前言
想要快速高效率去审计一个项目 一个好的审计工具是必不可少的
历时三天才弄好环境 我吐了
Tabby的环境搭建
项目地址:GitHub - wh1t3p1g/tabby: A CAT called tabby ( Code Analysis Tool )
作者教程:TABBY
环境要求:
java17
Neo4j 图数据库
Tabby的安装
首先 先安装Tabby 这边建议自己Clone下来 然后自己编译一遍 会减少很多报错(下面的也是一样)
Clone下来之后 在执行打包命令:
mvn clean package -DskipTests "-Dfile.encoding=UTF-8"把生成在target下的 tabby.jar包 复制到根目录下
然后就是安装tabby-vul-finder
Clone下来之后打包,另外需要把tabby-vul-finder 下的rules/cyphers.yml 文件复制到tabby的rules文件夹下
如果要使用脚本(run.sh) 参考
window 下 的 run.bat
@echo off
setlocal enabledelayedexpansion
if "%1"=="build" (
echo start to run tabby
java -Xmx16g -jar tabby.jar
) else if "%1"=="load" (
java -jar tabby-vul-finder.jar --load %2
) else if "%1"=="query" (
java -Xms4G -Xmx16G -jar tabby-vul-finder.jar --query %2 %3
) else if "%1"=="pack" (
tar -czvf output.tar.gz .\output\*.csv
) else (
echo Usage:
echo tabby.bat build - Run tabby analysis
echo tabby.bat load ^<arg^> - Load vulnerability data
echo tabby.bat query ^<arg1^> ^<arg2^> - Query vulnerabilities
