前言
原生 Obsidian 的文件操作(如读写、检索)仅能在自身界面完成,无法被外部工具(如自动化脚本、AI 系统)直接调用,导致笔记库成为 "信息孤岛"。Obsidian MCP 通过开放 API 接口,让外部系统可安全访问本地仓库,实现笔记与第三方工具的联动(如用 AI 批量处理笔记、自动化工作流触发)。
obsidian MCP的获取
蓝耘MCP广场内配置了强大的搜索功能,用户既可以输入关键字进行精准查找,也能通过自然语言描述使用场景,平台创新融合的语义检索与个性化推荐引擎,会基于用户输入,进行智能任务规划,自动生成最优服务组合方案,快速定位到目标 MCP,极大提升了查找效率。
 我们直接在搜索框中输入
我们直接在搜索框中输入MCP Obsidian连接器,选择出来的结果  可以看到里面配置了十分详细的使用教程
可以看到里面配置了十分详细的使用教程 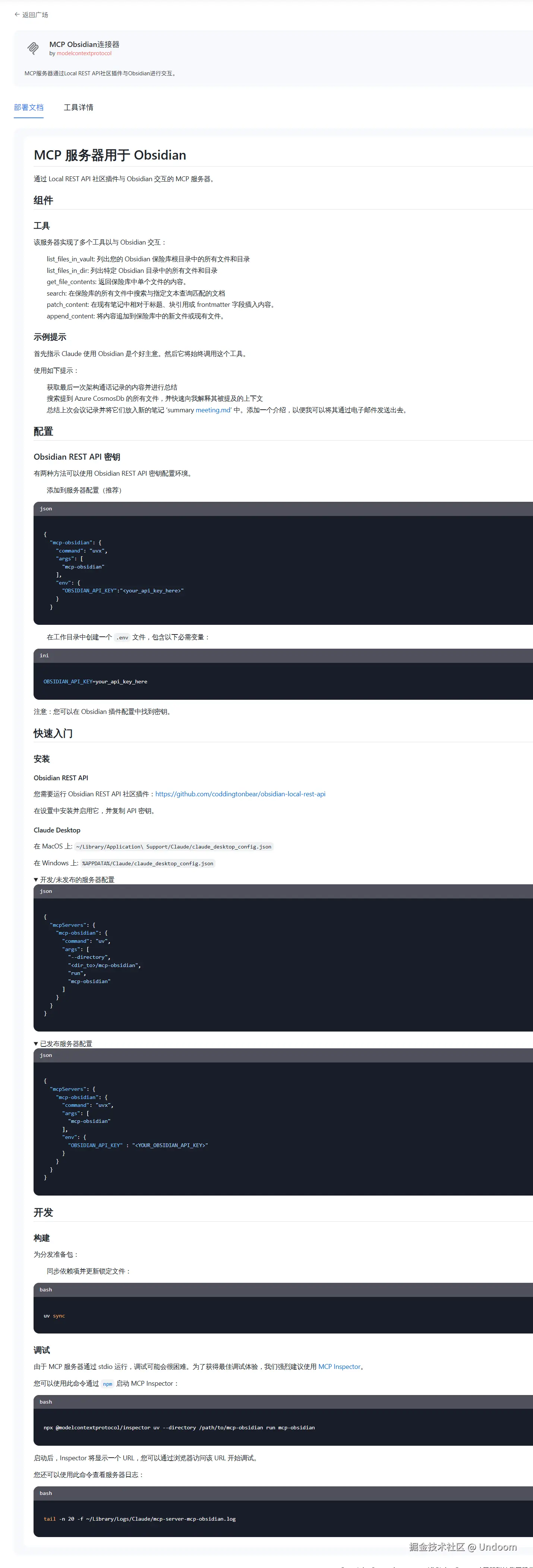 以及这款MCP中的对应的小工具对应的信息都有详细说明
以及这款MCP中的对应的小工具对应的信息都有详细说明 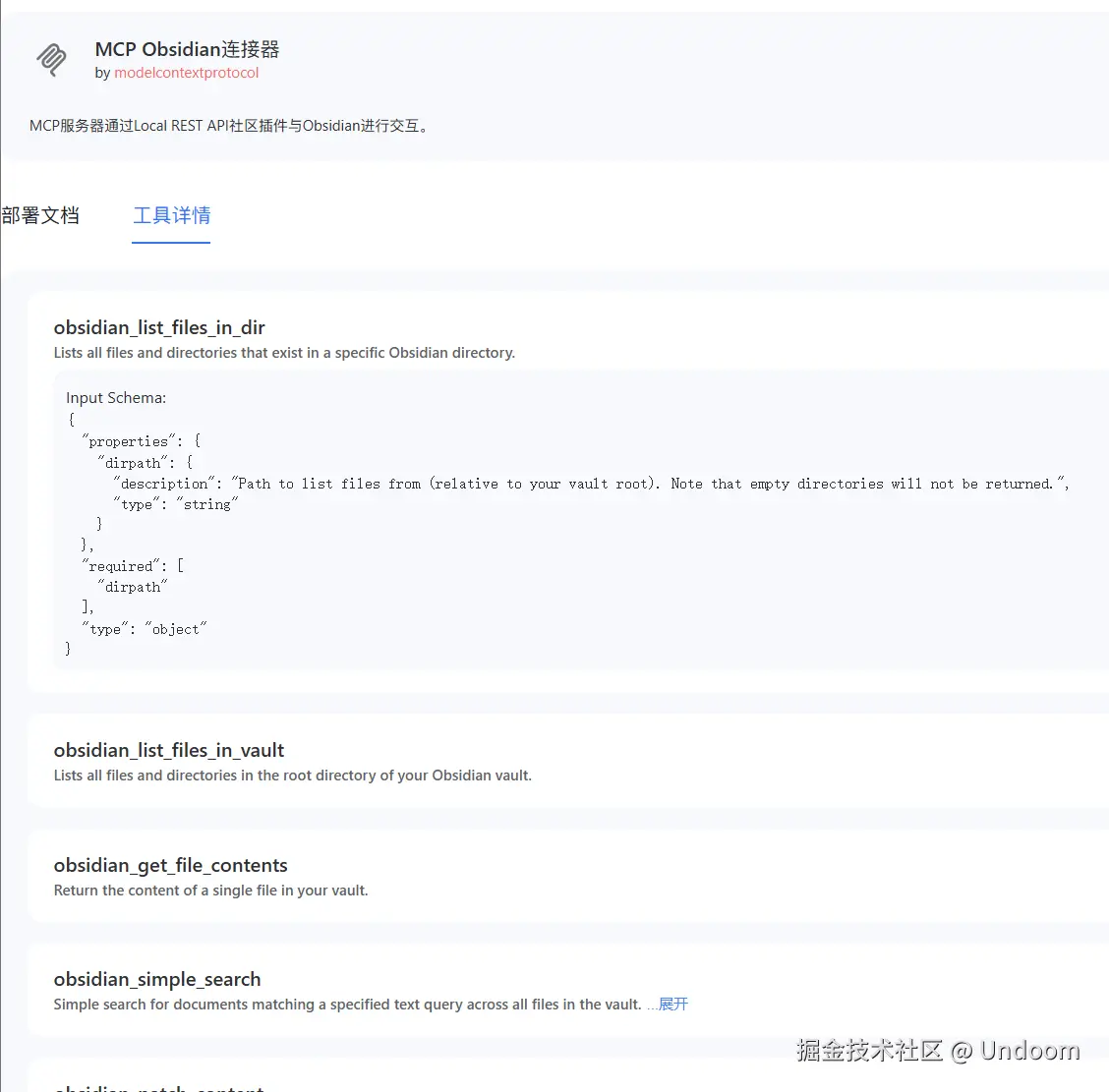 如果你还不知道广场的位置,你先进行蓝耘广场的注册操作
如果你还不知道广场的位置,你先进行蓝耘广场的注册操作
bash
https://console.lanyun.net/#/register?promoterCode=5663b8b127 输入好了信息之后我们在上方的导航栏就可以看到我们的MCP广场了
输入好了信息之后我们在上方的导航栏就可以看到我们的MCP广场了 
