
项目介绍
本项目使用 Java 开发,基于 Spring Boot 与 Spring AI 框架构建后端系统,集成 RAG(Retrieval-Augmented Generation)机制并连接南昌航空大学高考录取信息知识库,实现智能问答与志愿填报分析功能。前端采用 Vue 实现,支持用户与智能助手交互,实时获取录取数据、专业推荐与填报策略,提供高考信息的智能检索与决策辅助能力。
项目展示

项目已实现用户注册与登录、会话记录与复现、热门问题排行、智能对话等核心功能。每次创建新会话时,智能助手会首先介绍南昌航空大学的基本信息,随后等待用户提问。在注册过程中,用户需填写高考相关信息(如省份、总分、选科组合、意向专业等),系统将基于这些数据进行个性化分析,为用户提供更精准的录取信息查询与志愿填报推荐。
数据
数据来源
这部分我就不详细展开我们是怎么做的了,因为每个人的项目方向不一样,数据来源的方式也不固定。我这里主要讲一下我们用到的整体技术框架。
因为高校的高考录取信息在网上基本都是公开透明的,所以我们主要通过爬虫技术来获取这些数据。
这里推荐一个比较适合新手的软件------八爪鱼,它可以做到零代码采集,对小白非常友好。具体怎么用、怎么采得好,这就要靠大家自己去摸索和尝试了。
我们把爬取下来的数据做了一些预处理和整合,最后统一导入到了MySQL 数据库中。
这里我们使用的是 Navicat 进行数据导入和管理,我是已经安装过了Navicat,试用期过了需要破译,使用的方法是微信关注简忆工作室公众号,发送nav17,那边就会发破译方法,还要看一段小视频广告,还好效果不错,使用简单。网上也有一些 Navicat 破解版本的教程,可以自行了解。
数据库同步问题
这里我想补充一点关于数据同步的问题,特别是对于多人协作开发的团队来说非常重要。
我们这边使用的是本地数据库服务器 + 客户端连接的方式,也就是把数据统一放在服务器端,其他人通过客户端连接来访问。这种方式的好处是本地控制,数据安全性和隐私性比较好;但缺点也很明显:大家必须在同一个局域网下,离开服务器那台电脑,其他人就没办法继续开发或者访问数据。
本地数据库的使用其实比较简单。只需要在服务器那台电脑上创建好数据库,然后给其他开发成员分配账号和密码,并授权访问权限,其他人就可以通过客户端用这些账号密码进行连接和使用了。这部分配置流程也不复杂,问问 AI 或网上搜一下就能搞定,很适合初学者上手。
当然,也有一些团队会选择使用云数据库(比如阿里云、腾讯云等),它的优点是随时随地都能访问,团队协作更方便,但也可能存在一些安全性或成本方面的考量。
因为我这边暂时没用过云数据库,所以这一块就不做过多评价了,感兴趣的可以自行了解一下。
后端
框架与运行
创建
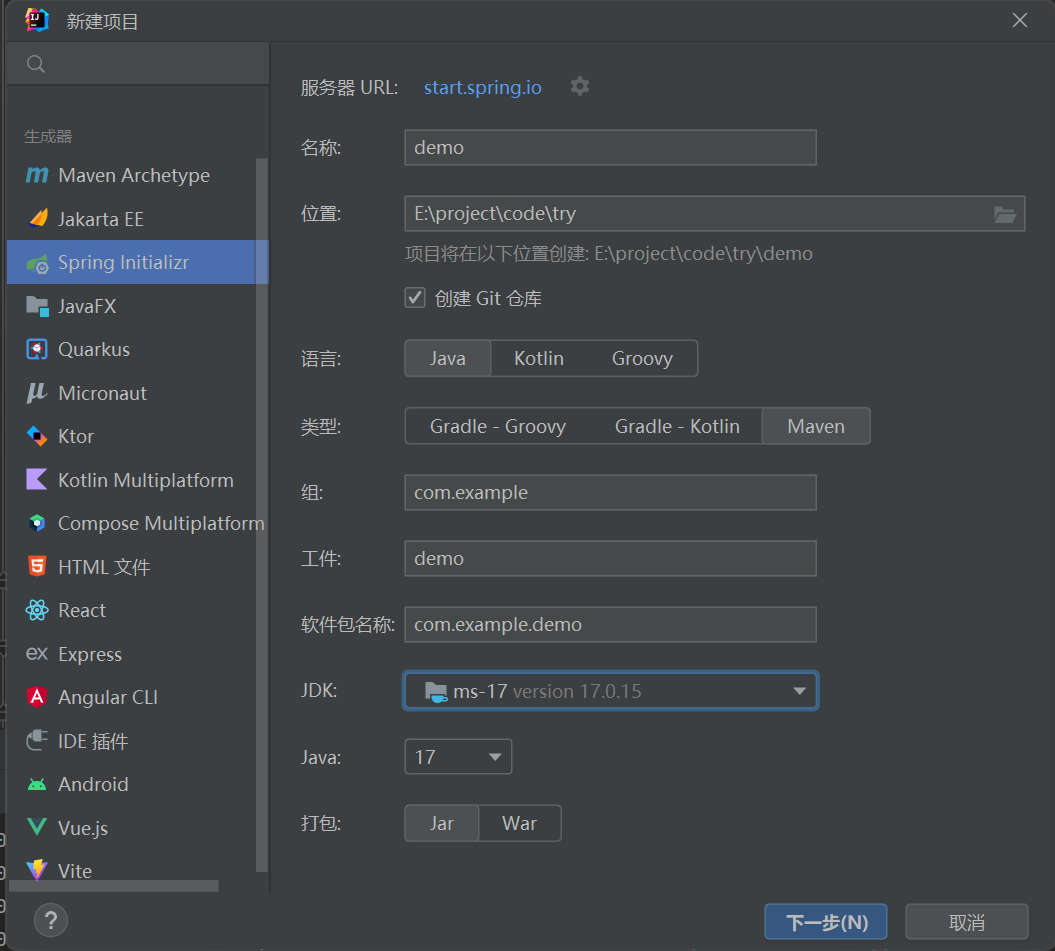
我使用的是idea这个IDE,在新建项目中找到spring initializr,可以创建一个springboot项目,类型我选择maven去管理环境和构建项目,java版本我这里使用的是17,我记得使用其他版本有一点不兼容报错,可能是我原本框架版本的问题,最后被迫下了一个17版本就正常了。
maven
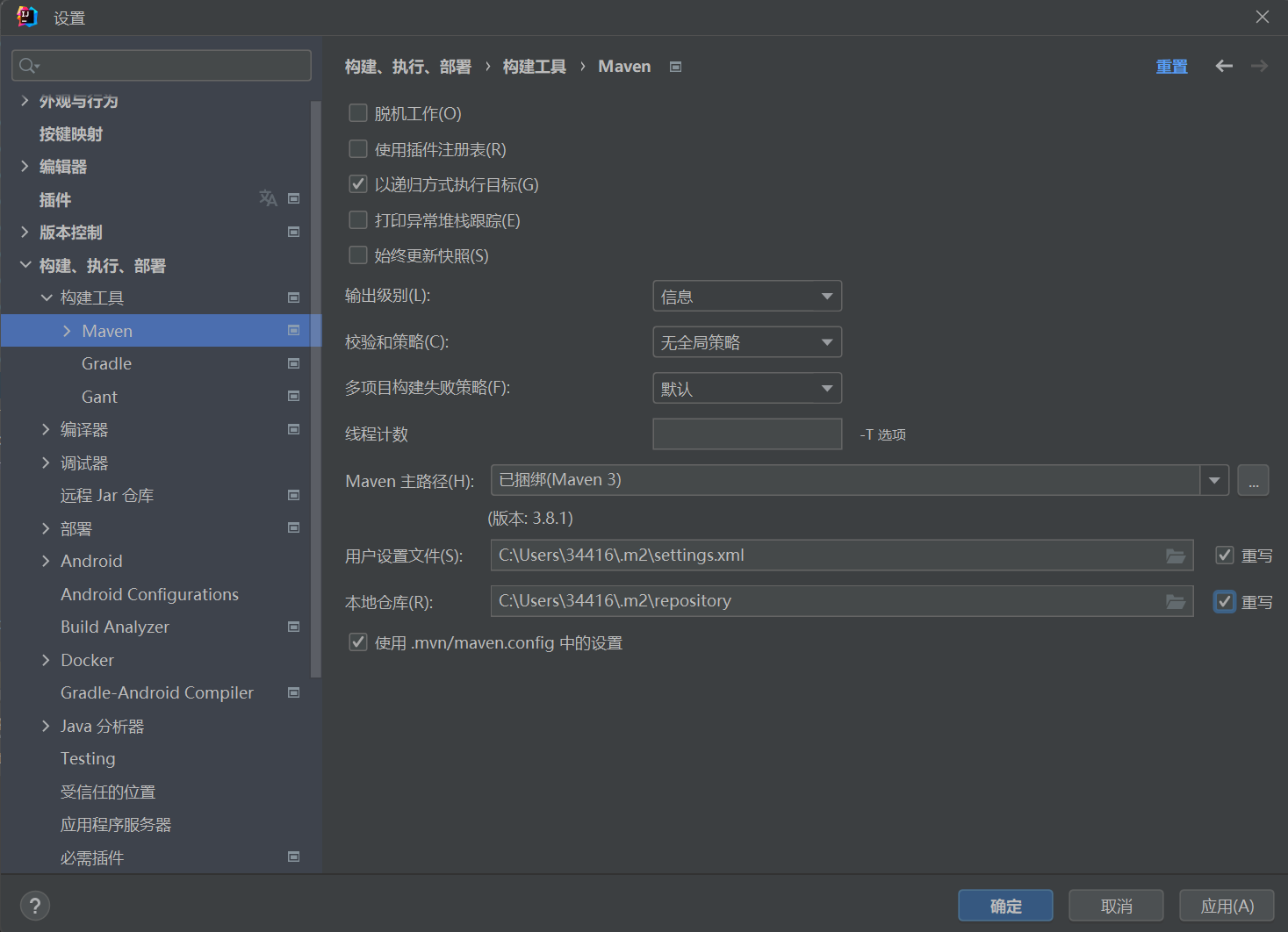
当你创建了一个新的springboot项目之后,会有一个application文件,内容大概跟下面这个差不多,是整个项目的核心入口,有些人是不是发现跟我的图片有些不一样?如果没有那个绿色的运行键,就需要看这一部分了,maven的下载。
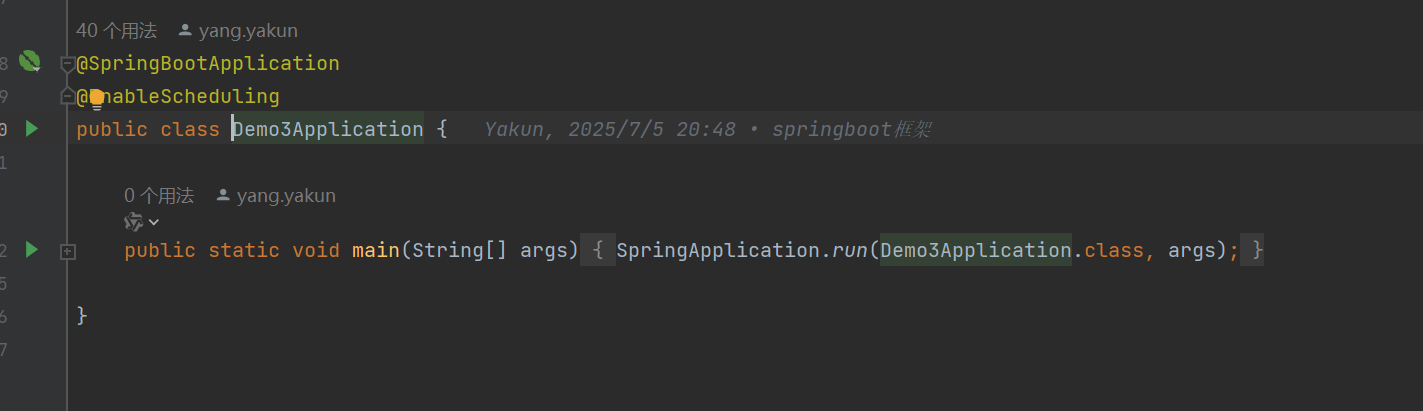
第一步
点击文件中的设置
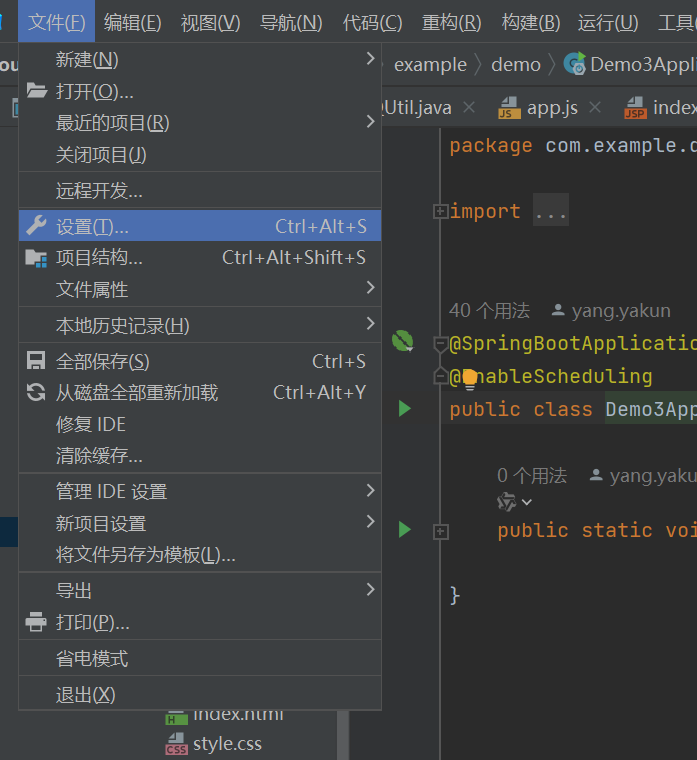
第二步
在构建,执行,部署下面找到构建工具点击maven
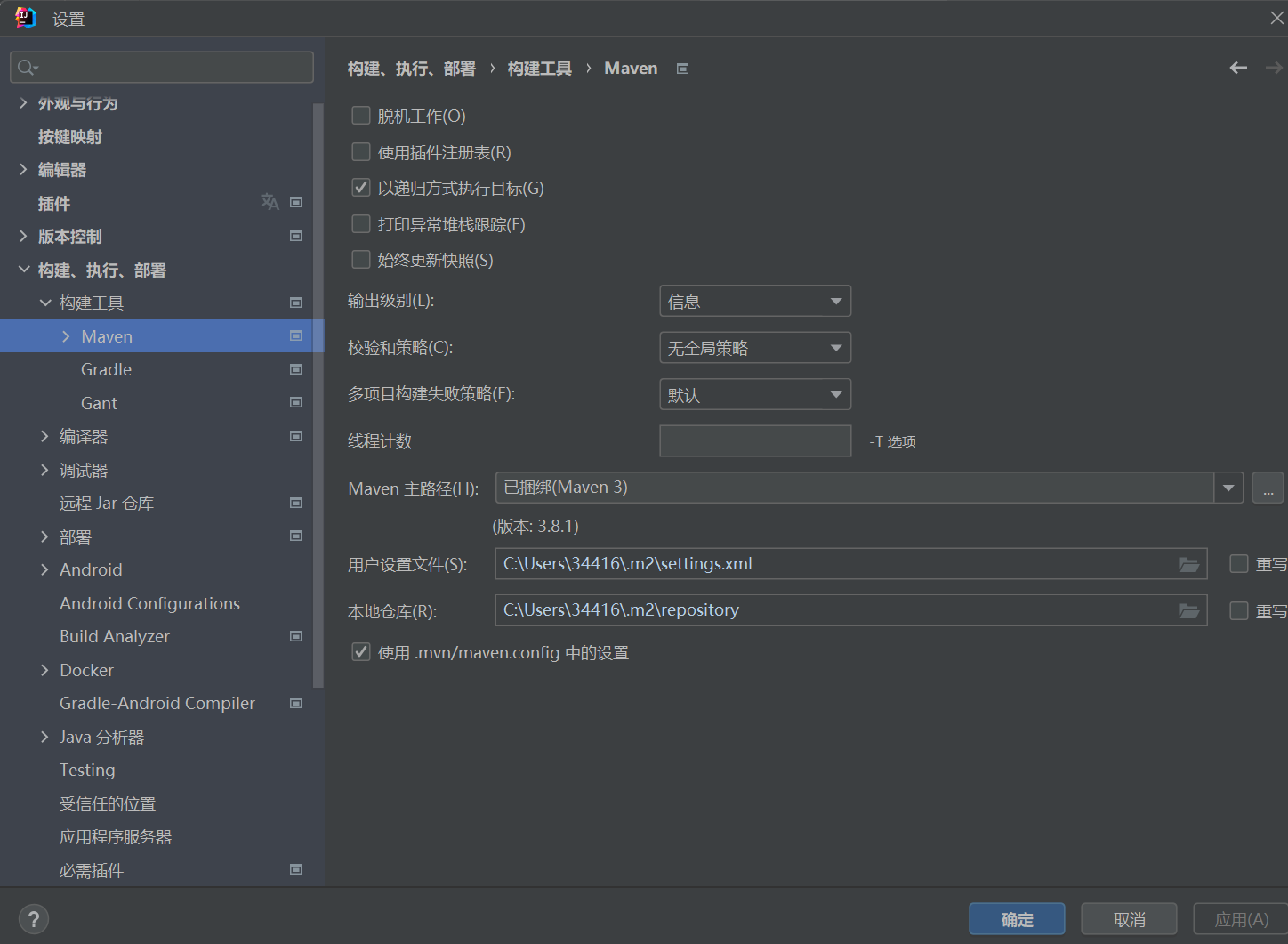
第三步
点击重写,然后点击应用,ide会自动帮你下载好,这里可能会出现文件和仓库是暗下去的,是由于缺失什么插件,我团队成员遇到了这个问题,但是我不知道具体是怎么解决的,如有遇到,自行查找。
环境配置
maven主要是配置环境和管理环境比较方便,新建的项目下会有一个pom.xml文件,我们项目需要什么环境直接在文件中写dependency。
