我们来看最复杂的部分,就是Term Dictionary和Term Index文件,Term Dictionary文件的后缀名为tim,Term Index文件的后缀名是tip,格式如图所示。

Term Dictionary文件首先是一个Header,接下来是PostingsHeader,这两个的格式一致,但是保存的是不同的信息。SkipInterval是跳跃表的跳的幅度,MaxSkipLevels是跳跃表的层数,SkipMinimun是应用跳跃表的最小倒排表长度,接下来就是Term的部分了。
在tim文件中,Term是分成Block进行保存的,如何将Term进行分块,则需要和tip文件配合。Term Index文件对于每一个Field都保存一个FSTIndex来帮助快速定位tim文件中属于这个Field的Term的位置,由于FSTIndex的长度不同,为了快速定位某个Field的位置,则应用指针列表规则,为每一个Field保存了指向这个Field的FSTIndex的指针。
FST全程是Finite State Transducers,是一个带输出的有限状态机,看过前面有限状态机规则的可以知道,有限状态机逻辑上来讲就是一颗树,就像图3-71中的那棵树,从初始状态输入字符a到达状态a,输入字符b到达状态b,输入字符d到达状态d,不同的是状态d有输出,所谓的输出就是一个指针,指向tim文件中的位置。
java
public BlockTreeTermsWriter(SegmentWriteState state, PostingsWriterBase postingsWriter, int minItemsInBlock, int maxItemsInBlock) throws IOException {
// 构造方法,用于初始化 BlockTreeTermsWriter,负责构建 Lucene 索引中的词项字典相关文件(.tim、.tip 等)
// 参数说明:
// state:包含当前段(segment)的写入状态信息,比如段名称、目录、上下文等,是 Lucene 索引写入时传递环境信息的载体
// postingsWriter:负责 postings 列表(倒排表中记录文档关联信息的部分)写入的基础组件,这里具体类型是 Lucene40PostingsWriter
// minItemsInBlock、maxItemsInBlock:控制 BlockTree 结构中每个块(block)容纳词项数量的上下限,影响索引的存储和查询效率
// ===================== 写入 .tim 文件(词项数据主文件) =====================
// 生成 .tim 文件的名称,遵循 Lucene 索引文件命名规则,结合段名称、后缀等
final String termsFileName = IndexFileNames.segmentFileName(state.segmentInfo.name, state.segmentSuffix, TERMS_EXTENSION);
// 创建用于写入 .tim 文件的输出流,state.directory 是索引文件存储的目录对象,负责文件的创建、读写等操作
out = state.directory.createOutput(termsFileName, state.context);
IndexOutput indexOut = null;
// 写入 .tim 文件的文件头,通过 CodecUtil.writeHeader 方法,标记文件类型(TERMS_CODEC_NAME)和版本(TERMS_VERSION_CURRENT)
// 这一步是为了让 Lucene 后续读取时能识别文件格式,确保兼容性
writeHeader(out);
// ===================== 写入 .tip 文件(词项索引文件,辅助快速查找) =====================
// 生成 .tip 文件的名称,同样遵循 Lucene 索引文件命名规则,后缀为 TERMS_INDEX_EXTENSION
final String termsIndexFileName = IndexFileNames.segmentFileName(state.segmentInfo.name, state.segmentSuffix, TERMS_INDEX_EXTENSION);
// 创建用于写入 .tip 文件的输出流
indexOut = state.directory.createOutput(termsIndexFileName, state.context);
// 写入 .tip 文件的文件头,标记文件类型(TERMS_INDEX_CODEC_NAME)和版本(TERMS_INDEX_VERSION_CURRENT)
writeIndexHeader(indexOut);
// ===================== 初始化 postingsWriter 相关 =====================
// 这里明确 postingsWriter 的具体类型,Lucene40PostingsWriter 是 Lucene 4.0 版本风格的 postings 写入实现
// 它负责处理倒排表中词项对应的文档编号、词频、位置等详细信息的写入
this.postingsWriter = postingsWriter;
// 调用 postingsWriter 的 start 方法,传入 .tim 文件的输出流,准备开始写入 postings 相关数据