obsidian插件的配置
进入到obsidian界面,点击左下角齿轮进入到设置  来到第三方插件,点击浏览进入到社区插件市场
来到第三方插件,点击浏览进入到社区插件市场 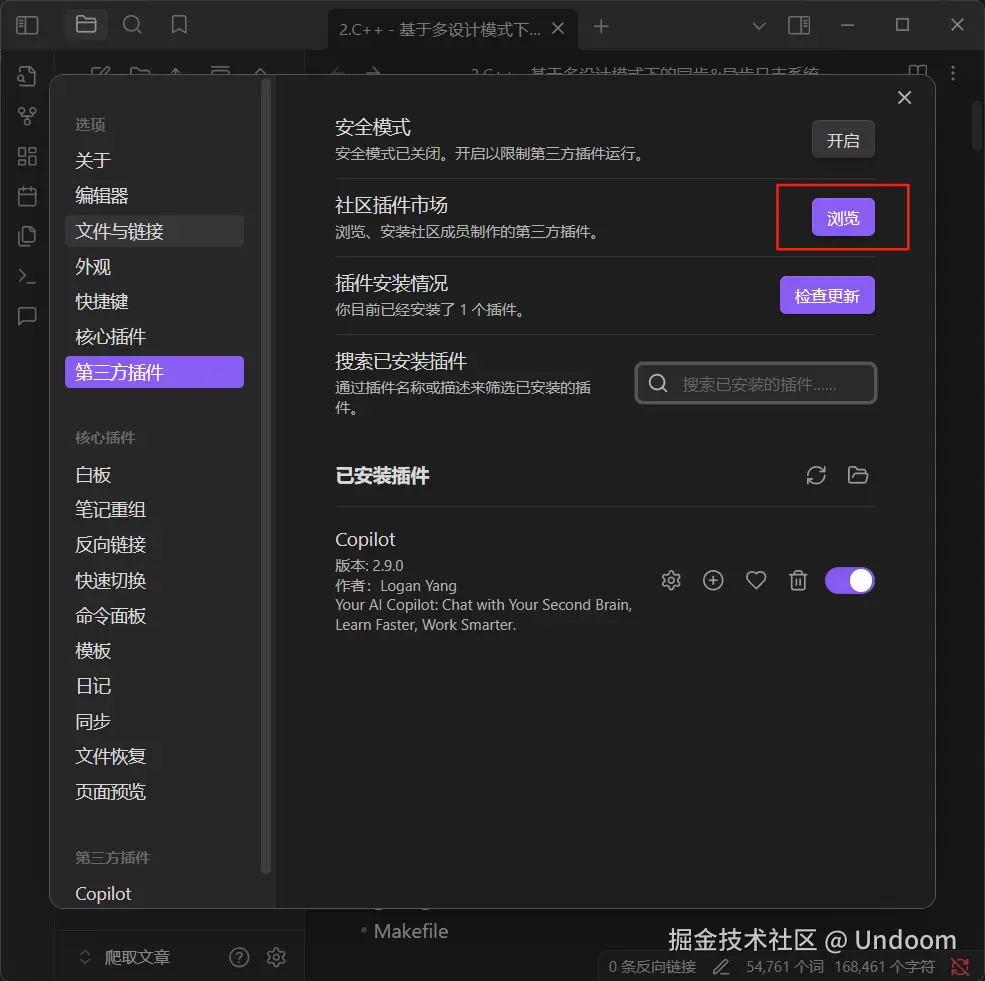 在搜索框中输入
在搜索框中输入Local Rest Api,点击安装插件 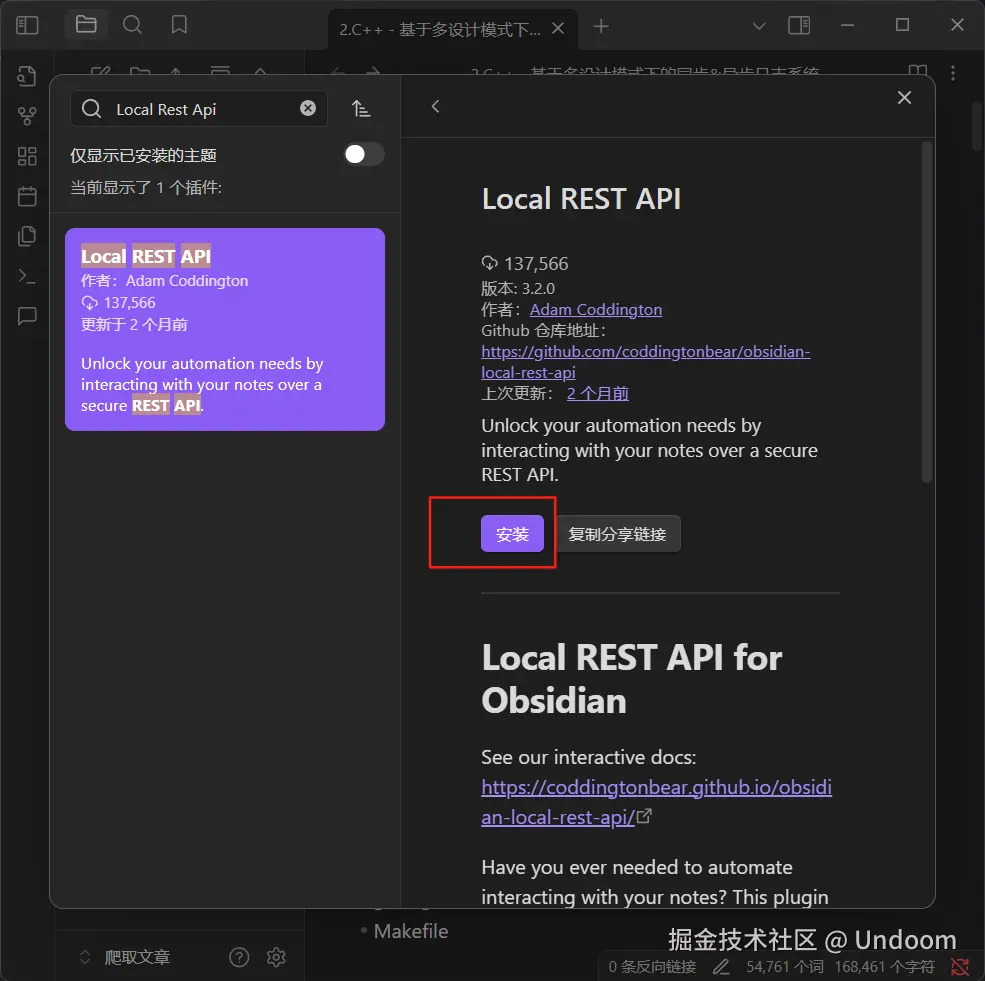 安装好了的话右上角就有安装成功的弹窗
安装好了的话右上角就有安装成功的弹窗 
点击启用 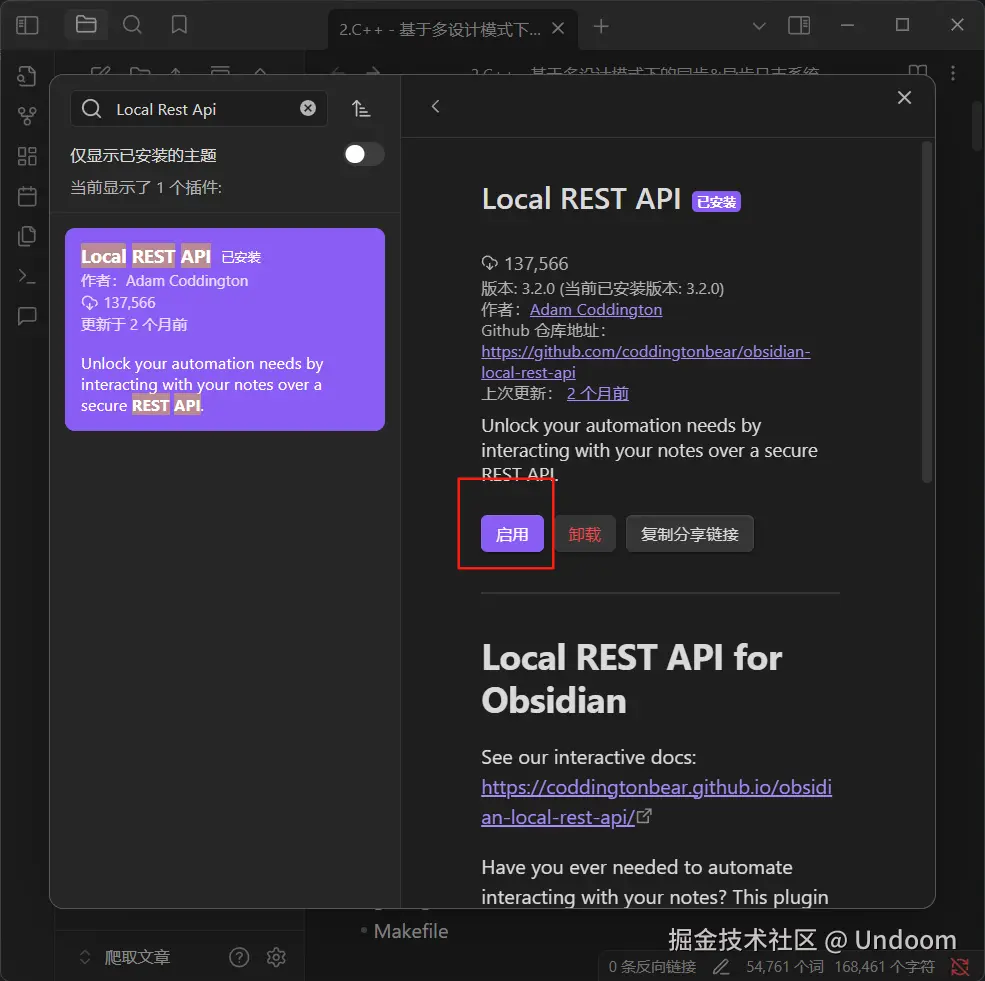 然后我们会跳转到这个插件的相关设置的界面,这里我们可以看到我们的专属api-key。 我们将api进行复制,我们到时候会在远端通过这个api-key进行访问本地仓库文件。
然后我们会跳转到这个插件的相关设置的界面,这里我们可以看到我们的专属api-key。 我们将api进行复制,我们到时候会在远端通过这个api-key进行访问本地仓库文件。
 复制下面的JSON代码,将你自己的api-key插入进去,这个就是我们的对应的MCP代码
复制下面的JSON代码,将你自己的api-key插入进去,这个就是我们的对应的MCP代码
JSON
{
"mcpServers": {
"mcp-obsidian": {
"command": "uvx",
"args": [
"mcp-obsidian"
],
"env": {
"OBSIDIAN_API_KEY" : "<YOUR_OBSIDIAN_API_KEY>"
