1.把数组分成一前一后的两个列表:分别是 化学家们 和 其余的人
bash
const people = [
{
id: 0,
name: '凯瑟琳·约翰逊',
profession: '数学家',
accomplishment: '太空飞行相关数值的核算',
imageId: 'MK3eW3A',
},
{
id: 1,
name: '马里奥·莫利纳',
profession: '化学家',
accomplishment: '北极臭氧空洞的发现',
imageId: 'mynHUSa',
},
{
id: 2,
name: '穆罕默德·阿卜杜勒·萨拉姆',
profession: '物理学家',
accomplishment: '关于基本粒子间弱相互作用和电磁相互作用的统一理论',
imageId: 'bE7W1ji',
},
{
id: 3,
name: '珀西·莱温·朱利亚',
profession: '化学家',
accomplishment: '开创性的可的松药物、类固醇和避孕药',
imageId: 'IOjWm71',
},
{
id: 4,
name: '苏布拉马尼扬·钱德拉塞卡',
profession: '天体物理学家',
accomplishment: '白矮星质量计算',
imageId: 'lrWQx8l',
},
];运行结果:

方法一:
javascript
const TableList = () => {
const isObjList = people.filter(item => {
return (item.profession === '化学家')
})
const noObjList = people.filter(item => {
return (item.profession !== '化学家')
})
const isEle = isObjList.map(item=>{
return <li key={item.id}>{item.name}:{item.profession}</li>
})
const noEle = noObjList.map(item=>{
return <li key={item.id}>{item.name}:{item.profession}</li>
})
return (
<>
<ul>{isEle}</ul>
<hr/>
<ul>{noEle}</ul>
</>
)
}优化方法一:
ini
const TableList = () => {
// 分离化学家与非化学家
const [chemists, nonChemists] = people.reduce(
([chemists, nonChemists], person) => {
return person.profession === '化学家'
? [[...chemists, person], nonChemists]
: [chemists, [...nonChemists, person]];
},
[[], []]
);
// 渲染人员列表的函数
const renderPersonList = (persons) => (
<ul>
{persons.map(person => (
<li key={person.id}>{person.name}: {person.profession}</li>
))}
</ul>
);
return (
<>
{renderPersonList(chemists)}
<hr/>
{renderPersonList(nonChemists)}
</>
);
};优化点解释:
- 简化了数组定义,去掉了多余的换行
- 使用 reduce 一次性分离化学家与非化学家,替代两次 filter
- 创建了 renderPersonList 函数来复用列表渲染逻辑
- 保持了原有的组件结构和导出方式
- 代码更简洁、可读性更高
这样的优化使代码更简洁,减少了重复逻辑,同时保持了原有的功能。
代码解释
这段代码使用 reduce 方法将 people 数组按职业是否为化学家分为两个数组:
jsx:/e:\MEditCodeSpace\edit-code-space\zeroReactApp\src\TableList.jsx
// 从people数组中分离出化学家和非化学家
const [chemists, nonChemists] = people.reduce(
// 回调函数:处理每个元素并更新累加器
([chemists, nonChemists], person) => {
// 条件判断(注:此处有重复判断,应为笔误)
return person.profession === '化学家'
? [[...chemists, person], nonChemists] // 是化学家则添加到chemists数组
: [chemists, [...nonChemists, person]]; // 否则添加到nonChemists数组
},
[[], []] // 初始值:包含两个空数组的元组
);reduce 方法详解
Array.prototype.reduce 是数组的高阶函数,用于将数组归并为单个值(或复杂结构),语法如下:
javascript
array.reduce(callback(accumulator, currentValue, currentIndex, array)[, initialValue])核心参数
-
回调函数: 其中callback回调函数用于处理每个数组元素,最后返回一个累加值。
accumulator:累加器,保存上一次回调的返回值(或提供的初始值)currentValue:当前正在处理的数组元素currentIndex(可选):当前元素的索引。array(可选):调用 reduce 的数组。
-
initialValue:
- 累加器的初始值
- 若不提供,则使用数组第一个元素作为初始值,从第二个元素开始遍历
工作流程
- 初始化累加器(使用
initialValue或数组第一个元素) - 遍历数组,对每个元素执行回调函数
- 将回调返回值作为新的累加器值
- 遍历结束后返回最终累加器值
使用技巧
array.reduce()是用于将数组元素归纳(或"缩减")为单个值的函数 (这个值可以是数字、对象、数组、字符串......都可以)。
应用场景:数据汇总、条件筛选和映射、对象属性的扁平化、转换数据格式、聚合统计、处理树结构数据、性能优化等。
| 使用场景 | 示例 | 是否使用reduce |
|---|---|---|
| 求和 | 数组求和 | ✅ 非常合适 |
| 统计 | 单词出现次数统计 | ✅ 高效 |
| 结构变换 | 数组转对象、转 Map | ✅ 优雅 |
| 嵌套结构处理 | 二维数组扁平化、树结构构建 | ✅ 函数式利器 |
| 简单遍历 | 单纯执行函数(无返回值) | ❌ 用 forEach 更合适 |
| 多条件过滤 | 保留某些元素 | ❌ 用 filter 更直接 |
实际应用场景
1. 数据汇总
在处理数据集时,经常需要对数据进行汇总,比如求和、求平均值、求最大/最小值等。
javascript
// 在处理数据集时,经常需要对数据进行汇总,比如求和、求平均值、求最大/最小值等。
const numbers = [1, 2, 3, 4, 5];
const total = numbers.reduce((acc, val) => acc + val, 0); // 求和/统计
const average = numbers.reduce((acc, val) => acc + val, 0) / numbers.length; // 求平均值
const maxNum = numbers.reduce((acc,cur)=> acc > cur ? acc : cur) //求最大值
const minNum = numbers.reduce((acc,cur)=> acc < cur ? acc : cur) //求最小值2. 条件筛选和映射
array.reduce()是可以结合条件判断,用于创建一个新数组,其中只包含满足特定条件的元素。
ini
// reduce() 可以结合条件判断,用于创建一个新数组,其中只包含满足特定条件的元素。
const users = [
