大文件上传到主要流程
- 客户端上传文件
- 文件切片
- 调用服务器的校验接口,判断当前文件是否在服务器中存在
- 如果存在则进度条直接完成(秒传)
- 如果存在部分,服务器会返回存在的部分给前端,然后前端上传剩余的部分(断点续传)
- 切片上传
- 所有切片上传成功后调用服务端合并的接口,由后端对所有切片进行合并
- 上传完成
- 先搭建前端框架,这里前端使用vue3 + elementui plus
- 执行创建项目命令
js
pnpm create vue@latest我们这里只是做一个demo其他的配置项就不需要添加 
- 安装一下elementui plus,具体使用看官网
js
pnpm install element-plus- 大致写一下页面结构
vue
<template>
<div class="upload-container">
<el-upload
class="upload-demo"
:auto-upload="false"
:on-change="handleFileChange"
:show-file-list="false"
>
<template #trigger>
<el-button type="primary">select file</el-button>
</template>
</el-upload>
<div class="progress-container" v-if="file1">
<div class="file-info">
<p>{{ file1.name }}</p>
<p>{{ (file1.size / 1024 / 1024).toFixed(2) }} MB</p>
</div>
<el-progress :percentage="progressPercent" :status="progressStatus" />
<el-button type="primary" @click="startUpload">开始上传</el-button>
</div>
</div>
</template>- 一开始页面长这样

- js代码
js
const handleFileChange = (uploadFile) => {
file1.value = uploadFile.raw; // 获取上传的文件信息
console.log('file1', file1.value)
progressPercent.value = 0; // 进度条
};上传文件以后页面长这样
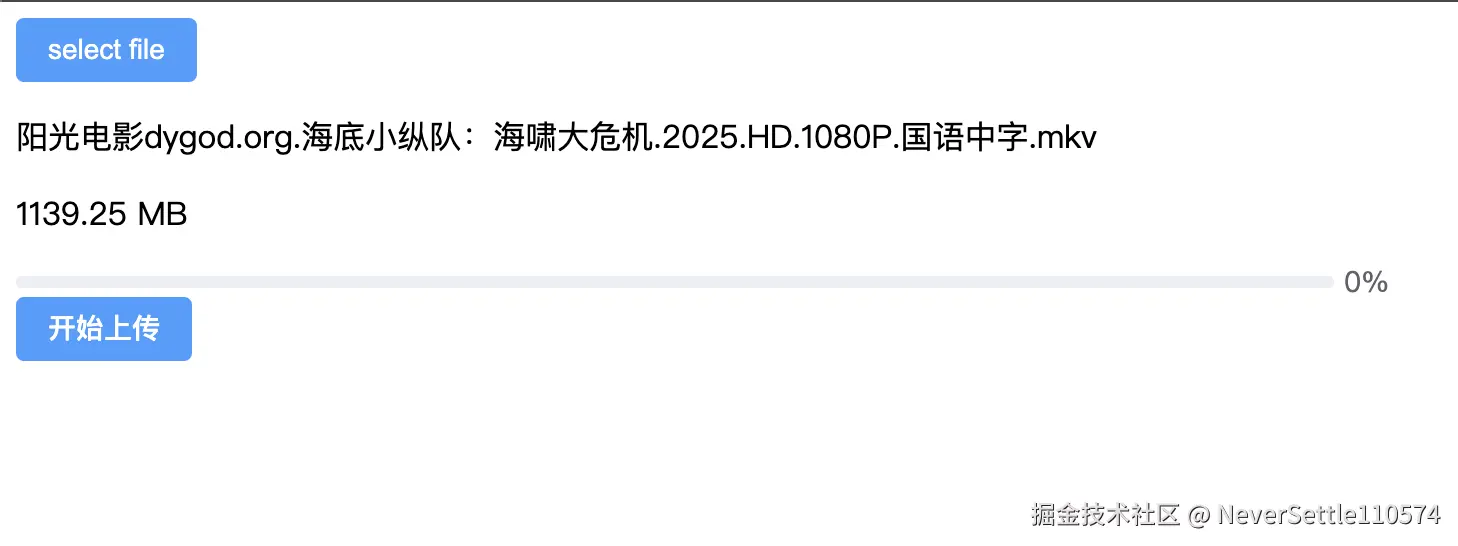
- 当点击开始上传按钮后,开始上传文件
众所周知大文件上传的方式是分片,将大文件分割成一个个小片,如下图所示
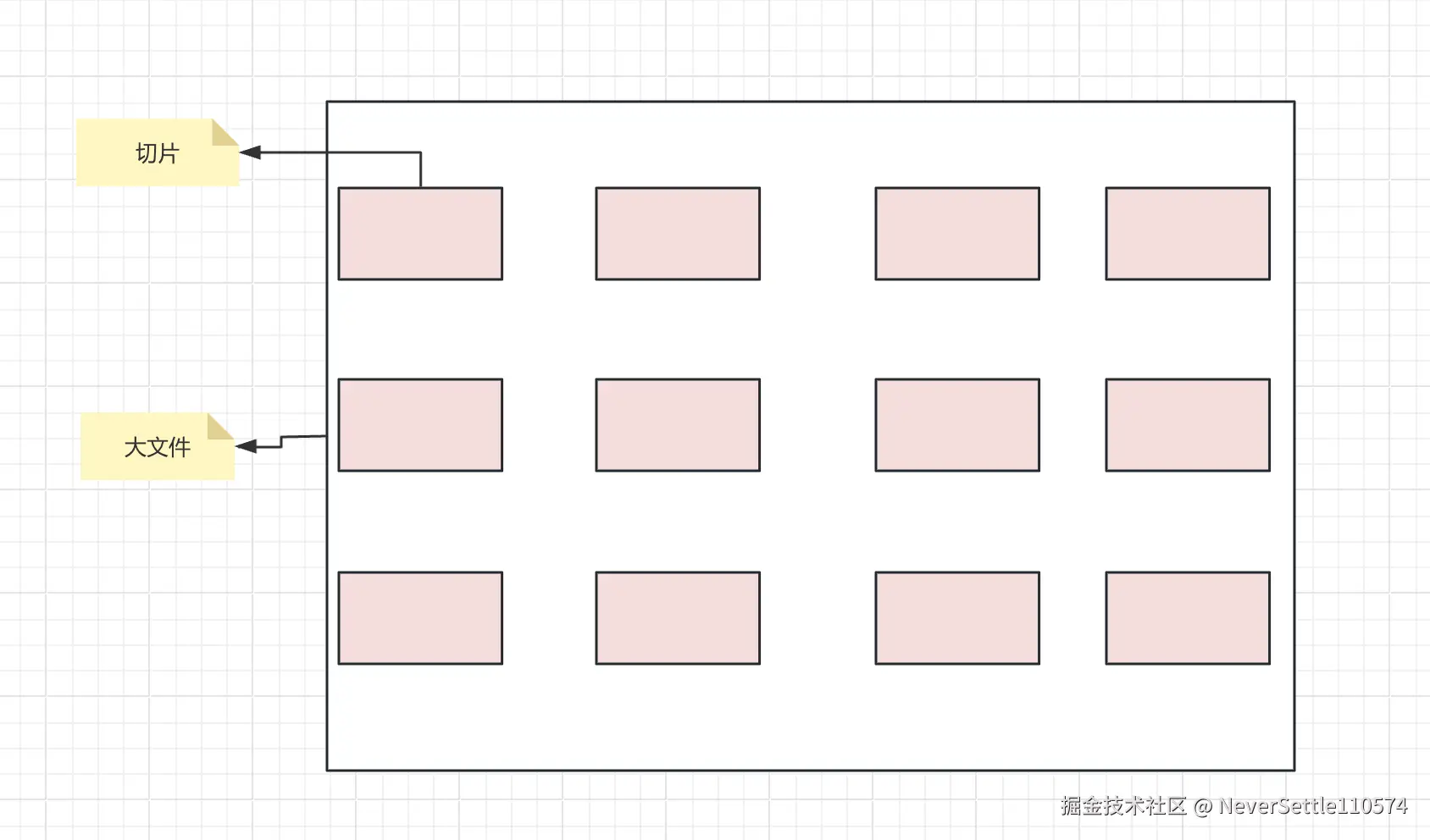
- 切片的原理我这里就不赘述了,相信大家也看过很多资料了
- 我这里直接实现对文件的切片
由于我们对切片生成hash值时用了一个spark-md5的插件,计算hash值是很耗时的,会阻塞浏览器,因此会使用到web Worker开启多线程计算hash值
index.js
js
// 这是对大文件切块多主要代码
export const chunkSize = 10 * 1024 * 1024; // 10MB
const threadCount = navigator.hardwareConcurrency || 4; // 线程数
export const cutFile = async (file) => {
return new Promise((resolve) => {
const chunkCount = Math.ceil(file.size / chunkSize); // 块数
const threadChunkCount = Math.ceil(chunkCount / threadCount); // 每个线程处理的块数
console.log('threadChunkCount', threadChunkCount, chunkCount)
const result = []
let finishCount = 0
for (let i = 0; i < threadCount; i++) {
const worker = new Worker(new URL('./worker.js', import.meta.url), {type: 'module'});
worker.postMessage({
file,
