LangChain 是一个用于开发基于大语言模型(LLM)应用程序的开源框架,它通过提供模块化的抽象组件和链式调用工具,将 LLM 与外部数据源(如文档、数据库)和计算工具(如搜索引擎、代码解释器)智能连接,从而构建出具备记忆、推理和行动能力的增强型 AI 应用,典型场景包括智能问答、内容生成和智能体(Agent)系统。
LangChain官方文档:docs.langchain.com/。网址的组成逻辑和Ne...
LangChain支持Python和TypeScript两种编程语言,如图11-1所示。
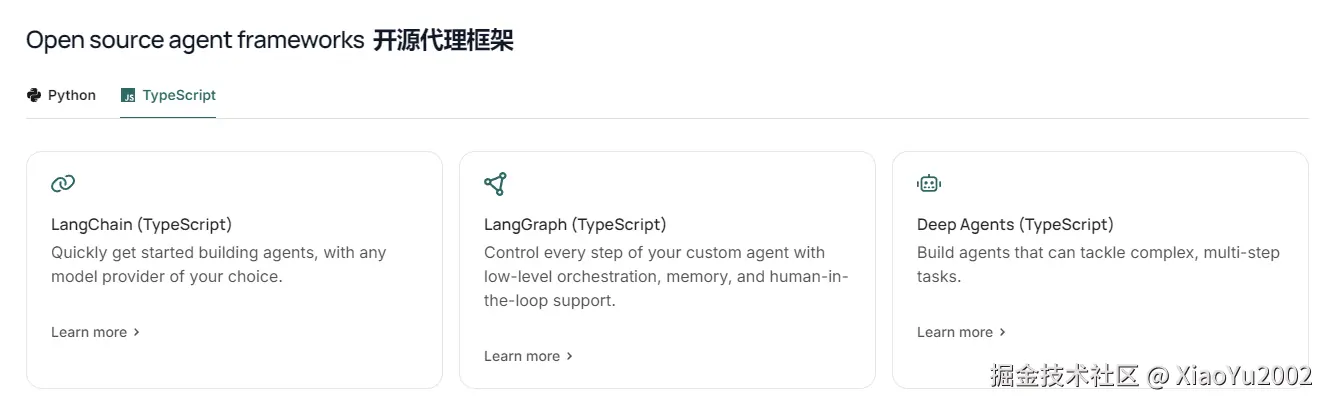
图11-1 LangChain开源代理框架-语言选项
LangChain开源代理框架有3种选择方案:
(1)LangChain:一些普通对话,音频识别、文字生成,图片生成等等与AIGC相关的,用这选择方案就够了。
(2)LangGraph:想做工作流,类似Dify,Coze,那么就需要使用该方案。
(3)Deep Agents:想做一些大型的AI相关高级应用,就需要使用该方案,Deep Agents是深度集成的意思。
LangChain 作为基础框架,适合构建常规的AIGC应用(如对话、文生图);LangGraph 专注于通过有状态、可循环的图结构来编排复杂、多步骤的智能体工作流,是开发类Dify/Coze平台或自动化业务流程的核心选择;而 Deep Agents 则代表了一种更深度集成、能处理高复杂度任务与自主决策的高级智能体架构,常用于需要多智能体协作或模拟人类工作流的大型企业级AI应用。
我们这里学习的话,使用第一个LangChain就完全够用。LangChain下载使用说明如图11-2所示。我们点击如图11-1所示的第一个选项后,会跳转到如图11-2所示的界面,需要点击左侧边栏的install选项。官方文档有对应的使用说明。
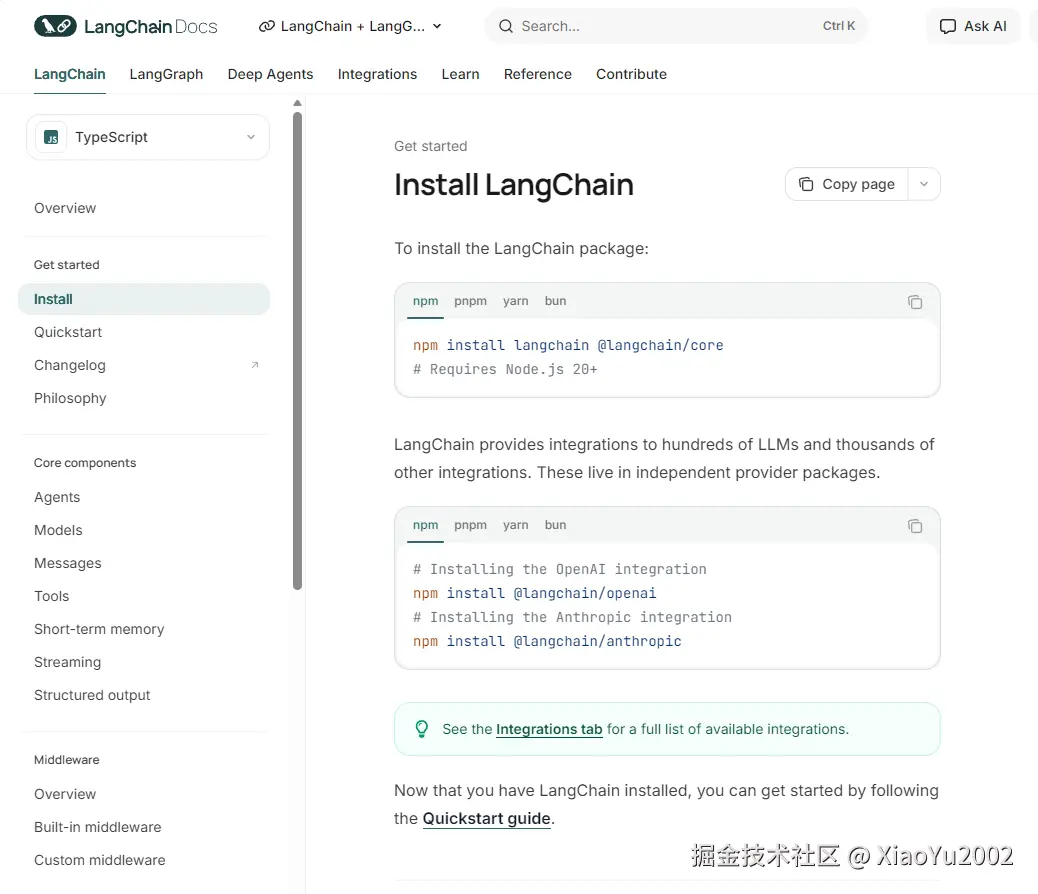
图11-2 LangChain下载使用说明
11.1 初始化项目
接下来,我们要开始初始化这次的项目。会沿用第10章 SSE魔改的代码,在该基础上,需要补充以下安装步骤:
(1)@langchain/core:LangChain 的核心基础库,包含链、提示模板、检索器等核心抽象。
(2)@langchain/deepseek: LangChain 为DeepSeek 模型专门提供的集成包,让我们能在 LangChain 框架中直接调用 DeepSeek 的 API。安装规则是@langchain/所需AI大模型,例如@langchain/openai。
(3)langchain:LangChain 的主包,提供了高级、易于使用的接口来组合和使用 LLM。
安装LangChain之后,我们需要一个AI大模型来支持,在这次示例中,选择DeepSeek,因为它的API非常便宜。
ts
// 终端执行命令
npm install @langchain/core @langchain/deepseek langchain安装之后的package.json文件如下所示。
ts
{
"type": "module",
"dependencies": {
"@langchain/core": "^1.1.6",
"@langchain/deepseek": "^1.0.3",
"@types/cors": "^2.8.19",
"@types/express": "^5.0.6",
"cors": "^2.8.5",
"express": "^5.2.1",
"langchain": "^1.2.1"
}
}由于我们在7.1小节已经升级过Node.js版本,因此可以直接用Node.js去运行ts后缀文件,满足Node.js版本大于23的都可以这么做,如果无法运行ts后缀文件,需要检查一下Node.js版本或者采用ts-node。