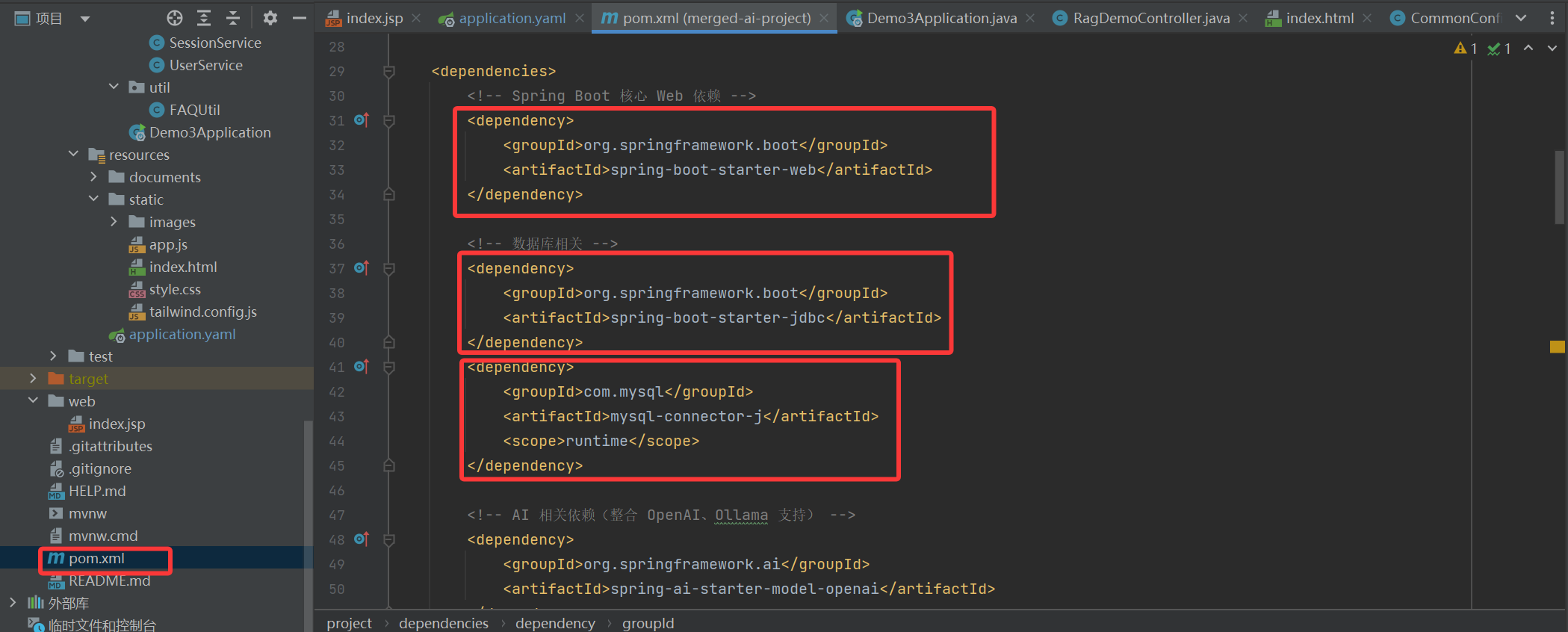
之后点击右侧maven
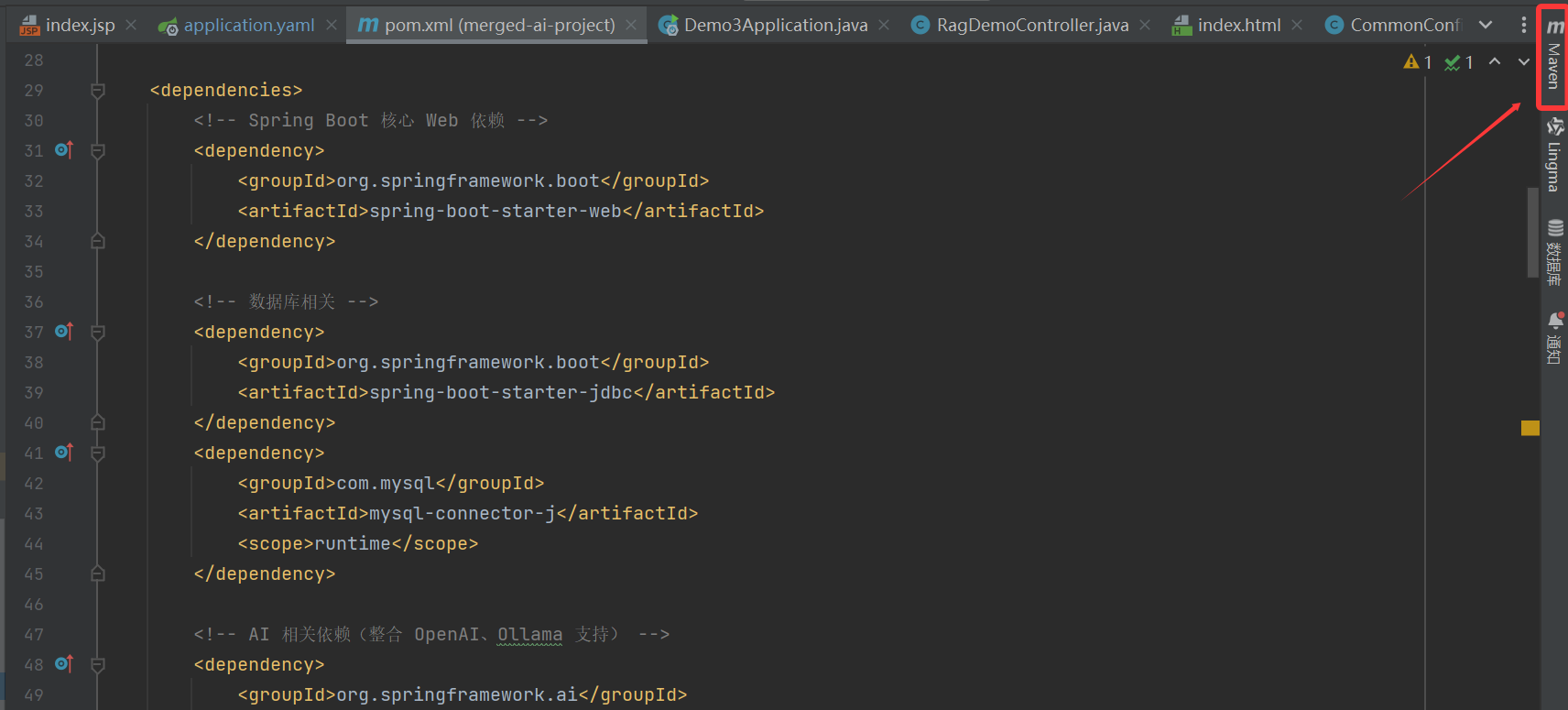
再点击刷新,maven就会自动配置环境。第一次编译会比较慢。
java版本修改
如果遇到java版本问题,这里也给出java版本修改的方法
第一步
点击文件,选择项目结构
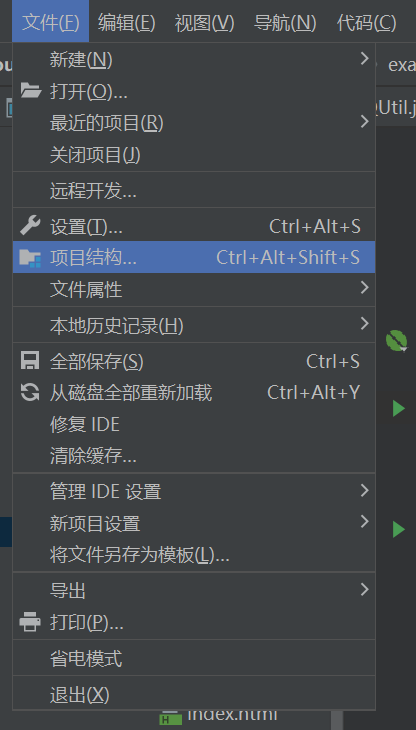
第二步
在项目中的SDK选择添加SDK,下载JDK
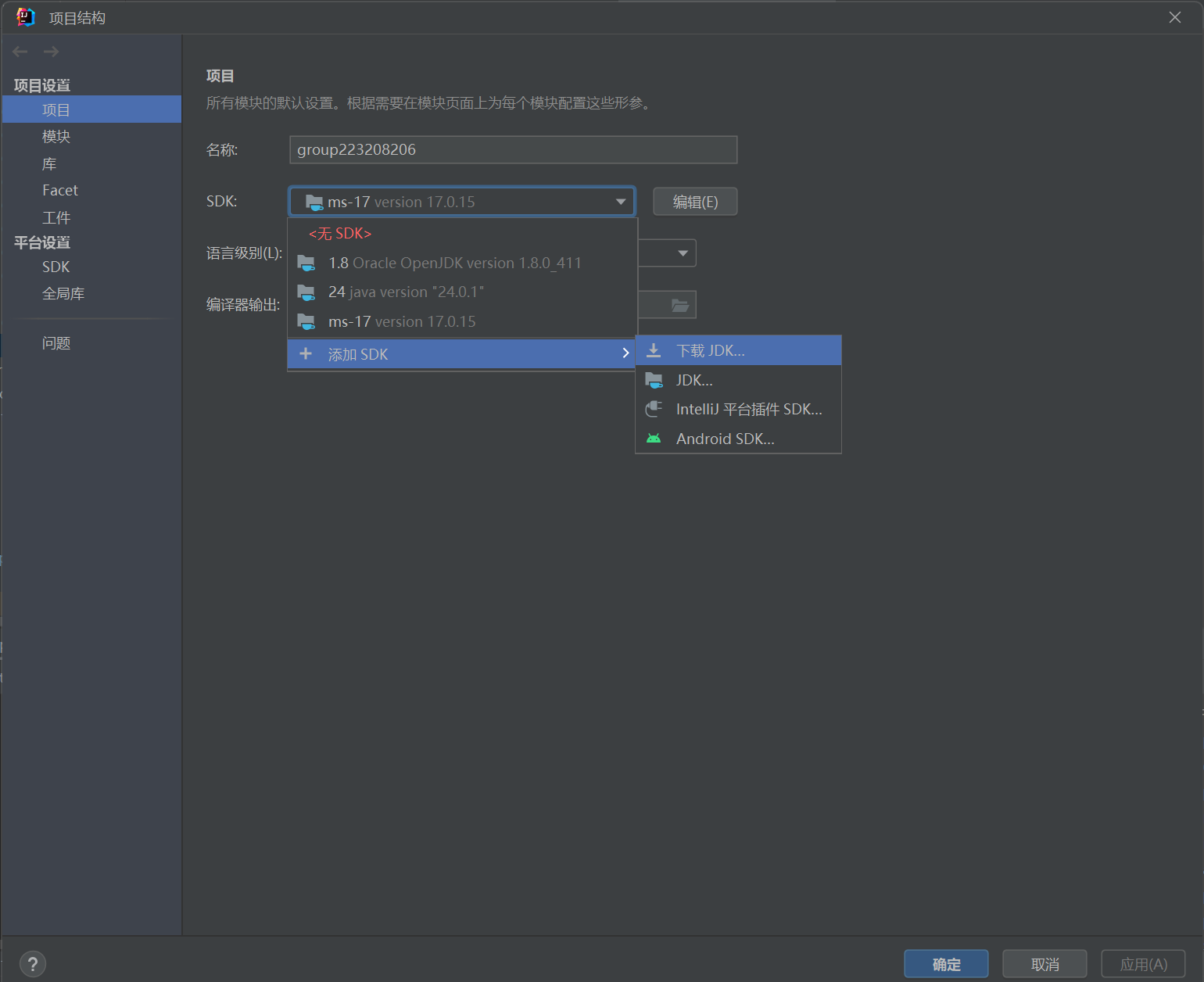
第三步
选择需要的版本下载就可以了
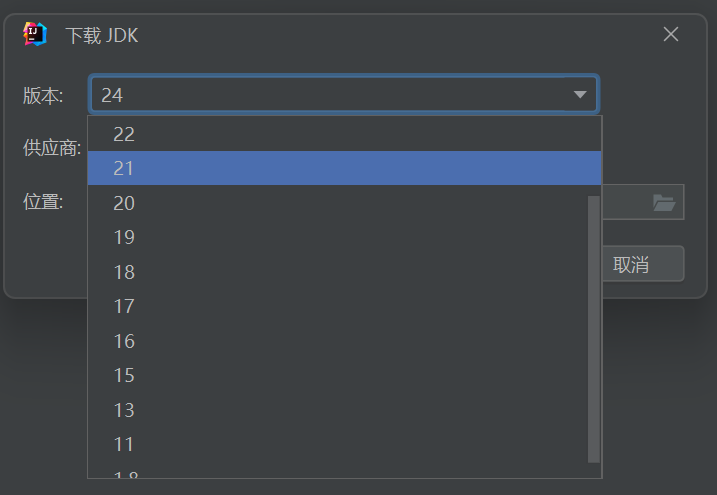
测试工具
没有做过后端开发的同学可能会比较疑惑,在没有前端的情况下如何确保后端运行的正确与否。我使用了一个名叫Postman的软件,可以很方便的测试后端接口。
使用方法
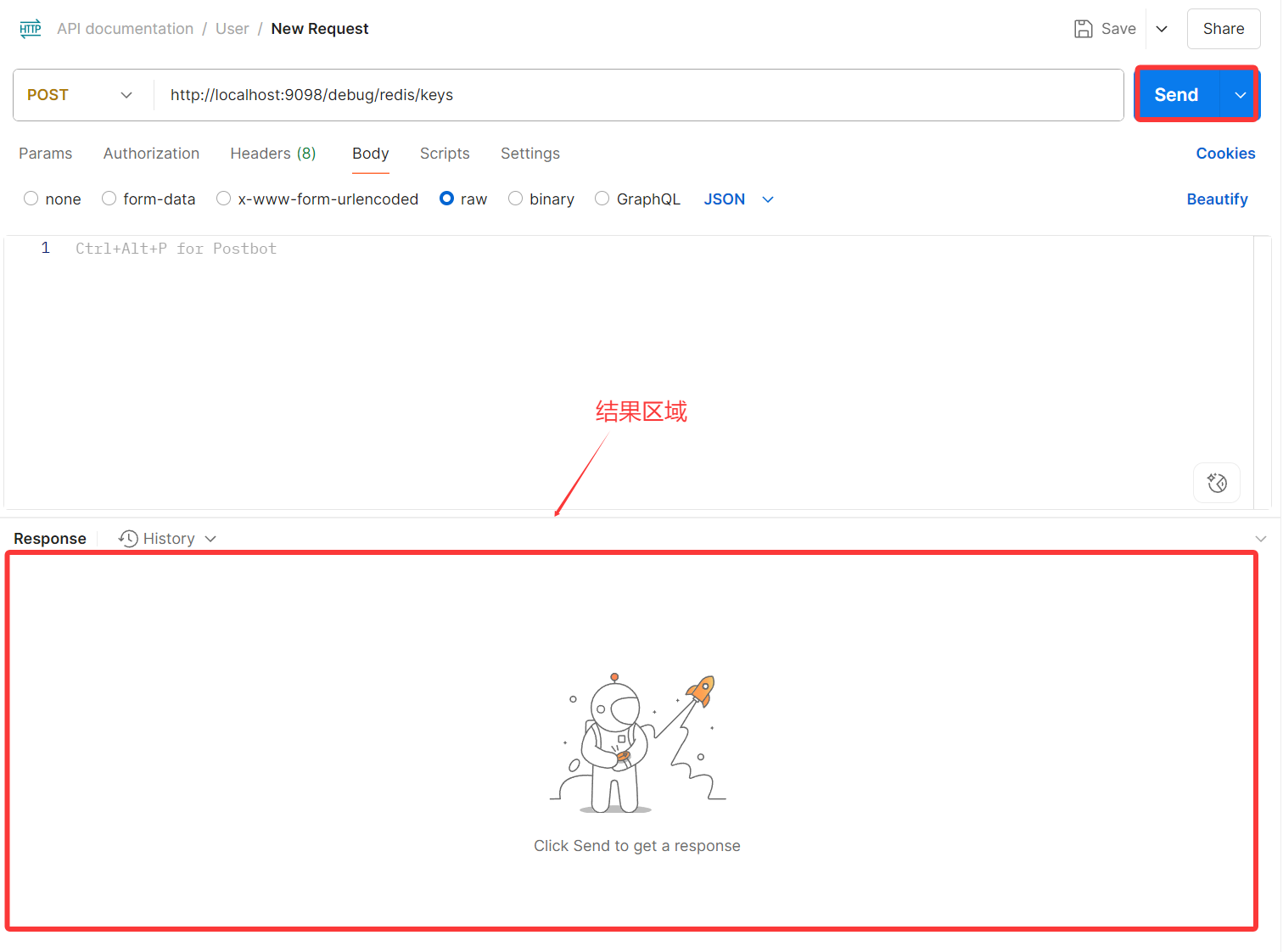
在下载安装注册登录之后,进来的页面差不多是这样的,点击右上角的加号,出现Block Collection,点击这个按钮。
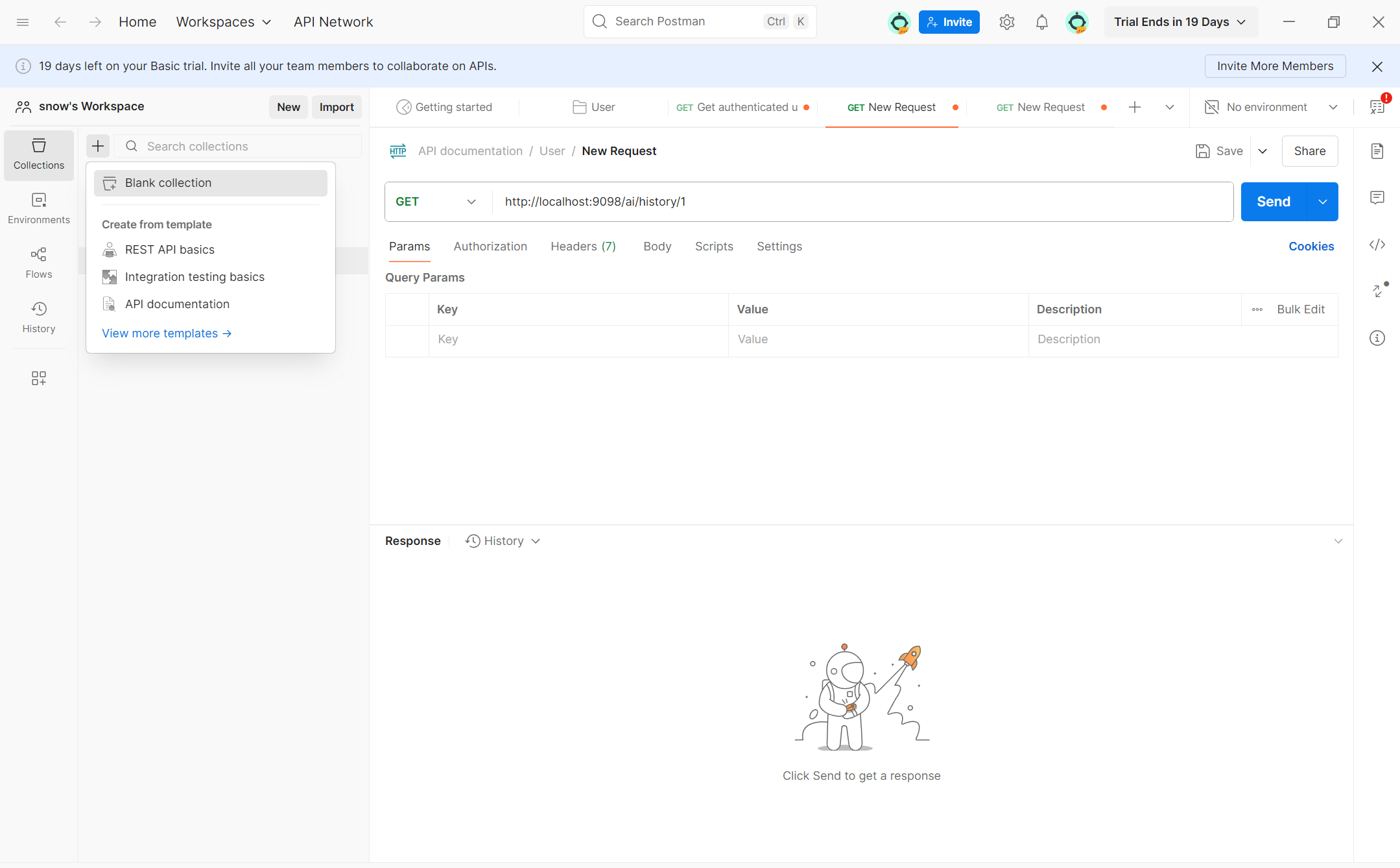
之后会出现一个类似下图文件夹,点击右侧的加号,就会出现一个新的new request
在红色框内输入后端接口的url
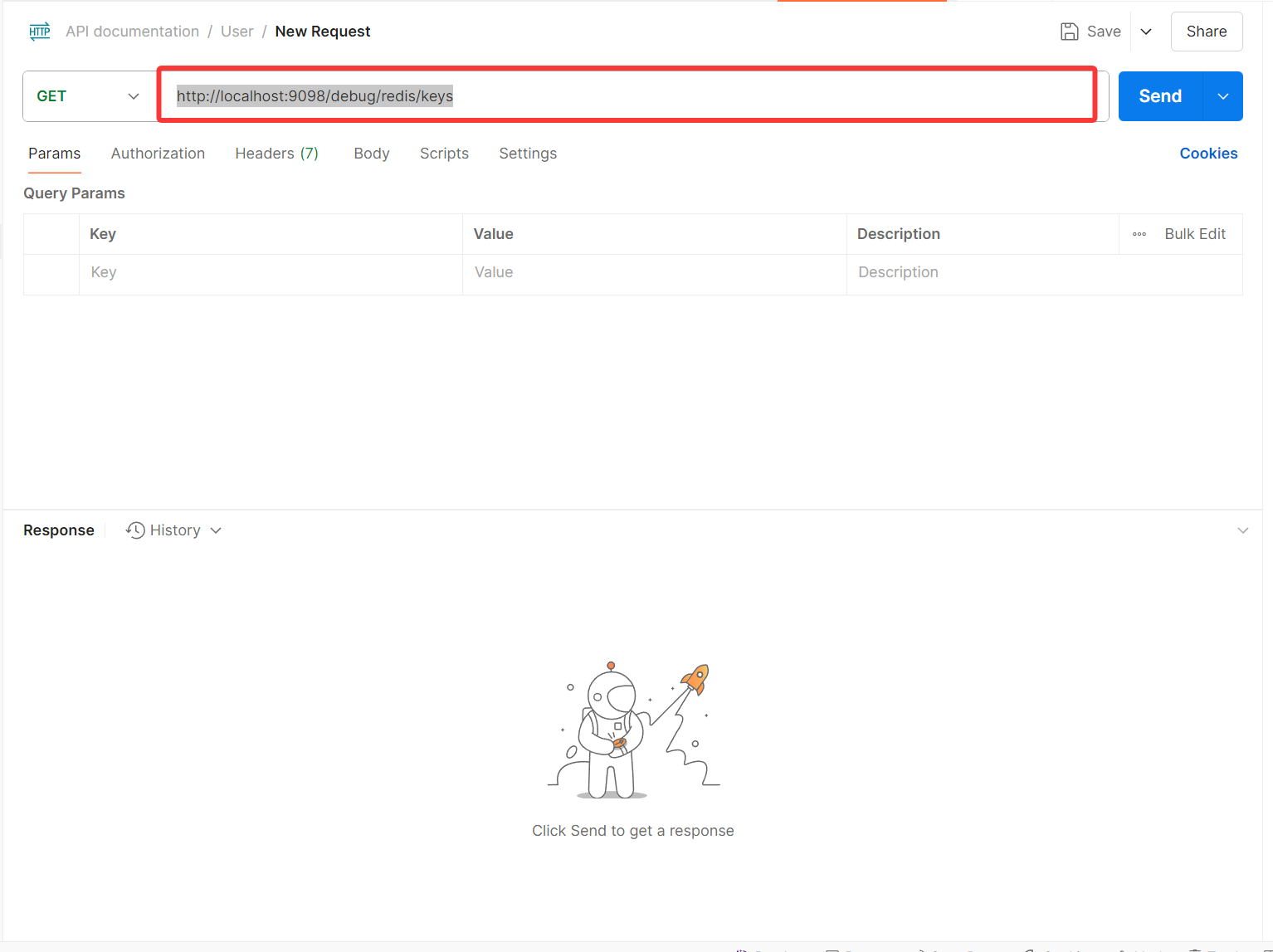
如果是POST方法的话,可以点击GET下拉框中的POST
GET参数传入
如果你需要传入参数,可以在url后面加?参数名=变量,如图。

POST参数传入
post参数的传入会麻烦一点,先选择Body再点击raw,下面会出现输入区域。
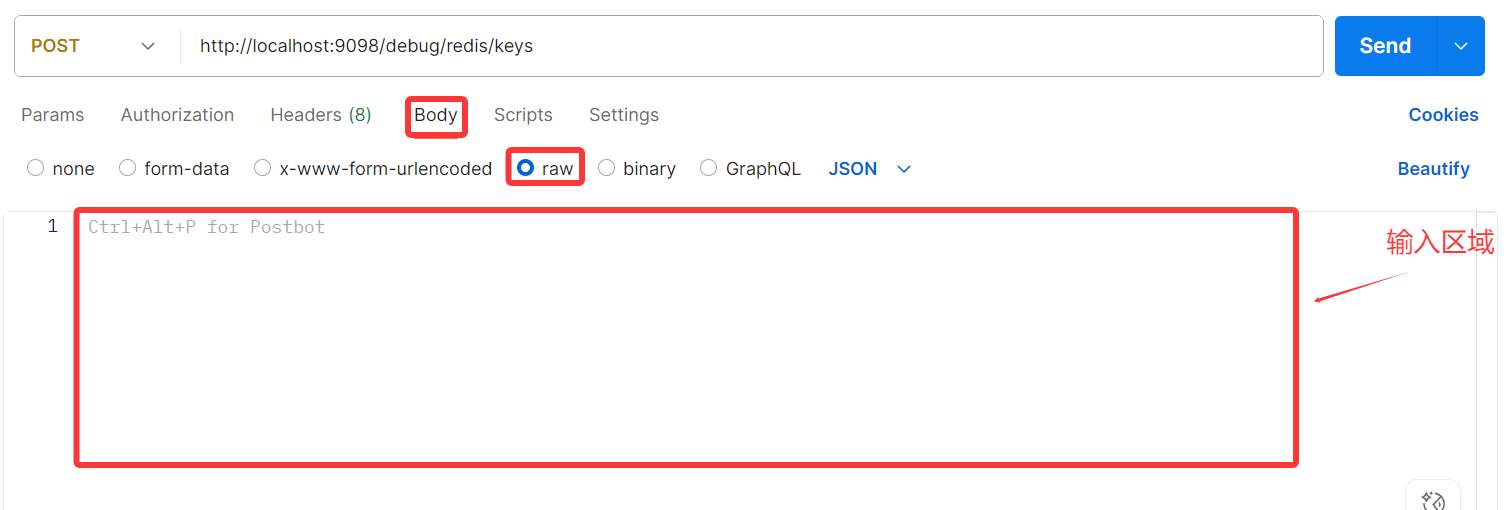
在输入区域内部用json格式写你要传入的参数参数: 变量。
最后点击Send,结果会呈现在结果区域中。
项目结构
在讲具体功能之前先讲讲我项目的核心结构(代码可能存在一些不规范的问题,在项目后期发现了,但是也没办法去改了,甚至可能存在部分冗余代码)
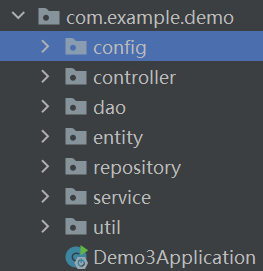
config中记录一些配置的注册,entity是数据库实体和其他实体,dao是与数据库语句实现的代码,service是业务层,controller是后端接口。
核心功能
基础对话助手
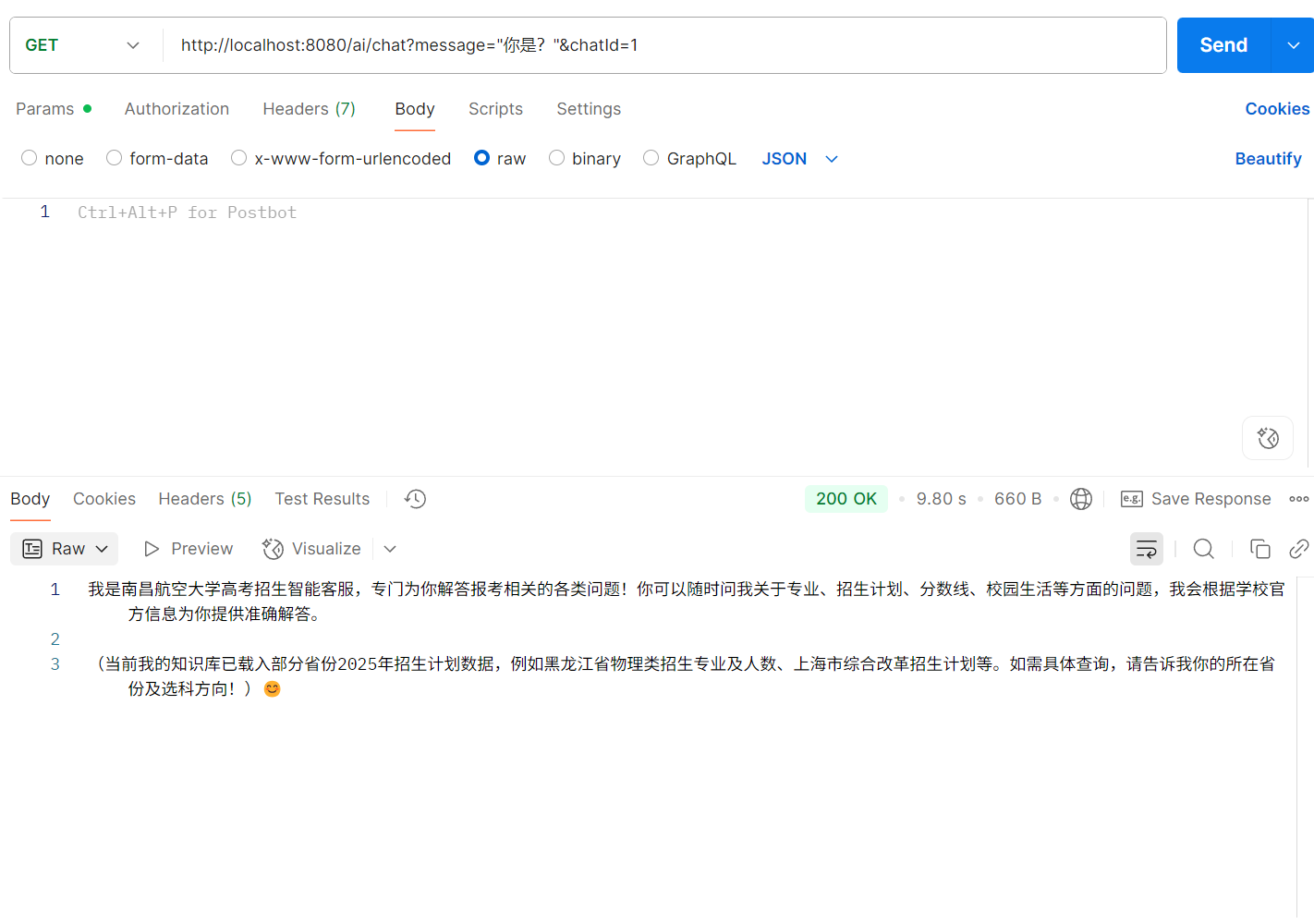
这个项目最核心的部分莫过于如何实现智能助手的功能,这个推荐黑马程序的的一个速成课程springai这个课程的免费部分,实现了一个后端的deepseek模型的接入,也是我整个项目的基石。可能是因为版本问题,视频中的部分代码实现会报错,所以我也做了部分修改实现代码也发布在gitee上,方便大家参考。代码后端调用聊天效果如图。
提示:拿到代码第一时间修改api-key,我写的那个已经没钱了,运行会报错。
视频里实现的只是一个基础的对话助手,虽然能进行简单交流,但还称不上"专属"。如果我们想让它具备真正的个性化能力,就需要为它构建一个专属的 RAG 知识库。只有这样,模型才能结合特定的数据,比如学校的录取情况、专业介绍等,去回答那些通用模型根本答不了的问题,真正实现"懂你想问"的效果。
标题中也提到了,我们使用的是阿里云百炼的大模型接口。相比本地模型,云端助手的优势在于模型更完整、回答更智能,但也有一个明显的缺点:需要持续付费。好在阿里云百炼的起步成本较低,注册账号就送 100 万 Token,足够个人或小团队初期使用。
视频中也提到另一个方案:使用本地的 Ollama 模型。这个方式不依赖云服务,能在普通电脑上运行,但模型规模较小,智能程度有限,回答有时会显得"笨"一点。
如果是企业或团队项目,也可以选择 一次性投入建设本地服务器,前期成本高,但长期使用下来的费用会更低,也更安全可控。
这部分我就介绍一下阿里云百炼是如何使用的。
搜索【阿里云百炼】,进入页面之后是这样的。
点击大模型
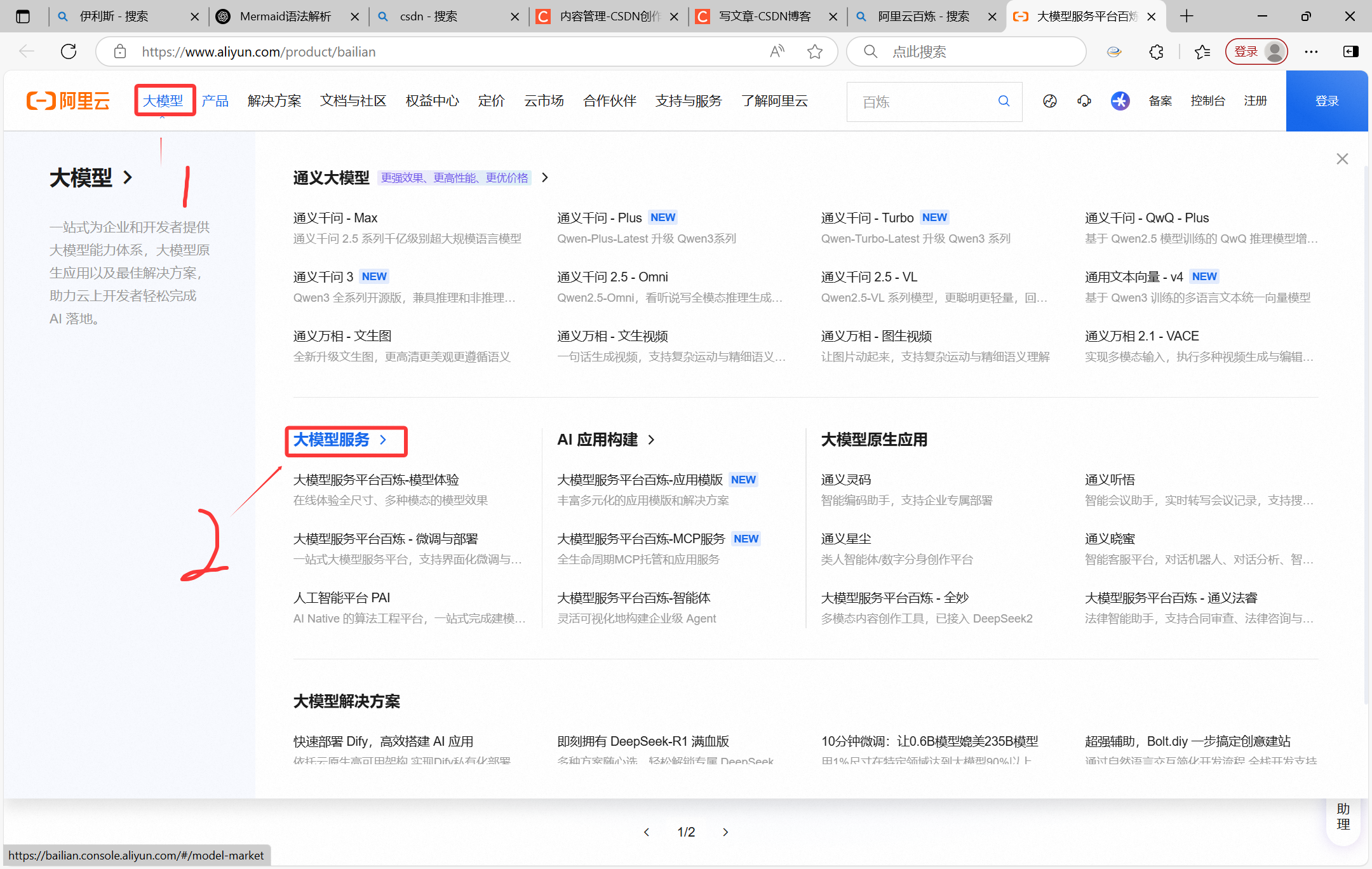