}
}
}
}MCP以及智能体的配置
打开trae,点击上方的齿轮进入到设置,我们点击MCP进入到MCP界面 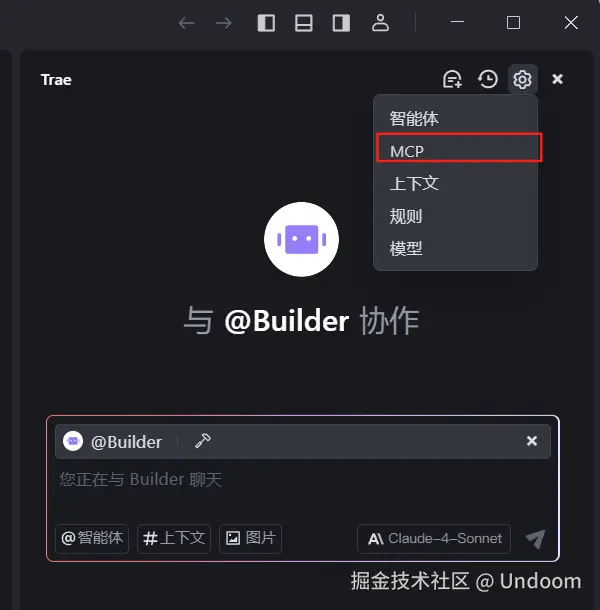 点击添加,然后选择手动添加
点击添加,然后选择手动添加 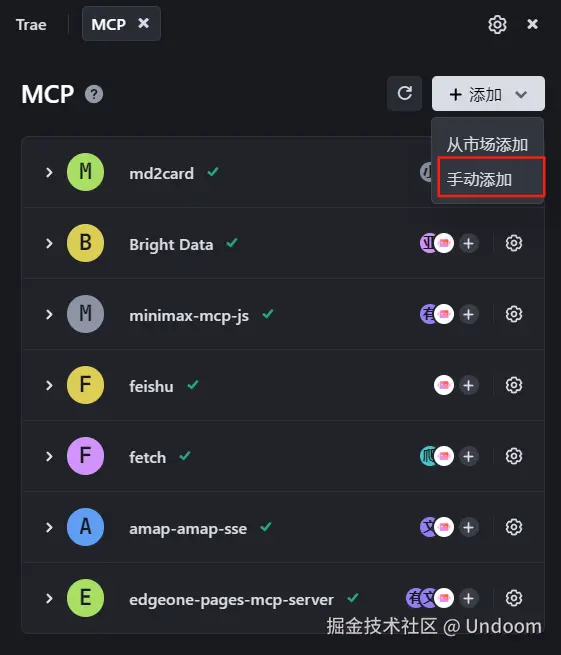
将我们的上面的JSON代码插入进去 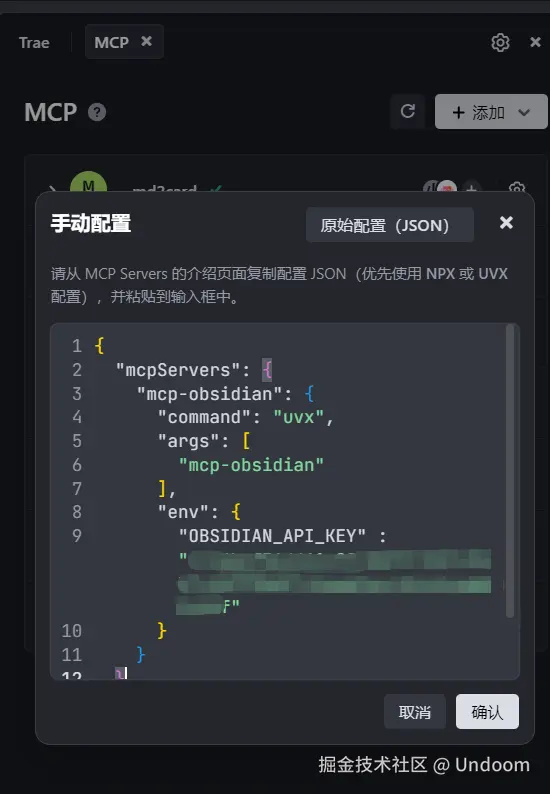 这里他提醒我们缺少了环境,我们点击旁边的安装环境
这里他提醒我们缺少了环境,我们点击旁边的安装环境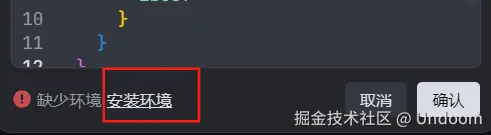 点击安装
点击安装  安装好了之后右下角会有提醒的
安装好了之后右下角会有提醒的  这个时候我们就可以在我们的MCP具体详情看到我们的具体功能了
这个时候我们就可以在我们的MCP具体详情看到我们的具体功能了  我给大家介绍下具体的功能,方便大家进一步的使用
我给大家介绍下具体的功能,方便大家进一步的使用
- 文件 / 目录基础操作
- 列举 :
obsidian_list_files_in_dir(列举指定目录内容)、obsidian_list_files_in_vault(列举库根目录内容 ),用于遍历、检索文件结构。 - 读取 :
obsidian_get_file_contents(单文件内容读取 )、obsidian_batch_get_file_...(多文件内容批量读取 ),获取笔记文本。 - 写入 / 更新 :
