1: 降级的理解
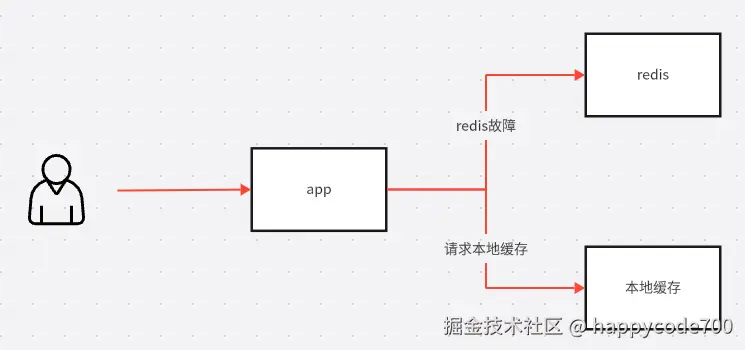
降级其实就是能过就将就的过,能用将就的用,相比熔断来说,没有这么暴力,直接, 比如之前公司的首页app首页,主要面对C端用户的,获取首页配置的qps非常的高,即使做了redis缓存,但是为了不影响用户的体验,我们也是做了降级操作,当redis出了问题,本地缓存有一个默认的配置,此时会降级读取本地缓存配置,这是非常经典的降级方案。
2: 降级的常用方案
2.1 跨服务降级
一台机器上部署了多个服务,此时流量高峰期,可能其它并不重要的服务会占用过多的机器资源,此时可能会关闭一些服务,将更多的机器资源腾出来给更重要的服务,怎么去衡量一个服务是否是更重要的呢?那就是赚钱能力。
2.1.1 跨服务降级常见操作
(1): 关闭不重要的服务节点
(2): 关闭部分节点
(3): 当客户端请求慢的时候,客户端可以不请求,直接默认返回即可,快速响应
2.2 本地提供有损服务
当面对业务高峰期的时候,比如一个用户需要去获取自定义的配置信息,但是当前业务高峰期,可能请求响应会存在慢,或者超时失败的请求,这个时候,可以提前拿本地配置响应给用户,快速先满足用户的需求。
2.2.1 本地提供有损服务
(1): 返回默认值,这算是最简单的一种状况。
(2): 将同步的请求转换为异步,将慢的步骤,能异步就异步
(3): 简化业务流程,关闭一些不重要的步骤,快速响应接口
3: 降级的工作实践
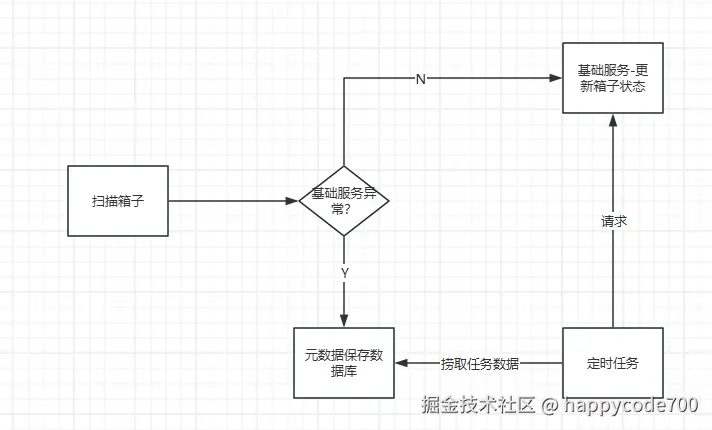
3.1: 扫描箱子的场景
3.1.1: 背景
背景是业务在操作的时候,会去扫描一个箱子,这个箱子状态是基础数据需要维护的,正常场景来说,如果基础数据服务稳定的话,更新状态都是同步的,为了面对异常情况,比如基础数据服务挂了,不能对外提供服务了,此时如果我们服务还是正常去请求,肯定会阻断现场业务操作,会被投诉的, 所以我们对扫箱子的业务进行改造
3.1.2: 改造点
1: 统计基础服务的异常频率,这个可以动态设置的,比如apollo, nacos等,比如 20次/分, 一分钟超过20次就会熔断触发服务降级。
2: 更新箱子的状态操作,从之前的同步改造成异步执行,我们会将请求的元数据信息保存到数据库中,定时任务去捞取数据,进行异步调用。
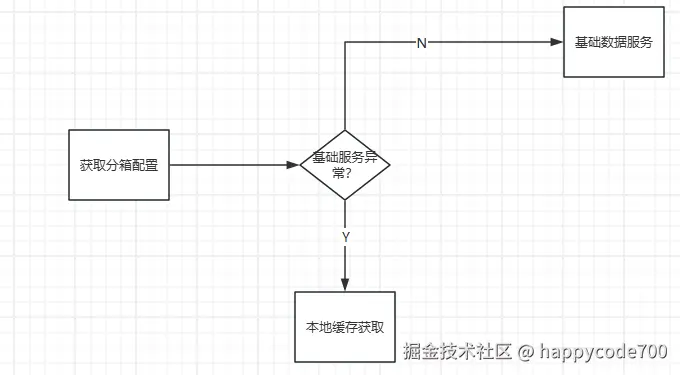
3.2: 获取分箱配置
3.2.1: 背景
背景是箱子里面装了很多不同品类,或者标签的商品,后续箱子需要进行分箱的操作,会获取分箱的配置,然后根据这个配置进行按品类,按品质去进行分箱,这个配置同样的是请求基础数据服务的,基础数据服务挂了,就会获取不到的话,可能就会阻断现场操作
3.2.2: 改造点
(1): 当基础数据服务挂了,获取不到配置的时候,就默认取本地缓存配置(写死在配置里面的),触发兜底策略