进去之后登录,登录完红框部分会出现新用户免费领取100万token的消息,点击进去,去领取,我这里已经领取完了,免费的。
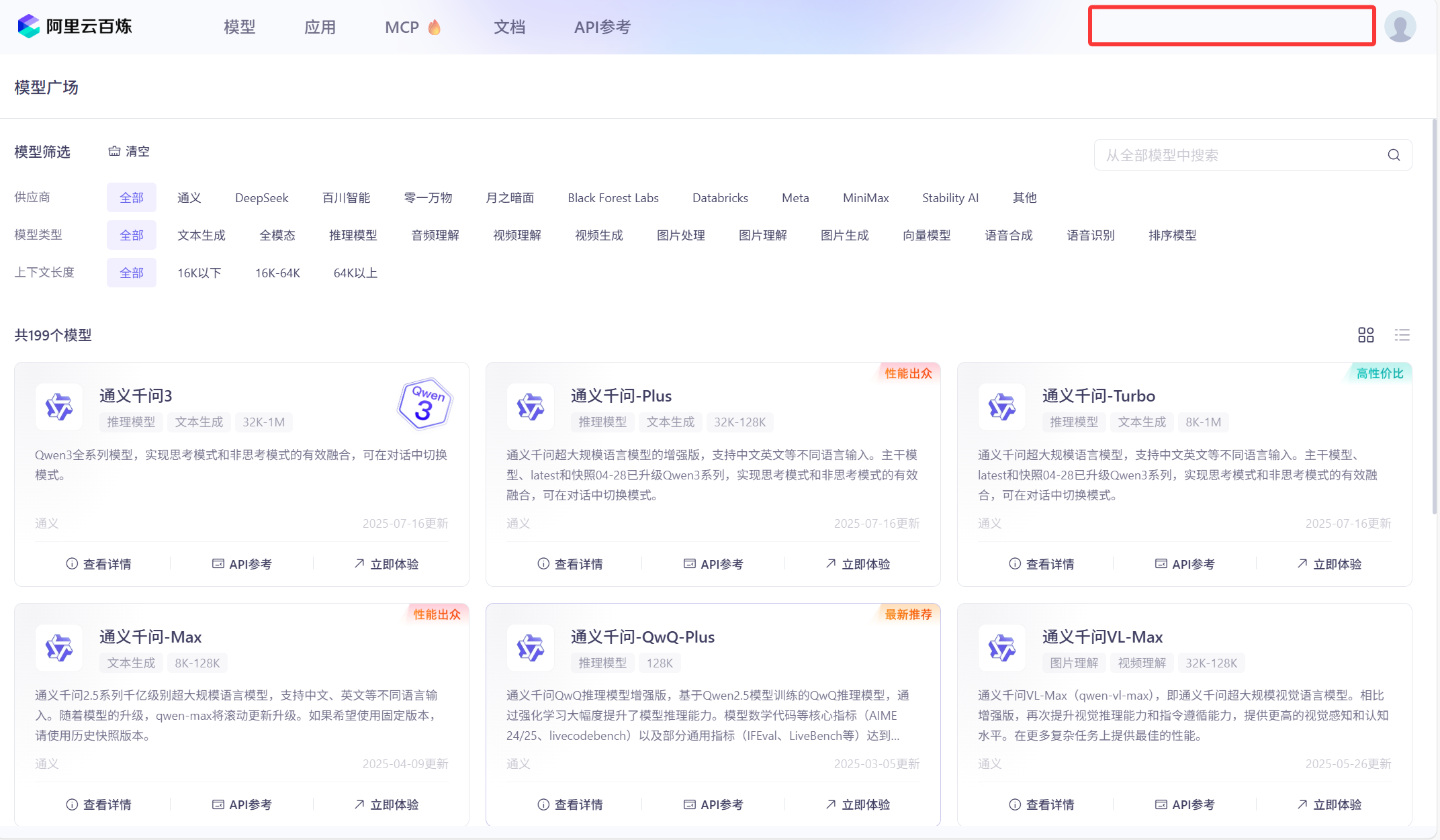
之后,点击模型,弹出左边框,选择API Key。
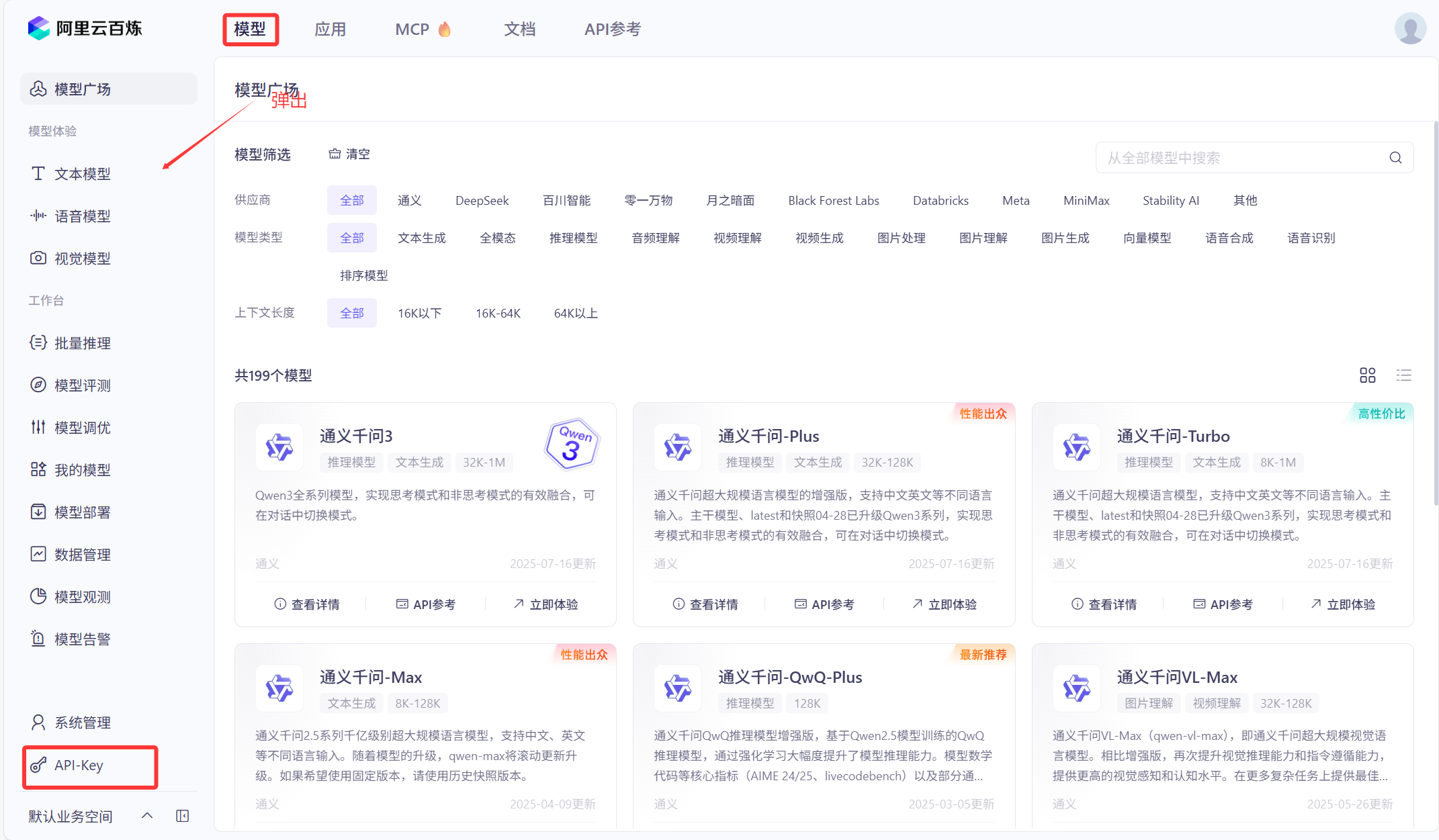
进去之后点击创建API KEY
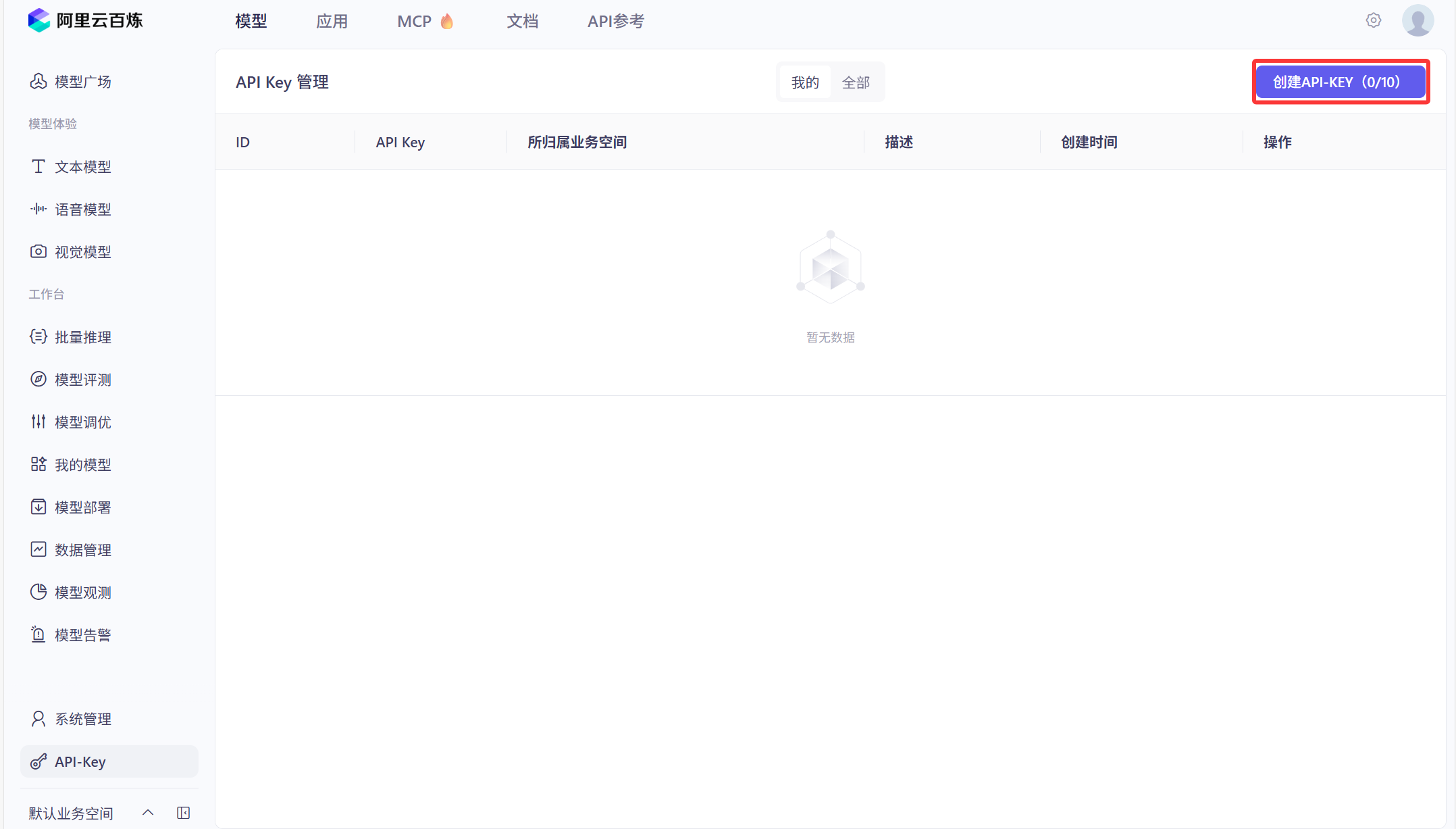
选择默认业务空间,描述随便填或者不填,点击确定。
会出现下面这个列表,点击查看,再点击复制,就得到了你自己的key。

进阶RAG专属助手
接下来,我要讲讲视频里的付费内容--如何实现RAG,这部分是我自己摸索出来的。
大家应该都知道,计算机是看不懂文字的,那么如何将我们的资料给ai助手呢?这里需要引入一个新的模型--向量模型。
阿里云百炼中同样提供了实现这种功能的模型,如图:
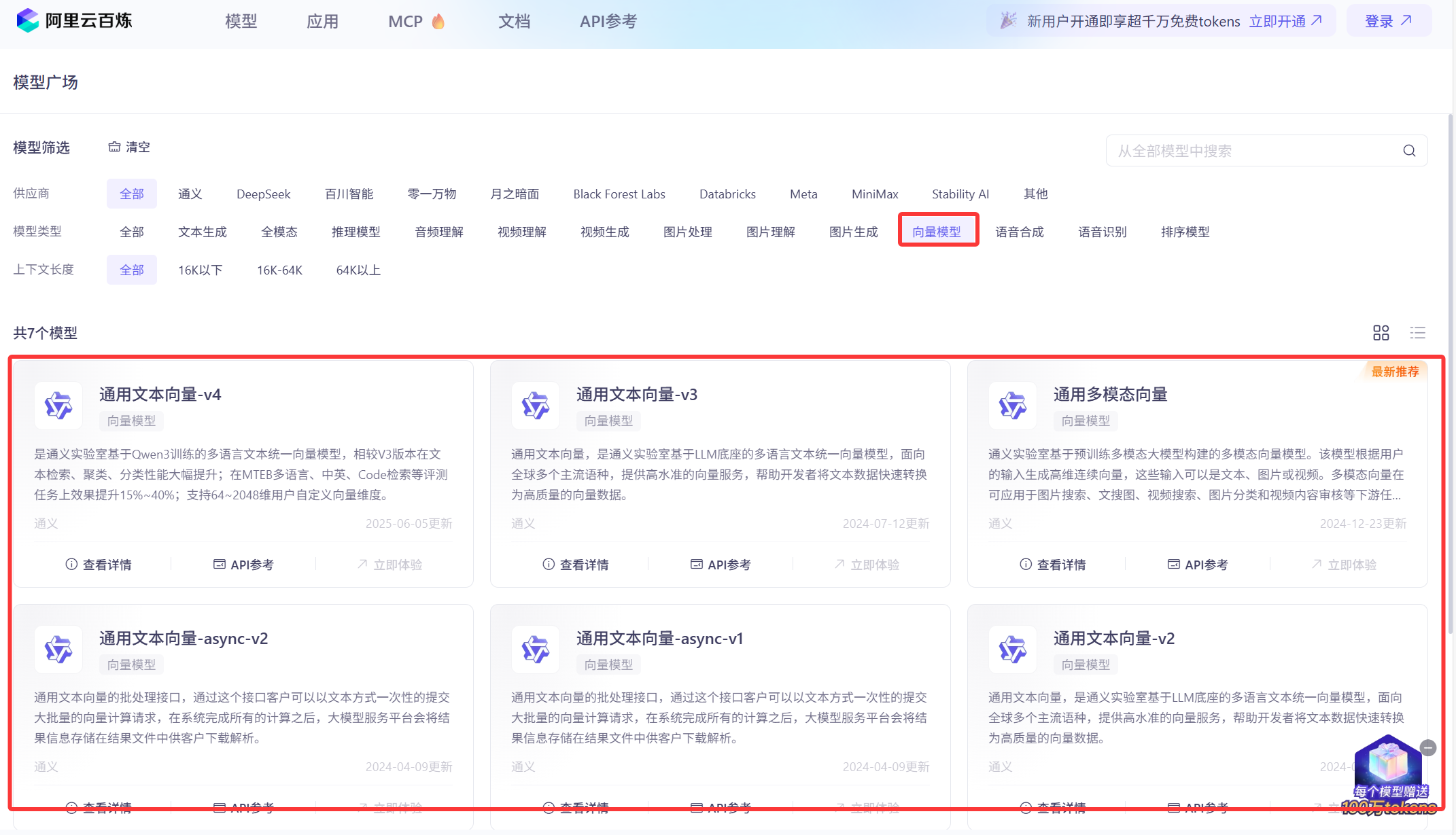
点击向量模型,下方会出现能提供的所有模型,我使用的就是第一个模型。
点击API参考
可以看到模型名,我们要使用什么模型,就写哪个名字。
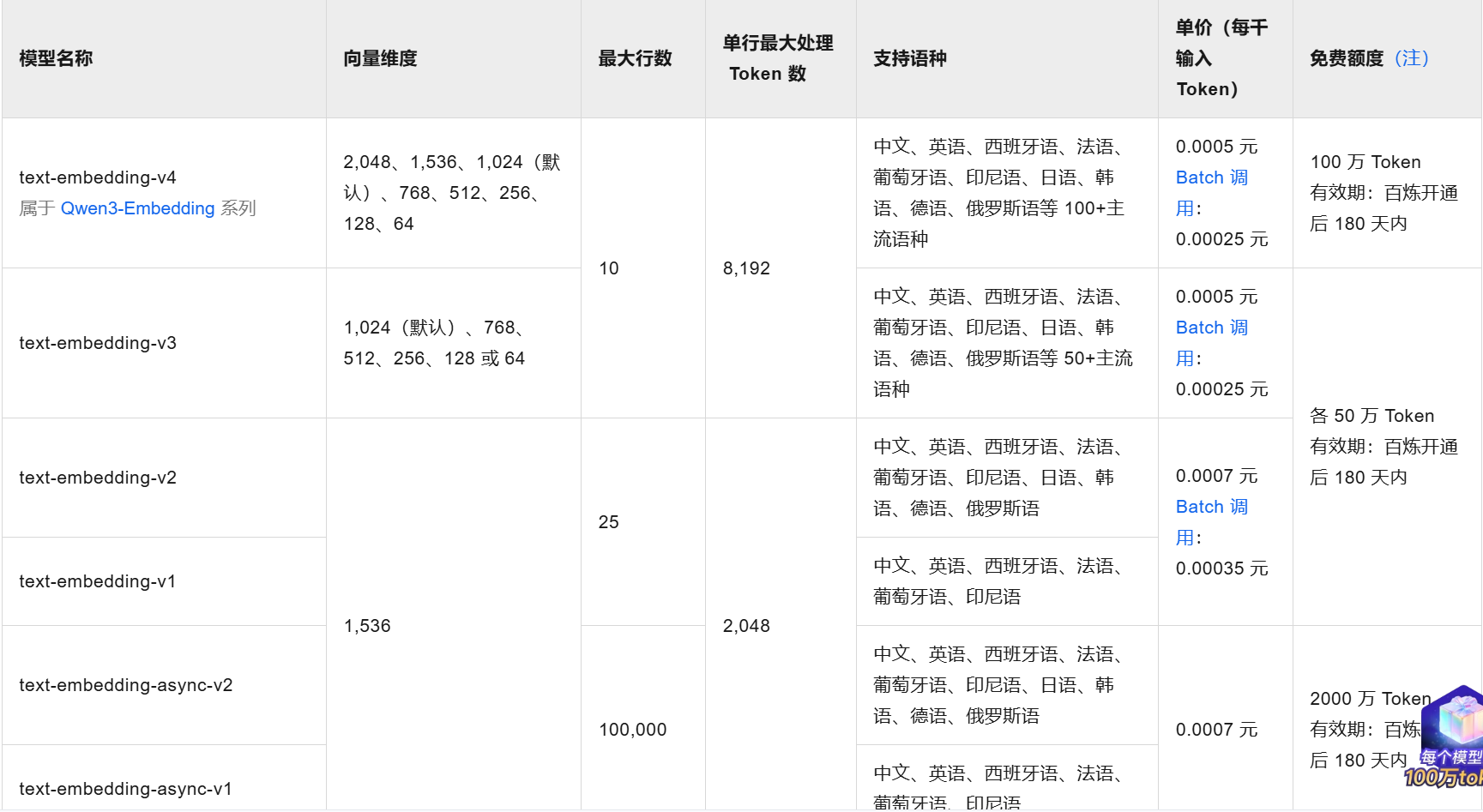
application配置向量模型和对话模型
yaml
ai:
openai:
api-key:
base-url: https://dashscope.aliyuncs.com/compatible-mode
chat:
options:
model: deepseek-r1
embedding:
options:
model: text-embedding-v4读取数据
在service文件夹下创建了RagService类,用于实现数据读取与向量化的核心业务逻辑。虽然该功能也可以放在controller中实现,但出于代码规范和职责分层的考虑,较复杂的逻辑应集中在service层中。当前已实现两种数据读取方式:一是从 .xlsx 文件中读取,二是从MySQL数据库中读取,并统一进行后续的向量化处理。
xlse读取
java
package com.example.deepseek_ai.controller;
import jakarta.annotation.PostConstruct;
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
@Slf4j
@RestController
@RequestMapping("/rag")
@AllArgsConstructor
public class RagDemoController {
private final VectorStore vectorStore;
@PostConstruct
public void init() {
addVectorStore(); // 启动时执行加载
}
public void addVectorStore() {
try {
// 你可以将多个文件放在 /resources/documents/ 目录下
List<String> filenames = List.of(
"data2025.xlsx",
"清理专业表.xlsx",
"data2017-2024.xlsx"
);
TokenTextSplitter splitter = new TokenTextSplitter(500, 200, 1, 8192, true);
List<Document> allDocs = new ArrayList<>();
for (String filename : filenames) {
Resource resource = new ClassPathResource("documents/" + filename);
TikaDocumentReader reader = new TikaDocumentReader(resource);
List<Document> docs = splitter.apply(reader.get());
allDocs.addAll(docs);
log.info("已处理文件 {},生成文档片段数:{}", filename, docs.size());
