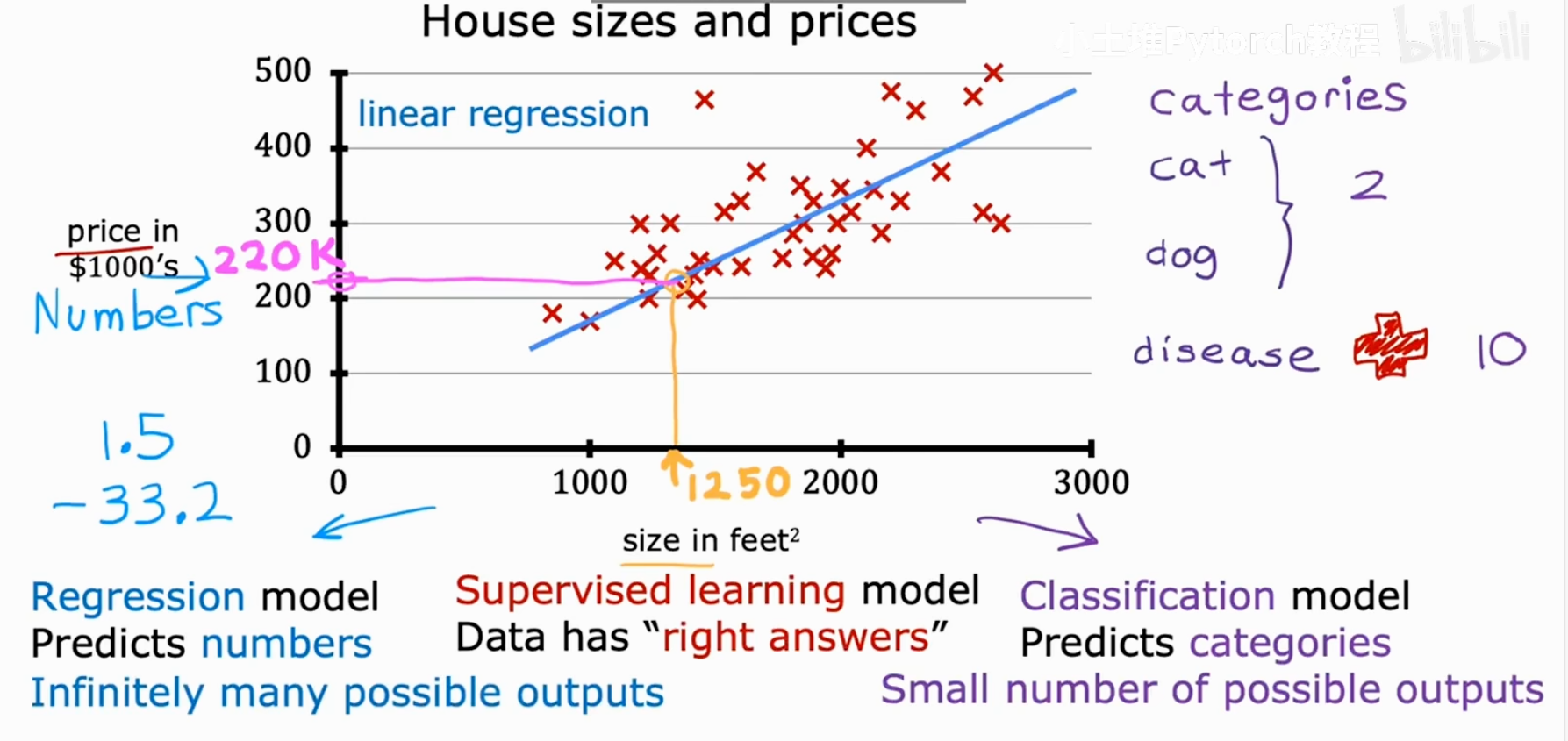
我们的目标是建立一个模型,它能根据房屋的面积(size)来预测其价格(price)。
- 回归模型 (Regression model):预测的是一个连续的数值(Numbers),理论上有无限多种可能的输出。
- 分类模型 (Classification model):预测的是一个离-散的类别(Categories),可能的输出数量是有限的。
而这两种模型都属于监督学习模型 (Supervised learning model),因为我们用来训练它们的数据都包含了"正确答案"。
3.2 模型的专业术语
在正式建立模型之前,我们需要先统一一下"专业语言",了解一些机器学习中的基本术语。
我们用来构建模型的数据,通常被称为数据集 (Data set)。在我们的例子中,数据集就是一系列房屋面积及其对应的真实价格。
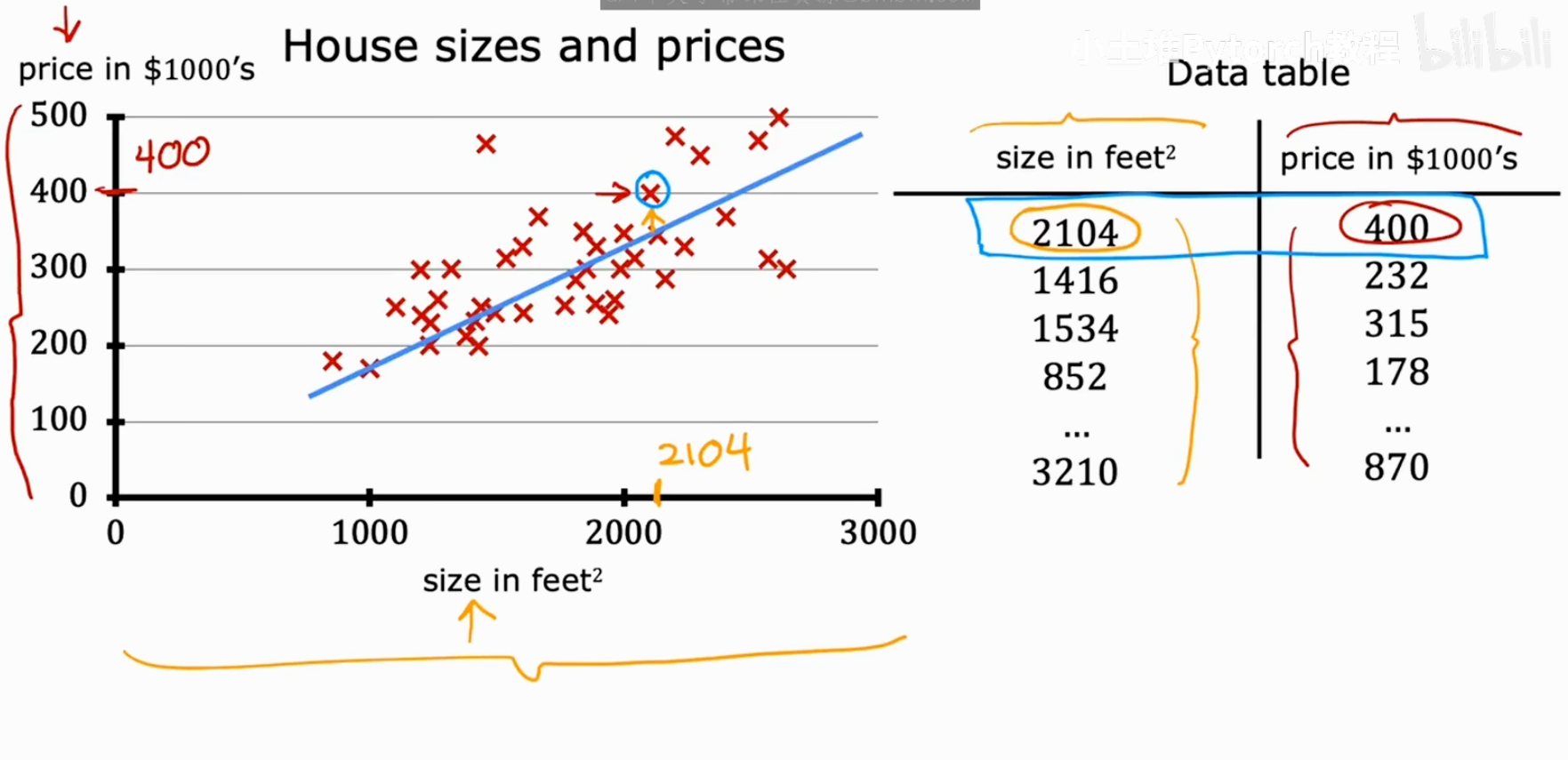
这张图非常直观地展示了数据点和数据表之间的关系。图上的每一个红叉,都对应着数据表中的一行。
为了更精确地描述,吴恩达老师引入了一套标准的数学符号:

- x : 表示输入变量 (input variable) ,也常被称为特征 (feature) 。在我们的例子中,
x就是房屋的面积。 - y : 表示输出变量 (output variable) ,也常被称为目标 (target) 。在我们的例子中,
y就是房屋的价格。 - m : 表示训练样本的数量 (number of training examples) 。图中的例子里,我们有47个训练样本,所以
m=47。 - (x, y) : 表示一个单个的训练样本 (single training example)。
- (x⁽ⁱ⁾, y⁽ⁱ⁾) : 表示第
i个训练样本。这里的上标(i)只是一个索引 (index) ,代表第几行数据,它不是 数学上的指数或次方。- 例如,
(x⁽¹⁾, y⁽¹⁾)就代表第一个训练样本,即(2104, 400)。
- 例如,