// 后续在处理词项时,postingsWriter 会把对应的倒排表信息写入到 .tim 文件中合适的位置
postingsWriter.start(out);
}关键逻辑梳理
- 文件创建 :分别创建
.tim(存储词项字典等核心数据 )和.tip(存储词项索引,用于加速查询 )文件的输出流,这两类文件是 Lucene 索引中词项字典(Terms Dictionary)的重要组成部分。 - 文件头写入 :通过
writeHeader和writeIndexHeader方法,为.tim和.tip文件写入头信息,标记文件类型和版本,方便 Lucene 后续读取时做格式校验和兼容性处理。 - postingsWriter 初始化 :关联负责倒排表写入的
Lucene40PostingsWriter,并调用其start方法,准备好将词项对应的倒排表数据(文档关联信息 )写入到.tim文件中,与词项字典数据协同构成完整的索引结构,支撑 Lucene 的搜索功能。
java
public void start(IndexOutput termsOut) throws IOException {
// 方法作用:初始化 postings 写入相关的输出流,为后续写入 postings 头信息等做准备
// 参数 termsOut:指向 Lucene 索引文件(通常是 .tim 文件,存储词项及倒排表相关数据 )的输出流,后续要往这个流里写 postings 相关内容
// 将传入的输出流保存到当前对象的成员变量,方便后续其他方法使用该流写入数据
this.termsOut = termsOut;
// 预留的逻辑位置,后续实际会在这里写入 postings 头信息(对应第二段代码的具体实现 )
// 写入 PostingHeader
}
java
CodecUtil.writeHeader(termsOut, TERMS_CODEC, VERSION_CURRENT);
// 调用 CodecUtil 的 writeHeader 方法,写入 postings 数据相关的文件头
// 参数说明:
// termsOut:就是前面保存的输出流,要往这个流对应的文件(比如 .tim )里写头信息
// TERMS_CODEC:标记当前使用的编解码器名称,Lucene 用它来识别文件格式,确保读写兼容性
// VERSION_CURRENT:当前编解码器的版本号,后续读取时会校验版本,处理可能的兼容性逻辑
termsOut.writeInt(skipInterval);
// 写入 skipInterval 的值,它是 Lucene 中用于倒排表跳跃查询的一个参数
// 作用是控制在倒排表中,每隔多少个文档记录就设置一个"跳跃点",加速查询时跳过无关数据,提升搜索效率
// 举例:如果 skipInterval=16,可能每 16 个文档就设置一个跳跃标记,查询时可快速跳过这 16 个之前的文档
termsOut.writeInt(maxSkipLevels);
// 写入 maxSkipLevels 的值,它决定了跳跃查询的层级数
// 多层跳跃可以进一步优化查询性能,比如不同层级设置不同的跳跃间隔,从粗到细定位数据
// 比如 maxSkipLevels=2,可能有两层跳跃结构,第一层间隔大、第二层间隔小,配合加快查找
termsOut.writeInt(skipMinimum);
// 写入 skipMinimum 的值,它是启用跳跃查询的最小文档数量阈值
// 当倒排表中的文档数量超过这个阈值时,才会启用跳跃查询优化;如果文档数少,直接顺序遍历可能更快
// 举例:skipMinimum=100,当倒排表文档数≥100 时,用跳跃查询;<100 时,直接遍历整体逻辑串联
这两段代码是 Lucene 索引构建中,倒排表(postings)写入流程的初始化环节:
- 先通过
start方法拿到写入.tim文件的输出流并保存; - 然后调用
CodecUtil.writeHeader写入文件头,标记编解码器和版本; - 接着写入
skipInterval、maxSkipLevels、skipMinimum这几个和倒排表跳跃查询优化相关的参数,为后续高效存储和查询倒排表数据做准备。
下面咱们具体讨论,Term如何分块,Block如何写入,FSTIndex如何构造。
我们首先通过一个简单的例子,来看一下一个普通的FST是如何构造的,Lucene的文档里面给了类似下面这样一个例子。
java
public static void main(String[] args) throws IOException {
// main 方法,程序入口,throws IOException 表示可能抛出 IO 异常(构建 FST 涉及文件/内存操作时可能出现)
String inputValues[] = { "abd", "abe", "acf" };
// 定义输入的字符串数组,这些字符串将作为 FST 的键(key),后续用于构建状态转移
byte[][] outputValues = { { 1, 2 }, { 3, 4 }, { 5, 6 } };
// 定义与输入对应的输出字节数组,每个输入字符串对应一个输出值,FST 会建立键到输出的映射
Outputs<BytesRef> outputs = ByteSequenceOutputs.getSingleton();
// 获取 ByteSequenceOutputs 的单例实例,用于处理 FST 的输出类型(这里输出是字节序列)
// ByteSequenceOutputs 专门处理以 BytesRef 为类型的输出合并、计算等逻辑
