前言
今天就和大家简单分析一下各任务框架怎么实现定时执行、任务是怎么调度的,如果任务阻塞会发生什么情况。 定时任务框架之间的差异,以及如何去选择我们的定时任务框架。
为什么会写这篇呢!因为之前我们生产环境经常出现定时任务中断的问题 [半年都还没解决的定时任务问题](https://juejin.cn/post/7520204324770627625 "https://juejin.cn/post/7520204324770627625")
我的同事以及网友,都说是任务阻塞了,任务执行时间太长了导致的。仔细看了我的文章或者视频应该就不会说是这些原因了。
定时任务框架原理分析
今天主要分析Spring Task、Quartz、XXL-Job, 这三个还是目前市场上用得比较多几个定时任务组件了。
spring task
Spring Task 是 Spring 框架提供的轻量级任务调度模块,基于 Java 的 ScheduledExecutorService 实现,核心原理可概括为 注解驱动 + 线程池调度 + 触发器机制;
✔不支持分布式调度,只能直接通过分布式锁去实现
基本流程(原理)
1.解析注解、任务注册
后置处理器,处理@Scheduled注解,关键代码ScheduledAnnotationBeanPostProcessor.java
以下代码只是源码的一小部分
java
@Override
public void postProcessAfterInitialization(Object bean, String beanName) {
// 扫描 bean 中所有 @Scheduled 注解的方法
Map<Method, Set<Scheduled>> annotatedMethods = MethodIntrospector.selectMethods(
targetClass,
(MethodIntrospector.MetadataLookup<Set<Scheduled>>) method -> {
Set<Scheduled> scheduledAnnotations = AnnotatedElementUtils.getMergedRepeatableAnnotations(
method, Scheduled.class, Schedules.class);
return (!scheduledAnnotations.isEmpty() ? scheduledAnnotations : null);
});
// 注册任务到 ScheduledTaskRegistrar
processScheduled(annotatedMethods, bean, beanName);
}任务注册:
java
protected void processScheduled(Set<Scheduled> scheduledAnnotations, Method method, Object bean) {
// 创建任务执行器
Runnable runnable = createRunnable(bean, method);
// 解析注解参数,创建触发器
for (Scheduled scheduled : scheduledAnnotations) {
if (StringUtils.hasText(scheduled.cron())) {
// Cron 表达式触发
registrar.addCronTask(new CronTask(runnable, new CronTrigger(scheduled.cron())));
}
else if (scheduled.fixedRate() > 0) {
// 固定频率触发
registrar.addFixedRateTask(new FixedRateTask(runnable, scheduled.fixedRate()));
}
// 其他触发类型...
}
}2. 任务调度器初始化
ScheduledTaskRegistrar 在初始化时创建默认的 ThreadPoolTaskScheduler(若未手动配置):
java
@Override
public void afterPropertiesSet() {
scheduleTasks();
}
protected void scheduleTasks() {
if (this.taskScheduler == null) {
// 创建默认线程池,核心线程数为 1
this.localExecutor = Executors.newSingleThreadScheduledExecutor();
this.taskScheduler = new ConcurrentTaskScheduler(this.localExecutor);
}
// 注册所有任务、将任务任务提交到线程池
if (this.triggerTasks != null) {
for (TriggerTask task : this.triggerTasks) {
addScheduledTask(scheduleTriggerTask(task));
}
}
if (this.cronTasks != null) {
for (CronTask task : this.cronTasks) {
addScheduledTask(scheduleCronTask(task));
}
}
// 其他任务类型...
