Fs2(Functional streams for Scala,Scala 的函数式流库)绝对是我一直以来最喜欢的库。它最初以 scalaz-stream 的名字诞生,源自那本著名的《红皮书》(现在已经出到第二版),经过多年演化,发展到如今业界领先的状态。
在本章中,我们将通过实用示例和软件设计理念进行讲解,这些内容对于后续基于流的分布式系统开发至关重要。
5.1 有限状态机(Finite State Machines)
我们在 PFPS 里已经简单介绍过有限状态机(FSM)这个主题,但这里再回顾一下,因为后续交易系统会大量用到。引用维基百科的定义:
有限状态机(FSM,或有限自动机 FSA)是一种计算的数学模型。它是一台抽象机器,在任意时刻只能处于有限个状态中的一个。FSM 可以根据输入从一个状态切换到另一个状态,这个切换叫做"转移(transition)"。FSM 由状态集合、初始状态和触发每个转移的输入组成。FSM 分为确定型(DFA)和非确定型(NFA),任何 NFA 都可以构造出等价的 DFA。
我们将用如下的 Scala 3 表达方式:
typescript
import cats.syntax.all.*
import cats.{ Functor, Id }
case class FSM[F[_], S, I, O](run: (S, I) => F[(S, O)]):
def runS(using F: Functor[F]): (S, I) => F[S] =
(s, i) => run(s, i).map(_._1)
object FSM:
def id[S, I, O](run: (S, I) => Id[(S, O)]) = FSM(run)run 函数接受一个状态 S 和一个输入 I,在上下文 F 中返回新的状态 S 和输出 O。当不需要 effect 上下文时,可以用身份态 FSM(cats.Id)。
runS 是扩展方法,运行状态机但丢弃输出,只返回新状态。如果需要,也可以写个只返回输出、丢弃新状态的方法。
5.1.0.1 交易引擎 FSM 示例
下面是下一章我们会用到的代码片段,建模了一个交易引擎的有限状态机:
typescript
object TradeEngine:
val fsm =
FSM.id[
TradeState,
TradeCommand | SwitchCommand,
(EventId, Timestamp) => TradeEvent | SwitchEvent
] {
// 交易状态为 On
case (st @ TradeState(On, _), cmd @ Create(_, cid, sl, ac, p, q, _, _)) =>
val nst = st.modify(sl)(ac, p, q)
nst -> ((id, ts) => CommandExecuted(id, cid, cmd, ts))
case (st @ TradeState(On, _), cmd @ Update(_, cid, sl, ac, p, q, _, _)) =>
val nst = st.modify(sl)(ac, p, q)
nst -> ((id, ts) => CommandExecuted(id, cid, cmd, ts))
case (st @ TradeState(On, _), cmd @ Delete(_, cid, sl, ac, p, _, _)) =>
val nst = st.remove(sl)(ac, p)
nst -> ((id, ts) => CommandExecuted(id, cid, cmd, ts))
// 交易状态为 Off
case (st @ TradeState(Off, _), cmd: TradeCommand) =>
val rs = Reason("Trading is off")
st -> ((id, ts) => CommandRejected(id, cmd.cid, cmd, rs, ts))
// 切换 On / Off
case (st @ TradeState(Off, _), Start(_, cid, _)) =>
val nst = TradeState._Status.replace(On)(st)
nst -> ((id, ts) => Started(id, cid, ts))
case (st @ TradeState(On, _), Stop(_, cid, _)) =>
val nst = TradeState._Status.replace(Off)(st)
nst -> ((id, ts) => Stopped(id, cid, ts))
case (st @ TradeState(On, _), Start(_, cid, _)) =>
st -> ((id, ts) => Ignored(id, cid, ts))
case (st @ TradeState(Off, _), Stop(_, cid, _)) =>
st -> ((id, ts) => Ignored(id, cid, ts))
}先不深入数据类型细节(第 6 章会详细讲),这里可以看到如何通过 TradeState 处理命令并产生事件来建模状态转移。
我们之所以可以用身份 FSM(Id),是因为事件的 EventId 和 Timestamp 是在生成事件时"延后"生成的。如果希望输出就是 F[TradeEvent | SwitchEvent],那 effect F 就要有 Applicative、GenUUID 和 Time 能力,Id 就不够了。
FSM 本质是纯函数,非常易于测试。只需传入初始状态和输入(命令),再断言输出的状态和事件即可。例如:
scss
test("Trade engine fsm") {
val st1 = fsm.runS(TradeState.empty, createCmd)
val ex1 = TradeState(On, pricesMap)
expect.same(st1, ex1)
}这里只是简单举例,具体细节后面会有讲解。
5.1.0.2 流(Stream)集成
Fs2 提供了两个和 FSM 结构天然契合的方法:mapAccumulate 和 evalMapAccumulate。它们的简化类型签名如下:
less
def mapAccumulate[S, O](s: S)(f: (S, I) => (S, O)): Stream[F, (S, O)]
def evalMapAccumulate[S, O](s: S)(f: (S, I) => F[(S, O)]): Stream[F, (S, O)]结合交易 FSM,可以这样用:
arduino
val commands: Stream[IO, TradeCommand | SwitchCommand] = ???
