最近我打算逐步重构我的一个python项目,将 init 使用 datatclass 替代,中间遇到一些问题,值得记录下。
在日常的 Python 开发中,我们经常会编写一些主要用于存储数据的类。这些类通常包含一个冗长的 __init__ 方法,里面充满了 self.x = x, self.y = y 这样的重复代码。这不仅乏味,也让类的定义显得臃肿。
Python 3.7 引入的 dataclass 装饰器,正是为了解决这个问题。它能帮助我们用更少的代码,写出更清晰、更健壮的数据类。
什么是 dataclass?
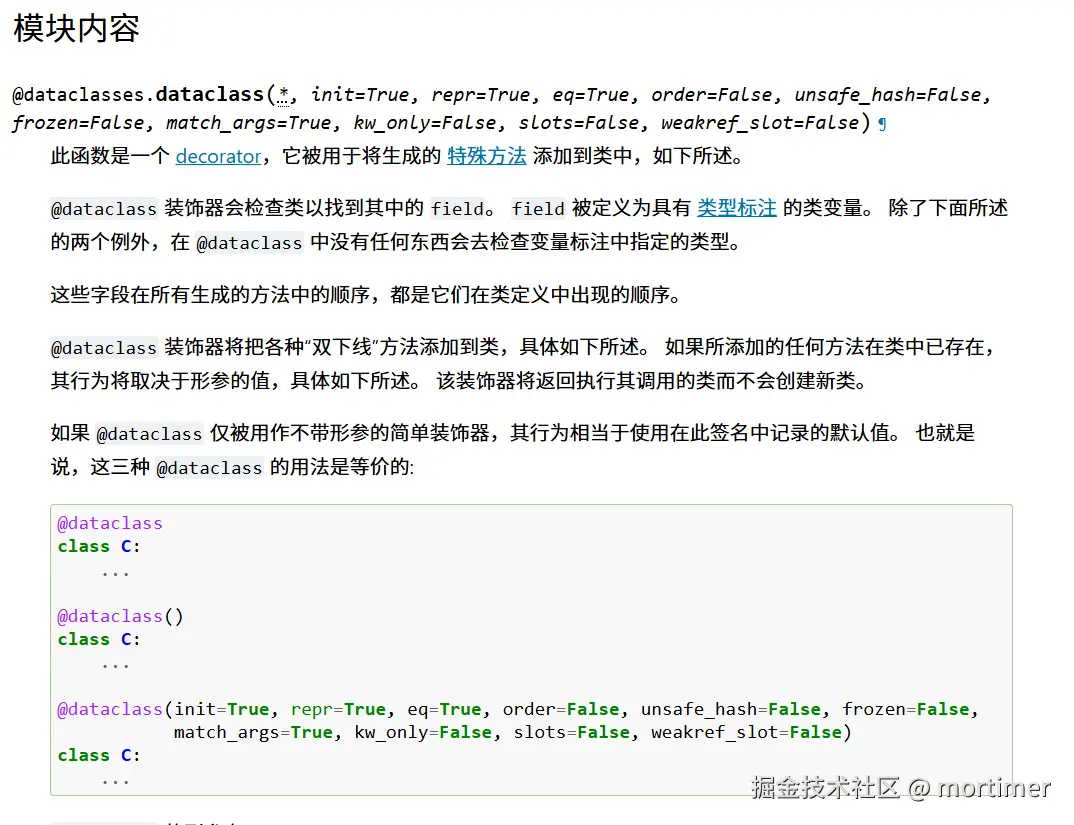
@dataclass 是一个类装饰器。当你把它放在一个类的上方时,它会自动为这个类生成一些基础的特殊方法,比如 __init__、__repr__ 和 __eq__。
我们来看一个最直观的例子。
传统方式:
python
class Product:
def __init__(self, name: str, price: float, quantity: int = 0):
self.name = name
self.price = price
self.quantity = quantity
def __repr__(self):
return f"Product(name='{self.name}', price={self.price}, quantity={self.quantity})"
def __eq__(self, other):
if not isinstance(other, Product):
return NotImplemented
return (self.name, self.price, self.quantity) == \
(other.name, other.price, other.quantity)使用 dataclass 的方式:
python
from dataclasses import dataclass
@dataclass
class Product:
name: str
price: float
quantity: int = 0这两种写法的最终效果几乎完全一样。但 dataclass 的版本显然更简洁,意图也更清晰。类的定义本身就像一份清晰的属性清单,而不是一堆实现代码。
dataclass 带来的核心优势
- 代码更少,意图更明:类的定义直接展示了它包含哪些数据,以及这些数据的类型。
- 自带实用功能 :自动生成的
__repr__方法让调试打印变得非常方便。__eq__方法让我们能直接用==比较两个实例的内容是否相等。 - 强制类型注解 :
dataclass要求你为属性添加类型提示。这不仅让代码更易读,还能配合 MyPy 等静态分析工具,在运行前就发现潜在的类型错误。 - 不可变性 :通过
@dataclass(frozen=True),你可以轻松创建不可变对象。任何尝试修改其属性的操作都会立即报错,这对于维护数据一致性非常有用。
重构实战:从简单的 __init__ 开始
重构的第一步通常很简单。如果你有一个类,其 __init__ 方法只做简单的属性赋值,你可以直接将其转换为 dataclass 的字段声明。
重构前:
python
class User:
def __init__(self, username: str, email: str, is_active: bool = True):
self.username = username
self.email = email
self.is_active = is_active重构后:
python
from dataclasses import dataclass
@dataclass
class User:
username: str
email: str
is_active: bool = True这里的转换规则很简单:
- 给类加上
@dataclass装饰器。 - 将
__init__的参数列表,连同类型和默认值,直接复制到类的顶层作为字段声明。 - 删除旧的
__init__方法。
进阶场景:处理复杂的初始化逻辑
现实世界中的 __init__ 方法往往不只是赋值。它可能包含验证、计算、文件操作等副作用。直接删除 __init__ 显然行不通。
这时,__post_init__ 方法就派上用场了。
dataclass 的工作流程是这样的:
- 它先根据你定义的字段,自动生成一个标准的
__init__方法,这个方法只做一件事:把你传入的参数赋值给self。 - 在这个
__init__方法执行完毕后,它会立即调用__post_init__。
这意味着,所有复杂的、有副作用的初始化逻辑,都应该从旧的 __init__ 迁移到 __post_init__ 中。
__post_init__ 对比 __init__ 的优势是什么?
看起来 __post_init__ 似乎只是替换了 __init__,但它们的职责有着本质的区别。
__init__(由 dataclass 生成) 的职责是**"数据绑定"**。它的任务是确保创建实例时传入的数据,被正确地绑定到实例的属性上。它应该保持纯粹和简单。__post_init__的职责是**"初始化逻辑"**。它的任务是在数据绑定完成后,执行所有必要的后续步骤,比如数据验证、计算派生属性、调用其他方法等。
这种职责分离 是 dataclass 设计的核心优势。它让类的结构更加清晰:字段定义了"有什么",__post_init__ 定义了"然后做什么"。
实战演练:一个复杂的任务类
让我们看一个更真实的例子。这是我的一个基类 BaseCon 和一个执行任务的子类 BaseTask。
重构前:
python
class BaseCon:
def __init__(self, **kwargs):
self.uuid = None
self.shound_del = False
class BaseTask(BaseCon):
def __init__(self, cfg: dict = None, obj: dict = None):
super().__init__()
self.cfg = cfg
if obj:
self.cfg.update(obj)
# ... 其他大量的属性赋值和逻辑 ...
self.precent = 1
self.hasend = False这里的 __init__ 方法混杂了配置合并、属性赋值等多种逻辑。
重构后的版本:
我们需要解决一个核心问题:如何让 dataclass 生成的 __init__ 与旧的调用方式兼容,同时把逻辑分离出去。
答案是使用 field(init=False)。这个参数告诉 dataclass:"这个属性是类的成员,但不要把它放到 __init__ 的参数里"。
重构后的 BaseCon:
python
from dataclasses import dataclass, field
from typing import Optional
@dataclass
class BaseCon:
# 这两个属性是内部状态,不应在创建时传入
uuid: Optional[str] = field(init=False)
shound_del: bool = field(init=False)
def __post_init__(self):
# 在这里执行旧 __init__ 的逻辑
self.uuid = None
self.shound_del = False由于没有任何字段需要 __init__ 处理,dataclass 会为 BaseCon 生成一个无参数的 __init__(self)。
重构后的 BaseTask:
python
from typing import Dict, Any, List
@dataclass
class BaseTask(BaseCon):
# 步骤 1: 定义 __init__ 的参数
# 这会生成 __init__(self, cfg: Dict, obj: Dict = None)
cfg: Dict = field(repr=False)
obj: Optional[Dict] = field(default=None, repr=False)
# 步骤 2: 定义所有内部状态属性,并用 init=False 排除
precent: int = field(default=1, init=False)
hasend: bool = field(default=False, init=False)
# ... 其他几十个状态属性 ...
# 步骤 3: 把所有逻辑放入 __post_init__
def __post_init__(self):
# 先调用父类的初始化逻辑
super().__post_init__()
# 再执行本类的逻辑
if self.obj:
self.cfg.update(self.obj)
# ... 其他逻辑 ...这个重构后的版本,完美地实现了我的所有目标:
- 调用方式不变 :
BaseTask(cfg=..., obj=...)依然可以正常工作。 - 类的结构清晰:类的顶部清晰地列出了构造参数和内部状态属性。
- 逻辑集中 :所有复杂的初始化逻辑都被收纳在
__post_init__中,职责单一。 - 继承链健壮 :子类可以通过
super().__post_init__()安全地调用父类的初始化流程。
处理Qt类等特殊情况
由于我的项目是基于
pyside6的 GUI 软件,不可避免的含有大量Qt组件
需要注意的是,@dataclass 并不适用于所有场景。例如,直接用它来装饰 QThread 或 QWidget 这样的 Qt 类是危险的,因为 dataclass 自动生成的 __init__ 可能会与 Qt 自身的元对象系统冲突。
在这种情况下,不使用 @dataclass 装饰器,但仍然可以借鉴它的思想:手动添加类型注解。
重构前:
python
class Worker(QThread):
def __init__(self, *, parent=None, app_mode=None, cfg=None):
super().__init__(parent=parent)
self.app_mode = app_mode
self.cfg=cfg重构后 (仅添加类型注解):
python
from typing import Optional, Dict, Any
class Worker(QThread):
app_mode: Optional[str]
cfg: Optional[Dict[str, Any]]
def __init__(self, *,
parent: Optional[QObject] = None,
app_mode: Optional[str] = None,
cfg: Optional[Dict[str, Any]] = None):
super().__init__(parent=parent)
self.app_mode = app_mode
self.cfg = cfg这样做的好处是,获得了类型提示带来的清晰度和编辑器支持,同时完全避免了与 Qt 底层机制的冲突,保证了代码的稳定和安全。
通过这些实战案例,可以看到 dataclass 不仅仅是一个语法糖,它更是一种引导我们编写更清晰、更健壮、更易于维护的类的设计模式。
当你下一次准备写一个新的 __init__ 方法时,不妨先想一想:这里是不是 dataclass 的用武之地?