3.3 模型的表示 (Model Representation)
了解了基本术语后,我们来看看一个机器学习模型是如何工作的,以及如何用数学语言来表示它。
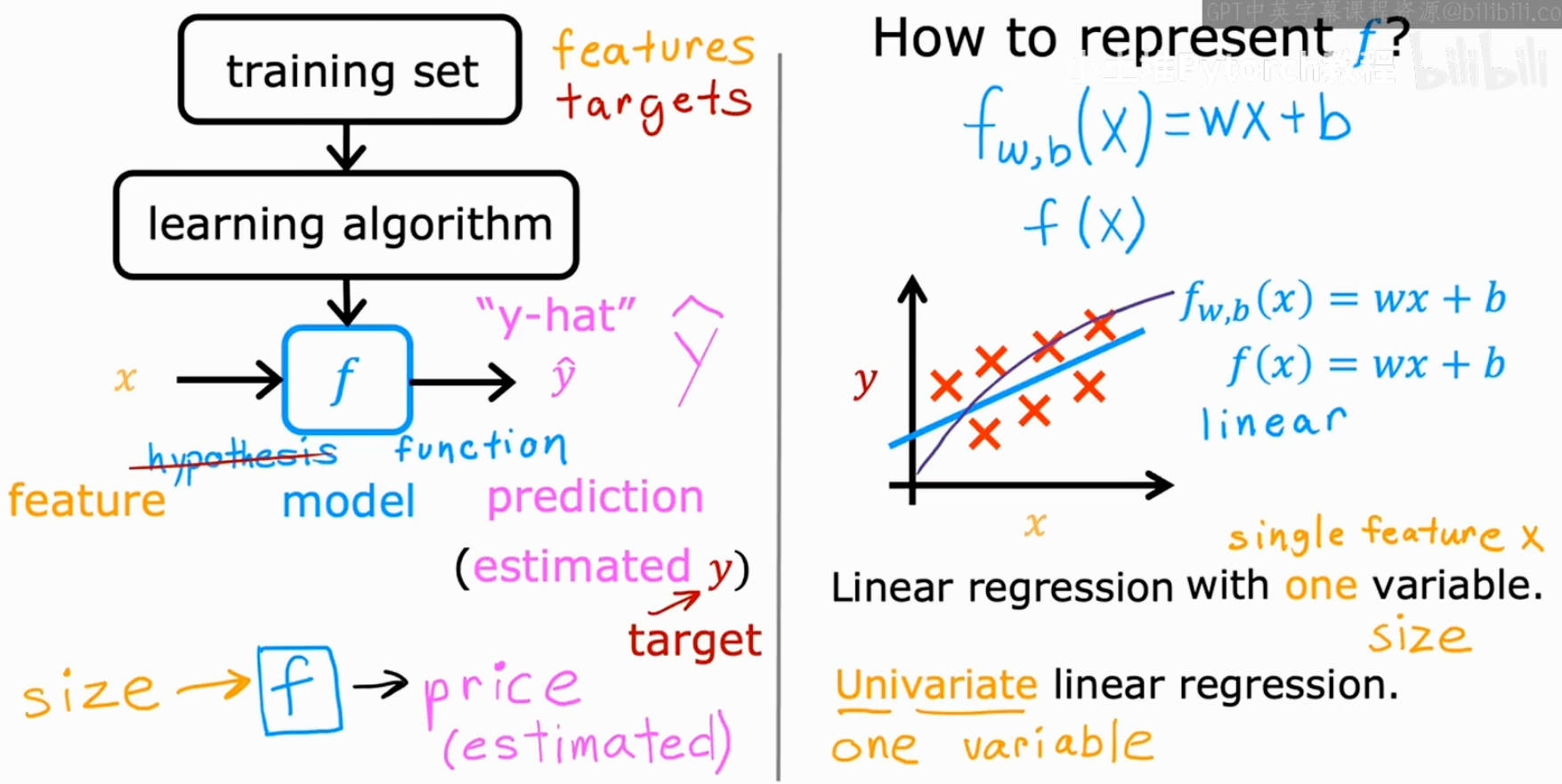
上图左侧清晰地展示了模型训练和预测的流程:
- 我们将训练集 (training set) (包含了特征
x和目标y)喂给一个学习算法 (learning algorithm)。 - 学习算法会输出一个函数
f。这个函数f就是我们最终得到的模型 (model) ,在一些文献中它也被称为假设 (hypothesis)。 - 当有新的输入
x(例如,一个全新的房屋面积)时,我们就可以用这个模型f来进行预测。模型输出的预测值,我们通常用 ŷ (读作 "y-hat") 来表示。
那么,这个模型 f 的具体形式是什么呢?对于线性回归,我们希望找到一条直线来拟合我们的数据。初中数学告诉我们,一条直线的方程可以表示为 y = wx + b。在机器学习中,我们沿用这个形式,将模型写作:
f_w,b(x) = wx + b
这个模型只有一个输入特征 x(房屋面积),因此它被称为单变量线性回归 (Univariate linear regression)。"Univariate"中的"uni"就是"单一"的意思。
我们的核心任务,就是通过学习算法,找到最优的参数 w 和 b,使得这条直线能够最好地拟合我们的训练数据。
3.4 总结
今天我们正式开启了线性回归模型的大门,重点掌握了以下内容:
- 核心术语:了解了特征(x)、目标(y)、训练集、样本数量(m)等基本概念及其数学符号。
- 模型流程 :明白了训练集通过学习算法生成模型
f,模型f再对新输入进行预测(输出ŷ)的基本流程。 - 模型表示 :知道了单变量线性回归的模型
f(x) = wx + b,即一条直线。
四、代价函数:如何衡量模型的好坏
在上文我们定义了线性回归模型 f(x) = wx + b。我们知道,通过调整参数 w 和 b,我们可以得到不同的直线。那么,接下来的问题是:如何自动地为我们的模型找到最合适的 w 和 b 呢?
