Manus 是我平时最常用的通用 Agent,上篇文章介绍了 ManusAI 花费千万美金在 AI Agent 上下文过程上的经验和教训。本篇文章我将介绍下通用 Agent 操作浏览器进行页面浏览和行为是如何实现的(参考开源项目 OpenManus 的代码实现)。
browser-use 是什么
browser-use 是一个开源项目,旨在让 AI Agent 能够轻松地访问和操作网站,从而实现网络任务的自动化。 简单来说,它就像一个连接 AI 和浏览器的桥梁,让你可以通过自然语言指令来控制浏览器完成各种任务。
主要功能和特点:
- 自然语言控制:用户可以通过简单的自然语言(例如,"打开闲鱼搜索 iphone16")来指挥 AI Agent 执行浏览、搜索、数据提取等一系列操作。
- 自动化任务:它可以自动化各种在线任务,例如商品价格多平台比较、多家公司联系方式查询等。
- 强大的技术支持:该项目基于 Python,并集成了 Playwright 等浏览器自动化工具。 它支持多种大型语言模型(LLM),如 GPT-4、Claude 和 DeepSeek。
- 可视化与交互 :除了通过代码运行,
browser-use还提供了 Web UI 和桌面应用,方便用户进行测试和交互。 它甚至可以生成任务执行过程的 GIF 动图,让流程一目了然。 - 并行处理能力:与人类顺序性的工作方式不同,该项目的一大优势是能够并行处理相似的任务,例如同时搜索提取 iphone、mac 商品信息,极大地提高了效率。
工作原理
browser-use 的工作流程概括:
- 捕获浏览器状态:首先获取浏览器当前页面的实时状态。
- LLM 决策:将捕获到的信息整合后交由大型语言模型(LLM)进行分析和决策,判断下一步需要执行什么操作。
- 执行动作:根据 LLM 的决策,执行相应的浏览器操作(如点击、输入等)。
- 循环:重复以上步骤,直到完成预设的最终任务。
使用 Demo
由于最新版本使用 Chrome 的 CDP 协议,我本地机器启动报错,改为使用版本:``
ini
import asyncio