commands.evalMapAccumulate(TradeState.empty)(fsm.run)比如 commands 可以来自 Pulsar topic 的消息流。
后面章节我们处理状态转移时,大部分代码都会采用类似结构。
如需查看更多 FSM 示例,可参考我以前写过的一篇博客。
5.2 资源与生命周期(Resources and lifecycle)
所有与 Cats Effect 集成的库都可以利用 Resource 数据类型(及其实例),它用于建模在任务完成或失败时需要执行清理动作的场景。
比如,HTTP 服务器或数据库连接通常都属于资源的典型例子,因为获取它们成本较高。有时也只是为了确保资源关闭前,最后一定要执行一段清理逻辑。
最常见的例子就是默认的 Http4s 服务器 Ember:
arduino
val mkServer: Resource[IO, Server] =
EmberServerBuilder
.default[IO]
.withHost(host"0.0.0.0")
.withPort(port"8080")
.build再比如创建 Redis 连接:
dart
Redis[IO].utf8("redis://localhost").use { redis =>
for
_ <- redis.set("foo", "123")
x <- redis.get("foo")
_ <- redis.setNx("foo", "should not happen")
y <- redis.get("foo")
_ <- IO(assert(x === y))
yield ()
}不过,这两类资源用法上是有区别的:
-
第一类(比如 HTTP 服务器)通常作为长期运行的任务,返回的 Server 实例其实不用关心,常见写法如下:
ini// 等同于 .use(_ => IO.never) mkServer.useForever -
第二类(比如 Redis 连接)通常要与多个业务组件共享,例如:
scssRedis[IO].utf8("redis://localhost").use { redis => serviceOne(redis) *> serviceTwo(redis) }
但它们也有共同点:一般都在应用的顶层初始化,先获取一系列资源,再用 IO 或 Stream 运行主程序。
Fs2 的 Stream 自带 resource 方法,可以与 Cats Effect 的 Resource 无缝对接,非常适合用来管理 Redis 连接。同样也可以用于 HTTP 服务器(但有一些语义上的细节要注意)。
scss
def run: IO[Unit] =
Stream
.resource(resources)
.flatMap { (serverRes, redisRes) =>
Stream.eval(serverRes.useForever).concurrently {
Stream.resource(redisRes).evalMap { redis =>
serviceOne(redis) *> serviceTwo(redis)
}
}
}
.compile
.drain在这个例子中,我们还是推荐用 useForever 并用 Stream.eval 提升到流中,这样写最简洁。当然也可以直接用 Stream.resource,但那样要加上 Stream.never 来实现等价语义:
scss
(Stream.resource(serverRes) >> Stream.never[IO])
.concurrently {
Stream.resource(redisRes).evalMap { redis =>
serviceOne(redis) *> serviceTwo(redis)
}
}在本书应用里,我们采用第一种 useForever 的方式,但你可以根据需要选择适合自己的风格。
5.3 数据管道(Data pipelines)
Fs2 是构建数据管道的强大工具。它可以很方便地连接各种数据源,比如文件、数据库,甚至消息中间件收到的消息。
不过,不同场景往往需要不同的处理方式。例如,用于实时数据处理的管道,和用于分析(analytics)或批处理(batch)的管道,设计思路是完全不一样的。
下图展示了一个混合型的数据管道结构。
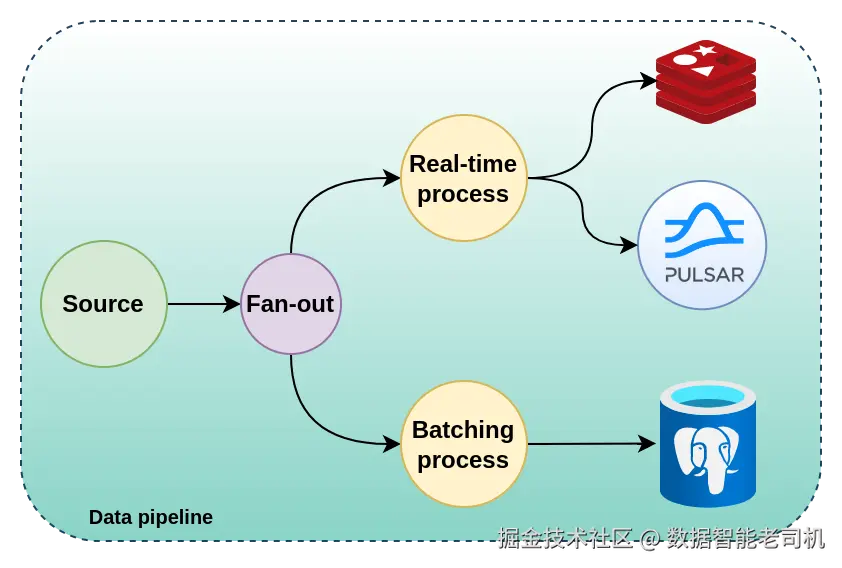
在本节中,我们将学习一些范例和设计思路,这些不仅适用于下一章我们要开发的系统,对你作为软件工程师的职业生涯、尤其是在系统设计领域同样大有裨益。
5.3.1 实时处理(Real-time)
专为实时处理设计的数据管道需要具备高吞吐。例如,接收足球比赛的相关事件(如 GoalScored、CornerKickAwarded),并实时反映到系统里,过程中可能包括一些计算、更新缓存、发布其他消息等。
如果每个事件都要落库,则会牺牲吞吐能力。因此,实时处理管道和分析/批处理管道需要严格区分,后面我们会举例说明。