接下来到index.ts文件中初始化后端服务。
ts
// index.ts
import express from 'express'
import cors from 'cors'
const app = express()
app.use(cors())
app.use(express.json())
app.post('/api/chat', async (req, res) => { })
app.listen(3000, () => {
console.log('Server is running on port 3000')
})11.2 接入大模型
接着接入我们的AI大模型DeepSeek,还是在index.ts文件中。
在这里引入了一个key.ts文件,该文件存放着DeepSeek API的Key。
ts
import { ChatDeepSeek } from '@langchain/deepseek'
import { key } from './key.ts'
const deepseek = new ChatDeepSeek({
apiKey: key,
model: 'deepseek-chat',
temperature: 1.3,
maxTokens: 1000, //500-600个汉字
topP: 1, //设得越小,AI 说话越"死板";设得越大,AI 说话越"放飞自我"
frequencyPenalty: 0,//防复读机诉 AI:"你别老重复同一个词!"-2 2
presencePenalty: 0,//鼓励换话题告诉 AI:"别老聊同一件事!" -2 2
})获取DeepSeek的key,如下4步骤:
(1)打开DeepSeek的API开放平台:platform.deepseek.com/。
(2)微信扫码登录,去实名认证。
(3)点击左侧边栏的用量信息选择去充值选项,有在线充值和对公汇款两个选项,选择在线充值,自定义输入1块钱(够用了),然后自己选择支付宝或者微信支付去付款。
(4)付款成功后,点击左侧边栏的API keys选项,创建API key,随便输入一个名称(中英文都可以),然后会弹出key值,此时复制key值再关闭弹窗,因为当你关闭后,就再也拿不到这个key值了。忘记就只能重新再建一个,DeepSeek会提醒你的,如图11-3所示。
友情提示:保护好你的key值,别暴露在公网中,在开源项目上传GitHub中,可以让git忽略key.ts文件。或者如果你的DeepSeek API就只充了1块钱,然后用得剩几毛钱,并且以后都不怎么打算充,那想不想保护key值,就看你心情了。

图11-3 创建API key注意事项
通过以上步骤获取到DeepSeek的key值后,在项目创建key.ts文件,创建常量key,填入你的key值并导出。
ts
export const key = '你DeepSeek的key值'回到index.ts文件,接入DeepSeek大模型之后,ChatDeepSeek有一个model字段,这是用于选择我们模型的。已有的模型类型需要从DeepSeek官方文档中获取:模型 & 价格 | DeepSeek API Docs。
ts
// DeepSeek字段
apiKey: key,
model: 'deepseek-chat',
temperature: 1.3,
maxTokens: 1000, // 500-600个汉字
topP: 1, // 设得越小,AI 说话越"死板";设得越大,AI 说话越"放飞自我"
frequencyPenalty: 0,// 防复读机诉 AI:"你别老重复同一个词!"-2 2
presencePenalty: 0,// 鼓励换话题告诉 AI:"别老聊同一件事!" -2 2目前可选的模型有deepseek-chat和deepseek-reasoner。DeepSeek官网价格计算是以百万Token为单位,其中1 个英文字符 ≈ 0.3 个 token;1 个中文字符 ≈ 0.6 个 token。只要大概知道很便宜就足够了。