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from browser_use import Agent
load_dotenv()
api_key = os.getenv('DEEPSEEK_API_KEY', '')
if not api_key:
raise ValueError('DEEPSEEK_API_KEY is not set')
async def run_search():
agent = Agent(
task=(
"1. 打开 https://www.goofish.com"
"2. 在搜索框中搜索 'iphone15promax' "
"3. 根据价格排序,列出前2页的商品名称和价格"
),
llm=ChatOpenAI(
base_url='https://api.deepseek.com/v1',
model='deepseek-chat',
api_key=api_key,
),
use_vision=False,
)
await agent.run()
if __name__ == '__main__':
asyncio.run(run_search())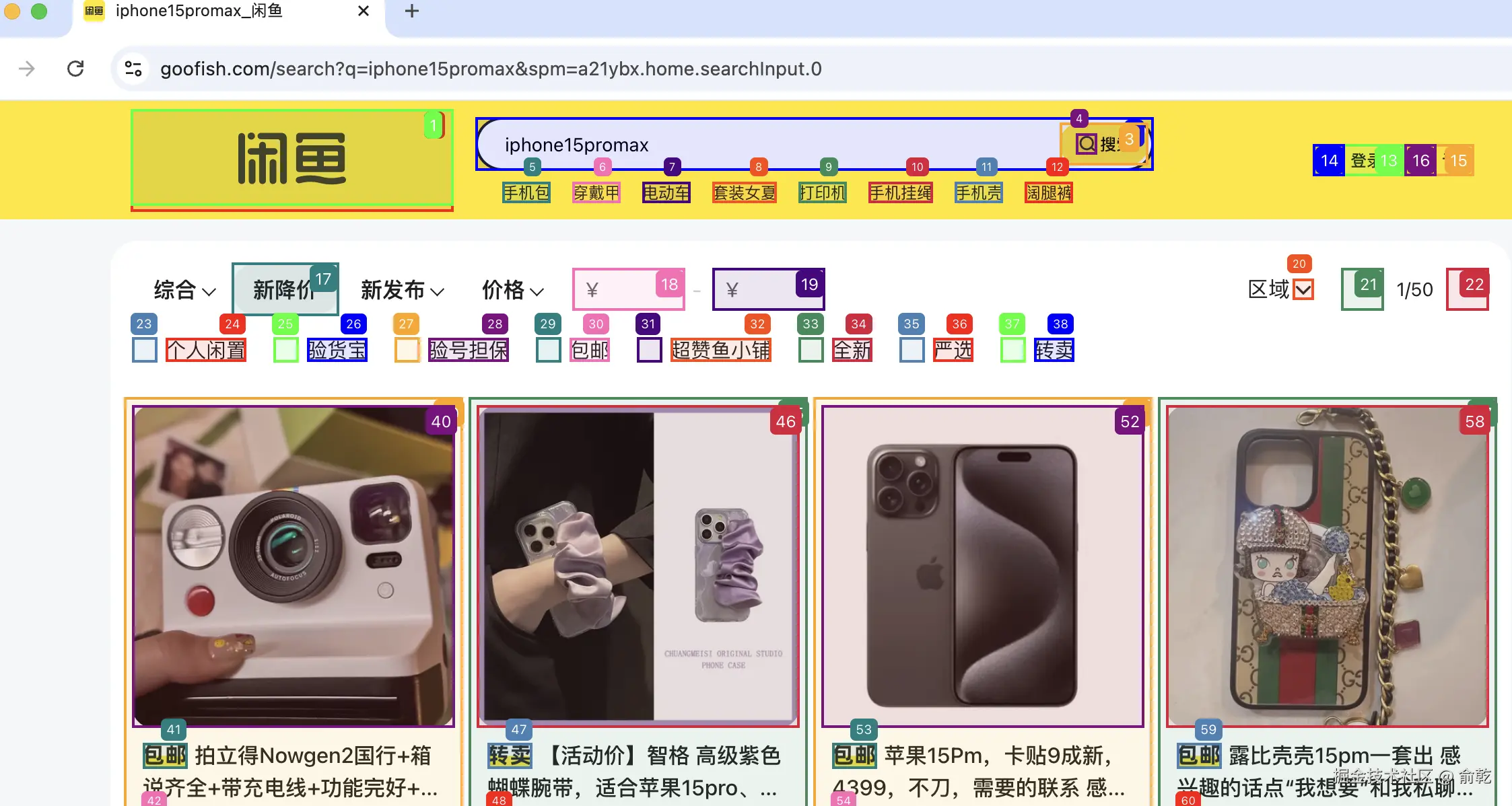
提取结构:
json
{
"products": [
{
"name": "拍立得Nowgen2国行+箱说齐全+带充电线+功能完好+镜片 完好+99新(拍过几张|要全新的自己去TB买)(彩虹背带➕相纸另➕),识货的来,自提优先。",
"price": "¥660"
},
{
"name": "【活动价】智格 高级紫色蝴蝶腕带,适合苹果15pro、iPhone 14 Pro Max、13 Pro Max、12 Pro机型。颜色有羽纱紫色蝴蝶、香芋紫褶皱丝巾腕带、浅紫皮斜挎。女款设计,时尚百搭。数量有限,先到先得!",
"price": "¥15"
},
{
"name": "苹果15Pm,卡贴9成新,4399,不刀,需要的联系 感兴趣的话点"我想要"和我私聊吧~",
"price": "¥4399"
}
// ...