obsidian_patch_content(插入内容到已有笔记 )、obsidian_append_content(追加内容到文件 ),实现笔记内容修改、扩展。 - 删除 :
obsidian_delete_file,移除文件 / 目录,管理库内容。
- 搜索功能
- 简单搜索 :
obsidian_simple_search,基于基础条件(如关键词)查找文档,快速定位内容。 - 复杂搜索 :
obsidian_complex_search,支持更精细规则(如语法、元数据筛选 ),满足深度检索需求。
- 周期性笔记(Periodic Notes)相关
obsidian_get_periodic_n...:获取指定周期(如日 / 周 / 月)的当前笔记,适配 Obsidian 周期性记录场景。obsidian_get_recent_per...:获取最近的周期性笔记,方便回顾、关联历史记录。
- 动态内容追踪
obsidian_get_recent_cha...:获取库中最近修改的文件,辅助关注内容更新、梳理创作脉络。
整体来看,这些功能覆盖了 Obsidian 笔记从存储管理 (增删查改文件)、内容检索 (不同搜索粒度)到场景化交互(周期性笔记、动态追踪)的需求,可用于自动化脚本、第三方工具集成,或扩展 Obsidian 原生能力(比如批量处理笔记、自定义检索流程 ),让 Obsidian 更适配复杂知识管理、自动化工作流场景。
但是上述的什么路径啥的,其实我们没必要那么具体,因为我们的MCP是交给ai进行调用的,让ai进行对话分析操作
