首先,我们来定义一下什么是空间索引,以及为什么在应用程序开发中需要它。空间索引可以降低在特定区域内搜索空间分布对象子集的计算成本。
例如,当你在手机上打开 Uber 应用时,它并不会搜索系统中所有已注册的出租车,而只会搜索你当前位置周围一定半径范围内的出租车。或者以计算机图形学为例:为了将帧速率保持在可接受的水平,游戏引擎或 CAD 软件会选择性地渲染摄像头视野范围内的物体。这需要空间查询。在所有这些情况下,通常都会使用空间索引。
为什么这很重要?如果没有索引,在地图点云中查找最近点的复杂度是线性的,并且取决于点的总数。如果点位于球体上,并由经纬度指定,那么对于点云中的每个点,都需要使用半正矢公式计算到搜索圆中心的距离。
如您所见,此公式涉及两次
unc Haversine(p1, p2 LngLat) float64 {
dLat := (p2.Lat - p1.Lat) * degInRad
dLon := (p2.Lng - p1.Lng) * degInRad
lat1 := p1.Lat * degInRad
lat2 := p2.Lat * degInRad
sinDLat2 := math.Sin(dLat / 2)
sinDLat2 *= sinDLat2
sinDLon2 := math.Sin(dLon / 2)
sinDLon2 *= sinDLon2
a := sinDLat2 + math.Cos(lat1)*math.Cos(lat2)*sinDLon2
return 2 * earthRadius * math.Atan2(math.Sqrt(a), math.Sqrt(1-a))
}平方根计算、两次正弦函数、两次余弦函数和一次反正切函数。总而言之,这些函数使得计算球形地球模型表面两点之间距离的函数计算量相当大。
为了证明这一点,让我们运行一个基准测试:
func BenchmarkHaversine(b *testing.B) {
p1 := LngLat{Lng: 1, Lat: 2}
p2 := LngLat{Lng: 3, Lat: 4}
for i := 0; i < b.N; i++ {
Haversine(p1, p2)
}
}
cpu: Intel(R) Core(TM) i7-4770HQ CPU @ 2.20GHz
BenchmarkHaversine-8 11320910 103.2 ns/op. 0 B/op 0 allocs/op每次操作 10^3 纳秒的速度意味着,如果您的点云包含 100 万个点,那么生成位于某个圆内的点子集将至少需要 10^3 毫秒------这还不包括任何额外的内存分配开销(如果需要)。换句话说,在单个 CPU 核心上,应用程序每秒最多可以执行 10 次这样的查询。
现在,如果您需要为每个点找到最近邻点(例如,实现 Delaunay 三角剖分或 DBSCAN 聚类),那么在算法复杂度为 O(n²) 的情况下,您需要花费 1.2 天的计算时间。由于复杂度是二次方的,因此对 1000 万个点进行聚类大约需要 4 个月的时间。
但是,如果使用空间索引,每个子查询的成本就会降至 O(log n),从而可以在不到一小时的时间内(而不是 4 个月)聚类 1000 万个点。