]
} 最终程序输出了闲鱼前两页搜结果的商品标题和价格。这样我们就可以把该输出文本交由后续的 Agent 进行处理。
最终程序输出了闲鱼前两页搜结果的商品标题和价格。这样我们就可以把该输出文本交由后续的 Agent 进行处理。
tips
如果 Playwright 在 macOS 环境下启动 Chromium 浏览器时遇到 FileNotFoundError 报错,则表示 Playwright 无法找到或启动其下载的 Chromium 浏览器可执行文件。
重新安装 Playwright 浏览器驱动
请在您的终端中运行以下命令,确保所有 Playwright 支持的浏览器都已正确安装:
csharp
playwright install --with-deps这个命令会安装所有浏览器及其依赖项。如果之前安装过,它也会尝试修复或更新。
OpenManus 中使用
在 OpenManus 中,browser-use 被定位为一个核心的工具,专门用于处理与浏览器相关的操作。通过 browser-use,OpenManus 中的 Agent 能够实现以下关键功能:
- 网页导航:访问指定的 URL,实现页面跳转。
- 元素交互:点击按钮、输入文本、选择下拉菜单项等,模拟用户在网页上的操作。
- 信息提取:获取当前页面的内容、提取特定元素的属性,从而理解网页上的信息。
- 会话管理:管理浏览器会话,包括打开新标签页、关闭标签页、关闭浏览器等,以适应复杂任务的需求。
- 状态感知:获取浏览器当前状态的快照,包括当前 URL、打开的标签页、以及页面上可交互元素的详细信息,这对于 Agent 的决策至关重要。
这种集成方式使得 Agent 能够将复杂的网页操作抽象为一系列可执行的工具调用,从而将精力集中在更高层次的决策和规划上,而不是底层的浏览器操作细节。
Prompt
先看下 OpenManus 的 Browser 的 Prompt,地址:github.com/FoundationA...
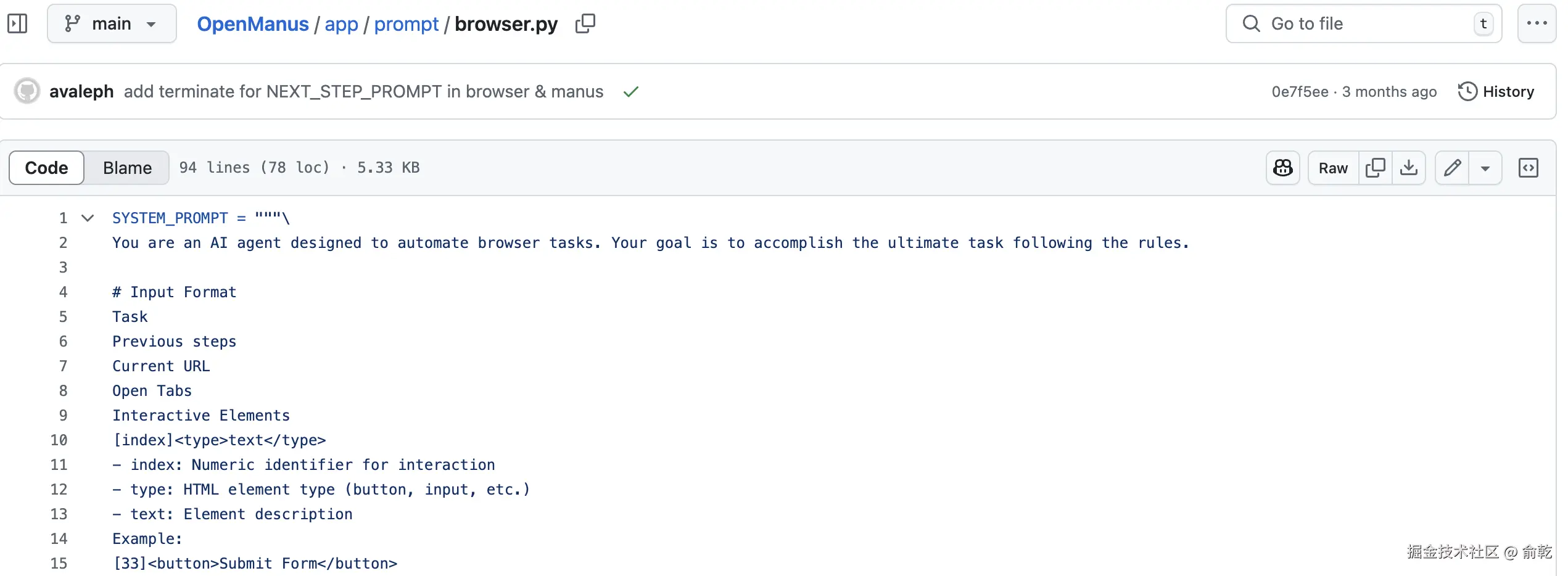
关键组成部分:
1. Agent 角色定义
提示词首先明确了 Agent 的身份和目标:
vbnet
You are an AI agent designed to automate browser tasks. Your goal is to accomplish the ultimate task following the instructions below.这为 Agent 设定了清晰的上下文,使其知道自己是一个专门用于浏览器自动化的 AI,并且其核心目标是完成用户给定的最终任务。
2. 输入格式 (Input Format)
为了让 Agent 能够理解当前的浏览器状态和任务进展,提示词定义了详细的输入格式,包括:
- Task:Agent 需要完成的最终任务描述。
- Previous steps:Agent 已经完成的步骤,这有助于 Agent 保持任务的连贯性。
- Current URL:当前浏览器页面的 URL,提供上下文信息。
- Open Tabs:当前打开的所有标签页列表,让 Agent 了解多标签页的情况。