实时管道分为需要保序和无需保序两类。需要保序时通常可用 evalMap 或 parEvalMap 实现:
scss
val events: Stream[IO, FootballEvent] = ???
events.parEvalMap(maxConcurrent = 10) {
process(_).flatMap { e =>
sendMessage(e) &> updateCache(e)
}
}一般来说,当数据源量大时,parEvalMap 性能更佳;数据量不大时和 evalMap 区别不大。
而如果不需要保序,可以用 parEvalMapUnordered(又名 mapAsyncUnordered)。
5.3.2 批处理(Batching)
另一个主流场景是:每条消息处理成本较高(比如写 SQL 数据库),也就是"快生产、慢消费"典型场景。若不优化,系统性能会大幅下降,甚至引发故障。此时应采用批处理。
仅用 evalMap 或 parEvalMap 很难抗住大数据流,很容易丢数据或内存爆炸。Fs2 支持用 fs2.Chunk 类型实现分批处理。
scss
scala> Stream(1,2,3).repeat.chunkN(2).take(5).toList
res0: List[Chunk[Int]] = List(
Chunk(1, 2), Chunk(3, 1), Chunk(2, 3), Chunk(1, 2), Chunk(3, 1)
)具体用法举例:
scss
events
.chunkN(1000)
.zip(Stream.iterate(0)(_ + 1))
.parEvalMap { (c, n) =>
IO.println(s"Chunk #$n") *> persist(c)
}
def persist(chunks: Chunk[FootballEvent]): IO[Unit] = ???这里 zip 是为了统计批次数,可以省略。
5.3.3 分析型管道(Analytics)
分析型数据管道既可以是实时流,也可以是批处理流,或者两者结合。实际业务视需求而定。
比如,先实时处理,再按批处理结果入库(当批处理依赖实时处理结果时):
scss
events
.parEvalMap(10) {
process(_).flatMap { e =>
sendMessage(e) &> updateCache(e).as(e)
}
}
.chunkN(1000)
.parEvalMap(10)(persist)不过要注意,这样会让批处理影响到实时处理。如果想解耦,建议引入内部 topic,采用 fan-out 拓扑:
scss
Stream.eval(Topic[IO, FootballEvent]).flatMap { topic =>
val realTime = consumer.receive.parEvalMap(10) {
process(_).flatMap { e =>
(
sendMessage(e), updateCache(e), topic.publish1(e)
).parSequence_
}
}
val batching =
topic
.subscribe(1000)
.chunkN(1000)
.parEvalMap(10)(persist)
Stream(realTime, batching).parJoinUnbounded
}如果批处理和实时处理完全独立,也可这样:
scss
Stream.eval(Topic[IO, FootballEvent]).flatMap { topic =>
val realTime =
topic.subscribe(1000).parEvalMap(50) {
process(_).flatMap { e =>
sendMessage(e) &> updateCache(e)
}
}
val batching =
topic
.subscribe(1000)
.chunkN(1000)
.parEvalMap(10)(persist)
Stream(
realTime,
batching,
consumer.receive.through(topic.publish)
).parJoinUnbounded
}当然"更独立"只是相对的,因为还是一个进程,可能共享线程池等资源。
5.3.4 数据源(Data source)
每个数据管道都始于某种数据源,可以是文件、数据库、缓存、网络连接或消息中间件等。
5.3.4.1 文件
处理文件可以直接用 fs2.io.file,但如果需要处理已知格式(如 CSV、XML、JSON),推荐用 fs2-data 库。
CSV 读取示例:
kotlin
import fs2.data.csv.*
import fs2.data.csv.generic.semiauto.*
import fs2.io.file.{ Files, Path }
// Stream[IO, Movie]
Files[IO]
.readAll(Path("dataset/movies.csv"))
.through(fs2.text.utf8.decode)