Builder<BytesRef> builder = new Builder<>(FST.INPUT_TYPE.BYTE1, outputs);
// 创建 FST 的构建器(Builder)
// FST.INPUT_TYPE.BYTE1 表示输入的每个字符用 1 个字节编码(比如 ASCII 字符)
// outputs 传入上面获取的输出处理器,让构建器知道如何处理输出数据
BytesRef scratchBytes = new BytesRef();
// 临时的 BytesRef 对象,用于存储转换过程中的字符串字节表示,避免频繁创建对象
IntsRef scratchInts = new IntsRef();
// 临时的 IntsRef 对象,用于存储将字符串转换为整数序列(FST 内部用整数表示字符)的结果
for (int i = 0; i < inputValues.length; i++) {
// 遍历输入的字符串数组,逐个将字符串加入 FST 构建流程
scratchBytes.copyChars(inputValues[i]);
// 将当前字符串(如 "abd")复制到 scratchBytes 中,转换为字节表示
// 这一步是为了后续将字符串转为 FST 内部需要的整数序列
builder.add(Util.toIntsRef(scratchBytes, scratchInts), new BytesRef(outputValues[i]));
// 向构建器添加键值对,用于构建 FST
// Util.toIntsRef:把 scratchBytes 中的字节数据(字符串)转换为整数序列(每个字符对应一个整数,比如 'a' 对应 97 等,具体看编码),存入 scratchInts
// new BytesRef(outputValues[i]):创建一个 BytesRef 封装当前输入对应的输出字节数组,作为 FST 中该键对应的输出
}
FST<BytesRef> fst = builder.finish();
// 完成 FST 的构建,生成最终的有限状态转换器对象
// 此时,FST 内部已经根据输入的键值对建立了状态转移图、输出映射等结构
BytesRef value = Util.get(fst, new BytesRef("acf"));
// 使用 Util.get 方法查询 FST,根据输入的键(这里是 "acf")查找对应的输出
// new BytesRef("acf"):将查询的字符串转为 BytesRef 格式,符合 FST 的输入要求
// 返回的 value 是 FST 中该键对应的输出字节序列
System.out.println(value);
// 打印查询得到的输出结果,比如对于 "acf" ,会输出对应的 {5,6} 转换后的 BytesRef 形式
}代码核心逻辑梳理
-
数据准备 :定义了输入字符串数组
inputValues和对应的输出字节数组outputValues,后续要基于这些数据构建 FST 的键值映射。 -
构建器初始化 :创建
Builder并指定输入类型(BYTE1表示字符用 1 字节编码 )和输出处理器(ByteSequenceOutputs处理字节序列输出 )。 -
逐个添加键值对:遍历输入数据,把每个字符串转为 FST 内部需要的整数序列,再关联对应的输出,逐步构建 FST 的状态转移结构。
-
完成构建与查询 :调用
builder.finish()生成最终的 FST,然后用Util.get根据键(如"acf")查询对应的输出并打印。
这里InputValues是构造FST的输入,是根据这些字符串,构造出图3-71中的那棵树。
OutputValue是有限状态机的输出,由于在实际应用中,输出是一个指向tim文件的一个指针,一般是byte\[\]类型,所以我们也在这里弄了三个byte\[\]作为输出。
Builder就是有限状态机的构造器,它支持多种输出类型,我们这里用byte\[\]作为输出,所以输出类型我们选择BytesRef,这是对byte\[\]的一个封装。
下一步就是用Builder的add函数将输入和输出关联起来,由于builder的输入必须是IntsRef类型,所以需要从字符串转换成为IntsRef类型,输出也要将byte\[\]封装为BytesRef。
Builder的finish函数真正构造一个FST,在内存中形成一个二进制结构,通过它可以通过输入,快速查询输出,例如程序中的给出输入"acf"就能得到输出5 6。
从表面现象来看,我们甚至可以决定FST就是一个hash map,给出输入,得到输出。这就满足了作为Term Dictionary的要求,给出一个字符串,我马上能找到倒排表的位置。
Builder里面一个很重要的成员变量UnCompiledNode\[\] frontier,在FST的构造过程中,它维护整棵FST树,其中里面直接保存的是UnCompiledNode,是当前添加的字符串所形成的状态节点,而前面添加的字符串形成的状态节点通过指针相互引用。
Builder.add函数主要包括四个部分:
java
public void add(IntsRef input, T output) throws IOException {
// add 方法:向 FST 中添加一个键值对(input 是键的整数序列,output 是对应的值)
// IntsRef:Lucene 中用于存储整数序列的结构(输入字符串会被转成字符的整数编码)
// T:输出值的泛型(如 BytesRef、Long 等,由 FST 类型决定)
// (1) 计算和上一个字符串的共同前缀
int pos1 = 0;