}3.提交线程池,执行目标方法
步骤2的scheduleTriggerTask方法,最终会调用 ReschedulingRunnable.java中的schedule()方法:
java
public ScheduledFuture<?> schedule() {
synchronized (this.triggerContextMonitor) {
// 计算下一次调度的时间
this.scheduledExecutionTime = this.trigger.nextExecutionTime(this.triggerContext);
if (this.scheduledExecutionTime == null) {
return null;
}
// 计算延迟执行的时间
long initialDelay = this.scheduledExecutionTime.getTime() - this.triggerContext.getClock().millis();
// 将任务提交到 线程池中,this 对象封装了要执行的目标等信息
this.currentFuture = this.executor.schedule(this, initialDelay, TimeUnit.MILLISECONDS);
return this;
}
}提交线程池之后,线程就会调用run方法了
typescript
public void run() {
Date actualExecutionTime = new Date(this.triggerContext.getClock().millis());
// 调用我们的业务代码了
super.run();
Date completionTime = new Date(this.triggerContext.getClock().millis());
synchronized (this.triggerContextMonitor) {
Assert.state(this.scheduledExecutionTime != null, "No scheduled execution");
this.triggerContext.update(this.scheduledExecutionTime, actualExecutionTime, completionTime);
if (!obtainCurrentFuture().isCancelled()) {
// 再次回调schedule()方法,计算下次执行时间
schedule();
}
}
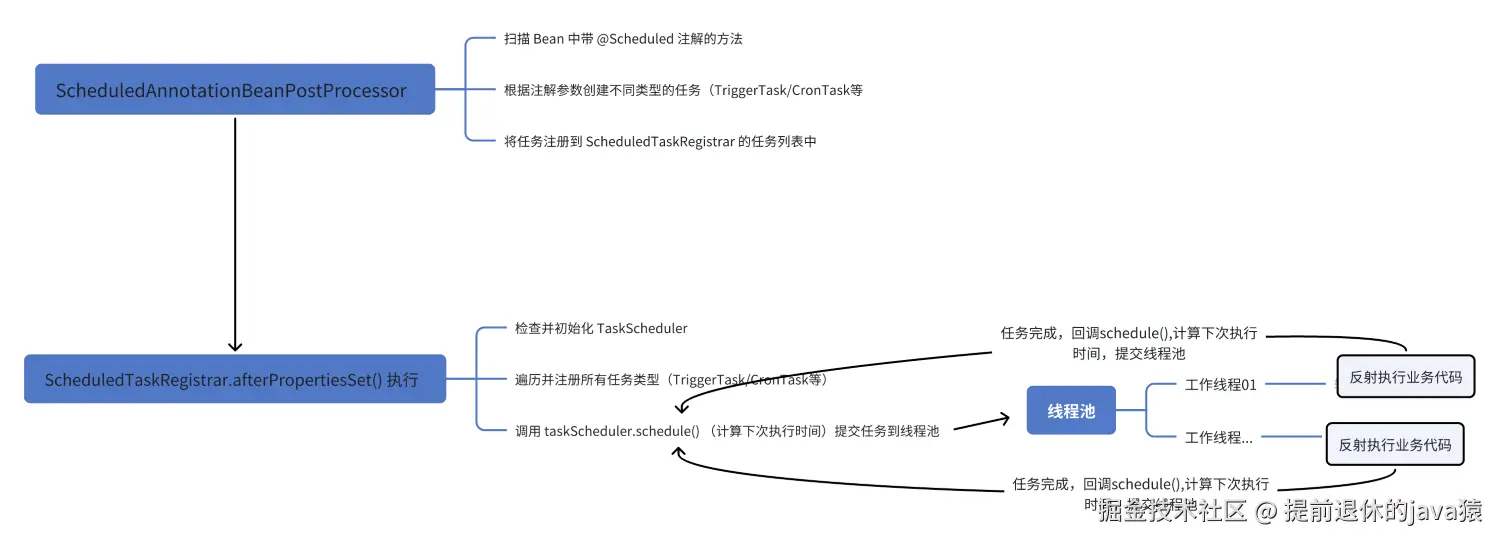
}总结
可以看到spring task 在 postProcessAfterInitialization 去解析我们的注解。 在afterPropertiesSet 阶段会去注册我们的任务,调用schedule方法去计算执行时间,提交到线程池 工作线程执行会去执行我们的run方法,执行我们的tagert 方法,执行完成之后又去回调schedule,一直重复(当然这是我们分析的 scheduleCronTask(task),其他类型大差不差)
✔所以对于同一个任务而言,假设执行过程中发生了阻塞。
✔那么这个当前调用的工作线程也会发生阻塞。并且在执行完成之前,就算到了这个任务的下一次运行时间,也不会触发(下一次的任务也是当前工作线程执行完成之后,计算下一次任务的执行时间然后丢给线程池的)。
❗注意:spring task 默认使用单线程池,建议自己配置线程池
Quartz
Quartz 的启动流程和调度流程核心依赖于其核心组件(Scheduler、ThreadPool、JobStore、SchedulerThread 等)的协作。任务信息的存储方式支持内存和数据库,本次介绍数据库存储的方式