.through(decodeUsingHeaders[Movie]())XML 读取示例:
arduino
import fs2.data.xml.*
Files[IO]
.readAll(Path("dataset/demo.xml"))
.through(fs2.text.utf8.decode)
.through(events[IO, String])其实还有许多兼容 Fs2 的库可选,fs2-data 只是个人推荐。
5.3.4.2 数据库
数据库流支持,取决于客户端是否支持 Fs2。PostgreSQL 的 Doobie 和 Skunk 都支持流式查询。
Doobie 示例:
arduino
sql"SELECT name FROM country"
.query[String]
.stream // Stream[ConnectionIO, String]Skunk 示例:
css
val e: Query[String, String] =
sql"SELECT name FROM country".query(varchar)
Stream
.resource(session.prepare(e))
.flatMap(_.stream("U%", 64))5.3.4.3 网络
原生 TCP/UDP 可用 fs2.io.net API 实现。例如极简 Echo TCP 服务器:
scss
Network[IO].server(port = Some(port"5555")).map { client =>
client.reads
.through(fs2.text.utf8.decode)
.through(fs2.text.lines)
.interleave(Stream.constant("\n"))
.through(fs2.text.utf8.encode)
.through(client.writes)
.handleErrorWith(_ => Stream.empty)
}.parJoin(100)更高层次可用如 fs2-grpc 等三方库。
5.3.4.4 消息中间件
后续章节会介绍如何用函数式 Scala 代码与 Apache Pulsar、Kafka 通信。其实市面上还有 RabbitMQ、ZeroMQ、MQTT(Mosquito)、AWS Kinesis、SQS、Google Cloud Pub/Sub 等各种消息系统,也都有可用库。
如 ZeroMQ 用 fmq:
arduino
import io.fmq.*
import io.fmq.socket.pubsub.Subscriber
import io.fmq.syntax.literals.*
val topic = Subscriber.Topic.utf8String("demo"))
Stream.resource {
Context
.create
.evalMap(_.createSubscriber(topic))
.flatMap(_.connect(tcp"://localhost:31234"))
}.flatMap { socket =>
Stream.repeatEval(socket.receiveFrame[String])
}AWS Kinesis/SQS 用 fs2-aws:
less
import fs2.aws.*
val kinesis: Stream[IO, CommittableRecord] =
readFromKinesisStream[IO]("appName", "streamName")
val sqs: Stream[IO, String] =
sqsStream[IO, String](
sqsConfig,
(cfg, cb) => SQSConsumerBuilder(cfg, cb)
).map(_.body())无论数据源是什么,都可以根据实际业务需求采用前面介绍的管道设计思路。
5.4 生产者-消费者(Producer-consumer)
Producer 和 Consumer 可以表示某个具体的消息中间件,比如 Kafka 或 Pulsar。在 Scala 代码中,我们可以通过客户端库提供的接口与它们交互。当然,也可以自己实现抽象接口。
先来看 Producer 的接口,这是最简单的部分:
less
trait Producer[F[_], A]:
def send(a: A): F[Unit]
def send(a: A, properties: Map[String, String]): F[Unit]它用 F_ 表示 effect 类型,A 表示消息类型。因此生产消息本质就是 A => FUnit。第二个方法允许携带附加属性(元数据)。
Consumer 接口稍微复杂一些:
scala
trait Acker[F[_], A]:
def ack(id: Consumer.MsgId): F[Unit]
def ack(ids: Set[Consumer.MsgId]): F[Unit]
