本人不是AI领域从业者,了解这方面的知识只是出于好奇。
以下这个简单的深度神经网络代码是AI写的,可以帮助理解原理:
cpp
// 简单神经网络类
class SimpleNeuralNetwork {
public:
// 构造函数:初始化网络参数
SimpleNeuralNetwork()
: w1(0.1), b1(0.1), // 输入层到隐藏层的权重和偏置,初始化为0.1
w2(0.1), b2(0.1), // 隐藏层到输出层的权重和偏置,初始化为0.1
learningRate(0.01) {} // 学习率设为0.01
// 前向传播函数:计算给定输入x的网络输出
double forward(double x) {
// 隐藏层计算(没有使用sigmoid激活函数,所以是纯线性变换)
hiddenOutput = w1 * x + b1; // 公式: h = w1*x + b1
// 输出层计算(也是线性变换)
output = w2 * hiddenOutput + b2; // 公式: y^ = w2*h + b2
return output; // 返回预测值
}
// 计算损失函数(均方误差)
double loss(double predicted, double target) {
// MSE公式: L = (y^ - y)^2
return (predicted - target) * (predicted - target);
}
// 反向传播函数:计算梯度并更新参数
void backward(double x, double predicted, double target) {
// 计算预测误差
double error = predicted - target; // e = y^ - y
// 输出层梯度计算
double dL_dw2 = error * hiddenOutput; // ∂L/∂w2 = e * h
double dL_db2 = error; // ∂L/∂b2 = e
// 隐藏层梯度计算(链式法则)
double dL_dhidden = error * w2; // ∂L/∂h = e * w2
double dL_dw1 = dL_dhidden * x; // ∂L/∂w1 = (e * w2) * x
double dL_db1 = dL_dhidden; // ∂L/∂b1 = e * w2
// 使用梯度下降更新参数(参数 = 参数 - 学习率 * 梯度)
w2 -= learningRate * dL_dw2; // 更新w2
b2 -= learningRate * dL_db2; // 更新b2
w1 -= learningRate * dL_dw1; // 更新w1
b1 -= learningRate * dL_db1; // 更新b1
}
// 训练一步:执行一次前向传播、损失计算和反向传播
void trainStep(double x, double y) {
// 1. 前向传播得到预测值
double prediction = forward(x);
// 2. 计算当前损失
double lossValue = loss(prediction, y);
// 3. 反向传播更新参数
backward(x, prediction, y);
// 打印训练信息(调试用)
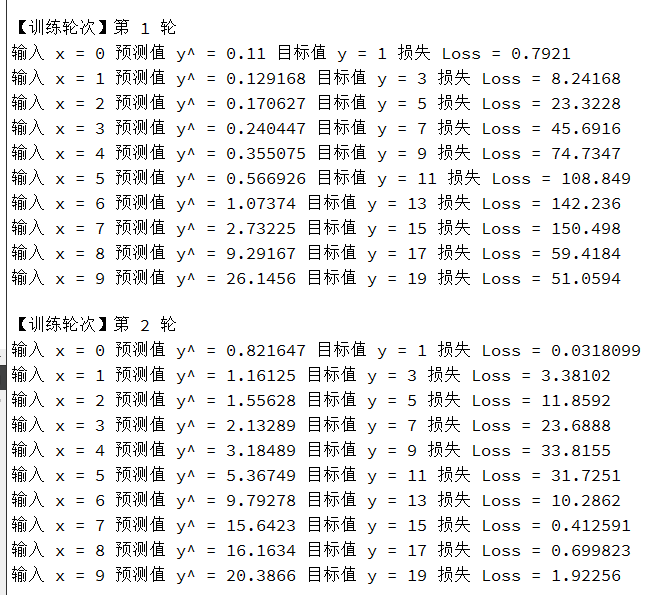
qDebug() << "输入 x =" << x
<< "预测值 y^ =" << prediction
<< "目标值 y =" << y
<< "损失 Loss =" << lossValue;
}
private:
// 网络参数
double w1, b1; // 输入层 -> 隐藏层的权重和偏置
double w2, b2; // 隐藏层 -> 输出层的权重和偏置
double learningRate; // 学习率
// 缓存前向传播的中间值(用于反向传播)
double hiddenOutput; // 隐藏层的输出值
double output; // 网络的最终输出值
};
int main(int argc, char *argv[])
{
// 创建神经网络实例
SimpleNeuralNetwork net;
// 构造训练数据:y = 2x + 1(我们要让网络学习这个线性关系)
std::vector<std::pair<double, double>> trainingData;
for (double x = 0; x < 10; x += 1) {
trainingData.push_back({x, 2 * x + 1}); // 生成(x, y)对
}