// pos1:遍历上一个已添加字符串(lastInput)的指针
int pos2 = input.offset;
// pos2:遍历当前输入字符串(input)的指针(offset 是起始偏移)
final int pos1Stop = Math.min(lastInput.length, input.length);
// 共同前缀的最大可能长度(取两个字符串的较短长度)
while (true) {
// 循环比较字符,找到共同前缀的长度
frontier[pos1].inputCount++;
// 统计当前前缀位置的使用次数(辅助优化,比如判断是否需要分裂节点)
if (pos1 >= pos1Stop || lastInput.ints[pos1] != input.ints[pos2]) {
// 退出条件:要么前缀比较完,要么字符不相等
break;
}
pos1++;
pos2++;
}
final int prefixLenPlus1 = pos1 + 1;
// 共同前缀的长度 +1(用于后续节点分裂)
// 到这里,prefixLenPlus1 表示:
// 上一个字符串和当前字符串的共同前缀长度是 pos1,当前字符串从 pos2 开始是新的部分
// (2) 从尾部一直到公共前缀的节点,将已经确定的状态节点冰封(freeze)
freezeTail(prefixLenPlus1);
// freezeTail:冻结节点,将不再变化的状态写入持久化存储(如字节数组)
// 原因:FST 构建是增量的,新字符串可能共享前缀,当遇到不共享的前缀时,之前的尾部节点不再变化,可以固化
// (3) 将当前的字符串形成状态节点加入到 FST 树中,由 frontier 维护
for (int idx = prefixLenPlus1; idx <= input.length; idx++) {
// 遍历当前字符串中"非共同前缀"的部分(从 prefixLenPlus1 到末尾)
frontier[idx - 1].addArc(input.ints[input.offset + idx - 1], frontier[idx]);
// 添加状态转移弧(Arc):
// 从 frontier[idx-1] 状态,输入字符 input.ints[input.offset + idx -1],转移到 frontier[idx] 状态
// frontier:维护当前构建中的活跃状态节点(类似"正在构建的路径")
frontier[idx].inputCount++;
// 统计新节点的使用次数
}
// 设置输出:将当前键对应的值(output)关联到最终状态节点
frontier[prefixLenPlus1 - 1].setLastOutput(input.ints[input.offset + prefixLenPlus1 - 1], output);
// prefixLenPlus1 -1 是共同前缀的最后一个节点,在此节点设置输出
// 当 FST 遍历到该节点时,会返回对应的 output 值
}举个例子: 假设我们要构建一个 FST,插入以下两个字符串的 key-value 对:
| 输入 | 转换后的 IntsRef | 输出 |
|---|---|---|
| "cat" | 99, 97, 116 | "动物" |
| "car" | 99, 97, 114 | "汽车" |
(其中 99 = 'c', 97 = 'a', 116 = 't', 114 = 'r')
第一次调用:add([99, 97, 116], "动物")
-
lastInput = 空(第一次添加)
-
共同前缀查找:
因为
lastInput是空,pos1Stop = 0,所以直接结束。共同前缀长度 =
0,prefixLenPlus1 = 1 -
冻结尾部节点(freezeTail(1)):
什么都不冻结(因为是第一个)
-
建立节点:
从
idx = 1到input.length = 3,依次添加 Arc:- idx=1:
frontier[0]添加99的 Arc 指向frontier[1] - idx=2:
frontier[1]添加97的 Arc 指向frontier[2] - idx=3:
frontier[2]添加116的 Arc 指向frontier[3]
- idx=1:
-
设置输出:
在
frontier[0](也就是共同前缀长度 - 1 = 0)上对弧
99设置输出"动物"
第二次调用:add([99, 97, 114], "汽车")
-
lastInput = 99, 97, 116
-
共同前缀查找:
- pos1=0,
99 == 99✅ - pos1=1,
97 == 97✅ - pos1=2,
116 != 114❌
停止,共同前缀长度 = 2 ,prefixLenPlus1 = 3
- pos1=0,
-
冻结尾部节点(freezeTail(3)):
把
frontier[3](原来的t节点)冻结,写入 FST,不再变化 -
建立新节点:
需要添加新的分支:
- idx=3:
frontier[2]添加114的 Arc 指向frontier[3](新的)
- idx=3:
-
设置输出:
在
frontier[2]上,input[2] = 114,设置输出"汽车"
此时 FST 结构:
rust
rust
复制编辑
root
└── 'c' ->
└── 'a' ->
├── 't' -> "动物"(冻结了)
└── 'r' -> "汽车"一个疑问:假如现在把cat的t冻结起来,但是之后又来了个catk这样的,那这个怎么处理?