start: i * threadChunkCount, // 每个线程处理的起始块数
end: Math.min((i + 1) * threadChunkCount, chunkCount), // 每个线程处理的结束块数
chunkSize
})
worker.onmessage = (e) => {
worker.terminate() // 处理完就关闭线程
result[i] = e.data // 将每个线程的结果保存到result数组中, 用下标时因为要保证顺序
finishCount++
if (finishCount === threadCount) {
resolve(result.flat()) // 将二维数组变为一维数组
}
}
}
})
}worker.js
js
import { createChunk } from "./creatChunk";
onmessage = async function (e) {
const { file, start, end, chunkSize } = e.data;
const result = []
for (let i = start; i < end; i ++) {
const chunk = await createChunk(file, i, chunkSize);
result.push(chunk)
}
const chunks = await Promise.all(result)
postMessage(chunks)
}creatChunk.js
js
import SparkMD5 from "spark-md5";
// 导出一个函数createChunk,用于创建文件块
export const createChunk = (file, index, size) => {
// 返回一个Promise对象
return new Promise((resolve) => {
// 计算文件块的起始位置
const start = index * size;
// 计算文件块的结束位置
const end = start + size
// 创建一个SparkMD5对象,用于计算文件块的hash值
const spark = new SparkMD5.ArrayBuffer();
const fileReader = new FileReader();
const blob = file.slice(start, end);
fileReader.onload = (e) => {
spark.append(e.target.result);
resolve({
start,
end,
index,
hash: spark.end(),
blob
})
}
fileReader.readAsArrayBuffer(blob);
})
}- 对文件分完块,并计算出每个切片的hash后,我们还需要得到整个文件的hash值,这个主要是给文件一个标识,保证文件名是唯一的
- 那我们还是利用sparkms5这个插件计算hash值
fileHash1.js
js
import SparkMD5 from "spark-md5";
export const fileHash1 = (chunk) => {
return new Promise((resolve) => {
const spark = new SparkMD5.ArrayBuffer()
_read(0)
function _read(i) {
if (i>= chunk.length) {
resolve(spark.end())
return
}
const blob = chunk[i]
spark.append(blob.hash) // 已经得到所有切片了,并且每个切片都有hash值,这里就不用再去获取文件数据,生成hash值,直接用每个切片的hash值进行增量计算,提高效率
_read(i+1)
}
})
}现在开始搭建node服务器,这里用到了express
文件目录很简单
 index.js
index.js
js
const express = require('express');
const multer = require('multer');
const fs = require('fs');
const path = require('path');
const cors = require('cors');
const app = express();
app.use(cors());
app.use(express.json());