{ name: 'Alice', age: 21 },
{ name: 'Bob', age: 25 },
{ name: 'Charlie', age: 20 }
];
const adults = users.reduce((acc, user) => {
if (user.age >= 18) acc.push(user);
return acc;
}, []);3. 对象属性的扁平化
ini
// 将嵌套的对象结构扁平化,便于后续处理。
const data = {
a: { x: 5, y: 6 },
b: { x: 7, y: 8 }
};
// 方案1、使用reduce嵌套forEach
const flattenedData = Object.keys(data).reduce((acc, key) => {
Object.keys(data[key]).forEach((subKey) => {
acc[key + "." + subKey] = data[key][subKey];
});
return acc;
}, {});
// 方案2、使用双层reduce嵌套,为了规避双层对象嵌套,将内层的累加起始值设置为外层累加器
// 就能实现内层键值对均累加到外层累加器中,实现双层reduce嵌套结果为单层对象的效果
const flattenedData = Object.keys(data).reduce((acc, key) => {
return Object.keys(data[key]).reduce((a, k) => {
a[key + "." + k] = data[key][k];
return a;
}, acc);
}, {});
/**
* flattenedData ={
* 'a.x': 5,
* 'a.y': 6,
* 'b.x': 7,
* 'b.y': 8
* }
//4. 聚合统计
在处理日志数据或其他需要聚合统计的场景中,array.reduce()可以用于计算不同分类下的统计数据。
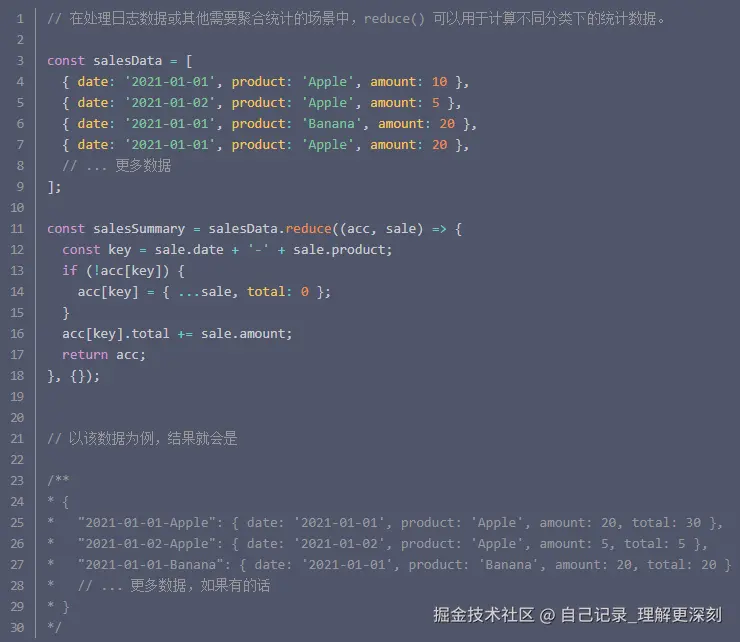
5. 处理树结构数据
在处理树状结构的数据时,array.reduce() 可以用来递归地构建一个树形结构。
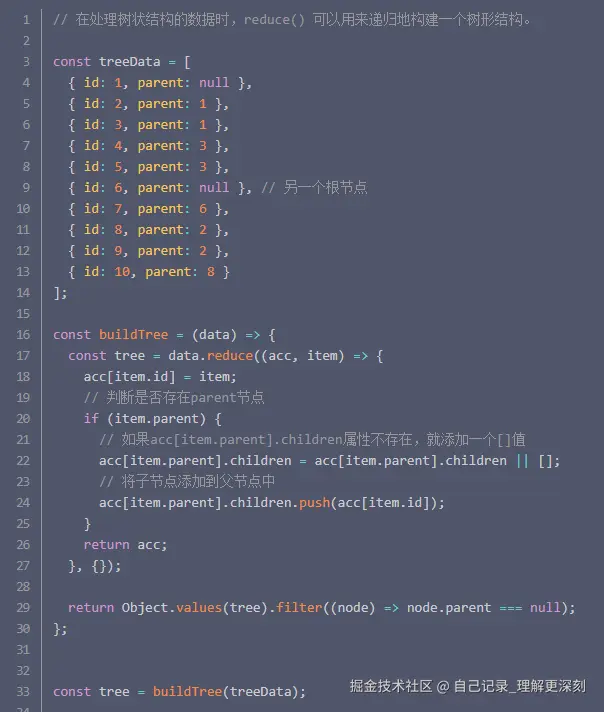

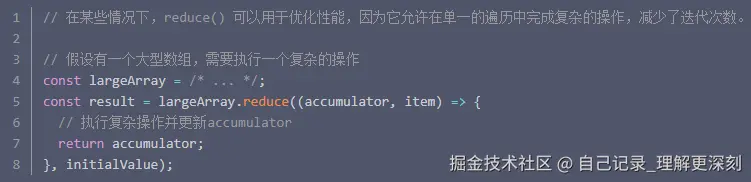
6. 性能优化
在某些情况下,array.reduce()可以用于优化性能,因为它允许在单一的遍历中完成复杂的操作,减少了迭代次数。
7. 数据分组(如当前代码)
javascript
const [groupA, groupB] = data.reduce(([a, b], item) => {
return item.condition ? [...a, item] : [...b, item];
}, [[], []]);8. 对象属性累加
javascript
const totalAge = people.reduce((acc, person) => acc + person.age, 0);9. 数组扁平化
javascript
const flat = [[1, 2], [3, 4]].reduce((acc, curr) => [...acc, ...curr], []);关键注意点
-
初始值的重要性:
- 不提供初始值时,若数组为空会报错
- 推荐始终提供初始值以确保代码健壮性
-
引用类型处理:
- 累加器若为对象/数组,需注意浅拷贝问题
- 示例中使用
[...chemists, person]创建新数组避免原数组被修改
-
与其他方法对比:
-
reduce灵活性极高,但可读性不如filter+map组合 -
简单分组场景可简化为:
javascriptconst chemists = people.filter(p => p.profession === '化学家'); const nonChemists = people.filter(p => p.profession !== '化学家');
-