def nack(id: Consumer.MsgId): F[Unit]
trait Consumer[F[_], A] extends Acker[F, A]:
def receiveM: Stream[F, Consumer.Msg[A]]
def receiveM(id: Consumer.MsgId): Stream[F, Consumer.Msg[A]]
def receive: Stream[F, A]
def lastMsgId: F[Option[Consumer.MsgId]]
object Consumer:
type MsgId = String
type Properties = Map[String, String]
final case class Msg[A](id: MsgId, props: Properties, payload: A)ack/nack 相关函数被单独放在 Acker 接口中,便于复用。
有了这些接口(tagless algebra),我们可以建模基本的业务逻辑。例如用 concurrently 组合生产者和消费者流:
ini
val c1 =
consumer.receive
.evalMap(n => IO.println(s"Consumed: $n"))
val p2 =
Stream.range(0, 100)
.evalMap(producer.send)
c1.concurrently(p2)p2 会在 c1 结束时自动终止。如果需要二者独立运行,可以用 parJoin 或 parJoinUnbounded:
scss
Stream(c1, p2).parJoin(2)多个 stream 并发运行时,类似如下结构常见于实际服务:
ini
def run: IO[Unit] =
Stream
.resource(resources)
.flatMap { (consumer, topic, server) =>
val http =
Stream.eval(server.useForever)
val subs =
topic.subscribers.evalMap { n =>
Logger[IO].info(s"WS connections: $n")
}
val alerts =
consumer.receive.through(topic.publish)
Stream(http, subs, alerts).parJoin(3)
}
.compile
.drain这个例子运行三个独立小程序:HTTP 服务、WS 连接日志、告警消费与分发。任何一个失败,整体流会终止,因此实际项目需做异常处理或容错。
5.4.1 基于内存的实现(Queue)
我们可以为 Producer 和 Consumer 实现内存版 interpreter。例如 Producer:
less
import cats.effect.std.Queue
def local[F[_]: Applicative, A](
queue: Queue[F, Option[A]]
): Resource[F, Producer[F, A]] =
Resource.make[F, Producer[F, A]](
Applicative[F].pure(
new:
def send(a: A): F[Unit] = queue.offer(Some(a))
def send(a: A, properties: Map[String, String]): F[Unit] = send(a)
)
)(_ => queue.offer(None))这里用 QueueF, Option\[A],生产者推送 None 时,消费者可以优雅地结束。也可以用 fs2.concurrent.Topic。
Consumer 类似:
less
def local[F[_]: Applicative, A](
queue: Queue[F, Option[A]]
): Consumer[F, A] = new:
def receiveM: Stream[F, Msg[A]] = receive.map(Msg("N/A", _))
def receive: Stream[F, A] = Stream.fromQueueNoneTerminated(queue)
def ack(id: Consumer.MsgId): F[Unit] = Applicative[F].unit
def nack(id: Consumer.MsgId): F[Unit] = Applicative[F].unit
...ack/nack 在内存实现下无实际意义,都是 no-op。receive 用 fromQueueNoneTerminated,只要收到 None 就终止。
可以写一个简单 demo:
ini
def run: IO[Unit] =
Queue.bounded .flatMap { q =>
val consumer = Consumer.local(q)
val producer = Producer.local(q)
val p1 =
