"上云"并非一劳永逸。一次停电、一次攻击、一次配置失误,都可能瞬间导致业务瘫痪。你是否曾想过:如果亚马逊网络服务发生故障,你的服务将何去何从?
本文将系统阐述如何在亚马逊云科技上设计一套高可用、可恢复的灾难恢复(DR)方案。
新用户可获得高达 200 美元的服务抵扣金
亚马逊云科技新用户可以免费使用亚马逊云科技免费套餐(Amazon Free Tier)。注册即可获得 100 美元的服务抵扣金,在探索关键亚马逊云科技服务时可以再额外获得最多 100 美元的服务抵扣金。使用免费计划试用亚马逊云科技服务,最长可达 6 个月,无需支付任何费用,除非您选择付费计划。付费计划允许您扩展运营并获得超过 150 项亚马逊云科技服务的访问权限。
为什么灾备如此重要?
亚马逊云科技明确划分了责任边界:亚马逊云科技负责"云的安全": 包括底层基础设施、物理机、网络和虚拟化层等。你负责"云中安全": 包括数据、账户权限、网络配置和应用架构。因此,亚马逊云科技提供工具,而你需要亲自部署和管理。这通常涉及多区域/多可用区部署 、数据复制 和自动化恢复机制。
灾备是一定要做的!因为:
- 宕机的代价高昂: Gartner 报告显示,IT 宕机平均每分钟损失高达 5600 美元。
- 客户信任流失: 服务不可用直接损害品牌信誉。
- 合规压力: 医疗、金融等行业法规强制要求制定灾备计划。
- 安全威胁不断: 勒索病毒和供应链攻击等安全威胁使 DR 成为企业必备。
四种灾备策略
| 模式 | 恢复时间(RTO) | 数据恢复点(RPO) | 成本 | 场景示例 |
|---|---|---|---|---|
| 1️⃣ 备份与恢复 | 几小时到几天 | 几小时 | 💰 | 存档、非关键业务 |
| 2️⃣ 火种(Pilot Light) | 几分钟到几小时 | 秒级到分钟 | 💰💰 | 核心数据库业务 |
| 3️⃣ 热备(Warm Standby) | 几分钟 | 秒级 | 💰💰💰 | 业务关键系统需快速恢复 |
| 4️⃣ 主动-主动(Active/Active) | 几秒内 | 几乎 0 | 💰💰💰💰 | 金融、电商等关键系统 |
- Amazon Backup: 集中式备份方案,支持时间点恢复和生命周期管理。
- Amazon S3 / Glacier: 对象存储和长期归档服务,成本低廉。
- EC2 AMI / 快照: 创建机器镜像,支持快速恢复。
- CloudFormation: 使用基础设施即代码(IaC)重建完整基础设施环境。
- Route 53: 智能 DNS,可自动切换到健康的区域。
- Elastic Disaster Recovery (DRS): 一键启动备份系统,实现自动化恢复。
- RDS Multi-AZ / Aurora Global: 数据库级故障转移,提供秒级可用性。
- CloudWatch + AWS Config: 监控和合规审计,不放过任何异常。
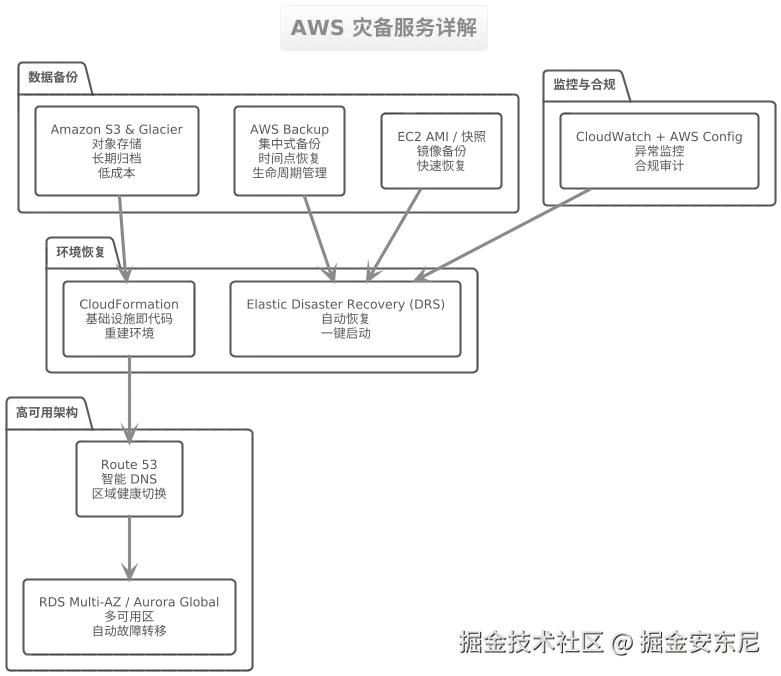
在 亚马逊云科技的灾备体系中,服务之间并不是孤立存在的,而是相互配合,共同支撑起从备份、恢复到监控审计的完整闭环。其中,Backup 提供了一个集中式的备份平台,可以对多个服务统一管理,实现时间点恢复和生命周期策略,从而确保数据在任何时刻都可还原。而这些备份数据常常存储在 Amazon S3 或 Glacier 上:前者适合高频访问的热数据备份,后者则以极低的成本提供长期存储,是归档级数据保护的理想选择。
为了实现计算资源的快速恢复,Amazon EC2 AMI 与快照 扮演了关键角色。通过创建完整的机器镜像或卷快照,即便主实例宕机,也能在极短时间内重建环境。而要真正做到"还原即上线",就离不开 Amazon CloudFormation 所提供的基础设施即代码(IaC)能力。它通过模板化方式定义和部署整个架构,让灾后重建不再依赖人工操作,而是自动、规范、可复制。
在网络层面,Route 53 作为智能 DNS 服务,可以基于健康检查自动切换到备用区域,确保流量永远指向健康节点。而在真正发生灾难时,Elastic Disaster Recovery (DRS) 可以一键启动备份系统,实现应用级别的恢复流程自动化,大幅缩短业务中断时间(RTO)。
数据库是灾备中的重中之重。亚马逊云科技提供了 RDS Multi-AZ 和 Aurora Global Database 两种数据库高可用方案,实现主从自动复制与秒级故障切换,为业务提供强有力的数据保障。而所有这些灾备组件的运行状态与合规性,都需要依赖 CloudWatch 与 Config 来持续监控与审计。前者提供实时指标与告警机制,后者追踪所有资源的配置变更,是确保灾备体系稳定运行的"哨兵"。
综上所述,亚马逊云科技并不只是提供一套备份工具,而是打造了一整套端到端的灾难恢复生态,从数据、计算、网络到数据库和监控,每一个环节都有对应的服务支撑。企业所要做的,就是因需而选,合理组合,构建出真正适合自己的"高韧性云架构"。
实战:Web 应用的 DR 架构
- 定义目标: 明确 RTO(恢复时间目标)和 RPO(恢复点目标),即你能容忍多久的停机时间和多少数据丢失。
- 识别关键组件: 确定业务中最重要的部分,例如数据库、存储和 API 服务等。
- 选择灾备策略: 根据业务影响程度选择最适合的灾备模型。
- 构建弹性架构: 利用多个可用区和跨区域数据复制来增强系统韧性。
- 自动化恢复流程: 利用 Amazon CloudFormation、Route 53、DRS 等服务实现恢复流程的自动化。
- 定期演练: 切勿等到灾难发生时才测试,务必进行"灾备演习"。
- 监控与审计: 使用 Amazon CloudWatch 告警和 Config 记录变更,确保一切正常。
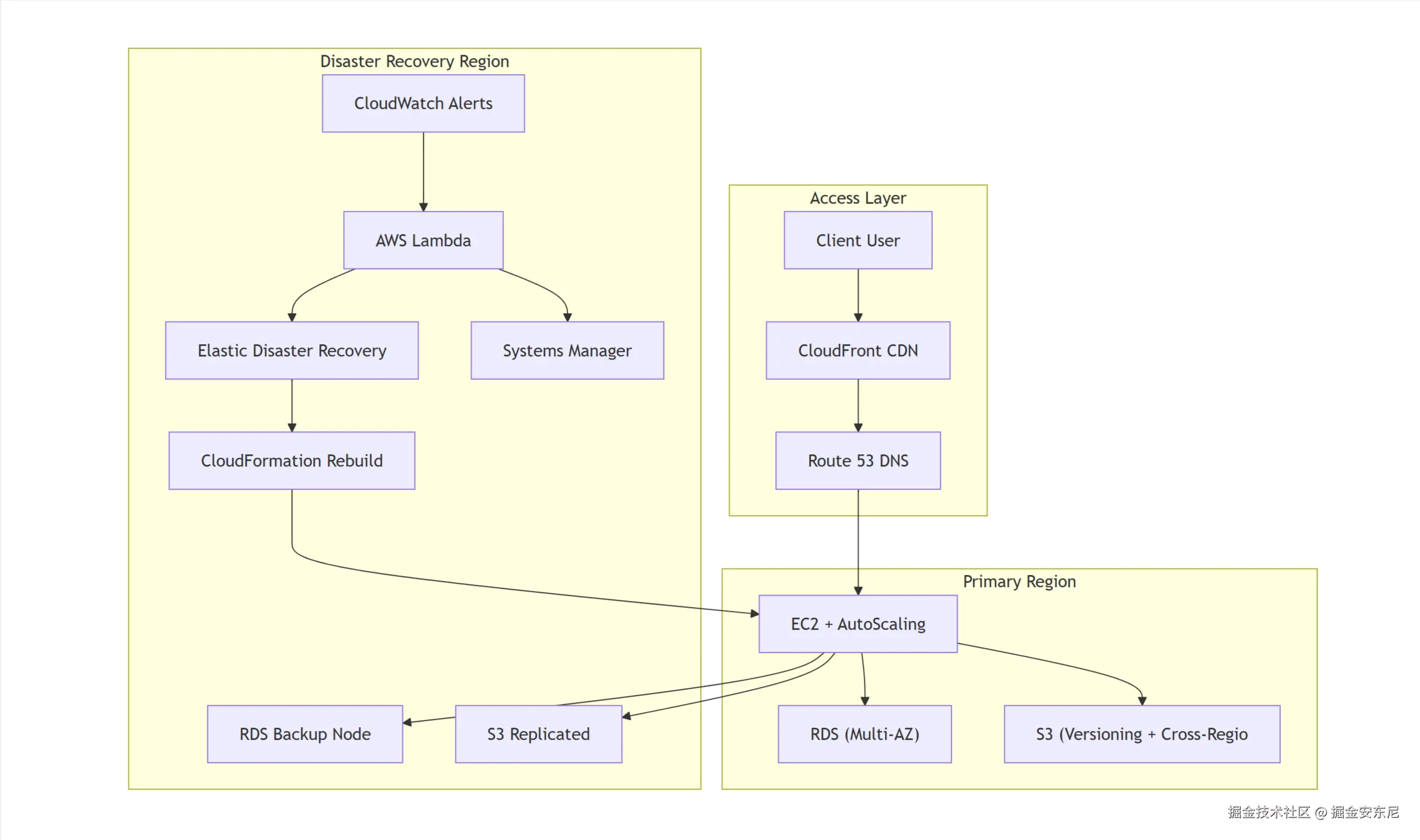
在灾备策略落地的过程中,最具参考价值的莫过于实际架构案例。以一个典型的 Web 应用为例,我们可以看到如何在各个层面支撑其高可用与快速恢复能力。
这个应用的前端部署在Amazon EC2 上,并通过 Auto Scaling 组实现自动伸缩,确保访问流量增长时依然具备弹性承载能力。后端使用 Amazon RDS,并启用 Multi-AZ 配置,使数据库在主节点故障时可以自动切换到备用节点,最大程度保障数据服务连续性。静态资源如图片、脚本等托管在 Amazon S3 上,配合 Amazon CloudFront 实现全球加速,让用户无论身在何处都能获得低延迟体验。DNS 由 Route 53 托管,通过健康检查与延迟路由策略,将用户请求始终引导到最健康、响应最快的区域节点。
这个架构背后的灾备关键点也非常清晰。
首先,Amazon EC2 实例会定期创建 AMI 快照,以便在故障发生后快速还原计算环境;Amazon S3 开启了版本管理与跨区域复制,保证静态资源在任意区域都可备份恢复;数据库层面,RDS 不仅配置了多可用区,还定期进行快照备份,为极端情况下的数据恢复提供保障。
同时,整个基础设施的部署流程已被封装进 Amazon CloudFormation 模板中,一旦灾难发生,只需一键即可重建完整环境。Route 53 的延迟路由机制也确保了 DNS 层面的智能切流能力,能将用户请求从主区域自动引导至备用区域。
当真正进入灾难恢复阶段,一整套自动化流程将迅速启动。Amazon Elastic Disaster Recovery 负责唤醒预设好的备份系统,几乎在秒级完成服务上线;CloudFormation 模板重建应用所需的全部资源,确保架构与主环境一致;Route 53 则自动更新 DNS 记录,将流量平滑切换到新部署的区域。Amazon Lambda 在其中扮演着"调度中枢"的角色,按顺序执行各项恢复任务;而 Systems Manager 会触发 Runbook,执行一系列恢复指令,实现业务恢复的标准化与自动化。
整个过程中,Amazon CloudWatch 提供全方位指标监控与异常告警,确保团队能够及时掌握系统状态,提前干预潜在风险。
通过这样一套"分层部署、全面备份、自动恢复、实时监控"的架构,即使面对意外宕机、区域故障甚至重大灾难,这个 Web 应用依然能保持高可用与快速恢复能力,体现了现代云灾备体系的真正价值。
结语
以上就是本文的全部内容啦。最后提醒一下各位工友,如果后续不再使用相关服务,别忘了在控制台关闭,避免超出免费额度产生费用~
灾备不是可选项,而是刚需。关键在于:你是否主动规划?是否定期演练?是否真正落实到业务场景?
别等灾难发生后才后悔。现在就开始,设计你的 Amazon 灾备方案!