图11-4 DeepSeek模型选择
temperature字段是温度的含义,在DeepSeek官方文档中有直接给出对应的建议,我们的示例是打算用于对话,因此设置1.3就足够了,Temperature参数设置如图11-5所示。
从应用场景,我们可以理解为temperature字段大概是理性与感性的权衡度,逻辑性越强的场景,温度越低;越感性的场景温度越高。所有AI大模型都是类似的,从他们对应的官方文档去获取对应信息就可以了。
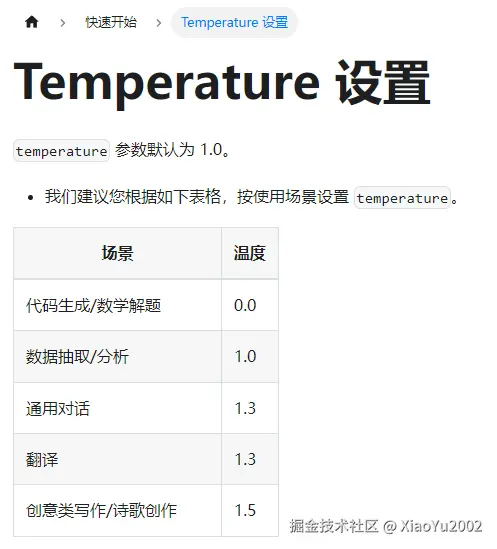
图11-5 DeepSeek模型-Temperature参数设置
其余4个参数maxTokens、topP,frequencyPenalty和presencePenalty如下:
(1)maxTokens 直接决定了 AI 回复的最大长度,限制了单次响应的文本量;
(2)topP(核采样参数)通过控制候选词的概率分布来影响文本的创造性与稳定性------值越低则 AI 的选词越集中和可预测,输出趋于"死板",值越高则选词范围越宽,输出越"放飞自我"并富有创意。
(3)而 frequencyPenalty 与 presencePenalty 则分别从词频和话题层面抑制重复:frequencyPenalty 正值会惩罚在当前回复中已经频繁出现的词语,促使用词更加多样;presencePenalty 正值则会惩罚在已生成的上下文中出现过的所有主题,鼓励 AI 主动切换到新的话题或角度,从而共同确保生成内容的多样性和连贯性,避免陷入单调或循环重复的表达。
这些值具体设置多少,则需要根据具体场景的经验以及自身的理解,推荐看我写的AI使用手册,开头有讲解到这一部分注意力机制:AI精准提问手册:从模糊需求到精准输出的核心技能(上)。
11.3 AI对话
接下来需要从langchain引入createAgent方法,并使用我们设置好的deepseek实例对象。我们调用agent身上的invoke()方法,该方法更适合单次输出(一次性直接返回),即非流式返回。
通过createAgent方法除了可以设置接入的大模型,还可以通过systemPrompt字段去设置Prompt提示词。
通过LangChain代理的stream()方法调用DeepSeek模型处理用户请求:将客户端发送的req.body.message作为用户消息输入,并设置streamMode为 "messages" 来获取结构化的消息流响应;在等待代理完成流式生成后,将整个结果集作为JSON数据一次性返回给客户端。
ts
import express from 'express'
import cors from 'cors'
import { ChatDeepSeek } from '@langchain/deepseek'
import { key } from './key.ts'
import { createAgent } from 'langchain'
const deepseek = new ChatDeepSeek({
apiKey: key,
model: 'deepseek-chat',
temperature: 1.3,
maxTokens: 1000, // 500-600个汉字
topP: 1, // 设得越小,AI 说话越"死板";设得越大,AI 说话越"放飞自我"
frequencyPenalty: 0, // 防复读机诉 AI:"你别老重复同一个词!"-2 2
presencePenalty: 0, // 鼓励换话题告诉 AI:"别老聊同一件事!" -2 2
})
const app = express()
app.use(cors())
app.use(express.json())
