什么是 BM25?
BM25(Best Matching 25)是一种改进的 TF-IDF 排序算法,在 Elasticsearch 中默认作为相关性计算模型。相比 TF-IDF,BM25 更好地考虑了:
- 词频饱和(Term Frequency Saturation)
- 文档长度归一化(Document Length Normalization)
BM25 的基本公式拆解
最终得分的计算可以表示为:
scss
score(freq) = boost × idf × tf其中三部分分别是:
1. TF 子公式(词频饱和处理)
css
tf = freq / (freq + k1 * (1 - b + b * (dl / avgdl)))freq: 查询词在当前文档中的出现次数dl: 当前文档的长度(token 数)avgdl: 所有文档的平均长度k1: 调节词频饱和程度的参数(默认 1.2)b: 控制文档长度归一化的程度(默认 0.75)
这个公式体现了"频率越高,得分越高,但增长逐渐变缓"的特性。
2. IDF 子公式(逆文档频率)
scss
idf = log(1 + (N - n + 0.5) / (n + 0.5))N: 索引中总文档数量n: 包含查询词的文档数量
IDF 越大说明词越稀有,越能区分文档,得分越高。
3. Score 完整公式
假设 freq = 3,boost = 1.0,则:
css
score(freq=3) = idf × (3 / (3 + k1 * (1 - b + b * (dl / avgdl))))参数含义与影响分析
参数一:k1(TF 饱和调节器)
- 典型取值:
1.2(Elasticsearch 默认) - 意义:决定词频增长的"速度"
| k1 值 | 影响 |
|---|---|
| 较小 | TF 饱和快,词频影响小(更关注是否包含) |
| 较大 | TF 饱和慢,词频影响大(更关注出现次数) |
固定 b,观察 k1 的变化效果:
- 当
k1 → 0,公式趋于布尔匹配(是否包含) - 当
k1 → ∞,公式趋于线性 TF 权重(TFIDF 形式)
推荐 :在语料差异大时适当提高 k1 会强化词频的区分能力。
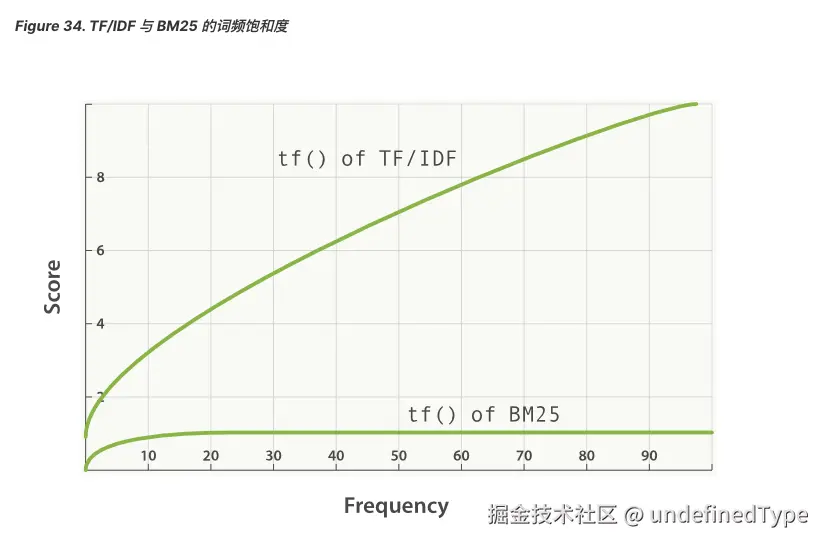
补充 :BM25 有一个上限,文档里出现 5 到 10 次的词会比那些只出现一两次的对相关度有着显著影响。但是如图 TF/IDF 与 BM25 的词频饱和度 所见,文档中出现 20 次的词几乎与那些出现上千次的词有着相同的影响。
这就是 非线性词频饱和度(nonlinear term-frequency saturation) 。
参数二:b(文档长度归一化调节器)
- 典型取值:
0.75(Elasticsearch 默认) - 意义:是否惩罚/奖励过长或过短的文档
| b 值 | 影响 |
|---|---|
| 0 | 忽略文档长度,类似 TF-IDF |
| 1 | 完全应用文档长度归一化 |
固定 k1,观察 b 的变化效果:
b=0:对所有文档一视同仁(不管文档长短)b=1:长文档的 TF 会被显著缩小(被惩罚)- 适当调低 b 可防止短文档因词频密度高而得分过高
推荐:长文档较多的场景(如新闻、文档库)可适当增加 b,防止评分偏差。
总结
| 参数变化 | 评分变化趋势(定性) | 场景建议 |
|---|---|---|
| ↑ k1 | 提升高 TF 文档得分,增强 TF 区分度 | 关键词重复较多的文档 |
| ↓ k1 | TF 区分度降低,趋于布尔匹配 | 简短文档,高相关词命中 |
| ↑ b | 长文档得分下降,短文档得分上升 | 需要防止"水文"得分高的场景 |
| ↓ b | 忽略长度影响,仅依赖 TF | 文档长度差异不大 |
Elasticsearch 中如何使用 BM25?
BM25 是默认的相似度算法。你也可以在 mapping 中手动设置:
css
PUT my_index
{
"settings": {
"similarity": {
"default": {
"type": "BM25",
"k1": 1.2,
"b": 0.75
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text"
}
}
}
}可以按字段指定,只需在映射中为不同字段选定即可:
bash
PUT /my_index
{
"mappings": {
"doc": {
"properties": {
"title": {
"type": "string",
"similarity": "BM25"
},
"body": {
"type": "string",
"similarity": "default"
}
}
}
}配置相似度算法和配置分析器很相似,自定义相似度算法可以在创建索引时指定
bash
PUT /my_index
{
"settings": {
"similarity": {
"my_bm25": {
"type": "BM25",
"b": 0
}
}
},
"mappings": {
"doc": {
"properties": {
"title": {
"type": "string",
"similarity": "my_bm25"
},
"body": {
"type": "string",
"similarity": "BM25"
}
}
}
}
}目前,Elasticsearch 不支持更改已有字段的相似度算法 similarity 映射,只能通过为数据重新建立索引来达到目的。修改 k1、b 后需要 重建索引 并重新导入数据。