要回答这个问题,我们首先需要一种方法来衡量模型的好坏。这就是代价函数(Cost Function的作用。
4.1 理解模型的参数 w 和 b
首先,我们再来回顾一下模型 f(x) = wx + b 中的两个参数(parameters) w 和 b 究竟是做什么的。在一些文献中,它们也被称为系数(coefficients)或权重(weights)。

通过下面这组图,我们可以非常直观地理解它们的作用:
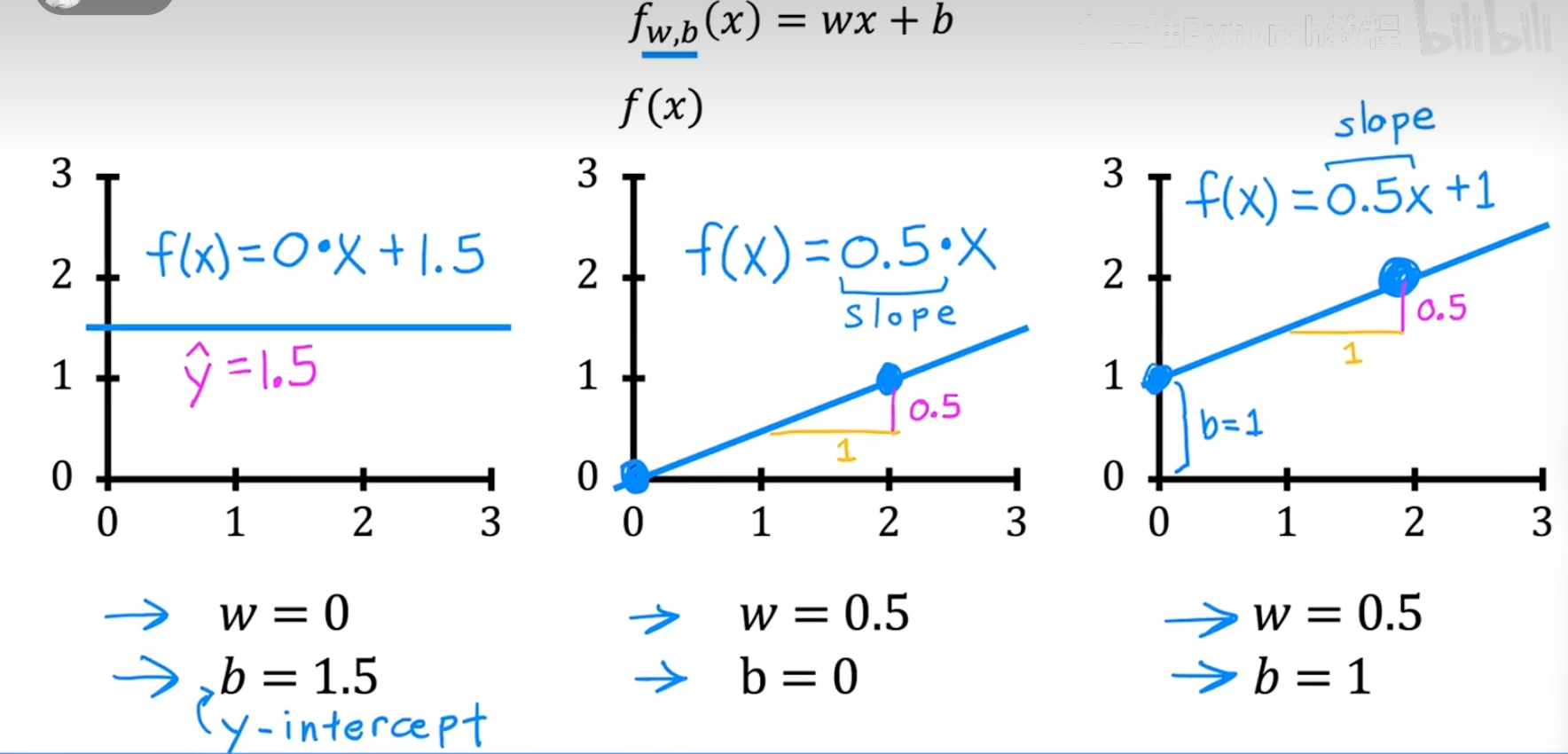
- b (y-intercept) :当
w=0时,f(x) = b,这是一条水平线。b决定了直线与y轴的截距。 - w (slope) :
w决定了直线的斜率。它表示x每增加1,f(x)变化的量。w越大,直线越陡峭。
通过选择不同的 w 和 b,我们的直线模型就能以不同的方式去拟合数据。我们的目标,就是找到那个能"最好地"拟合数据的 w 和 b。
4.2 定义代价函数 J(w, b)