app.post('/api/chat', async (req, res) => {
res.setHeader('Content-Type', 'application/json')
res.setHeader('Cache-Control', 'no-cache')
res.setHeader('Connection', 'keep-alive')
const agent = createAgent({
model: deepseek,
systemPrompt: `你是一个聊天机器人,请根据用户的问题给出回答。`,
})
const result = await agent.invoke({
messages: [
{
role: 'user',
content: req.body.message,
}
]
})
res.json(result)
})
app.listen(3000, () => {
console.log('Server is running on port 3000')
})接下来回到index.html文件一下,我们需要设置客户端返回给后端的问题,也就是往req.body.message里塞一下咨询AI的问题。
ts
<script>
fetch('http://localhost:3000/api/chat', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({ message: '请问你是什么AI大模型' })
}).then(async res=>{
const reader = res.body.getReader()
const decoder = new TextDecoder()
while (true) {
const { done, value } = await reader.read()
if (done) {
break
}
const text = decoder.decode(value, { stream: true })
console.log(text)
}
})
</script>我们问了一个:"你是什么AI大模型"的问题,浏览器返回AI对话信息如图11-6所示。
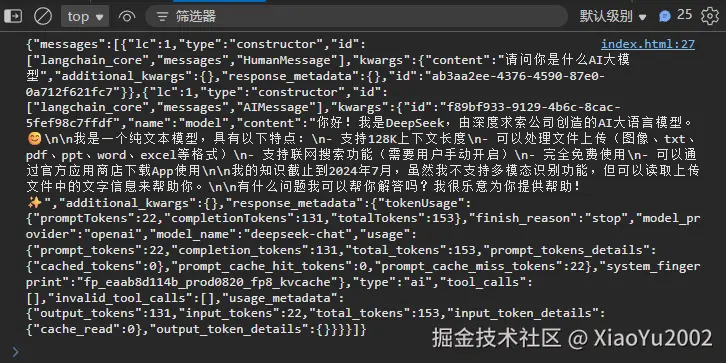
图11-6 DeepSeek模型-Temperature参数设置
到这为止,我们就正式打通了AI对话的环节。并且如果我们打开网络选项卡,可以发现AI对话返回的内容是post请求的。如果我们想改成流式输出也是post请求,在第10.3小节所学习的SSE设置post请求就可以用上了。
11.4 流式输出AI对话
如果我们想修改成流式输出对话的话,需要修改3个地方:
(1)后端设置的Content-Type类型改成事件流类型。
(2)agent不使用invoke()方法,该换专门的agent.stream()流输出方法,并调整对应参数。
(3)agent.stream()流输出方法返回迭代器,针对迭代器去调整输出形式。
ts
import express from 'express'
import cors from 'cors'
import { ChatDeepSeek } from '@langchain/deepseek'
import { key } from './key.ts'
import { createAgent } from 'langchain'
const deepseek = new ChatDeepSeek({
apiKey: key,
model: 'deepseek-chat',
temperature: 1.3,
maxTokens: 1000, // 500-600个汉字
topP: 1, // 设得越小,AI 说话越"死板";设得越大,AI 说话越"放飞自我"