consumer.receive
.evalMap(s => IO.println(s">>> GOT: $s"))
val p2 =
Stream
.resource(producer)
.flatMap { p =>
Stream
.sleep[IO](100.millis)
.as("test")
.repeatN(3)
.evalMap(p.send)
}
IO.println(">>> Initializing in-memory demo <<<") *>
p1.concurrently(p2).compile.drain
}输出如下:
shell
>>> Initializing in-memory demo <<<
>>> GOT: test
>>> GOT: test
>>> GOT: test5.4.2 分布式实现:基于 Apache Pulsar
接下来我们基于 Apache Pulsar 和 Neutron 库实现分布式的生产者和消费者。
5.4.2.1 Producer
Pulsar 支持 Key-Shared 订阅模式,生产者可以给每条消息设置一个 ordering key,实现"分片"能力:
ini
val m1 = Message("key-1", "a1")
val m2 = Message("key-2", "b1")
val m3 = Message("key-3", "a2")比如有两个消费者,m1/m3 发给 c1,m2 发给 c2。
为此我们定义 Shard typeclass:
kotlin
import dev.profunktor.pulsar.ShardKey
trait Shard[A]:
def key: A => ShardKeyCompaction typeclass 用于 compacted topic:
kotlin
import dev.profunktor.pulsar.MessageKey
trait Compaction[A]:
def key: A => MessageKeyProducer 构造如下:
less
import dev.profunktor.pulsar.{ Producer as PulsarProducer, * }
def pulsar[F[_]: Async: Logger: Parallel, A: Encoder](
client: Pulsar.T,
topic: Topic.Single,
settings: Option[PulsarProducer.Settings[F, A]] = None
): Resource[F, Producer[F, A]] =
val _settings = ...
val encoder: A => Array[Byte] = _.asJson.noSpaces.getBytes(UTF_8)
PulsarProducer
.make[F, A](client, topic, encoder, _settings)
.map { p =>
new:
def send(a: A): F[Unit] = p.send_(a)
def send(a: A, properties: Map[String, String]): F[Unit] = p.send_(a, properties)
def send(a: A, tx: Txn): F[Unit] = p.send_(a, tx.get)
}5.4.2.2 Consumer
Pulsar Consumer 更复杂。包括死信队列策略和解码错误处理:
ini
import dev.profunktor.pulsar.{ Consumer as PulsarConsumer, * }
def pulsar[F[_]: Async: Logger, A: Decoder: Encoder](
client: Pulsar.T,
topic: Topic,
sub: Subscription,
settings: Option[PulsarConsumer.Settings[F, A]] = None
): Resource[F, Consumer[F, A]] =
val deadLetterPolicy = ...
val _settings = ...
val decoder: Array[Byte] => F[A] = ...
val handler: Throwable => F[PulsarConsumer.OnFailure] = ...
PulsarConsumer.make[F, A](
client, topic, sub, decoder, handler, _settings
).map { c =>
new:
def receiveM: Stream[F, Msg[A]] = ...
def receive: Stream[F, A] = ...
def ack(id: MsgId): F[Unit] = ...
def nack(id: MsgId): F[Unit] = ...
...