在本文中,我们将探讨空间索引背后的原理,研究用于实现它的常见数据结构,并评估其在实际场景中的性能。目标是了解如何选择和应用正确的空间索引,以显著加速实际应用中的空间查询。
四叉树、八叉树和超八叉树
四叉树 (QuadTree) 数据结构理解和实现都相当简单。将一定范围内的二维空间划分为四个相等的矩形或正方形。然后,每个正方形递归地细分为四个嵌套的较小正方形,并持续此过程,直到达到指定的最大深度。总共可生成最多 4^N 个正方形,其中 N 为最大深度。
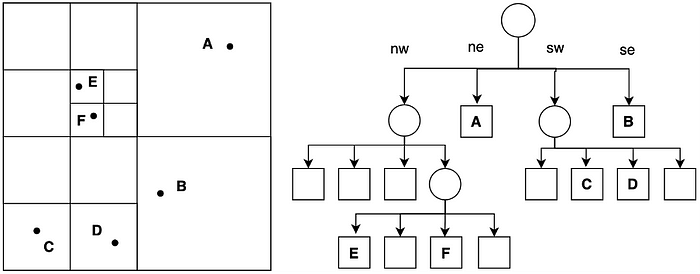
图 1:四叉树示例------点图(左)和相应的树结构(右)
每个方块包含空间对象,通常由一个边界框定义。如果边界框完全适合某个子方块,则会将其传递到树的相应分支中。对于点云,点总是以这种方式"落户"在叶节点中。
然而,没有必要创建所有级别的嵌套。事实上,当空间对象分布不均匀时,最有效的方法是在树的深度和每片叶子节点的对象数量之间取得平衡。例如,仅仅为了找到一个对象就遍历 10 个父边界框会浪费资源。因此,在实践中,除了最大深度之外,每片叶子节点的最小对象数量通常也被定义为进一步细分的阈值。
由于搜索对象的数量在每一层嵌套中都会除以 4,并且假设空间分布足够均匀,因此四叉树的搜索复杂度为 O(log n)。插入、删除和移动对象的复杂度均为 O(1)。然而,为了实现真正的高性能,重要的是应用额外的优化措施来降低内存分配的频率------理想情况下,可以通过缓冲等技术完全消除内存分配。
正是出于这个原因,图形引擎中四叉树的分支通常被实现为场景图节点的特例。这种数据结构的局限性很明显:空间必须是线性的和二维的。
下一个数据结构自然地继承了前一个结构,只是简单地添加了第三个空间维度:八叉树。从根本上讲,它的工作原理相同,只不过是在 3D 坐标系中。八叉树主要用于 3D 游戏引擎和 CAD 系统。
理论上,你可以通过添加任意数量的空间维度来延续这种模式。当维度数超过 3 时,这种结构通常被称为超八叉树 (HyperOctree)。然而,在实践中,超八叉树很少使用,因为维度数的增加会指数级增加嵌套超立方体的数量。因此,KD 树 (KD Tree) 是一个更实用的替代方案。
KD树
KD 树是一种二叉树,用于组织任意维度 K 空间中的点。与将空间划分为相等正方形或立方体的四叉树或八叉树不同,KD 树根据点本身的实际坐标值来划分空间。
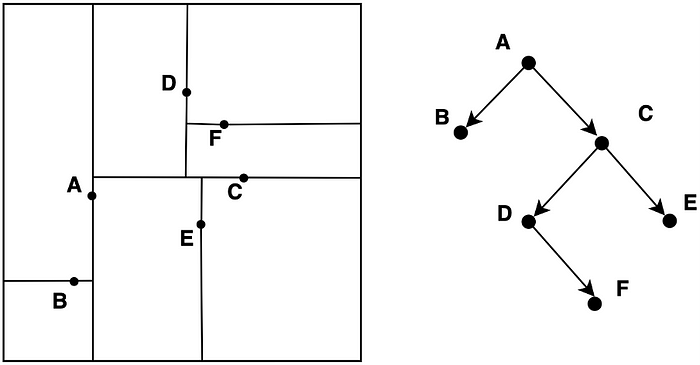
图 2:KD 树的示例,左侧有点,右侧树
树中的每个节点代表原始数据集中的一个点。插入点时,算法会在树的每一层选择一个坐标轴(例如,先 X,然后 Y,然后 Z,依此类推),并比较沿该轴的值。值较小的点进入左子树,值较大或相等的点进入右子树。通过这种方式,树会递归地沿每个轴将空间一分为二,并在每一层交替使用不同的轴。
这种方法即使在高维空间中也能保持树的结构相对平衡,而四叉树等传统结构由于单元数量呈指数增长而变得效率低下。
KD 树中最近邻搜索的复杂度与四叉树相同------O(log n)。然而,与四叉树不同的是,KD 树中的节点数始终等于点数,而与维数无关。这使得 KD 树成为许多分析库和机器学习框架中索引多维点的默认选择。