const upload = multer();
app.use(express.urlencoded({ extended: true }));
// 文件上传临时目录
const UPLOAD_DIR = path.resolve(__dirname, 'uploads');
// 分块上传接口
app.post('/upload', upload.single('chunk'), (req, res) => {
// 检查上传目录是否存在,如果不存在则创建
if (!fs.existsSync(UPLOAD_DIR)) {
fs.mkdirSync(UPLOAD_DIR);
}
// console.log('req.body', req.file)
const { fileHash, chunkHash, chunkIndex } = req.body;
const chunk = req.file;
// 检查参数是否正确
if (!chunk || !fileHash || !chunkHash || chunkIndex === undefined) {
return res.status(400).send({ code: 1, message: '参数错误' });
}
// 创建分块目录
const chunkDir = path.resolve(UPLOAD_DIR, fileHash);
if (!fs.existsSync(chunkDir)) {
fs.mkdirSync(chunkDir);
}
// 保存分块文件
const chunkPath = path.resolve(chunkDir, `${chunkIndex}-${chunkHash}`);
fs.writeFileSync(chunkPath, chunk.buffer);
res.send({ code: 0, message: '上传成功' });
});
// 合并文件接口
app.post('/merge', (req, res) => {
const { fileHash, fileName, chunkCount } = req.body;
// 检查参数是否正确
if (!fileHash || !fileName || !chunkCount) {
return res.status(400).send({ code: 1, message: '参数错误' });
}
// 创建分块目录
const chunkDir = path.resolve(UPLOAD_DIR, fileHash);
const filePath = path.resolve(UPLOAD_DIR, fileName);
// 检查所有分块是否已上传
for (let i = 0; i < chunkCount; i++) {
const chunkPath = path.resolve(chunkDir, `${i}-${req.body.chunks[i].hash}`);
// console.log(chunkPath)
if (!fs.existsSync(chunkPath)) {
return res.status(400).send({ code: 1, message: `分块${i}缺失` });
}
}
// 合并文件
const writeStream = fs.createWriteStream(filePath);
for (let i = 0; i < chunkCount; i++) {
const chunkPath = path.resolve(chunkDir, `${i}-${req.body.chunks[i].hash}`);
const chunk = fs.readFileSync(chunkPath);
writeStream.write(chunk);
fs.unlinkSync(chunkPath);
}
writeStream.end();
fs.rmdirSync(chunkDir);
res.send({ code: 0, message: '合并成功' });
});
// 校验文件接口
app.post('/verify', (req, res) => {
const { fileHash, fileName } = req.body;
// 检查参数是否正确
if (!fileHash || !fileName) {
return res.status(400).send({ code: 1, message: '参数错误' });
