内附 KubeCon China 2025 阿里云相关演讲视频回放及 KubeCon China 2025 分论坛 | 阿里云 AI 基础设施技术沙龙演讲 PDF。
KubeCon + CloudNativeCon China 2025 近期在香港圆满落幕。
自 2015 年首次举办以来,随着 Kubernetes 的迅速发展,KubeCon 的规模和参与者数量逐年增加,现已演变为全球范围内最大的云原生技术会议之一。其形式多样的活动、领先的技术主题和强大的社区支持,为全球开源社区、开发者、技术专家和最终用户提供一个交流和展示的平台,凭借高度的专业性和广泛的行业影响力,吸引了众多参会者。
在全球技术迅速发展的背景下,AI 技术正在重塑各行各业,成为当今备受关注的话题。本次大会上,AI 无疑是绝对的主旋律。作为全球领先的云计算厂商之一,阿里云在 KubeCon China 2025 盛会上带来了多个精彩议题,共同探讨云原生、开源及 AI 领域的前沿进展、核心技术和最佳实践。此外,阿里云还在分论坛中展示了针对 AI 场景的基础设施产品的全面升级及端到端的解决方案。
本文整理自阿里云在 KubeCon China 2025 大会及 KubeCon China 2025 分论坛 | 阿里云 AI 基础设施技术沙龙上的精彩分享。
01. AI Infra 开源技术创新与优化在 Kubernetes 上高效构建机器学习 Pipelines
Argo Project 开源的首个项目 - Argo Workflows,作为专为 Kubernetes 设计的编排批量任务的工作流引擎,具有云原生、轻量化、易扩展等特点,广泛应用于机器学习 Pipelines、批量数据处理、基础设施自动化和 CI/CD 等场景。帮助众多自动驾驶、科学计算、金融量化用户执行大规模并行任务、有效节省成本。
阿里云作为 Argo Workflows 的主要维护者之一,在大会上分享了 Argo Workflows 近期的一些项目更新:
- 性能和可扩展性优化
通过支持 Multiple Mutexes、Semaphores、Parallel Artifacts Resolving 等机制,显著提升了任务执行效率。这使得在计算资源密集型的机器学习工作负载下,减少任务执行时间和提高系统响应速度。
- Python SDK Hera 支持
Hera 的引入使得数据科学家和机器学习工程师可以使用熟悉的 Python 语言构建工作流,降低了技术门槛,加快了开发周期,使得用户能够更快速地迭代和优化机器学习算法。
- CronWorkflows 策略增强
CronWorkflows 的增强允许用户进行定期调度,方便按需训练和更新模型,确保机器学习 Pipeline 中的数据始终保持最新,提高了模型的准确性和效率。
- AI 和大数据任务支持
新增对 Spark、Ray、Pytorch 等多种 Plugin 的支持,使得用户能够无缝构建端到端的 AI 和机器学习 Pipeline。这种灵活性加速了复杂 AI 项目的实施进程,提升了工作流的集成能力。
点击跳转观看完整视频:Argo Workflows: Intro, Update and Deep Dive
平衡成本与性能的 Kubernetes 工作流最佳存储方案
一个可靠的 Pipelines,除了 Argo Workflows 提供的灵活编排能力外,存储方案也至关重要。以下是阿里云在服务客户过程中积累的基于 Argo 的存储系统设计与优化经验。
大多数模型均存储在云端,及时的弹性伸缩在降低资源使用成本方面发挥了重要作用。然而,随着可扩展 AI/ML 需求的增长,在云原生基础架构中高效地分发 AI 模型已成为企业面临的关键挑战。对于一些达到 TB 级规模的模型,云存储的读写性能和带宽瓶颈往往接近上限,这对模型的高效加载和推理造成困难。因此在成本和性能的双重考量下,选择合适的云存储解决方案,并优化其在云原生架构中的配置尤为关键。
Argo Workflows 中存储读写主要通过 Artifact 机制 和 Kubernetes 原生 Volume(存储卷)机制两种方式实现。底层存储架构的差异性直接影响存储卷的读写性能表现,以下分享基于 Volume 方案的存储架构设计与优化方向探讨,并以自动驾驶场景抽象出的流水线为例,解析该流水线中不同数据的特性与存储选型。
存算一体 vs 存算分离 ?