✔支持分布式任务调度
基本流程(原理)
Quartz 的启动流程简单理解为 初始化核心组件(线程池、存储、插件等)并启动调度线程 的过程,核心入口是 SchedulerFactoryBean、StdSchedulerFactory 和 StdScheduler。
1. 初始化流程
Quartz 的初始化还是比较复杂,初始化的入口是在SchedulerFactoryBean类中,该类实现了InitializingBean.afterPropertiesSet接口(👴spring的生命周期还记得吗?)
SchedulerFactoryBean.afterPropertiesSet 方法
java
public void afterPropertiesSet() throws Exception {
if (this.dataSource == null && this.nonTransactionalDataSource != null) {
this.dataSource = this.nonTransactionalDataSource;
}
if (this.applicationContext != null && this.resourceLoader == null) {
this.resourceLoader = this.applicationContext;
}
//初始化 StdSchedulerFactory、scheduler..........
// Initialize the Scheduler instance...
this.scheduler = prepareScheduler(prepareSchedulerFactory());
try {
// 注册监听器
registerListeners();
//注册任务 和 触发器
registerJobsAndTriggers();
}
catch (Exception ex) {
.................
}
}在初始化过程 ,会初始化QuartzSchedulerThread,并且加入到线程池,执行
java
QuartzSchedulerThread(QuartzScheduler qs, QuartzSchedulerResources qsRsrcs, boolean setDaemon, int threadPrio) {
super(qs.getSchedulerThreadGroup(), qsRsrcs.getThreadName());
this.qs = qs;
this.qsRsrcs = qsRsrcs;
this.setDaemon(setDaemon);
if(qsRsrcs.isThreadsInheritInitializersClassLoadContext()) {
log.info("QuartzSchedulerThread Inheriting ContextClassLoader of thread: " + Thread.currentThread().getName());
this.setContextClassLoader(Thread.currentThread().getContextClassLoader());
}
this.setPriority(threadPrio);
// --------暂停线程---------------------------
// start the underlying thread, but put this object into the 'paused' state
// so processing doesn't start yet...
