1.现象
当我们操作一个线程池的时候,可能需要去计数,也就是统计count,那我们这里有一个疑问,会不会产生线程安全问题?
毫无疑问绝对会有线程安全问题 。在线程池环境中,多个线程并发访问和修改一个共享的 count 变量(例如通过 count++ 或 count = count + 1),如果不加锁或使用其他同步机制,会导致结果不可预测和不正确。
2.就像我们现在的这样
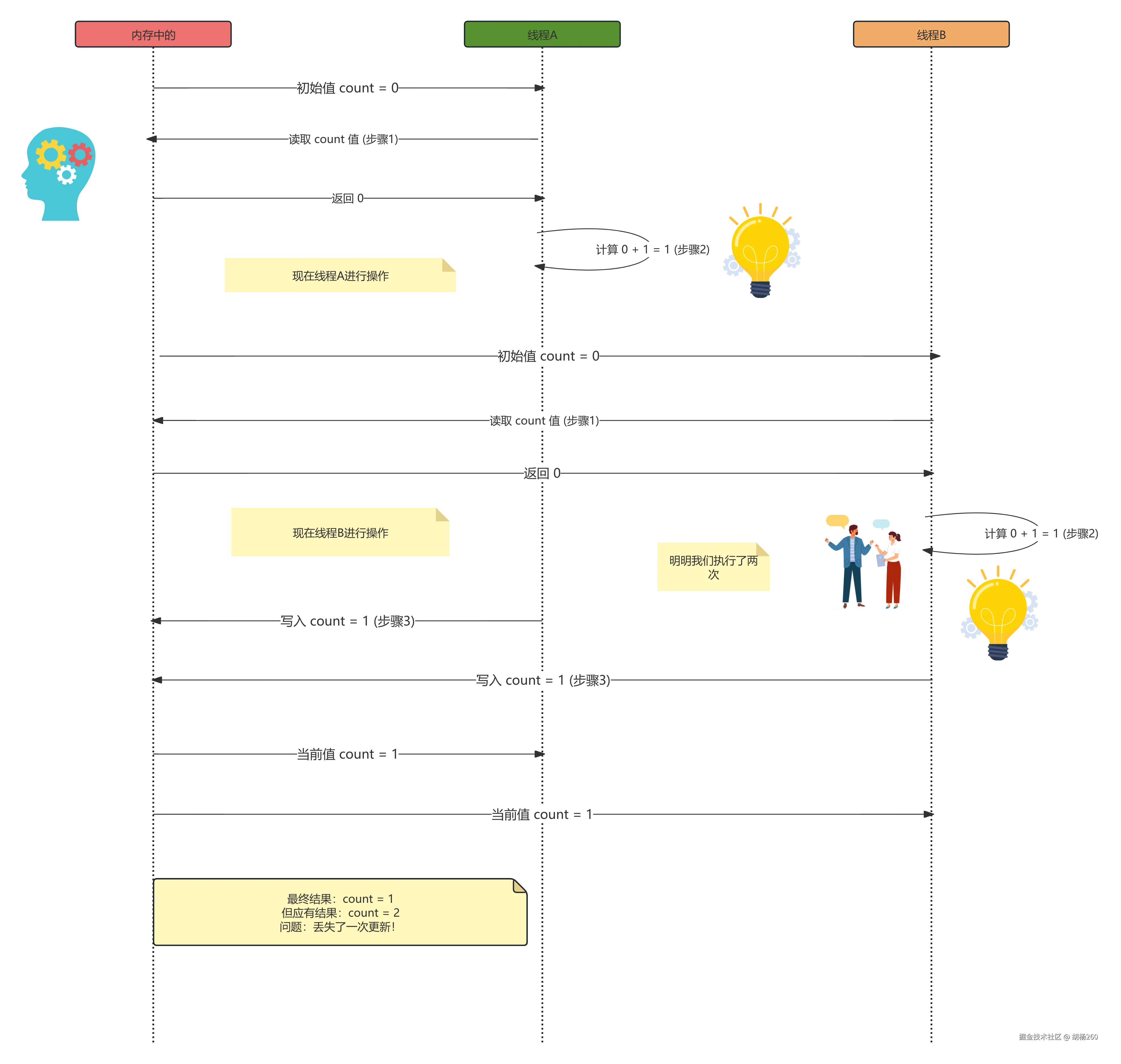
根本原因分析:
- 非原子性 :
count++操作被拆分为 3 个独立步骤 - 时间窗口:在读取和写入之间存在竞争窗口期
- 缺乏可见性:线程 B 看不到线程 A 的中间结果
- 写覆盖:后写入的线程覆盖了前一线程的结果
原因如下:
-
非原子性操作 (
count++):- 像
count++这样看似简单的操作,在底层通常需要多个步骤:- 读取 :从内存中读取
count的当前值到线程的寄存器或本地缓存。 - 修改:在寄存器/缓存中将读取到的值加 1。
- 写入 :将修改后的新值写回内存中的
count变量。
- 读取 :从内存中读取
- 这些步骤本身不是原子操作 (不可分割的操作)。多个线程完全有可能交错执行这些步骤。
- 像
-
竞争条件 (Race Condition):
- 假设
count初始值为 0。 - 线程 A 执行步骤 1,读取到
count = 0。 - 线程 B 执行步骤 1,也读取到
count = 0(因为线程 A 还没来得及写回)。 - 线程 A 执行步骤 2,计算
0 + 1 = 1。 - 线程 B 执行步骤 2,计算
0 + 1 = 1。 - 线程 A 执行步骤 3,将
1写入count,内存中count变为 1。 - 线程 B 执行步骤 3,将
1写入count,内存中count还是 1(覆盖了线程 A 的结果)。 - 结果 :两个线程都执行了
count++,但最终count的值是 1 而不是预期的 2。这就是经典的"丢失更新"问题。
- 假设
-
可见性问题 (Visibility):
- 现代 CPU 架构拥有多级缓存(L1, L2, L3)。每个线程可能在自己的 CPU 核心的缓存中操作
count的副本。 - 当一个线程修改了它缓存中的
count值,这个修改不会立即对其他线程的缓存可见。 - 线程 B 可能仍然看到
count的旧值(比如 0),即使线程 A 已经把它加到了 1(但新值还在线程 A 的缓存里,没刷回主内存或线程 B 的缓存没更新)。 - 这也会导致线程 B 基于过时的值进行计算,最终结果错误。
- 现代 CPU 架构拥有多级缓存(L1, L2, L3)。每个线程可能在自己的 CPU 核心的缓存中操作
后果:
- 最终
count的值会小于 实际所有线程执行count++操作的次数总和。丢失更新的次数越多,差距越大。 - 程序行为不可预测,结果每次运行都可能不同(取决于线程调度的时机)。
3.如何解决?
必须使用同步机制来保证对 count 的访问和修改是原子性 的,并且修改对其他线程是可见的:
-
使用
synchronized关键字 (锁):javaprivate int count = 0; private final Object lock = new Object(); // 专门用作锁的对象 public void increment() { synchronized (lock) { // 获取锁 count++; // 在锁保护的临界区内安全地递增 } // 释放锁 }- 优点:简单直观,适用于复杂的同步逻辑。
- 缺点:性能开销相对较大(获取/释放锁、线程阻塞/唤醒)。
-
使用
ReentrantLock:javaprivate int count = 0; private final ReentrantLock lock = new ReentrantLock(); public void increment() { lock.lock(); // 显式获取锁 try { count++; } finally { lock.unlock(); // 确保在finally块中释放锁 } }- 优点:比
synchronized更灵活(如可尝试获取锁、可中断锁、公平锁等)。 - 缺点:需要手动管理锁的获取和释放,否则容易死锁;性能开销与
synchronized接近或略优/劣(取决于场景和 JDK 版本)。
- 优点:比
-
使用原子类 (
java.util.concurrent.atomic) - 强烈推荐用于计数器:javaprivate final AtomicInteger count = new AtomicInteger(0); public void increment() { count.incrementAndGet(); // 原子地递增并返回新值 // 或者 count.getAndIncrement(); // 原子地递增并返回旧值 }-
优点:性能最高!底层使用 CPU 提供的 CAS (Compare-And-Swap) 指令实现无锁并发。特别适合简单的计数器场景。
-
缺点:只能用于特定的原子操作(递增、递减、加法、比较并设置等)。对于需要保护多个变量或复杂逻辑的复合操作,原子类可能不够用,需要用锁。
解决方案对比:
方法 原理 性能影响 适用场景 synchronized 互斥锁 高 (上下文切换) 复杂同步逻辑 AtomicInteger CAS 指令 低 (CPU 原语) 简单计数器 ReentrantLock 可重入锁 中 (优于 synchronized) 需要灵活控制的场景 -
4.结论:
在线程池(或任何多线程环境)中,对共享可变状态(如你的 count)进行并发修改,必须 使用适当的同步机制(锁或原子类)。不采取任何同步措施必然会导致线程安全问题,使 count 的值不可靠。
对于简单的计数器场景,优先考虑 AtomicInteger 或 AtomicLong,它们提供了最佳的性能和简洁性。