存算一体适合非数据型企业通过 MinIO/Ceph 等开源方案实现低成本基础读写,或大型 AI 公司通过 3FS 等开源方案利用 RDMA 等硬件及 GPU 闲置存储资源(需具备二次开发能力)。其余企业仍以存算分离为主。
NAS vs OSS ?
NAS/CPFS 有性能优势,适合 HPC 场景,对于需要强一致性、高并发、随机写入或依赖文件元信息的的场景,建议优先考虑 NAS 方案。若考虑成本、容量与 http 访问简易性,选择 OSS 时可针对数据特性与访问模型进行调优。
OSS 优化方案 ?
通用的 OSS 访问性能优化方案包括修改服务端存储布局、使用轻量客户端、集群侧分布式缓存及服务端加速等。
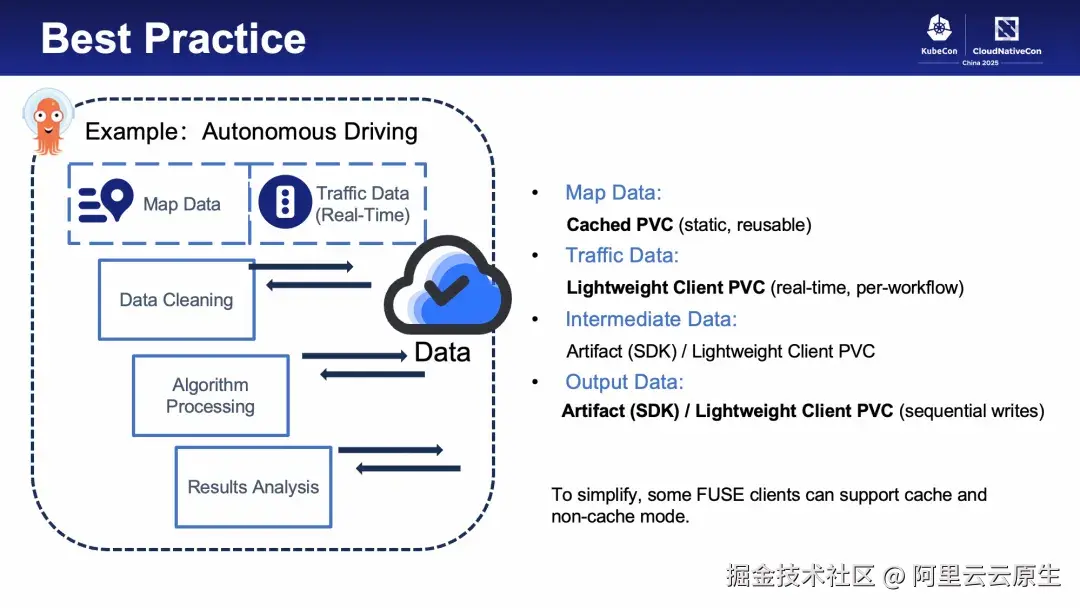
在自动驾驶流水线中,静态地图数据适合用带缓存的客户端存储卷(如 JindoFuse ),实时路况数据则可用轻量客户端(如 ossfs2.0 )。中间及最终数据上传下载可结合 Argo 原生 Artifacts 或轻量客户端存储卷,按并发量选择。
对于 OSS 的性能优化,实践经验是:单一存储卷难以满足全流程性能需求。建议按数据的特性和业务的访问模型拆分多个存储卷(如隔离随机写与只读场景)。因此在优化 OSS 存储访问时,还需要权衡运维难度与性能限制。以本流水线为例,若维护成本高,可优先全用轻量客户端;若使用 Fluid 等缓存平台,可选择同时支持无缓存模式的客户端。
点击跳转观看完整视频:AI Model Distribution Challenges and Best Practices、Argo Workflows: Intro, Update and Deep Dive
AI 工作负载的数据访问优化
同样作为大会焦点的 Fluid ,其随着对更高效数据管理能力的需求而生。
在 AI 工作负载中访问数据所面临的挑战里,Kubernetes 环境中的数据管理和使用问题尤为突出。虽然 Kubernetes 提供了传统的数据访问接口(CSI),但并未提供满足数据密集型应用(如 AI)的高效数据访问与管理能力。这导致了在 Serverless 算力、混合云环境下的多样化数据接入需求以及数据科学家动态切换数据集时低效的问题。
为了解决这些挑战,阿里云容器服务团队、南京大学和 Alluxio 社区共同提出了"云原生弹性数据抽象"概念,并以此创建了云原生数据编排与加速系统 Fluid。Fluid 围绕弹性数据集构建了容器数据分布式缓存层,提供了数据集管理、权限控制和访问加速等功能,并强调"简单接入、到处运行、按需使用"的愿景。
Fluid 的关键概念包括 Dataset、Runtime 和 DataOperation,其允许用户灵活地定义异构数据源、使用插件化的分布式缓存系统,并实现数据的主动预热与处理。
此外, Fluid 做了一些项目更新,如轻量级的 Thinruntime 和通用的 CacheRuntime。
轻量级 Thinruntime 通过简化 API 定义和职责,专注于在 Kubernetes 环境中实现数据客户端的插件化接入,从而显著提升了大规模集群中海量数据集的处理效率。而通用的 CacheRuntime 则为存储供应商提供了一种非入侵的接入机制,减少了学习和开发成本,无需深入理解 Fluid 的完整工作机制即可轻松接入。通过实施通用的 CacheRuntime CRD,终端用户也可以借助统一的 CRD API 更方便地使用与管理多样化的分布式缓存系统。
特别值得一提的是,Fluid 入选 CNCF 2024 技术雷达报告(Adopt 类别) ,根据报告结果,Apache Airflow、CubeFS、Kubeflow 和 Fluid 在批处理、AI 和 ML 领域得到了广泛的认可,并已被大量部署在最终用户的生产环境中。已开源 10 年的 Airflow 已连续 3 年获得此项荣誉,与此形成对比的是,作为这四个项目中最年轻的成员,Fluid 的突出表现不仅获得了社区用户的广泛认可,也代表了对 Fluid 开源社区维护者和贡献者的极大赞赏。