paused = true;
halted = new AtomicBoolean(false);
}QuartzSchedulerThread 的run方法暂时分析,第三步的时候我们再分析
2. 任务状态恢复(集群线程启动)并且开始调度任务
启动调度器方法,由SchedulerFactoryBean.java 实现了Lifecycle.start()接口,在此接口中启动调度器
SchedulerFactoryBean.start() 方法如下:
java
public void start() throws SchedulingException {
if (this.scheduler != null) {
try {
startScheduler(this.scheduler, this.startupDelay);
}
catch (SchedulerException ex) {
throw new SchedulingException("Could not start Quartz Scheduler", ex);
}
}
}核心逻辑: SchedulerFactoryBean 会去new Thread 一个线程去启动QuartzScheduler.start()方法:
java
public void start() throws SchedulerException {
if (shuttingDown|| closed) {
throw new SchedulerException(
"The Scheduler cannot be restarted after shutdown() has been called.");
}
// QTZ-212 : calling new schedulerStarting() method on the listeners
// right after entering start()
notifySchedulerListenersStarting();
if (initialStart == null) {
initialStart = new Date();
//恢复存储的任务信息
this.resources.getJobStore().schedulerStarted();
startPlugins();
} else {
resources.getJobStore().schedulerResumed();
}
//---------------------这一行代码就非常关键了-------
// 任务状态检测恢复完成之后,修改pause变量为false,为唤醒调度线程,开始调度任务
schedThread.togglePause(false);
getLog().info(
"Scheduler " + resources.getUniqueIdentifier() + " started.");
notifySchedulerListenersStarted();
}JobStoreSupport.schedulerStarted() 启动调度器,恢复存储的任务信息
java
public void schedulerStarted() throws SchedulerException {
// 启动 集群管理
if (isClustered()) {
//集群管理线程:
clusterManagementThread = new ClusterManager();
if(initializersLoader != null)
clusterManagementThread.setContextClassLoader(initializersLoader);
clusterManagementThread.initialize();
} else {
try {
//非集群模式 恢复任务
recoverJobs();
} catch (SchedulerException se) {
throw new SchedulerConfigException(
"Failure occured during job recovery.", se);
}
}
misfireHandler = new MisfireHandler();
if(initializersLoader != null)
misfireHandler.setContextClassLoader(initializersLoader);
misfireHandler.initialize();
