文章目录
需求背景
当前系统日志主要存 ElasticSearch,存在以下问题:
- 查询效率较低,尤其在高并发场景下性能瓶颈明显;
- 存储成本较高,部分日志存储冗余,压缩效果不佳;
- 查询维度较弱,难以支持多维分析与快速聚合。
ClickHouse 作为高性能列式 OLAP 引擎,在日志存储和分析方面具备显著优势,能够支持大吞吐量、高压缩比及亚秒级查询延迟。因此,计划将关键日志数据接入 ClickHouse 进行统一分析、降本增效。
需求目的
- 实现日志写入 ClickHouse,提升查询性能与响应速度;
- 支持常见的日志检索、聚合分析;
- 兼容现有日志收集流程;
- 降本增效;
计划完成时间
2025-07-31
阶段
- Clickhouse结合日志存储调研,是否自建表?补充字段如何处理?
- 分布式集群搭建
- 性能优化
- 结合监控数据展示及告警
- 前端组件调研使用
- 自动清理旧数据
调研内容
日志写入链路
markdown
Filebeat / Logstash
↓
Kafka
↓
ClickHouse(Kafka 引擎表 → MergeTree 表)- Kafka 消费:ClickHouse 原生支持 Kafka 引擎,无需额外消费者;
- 数据转换:通过 Materialized View 进行字段映射与结构清洗;
- 落盘存储:使用 MergeTree 表优化查询性能与数据保留策略。
方案设计
表结构设计
落地表(ReplicatedMergeTree)
sql
CREATE TABLE IF NOT EXISTS default.ycloud_log_local
(
`message` String,
`host` String,
`@timestamp` UInt64,
`port` Int64,
`secondFacility` String,
`traceId` String,
`logtime` String,
`linenum` String,
`procedure` String,
`peerAddr` String,
`level` String,
`ck_assembly_extension` String,
`orderId` String,
`username` String,
`spanId` String,
`version` String,
INDEX timestamp_index `@timestamp` TYPE minmax GRANULARITY 8192
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/ycloud_log_local', '{replica}')
PARTITION BY (toYYYYMMDD(toDateTime(`@timestamp` / 1000, 'Asia/Shanghai')), toHour(toDateTime(`@timestamp` / 1000, 'Asia/Shanghai')))
ORDER BY (intHash64(`@timestamp`))
SAMPLE BY intHash64(`@timestamp`)
TTL toDateTime(`@timestamp` / 1000) + INTERVAL 120 DAY DELETE
SETTINGS in_memory_parts_enable_wal = 0, index_granularity = 8192;分布式表
sql
CREATE TABLE IF NOT EXISTS default.ycloud_log_all AS default.ycloud_log_local
ENGINE = Distributed('gs_clickhouse_cluster', default, ycloud_log_local, rand());Kafka 引擎表
sql
CREATE TABLE default.ycloud_log_kafka
(
`raw_json` String
)
ENGINE = Kafka
SETTINGS
kafka_broker_list = '192.168.100.10:9092,192.168.100.20:9092,192.168.100.30:9092',
kafka_topic_list = 'ycloud',
kafka_group_name = 'ycloud_test_group',
kafka_format = 'JSONAsString',
kafka_num_consumers = 10,
kafka_max_block_size = 1048576;物化视图
sql
CREATE MATERIALIZED VIEW IF NOT EXISTS default.ycloud_log_mv
TO default.ycloud_log_local
AS
SELECT
JSONExtractString(raw_json, 'message') AS message,
JSONExtractString(raw_json, 'host') AS host,
toUnixTimestamp64Milli(parseDateTime64BestEffort(JSONExtractString(raw_json, 'logtime'))) AS `@timestamp`,
toInt64OrNull(JSONExtractString(raw_json, 'port')) AS port,
JSONExtractString(raw_json, 'secondFacility') AS secondFacility,
JSONExtractString(raw_json, 'traceId') AS traceId,