构建平衡树需要 O(n log n) 的时间复杂度,而插入、删除和点移动通常也需要 O(log n)。与其他索引结构一样,建议避免频繁重建树,并在批量插入数据时使用缓冲机制,以实现最佳性能。
地理哈希
GeoHash 与我们之前讨论过的基于树的空间索引(例如四叉树和 KD 树)截然不同。这些结构通过将空间划分为嵌套区域或按坐标值拆分来组织点,而 GeoHash 采用了更直接的方法:它将地理坐标(纬度和经度)转换为简单、紧凑的字符串。
图3:GeoHash 编码的精度级别
它的工作原理如下。想象一下地球表面是一个大网格。GeoHash 不断将这个网格划分成越来越小的矩形,并将每个细分区域编码成比特位。这些来自纬度和经度的比特位随后被交织,并使用一组特殊的字母和数字转换为一个短字符串。字符串越长,它所代表的区域就越小。例如,像"u4pruyd"这样的 GeoHash 可能精确定位到城市中的一个小街区,而"u4pr"则指向一个更大的区域。
GeoHash 的特别之处在于,地理位置相近的点通常在其哈希值中共享相同的起始字符。因此,如果您想查找某个点附近的所有位置,可以通过匹配其 GeoHash 的前缀来快速筛选。这在使用数据库或键值存储时非常有用,因为您可以运行快速的前缀搜索,而无需复杂的树形遍历。
举个具体的例子,假设您有一个外卖应用,想要查找距离客户几公里内的所有司机。使用 GeoHash,您可以同时对司机和客户的位置进行编码。如果司机的 GeoHash 开头的字符与客户的 GeoHash 开头的字符相同,那么他们很可能就在附近,因此您只需检查这个较小的群体,而无需检查系统中的所有司机。
然而,由于 GeoHash 将空间划分为矩形,因此它并不适用于精确的圆形或基于半径的搜索。通过 GeoHash 前缀缩小候选范围后,通常需要进行更精确的距离计算来筛选结果。
需要注意的一个限制是 GeoHash 仅适用于两个维度------纬度和经度。这对于基于地球的位置非常有用,但如果需要在高维空间(例如 3D 模型或时间序列数据)中索引点,则不太合适。
R树
R 树是另一种流行的空间数据组织方式,但它的工作原理与 KD 树等树结构以及 GeoHash 等编码方法截然不同。R 树可以理解为一种将邻近对象分组到嵌套矩形中的方法,这样就更容易找到彼此相邻的对象,而无需逐个检查每个点。

图 4:KD 树点的空间布局(左)和由此产生的树结构(右)
其基本思想如下:R 树不直接存储单个点,而是存储边界框------包含一个或多个空间对象的矩形。这些矩形被组织成树形结构,每个节点覆盖特定区域,子节点代表该区域内更小的矩形。当您想要搜索某个位置附近的对象时,您会从根节点开始,只探索那些可能与搜索区域重叠的矩形,忽略那些肯定不包含相关点的大片空间。
例如,假设有一个地图应用,显示公园、餐厅和商店。每个公园或餐厅都用一个矩形表示,该矩形涵盖了其位置和大小。R 树将这些矩形分组为更大的矩形------例如,将一个街区内的所有公园分组,然后将街区分组为区域,依此类推。当用户搜索附近地点时,R 树会快速缩小要检查的组别,即使有成千上万个对象,也能确保搜索效率。
R 树的强大之处在于,它可以处理各种大小和形状的对象,因为它处理的是边界矩形,而不仅仅是点。这种灵活性是 R 树或四叉树(通常索引点或大小均匀的单元)的一大优势。
