这份笔记涵盖:
-
多级缓存的整体结构
-
各层的作用(浏览器、本地缓存、Redis、JVM 缓存)
-
请求的完整流向
-
缓存更新与同步机制
-
Canal 的作用
-
缓存一致性
-
多级缓存优点与注意点
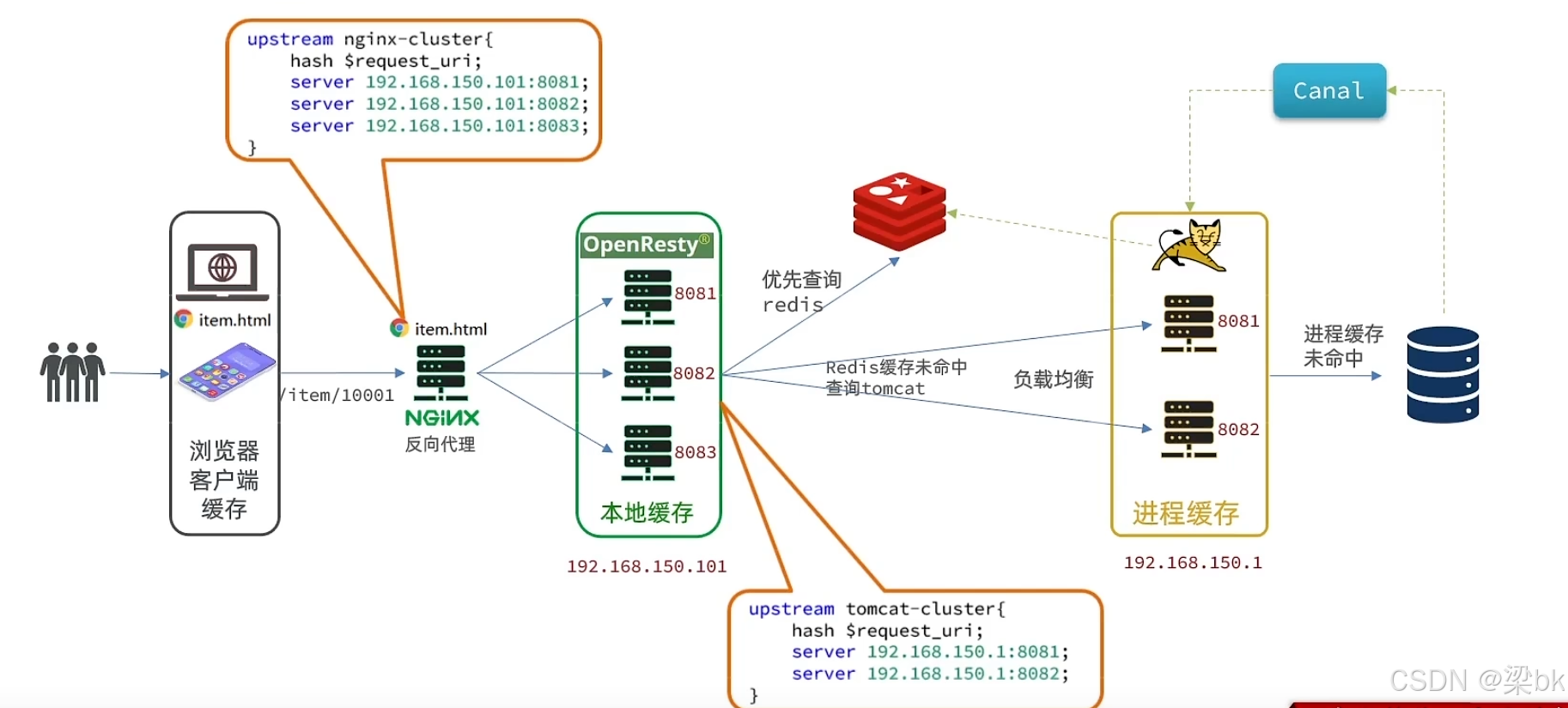
一、系统总体结构概述
根据架构图,系统采用 多级缓存体系 来提升接口性能、减少数据库压力、应对高并发。整体通路如下:
浏览器缓存
↓
Nginx 反向代理(多个节点) → OpenResty 本地缓存
↓
Redis 分布式缓存
↓
Tomcat(多个节点)JVM 进程缓存
↓
数据库
↑
Canal(监听数据库更新并同步缓存)这里包含:
-
客户端缓存(浏览器缓存)
-
Nginx 层本地缓存(OpenResty)
-
Redis 缓存层(分布式缓存)
-
JVM 进程内缓存(应用服务器本地缓存)
-
数据库(最终一致性)
-
Canal(缓存更新同步组件)
二、缓存分层结构详解
1. 浏览器端缓存(客户端缓存)
特点:
-
由前端配置 Cache-Control 产生
-
直接存储 HTML、JS、CSS 或静态 JSON
-
减少请求进入服务器
适用:
-
静态页面(如 item.html)
-
不经常变化的资源
2. Nginx → OpenResty 本地缓存(一级缓存)
架构图中 Nginx 上挂了多个 OpenResty 实例(8081、8082、8083),它们提供:
-
本地 L1 缓存(Lua Shared Dict)
-
复杂缓存逻辑控制(比原生 proxy_cache 更灵活)
工作机制(一级缓存)
请求到达 OpenResty
→ 查本地共享字典缓存
→ 命中:直接返回
→ 未命中:查 Redis优点:
-
在 Nginx 层拦截大量请求
-
减轻后端压力
-
不需要经过 Java 服务即可返回数据
-
延迟极低
缓存对象:
-
商品详情页数据
-
首页热点数据
-
店铺信息
这是图片中绿色区域 "本地缓存" 所表达的部分。
3. Redis 缓存(二级缓存)
OpenResty 未命中缓存后会访问 Redis:
OpenResty → Redis这是系统的中心缓存层:
-
全局共享
-
持久存在于内存中
-
QPS 高
-
可配置过期时间、热点数据保护
职责:
-
缓存大量热点数据
-
给一级缓存回填数据
-
向应用服务器提供共享缓存
适用:
-
商品、店铺、分类等基础信息
-
分布式业务数据缓存
4. JVM 进程缓存(三级缓存)
架构图右侧黄色的 Tomcat 集群(8081、8082)代表 Java 服务节点,每个节点内部都会维护一个:
- 进程内缓存(如 Caffeine)
三级缓存属于:
应用级本地缓存用途:
-
加速 Redis 命中后的数据处理,例如反序列化
-
减少 Redis 调用次数
-
缓解网络压力和序列化开销
特点:
-
仅当前 JVM 节点可用
-
不共享,需要 TTL 维持一致性
-
命中速度最快(纳秒级)
三级缓存是 Redis 未命中后最后一层"缓存兜底层"。
5. 数据库(最终数据源)
当 JVM 缓存仍未命中:
Tomcat → DB从数据库读取最新数据,并负责:
-
回写 Redis
-
通过 Canal 的监听实现缓存更新
6. Canal(数据变更监听)
图中 Canal 位于 DB 与缓存层之间,用于:
-
监听 MySQL binlog
-
捕获数据库更新、插入、删除