echo tabby.bat pack - Pack CSV results to output.tar.gz
echo.
echo Note: For 'pack' command, ensure tar.exe is available in PATH
)项目结构
$ tree
.
├── cases # 用于放置待分析的项目,可以是单个文件,也可以是目录
│ └── commons-collections-3.2.1.jar
├── config # 用于放置配置文件
│ ├── db.properties # 配置数据库相关内容
│ └── settings.properties # 配置待分析项目、污点分析等内容
├── output # 用于放置生成后的csv文件
│ └── dev
├── rules # 规则文件夹
│ ├── basicClasses.json
│ ├── commonJars.json # 用于排除无需分析的三方jar
│ ├── cyphers.yml # 用于 tabby-vul-finder 自动化检索
│ ├── sinks.json # 用于配置 sink 函数
│ ├── system.json # 用于配置专家规则
│ └── tags.json # 用于配置source点识别
├── temp # v2.0 版本开始将临时文件都生成到同级temp目录下
├── run.sh # 运行各类任务的bash脚本
├── tabby-vul-finder.jar # 用于导入和自动化查询的 jar
└── tabby.jar # 核心jar,用于生成图数据如果是分析例如CC链,放置 commons-collections-3.2.1.jar 的同时还需要去修改配置文件settings.properties,具体参数详细看
作者文档,笔者在这个里给个参考:
# targets to analyse
tabby.build.target = cases/commons-collections-3.2.1.jar
tabby.build.libraries = libs