在性能方面,R 树提供了良好的平均搜索时间,通常在 O(log n) 左右,其中 n 是对象的数量。它还支持高效的插入和删除操作,这对于位置可能频繁更改或添加的动态数据集非常有用。
然而,R 树面临的一个挑战是保持树的平衡并最小化边界框之间的重叠。过多的重叠会降低搜索速度,因为需要探索更多分支。为了解决这个问题,R 树的变体有很多,但其核心思想始终如一。
BSP 树
还记得 90 年代的经典游戏,比如《毁灭战士》和《雷神之锤》吗?它们依赖于一种叫做二叉空间分割树(BSP 树)的技术。BSP 树曾是计算机图形学和游戏开发中组织空间数据的首选解决方案,尽管如今它们大多已被取代。与其他将空间划分成整齐网格或盒子的空间结构不同,BSP 树采用了不同的方法------它们使用可以朝向任意方向的平面来划分空间。
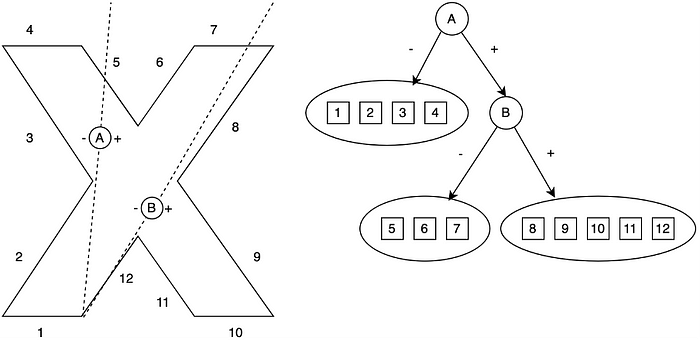
图 5:BSP 树示例,显示点图(左)及其树结构(右)
这个过程从你的整个空间(你的游戏世界)开始,然后创建一个贯穿它的分割平面。一侧的所有内容都进入左分支,另一侧的所有内容都进入右分支。你继续递归地进行这些划分,创建越来越小的区域。真正的优势在于,你可以将这些分割平面放置在任何适合你特定场景的位置------无需遵循严格的网格模式。
BSP 树在 90 年代那些开创性的游戏中达到了鼎盛时期,帮助在以今天的标准来看功能极其有限的计算机上创建 3D 世界!当玩家在《毁灭战士》中环顾四周时,游戏会使用其 BSP 树快速确定哪些墙壁可见、哪些不可见,而无需浪费宝贵的计算能力检查关卡中的所有内容。
这些用途广泛的树状图能够以令人印象深刻的精度描绘复杂的环境。但是------这也是它们在很大程度上被取代的原因------它们也有一些明显的缺点。随着世界规模的扩大,构建 BSP 树会变得越来越复杂。而且,如果你想动态地移动对象(这在现代游戏中至关重要),更新树状图会变得极其困难。
在过去,BSP 树至关重要,因为它们在处理能力极其有限的情况下,能够帮助游戏流畅运行。它们能够有效地消除玩家无法看到的场景部分,从而在当时的硬件条件下实现实时游戏。
优步 H3
H3 是当今领先的地理空间索引系统之一,由 Uber 于 2018 年开发,现已被业界广泛采用。与我们之前讨论过的过时的 BSP 树不同,H3 专为满足现代基于位置的服务和大数据应用的需求而设计。
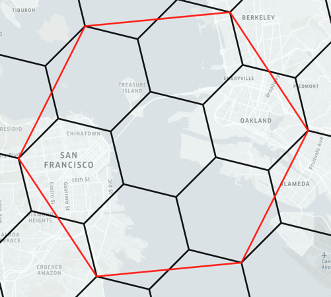
图 6:H3 索引系统中的分层六边形
H3 将地球表面划分为具有多种分辨率的六边形单元。该六边形网格系统最初由 122 个覆盖地球的基单元组成,每个单元可进一步细分为七个更小的六边形,从而形成一个逐级递增的层级结构。在最精细的分辨率(15 级)下,H3 单元的直径仅为几厘米。
该系统在 Uber 开源后迅速流行起来,这并非偶然。六边形网格方法比传统的方形网格具有显著优势。六边形具有均匀邻接性------每个单元格恰好有六个相邻单元格,且相邻单元格的距离相同------这使得移动和接近度的计算更加准确和一致。这一特性对于拼车、配送服务以及类似的距离计算直接影响用户体验的应用尤其有用。
H3 解决了困扰旧版空间索引系统的诸多局限性。其层级结构使其在空间连接和聚合等操作中极其高效。当您需要分析不同尺度的数据时(例如,分别考察社区和城市层面的乘车需求模式),H3 能够让这一过程变得异常简单。统一的单元大小也消除了许多其他全局网格系统所面临的失真问题。