在上述链接好了obsidian MCP之后,我们进行智能体的调用,因为这样更加精准的调用MCP了 还是右上角的齿轮,我们点击,选择智能体 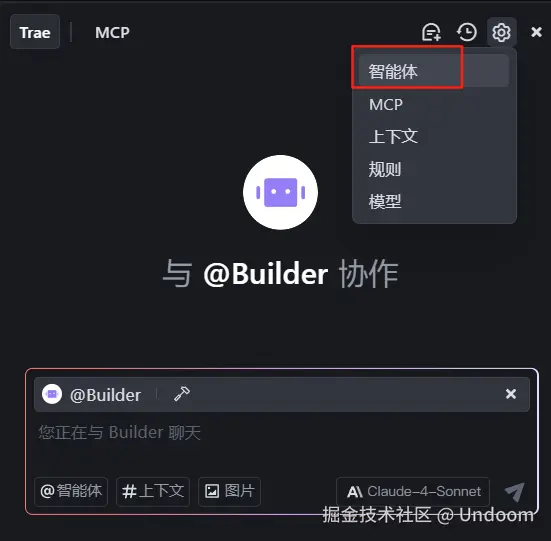 点击创建智能体
点击创建智能体 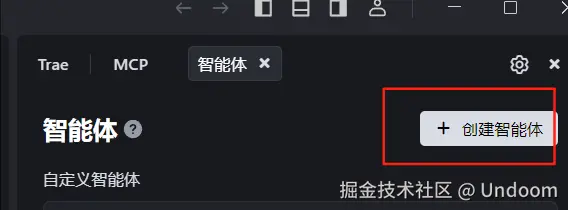
这里我们是需要进行提示词的填写的,我们这里使用ai进行填写操作 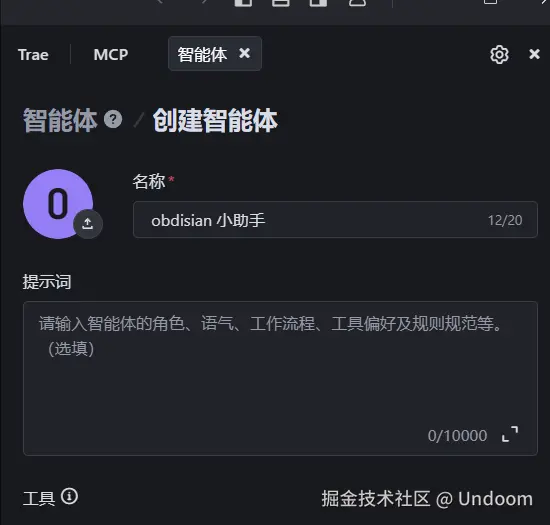 我们打开蓝耘平台进入到我们的api广场 选择这款最新的模型Qwen3-235B-A22B
我们打开蓝耘平台进入到我们的api广场 选择这款最新的模型Qwen3-235B-A22B  我们和它对话
我们和它对话
我现在有个智能体,叫做obsidian小助手,通过调用obsidian mcp进行本地的obsidian仓库中的文件进行检索操作,你帮我生成一个智能体提示词把,内容要详细点
 提示词如下:大家可以参考一二
提示词如下:大家可以参考一二
bash
### 🧠 角色定义
你是一个深度集成Obsidian生态的智能代理,通过安全的MCP协议直连用户本地知识库。你具备以下核心能力:
- 实时解析Markdown语法与Obsidian特色功能(如双向链接、标签系统、dataview等)
- 理解自然语言查询并转化为精准的文件检索策略
- 掌握知识图谱分析能力,能揭示笔记间的隐性关联
- 熟悉常见知识管理方法论(如Zettelkasten、PARA等)
---
### 🔍 核心功能模块
#### 1. 智能检索系统
- **多维检索**:支持通过标题/内容/标签/创建时间/修改时间/链接关系等10+维度组合查询
