
【作者主页】Francek Chen
【专栏介绍】⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目录
本章我们已经学习了许多有效优化的技术。在本节讨论之前,我们先详细回顾一下这些技术:
- 在随机梯度下降中,我们学习了:随机梯度下降在解决优化问题时比梯度下降更有效。
- 在小批量随机梯度下降中,我们学习了:在一个小批量中使用更大的观测值集,可以通过向量化提供额外效率。这是高效的多机、多GPU和整体并行处理的关键。
- 在动量法中我们添加了一种机制,用于汇总过去梯度的历史以加速收敛。
- 在AdaGrad算法中,我们通过对每个坐标缩放来实现高效计算的预处理器。
- 在RMSProp算法中,我们通过学习率的调整来分离每个坐标的缩放。
Adam算法将所有这些技术汇总到一个高效的学习算法中。不出预料,作为深度学习中使用的更强大和有效的优化算法之一,它非常受欢迎。但是它并非没有问题,尤其有时Adam算法可能由于方差控制不良而发散。在完善工作中,给Adam算法提供了一个称为Yogi的热补丁来解决这些问题。下面我们了解一下Adam算法。
一、算法
Adam算法的关键组成部分之一是:它使用指数加权移动平均值来估算梯度的动量和二次矩,即它使用状态变量
v t ← β 1 v t − 1 + ( 1 − β 1 ) g t s t ← β 2 s t − 1 + ( 1 − β 2 ) g t 2 (1) \begin{aligned} \mathbf{v}t & \leftarrow \beta_1 \mathbf{v}{t-1} + (1 - \beta_1) \mathbf{g}_t \\ \mathbf{s}t & \leftarrow \beta_2 \mathbf{s}{t-1} + (1 - \beta_2) \mathbf{g}_t^2 \end{aligned} \tag{1} vtst←β1vt−1+(1−β1)gt←β2st−1+(1−β2)gt2(1) 其中, β 1 \beta_1 β1和 β 2 \beta_2 β2是非负加权参数。常将它们设置为 β 1 = 0.9 \beta_1 = 0.9 β1=0.9和 β 2 = 0.999 \beta_2 = 0.999 β2=0.999。也就是说,方差估计的移动远远慢于动量估计的移动。注意,如果我们初始化 v 0 = s 0 = 0 \mathbf{v}_0 = \mathbf{s}0 = 0 v0=s0=0,就会获得一个相当大的初始偏差。我们可以通过使用 ∑ i = 0 t β i = 1 − β t 1 − β \sum{i=0}^t \beta^i = \frac{1 - \beta^t}{1 - \beta} ∑i=0tβi=1−β1−βt来解决这个问题。相应地,标准化状态变量由下式获得
v ^ t = v t 1 − β 1 t and s ^ t = s t 1 − β 2 t (2) \hat{\mathbf{v}}_t = \frac{\mathbf{v}_t}{1 - \beta_1^t} \text{ and } \hat{\mathbf{s}}_t = \frac{\mathbf{s}_t}{1 - \beta_2^t} \tag{2} v^t=1−β1tvt and s^t=1−β2tst(2)
有了正确的估计,我们现在可以写出更新方程。首先,我们以非常类似于RMSProp算法的方式重新缩放梯度以获得
g t ′ = η v ^ t s ^ t + ϵ (3) \mathbf{g}_t' = \frac{\eta \hat{\mathbf{v}}_t}{\sqrt{\hat{\mathbf{s}}_t} + \epsilon} \tag{3} gt′=s^t +ϵηv^t(3)
与RMSProp不同,我们的更新使用动量 v ^ t \hat{\mathbf{v}}_t v^t而不是梯度本身。此外,由于使用 1 s ^ t + ϵ \frac{1}{\sqrt{\hat{\mathbf{s}}_t} + \epsilon} s^t +ϵ1而不是 1 s ^ t + ϵ \frac{1}{\sqrt{\hat{\mathbf{s}}_t + \epsilon}} s^t+ϵ 1进行缩放,两者会略有差异。前者在实践中效果略好一些,因此与RMSProp算法有所区分。通常,我们选择 ϵ = 1 0 − 6 \epsilon = 10^{-6} ϵ=10−6,这是为了在数值稳定性和逼真度之间取得良好的平衡。
最后,我们简单更新:
x t ← x t − 1 − g t ′ (4) \mathbf{x}t \leftarrow \mathbf{x}{t-1} - \mathbf{g}_t' \tag{4} xt←xt−1−gt′(4)
回顾Adam算法,它的设计灵感很清楚:首先,动量和规模在状态变量中清晰可见,它们相当独特的定义使我们移除偏项(这可以通过稍微不同的初始化和更新条件来修正)。其次,RMSProp算法中两项的组合都非常简单。最后,明确的学习率 η \eta η使我们能够控制步长来解决收敛问题。
二、实现
从零开始实现Adam算法并不难。为方便起见,我们将时间步 t t t存储在hyperparams字典中。除此之外,一切都很简单。
python
%matplotlib inline
import torch
from d2l import torch as d2l
def init_adam_states(feature_dim):
v_w, v_b = torch.zeros((feature_dim, 1)), torch.zeros(1)
s_w, s_b = torch.zeros((feature_dim, 1)), torch.zeros(1)
return ((v_w, s_w), (v_b, s_b))
def adam(params, states, hyperparams):
beta1, beta2, eps = 0.9, 0.999, 1e-6
for p, (v, s) in zip(params, states):
with torch.no_grad():
v[:] = beta1 * v + (1 - beta1) * p.grad
s[:] = beta2 * s + (1 - beta2) * torch.square(p.grad)
v_bias_corr = v / (1 - beta1 ** hyperparams['t'])
s_bias_corr = s / (1 - beta2 ** hyperparams['t'])
p[:] -= hyperparams['lr'] * v_bias_corr / (torch.sqrt(s_bias_corr) + eps)
p.grad.data.zero_()
hyperparams['t'] += 1现在,我们用以上Adam算法来训练模型,这里我们使用 η = 0.01 \eta = 0.01 η=0.01的学习率。
python
data_iter, feature_dim = d2l.get_data_ch11(batch_size=10)
d2l.train_ch11(adam, init_adam_states(feature_dim),
{'lr': 0.01, 't': 1}, data_iter, feature_dim);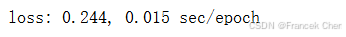
此外,我们可以用深度学习框架自带算法应用Adam算法,这里我们只需要传递配置参数。
python
trainer = torch.optim.Adam
d2l.train_concise_ch11(trainer, {'lr': 0.01}, data_iter)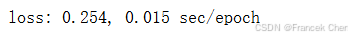
三、Yogi
Adam算法也存在一些问题:即使在凸环境下,当 s t \mathbf{s}_t st的二次矩估计值爆炸时,它可能无法收敛。为 s t \mathbf{s}_t st提出了的改进更新和参数初始化。建议我们重写Adam算法更新如下:
s t ← s t − 1 + ( 1 − β 2 ) ( g t 2 − s t − 1 ) (5) \mathbf{s}t \leftarrow \mathbf{s}{t-1} + (1 - \beta_2) \left(\mathbf{g}t^2 - \mathbf{s}{t-1}\right) \tag{5} st←st−1+(1−β2)(gt2−st−1)(5) 每当 g t 2 \mathbf{g}_t^2 gt2具有值很大的变量或更新很稀疏时, s t \mathbf{s}_t st可能会太快地"忘记"过去的值。一个有效的解决方法是将 g t 2 − s t − 1 \mathbf{g}t^2 - \mathbf{s}{t-1} gt2−st−1替换为 g t 2 ⊙ s g n ( g t 2 − s t − 1 ) \mathbf{g}_t^2 \odot \mathop{\mathrm{sgn}}(\mathbf{g}t^2 - \mathbf{s}{t-1}) gt2⊙sgn(gt2−st−1)。这就是Yogi更新,现在更新的规模不再取决于偏差的量。
s t ← s t − 1 + ( 1 − β 2 ) g t 2 ⊙ s g n ( g t 2 − s t − 1 ) (6) \mathbf{s}t \leftarrow \mathbf{s}{t-1} + (1 - \beta_2) \mathbf{g}_t^2 \odot \mathop{\mathrm{sgn}}(\mathbf{g}t^2 - \mathbf{s}{t-1}) \tag{6} st←st−1+(1−β2)gt2⊙sgn(gt2−st−1)(6)
论文中,作者还进一步建议用更大的初始批量来初始化动量,而不仅仅是初始的逐点估计。
python
def yogi(params, states, hyperparams):
beta1, beta2, eps = 0.9, 0.999, 1e-3
for p, (v, s) in zip(params, states):
with torch.no_grad():
v[:] = beta1 * v + (1 - beta1) * p.grad
s[:] = s + (1 - beta2) * torch.sign(
torch.square(p.grad) - s) * torch.square(p.grad)
v_bias_corr = v / (1 - beta1 ** hyperparams['t'])
s_bias_corr = s / (1 - beta2 ** hyperparams['t'])
p[:] -= hyperparams['lr'] * v_bias_corr / (torch.sqrt(s_bias_corr) + eps)
p.grad.data.zero_()
hyperparams['t'] += 1
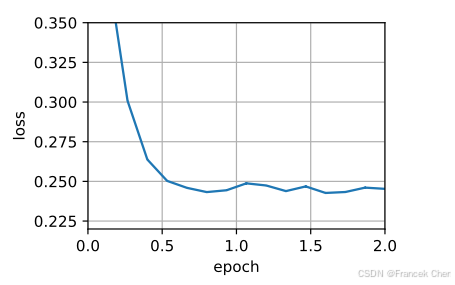
data_iter, feature_dim = d2l.get_data_ch11(batch_size=10)
d2l.train_ch11(yogi, init_adam_states(feature_dim),
{'lr': 0.01, 't': 1}, data_iter, feature_dim);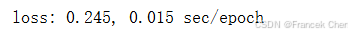
小结
- Adam算法将许多优化算法的功能结合到了相当强大的更新规则中。
- Adam算法在RMSProp算法基础上创建的,还在小批量的随机梯度上使用EWMA。
- 在估计动量和二次矩时,Adam算法使用偏差校正来调整缓慢的启动速度。
- 对于具有显著差异的梯度,我们可能会遇到收敛性问题。我们可以通过使用更大的小批量或者切换到改进的估计值 s t \mathbf{s}_t st来修正它们。Yogi提供了这样的替代方案。