项目地址 : github.com/baozjj/Seam...
在前端开发中,将HTML内容导出为PDF是个常见需求。但传统的实现方式在处理长内容时经常出现文字、表格被中间截断的问题。本文分享一种基于像素分析的解决思路,通过"渲染后分析"来实现更合理的分页切割。
问题背景:固定高度分页的局限性
纯前端PDF导出的常见方案是使用 html2canvas + jsPDF。这套方案的基本流程是:
- 使用html2canvas将HTML元素渲染为Canvas
- 按照PDF页面的固定高度切割Canvas
- 将每个切片作为一页添加到PDF中
这种方式的问题在于分页逻辑过于简单:
javascript
// 传统方案的分页逻辑
const pageHeight = 841.89; // A4页面高度
let currentY = 0;
while (currentY < totalHeight) {
const slice = canvas.getImageData(0, currentY, width, pageHeight);
pdf.addImage(slice, 'JPEG', 0, 0);
currentY += pageHeight;
}这种固定高度的切割方式不会考虑内容的语义边界,导致文字行被从中间切断,表格数据被拆分到不同页面,影响文档的可读性。如下图所示:
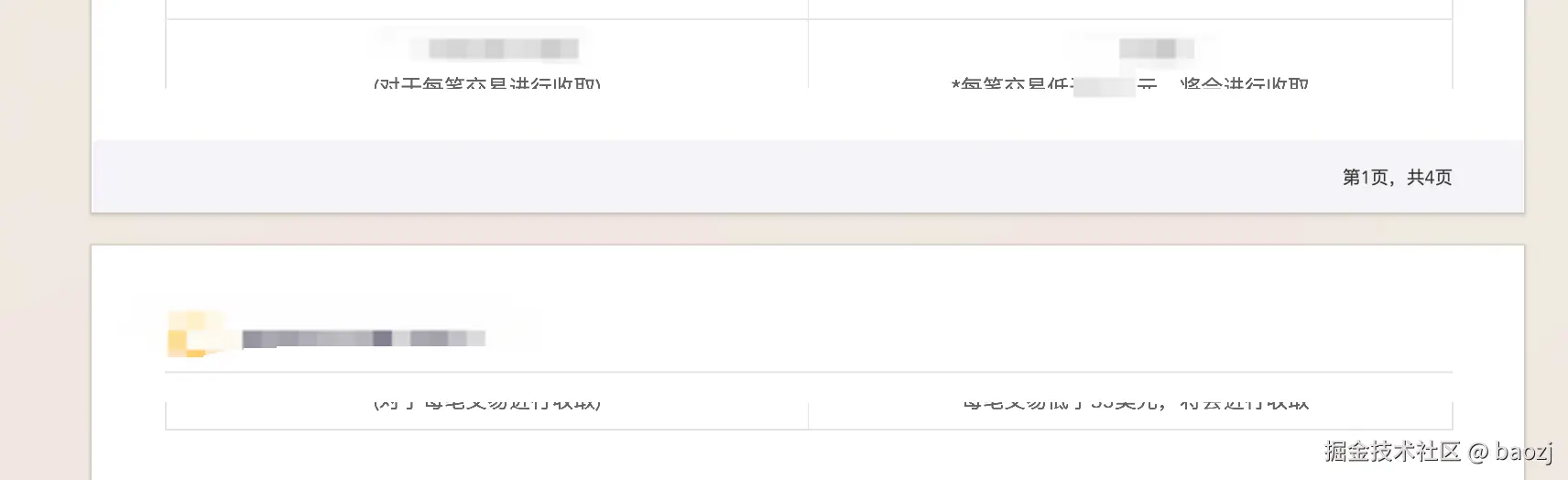
解决思路:渲染后的像素级分析
SeamlessPDF采用了不同的策略:先完整渲染内容,再通过像素分析找到合适的分页位置。优化后的效果如图所示:
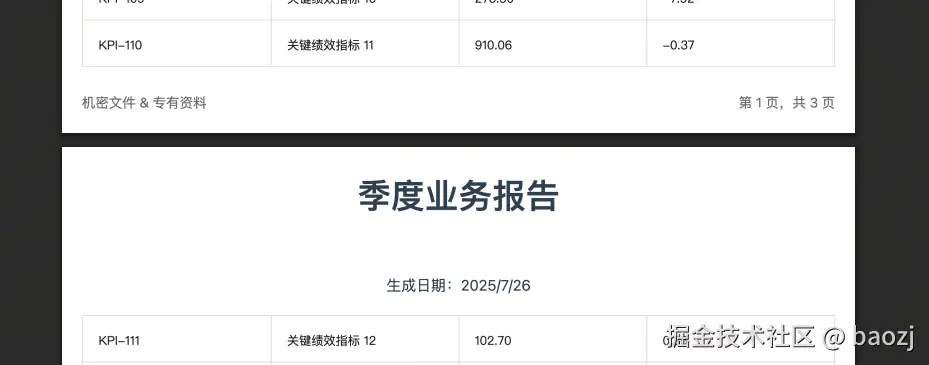
整体架构
typescript
export async function generateIntelligentPdf({
headerElement,
contentElement,
footerElement,
onFooterUpdate,
}: PdfGenerationOptions): Promise<jsPDF> {
// 第一阶段:将页面元素转换为 Canvas
const canvasElements = await renderElementsToCanvas({
headerElement,
contentElement,
footerElement,
});
// 第二阶段:计算页面布局参数
const layoutMetrics = calculatePageLayoutMetrics(canvasElements);
// 第三阶段:智能分页计算
const pageBreakCoordinates = calculateIntelligentPageBreaks(
canvasElements.content,
layoutMetrics.contentPageHeightInPixels
);
// 第四阶段:生成 PDF 文档
return await generatePdfDocument({
canvasElements,
layoutMetrics,
pageBreakCoordinates,
footerElement,
onFooterUpdate,
});
}核心思路是将分页决策从渲染前移到渲染后,通过分析已渲染的Canvas来确定最佳分页位置。
技术实现细节
1. 像素级的行分析
系统会逐行分析Canvas的像素数据,识别适合分页的位置:
typescript
export function analyzePageBreakLine(
yCoordinate: number,
canvas: HTMLCanvasElement
): PageBreakAnalysisResult {
const context = canvas.getContext("2d")!;
const currentLineImageData = context.getImageData(
0,
yCoordinate,
canvas.width,
1
).data;
const colorDistribution = analyzeColorDistribution(currentLineImageData);
const lineCharacteristics = determineLineCharacteristics(
colorDistribution,
canvas.width
);
return {
isCleanBreakPoint: lineCharacteristics.isPureWhite || lineCharacteristics.isTableLine,
isTableBorder: lineCharacteristics.isTableLine,
};
}这个函数会分析每一行的颜色分布,识别两种适合分页的位置:
- 纯白行:段落间的空白区域
- 表格边框行 :颜色为
rgb(221,221,221)且占比超过80%的行
2. 向上搜索最优切割点
当分页位置不适合时,系统会向上搜索最近的合适位置:
typescript
export function findOptimalPageBreak(
startYCoordinate: number,
canvas: HTMLCanvasElement
): OptimalBreakPointResult {
for (let y = startYCoordinate; y > 0; y--) {
const analysisResult = analyzePageBreakLine(y, canvas);
if (analysisResult.isCleanBreakPoint) {
return {
cutY: y + 1,
isTableBorder: analysisResult.isTableBorder,
};
}
}
return {
cutY: startYCoordinate,
isTableBorder: false,
};
}这种向上搜索的策略确保了分页位置的合理性,避免在内容中间强制切割。
3. 表格边框的特殊处理
考虑到表格的特殊性,系统会检测表格顶部边框,避免在表格开始位置分页:
typescript
function shouldAdjustOffsetForPreviousTableBorder(
pageBreakCoordinates: PageBreakCoordinate[]
): boolean {
return (
pageBreakCoordinates.length > 0 &&
pageBreakCoordinates[pageBreakCoordinates.length - 1].isTableBorderBreak
);
}当检测到上一页以表格边框结束时,会调整下一页的起始位置,保持表格内容的连续性。
使用方式
从开发者角度看,使用方式相对简单:
typescript
const handleExport = async () => {
const headerElement = reportHeader.value?.$el as HTMLElement;
const contentElement = reportContent.value?.$el as HTMLElement;
const footerElement = reportFooter.value?.$el as HTMLElement;
const pdf = await generateIntelligentPdf({
headerElement,
contentElement,
footerElement,
onFooterUpdate: (currentPage: number, totalPages: number) => {
footerState.currentPage = currentPage;
footerState.totalPages = totalPages;
},
});
await pdf.save(`报告.pdf`, { returnPromise: true });
};只需要提供页眉、内容、页脚三个DOM元素,系统会自动处理分页逻辑。
方案局限性
这种方案也有一些限制需要注意:
1. 依赖特定的视觉特征
系统依赖特定的颜色值来识别表格边框(rgb(221,221,221))。如果表格使用了不同的边框样式,识别效果会受影响:
css
.report-table {
border: 1px solid #ddd; /* 需要保持边框颜色的一致性 */
}适用场景
这种方案比较适合以下场景:
- 报表和数据展示页面的PDF导出
- 包含大量表格的文档生成
- 内容结构相对规整的页面
总结
通过"渲染后分析"的思路,可以在一定程度上改善前端PDF导出的分页质量。虽然这种方案有其局限性,但对于常见的报表导出场景,能够有效避免内容被不合理截断的问题。
项目地址 : github.com/baozjj/Seam...
欢迎有类似需求的开发者尝试使用,也欢迎提出改进建议。