https 协议在爬虫逻辑中的位置关系:
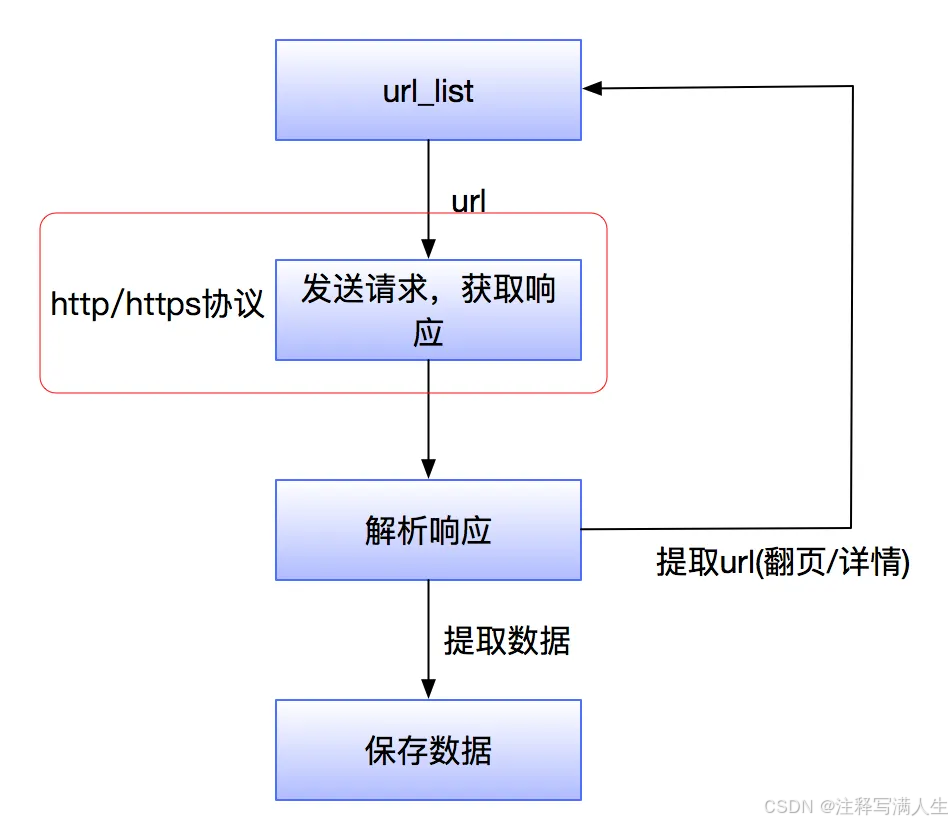
http 和 https 的概念
● HTTP:超文本传输协议,默认端口号是80
○ 超文本:是指超过文本,不仅限于文本;还包括图片、音频、视频等文件
○ 传输协议:是指使用共用约定的固定格式来传递转换成字符串的超文本内容
● HTTPS:HTTP + SSL(安全套接字层),即带有安全套接字层的超本文传输协,默认端口号:443
○ SSL对传输的内容(超文本,也就是请求体或响应体)进行加密
http 请求头和响应头
请求头字段
● Content-Type
● Host (主机和端口号)
● Connection (链接类型)
● Upgrade-Insecure-Requests (升级为HTTPS请求)
● User-Agent (浏览器名称)
● Referer (页面跳转处)
● Cookie (Cookie)
● Authorization(用于表示HTTP协议中需要认证资源的认证信息,如前边web课程中用于jwt认证)
加粗的请求头为常用请求头,在服务器被用来进行爬虫识别的频率最高,相较于其余的请求头更为重要。
响应头字段
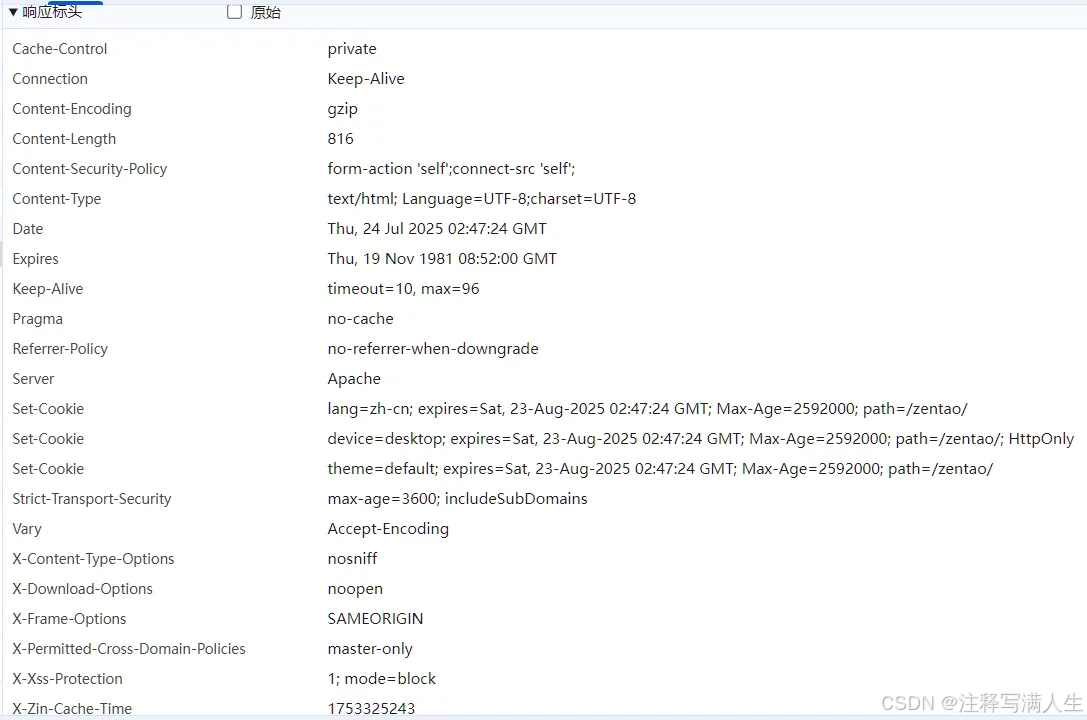
http响应的形式如上图所示,爬虫只关注一个响应头字段
● Set-Cookie (对方服务器设置cookie到用户浏览器的缓存)