schedulerRunning = true;
getLog().debug("JobStore background threads started (as scheduler was started).");
}clusterManagementThread这个集群线程也非常重要,关键的方法就run方法调用的 doCheckIn()核心功能就是
- 节点心跳更新:当前调度器节点向集群报告 "存活状态"(更新数据库心跳信息)。
- 故障节点检测:识别集群中因心跳超时(如节点宕机、网络故障)的失效节点。
- 任务接管与恢复:对失效节点的任务进行恢复(将其负责的触发器重新标记为可执行状态),由存活节点接管执行。
3.任务的调度
负责任务调度的线程QuartzSchedulerThread在步骤一【初始化流程】的时候已经初始化并且提交到线程池中执行了。只是运行的时候,会被挂起,直到步骤二【任务状态恢复】被唤醒,或者等待超时继续执行。
我们看一下其run方法(伪代码):
java
public void run() {
while (!halted.get()) { // 调度器未停止时持续运行
// 1. 处理暂停状态:暂停时等待,恢复后重置错误计数器
synchronized (sigLock) {
while (paused && !halted.get()) {
sigLock.wait(1000); // 等待恢复信号
acquiresFailed = 0; // 重置失败计数器
}
}
// 2. 处理连续获取Trigger失败的情况:指数退避策略
if (acquiresFailed > 1) {
long delay = computeDelayForRepeatedErrors(acquiresFailed);
Thread.sleep(delay); // 等待一段时间再重试
}
// 3. 等待工作线程池有可用线程
int availThreadCount = qsRsrcs.getThreadPool().blockForAvailableThreads();
// 4. 获取即将触发的Trigger列表(未来idleWaitTime毫秒内)
List<OperableTrigger> triggers = qsRsrcs.getJobStore().acquireNextTriggers(
System.currentTimeMillis() + idleWaitTime,
Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()),
qsRsrcs.getBatchTimeWindow()
);
// 5. 计算最近Trigger的触发时间,决定是否需要等待
if (!triggers.isEmpty()) {
long triggerTime = triggers.get(0).getNextFireTime().getTime();
long timeUntilTrigger = triggerTime - System.currentTimeMillis();
// 若未到触发时间,精确等待
while (timeUntilTrigger > 2) {
synchronized (sigLock) {
if (halted.get()) break;
sigLock.wait(timeUntilTrigger); // 等待触发时间
}
timeUntilTrigger = triggerTime - System.currentTimeMillis();
}
// 6. 更新Trigger状态为"执行中",并获取Job执行上下文
List<TriggerFiredResult> firedBundles = qsRsrcs.getJobStore().triggersFired(triggers);
// 7. 将Job提交到线程池执行
for (TriggerFiredResult result : firedBundles) {
JobRunShell shell = qsRsrcs.getJobRunShellFactory().createJobRunShell(result);
qsRsrcs.getThreadPool().runInThread(shell); // 提交到线程池
}
} else {
// 若无待触发的Trigger,随机等待一段时间后再次检查
synchronized (sigLock) {
sigLock.wait(getRandomizedIdleWaitTime());