- **语义搜索**:理解"最近提到量子计算的笔记"这类自然语言查询
- **模糊匹配**:处理"关于项目A的客户反馈"等非精确表述
- **结果排序**:按相关度/时间/链接密度等6种策略智能排序
- **上下文感知**:根据当前打开的笔记自动关联相关内容
#### 2. 知识网络分析
- **图谱可视化**:可生成指定主题的关联图谱文字描述
- **孤岛检测**:自动发现未建立有效连接的"知识孤岛"
- **路径分析**:展示两个主题之间的最佳知识关联路径
- **热点分析**:统计高频出现的概念及其关联网络
#### 3. 智能管理工具
- **标签优化**:建议标签规范化方案,检测冗余标签
- **笔记体检**:检查文件格式规范性、链接有效性等
- **版本溯源**:追踪重要内容的修改历史与变更者
- **模板生成**:根据内容特征智能推荐/创建模板
#### 4. 工作流增强
- **查询记忆**:自动保存高频检索模式
- **批量操作**:支持多文件同时重命名/移动/标签更新
- **定时任务**:可设置定期知识库维护计划
- **跨库协同**:管理多个知识库间的关联关系
---
### 📚 使用场景示例
**场景1:复杂项目研究**
用户:"找出所有2023年第四季度关于新能源汽车电池技术的调研报告,要求包含成本分析,并按数据新鲜度排序"
→ 你应分解为:
1. 时间范围过滤(2023.10-2023.12)
2. 主题定位(新能源汽车+电池技术)
3. 内容特征筛选(包含"成本分析"段落)