frequencyPenalty: 0, // 防复读机诉 AI:"你别老重复同一个词!"-2 2
presencePenalty: 0, // 鼓励换话题告诉 AI:"别老聊同一件事!" -2 2
})
const app = express()
app.use(cors())
app.use(express.json())
app.post('/api/chat', async (req, res) => {
res.setHeader('Content-Type', 'application/event-stream')
res.setHeader('Cache-Control', 'no-cache')
res.setHeader('Connection', 'keep-alive')
const agent = createAgent({
model: deepseek,
systemPrompt: `你是一个聊天机器人,请根据用户的问题给出回答。`,
})
const result = await agent.stream({
messages: [
{
role: 'user',
content: req.body.message,
}
]
}, { streamMode: "messages" })
for await (const chunk of result) {
res.write(`data: ${JSON.stringify(chunk)}\n\n`)
}
res.end()
})
app.listen(3000, () => {
console.log('Server is running on port 3000')
})agent.stream()方法有第二个参数,用于指定流式输出的数据格式和粒度,决定了从流中接收到的是原始令牌、结构化消息还是其他中间结果。agent.stream()方法第二个参数的选项如表11-1所示。我们选择messages就可以了。如果想要真正存粹的打字效果并且节约token,可以使用values选项。
表11-1 agent.stream()方法第二个参数的选项
| 流模式 | 返回的数据类型 | 典型用途 | 示例输出(逐块) |
|---|---|---|---|
| "messages" | 完整的消息对象 | 需要处理结构化对话(如获取AI回复的完整消息) | {"role": "assistant", "content": "你好"} |
| "values" | 底层值(如原始token) | 需要实现逐字打印效果或最低级控制 | "你" "好" |
| "stream" | 混合事件流 | 需要同时获取token和消息等多样信息 | {"type": "token", "value": "你"} |
ts
const result = await agent.stream({
messages: [
{
role: 'user',
content: req.body.message,
}
]
}, { streamMode: "values" })其次,由于agent.stream()方法的返回值类型是IterableReadableStream<StreamMessageOutput>,说明返回值就是一个迭代器。因此可以使用for await of语法糖来流式输出内容,不用手动的去调用迭代器的next()方法。
ts
for await (const chunk of result) {
res.write(`data: ${JSON.stringify(chunk)}\n\n`)
}
res.end()AI对话-流式输出如图11-7所示。会按顺序返回非常多的JSON格式数据,通过data字段下的kwargs的content可以看到AI返回内容以三两字的形式不断输出。并且在前端的接收流式输出,不会因post请求而出现问题。