}
}
}
}核心流程如下:
- 状态管理:处理调度器的暂停 / 恢复状态
- 错误恢复:实现指数退避策略,避免频繁重试
- 资源检查:确保工作线程池有可用线程
- Trigger 扫描:从 JobStore 获取即将触发的任务
- 精确等待:计算 Trigger 触发时间,使用 wait 精确控制
- 任务执行:更新 Trigger 状态,创建 Job 执行上下文并提交到线程池
提交到线程池之后,就调用包装之后的JobRunShell,run方法如下(伪代码):
java
public void run() {
// 1. 初始化:获取当前任务和触发器
OperableTrigger trigger = (OperableTrigger) jec.getTrigger(); // 触发器
JobDetail jobDetail = jec.getJobDetail(); // 任务详情
Job job = jec.getJobInstance(); // 具体执行的Job实例
try {
// 2. 开始执行前的准备(如事务开始)
begin();
// 3. 通知监听器:任务开始执行
if (!notifyListenersBeginning(jec)) {
break; // 若被监听器否决,终止执行
}
// 4. 执行Job的核心业务逻辑(用户编写的execute方法)
long startTime = System.currentTimeMillis();
JobExecutionException jobExEx = null;
try {
job.execute(jec); // 调用用户Job的execute方法
} catch (JobExecutionException e) {
jobExEx = e; // 捕获Job主动抛出的异常
} catch (Throwable e) {
jobExEx = new JobExecutionException(e, false); // 包装其他未捕获异常
}
long endTime = System.currentTimeMillis();
jec.setJobRunTime(endTime - startTime); // 记录执行耗时
// 5. 通知监听器:任务执行完成
notifyJobListenersComplete(jec, jobExEx);
// 6. 处理触发器后续状态(计算下次执行时间等)
CompletedExecutionInstruction instCode = trigger.executionComplete(jec, jobExEx);
notifyTriggerListenersComplete(jec, instCode);
// 7. 根据指令决定是否重试
if (instCode == CompletedExecutionInstruction.RE_EXECUTE_JOB) {
continue; // 重新执行当前Job(循环继续)
}
// 8. 完成执行(如事务提交)
complete(true);
qs.notifyJobStoreJobComplete(trigger, jobDetail, instCode); // 通知JobStore更新状态
} catch (Exception e) {
// 异常处理:通知监听器错误信息
qs.notifySchedulerListenersError("执行任务出错", e);
} finally {
// 清理资源:移除监听器
qs.removeInternalSchedulerListener(this);
}
}核心逻辑如下:
- 初始化:获取当前要执行的
Job实例、Trigger触发器和上下文信息。 - 前置通知:通过监听器(
JobListener、TriggerListener)通知 "任务开始执行",支持监听器否决执行(如VetoedException)。 - 核心执行:调用用户实现的
Job.execute()方法,捕获所有异常(包括用户主动抛出的JobExecutionException)。 - 后置处理:
- 记录执行耗时。
- 通知监听器 "任务执行完成"。
- 触发器计算下次执行时间(
executionComplete)。
- 重试机制:若触发器指令为
RE_EXECUTE_JOB,则重新执行当前任务(循环继续)。 - 收尾工作:完成事务、更新 JobStore 中任务和触发器的状态。
总结