}
const filePath = path.resolve(UPLOAD_DIR, fileName);
// 检查文件是否已存在
if (fs.existsSync(filePath)) {
return res.send({
code: 0,
message: '文件已存在',
data: { shouldUpload: false }
});
}
// 检查已上传的分块
const chunkDir = path.resolve(UPLOAD_DIR, fileHash);
const uploadedChunks = [];
if (fs.existsSync(chunkDir)) {
uploadedChunks.push(...fs.readdirSync(chunkDir)); // 将文件夹中的chunk添加到数组中
}
res.send({
code: 0,
message: '校验成功',
data: {
shouldUpload: true,
uploadedChunks: uploadedChunks.map(c => parseInt(c.split('-')[0])) // 返回已经上传过的chunks的索引
}
});
});
const PORT = 12306;
app.listen(PORT, () => {
console.log(`Server running on port ${PORT}`);
});客户端实现上传
js
<script setup>
import { ref } from 'vue'
import { cutFile, chunkSize} from './utils'
import { fileHash1 } from './utils/fileHash'
import axios from 'axios'
// const upload = ref()
const file1 = ref() // 文件
const progressPercent = ref(0) // 进度百分比
const progressStatus = ref('') // 进度状态
const uploadedChunks = ref([]) // 已上传的块
const uploadCount = ref(0) // 已上传的块数量
let total = 0 // 总块数量
// 开始上传
const startUpload = async () => {
const file = file1.value
let chunks = await cutFile(file, chunkSize) // 切割文件
const fileHash = await fileHash1(chunks) // 计算文件哈希值
total = chunks.length
// 检查文件是否已上传或部分上传
// 发送post请求到http://localhost:12306/verify,请求体中包含fileHash和fileName
const { data: verifyRes } = await axios.post('http://localhost:12306/verify', {
fileHash,
fileName: file1.value.name
});
// 如果verifyRes.data.shouldUpload为false,则设置进度条为100%和success状态,并返回
if (!verifyRes.data.shouldUpload) {
progressPercent.value = 100;
progressStatus.value = 'success';
return;
}
// 如果verifyRes.data.shouldUpload为true,且verifyRes.data.uploadedChunks不为空,则将uploadedChunks.value设置为verifyRes.data.uploadedChunks的排序后的数组,uploadCount.value设置为uploadedChunks.value的长度,并打印uploadedChunks.value
let temp = []
if (verifyRes.data.shouldUpload && verifyRes.data.uploadedChunks.length) {
uploadedChunks.value = verifyRes.data.uploadedChunks.sort((a, b) => a - b);