}
vectorStore.add(allDocs);
log.info("共成功加载 {} 条文档片段", allDocs.size());
} catch (Exception e) {
log.error("加载文档失败", e);
}
}
}处理xlsx文件向量化,这部分需要注意一个参数问题,具体怎么调,问ai,确保所有数据都加载进来。
java
TokenTextSplitter splitter = new TokenTextSplitter(500, 200, 1, 8192, true);mysql数据库
java
package com.example.demo.service;
import com.example.demo.entity.*;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.document.Document;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import jakarta.annotation.PostConstruct;
import java.io.File;
import java.util.*;
import java.util.stream.Collectors;
@Service
@Slf4j
@RequiredArgsConstructor
public class RagService {
private final VectorStore vectorStore;
private final MajorService majorService;
private final AdmissionService admissionService;
private final AdmissionNewService admissionNewService;
private final UserService userService;
@PostConstruct
public void init() {
try {
if (vectorStore instanceof FileBackedVectorStore fileBacked) {
File file = fileBacked.getFile();
if (file.exists()) {
log.info("📂 向量文件存在,FileBackedVectorStore 将自动加载(路径={})", file.getAbsolutePath());
return;
}
}
log.info("🚀 首次运行,开始加载 Admission / Major 数据并构建向量索引...");
List<Document> documents = buildAllDocuments();
TokenTextSplitter splitter = new TokenTextSplitter(1000, 5, 1, 10000, true);
List<Document> chunks = splitter.apply(documents);
vectorStore.add(chunks);
log.info("✅ 数据加载完成:共切分 {} 条向量片段", chunks.size());
if (vectorStore instanceof FileBackedVectorStore fileBacked) {
fileBacked.save();
log.info("💾 向量数据已保存至本地:{}", fileBacked.getFile().getAbsolutePath());
}
} catch (Exception e) {
log.error("❌ RAG 向量初始化失败:", e);
}
}
private List<Document> buildAllDocuments() {
List<Document> allDocs = new ArrayList<>();
List<Admission> admissions = Optional.ofNullable(admissionService.getAllAdmissions()).orElse(List.of());