点击跳转观看完整分享:Fluid Data Anyway, Data Anywhere, Data Anytime、Practice in Horizon Robotics on Large-scale End-to-end Model Training
基于 Kubernetes 一键部署多种开源 PD 分离框架
在处理大型语言模型(LLM)时,推理请求可分为 Prefill 和 Decode 两个阶段。其中,Prefill 阶段需要计算用户输入 Prompt 的 KV 值,属于计算密集型;而 Decode 阶段则需存储之前计算得到的所有 KV 值,属于显存密集型。当这两个阶段在同一 GPU 上运行时,会相互干扰导致处理时间增加以及性能下降。
目前,开源社区有多种 PD 分离架构的解决方案以优化这一问题,如 vLLM、SGLang 和 Dynamo 等。然而,这种多样性虽然提供了灵活性,但也给实际应用带来了挑战,原因是这些方案在组件构成、部署方式以及配置要求等方面存在不一致性,导致用户在选择和部署运维时面临了一系列困难。
因此,阿里云技术团队创新性地提出了 RoleBasedGroup 工作负载(以下简称 RBG),并在大会上进行分享。
RBG 支持一键部署多种开源 PD 分离框架,如 vLLM、SGLang 和 Dynamo。其灵活地支持 Prefill/Decode 的弹性配置,极大地简化了用户的部署流程,并有效降低了大型语言模型(LLM)应用的部署和运维复杂度。RBG 现已开源,可以在 GitHub 开源平台上获取。以下是 RBG 在不同层面的功能:
编排
- 统一调度: 将紧密协作的多角色服务抽象为"Super Pod Group",突破传统 Pod 粒度限制,实现高效的资源利用与负载均衡。
- 支持声明式角色模板(RoleTemplate): 允许定义角色镜像、资源配额、持久化卷等基础属性,支持多种工作负载实现(如 Deployment、StatefulSet、LWS),简化配置与管理。
- 主流 PD 分离方案支持: 原生支持 Dynamo、vLLM+Mooncake 和 SGLang+Mooncake 等方案,提升适用性。
- DAG 定义角色启动顺序: 通过有向无环图(DAG)定义各个角色的启动顺序,确保依赖关系的有效管理,支持阻塞式启动协调。
- 按角色扩缩容: 允许根据不同角色的需求灵活调整资源,优化性能与资源使用。
运行时
- 分级故障处理: Pod 崩溃重启(Level 1)→ 角色级重建(Level 2)→ 全组重构(Level 3),在发生故障时提高系统的可靠性与恢复能力。
- 智能滚动升级: 基于请求排空机制,支持零中断的智能滚动更新,确保服务在升级过程中不中断。
扩展
- 统一监控: 实现对主流引擎(如 vLLM、SGLang 等)指标的统一监控,提供全面的性能视图,并简化管理流程。
- 动态 LoRA 管理: 支持对 LoRA(Low-Rank Adaptation)技术的动态管理,提高适应性与灵活性。
- 全局拓扑信息转换: 将 RBG 的全局拓扑信息自动转换为引擎可识别的专属格式(如Dynamo、Mooncake),从而增强系统的可管理性。
点击跳转观看完整分享:Mastering Prefill-Decode-Disaggregated Architecture: Solutions and Best Practices in Alibaba Cloud
保障多租场景安全与稳定性最佳实践
企业 AI/ML 应用在规模化发展进程中或多或少都面临实施多租户架构的挑战。多租架构在帮助企业降低运维和资源成本的同时,也会引起相应的安全和稳定性问题。虽然据安全报告显示,近两年企业线上应用 Pod 的安全水位在整体上有所提升,但仍然给攻击者留下了很多可乘之机。在成功入侵集群中的任意 Pod 后,攻击者会迅速排查自己当前所处的集群位置,并思索发起进一步横向攻击的路径。
为此 K8s 社区先后推出了多个相关特性,包括:KEP-4193 Bound service account token improvements、KEP-4601 Authorized with Selector、KEP-3488 CEL for Admission Control 等关键特性,这些特性可以有效提升多租共享集群的节点隔离和鉴权准入能力。
阿里云技术专家在大会上通过一组攻防 demo 演示如何基于 KEP-3488 中相关 VAP 策略准入拦截多租场景下典型的节点弹跳横向攻击。并列举了当下企业实施多租的典型方法论和对应的 CNCF 社区开源项目,以及在多租鉴权和准入领域中典型的策略模型和引擎的关键特性。
针对企业在实施租户隔离进程中遇到的核心挑战,阿里云技术专家提出并演示了一种基于 Label/Field Selector 的 ReBAC 精细化动态鉴权机制,即通过社区结构化鉴权配置特性,借助 CEL 策略语言实现目标资源、命名空间、请求用户 Group 或请求动作等属性的精细化动态控制,配置简单且灵活;同时,依托社区 Authorize with Selectors 特性门控和 ReBAC 关系模型策略引擎 OpenFGA,不同租户资源对应的鉴权上下文信息可以在 webhook 组件中动态组装为请求 OpenFGA 策略引擎的三元组;最后,通过可动态配置的 OpenFGA 策略模型完成多租资源鉴权。此方案可帮助企业在构建多租架构时降低资源和运维成本,灵活地实施对 K8s 集群维度资源和 CRD 资源的动态访问控制。
点击跳转观看完整分享:Enhanced Authorization To Prevent Lateral Node Escape
此外,大会上阿里云的技术专家们还分享了一些云原生相关的重要技术洞见和最佳实践。包括:服务网格的升级最佳实践,尤其是与侧车模式和热升级相关的技术策略;如何在 Kubernetes 和容器管理中优化 Pod 启动和资源管理,以确保高稳定性和有效的资源利用率;如何利用 OpenTelemetry 增强系统的可观察性和监控能力等。这些技术与经验共同促进了云原生与 AI 应用的深度融合,为企业提供了创新的解决方案。相关完整分享可以点击下方视频链接进行观看。
| 议题 | 视频链接 |
|---|---|
| AI 模型分发挑战和最佳实践AI Model Distribution Challenges and Best Practices - Wenbo Qi, Xiaoya Xia & Peng Tao, Ant Group; Wenpeng Li, Alibaba Cloud; Han Jiang, Kuaishou | 视频 |
| 速度与激情:地平线大规模端到端模型训练实践Fast and Furious: Practice in Horizon Robotics on Large-scale End-to-end Model Training - Chen Yangxue, Horizon Robotics & Zhihao Xu, Alibaba Cloud | 视频 |
| 从瓶颈到突破:征服 Kubernetes 中的应用程序启动高峰From Bottleneck To Breakthrough: Conquering Applications Startup Peaks in Kubernetes - Hexi Guo, Alibaba Cloud; Rentian Zhou & Zhuoqi Liu, CloudPilot AI | 视频 |
| 利用 Golang 中的编译时自动检测功能提升可观测性Advancing Observability With Compile-Time Auto-Instrumentation in Golang - Liu Ziming, Alibaba Cloud & Przemek Delewski, Quesma | 视频 |
| Argo 工作流程:介绍、更新和深入探讨Argo Workflows: Intro, Update and Deep Dive - Shuangkun Tian & Yashi Su, Alibaba Cloud | 视频 |
| OpenTelemetry 项目更新OpenTelemetry Project Update - Zihao Rao, Alibaba Cloud; Hui Wang, VictoriaMetrics; Jared Tan, DaoCloud | 视频 |
| 多租户守护者:增强授权以防止横向节点逃逸Guardians of Multi-Tenancy: Enhanced Authorization To Prevent Lateral Node Escape - Dahu Kuang & Cheng Gao, Alibaba Cloud | 视频 |
| 项目闪电演讲:流体数据,随时随地数据,随时数据Project Lightning Talk: Fluid Data Anyway, Data Anywhere, Data Anytime - Tongyu Guo, Maintainer,Alibaba Cloud | 视频 |
| 闪电演讲:无缝升级服务网格的最佳实践Lightning Talk: Best Practices for Upgrading Service Mesh Seamlessly - Hang Yin, Alibaba Cloud & Zhencheng Lee, Huawei Technologies | 视频 |
| 闪电演讲:掌握预填充-解码-分解架构:阿里云的解决方案和最佳实践Lightning Talk: Mastering Prefill-Decode-Disaggregated Architecture: Solutions and Best Practices in Alibaba Cloud - Jing Gu & Yang Che, Alibaba Cloud | 视频 |
KubeCon China 2025 阿里云相关精彩分享视频回放
02. AI Infra 产品的全面升级
除了在开源项目中持续探索与创新,阿里云弹性计算、存储和云原生团队的专家们在 KubeCon China 2025 分论坛 | 阿里云 AI 基础设施技术沙龙上,还分享了面向 AI 场景的基础设施产品全面升级的最新进展与实践经验。
AI网关 × Nacos × 全栈可观测:助力 AI Agent 与 MCP 开发落地
在 AI 应用开发和部署过程中,AI 网关与 Nacos 服务为 AI Agent 和 MCP(Model Control Plane)的开发提供了强大的支持和优化。借助阿里云全面的可观测性能力,这套解决方案不仅提升了大模型训练和推理过程中的效率和稳定性,还实现了深度监控、快速调试和智能运维。
AI 网关作为连接前端应用与后端 AI 模型的桥梁,能够高效地管理和调度各种 AI 请求,同时确保数据的安全传输和处理。通过阿里云的可观测性能力,AI 网关可实现对流量、延迟、错误率等关键指标的实时监控,帮助开发者快速发现性能瓶颈,并通过分布式追踪技术深入分析请求链路,优化系统整体性能。
Nacos 作为一个动态服务发现、配置管理和服务管理平台,在 AI Agent 和 MCP 的开发中扮演着至关重要的角色。它帮助开发者实现服务的自动注册与发现,简化了服务治理问题。通过 Nacos,AI Agent 可以实时获取最新的配置信息,动态调整其行为以适应不同的应用场景和需求。同时,Nacos 还支持容灾备份功能,确保业务的连续性和高可用性。结合阿里云的可观测性工具,如日志服务(SLS)、应用监控(ARMS)和链路追踪(Tracing),开发者可以全面掌握 AI Agent 的运行状态,实现异常预警、根因分析和自动化告警,从而显著提升系统的可靠性和运维效率。AI 网关与 Nacos的协同作用,加上阿里云在可观测性领域的深度能力,使得 AI Agent 和 MCP 能够在复杂多变的 AI 应用场景中展现出卓越的性能和稳定性。
无论是企业 AI 创新、大数据分析、应用管理还是办公协同,这套解决方案都能提供定制化的支持,助力企业在智能化转型的道路上稳步前行。
一键托管,轻松驾驭 Kubernetes
阿里云容器服务团队回收了 125 份关于容器使用情况的调研反馈,数据显示,52% 受访者使用容器化方式部署 AI/ML 工作负载,其中 72% 的受访者仍认为使用 Kubernetes 面临的最大挑战是易用性。
针对这一痛点,阿里云容器服务 Kubernetes 版 ACK 推出智能托管模式,即 Auto Mode。其支持在创建 ACK Pro 集群过程中选择开启智能托管模式,仅需进行进行简单的网络规划配置,即可快速创建一个符合最佳实践、全面自动化托管运维的 Kubernetes 集群。
多集群管理与容器 AI 解决方案
随着业务的发展,企业会采用多 K8s 集群架构,虽然这提升了企业的隔离性、扩展性和容灾能力,但也会引入一些管理和运维上的挑战。
分布式云容器平台 ACK One 是面向混合云、多集群、分布式计算、容灾等场景的企业级云原生平台。ACK One可以连接并管理您任何地域、任何基础设施上的 Kubernetes 集群,提供统一运维与安全、统一资源调度、统一应用分发等能力。
万兴科技通过 ACK One 为全球 20 多个不同环境的集群进行数千 AIGC 的应用分发; 极氪汽车基于 ACK One提供的多集群成本分析能力,为数千 Pod 开启成本洞察并节省了数百万美元;某国际酒店集团, 基于 ACK One 实现了统一的安全策略管理。
对于多集群之间业务互访等多集群 service 管理的需求, 可以结合使用阿里云服务网格 ASM 简化服务治理,获得包括服务调用之间的流量路由与拆分管理、服务间通信的认证安全以及网格可观测能力。
合思科技基于此方案构建了全球多家公共云厂商 K8s 集群的容灾方案,既实现了在 K8s 地址冲突情况下的统一 Service 管理,又实现某集群服务不可用时的自动故障切换。
ACK One 还提供了多集群 AI 作业调度和分发能力:当单一 ACK 集群无法满足大规模 AI 训练和推理任务的资源需求,或当前已有的多个 ACK 集群有较多资源闲置时,企业可以利用 ACK One 多集群作业分发能力,将任务调度到多个集群。
此外,阿里云全新推出的 ACS GPU 容器算力,其支持高性能网络 HPN,满足模型训练和推理场景需求,同时产品内置 PD 分离等 Infra 优化能力,单 GPU Pod 性能可提升 20%。
在以上方案基础上,结合阿里云容器镜像服务企业版 ACR EE ,可实现应用镜像的高速分发及全球多 Region 自动同步,进一步缩短发布时延。
超大规模 GPU 集群高效支撑大模型训练与推理
智能计算灵骏是阿里云专为 AI 模型训练与推理打造的高性能 GPU 集群服务,面向大规模人工智能计算场景而设计。它广泛适用于大模型研发、自动驾驶、生命科学、金融科技等多个前沿领域,提供高性能、高扩展性与高稳定性的软硬一体智算底座。智能计算灵骏支持十万卡级别的超大规模集群部署,全面支持大模型 TP、DP、EP 等多种并行策略。万卡规模下,网络线性度高达 96%,超大 MoE 训练任务算力有效利用率高达 97%,轻松应对万亿乃至十万亿参数级别大模型的训练需求,并通过优化算力性能,降低推理服务成本。目前,智能计算灵骏已服务国内超过一半的大模型企业,成为行业主流选择。
高可用与 AI 创新存储解决方案
阿里云发布多项高可用与 AI 创新存储解决方案。在业务高可用领域,ESSD 同城冗余云盘实现多可用区物理隔离存储,任一可用区发生故障时,系统可秒级完成读写切换,保障业务连续性且 RPO=0 ,已覆盖新加坡、日本等全球区域,TOP 游戏及跨境支付客户已全面采用 ESSD 同城冗余云盘作为其核心存储底座。OSS 同城冗余新增马来西亚地域,覆盖全球 12 个地域,快照备份可抵御单可用区故障。云备份服务 Cloud Backup 覆盖全球主要区域,支持跨地域/账号备份及不可变存储,满足金融合规要求;数据灾备中心 BDRC 实现 ECS、OSS 等 IAAS 产品统一灾备管理,提供可视化风险监控与策略优化。
AI 创新方面,CPFS 支持计算侧磁盘/内存分布式读缓存加速,100 GB/s 和 OSS 数据流动,单节点吞吐达 40 GB/s,助力大模型训练和推理效率提升;OSS 数据湖单湖性能突破 20Tbps,发布资源池 QoS 新增 BucketGroup 流控,新加坡等五地实现100Gbps 默认读吞吐;OSS-HDFS 服务覆盖 8 大海外区域,支持企业出海云上数据分析。