// 多轮训练(epoch指完整遍历数据集一次)
for (int epoch = 0; epoch < 1000; ++epoch) {
qDebug() << "\n【训练轮次】第" << epoch + 1 << "轮";
// 遍历所有训练样本
for (const auto& sample : trainingData) {
// 对每个样本执行一次训练步骤
net.trainStep(sample.first, sample.second);
}
}
// 测试训练好的模型
qDebug() << "\n【测试模型】";
for (double x = 0; x < 5; ++x) {
// 使用训练好的网络进行预测
double prediction = net.forward(x);
// 打印预测结果和真实值对比
qDebug() << "输入 x =" << x
<< "预测输出 y^ =" << prediction
<< "真实输出 y =" << (2 * x + 1);
}
}

前向传播(Forward Propagation)
输入数据通过网络层层计算,得到输出。就是从输入到输出的"推理"过程。
从forward函数可以看出这个神经网络具有:
- 输入层:1 个神经元,接收输入 x
- 隐藏层:1 个神经元,使用线性激活(即没有激活函数)
- 输出层:1 个神经元,输出预测值 y^

损失函数(Loss Function)
衡量预测值与真实值之间的误差。

这里使用的是回归任务中常用的损失函数。
反向传播(Backward Propagation)
根据损失函数的梯度,反向调整网络参数。


实际上训练的结果是得到一组参数,这组参数带入到forward可以对输入内容做出预测。
以下这个版本是计算预测x^2的值, x^2函数图像是非线性的,要加上激活函数:
cpp
// Sigmoid 激活函数
double sigmoid(double x) {
return 1.0 / (1.0 + exp(-x));
}
// Sigmoid 导数(用于反向传播)
double sigmoidDerivative(double x) {
double s = sigmoid(x);
return s * (1 - s);
}
// 改进的神经网络类(支持非线性任务)
class SimpleNeuralNetwork {
public:
// 构造函数:初始化网络参数
SimpleNeuralNetwork()
: w1(0.1), b1(0.1), // 输入层到隐藏层的权重和偏置
w2(0.1), b2(0.1), // 隐藏层到输出层的权重和偏置
learningRate(0.1) {} // 学习率设为0.1(非线性任务需要更大的学习率)
// 前向传播函数:计算给定输入x的网络输出(现在使用激活函数)
double forward(double x) {
// 隐藏层计算(使用sigmoid激活函数)
hiddenInput = w1 * x + b1; // 线性变换
hiddenOutput = sigmoid(hiddenInput); // 非线性激活
// 输出层计算(线性变换,不加激活函数以便输出任意值)
output = w2 * hiddenOutput + b2;
return output; // 返回预测值
}
// 计算损失函数(均方误差)
double loss(double predicted, double target) {
return 0.5 * (predicted - target) * (predicted - target); // 乘以0.5方便求导
}
// 反向传播函数:计算梯度并更新参数(考虑激活函数)
void backward(double x, double predicted, double target) {
// 计算预测误差
double error = predicted - target;
// 输出层梯度计算
double dL_dw2 = error * hiddenOutput; // ∂L/∂w2 = e * h
double dL_db2 = error; // ∂L/∂b2 = e
// 隐藏层梯度计算(考虑sigmoid激活函数的导数)
double dL_dhidden = error * w2; // ∂L/∂h = e * w2
// 乘以sigmoid的导数
double dhidden_dz = sigmoidDerivative(hiddenInput); // ∂h/∂z = h*(1-h)
double dL_dz = dL_dhidden * dhidden_dz; // ∂L/∂z = ∂L/∂h * ∂h/∂z