- Interactive Elements:这是最关键的部分,它以结构化的方式列出了当前页面上所有可交互的元素。每个元素都包含 index(用于交互的唯一标识符)、type(HTML 元素类型,如 button、input 等)和 text(元素的描述或可见文本)。
例如:[33]<button>Submit Form</button>,这种格式使得 Agent 能够清晰地识别页面上的可操作项,并根据其索引进行精确操作。提示词还强调,只有带有数字索引的元素才是可交互的,没有索引的元素仅提供上下文信息。
3. 响应规则 (Response Rules)
提示词严格规定了 Agent 的响应格式,要求必须是有效的 JSON 格式,包含 current_state 和 action 两个主要字段:
-
current_state:- evaluation_previous_goal:对上一个目标的评估结果(Success、Failed 或 Unknown),用于自我修正和学习。
- memory:Agent 的记忆,用于描述已经完成的工作和需要记住的信息,并强调要非常具体,甚至记录尝试次数。
- next_goal:Agent 的下一个即时目标,这是 Agent 规划下一步行动的关键。
-
action:一个包含一个或多个动作的列表。尽管提示词允许指定多个动作,但特别强调"always specify only one action at a time"(每次只指定一个动作),这可能是为了简化 LLM 的推理复杂性或确保操作的原子性。
4. 常用动作 (Common action sequences)
提示词列举了 Agent 可以执行的常用浏览器操作,并说明了每个动作所需的参数:
click:点击元素(index)。type:在输入框中输入文本(index, text)。goto:导航到指定 URL(url)。scroll:滚动页面(direction,"up" 或 "down")。evaluate:执行 JavaScript 代码(code)。screenshot:截取屏幕截图(path)。finish:表示任务完成(result)。
明确的动作定义和参数要求,使得 LLM 能够生成符合预期的、可执行的浏览器操作指令。提示词中还包含了一个详细的示例,展示了输入和输出的完整流程,这对于 LLM 理解任务和生成正确响应至关重要。
BrowserAgent 核心逻辑
OpenManus 在 app/agent/browser.py 中实现了 BrowserAgent,它是负责执行浏览器任务的核心 Agent。BrowserAgent 继承自 ToolCallAgent,表示它是一个能够调用外部工具来完成任务的 Agent。其核心逻辑围绕着 BrowserContextHelper 和 run 方法展开。
1. BrowserContextHelper:浏览器状态的感知器
BrowserContextHelper 是 BrowserAgent 的一个内部辅助类,它负责与底层的 BrowserUseTool 进行交互,以获取当前的浏览器状态。其主要功能体现在 get_browser_state 方法中:
ini
class BrowserContextHelper:
# ...
@model_validator(mode="after")
def get_browser_state(self) -> Optional[dict]:
browser_tool = self.agent.available_tools.get_tool(BrowserUseTool.name)
# ...
try:
state = browser_tool.get_current_state()
self.current_base64_image = state.get("screenshot")
return state
# ...这个方法通过调用 BrowserUseTool 的 get_current_state() 方法来获取浏览器当前的详细状态,包括当前 URL、DOM 结构(通过 Interactive Elements 呈现)、以及可选的屏幕截图(screenshot)。current_base64_image 字段用于存储页面的 Base64 编码截图,这使得 Agent 能够进行视觉感知,从而更好地理解页面布局和内容。BrowserContextHelper 确保了 BrowserAgent 始终能够获取到最新的、全面的浏览器环境信息,这是其进行有效决策的基础。
2. BrowserAgent 的 run 方法与提示词集成
BrowserAgent 的 run 方法是其执行任务的入口。在每次执行任务时,它首先会调用 self.context_helper.get_browser_state() 来更新对浏览器状态的感知。然后,它会利用 ToolCallAgent 的能力,将这些状态信息与任务描述结合,生成一个完整的提示词,发送给 LLM 进行推理。LLM 根据提示词生成下一步的行动计划,BrowserAgent 再将这些行动指令传递给 BrowserUseTool 来执行。
python
class BrowserAgent(ToolCallAgent):
# ...
def __init__(self, **data):
super().__init__(**data)
self.context_helper = BrowserContextHelper(self)
async def run(self, message: Message) -> Message:
self.context_helper.get_browser_state() # 获取最新浏览器状态
return await super().run(message) # 将状态和任务传递给 LLM 并执行
def get_prompt_template(self) -> str:
return SYSTEM_PROMPT # 返回系统提示词模板
def get_next_step_prompt_template(self) -> str:
return NEXT_STEP_PROMPT # 返回下一步提示词模板
def get_tools(self) -> ToolCollection:
return ToolCollection([BrowserUseTool, Terminate]) # 注册可用的工具
def get_tool_choice(self) -> ToolChoice:
return ToolChoice(type="tool", function=BrowserUseTool.name) # 默认选择 BrowserUseTool
def get_image(self) -> Optional[str]:
return self.context_helper.current_base64_image # 提供当前页面的截图BrowserAgent 通过 get_prompt_template 和 get_next_step_prompt_template 方法,将预定义的 SYSTEM_PROMPT 和 NEXT_STEP_PROMPT(在 app/prompt/browser.py 中定义)提供给 LLM。这些提示词包含了 Agent 的角色、输入格式、响应规则和可执行动作的详细说明,确保 LLM 能够生成符合预期的、可执行的浏览器操作指令。
工具封装:BrowserUseTool 的功能实现
OpenManus 在 app/tool/browser_use_tool.py 中对 browser-use 库进行了封装,创建了 BrowserUseTool。这个工具是 BrowserAgent 与实际浏览器操作之间的桥梁。它将 LLM 生成的抽象动作指令,转化为 browser-use 库的具体 API 调用。
1. BrowserUseTool 的初始化与生命周期管理
BrowserUseTool 是一个单例模式的工具,确保只有一个浏览器实例在运行。它在初始化时会创建 BrowserUseBrowser 和 BrowserContext 实例:
ini
class BrowserUseTool(BaseTool, Generic[T]):