不能 ,如果 "cat" 已经先被添加(且冻结),后面再添加 "catk" 是非法的 ,会抛异常或者断言失败。FST 构建要求输入字符串是有序的(字典序)。
当第一个字符串abd加入之后,frontier的结构如图3-72所示,图中蓝色的节点都是。
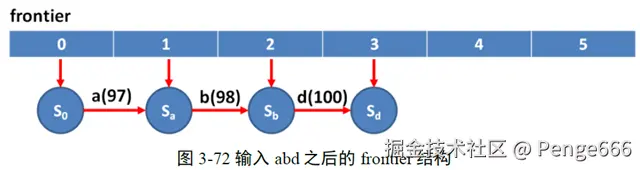
当新的字符串abe之后,首先(1)找出公共前缀ab,则prefixLenPlus1=3。然后调(2)用freezeTail将尾节点Sd进行冰封。为什么要进行冰封(一个形象的说法)呢?因为Sd节点不会再改变了。在实际应用中,字符串都是按照字母顺序依次处理的,上一次的字符串是abd,下一个字符串可能是abdm,再下一个字符串可能是abdn,这都会导致Sd这个节点的变化。然而当abe出现后,说明abd*都不可能出现了,状态Sd也不可能再有新的子节点了,所以Sd也就确定下来了,需要冰封。那么Sb节点要不要冰封呢?当然不行了,因为这次来了abe,下次还可能有abf, abg等等新的Sb的子节点出现,这就是为什么要计算公共前缀了,公共前缀之后的状态节点都是可以冰封的了,而这些冰封的节点都从尾部开始,所以这一步的函数叫freezeTail。
java
private void freezeTail(int prefixLenPlus1) throws IOException {
// freezeTail 方法:冻结 FST 中"尾部节点",将临时构建的状态固化为持久化结构
// prefixLenPlus1:共同前缀长度 +1(标记新、旧字符串的分裂点)
if (freezeTail != null) {
// 如果存在自定义的 freezeTail 实现(可能是扩展或优化逻辑)
freezeTail.freeze(frontier, prefixLenPlus1, lastInput);
// 调用自定义实现,冻结节点(将 frontier 中的临时节点写入持久化存储)
} else {
// 默认冻结逻辑(未自定义时执行)
final int downTo = Math.max(1, prefixLenPlus1);
// 计算冻结的起始位置:至少从 1 开始,或从 prefixLenPlus1 开始(取较大值)
// 作用:确定需要冻结的节点范围(从尾部往共同前缀方向遍历)
for (int idx = lastInput.length; idx >= downTo; idx--) {
// 从"上一个字符串的长度"开始,往共同前缀方向遍历(倒序处理节点)
// lastInput:上一个添加的字符串对应的整数序列
final UnCompiledNode<T> node = frontier[idx];
// 获取当前 frontier 中的临时节点(UnCompiledNode 是构建过程中的临时状态)
final UnCompiledNode<T> parent = frontier[idx - 1];
// 获取当前节点的父节点(同样是临时状态)
// 省略部分代码(可能是计算 output、isFinal 等辅助逻辑)......