JSONExtractString(raw_json, 'logtime') AS logtime,
JSONExtractString(raw_json, 'linenum') AS linenum,
JSONExtractString(raw_json, 'procedure') AS procedure,
JSONExtractString(raw_json, 'peerAddr') AS peerAddr,
JSONExtractString(raw_json, 'level') AS level,
raw_json AS ck_assembly_extension,
JSONExtractString(raw_json, 'orderId') AS orderId,
JSONExtractString(raw_json, 'username') AS username,
JSONExtractString(raw_json, 'spanId') AS spanId,
JSONExtractString(raw_json, 'version') AS version
FROM default.ycloud_log_kafka;保留策略
- 热数据:120 天内的日志使用主表存储;
- 清理机制:定期使用 TTL 策略清理过期分区。
前端选型
Ckibana + kibana
踩坑 Ckibana不支持8.0以上版本,官方文档写着支持Ckibana。使用时获取不到正确的时间戳字段。
部署方式采用自定义 Helm Charts,kibana 依赖Ckibana
yaml
spring:
application:
name: ckibana
server:
port: 8080
logging:
config: classpath:logback-spring.xml
file:
path: logs
metadata-config:
hosts: 192.168.100.10:9200
headers:
Authorization: ApiKey TzQ4N0VaZ0JjQWg3YWgzdw==配置ClickHouse连接信息与索引白名单
设置ClickHouse连接信息:
shell
curl --location --request POST 'localhost:8080/config/updateCk?url=ckUrl&user=default&pass=default&defaultCkDatabase=ops'配置需要切换到ClickHouse的index
shell
curl --location --request POST 'localhost:8080/config/updateWhiteIndexList?list=index1,index2'⚡️: 实际使用 ES + Kibana 方式一致
常见问题与解决方案
1. offset out of range
日志:
pgp
offset reset to offset BEGINNING: fetch failed due to requested offset not available on the broker原因:Kafka 中记录的 offset 已被删除,ClickHouse 自动回退到 earliest;
处理建议:
- 设置
kafka_auto_offset_reset = 'latest'避免历史 offset 回退; - 定期清理消费组;
- 设置合理的 Kafka 数据保留时间。
2. 消费延迟过高
原因:Kafka TPS 高时 ClickHouse 消费不及时;主要出现在更添加INDEX时,TOPIC存储周期长,数据量大导致。
方案:
- 增加消费者副本(表配置
kafka_num_consumers); - 将大表进行拆分;
- 提前清洗复杂字段,避免落地时频繁 JSON 解析。
3.常用操作
toUnixTimestamp64Milli(now64(3)) 用于获取当前时间的 Unix 毫秒级时间戳。
sql
## 添加字段
ALTER TABLE default.gsnormal_log_local
ADD COLUMN facility String AFTER level;
## 删除字段
ALTER TABLE default.gsnormal_log_local
DROP COLUMN port;成果展示
| 目标项 | 目标值 | 实际达成值 | 差值分析 |
|---|---|---|---|
| 查询效率 | P95 ≤ 3s | p95 1 s | 性能超出预期,ClickHouse 列式存储和分区裁剪发挥了优势,查询明显更快 |
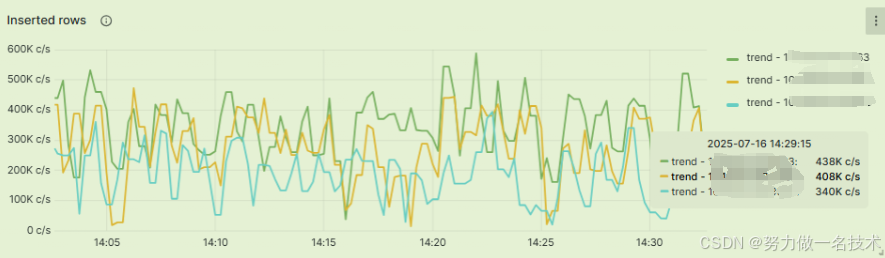
| 写入性能 | QPS ≥ 10 万 | QPS 实测峰值约 15 万 | 写入性能超额完成,Kafka 消费 + 批量 insert 提升了写入能力 |
| 存储成本 | 降低 ≥ 50% | 实际约降低 60% | 替换 ELK,去除副本冗余和冷热分层后,存储成本进一步下降 |
实际插入情况
亮点
- 提前规划固定字段(如 traceId、logtime、level 等)与原始 JSON 扩展字段(ck_assembly_extension)分开存储,保留日志灵活性,后期可快速应对字段变动需求,无需频繁修改表结构。
- 引入 ClickHouse TTL 自动清理策略,保障长期稳定运行。
- 使用 ReplicatedMergeTree 实现多副本同步,自动 failover 提升可用性,保证日志数据持久可靠。
不足
性能还需进一步加强,对极端写入压力的承载验证不足