为了衡量拟合的好坏,我们需要量化模型预测值与真实值之间的"差距"或"误差"。

对于第 i 个训练样本 (x⁽ⁱ⁾, y⁽ⁱ⁾):
- 真实值是
y⁽ⁱ⁾。 - 模型的预测值是
ŷ⁽ⁱ⁾ = f(x⁽ⁱ⁾) = wx⁽ⁱ⁾ + b。 - 两者之间的误差就是
ŷ⁽ⁱ⁾ - y⁽ⁱ⁾。
为了得到一个总体的误差评估,一个非常有效且常用的方法是计算所有样本误差的平方和的平均值 。这就是我们的代价函数,通常用 J(w, b) 来表示:
J(w,b) = (1 / 2m) * Σ (f(x⁽ⁱ⁾) - y⁽ⁱ⁾)² (从 i=1 到 m)
这个公式被称为平方误差代价函数(Squared error cost function),它是解决回归问题最常用的代价函数。让我们来拆解一下这个公式:
- f(x⁽ⁱ⁾) - y⁽ⁱ⁾:计算单个样本的预测值和真实值之间的误差。
- (...)² :对误差取平方。这有两个好处:
- 可以确保误差值为正,避免正负误差相互抵消。
- 可以放大较大误差的惩罚,使得模型更倾向于去拟合那些偏差大的点。
- Σ ... :将所有
m个训练样本的平方误差求和。 - (1 / 2m) :求平均值。除以
m是为了让代价函数的值不受样本数量的影响。而乘以1/2是一个数学上的小技巧,它可以在后续计算(求导)时简化公式,但并不会影响我们找到最优w和b的最终结果。
我们的目标 就是:找到能使代价函数 J(w, b) 最小的 w 和 b 的值。
minimize J(w, b)
4.3 直观理解代价函数
为了更清晰地理解代价函数 J 是如何工作的,吴恩达老师用了一个非常巧妙的方法:先简化模型,再将其推广到一般情况。
4.3.1 简化情况:b = 0
我们暂时假设 b=0,这样模型就变成了 f(x) = wx,代价函数也简化为 J(w)。现在我们只需要关注一个参数 w。
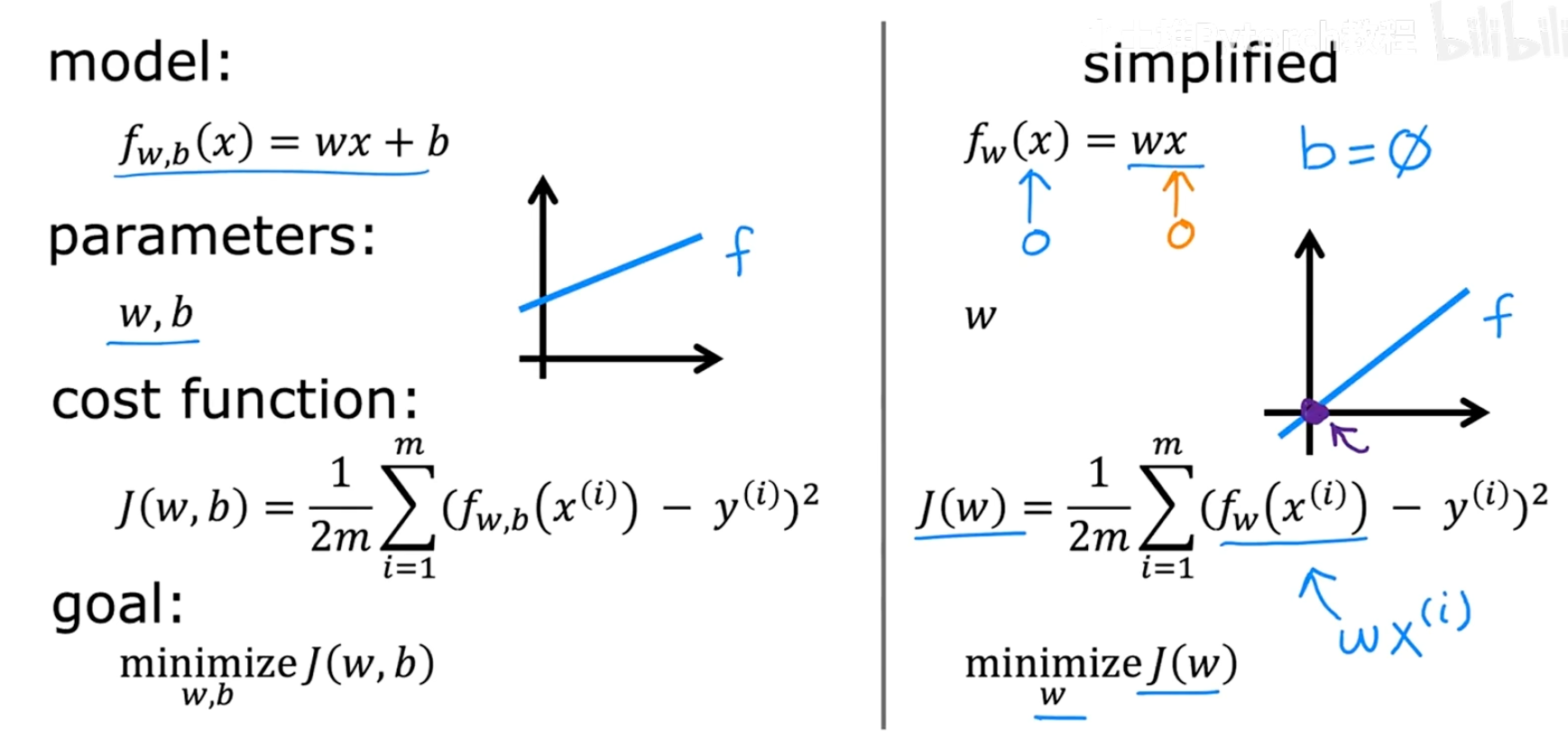
左边的图是我们的模型 f(x) 关于输入 x 的函数,右边的图是我们的代价函数 J(w) 关于参数 w 的函数。请注意这两个图的坐标轴是完全不同的。