H3 生态系统现在包括多种编程语言的实现、可视化工具以及与流行地理空间库的集成。
谷歌S2
S2 代表了另一种先进的地理空间索引方法,目前已广泛应用于生产系统。S2 由 Google 于 2011 年左右开发,随后开源。它采用了与 H3 截然不同的方法,同时解决了空间索引中许多相同的核心问题。

图 7:地球覆盖着来自其边界框的投影希尔伯特曲线
与 H3 的六边形平铺不同,S2 采用基于球体立方体投影的分层四叉树结构。该实现将地球映射到立方体的六个面上,然后每个面递归细分为四个单元,从而创建多分辨率网格。这些单元使用希尔伯特曲线索引进行寻址,该索引能够出色地保留局部性------物理空间中距离较近的点往往具有相似的单元 ID。
S2 在计算几何运算方面表现出色,而许多其他地理空间系统却难以应对。它不仅仅是一个索引系统,更是一个处理复杂多边形运算、覆盖和空间关系的几何库。该库包含用于点与多边形的测试、多边形的并集、交集和差集的算法------所有这些运算在球面上都难以正确实现。
性能是 S2 真正闪耀的地方。谷歌地图、谷歌地球以及众多其他谷歌服务都依赖 S2 进行地理空间操作,每天处理数十亿次查询。
S2 的一个关键技术优势在于其对投影畸变的处理。通过使用立方体投影而非单一平面投影,S2 最大限度地减少了困扰许多其他全球索引系统(尤其是在极地附近)的畸变问题。这使得 S2 特别适合需要全球一致空间精度的应用。
与其他选项相比,S2 肯定需要更多时间来掌握,但其强大的功能使其成为您需要处理复杂空间操作时的首选。
牛疱疹病毒
边界体积层次结构 (BVH) 是一种在现代计算机图形学中广泛使用的空间数据结构,尤其适用于实时渲染、光线追踪和物理模拟。它反映了当代的需求------高效处理复杂、动态的 3D 环境------这与 BSP 树等旧方法不同,后者是在静态几何和软件光栅化盛行的时代开发的。
图 8:BVH 树------点分布(左)和由此产生的层次结构(右)
BVH 背后的原理很简单:它不是对空间本身进行划分,而是通过将邻近的对象分组到边界体积(通常是轴对齐边界框 (AABB))中来组织对象,并构建一个二叉树,其中每个节点都封装了其子节点的边界。在查询树时(例如,投射射线或检查碰撞),如果节点处的边界框与查询不相交,则可以完全跳过场景的大部分内容。这可以显著提升性能,尤其是在几何测试成本高昂的应用中。
BVH 的优势之一是其适应性。八叉树无论物体的分布或大小如何,都会将空间均匀地划分为八个立方体,而 BVH 结构则与场景的实际排列相符。当数据均匀分布时(例如基于体素的表示或体积模拟),八叉树可能非常有效;但在包含稀疏、聚集或动态对象的场景中,它们往往会浪费内存和处理能力来细分空白区域。此外,在八叉树中处理移动物体非常繁琐,因为任何位置的变化都可能需要在树结构中重新分配该物体。
BVH 能够更加优雅地处理动态内容。由于其结构以对象为中心,因此可以以极低的开销进行重建或增量更新,甚至可以实时进行。边界框重新拟合和表面积启发式等技术使 BVH 树能够随着场景的演变而高效地适应------这在现代游戏引擎和实时光线追踪器中变得越来越重要。