for (Admission admission : admissions) {
String content = String.format("""
【完整招生信息】
年份: %s
省份: %s
专业: %s
选科要求: %s
招生人数: %s
最低分: %s
最低位次: %s
""",
admission.getYear(), admission.getProvince(), admission.getMajorName(),
admission.getRequiredSubjects(), admission.getQuota(),
admission.getMinScore(), admission.getMinRank()
);
allDocs.add(new Document(content));
}
List<AdmissionNew> admissionNews = Optional.ofNullable(admissionNewService.getAllAdmissionNew()).orElse(List.of());
for (AdmissionNew admissionNew : admissionNews) {
String content = String.format("""
【简化招生信息】
年份: %s
省份: %s
专业: %s
选科要求: %s
招生人数: %s
""",
admissionNew.getYear(), admissionNew.getProvince(), admissionNew.getMajorName(),
admissionNew.getRequiredSubjects(), admissionNew.getQuota()
);
allDocs.add(new Document(content));
}
List<Major> majors = Optional.ofNullable(majorService.getAllMajors()).orElse(List.of());
for (Major major : majors) {
if (major != null ) {
String content = String.format("""
【专业信息】
%s 专业属于 %s。
专业名称: %s
所属学院: %s
学费: %s
学制: %s年
专业简介: %s
""",
major.getMajorName(),
major.getFacultyName(),
major.getMajorName(),
major.getFacultyName(),
major.getTuition(),
major.getDuration(),
major.getMajorDescription()
);
allDocs.add(new Document(content));
}
}
allDocs.add(new Document("我们学校有17个学院,有64个专业"));
log.info("📦 文档构建完成:Admission={},AdmissionNew={},Majors={}",
admissions.size(), admissionNews.size(), majors.size());
return allDocs;
}
public List<Document> findSimilarDocuments(String query) {
SearchRequest request = SearchRequest.builder()
.query(query)
.topK(20)
.build();
List<Document> docs = vectorStore.similaritySearch(request);
return docs;
}
}这里我将数据拿出来之后在进行拼接成document文件,方便更好的分词。
.topK(20)我设置了20,每次查询会找到最相关的20条信息。
每次运行程序之后RAG后端接口会自己运行,方便模型在回答之前调用查询相关内容。
向量数据保存
向量化后的数据需要持久化存储,否则每次启动项目都需重新向量化,既耗时又增加 token 消耗。为此,我尝试了以下三种保存方式:
内存保存:实现简单,但数据随进程结束而丢失,导致每次启动都需重新加载和向量化,启动时间长,且成本较高。
Redis 保存:具备持久化能力,但实现过程中遇到一些技术障碍,尚未完全成功,可能需要额外配置或网络支持。
本地 JSON 文件保存:效果较好,避免了重复向量化,显著提升启动速度。但当源数据发生变化时,需要手动删除旧的 JSON 文件以重新生成。
为解决数据变更检测问题,我曾设想通过对每个文件进行哈希标记的方式判断是否需要重新向量化。但目前尚未实现,感兴趣的同学可以尝试扩展该方案。
内存保存
实现很简单,在配置文件中添加一个bean
java
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
File file = new File("data/vector-store.json");
file.getParentFile().mkdirs();
return new FileBackedVectorStore(embeddingModel, file);
}json保存
这里需要创建一个实体代替SimpleVectorStore保存在内存中,这里创建了一个FileBackedVectorStore。
配置注册改为如下
java
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
File file = new File("data/vector-store.json");
file.getParentFile().mkdirs();
return new FileBackedVectorStore(embeddingModel, file);
}实体
java
package com.example.demo.entity;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.document.Document;
import jakarta.annotation.PostConstruct;
import jakarta.annotation.PreDestroy;
import org.springframework.ai.vectorstore.filter.Filter;
import org.springframework.stereotype.Component;
import java.io.File;
import java.util.List;
public class FileBackedVectorStore implements VectorStore {
private final SimpleVectorStore delegate;
private final File file;
public FileBackedVectorStore(EmbeddingModel embeddingModel, File file) {
this.delegate = SimpleVectorStore.builder(embeddingModel).build();
this.file = file;
}
@PostConstruct
public void load() {
if (file.exists()) {
delegate.load(file);
System.out.println("✅ Vector store loaded from file: " + file.getAbsolutePath());
} else {
System.out.println("ℹ️ No vector store file found. Starting fresh.");
}
}
@PreDestroy
public void save() {
delegate.save(file);
System.out.println("💾 Vector store saved to file: " + file.getAbsolutePath());
}
@Override
public void add(List<Document> documents) {
delegate.add(documents);
}
@Override
public List<Document> similaritySearch(SearchRequest request) {
return delegate.similaritySearch(request); // ✅ 实现
}
@Override
public void delete(List<String> ids) {
delegate.delete(ids);
}
@Override
public void delete(Filter.Expression filterExpression) {
delegate.delete(filterExpression); // ✅ 推荐补全
}
public File getFile() {
return file;
}
}对话模型创建
在配置文件中创建一个bean,注册一个对话模型,RAG的调用也在这里实现。
java
/**
* 聊天模型
*/
@Bean
public ChatClient chatClient(
OpenAiChatModel model,
ChatMemory chatMemory,
VectorStore vectorStore) {
// 添加 RAG & 记忆顾问
QuestionAnswerAdvisor ragAdvisor =QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.topK(20)
.build())
.build();
return ChatClient.builder(model)
.defaultSystem("你是南昌航空大学的智能招生助手。\n" +
"\n" +
"系统为你提供的资料片段(可能不完整):\n" +
"请结合这些资料内容,**并结合你自己的常识和经验以及对于南昌航空大学往年的了解**,尽力回答用户提出的问题,不要硬搬资料的内容,资料只是提供最新信息\n" +
"如果用户没有提及自己的省份不要随便给一个省份的信息,询问用户的信息\n"+
"如果问学院有关的问题直接在专业表里面查找"+
"如果资料中没有明确提到,也可以适当推理,但要确保专业、可信。不要使用mermaid语法,尽量多的使用图表。\n")
.defaultAdvisors(
new SimpleLoggerAdvisor(),
MessageChatMemoryAdvisor.builder(chatMemory).build(),
ragAdvisor
)
.build();
}数据库连接功能
核心功能讲完,最后讲一下后端的数据库连接,可能不是所有人都用数据库,如果不涉及数据库可以跳过。
后端从某一种程度来说,很多工作是在从数据库中获取数据,经过部分整合或者不整合直接发送给前端,让前端对数据进行显示,所以这里就讲一个简单的例子。
学校介绍是如何从数据库中显示到前端的。
实体层
实体创建几乎跟数据库的表一一对应就可以,这里使用了@Data所以就不需要给每个属性进行set和get方法,还是比较方便的。
java
package com.example.demo.entity;
import lombok.Data;
@Data
public class School {
private String schoolName;
private String schoolInfo;
}数据库dao层
连接数据库之后,在这一层使用查询或者更新等语句实现对数据库的操作。
java
package com.example.demo.dao;
import com.example.demo.entity.School;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.stereotype.Repository;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.List;
@Repository
public class SchoolDao {
@Autowired
@Qualifier("db1JdbcTemplate")
JdbcTemplate jdbcTemplate;
/**
* 显示学校信息
*/
public School findschool_info() {