-
当
w=1时 :
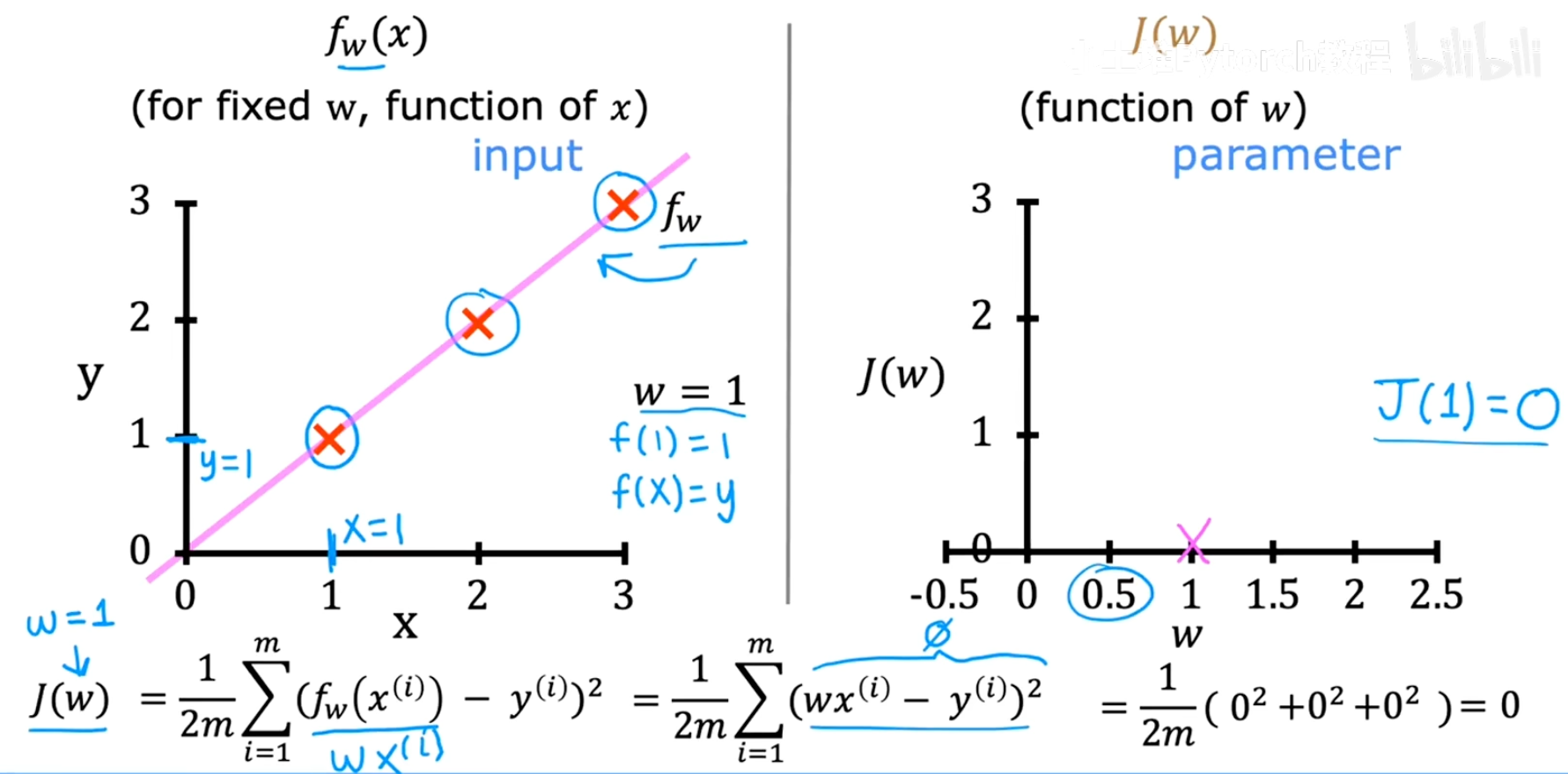
我们发现,当
w=1时,模型f(x) = 1*x完美地穿过了所有训练数据点。此时,每个点的误差(wx⁽ⁱ⁾ - y⁽ⁱ⁾)都为0,因此总的代价J(1) = 0。这是我们能得到的最小代价。 -
当
w不为1时 :
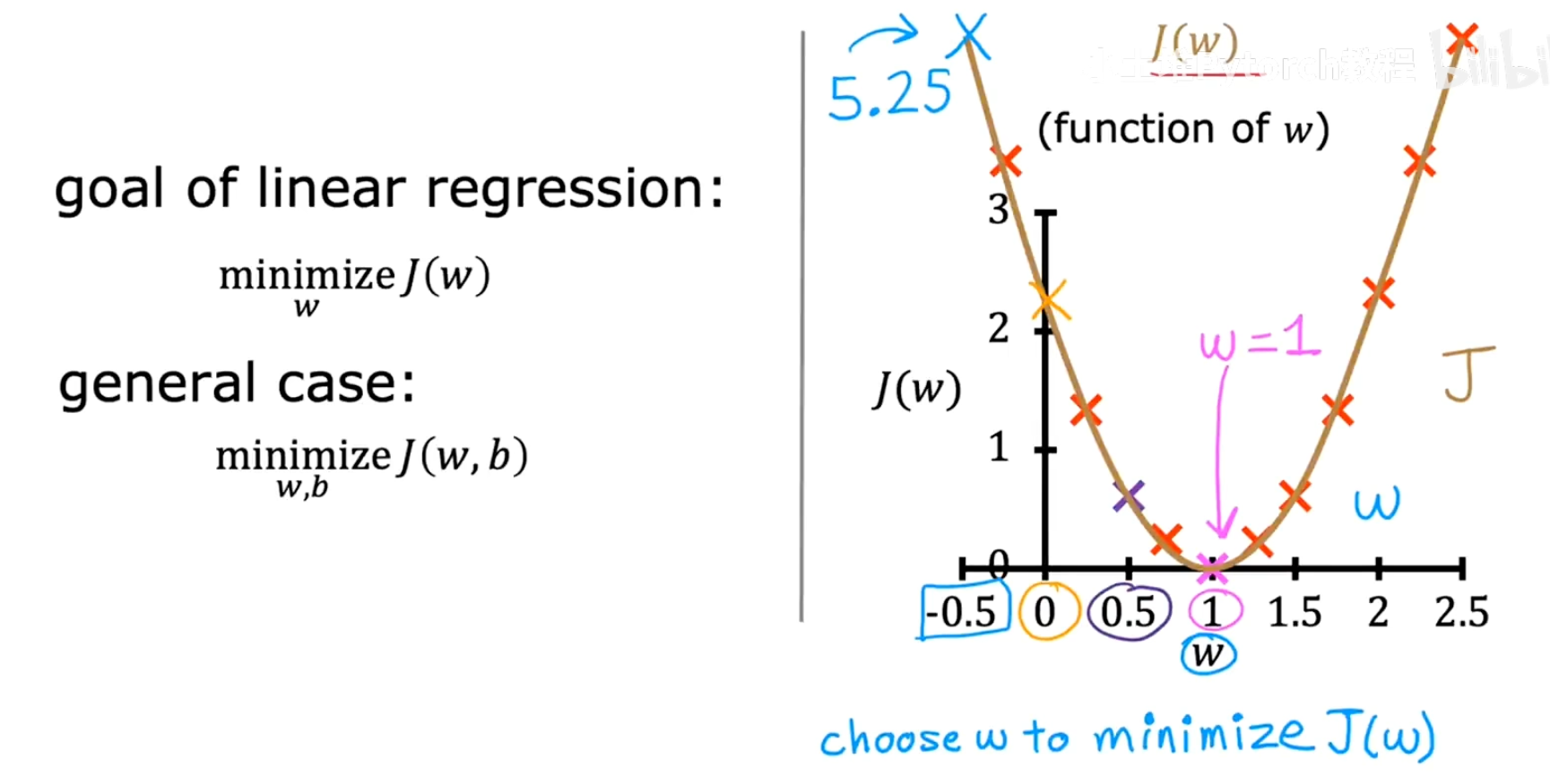
如果我们选择不同的
w值(比如w=0.5,w=0,w=-0.5等),模型就无法完美拟合数据,会产生误差。将这些w值对应的J(w)计算出来并绘制成图,我们会得到一个类似抛物线的形状。
从上图可以看出,代价函数 J(w) 的最低点,正是在 w=1 时取到。因此,对于这个简化的模型,线性回归的目标就是找到这个抛物线的最低点,并返回其对应的 w 值。
4.3.2 一般情况:w 和 b