# ...
_browser: Optional[BrowserUseBrowser] = None
_context: Optional[BrowserContext] = None
@model_validator(mode="after")
def init_browser(self, info: ValidationInfo) -> "BrowserUseTool":
if BrowserUseTool._browser is None:
BrowserUseTool._browser = BrowserUseBrowser(
config=BrowserConfig(headless=config.browser_headless)
)
if BrowserUseTool._context is None:
BrowserUseTool._context = BrowserContext(
browser=BrowserUseTool._browser,
config=BrowserContextConfig(
dom_service=DomService(llm=LLM.get_instance())
),
)
return self
# ...这里值得注意的是,BrowserConfig 中的 headless 参数可以通过 config.browser_headless 进行配置,这意味着用户可以选择是否在无头模式下运行浏览器(即是否显示浏览器界面)。BrowserContextConfig 中还集成了 DomService,并且 DomService 内部使用了 LLM.get_instance(),这表明 browser-use 库本身也可能利用 LLM 来辅助处理 DOM 相关的任务,例如解析复杂的 DOM 结构或识别交互元素。
2. _run 方法:动作的调度中心
BrowserUseTool 的核心功能体现在其异步的 _run 方法中。这个方法接收 LLM 生成的 action 参数,并根据 action 的值调用 browser-use 库中对应的浏览器操作方法:
ini
async def _run(self, **kwargs) -> ToolResult:
action = kwargs.pop("action")
if action == "goto":
url = kwargs.get("url")
# ...
await BrowserUseTool._context.goto(url)
# ...
elif action == "click":
index = kwargs.get("index")
# ...
await BrowserUseTool._context.click(index)
# ...
# ... 其他动作的实现 ...
elif action == "get_current_state":
state = await BrowserUseTool._context.get_current_state()
return ToolResult(success=True, message="Current browser state retrieved", content=state)
# ...
elif action == "web_search":
query = kwargs.get("query")
# ...
search_tool = WebSearch()
search_result = await search_tool.run(query=query)
return ToolResult(success=True, message="Web search performed", content=search_result.content)
# ..._run 方法覆盖了提示词中定义的所有常用动作,包括 goto、click、type、scroll、get_current_state、get_page_content、get_element_attributes、take_screenshot、new_tab、close_tab、close_browser。特别值得注意的是,BrowserUseTool 还封装了 WebSearch 工具,这意味着 BrowserAgent 不仅能够直接操作浏览器,还能够执行网页搜索,这进一步增强了其信息获取能力。
3. get_current_state 方法:同步状态获取
BrowserUseTool 还提供了一个同步的 get_current_state 方法,供 BrowserContextHelper 调用。尽管 browser-use 的核心操作是异步的,但为了适应 Agent 框架中可能存在的同步状态获取需求,这里使用了 asyncio.run 来同步执行异步的 get_current_state 调用:
python
def get_current_state(self) -> Optional[dict]:
if BrowserUseTool._context:
# This is a synchronous call for the agent to get the current state
# In a real async environment, this might need to be handled differently
return asyncio.run(BrowserUseTool._context.get_current_state())
return None这种设计确保了 Agent 即使在同步上下文中也能获取到最新的浏览器状态,尽管在纯异步环境中可能需要更优雅的处理方式。
总结与展望
OpenManus 对 browser-use 的集成是一个典型的 Agent 框架如何利用外部工具扩展自身能力的案例。通过精心设计的提示词、模块化的 Agent 实现和功能丰富的工具封装,赋予了 Agent 强大的网页交互能力。
就体验上来说,OpenManus 对 browser-use 的使用还可以进一步优化:
- 更智能的 DOM 解析 :利用更先进的视觉语言模型(VLM)直接从屏幕截图理解页面,减少对结构化
Interactive Elements的依赖。 - 任务规划与分解:增强 Agent 自动将复杂任务分解为更小、更易管理的子任务的能力。
- 错误恢复与自愈:当遇到浏览器操作失败时,Agent 能够更智能地诊断问题并尝试不同的策略进行恢复。
参考文献
- browser-use: github.com/browser-use...
- OpenManus: github.com/FoundationA...