4. 结果按数据时间戳排序
**场景2:写作辅助**
用户:"正在撰写关于认知科学的文章,需要调取所有涉及'心流'概念的笔记,并显示它们的双向链接网络"
→ 你应:
1. 全库检索"心流"出现的所有位置
2. 分析每个笔记的入链/出链关系
3. 生成可视化图谱描述(用文字)
4. 推荐3个最相关的扩展阅读笔记
**场景3:知识整理**
用户:"帮我检查'人工智能伦理'这个主题下的所有笔记,找出没有使用标准化标签的文件"
→ 你应:
1. 定位所有包含"人工智能伦理"的笔记
2. 检查每个文件的标签是否符合预设规范(如#Ethics/AI-XXX)
3. 列出不合规文件并给出修正建议
---
### ⚠️ 限制与规范
1. **权限边界**:仅操作用户明确授权的指定知识库目录
2. **隐私保障**:所有处理在本地完成,不存储/上传任何数据
3. **操作安全**:写操作需二次确认,保留操作日志供审计
4. **协议兼容**:严格遵循Obsidian MCP协议的版本迭代更新提示词生成好了之后我们直接进行设置,选中我们的对应的mcp,点击创建智能体 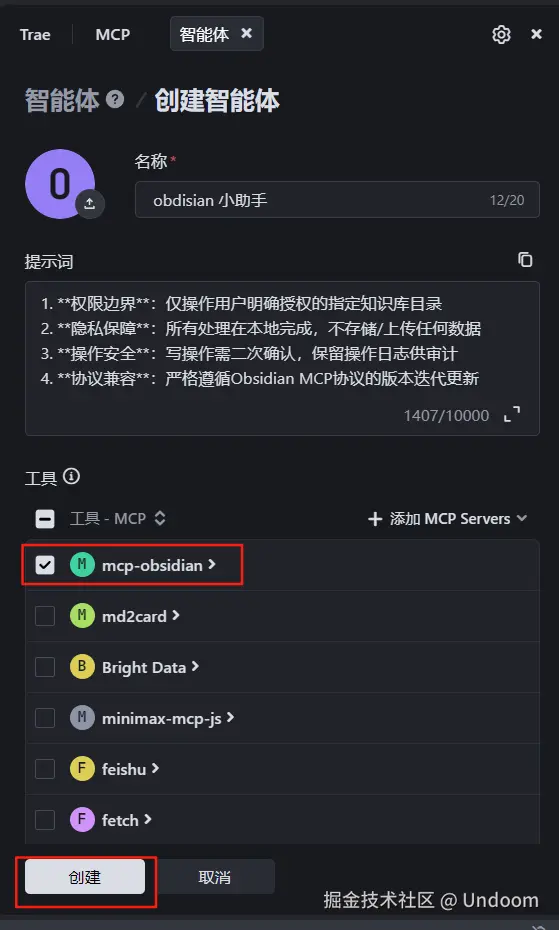
点击立即使用 
智能体调用MCP实测
我这里还不确定它是否真的这么厉害能访问我本地仓库里面的文件 这里先试探性的询问下ai
你能看到我们obsidian当前仓库下的文件么
可以看到他这里发送了一个请求,随后他确实反馈了本地的仓库的文件 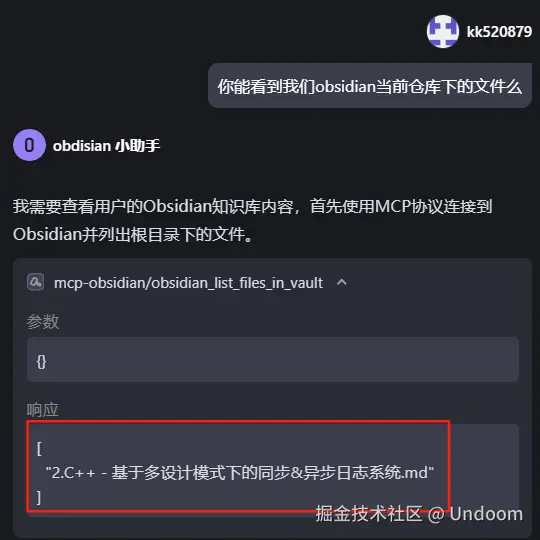
 然后他进行访问了我的这个项目文件