-
通知 Redis/JVM/Nginx 缓存更新
-
保证缓存一致性
这是保证多级缓存数据准确性的关键组件。
三、请求全链路流程解析(结合图片)
以请求 /item/10001 为例:
浏览器 → Nginx → OpenResty → Redis → JVM Cache → DB步骤 1:浏览器缓存
若 item.html 已缓存 → 直接命中,不进入服务器。
步骤 2:Nginx 反向代理
浏览器未命中 → 将请求发送到 OpenResty。
Nginx 内部 upstream 采用 URI Hash 实现负载均衡(图中配置):
upstream nginx-cluster {
hash $request_uri;
}保证相同商品请求分到同一个 OpenResty 节点,提高本地缓存命中率。
步骤 3:OpenResty 本地缓存(一级)
OpenResty 查共享字典:
local_cache:get("item:10001")命中 → 直接返回。
未命中 → 查 Redis。
步骤 4:Redis 二级缓存
若 Redis 命中:
-
返回数据给 OpenResty
-
OpenResty 回填一级缓存
-
返回给客户端
若 Redis 未命中:
-
请求后端 Tomcat(负载均衡)
-
Tomcat 查 JVM 本地缓存(三级)
-
JVM 仍未命中 → 查 DB
-
回写 Redis
-
回写 OpenResty
-
返回给客户端
四、数据更新流程(结合 Canal)
当数据在 DB 中被更新时,缓存必须同步更新。
流程如下:
DB → binlog → Canal → 通知缓存系统 → 删除 Redis 缓存 → L1 缓存自然过期Canal 不直接操作 OpenResty,只需要删除 Redis 缓存即可:
-
Canal 监听 binlog
-
Canal 触发缓存删除事件
-
删除 Redis key
-
OpenResty 一级缓存失效
-
JVM 缓存 TTL 到期自然清理
最终实现:
-
一致性维持
-
老数据不会长期存在
五、缓存一致性策略
多级缓存天生会存在不一致问题,因此系统采用:
-
Redis 主动删除(强一致性保障)
-
Nginx/OpenResty 本地缓存设置较短 TTL
-
JVM 进程缓存 TTL 更短(几十秒 ~ 几分钟)
-
写操作后主动删除 Redis 缓存(Cache Aside)
整体保证系统在短时间内达到最终一致性。
六、采用多级缓存的优势
-
最高性能:OpenResty 缓存 + JVM 进程缓存
-
高可用:Redis 作为中心缓存
-
高扩展性:Nginx 与 Tomcat 都是多实例
-
天然抗高并发:多层挡住大量请求
-
容错能力强:Redis 宕机也能靠 L1/L3 临时顶住
七、总结(结合图片结构)
根据图中架构,多级缓存三层分别扮演了:
| 层级 | 名称 | 描述 | 目标 |
|---|---|---|---|
| L1 | OpenResty 本地缓存 | 最前端、本地内存缓存 | 拦截 70% 以上请求 |
| L2 | Redis 分布式缓存 | 全局共享缓存 | 服务集群一致的热点数据 |
| L3 | JVM 进程缓存 | 应用内部缓存 | 减少 Redis 压力、提高性能 |
Canal:
-
负责数据更新后的缓存同步
-
避免缓存脏读
-
维持最终一致性
这也正是黑马程序员课程中重点讲解的 多级缓存架构方案。