parent.replaceLast(
lastInput.ints[lastInput.offset + idx - 1],
// 父节点到当前节点的转移字符(从 lastInput 中提取)
compileNode(node, 1 + lastInput.length - idx),
// 编译当前节点为持久化结构(将临时节点转为 FST 可存储的格式)
nextFinalOutput,
// 输出值(关联到节点的最终输出)
isFinal
// 是否为最终节点(是否对应一个完整的键)
);
// replaceLast:替换父节点的最后一个转移弧,将临时节点替换为编译后的持久化节点
// 这一步是核心:将构建过程中的临时状态(frontier 中的节点)固化为 FST 的持久化结构
}
}
}freezeTail主要有两个分支,在Builder构造的时候,用户可以传进自己的freezeTail,如果用户指定了,则调用它的freeze函数,如果没有指定,则执行else部分默认的行为。在这里,我们使用默认行为,在后面的代码分析中,我们还能看到使用自己的freezeTail的情况。
默认行为中,从尾部到公共前缀节点,对于每个状态节点,调用compileNode函数。在这之前,frontier里面保存的都是UnCompiledNode,经过compileNode函数后,就变成了CompiledNode,并从frontier摘下来,parent.replaceLast函数将父节点的指针指向新的CompiledNode。所谓compile过程,就是将内存中的数据结构变成二进制。
compileNode最终调用org.apache.lucene.util.fst.FST.addNode(UnCompiledNode),代码如下:
java
int addNode(Builder.UnCompiledNode<T> nodeIn) throws IOException {
// addNode 方法:将未编译的节点(UnCompiledNode)编译为持久化结构,写入 FST 的字节存储
// 返回值:节点在 FST 中的地址(或特殊标记,如 FINAL_END_NODE)
// 如果没有出度则直接返回
if (nodeIn.numArcs == 0) {
// numArcs:节点的出边数量(没有出边说明是叶子节点)
if (nodeIn.isFinal) {
// isFinal:节点是否是最终节点(对应一个完整的键)
return FINAL_END_NODE;
// 返回"最终叶子节点"标记
} else {
return NON_FINAL_END_NODE;
// 返回"非最终叶子节点"标记
}
}
int startAddress = writer.posWrite;
// 记录当前写入位置(作为节点的起始地址)
// writer:负责写入字节数据的工具(如 IndexOutput 的封装)
// 省略部分代码(可能是初始化、辅助变量声明等)......
// 对于每一个边,写入目标的节点
for (int arcIdx = 0; arcIdx < nodeIn.numArcs; arcIdx++) {
// 遍历节点的所有出边
final Builder.Arc<T> arc = nodeIn.arcs[arcIdx];
// 获取当前边(Arc):包含 label(转移字符)、target(目标节点)、output(输出值)等信息
final Builder.CompiledNode target = (Builder.CompiledNode) arc.target;
// 将目标节点转为已编译的节点(CompiledNode 是持久化后的节点结构)
int flags = 0;
// flags:边的标记位(如是否有输出、是否是最终节点等,用于压缩存储)
// 省略部分代码(可能是计算 flags 的逻辑,如判断 output 是否存在、是否是最终节点等)......
// 首先生成 flags,然后写入 flags
writer.writeByte((byte) flags);
// 将 flags 写入字节流(1 个字节)
// 写入 label
writeLabel(arc.label);
// 写入边的转移字符(label):可能是字符的整数编码,根据 FST 配置的输入类型(如 BYTE1)编码
// 写入 output
if (arc.output != NO_OUTPUT) {
// 如果边有输出值(非空)
outputs.write(arc.output, writer);
// 将输出值写入字节流(outputs 是 Outputs 类型,负责输出值的编码)
arcWithOutputCount++;
// 统计有输出的边数量(辅助优化或校验)
}
// 省略部分代码(可能是处理 target 节点的递归编译、地址记录等)......
}
final int endAddress = writer.posWrite - 1;
// 计算节点写入后的结束地址
// 将写入的内容翻转
int left = startAddress;
int right = endAddress;
while (left < right) {
// 交换 left 和 right 位置的字节(类似字符串反转)
// 作用:可能与 FST 的读取顺序有关(如小端序、大端序转换,或优化缓存访问)
byte temp = writer.getByte(left);
writer.setByte(left, writer.getByte(right));
writer.setByte(right, temp);
left++;
right--;
}
// 省略部分代码(可能是返回节点地址、更新统计信息等)......