现在,我们把参数 b 加回来。代价函数 J(w, b) 变成了两个参数的函数。
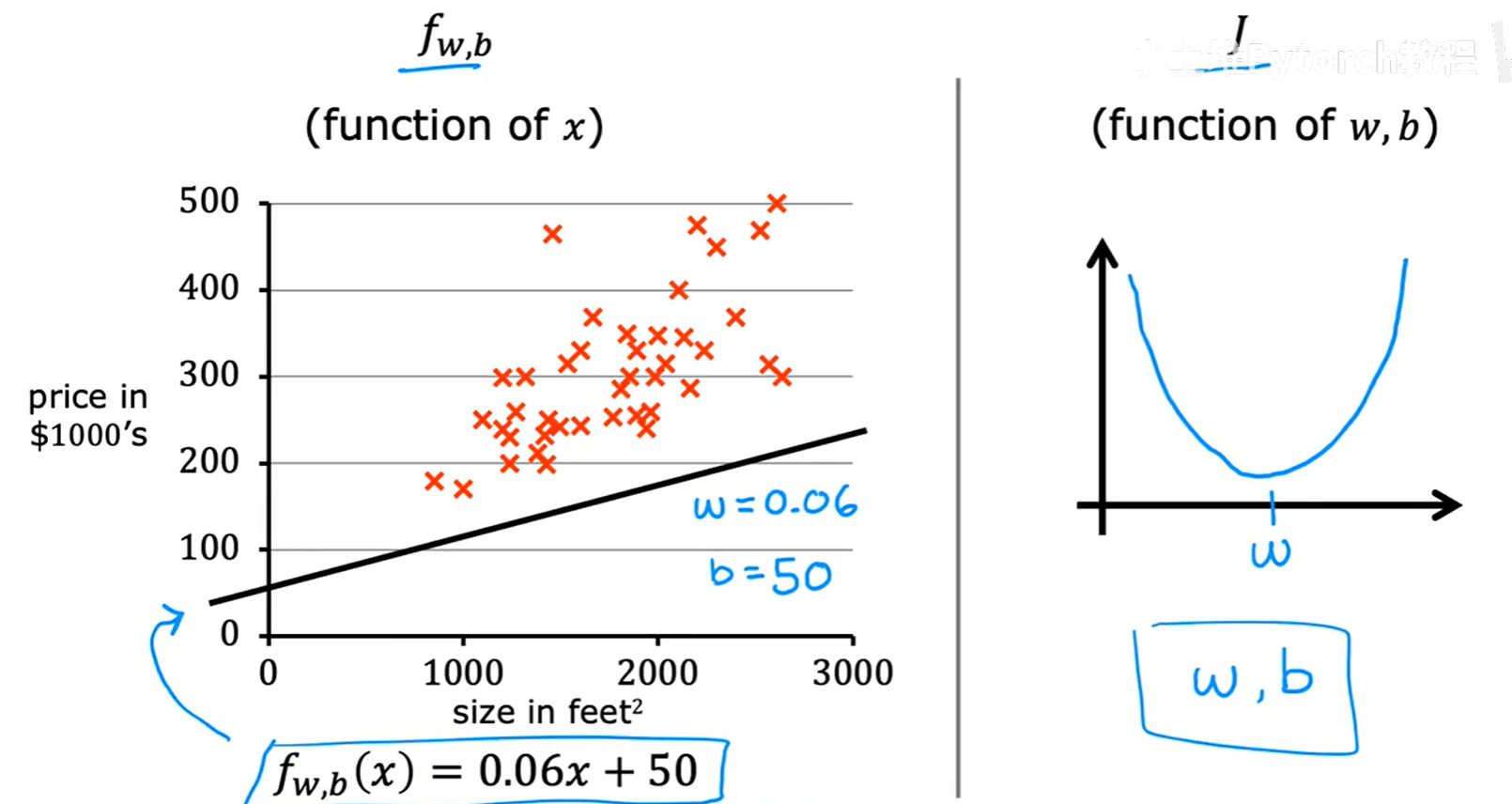
如果说 J(w) 是一个2D的抛物线,那么 J(w, b) 就是一个3D的"碗"形曲面。
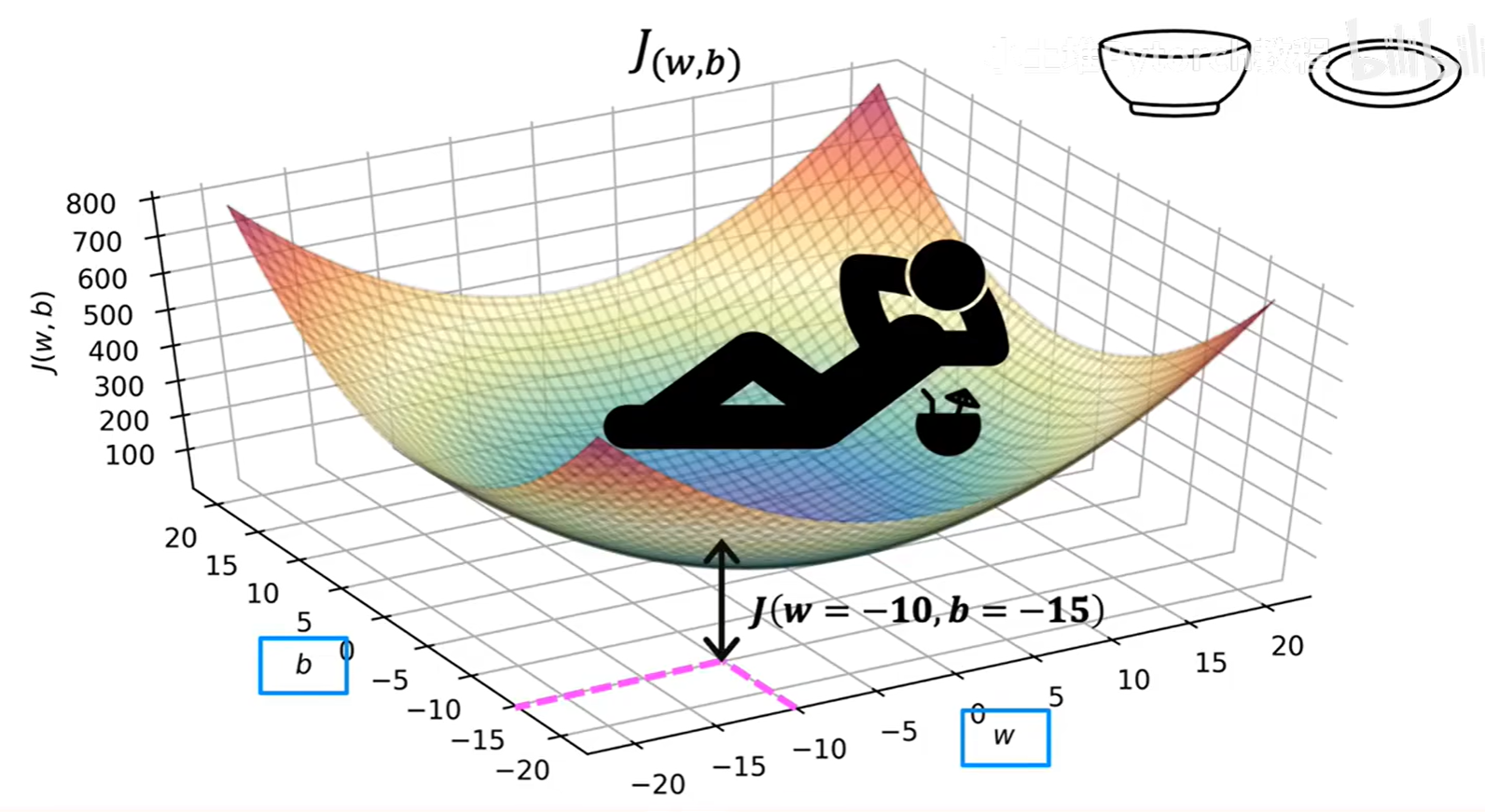
这个3D曲面上的每一点,都对应着一组 (w, b) 参数,以及由这组参数计算出的代价值 J(也就是曲面的高度)。我们的目标,就是找到这个"碗"底部的最低点。
4.3.3 可视化工具:等高线图 (Contour Plot)
3D图像虽然直观,但在纸面上绘制和分析并不方便。因此,我们常常使用等高线图来从"正上方"俯视这个3D曲面。
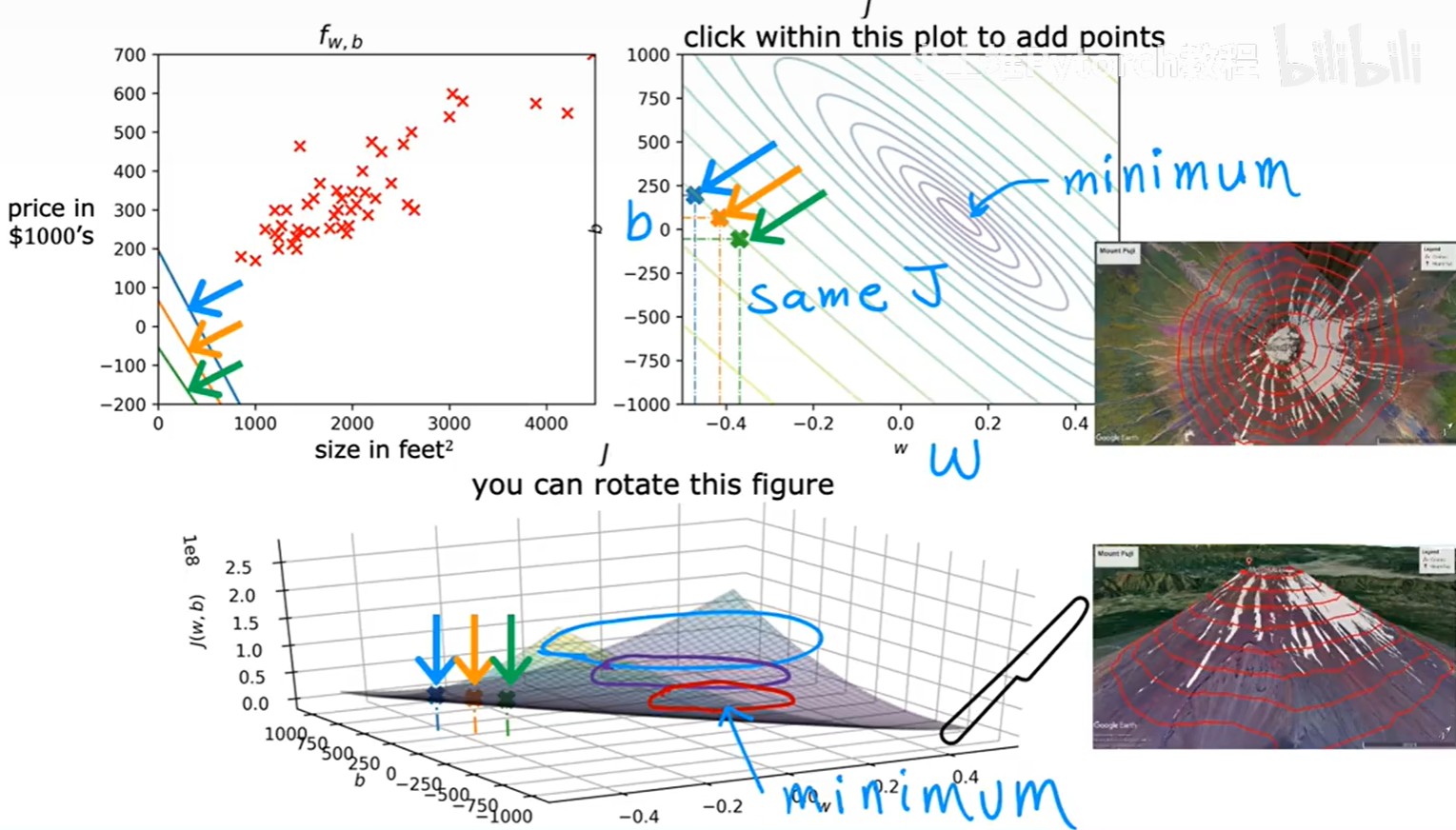
等高线图就像我们地理课上学的地形图:
- 图上的每一个椭圆(等高线),都代表着一组能得到相同代价值
J的(w, b)组合。 - 最中心的那个点,就是"碗"的最低点,也就是我们寻找的代价函数的最小值点。