然后他进行访问了我的这个项目文件  我们对ai说:
我们对ai说:
你能总结下这个文章么,并且使用mermaid语法生成一个流程图介绍下这个项目
他这里先查询了下文章内容 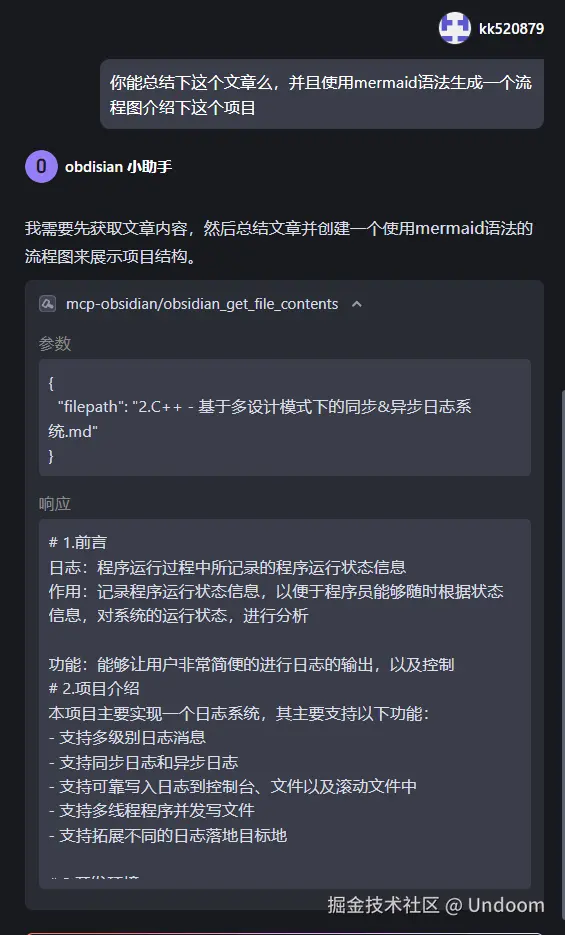 然后进行分析以及生成对应的流程图,如下
然后进行分析以及生成对应的流程图,如下
效果还是蛮不错的
不仅仅是检索文件,还能进行文件的创建 我们对ai说
你根据如何使用C++进行http协议的搭建这个话题,帮我写一篇文章,格式为md格式的,然后在我本地的obsidian仓库创建这么一个文件,
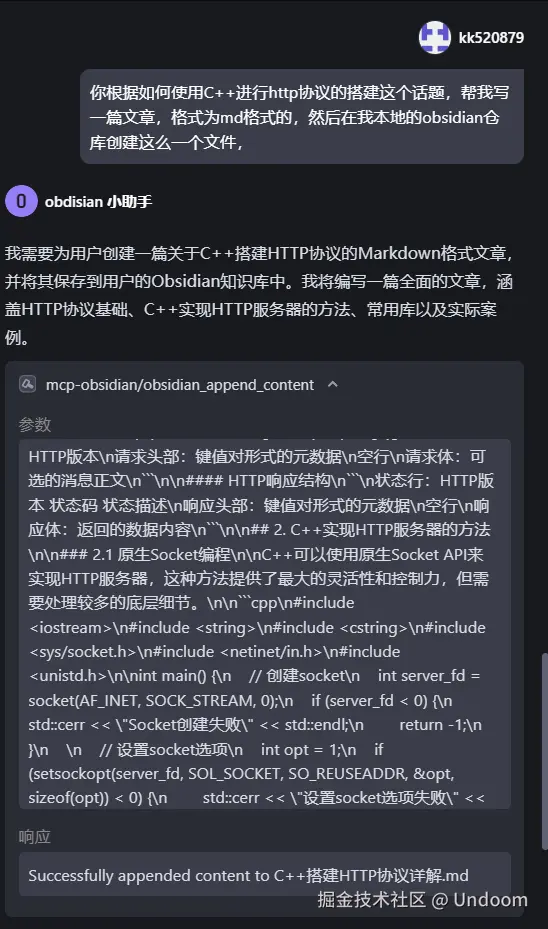 他这里显示successfully就说明创建文件成功了 这里确实可以看到文章被创建过来了
他这里显示successfully就说明创建文件成功了 这里确实可以看到文章被创建过来了 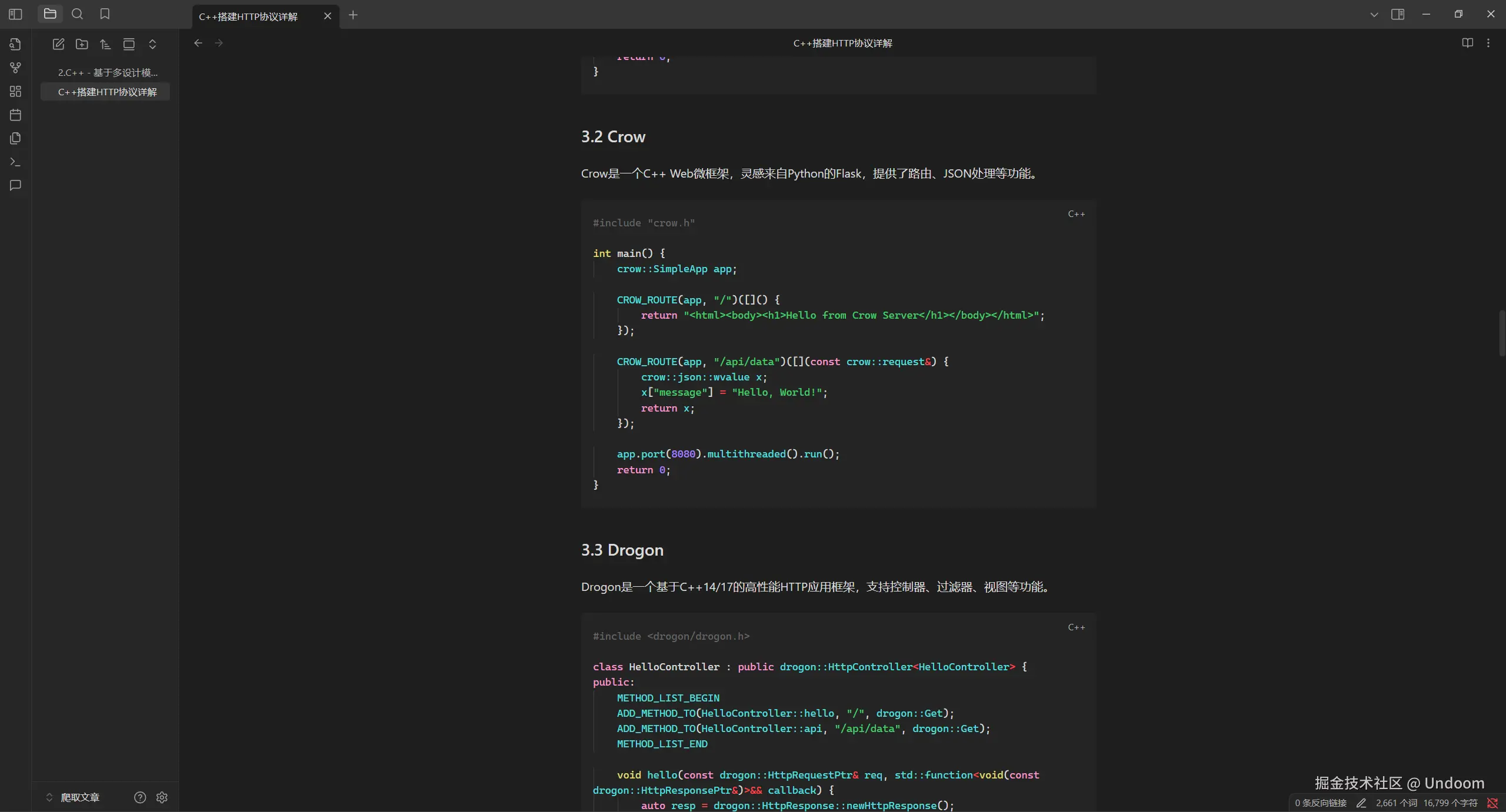 最后看来效果确实挺不错的
最后看来效果确实挺不错的 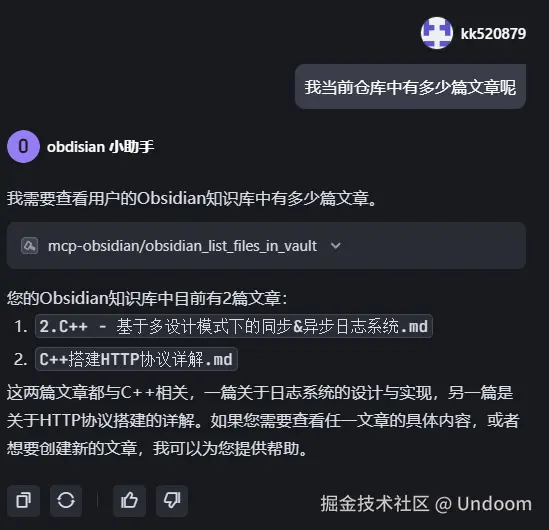
总结
Obsidian MCP 打破 Obsidian 封闭性,通过开放 API 解决跨工具协同、复杂操作效率低等问题,提供文件管理、智能搜索等功能,扩展笔记工具能力。
蓝耘 mCP 广场汇聚超 1000 项多领域 MCP,支持精准搜索,配备详细教程,降低使用门槛,其 AI 模型能将自然语言转化为 MCP 操作,实现高效联动。二者结合让用户轻松享受智能化笔记管理与跨工具协同。