}然后(3)将新的input添加到frontier之后,变成如图3-73的数据结构。
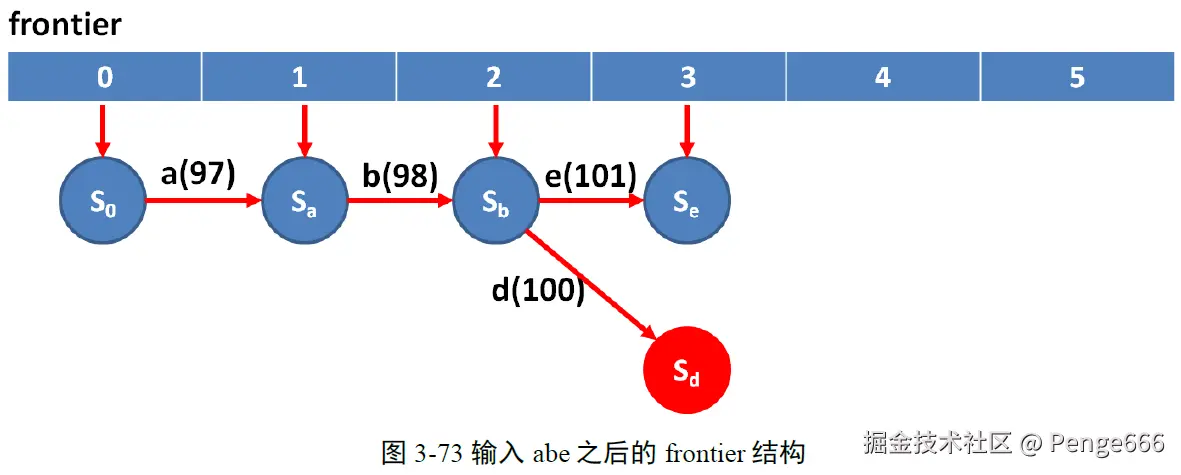
依次类推,当添加acf之后,frontier变成如下的数据结构。

最后调用Builder的finish函数生成FST,代码如下:
第一段代码:finish 方法起始部分
java
public FST<T> finish() throws IOException {
// finish 方法:完成 FST 的构建,将临时构建的结构(frontier 中的节点)最终固化为可查询的 FST 对象
final UnCompiledNode<T> root = frontier[0];
// 获取 FST 的根节点(frontier[0] 存储的是构建过程中维护的根节点临时结构)
// UnCompiledNode:构建过程中使用的未编译、临时的节点结构
// 从根节点开始冰封
freezeTail(0);
// 调用 freezeTail 方法,从根节点(索引 0 对应的节点)开始冻结节点
// 冻结操作会将临时构建的节点结构逐步固化为持久化的 FST 存储格式第二段代码:finish 方法后续部分
java
// 省略的代码:可能包含一些中间处理逻辑,比如对构建过程中统计信息的整理、
// 对未处理节点的收尾操作等,但核心是为最终编译成二进制做准备
// 最终 compile 成为二进制
fst.finish(compileNode(root, lastInput.length).node);
// compileNode:将根节点(root)及关联的整个临时节点结构编译为持久化的节点表示
// lastInput.length:上一个输入字符串的长度,辅助确定编译的范围等
// fst.finish:将编译后的根节点设置到 FST 对象中,完成 FST 的构建收尾,使其可用于查询
return fst;
// 返回构建完成的 FST 对象,外部可以用这个对象进行键值查询等操作
}成的二进制数组如图3-75所示,由于有内容翻转,所以解析的时候需要从右向左解析。

了解了最基本的FST的原理之后,让我们来一步一步通过代码,了解tim和tip文件的block和FSTIndex是如何生成的。
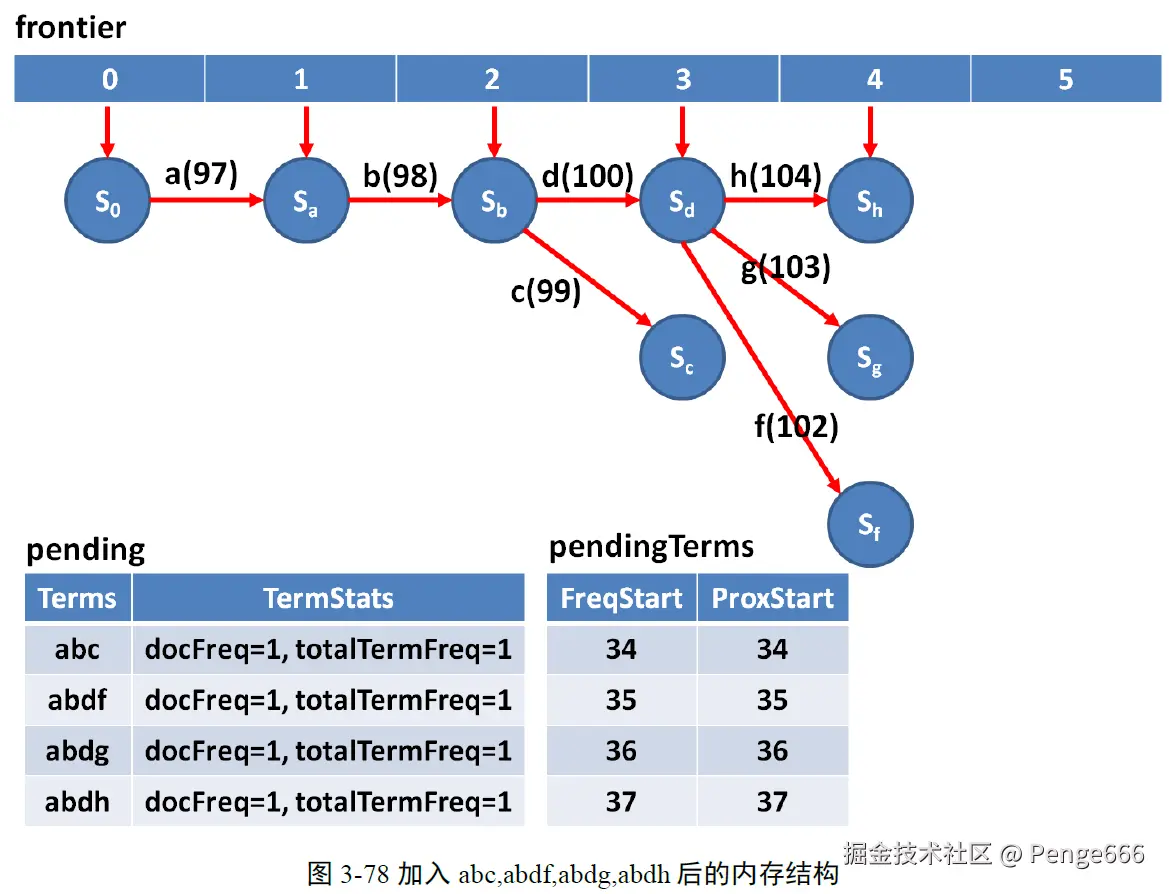