通过下面这组动图,我们可以清晰地看到模型、代价函数曲面和等高线图之间的联动关系:
-
一个糟糕的拟合 :
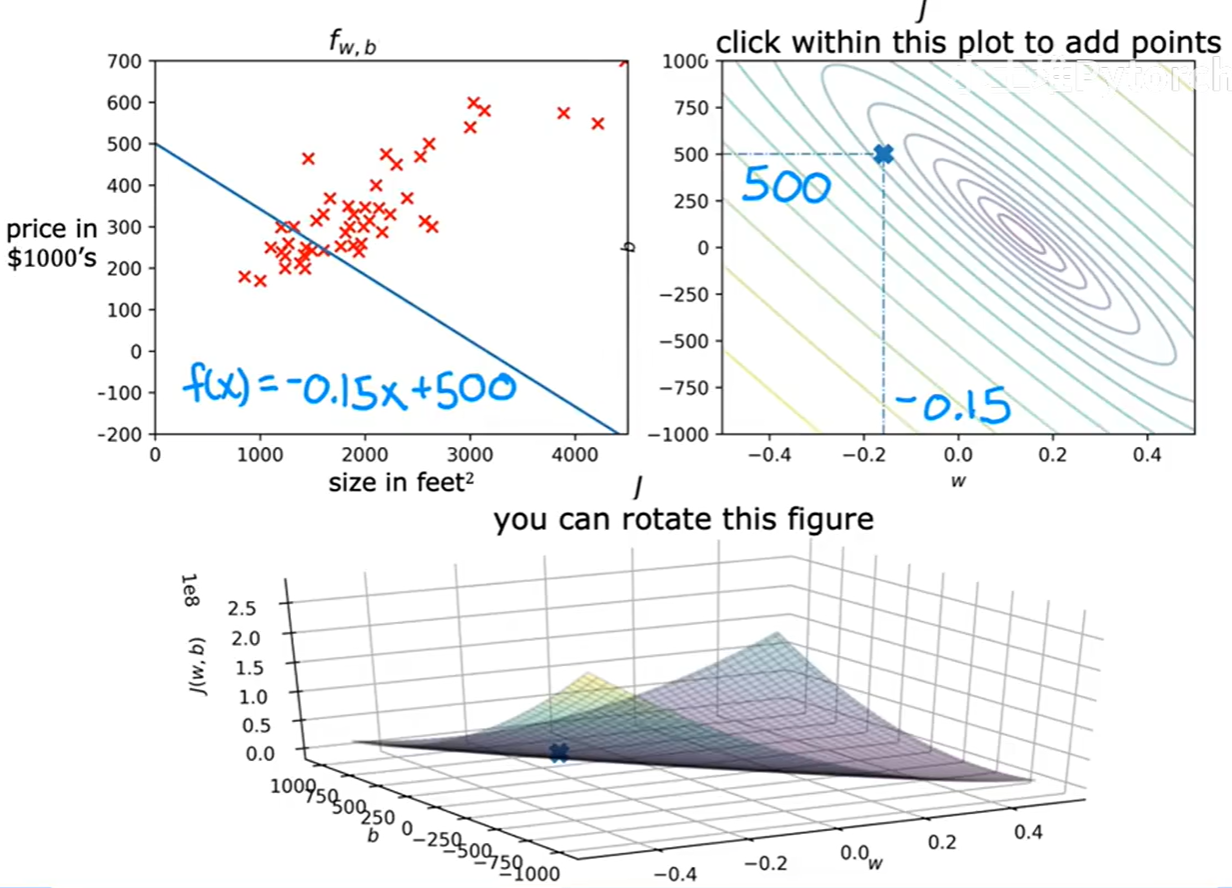
当
w=-0.15, b=500时,我们在等高线图上处于一个远离中心的位置。对应的,左边的拟合直线与数据点偏差很大,误差很高,因此在3D曲面上的位置也很高。 -
一个更好的拟合 :
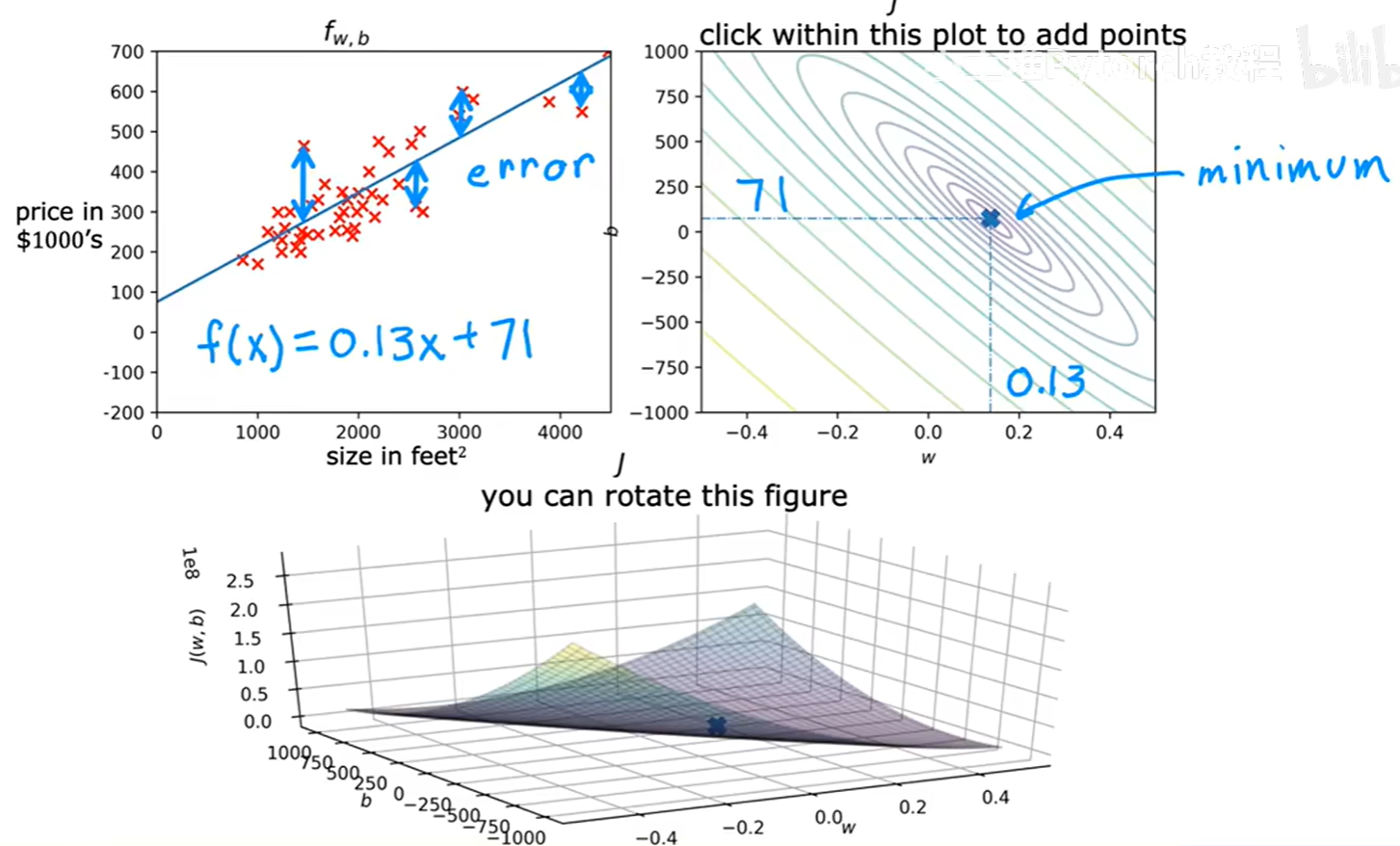
当我们选择
w=0.13, b=71,这个点在等高线图上更靠近中心。此时,左边的拟合直线与数据点的贴合程度明显变好,总误差(代价J)也显著降低。
我们的最终目标,就是找到等高线图最中心点对应的 (w, b),因为它能让我们的模型产生的总误差最小,也就是对数据拟合得最好。
下一篇文章,我们将介绍一种强大的算法------梯度下降,它能够自动地、高效地为我们找到这个代价函数的最低点。