String sql = "SELECT * from schools";
return jdbcTemplate.queryForObject(sql, new SchoolRowMapper());
}
private class SchoolRowMapper implements RowMapper<School> {
@Override
public School mapRow(ResultSet rs, int rowNum) throws SQLException {
School school = new School();
school.setSchoolName(rs.getString("school_name"));
school.setSchoolInfo(rs.getString("school_info"));
return school;
}
}
}业务层
复杂算法和操作就在这一层实现,由于我这里不需要进行什么变换,所以非常简单。
java
package com.example.demo.service;
import com.example.demo.dao.SchoolDao;
import com.example.demo.entity.School;
import org.springframework.stereotype.Service;
/**
* 显示学校信息
*/
@Service
public class SchoolService {
private static SchoolDao schoolDao = null;
public SchoolService(SchoolDao schoolDao) {
this.schoolDao = schoolDao;
}
public School getSchoolInfo() {
return schoolDao.findschool_info();
}
}接口层
后端对外的接口,测试的路径就是在这里进行设置的。
java
package com.example.demo.controller;
import com.example.demo.entity.School;
import com.example.demo.service.SchoolService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
@RestController
@RequestMapping("/school")
public class SchoolController {
@Autowired
SchoolService schoolService;
/**
* 显示学校信息
*/
@PostMapping("/info")
public Map<String, Object> getSchoolInfo() {
Map<String, Object> result = new HashMap<>();
try {
School school = schoolService.getSchoolInfo();
result.put("status", "success");
result.put("message", "获取学校信息表成功");
result.put("data", school);
} catch (Exception e) {
result.put("status", "error");
result.put("message", "获取用户列表失败:" + e.getMessage());
}
return result;
}
}测试
以这个功能为例,具体演示如何进行后端测试
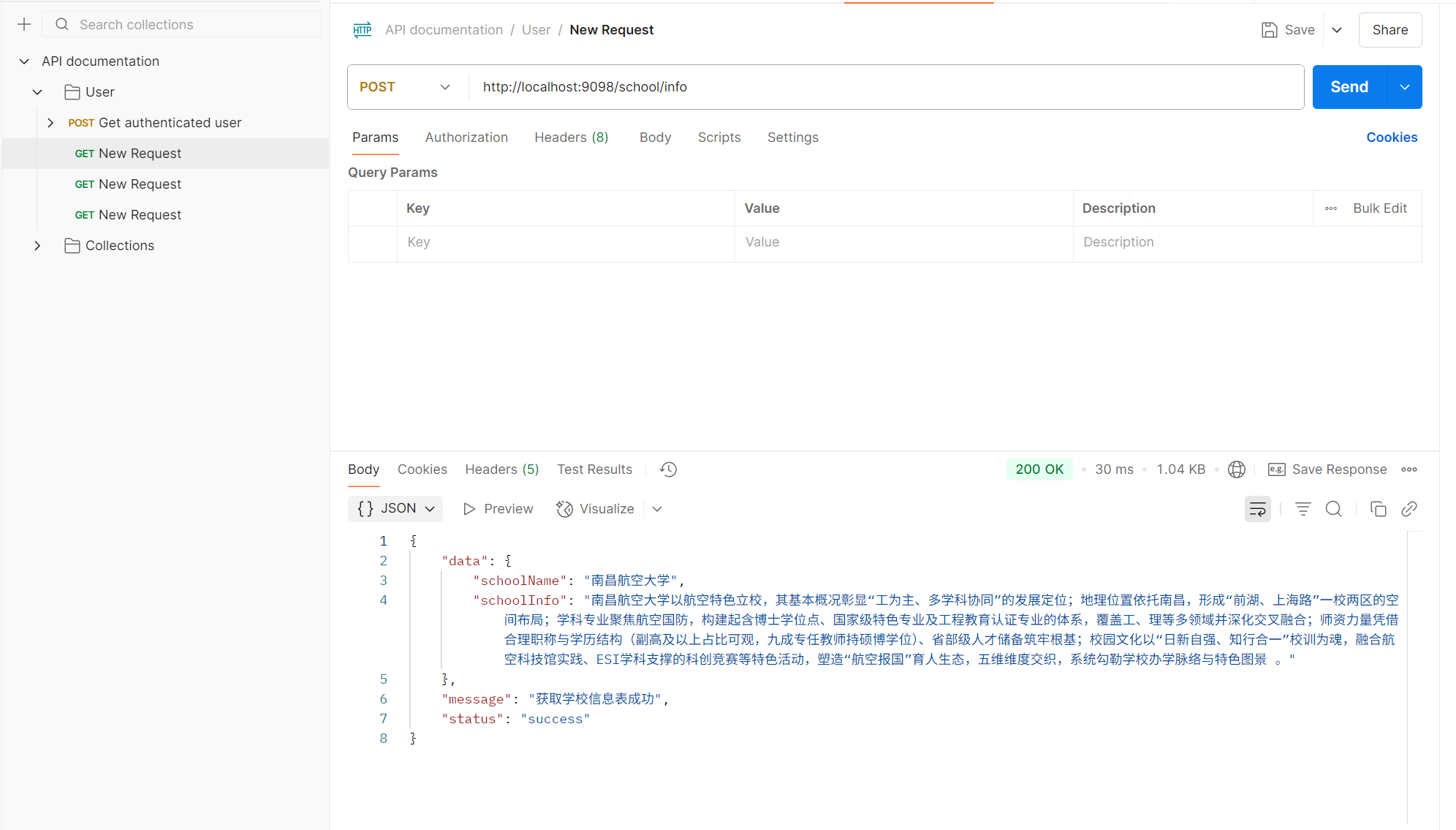
前端
前端我就不讲太多了,因为这部分不是我实现的,现在的ai写个前端还是比较好用的。
总结
大二实训愉快地结束啦!非常感谢一路上支持我们的老师,也感谢每一位参与项目的同伴。虽然一开始这个选题被认为难度较大,不太推荐,但还是很开心你们选择相信我,一起坚持下来。我们也几乎是用最快的速度完成了整个项目,从最终效果来看,这可能是我参与过完成度最高的一次项目了,真的很有成就感!