将 BVH 与 R 树进行比较,差异在于预期用例和遍历效率。R 树也使用边界体积对空间对象进行分组,但它们针对 GIS 系统中的数据库式查询以及二维或三维空间中的空间索引进行了优化。R 树是多路树,旨在在插入和删除操作中保持平衡,优先考虑通用空间查询而不是遍历速度。然而,由于 R 树中的边界体积通常存在较大重叠,遍历它们可能需要检查多个分支,这可能会导致实时应用程序中的性能瓶颈。
相比之下,BVH 树通常是二叉树,其构造旨在最小化重叠和表面积,从而使树更浅,遍历速度更快。这使得它们特别适合射线几何相交测试,因为在这种测试中,每次不必要的边界框遍历都意味着计算的浪费。
哈希网格
哈希网格是一种简单但功能强大的空间索引技术,常用于粒子系统、流体模拟和邻近查询等实时应用。与 BVH、八叉树或 R 树等依赖于层级细分的树状结构不同,哈希网格将空间扁平化为均匀的网格,并使用哈希算法高效地存储和检索空间数据。这使得它们在某些任务中速度极快,尤其是在性能和简洁性比精确的空间组织更重要的情况下。
图 9:哈希网格中点的空间分布
这个概念很容易理解。空间被划分为规则的二维或三维网格单元。每个对象根据其位置映射到一个单元------本质上是将其坐标除以网格分辨率并四舍五入到最接近的整数。这些单元坐标并非存储在内存中(这对于稀疏或无限空间来说不切实际),而是通过哈希函数传递,该函数将它们映射到哈希表中的某个槽位。落入同一个单元(或哈希槽位)的对象将一起存储在一个列表中。
当进行查询时(例如查找某个点附近的所有对象),您只需计算该点属于哪个单元格,并检查该单元格及其相邻单元格即可。由于对象在本地分组,因此大多数查询只需进行少量查找和比较。插入和查找的平均时间复杂度为 O(1),这在性能关键型场景中是一个显著优势。
与 BVH 相比,哈希网格更加简单轻量。它没有层级结构,没有递归拆分,也无需维护边界框。这使得它们非常适合对象不断被添加、移除或移动的动态环境,例如基于粒子的模拟或实时人群系统。然而,这种简单性也伴随着一些弊端。
与 BVH 或 R 树不同,哈希网格不太适用于对象大小或密度变化较大的场景。固定的网格分辨率意味着非常大的对象可能跨越多个单元,而非常小的对象可能全部聚集在同一个单元中,这会降低性能。此外,由于哈希函数可能会产生冲突(多个单元映射到同一个槽位),因此需要仔细设计和调整,以避免在大型数据集中出现性能陷阱。
与八叉树(以递归方式细分空间并根据场景深度进行自适应)相比,哈希网格采用平面结构。它们不根据数据进行自适应------而是要求开发者提前选择合适的单元大小。在均匀的场景中(例如液体模拟或均匀分布的粒子),这种方法效果很好。在不均匀或聚类的数据中,分辨率选择不当可能会导致过多的空单元或存储桶过载。
尽管哈希网格存在局限性,但它仍然是许多实时系统的首选------主要是因为它们快速且易于实现。当您处理分布均匀且不断变化的数据,并且能够接受固定分辨率时,哈希网格通常能够在速度和简便性之间找到最佳平衡点。事实上,在合适的环境下,它们的性能甚至可以超越 BVH 或 R 树等更复杂的结构。这提醒我们,有时最简单的方法才是最有效的。
关键要点
选择正确的地理空间索引方法取决于您的特定需求------无论是查询速度、易于实现还是处理地球曲率。为了帮助您做出决定,我在下表中比较了九种关键的空间索引结构: