近年来,随着 AI 和大模型技术的发展,向量数据在各个领域的应用日益广泛。如何高效地存储、索引和查询向量数据,已成为一个重要的挑战。
Databend 作为一款云原生的 OLAP 数据库,也在积极拥抱向量数据。在「Data Infra 研究社」第 27 期活动中,我们邀请到 Databend 数据库研发工程师白珅,带来主题为**「Databend 向量索引:加速AI应用的数据引擎」的深度分享。重点介绍 Databend 最近开发的向量数据类型和向量分析技术,帮助用户深入了解 Databend 在向量数据处理方面的能力。
一、向量索引的实践与性能优化
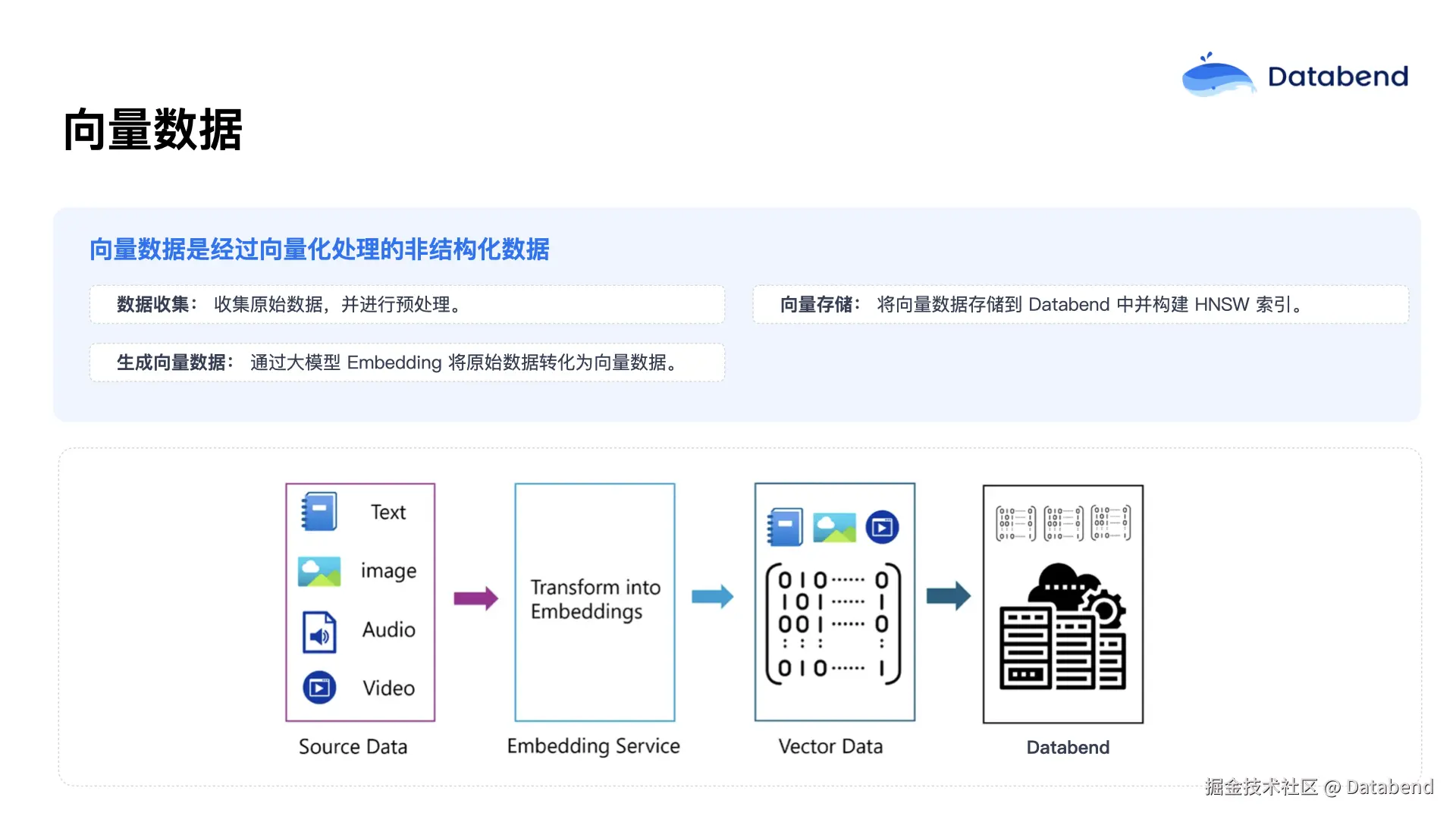
向量数据是将非结构化数据经过 embedding 向量化处理后得到的一种数据。非结构化数据包括图像、视频、文本、音频等,这些数据不像传统表格数据那样规整,而是以更加自由、多样化的形式存在,蕴含着巨大的价值。例如,通过分析用户的浏览记录和购买行为,我们可以构建更为精准的推荐系统。
为了将这些非结构化数据转化为计算机可处理的形式,通常需要使用大模型对数据进行处理,将其转换为数字化的向量。这些向量能够捕捉原始数据的各个维度信息,为后续分析和应用奠定基础。然而,传统数据库主要针对结构化数据设计,对于向量数据的处理能力有限,无法高效地存储和索引。为满足新需求,越来越多的数据库开始支持向量数据,并通过索引技术加速相关查询。Databend 同样支持向量数据,能够实现高性能的检索。
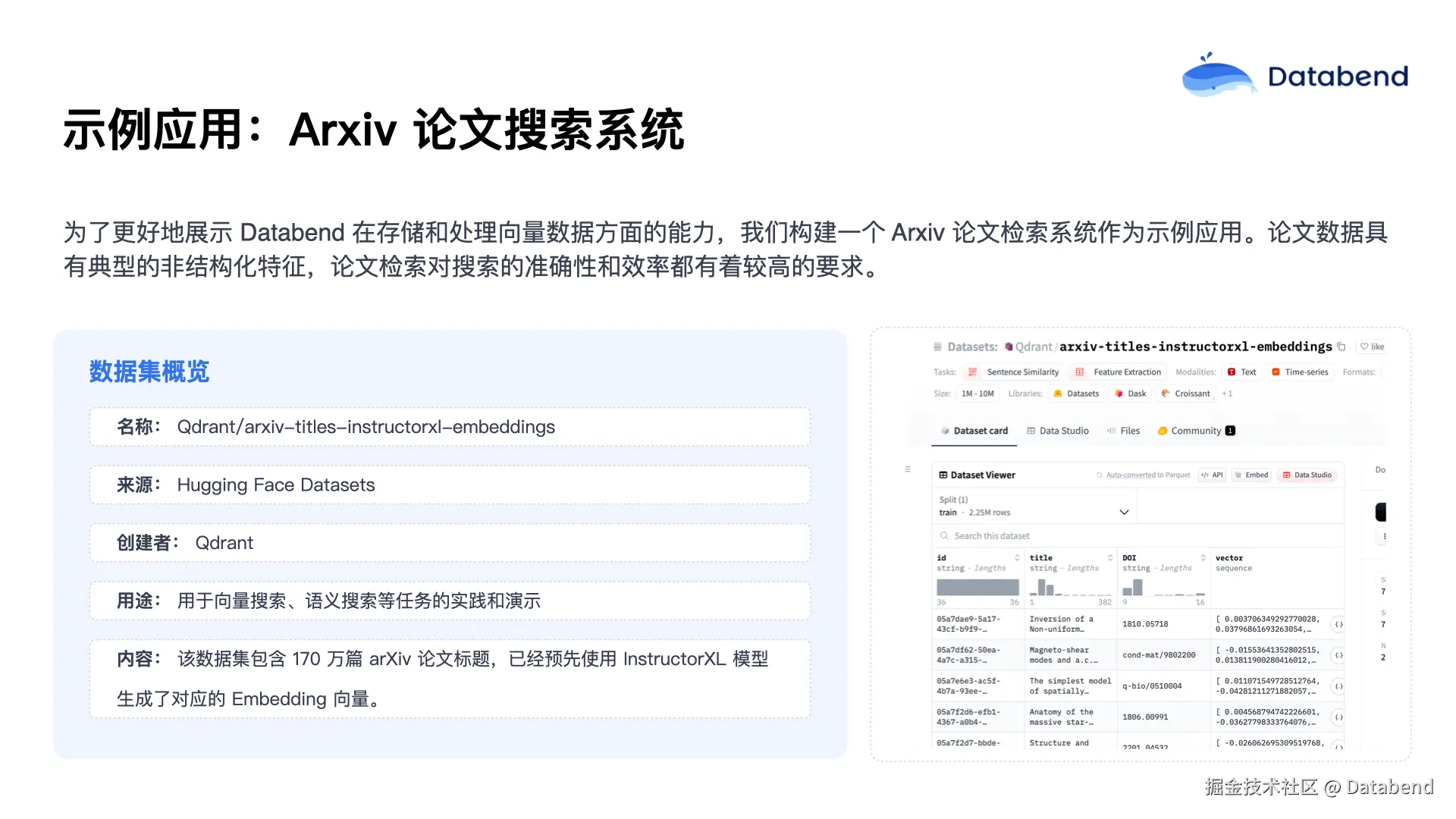
下面通过一个 Arxiv 论文检索系统的示例应用,展示 Databend 在向量数据存储和处理方面的能力。之所以选择论文检索系统,是因为其数据具备典型的非结构化特征,论文的标题和摘要都是文本,需要经过 embedding 技术转换成向量数据。同时,论文检索对搜索的准确性和效率要求很高,能够充分体现向量索引技术的优势。
这里选用了一个公开的数据集------托管在 Hugging Face Datasets 的 arxiv-titles-instructorxl-embeddings 数据集,包含 170 多万篇论文的标题,并已通过训练生成了对应的向量,可直接用于存储和查询,无需额外 embedding 处理。这让我们可以更专注于向量数据存储和检索能力的展示。

构建该搜索系统主要分三步:
第一步、表结构设计。 得益于 Databend 原生支持向量类型,我们可以直接将向量数据定义为 vector 字段,同时增加如 ID、title 等描述性字段,以提升数据可观测性。此外,还需要选择合适的索引类型,并通过参数调优优化性能。

在表结构设计中,我们首先定义了一个 ar``x``iv``_``titles 的表,用于存储论文标题及对应向量数据,字段主要包括 ID、title 和 vector(向量),vector 是 128 维。这个表是用于测试的,未加索引,主要用于对比。
第二个表是 arxiv_titles_idx。结构与第一个表类似,但增加了向量索引,并设置了如 M、ef_construct 等参数,具体含义后面会详细说明。
第二步、数据导入。 由于我们已经有了预先 embedding 好的向量数据,因此可以直接批量导入。 Databend 支持多种导入方式,包括 COPY INTO、INSERT 等语法。

数据导入流程如下:首先创建一个 stage。Databend 中的 可以理解为数据存放区,既可以是本地文件系统,也可以是像 S3 这样的云平台,或者这里用到的 Hugging Face。通过 stage,能够高效地将外部数据读取到 Databend 中,非常适合大规模数据集。
创建好 stage 后,可以通过 INSERT 和 SELECT 语句,将 stage 中的 Parquet 文件读取出来,再分别导入到两个表中。
第三步、实现相似度搜索和应用。 用户查询词会先转换为向量,然后利用 Databend 的向量索引大幅缩短查询时间,最终将查询结果与上层应用结合起来。
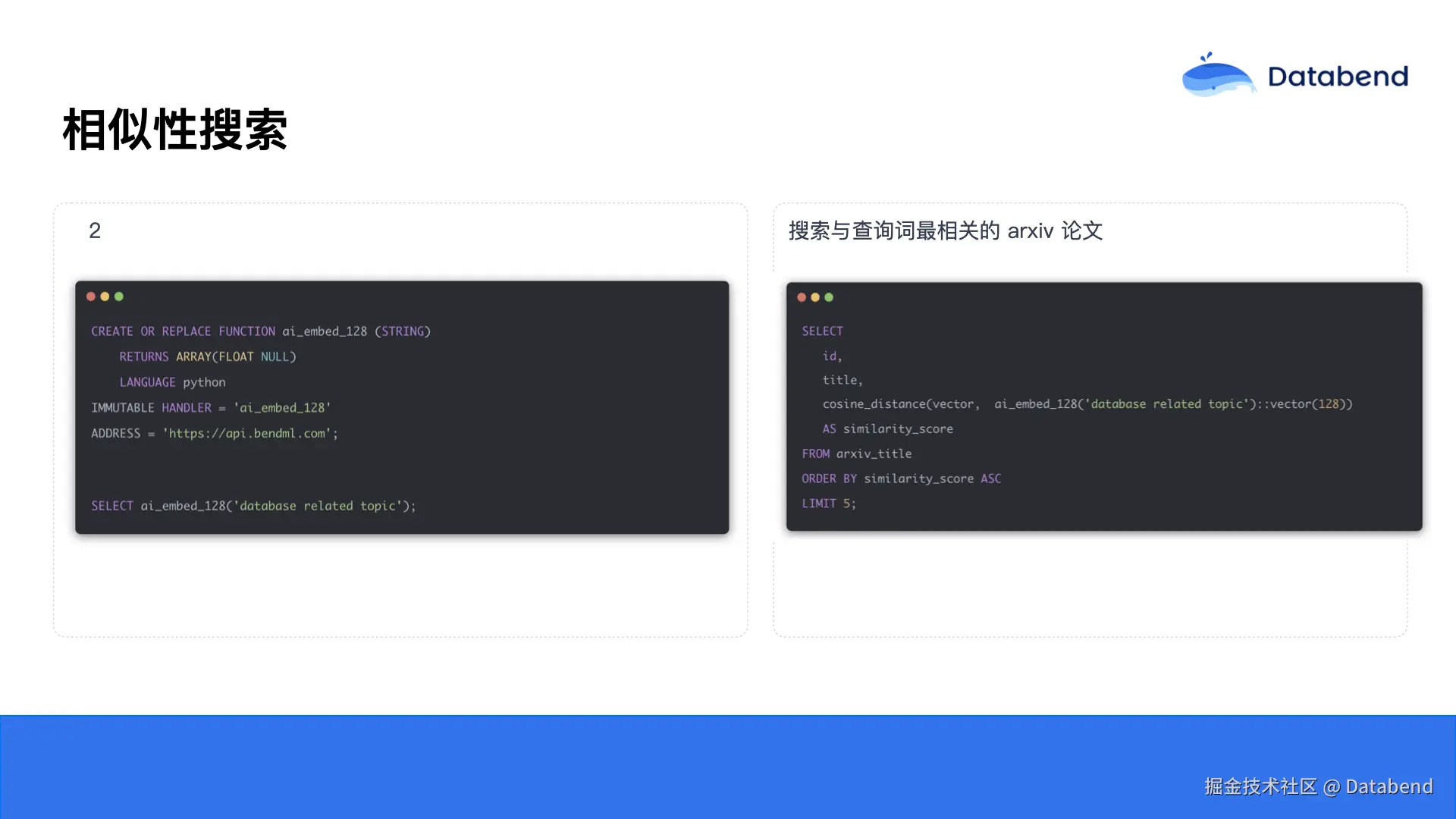
首先需要创建一个 UDF(用户自定义函数)。Databend 的 UDF 允许用户自定义,像使用内置函数一样,在 SQL 中扩展所需功能。由于Databend本身还未内置 embedding 的函数,因此我们自定义了一个 ai_embed_128 的 UDF,实现将文本转化为128维向量,具体实现调用了外部的 embedding 服务。
接下来就是核心的查询语句。我们使用 SELECT 语句在arxiv_titles 表中查询相关数据,通过 cosine 函数计算向量与用户查询词之间的距离并排序,最终返回最接近的五条记录。
下面是在 Databend Cloud 中的演示效果:

测试结果中,未加索引的表在查询时通常耗时都在一秒以上,大约 1.3s 左右。而加了索引后是 200ms,差距为 6 倍。此外,我们还对写入性能进行了测试。由于加索引会同步写入索引数据,写入耗时也有所增加:无索引时写入约需20秒,带索引时则增加到120秒。尽管写入速度变慢,但在实际业务中,查询的频率通常远高于写入,因此这一牺牲是可以接受的。
二、向量数据类型介绍

为什么需要向量?
由于计算机只能理解数字,而人类交流主要依赖于文本、图像、音频等丰富的信息,这些数据存在大量歧义和复杂的上下文。如果没有合适的向量类型,计算机很难理解和处理这些非结构化数据。向量数据正好充当了桥梁,把人类复杂的信息转化为计算机能够处理的数字空间,从而让机器能够"理解"人类的信息。
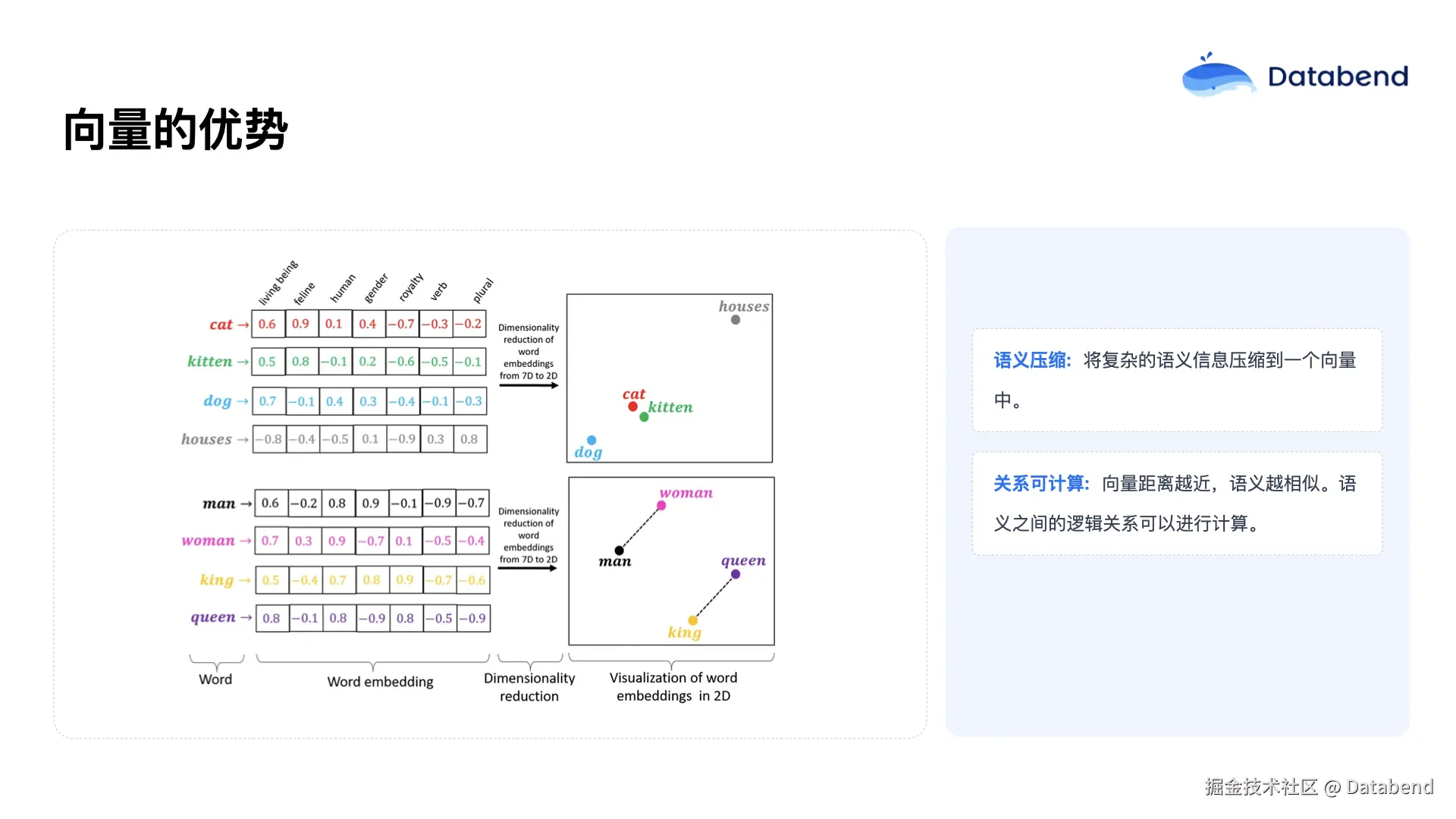
使用向量主要有两个主要优势:
- 第一,向量能够对语义进行压缩。例如,文本信息经过向量化后可以转换为固定长度的向量。以图中示例为例,像 cat、kitty、dog、house 这些词汇都可以通过向量处理变成七维向量,去除原始数据中的冗余信息,仅保留关键特征。
- 第二,向量化之后,数据之间的关系可以用数学方法进行量化。我们可以通过向量之间的距离来判断相似性。例如,在示意图中,cat 和 kitty 的距离比 dog 要近,这反映了语义上的接近性。此外,像 man 和 woman、king 和 queen 这两组词,其向量间的距离也类似,说明它们在语义空间中具有一定的对应关系。
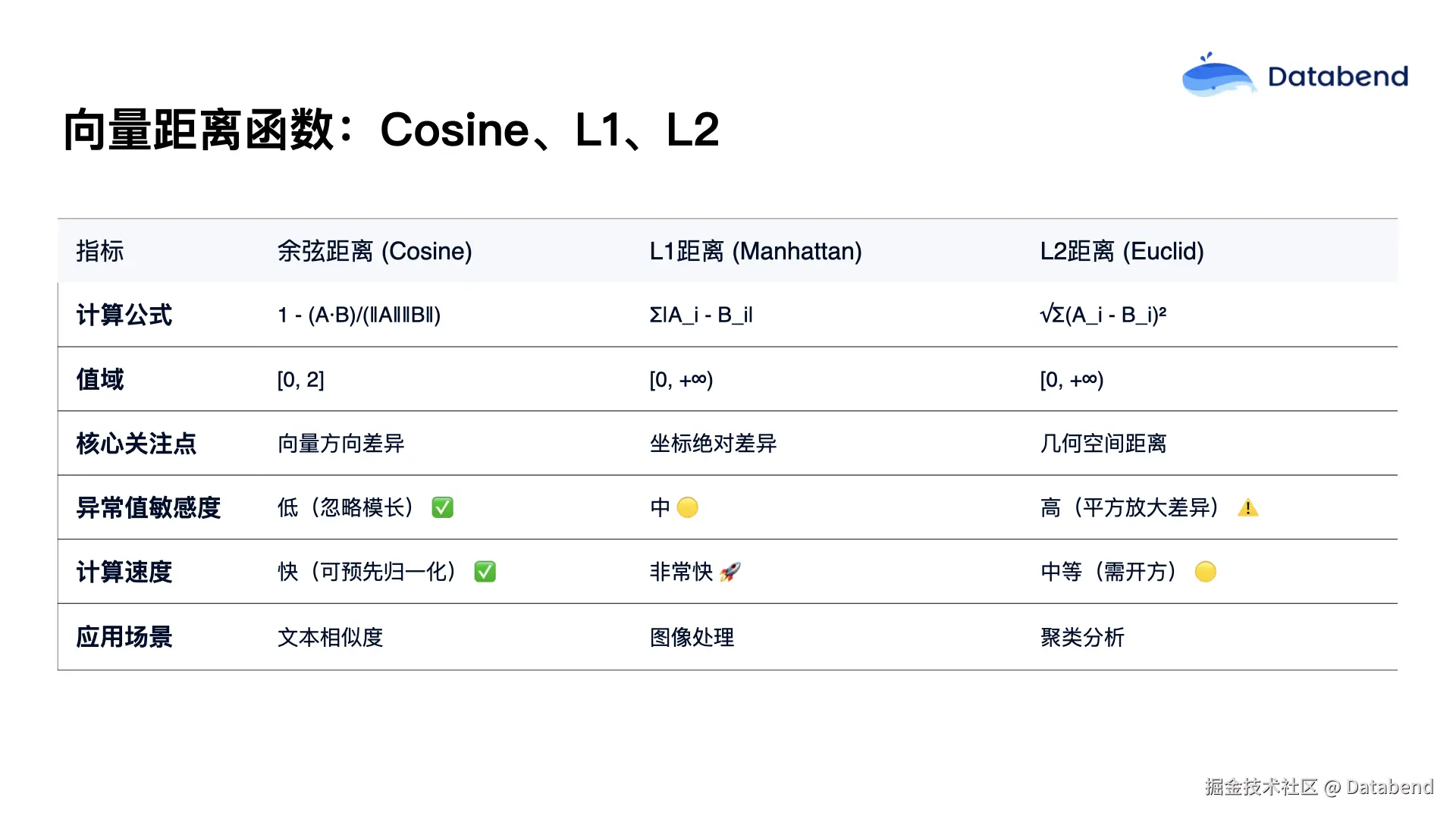
前面我们介绍了距离的计算方式。实际应用中,常见的距离函数有三种:余弦距离(cosine)、L1 距离和 L2 距离。三者的主要区别在于计算公式不同,适用场景也有差异。一般来说,如果数据是高维且稀疏,并且只关注向量的方向,则适合用余弦函数;如果数据稠密,只需要计算向量的直线距离,L2 距离更合适;若数据中包含较多异常值、各维度差异较大,则 L1 距离更为合适。实际应用中,可根据具体场景进行选择和调优。
三、向量索引原理:HNSW 算法详解
随着 AI 技术普及和各类 AI 应用涌现,向量数据量呈现爆发式增长。在海量数据中做相似性搜索,如果不使用索引,只能进行暴力搜索------即对每一条向量都计算一次距离,这种方式效率极低、计算复杂度高,耗时严重。数据量越大,查询时间可能达到几秒甚至十几秒。
许多实际场景如推荐系统、图像搜索等对响应时间有极高要求,需要毫秒级的实时反馈,暴力搜索显然无法满足需求。使用索引则能大幅提升检索效率。例如,Spotify 开源的向量搜索库 Voyager,用于音乐推荐系统后,检索性能提升了 10 倍,同时内存消耗减少了4倍,充分说明向量索引在实际中的巨大价值。

HNSW,全称"Hierarchical Navigable Small World graph " (分层可导航小世界图),源自 2016 年的一篇论文。这一算法已成为向量检索领域的核心参考,大多数主流向量索引实现都基于此论文。如果大家感兴趣,可以在 arXiv 等网站上查阅原文。
HNSW 主要包含两项关键技术:
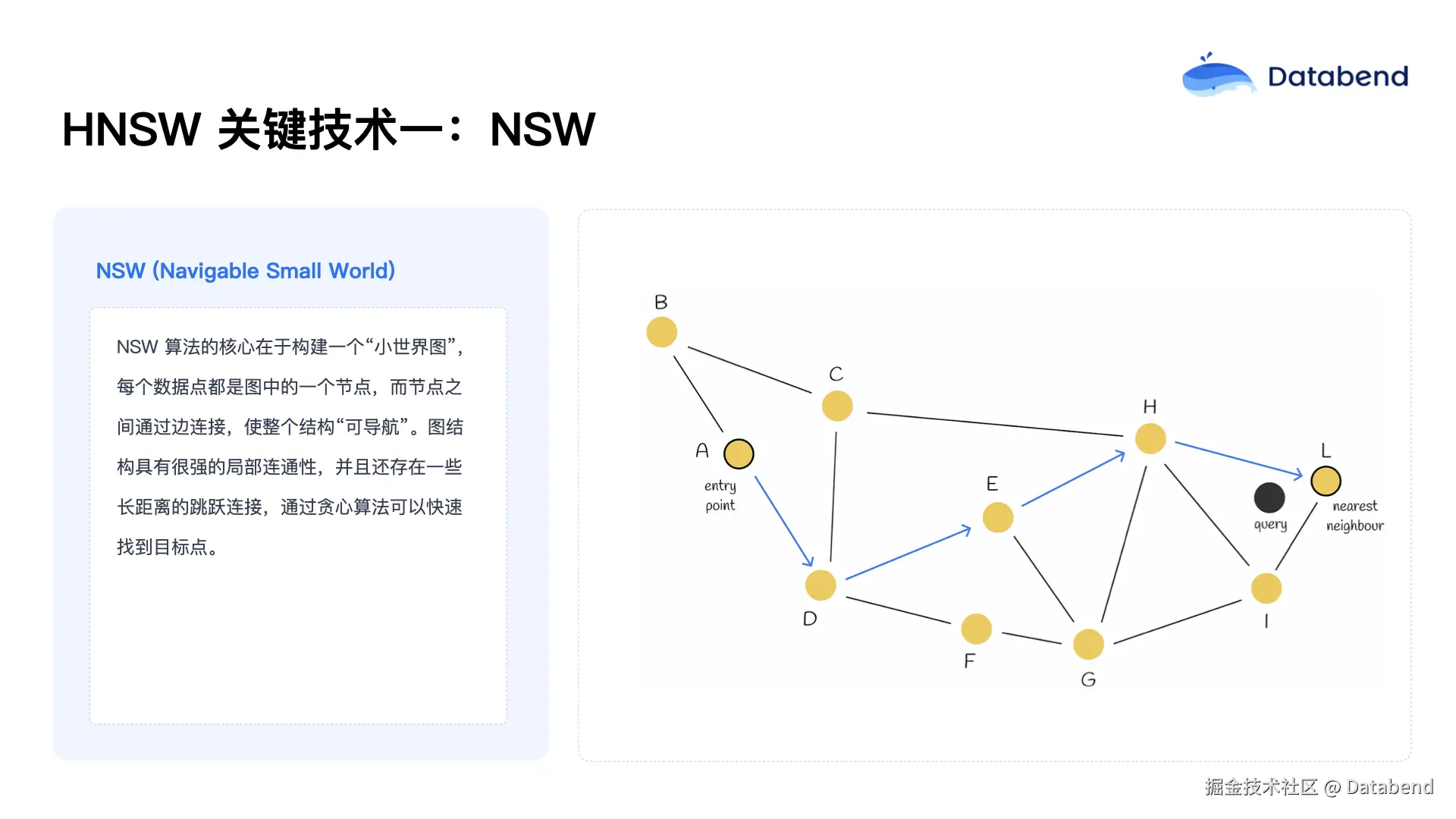
第一,NSW(Navigable Small World) ,即小世界图结构,每个数据点是一个节点,节点之间通过边相连,形成可导航的网络。查询时,可以从任意节点出发,沿着最短路径逐步靠近目标。例如,从点a出发,比较其相邻点b和d与目标的距离,选择更近的d,然后继续比较d的邻居,依次前进,最终找到最接近目标的点。
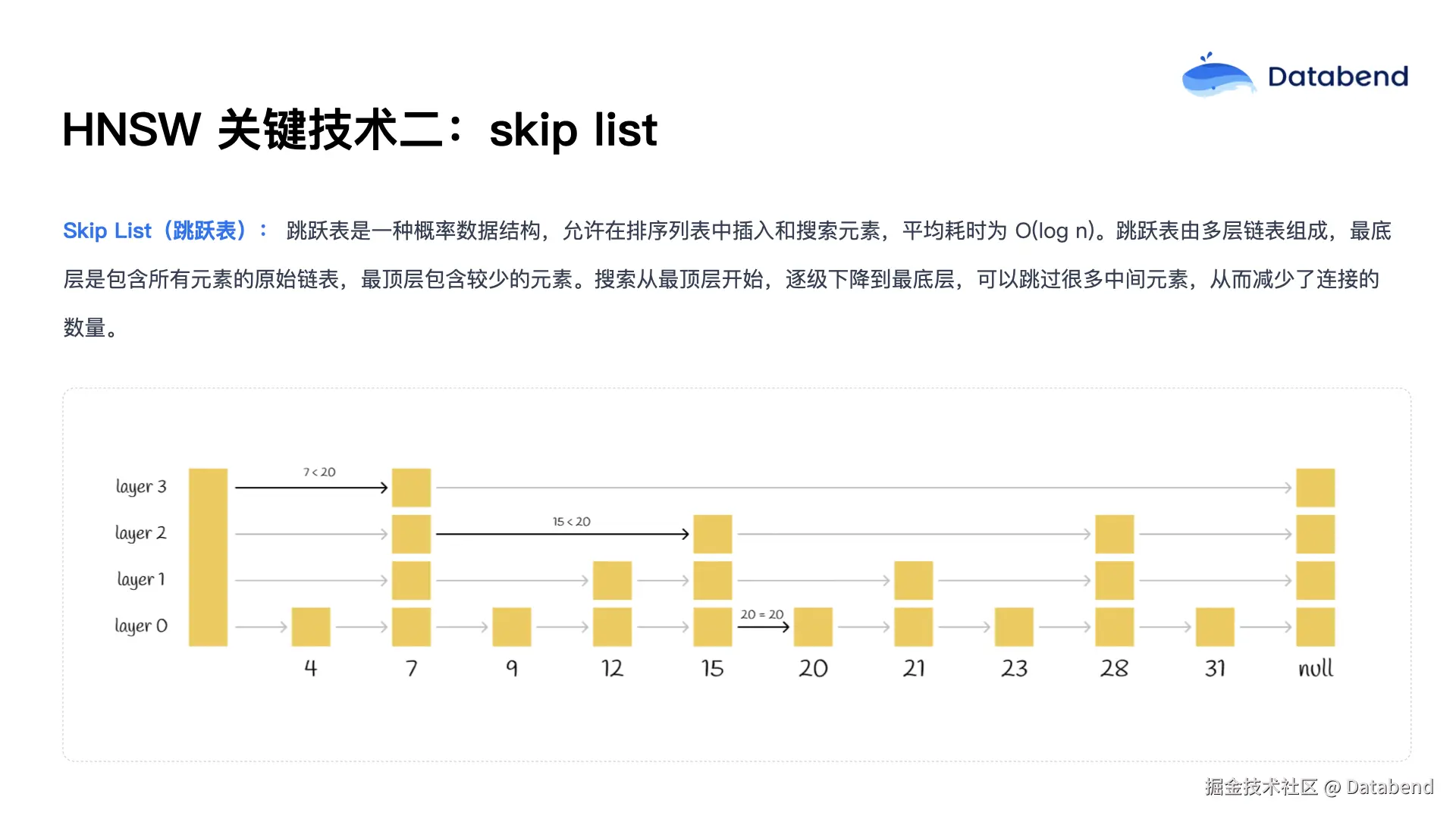
第二项技术是 跳表 ( Skip List ) ,引入了分层结构。最底层包含所有原始数据,越往上每层包含的数据越少,最顶层仅有极少数抽样节点。检索时,从顶层开始,逐层向下缩小范围,大幅减少搜索路径。比如在查找 20 这个数时,从第三层仅需遍历 3 个节点,而若从最底层遍历则要经过 6 个节点,分层结构显著提升了检索效率。
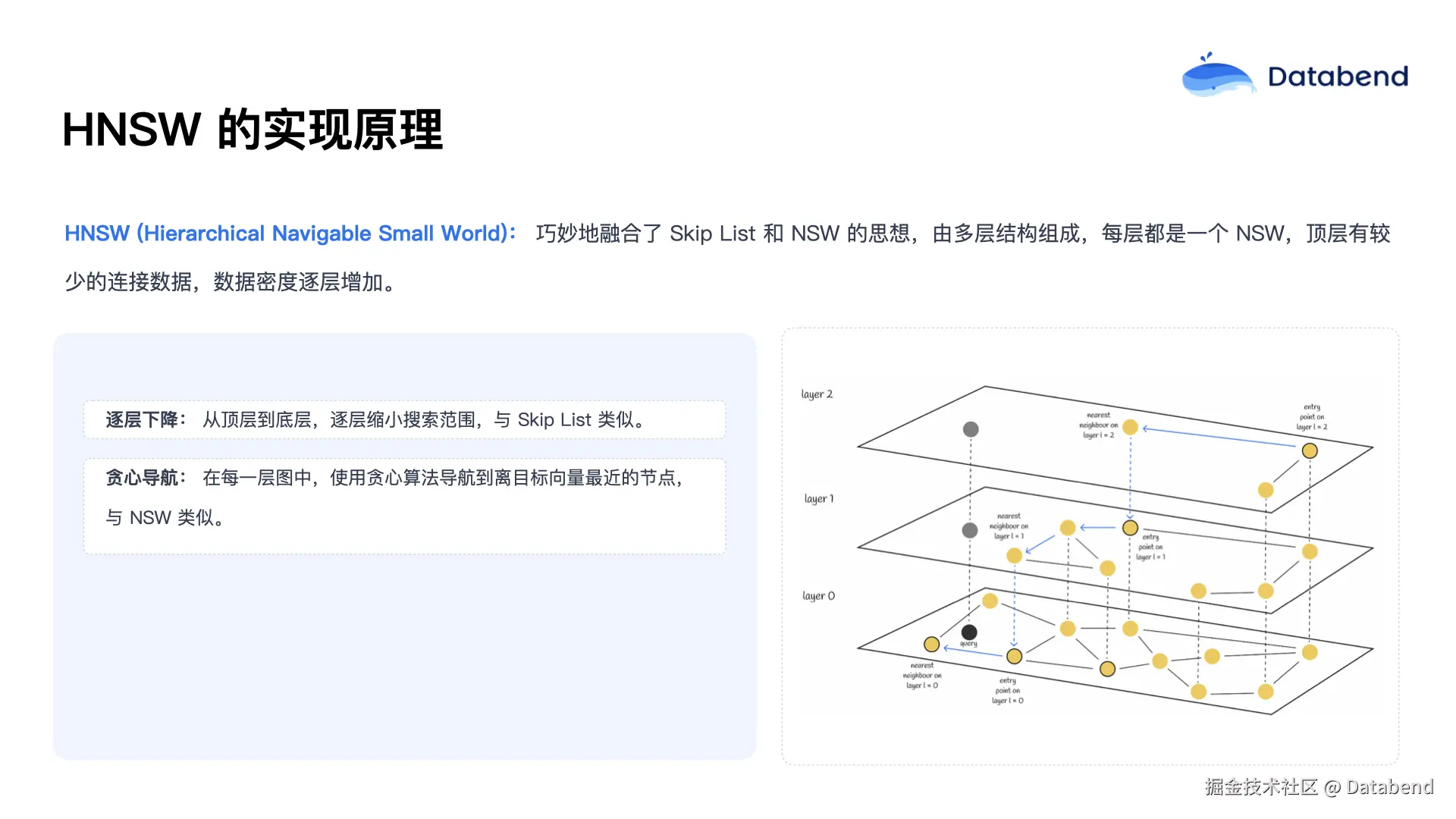
HNSW 融合了这两种技术的优点,通过多层的小世界图,每一层都是一个独立的 NSW 结构。搜索时从顶层开始,快速筛选最接近的节点,然后逐层下降,最终定位到最优解。这一机制保证了极高的检索性能。
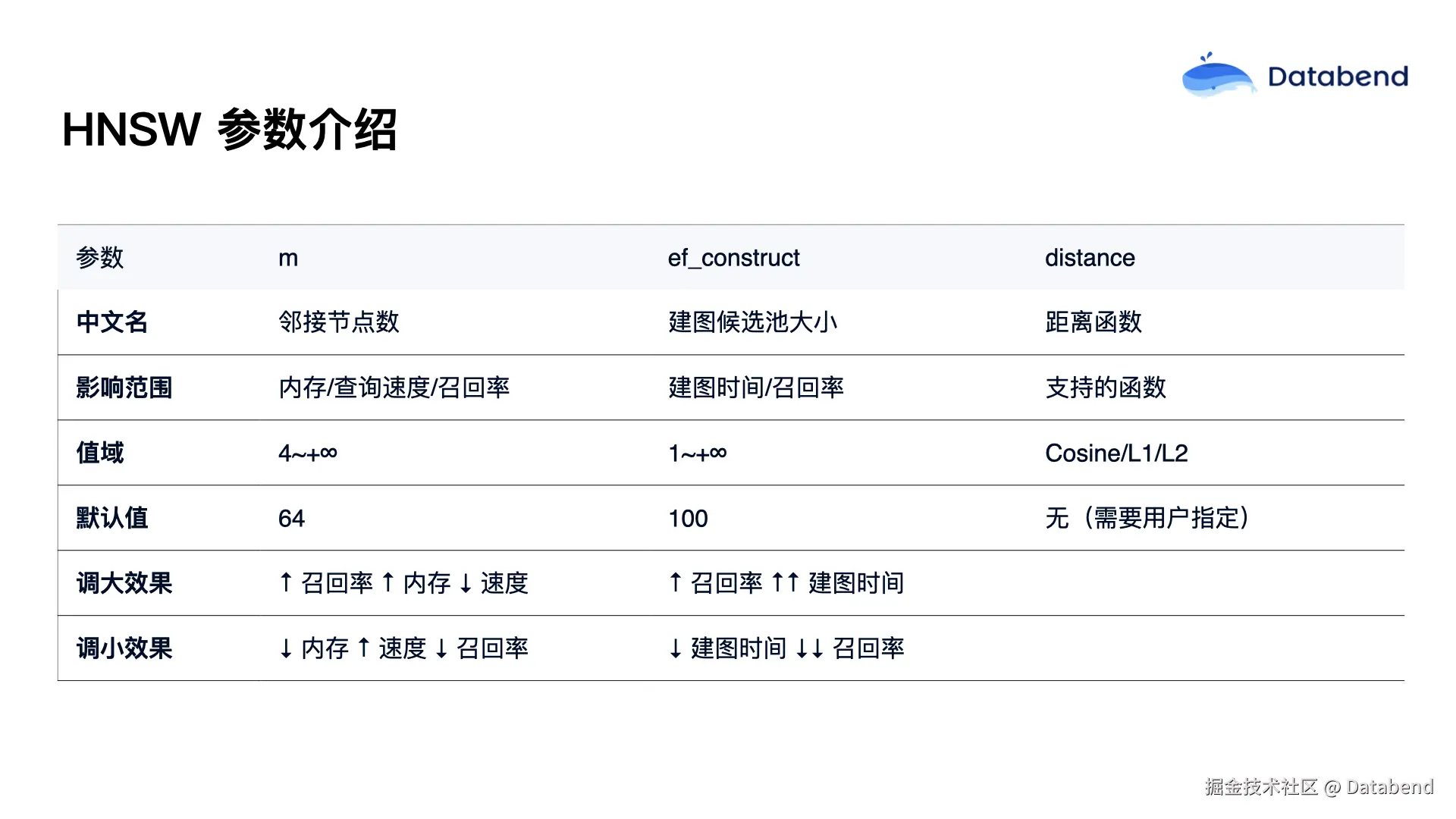
HNSW 中有几个重要参数:
- M: 表示每层中每个节点允许的最大连接数,M 越大邻居越多,连通性越好,能加快检索速度,但同时会增加内存消耗和索引构建时间;
- ef_construct: 主要控制索引构建过程中搜索范围,值越大检索效果越好,但构建时间也会相应增长;
- distance: 即距离计算函数(如cosine、L1、L2等),可以按需选择和构建,减少不必要的计算。实际应用中,这些参数需根据具体数据和场景调优,以实现最佳效果。
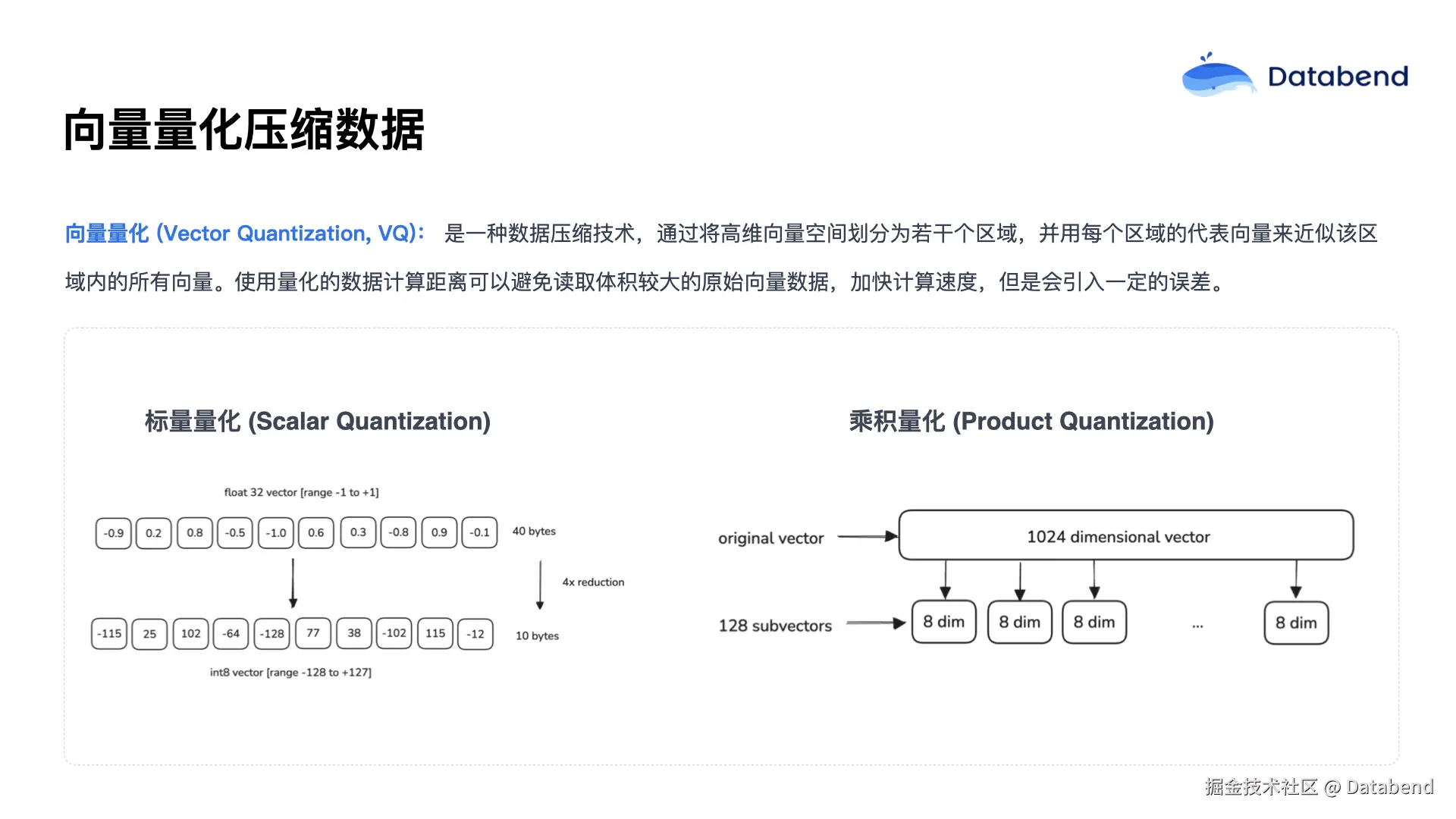
接下来介绍一项关键的向量压缩技术------向量量化。向量量化的主要目的是对原始向量数据进行压缩。因为在索引和检索的过程中,需要频繁计算查询向量与原始向量之间的距离。如果每次都读取全部原始数据,将导致数据读取量过大,影响查询效率。为了减少数据体积、提升检索速度,我们通常会对原始向量进行量化压缩处理。
常用的量化方法有两种。
第一种是 标量 量化(Scalar Quantization)。其原理是将原始向量数据从 float32 类型转换为 int8 类型。由于 float32 占用 4 个字节,而 int8 只占 1 个字节,因此经过这种转换后,数据体积可以缩小 4 倍。
第二种是 乘积量化(Product Quantization)。这种方法是将一个高维的向量拆分成多个低维子向量,对每个子向量分块后,取其聚类中心的平均值,再由这些均值组成新的紧凑向量。这样不仅可以极大地压缩数据体积(子块数目可以根据需求灵活调整),也能显著减少内存占用。但与此同时,数据压缩后不可避免地会引入一定误差。

向量索引可以对大规模向量数据进行预处理,构建高效的检索结构,从而大幅加速搜索过程。当然,向量索引并非万能,也有一些局限,因此在实际应用中需要充分理解其优缺点,合理选型。
其主要优点有两个。第一是查询速度极快,相较于暴力查询,向量索引通常能够将检索速度提升数个数量级,实现近乎实时的相似性搜索。正因为有了高性能的索引技术,才使得诸如推荐系统、视频和图像检索等智能应用成为可能。
但向量索引也存在一些缺点。首先,使用索引会增加数据写入时的延迟。因为每写入一条新数据,都需要同时更新索引结构,这会导致写入操作耗时变长。其次,索引和量化压缩等技术会引入一定的检索误差,导致最终结果不完全精确。但这种误差通常在可控范围内,可以通过合理选择参数进行调优。
四、总结与展望

目前业界已经有多种专门面向向量检索的数据库产品,例如 Qdrant、Milvus、Lancedb 等。这类数据库的优势是生态成熟、工具完善、针对相似性搜索做了专门优化。但其不足也比较明显:第一,易形成数据孤岛,难以与业务数据关联分析;第二,功能较为单一,无法支持更复杂的数据分析场景;第三,架构封闭,难以充分利用云原生平台的弹性和资源优化能力。此外,部署独立的向量数据库通常还需要额外的运维成本。

Databend 作为云原生 OLAP 数据库,在原生支持向量数据类型后,可以为需要融合结构化和向量数据分析的场景,提供更强大的能力。用户可以通过标准 SQL 语句进行向量数据的查询和搜索,充分利用 Databend 自带的弹性扩缩架构优势,无需单独部署和运维向量数据库,极大降低了整体运维成本。同时,向量数据也可以与其他业务数据融合分析,助力更多创新应用的落地。当然,目前 Databend 在向量方面的功能和生态还不如专业向量数据库丰富,工具链也有待完善。

Databend 现阶段已经具备了原生向量数据类型的支持,提供了基本的向量函数和 HNSW 索引。未来将不断完善功能,持续提升索引的性能与稳定性,丰富应用场景,开发更多与向量数据相关的工具,优化文档体验,方便广大用户使用。
目前 Databend 向量索引功能已经上线 Databend Cloud,感兴趣的朋友可以点击阅读原文试用体验!
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式湖仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:docs.databend.cn
💻 Wechat:Databend
✨ GitHub:github.com/databendlab...