uploadCount.value = uploadedChunks.value.length
console.log('uploadedChunks', uploadedChunks.value)
// 将chunks中不包含uploadedChunks.value的元素过滤出来,并赋值给temp
temp = chunks.filter((chunk) => !uploadedChunks.value.includes(chunk.index));
} else {
// 否则将chunks赋值给temp
temp = chunks
}
console.log('chunks', uploadCount.value, temp)
// return
// 上传每个分片
// 遍历temp数组
for(let i = 0; i < temp.length; i++) {
// 获取当前元素的hash值
const chunkHash = temp[i].hash
// 获取当前元素的blob值
const blob = temp[i].blob
// 创建一个FormData对象
const formData = new FormData();
// 向FormData对象中添加fileHash字段
formData.append('fileHash', fileHash);
// 向FormData对象中添加chunkHash字段
formData.append('chunkHash', chunkHash);
// 向FormData对象中添加chunkIndex字段
formData.append('chunkIndex', temp[i].index);
// 向FormData对象中添加chunk字段
formData.append('chunk', blob);
// 发送post请求
try {
await axios.post('http://localhost:12306/upload', formData);
// 更新进度百分比
progressPercent.value = Math.round(((i + 1) / temp.length) * 100);
// 更新上传数量
uploadCount.value ++
} catch (err) {
// 打印错误信息
console.log('err', err)
// 更新进度状态
progressStatus.value = 'exception';
// 返回
return;
}
}
console.log('chunks', temp.length, uploadCount.value, total)
if (uploadCount.value === total) {
// 合并文件
try {
await axios.post('http://localhost:12306/merge', {
fileHash,
fileName: file1.value.name,
chunkCount: chunks.length,
chunks: chunks,
});
progressStatus.value = 'success';
} catch (error) {
progressStatus.value = 'exception';
console.error(error);
}
}
}
// 文件改变时触发
const handleFileChange = (uploadFile) => {
file1.value = uploadFile.raw;
console.log('file1', file1.value)
progressPercent.value = 0;
};
</script>效果
- 当文件在后端不存在时
调用校验接口,接口返回
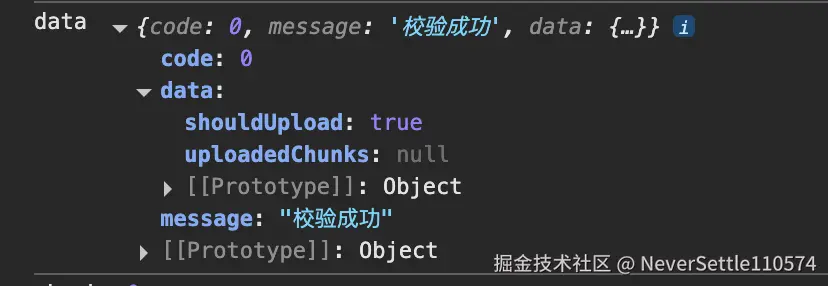
- 如果需要上传则将切片一个个上传到服务器
- 当所有切片的数量等于上传的数量时
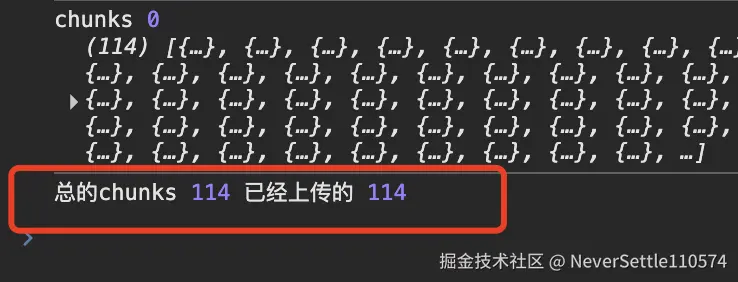
- 此时需要调用合并文件接口,告诉后端文件上传完了,可以合并文件了
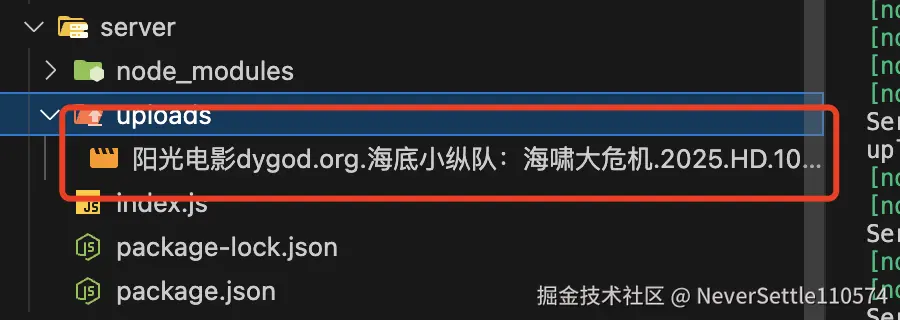
此时服务器会多一个文件出来
- 当文件只上传了一半(上传一半刷新页面或者断网)
此时的服务器存的是部分切片数据

- 当我们再次上传时,调用校验接口
校验接口会返回已经上传了的分片的下坐标 
此时前端会做处理,需要将还没上传的切片继续上传
全部上传完成后对文件进行合并