常见的响应状态码
● 200:成功
● 302:跳转,新的url在响应的Location头中给出
● 303:浏览器对于POST的响应进行重定向至新的url
● 307:浏览器对于GET的响应重定向至新的url
● 403:资源不可用;服务器理解客户的请求,但拒绝处理它(没有权限)
● 404:找不到该页面
● 500:服务器内部错误
● 503:服务器由于维护或者负载过重未能应答,在响应中可能可能会携带Retry-After响应头;有可能是因为爬虫频繁访问url,使服务器忽视爬虫的请求,最终返回503响应状态码
我们在学习web知识的时候就已经学过了状态码的相关知识,我们知道这是服务器给我的相关反馈,我们在学习的时候就被教育说应该将真实情况反馈给客户端,但是在爬虫中,可能该站点的开发人员或者运维人员为了阻止数据被爬虫轻易获取,可能在状态码上做手脚,也就是说返回的状态码并不一定就是真实情况,比如:服务器已经识别出你是爬虫,但是为了让你疏忽大意,所以照样返回状态码200,但是响应体中并没有数据。
所有的状态码都不可信,一切以是否从抓包得到的响应中获取到数据为准
浏览器的运行过程
浏览器发送http请求的过程
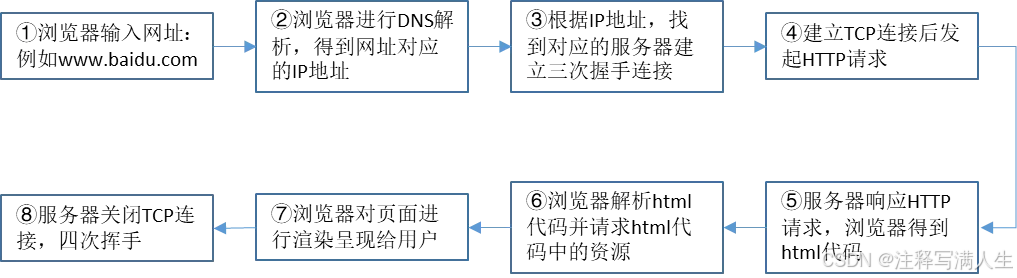
浏览器最终展示的结果是由多个url地址分别发送的多次请求对应的多次响应共同渲染的结果
所以在爬虫中,需要以发送请求的一个url地址对应的响应为准来进行数据的提取