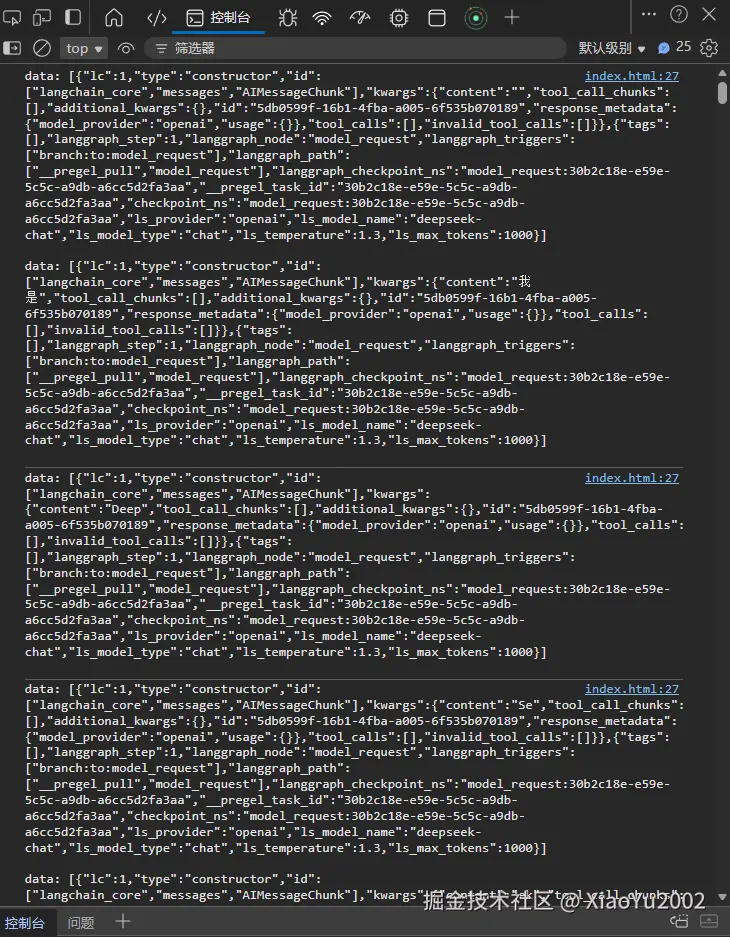
图11-7 AI对话-流式输出
流式输出AI对话的完整代码如下:
ts
// index.ts
import express from 'express'
import cors from 'cors'
import { ChatDeepSeek } from '@langchain/deepseek'
import { key } from './key.ts'
import { createAgent } from 'langchain'
const deepseek = new ChatDeepSeek({
apiKey: key,
model: 'deepseek-chat',
temperature: 1.3,
maxTokens: 1000, // 500-600个汉字
topP: 1, // 设得越小,AI 说话越"死板";设得越大,AI 说话越"放飞自我"
frequencyPenalty: 0, // 防复读机诉 AI:"你别老重复同一个词!"-2 2
presencePenalty: 0, // 鼓励换话题告诉 AI:"别老聊同一件事!" -2 2
})
const app = express()
app.use(cors())
app.use(express.json())
app.post('/api/chat', async (req, res) => {
res.setHeader('Content-Type', 'application/event-stream')
res.setHeader('Cache-Control', 'no-cache')
res.setHeader('Connection', 'keep-alive')
const agent = createAgent({
model: deepseek,
systemPrompt: `你是一个聊天机器人,请根据用户的问题给出回答。`,
})
const result = await agent.stream({
messages: [
{
role: 'user',
content: req.body.message,
}
]
}, { streamMode: "messages" })
for await (const chunk of result) {
res.write(`data: ${JSON.stringify(chunk)}\n\n`)
}
res.end()
})
app.listen(3000, () => {
console.log('Server is running on port 3000')
})
ts
// index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script>
fetch('http://localhost:3000/api/chat', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({ message: '请问你是什么AI大模型' })
}).then(async res => {
const reader = res.body.getReader()
const decoder = new TextDecoder()
while (true) {
const { done, value } = await reader.read()
if (done) {
break
}
const text = decoder.decode(value, { stream: true })
console.log(text)
}
})
</script>
</body>
</html>以上就是使用LangChain接入DeepSeek大模型并实现AI对话和基础提示词的案例。