#tabby.build.mode = web
tabby.build.mode = gadget
tabby.output.directory = ./output/dev
tabby.build.rules.directory = ./rules
tabby.build.thread.size = max
# settings for jre environments
tabby.build.useSettingJRE = true
tabby.build.isJRE9Module = false
#tabby.build.javaHome = /Library/Java/JavaVirtualMachines/graalvm-jdk-17.0.9+11.1/Contents/Home
#tabby.build.javaHome = /Library/Java/JavaVirtualMachines/zulu-17.jdk/Contents/Home
#tabby.build.javaHome = /Library/Java/JavaVirtualMachines/zulu-21.jdk/Contents/Home
#tabby.build.javaHome = /Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home
tabby.build.javaHome =E:\\JAVA_8U65_NEW
# debug
tabby.debug.details = false
tabby.debug.print.current.methods = true
# jdk settings
tabby.build.isJDKProcess = true
tabby.build.withAllJDK = false
tabby.build.isJDKOnly = false
# dealing fatjar
tabby.build.checkFatJar = true
# set false for debug
tabby.build.removeNotPollutedCallSite = true
# pointed-to analysis types
tabby.build.interProcedural = true
tabby.build.onDemandDrive = false
# pointed-to analysis settings
tabby.build.analysis.everything = true
tabby.build.isPrimTypeNeedToCreate = false
tabby.build.thread.timeout = 2
tabby.build.method.timeout = 5
tabby.build.alias.maxCount = 5
tabby.build.array.maxLength = 25
tabby.build.method.maxDepth = 500
tabby.build.method.maxBodyCount = 8000
tabby.build.object.maxTriggerTimes = 300
tabby.build.object.field.k.limit = 10
tabby.build.with.cache.enable = false
tabby.build.isNeedToCreateIgnoreList = false
tabby.build.isNeedToDealNewAddedMethod = true
tabby.build.timeout.forceStop = true
# plugin settings
tabby.build.isNeedToProcessXml = trueNeo4j配置
推荐是去下载社区版的Neo4j Deployment Center - Graph Database & Analytics
但是社区版一些高版本是没有Neo4j浏览器的 ,笔者这里选择的是下载桌面版的
有几个注意点:
桌面版打不开的问题:先断网在去打开桌面版就会弹出界面了
数据库启动问题,这边建议是在桌面版的软件去启动,而不是去文件夹中自己启动
上传数据崩溃问题,需要调整内存分配,一定要调整,不然几乎用不了
下载完之后打开:
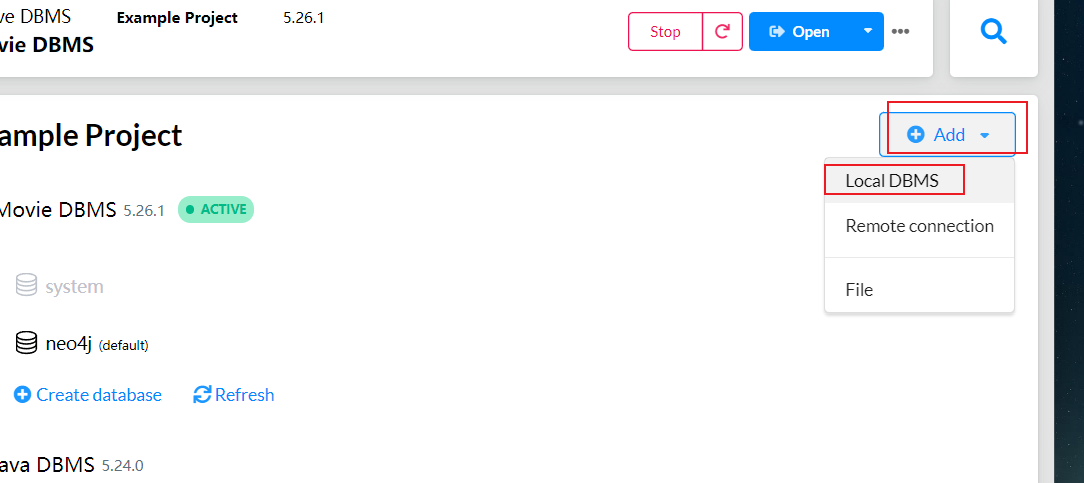
下拉选择版本(这里需要挂梯子 不然版本出不来) 选择5.26.1 这个版本插件没什么问题
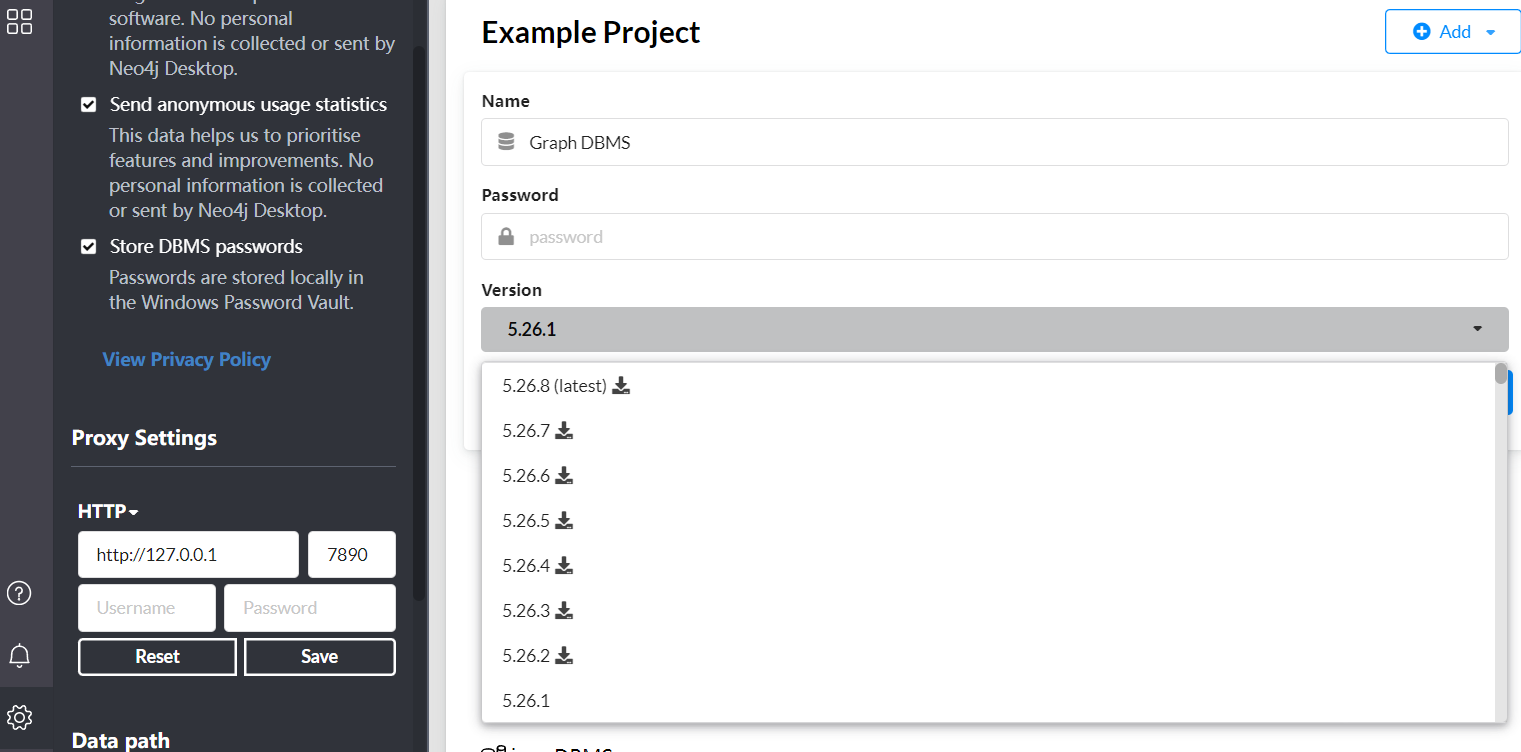
创建好之后 进行修改配置:
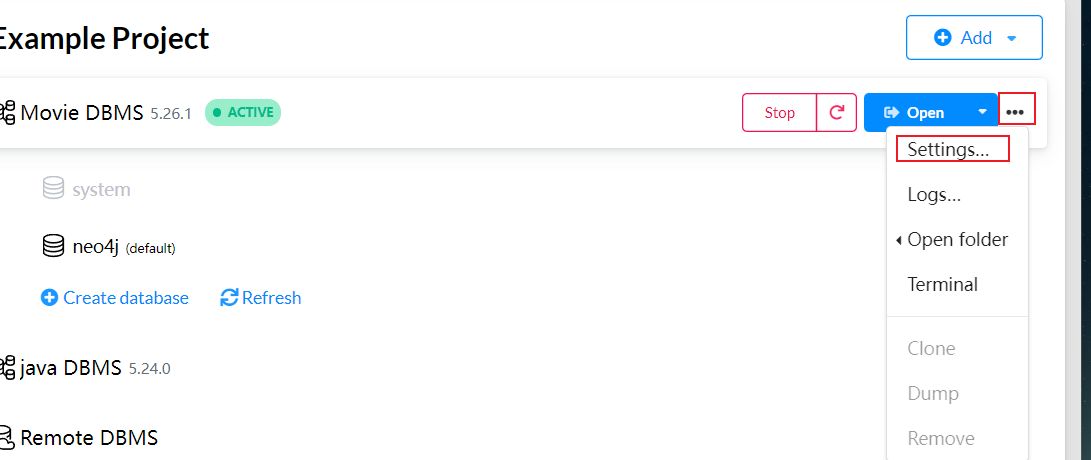

# 注释下面的配置,允许从本地任意位置载入csv文件
#server.directories.import=import
# 允许 apoc 扩展
dbms.security.procedures.unrestricted=jwt.security.*,apoc.*然后下滑到最下面:修改允许内存配置,这里不改 上传数据的时候数据库就会崩
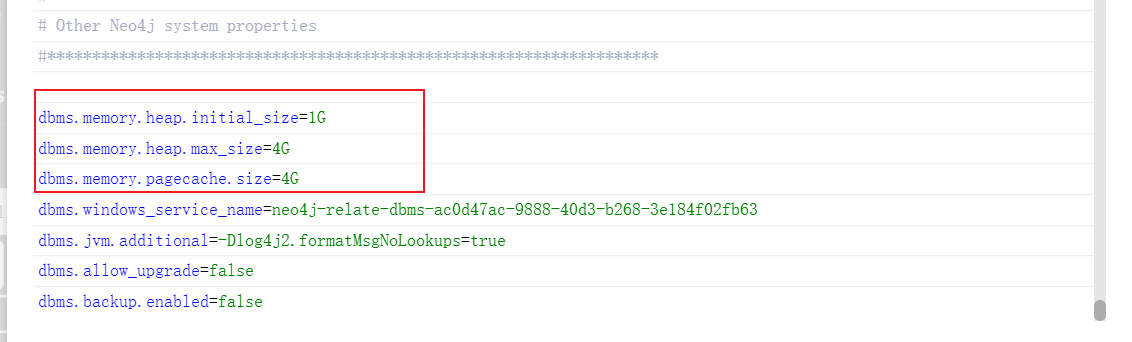
然后就是数据库的配置文件和插件:
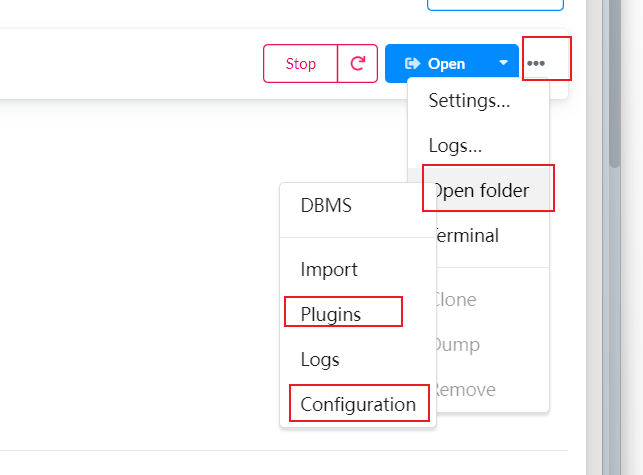
先选择最下面那个:
新建 apoc.conf 文件
apoc.import.file.enabled=true
apoc.import.file.use_neo4j_config=false然后在去下载插件:
apoc 插件
Neo4j v5 版本 apoc 插件改成了两个部分 apoc-core 和 apoc-extend,可自行在以下两个库下载
- apoc-core https://github.com/neo4j/apoc
- apoc-extended https://github.com/neo4j-contrib/neo4j-apoc-procedures
关于 apoc 插件的版本选择方法:Neo4j 数据库版本的前两位对应 apoc 插件的版本
比如 Neo4j 数据库版本为 v5.3.0,则选择 apoc 插件 v5.3.x 版本
tabby-path-finder 插件
该插件集成了图上的污点传递规则,可以进一步减少误报链路的产生。
项目地址 https://github.com/wh1t3p1g/tabby-path-finder,下载打包生成对应 jar 文件
然后全部放在plugins目录下
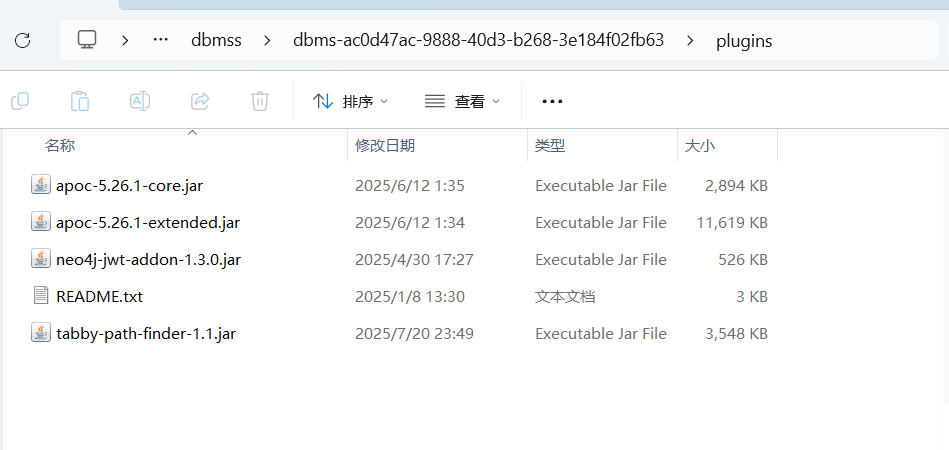
然后回到Tabby文件夹下:新建config/db.properties
# for docker
tabby.cache.isDockerImportPath = false
# db settings
tabby.neo4j.username = neo4j
tabby.neo4j.password = password
tabby.neo4j.url = bolt://127.0.0.1:7687图数据库索引配置(必做项)
为了加快导入/删除的速度,这里提前对节点进行索引建立
这下面的会报错,不影响使用
CREATE CONSTRAINT c1 IF NOT EXISTS FOR (c:Class) REQUIRE c.ID IS UNIQUE;
CREATE CONSTRAINT c2 IF NOT EXISTS FOR (c:Class) REQUIRE c.NAME IS UNIQUE;
CREATE CONSTRAINT c3 IF NOT EXISTS FOR (m:Method) REQUIRE m.ID IS UNIQUE;
CREATE CONSTRAINT c4 IF NOT EXISTS FOR (m:Method) REQUIRE m.SIGNATURE IS UNIQUE;
CREATE INDEX index1 IF NOT EXISTS FOR (m:Method) ON (m.NAME);
CREATE INDEX index2 IF NOT EXISTS FOR (m:Method) ON (m.CLASSNAME);
CREATE INDEX index3 IF NOT EXISTS FOR (m:Method) ON (m.NAME, m.CLASSNAME);
CREATE INDEX index4 IF NOT EXISTS FOR (m:Method) ON (m.NAME, m.NAME0);
CREATE INDEX index5 IF NOT EXISTS FOR (m:Method) ON (m.SIGNATURE);