我们以下图3-76为例子。默认情况下,BlockTreeTermsWriter有两个静态变量,DEFAULT_MIN_BLOCK_SIZE=25,DEFAULT_MAX_BLOCK_SIZE=48,MIN的意思是当某个状态节点的子节点个数超过25个的时候,可以写成一个Block,MAX的意思是当个数超过48的时候,则写成多个Block,多个Block构成一个层级Block。为了能够清晰的解析代码,我们设DEFAULT_MIN_BLOCK_SIZE=2,DEFAULT_MAX_BLOCK_SIZE=4。我们仅仅添加一篇文档,里面的Term依次为 abc abdf abdg abdh abei abej abek abel abem aben。所形成的状态树如图所示,根据MIN和MAX的设置,f, g, h会写成一个Block,i, j, k, l, m, n写成一个层级Block,c, d, e写成一个Block。我们之所以把从a到n的十进制和十六进制列在这里,是因为在eclipse中,有时候字符显示的是十进制,有时候是十六进制,当看到这些数值的时候,知道是这些字符即可。

写tim和tip文件的过程纷繁复杂,下面的流程图3-77作为一个线索

finishTerm的blockBuilder是没有output的,这个blockBuilder是用来进行Term分块的,而不是用来生成FSTIndex的。blockBuilder.add函数的流程和上面的叙述过的FST基本原理中的过程基本一致,不同的是blockBuilder是被用户指定了freezeTail的,为org.apache.lucene.codecs.BlockTreeTermsWriter.TermsWriter.FindBlocks,所以freezeTail调用的是FindBlocks.freeze函数。这个freeze函数仅仅处理子节点的个数大于min的节点,调用writeBlocks函数将子节点写成block,对于不满足这个条件的节点,仅仅从frontier上摘下来,不做其他操作。
在整个过程中,维护两个成员变量,一个是List pending保存尚未处理的Term或者block,对于Term,里面保存这个Term的text,docFreq,totalTermFreq信息。另一个是pendingTerms,保存尚未处理的Term的freqStart和proxStart信息。
当加入abc,abdf,abdg,abdh之后,frontier成为如下的结构,在这个过程FindBlock.freeze什么都不做。这个时候的pending和pendingTerms也如图所示。