}5.4.2.3 示例
用前述抽象创建 Producer 和 Consumer:
ini
def resources =
for
config <- Resource.eval(Config.load[IO])
pulsar <- Pulsar.make[IO](config.pulsar.url, Pulsar.Settings().withTransactions)
cmdTopic = AppTopic.TradingCommands.make(config.pulsar)
evtTopic = AppTopic.TradingEvents.make(config.pulsar)
producer <- Producer.pulsar[IO, TradeEvent](pulsar, evtTopic, evtSettings)
consumer <- Consumer.pulsar[IO, TradeCommand](pulsar, cmdTopic, sub)
yield (server, consumer, Engine.fsm(producer, Txn.make(pulsar), consumer))5.4.3 分布式实现:Apache Kafka
我们也可以用 fs2-kafka 库实现 Kafka 版 Producer/Consumer。
Producer:
less
import fs2.kafka.{ KafkaProducer, ProducerSettings }
def kafka[F[_]: Async, A](
settings: ProducerSettings[F, String, A],
topic: String
): Resource[F, Producer[F, A]] =
KafkaProducer.resource(settings).map { p =>
new:
def send(a: A): F[Unit] =
p.produceOne_(topic, "key", a).flatten.void
def send(a: A, properties: Map[String, String]): F[Unit] = send(a)
}Consumer 更复杂,需要维护 offset 状态:
ini
import fs2.kafka.{ ConsumerSettings, KafkaConsumer }
import org.apache.kafka.clients.consumer.OffsetAndMetadata
import org.apache.kafka.common.TopicPartition
def kafka[F[_]: Async, A](
settings: ConsumerSettings[F, String, A],
topic: String
): Resource[F, Consumer[F, A]] =
Resource.eval(
Ref.of[F, List[CommittableOffset[F]]](List.empty)
).flatMap { ref =>
KafkaConsumer
.resource[F, String, A](settings.withEnableAutoCommit(false))
.evalTap(_.subscribeTo(topic))
.map { c =>
new:
def receiveM: Stream[F, Msg[A]] = ...
def receive: Stream[F, A] = ...
def ack(ids: Set[MsgId]): F[Unit] = ...
...
}
}5.4.3.3 示例
最终,组合 producer/consumer:
ini
val topic = "trading-kafka"
val consumerSettings = ...
val producerSettings = ...
def resources =
for
c <- Consumer.kafka[IO, TradeEvent](consumerSettings, topic)
p <- Producer.kafka[IO, TradeEvent](producerSettings, topic)
yield c -> p
val event: Option[TradeEvent] = ??? // 随机数据
def run: IO[Unit] =
Stream
.resource(resources)
.flatMap { (consumer, producer) =>
val p1 =
consumer.receive
.evalMap(e => IO.println(s">>> KAFKA: $e"))
val p2 =
Stream
.awakeEvery[IO](1.second)
.as(event)
.evalMap(_.traverse_(producer.send))
p1.concurrently(p2)
}
.interruptAfter(5.seconds)
.compile
.drain运行效果:
yaml
>>> Initializing kafka demo <<<
>>> KAFKA: CommandExecuted(...)
>>> KAFKA: CommandExecuted(...)
>>> KAFKA: CommandExecuted(...)
>>> KAFKA: CommandExecuted(...)
[success] Total time: 8 s, completed Nov 18, 2021, 1:33:28 PM5.5 小结
我们已经看到,Kafka 和 Pulsar 的语义实际上完全不同。虽然实现一个 Consumer 和 Producer 的抽象很有趣,而且在原型验证阶段也许能用,但你仍然需要深入理解所选消息中间件的优缺点,选定工具后,建议直接使用对应的官方库(比如 fs2-kafka 或 neutron)。
在我们下一章要写的应用中,依然会保留对 Consumer 和 Producer 创建的抽象接口。不过你会发现,很多与 Pulsar 相关的代码(比如订阅、消费/生产设置等)都会混杂在服务实现中。如果选 Kafka 也会遇到同样的情况。
也就是说,为所有服务提供一个通用的构造器(比如内置 JSON 日志、统一默认配置、统一语义),依然是很好的实践。
除了了解这两种流行消息中间件的客户端库之外,本章我们还学习了有限状态机、数据流水线及其他流式处理的实用技巧,这些内容在后续真正动手写应用代码时会非常有帮助。