double dL_dw1 = dL_dz * x; // ∂L/∂w1 = ∂L/∂z * x
double dL_db1 = dL_dz; // ∂L/∂b1 = ∂L/∂z
// 使用梯度下降更新参数
w2 -= learningRate * dL_dw2;
b2 -= learningRate * dL_db2;
w1 -= learningRate * dL_dw1;
b1 -= learningRate * dL_db1;
}
// 训练一步:执行一次前向传播、损失计算和反向传播
void trainStep(double x, double y) {
double prediction = forward(x);
double lossValue = loss(prediction, y);
backward(x, prediction, y);
qDebug() << "输入 x =" << x
<< "预测值 y^ =" << prediction
<< "目标值 y =" << y
<< "损失 Loss =" << lossValue;
}
void show() {
qDebug() << "网络参数:";
qDebug() << "w1 = " << w1;
qDebug() << "b1 = " << b1;
qDebug() << "w2 = " << w2;
qDebug() << "b2 = " << b2;
}
private:
// 网络参数
double w1, b1; // 输入层 -> 隐藏层的权重和偏置
double w2, b2; // 隐藏层 -> 输出层的权重和偏置
double learningRate; // 学习率
// 缓存前向传播的中间值(用于反向传播)
double hiddenInput; // 隐藏层的输入值(激活函数之前)
double hiddenOutput; // 隐藏层的输出值(激活函数之后)
double output; // 网络的最终输出值
};
int main(int argc, char *argv[]) {
// 创建神经网络实例
SimpleNeuralNetwork net;
// 构造非线性训练数据:y = x^2(我们要让网络学习这个非线性关系)
std::vector<std::pair<double, double>> trainingData;
for (double x = -2.0; x <= 2.0; x += 0.2) {
trainingData.push_back({x, x * x}); // 生成(x, x^2)对
}
// 多轮训练
for (int epoch = 0; epoch < 1000; ++epoch) {
qDebug() << "\n【训练轮次】第" << epoch + 1 << "轮";
// 遍历所有训练样本
for (const auto& sample : trainingData) {
net.trainStep(sample.first, sample.second);
}
}
// 测试训练好的模型
qDebug() << "\n【测试模型】";
for (double x = -2.0; x <= 2.0; x += 0.5) {
double prediction = net.forward(x);
qDebug() << "输入 x =" << x
<< "预测输出 y^ =" << prediction
<< "真实输出 y =" << (x * x)
<< "误差 =" << (prediction - x * x);
}
net.show();
}
为什么激活函数使神经网络能够学习非线性关系
在没有激活函数时,神经网络只是多个线性变换的组合:
输出 = W₂(W₁X + b₁) + b₂ = (W₂W₁)X + (W₂b₁ + b₂)
这可以简化为:
输出 = W'X + b'
无论你堆叠多少层线性变换,最终结果仍然是一个线性变换。这意味着:
- 网络只能学习线性关系
- 无法解决非线性问题
- 深度网络不会比单层网络更强大
当在层与层之间加入非线性激活函数(如sigmoid、ReLU等)时:
隐藏层输出 = σ(W₁X + b₁) // σ表示激活函数
最终输出 = W₂(隐藏层输出) + b₂
现在网络不再是简单的线性组合,因为激活函数引入了非线性。这使得网络可以表示非线性函数:每个激活函数就像一个"弯曲器",将线性变换的结果进行非线性扭曲。通过组合多个这样的非线性变换,网络可以逼近任意复杂的非线性函数。
直观理解,想象要用乐高积木拼出一个圆形:
- 只有直线积木(无激活函数):只能拼出多边形,永远无法接近圆形
- 有弯曲积木(激活函数):可以用许多小弯曲积木拼出接近完美的圆形
激活函数就是提供了这些"弯曲积木",使网络能够构造复杂的非线性形状。