Quartz 通过 "初始化调度器→循环检测触发条件→分配线程执行任务→更新任务状态" 的流程,实现了任务的定时、周期性调度。主要就是在spring生命周期阶段afterPropertiesSet这个阶段完成初始化工作,以及在refresh 阶段调用Lifecycle.start()接口去恢复任务状态,唤醒调度线程进行任务调度。
✔和spring task 一样同一个任务,执行完成之后才会接着执行(就算执行过程下一次的执行时间又到了)
✔任务调度由
QuartzSchedulerThread循环调度,所以如果该线程阻塞那么所有的任务都将阻塞
xxl-job
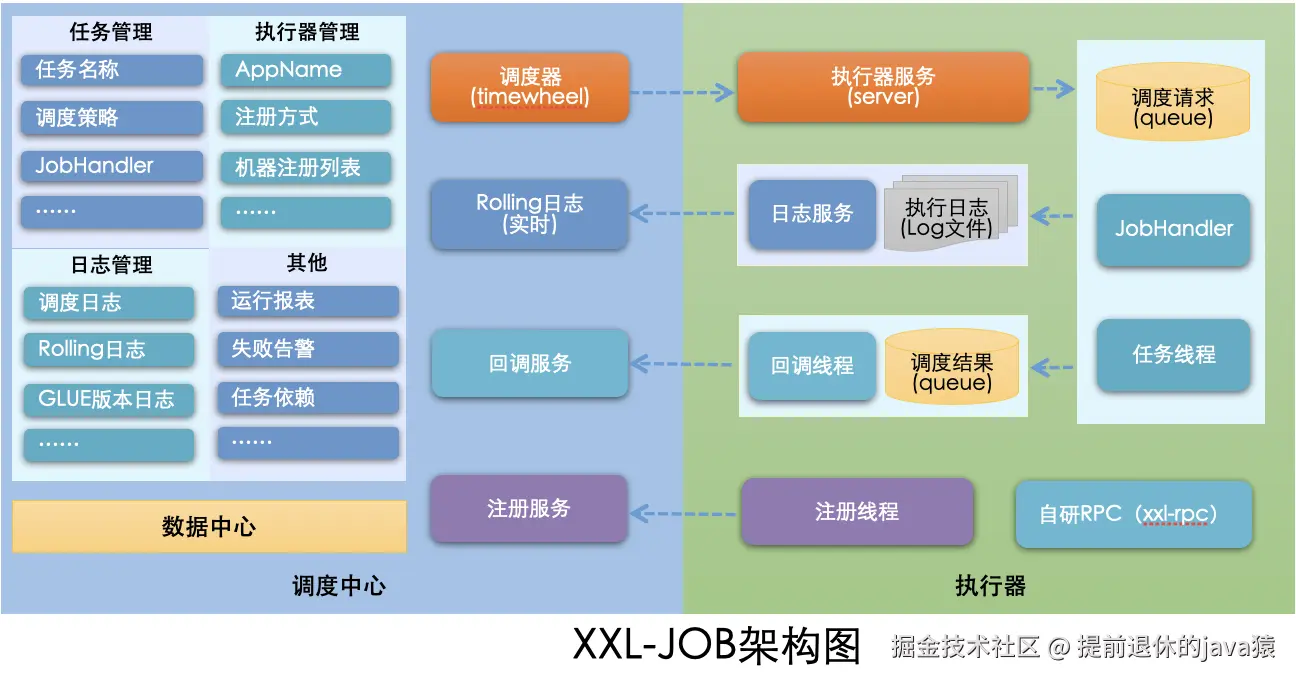
xxl-job远比前面两个框架复杂,从大的架构上来说就分为XL-Job 采用 "调度中心 + 执行器" 的分布式架,类似配置中心,服务端需要单独的部署,支持集群部署。先看看架构图吧:
-
调度中心(Scheduler)
- 核心功能:管理任务元数据(如任务名称、调度规则、执行器地址等)、触发任务调度、监控任务执行状态、记录执行日志。
- 本质:一个独立部署的 Web 应用,不直接执行任务,仅负责 "发号施令"。
-
执行器(Executor)
- 核心功能:接收调度中心的任务触发请求、执行具体任务逻辑、将执行结果回调给调度中心。
- 本质:嵌入业务系统的组件(或独立部署的服务),负责 "干活",可集群部署以提高吞吐量。
任务调度核心流程
XXL-Job 的调度过程可概括为 "任务注册 → 调度触发 → 任务执行 → 结果回调" 四个步骤,具体细节如下:
1. 任务注册与发现
-
执行器注册到调度中心 :
执行器启动时,会通过 心跳机制 向调度中心注册自身信息(如 IP、端口、应用名称),调度中心将其维护在内存中,用于后续任务分发。
(✔若执行器集群部署,调度中心会感知到所有节点,形成可用节点列表)
-
任务配置 :
开发人员在调度中心配置任务(如 Cron 表达式、执行器名称、任务参数等),调度中心将任务元数据存储在数据库中(确保重启后不丢失)。
2. 调度触发(核心逻辑)
调度中心基于 Cron 表达式 或 手动触发 生成调度指令,关键步骤如下:
-
触发源:
定时触发:调度中心内置 时间轮(TimeWheel) 机制,根据任务的 Cron 表达式计算下次执行时间,到期后触发调度。
手动触发:通过调度中心 UI 手动点击 "执行" 按钮,立即触发。
-
任务路由(分发) :
调度中心根据任务配置的 路由策略(如轮询、随机、一致性哈希等),从执行器集群中选择一个节点,生成 HTTP 请求(包含任务 ID、参数等),发送执行指令。 (若执行器集群有 3 个节点,轮询策略会依次将任务分配给每个节点)
-
重试机制 :
若调度中心发送请求失败(如执行器节点宕机),会根据配置的重试次数重复发送,确保任务尽可能被执行。
3. 任务执行
执行器接收到调度中心的 HTTP 请求后,执行具体任务逻辑:
- 线程池处理 :执行器内部维护一个 任务线程池,接收到的任务会被提交到线程池异步执行,避免单任务阻塞影响其他任务。
- 任务隔离:通过线程池隔离不同任务,防止某一任务异常(如死循环)占用所有资源。
4. 结果回调与日志记录
- 执行结果反馈 :
任务执行完成后,执行器将结果(成功 / 失败、日志 ID 等)通过 HTTP 回调给调度中心,调度中心更新数据库中的任务状态。 - 日志处理 :
任务执行日志默认存储在执行器本地磁盘,调度中心通过日志 ID 远程读取执行器的日志文件,实现日志集中查看。
总结(如何选择定时任务组件)
Spring Task:使用简单,非单例的情况需要自己实现分布式锁。业务体量小或者业务属性不是特别的敏感(如定时清理本地缓存、简单数据同步) 可以使用优先考虑这个框架。
Quartz:支持复杂的调度规则,也支持分布式场景。每个业务系统维护各自的任务状态,同时任务调用的各个阶段的监听器还是挺完善的。可以化界面的化需要自己实现,学习成本还是挺高的。(考虑使用Quartz 还不如使用xxl-job)
xxl-job: 调度中心单独部署,方便扩展,和业务系统解耦。支持分布式系统,视化管理、监控告警、动态调整任务。业务体量大,需要对任务做监控,选择xxl-job是个不错的选择
还有那些定时任务组件或者框架,欢迎留言评论🤞
😭 xxl-job的源码没有分析了, 因为跟了spring task 和 Quartz 源码之后,精力已经被吸干了。继续分析的话,这篇文章也会变得非常长。如果有兄弟想看 xxl-job 的源码分析的话,也可以留言。我单独出一篇文章