CREATE INDEX index6 IF NOT EXISTS FOR (m:Method) ON (m.NAME0);
CREATE INDEX index7 IF NOT EXISTS FOR (m:Method) ON (m.NAME0, m.CLASSNAME);
:schema //查看表库
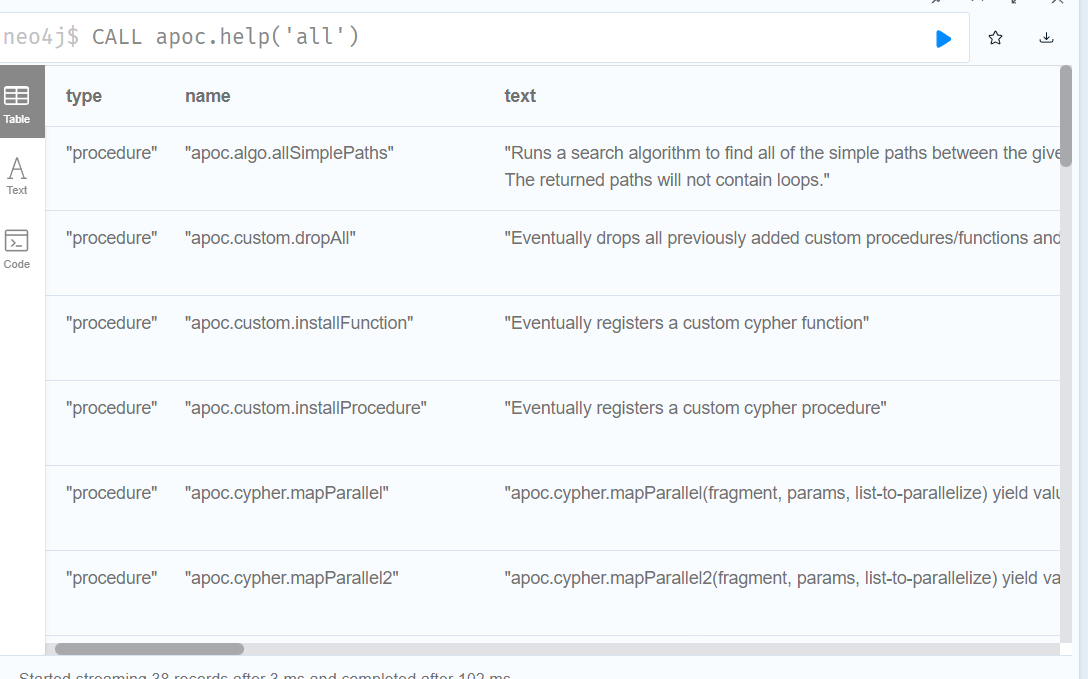
:sysinfo //查看数据库信息检查数据库插件是否正常运行
启动图数据库并打开 Neo4j Brower
查询 CALL apoc.help('all')
CALL tabby.help('tabby')
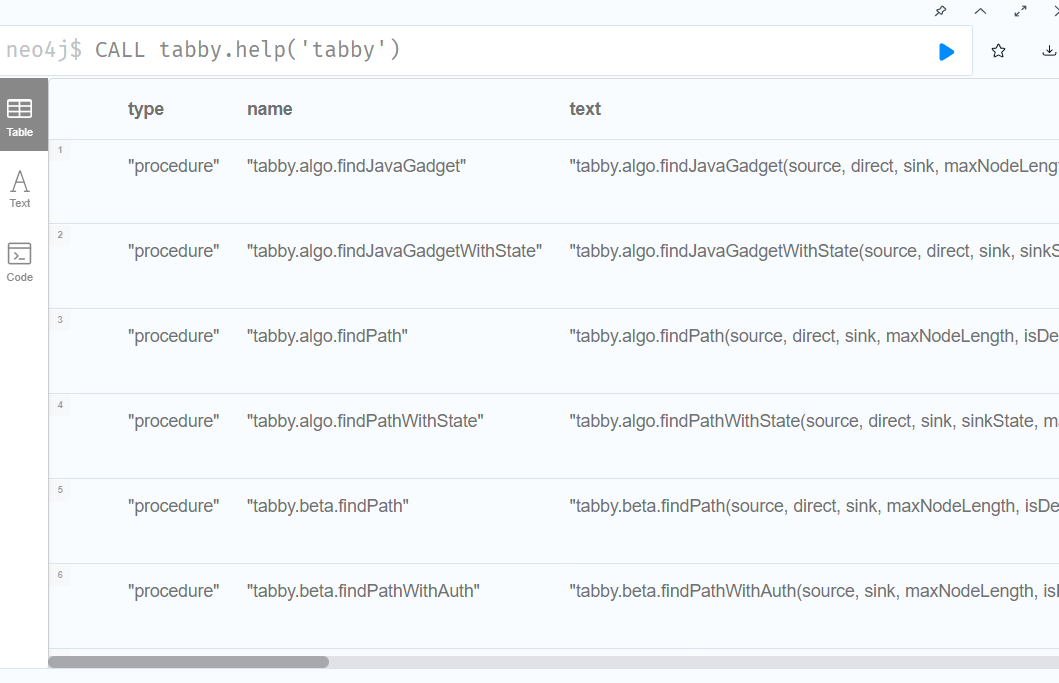
至此大功告成:
测试
先build
然后生成了csv文件
然后在load到数据库中
查询语句:
//cc2
match (m1:Method {SIGNATURE:"<java.util.PriorityQueue: void readObject(java.io.ObjectInputStream)>"})-[:CALL ]->(m2:Method {NAME:"heapify"})-[:CALL ]->(m3)-[:CALL]->(m4:Method {NAME:"siftDownUsingComparator"})-[:CALL]->(m5)-[:ALIAS*]-(m6 {SIGNATURE:"<org.apache.commons.collections.comparators.TransformingComparator: int compare(java.lang.Object,java.lang.Object)>"})-[:CALL]->(m7)-[:ALIAS*]-(m8:Method)-[:CALL]->(m9:Method {IS_SINK:true}) return *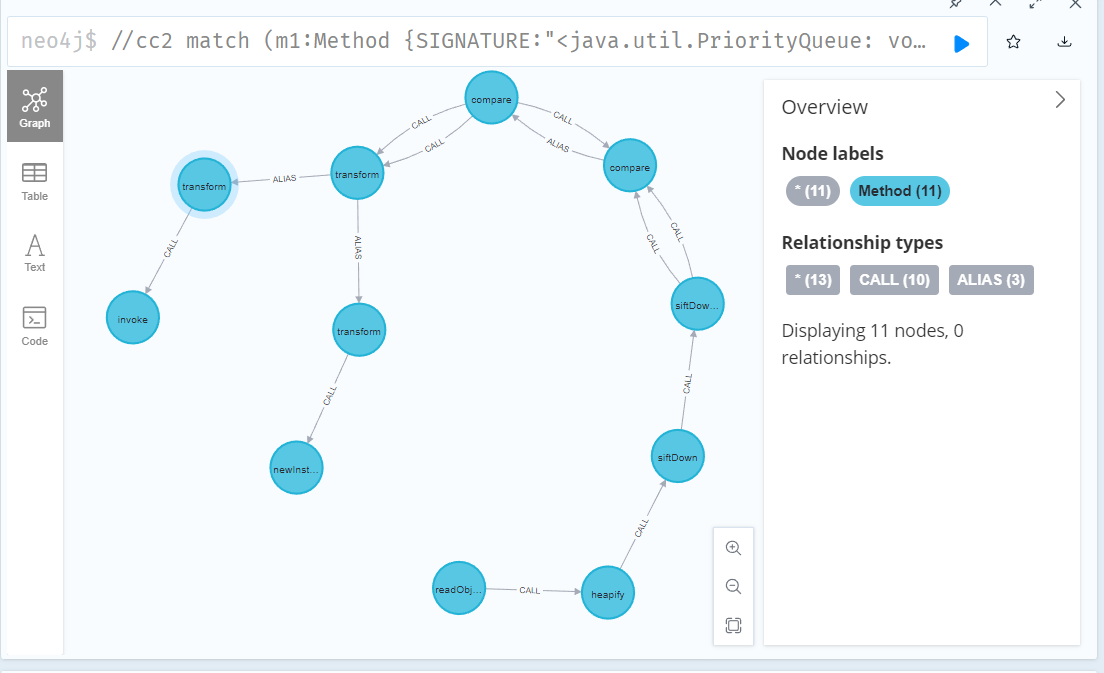
对了 一开始可能小球没有字,要去设置一下:
官方给的查询语句:
好好学一下语法 早日挖0day