系列文章目录
文章目录
- 系列文章目录
- 前言
- 零、数据库性能指标
- 一、mysql高延迟排查思路
- 二、解决方案一
- 三、解决方案二
-
-
- 3.1、查看指定库下的所有表的表结构,确认是否存在主键id
- 3.2、在主库执行增加无意义的自增主键sql
- [3.3、从库kill 掉当前执行的进程id](#3.3、从库kill 掉当前执行的进程id)
- 3.4、在从库再次进行以下操作
- 3.5、问题分析
-
- 四、解决方案三
- 总结
前言
在之前项目维护中遇到过一个问题,环境: 基于GTID搭建的主从mysql数据库,版本5.7.32,服务器配置8C 16G 500G数据盘<SSD盘>
现象: 在最近这两天,prometheus监控告警频发mysql从库,主从同步延时过高,配置的延时阈值是300秒,通过监控和在从数据库服务器上执行show slave status\G命令后,发现主从延时高达4784150秒,这严重的超过了阈值,而且执行的是delete删表语句,且该表数据只有50w~100w左右,这么大的延迟而且数据量不大的情况下执行delete都这么长时间,那么相当于从服务器早已夯死,只有一个主库运行。给项目带来了极大的风险,容易造成单点故障,在解决了此问题后,补充一篇文章进行分享。
提示:以下是本篇文章正文内容,下面案例可供参考
结合顶部之前写的初步排查方案,本篇文章进行细节补充和解决方案补充
零、数据库性能指标
| 指标 | 英文含义 | 说明 |
|---|---|---|
| QPS | Query Per Second | 数据库每秒执行的SQL数,包含insert、select、update、delete等。 |
| TPS | Transaction Per Second | 数据库每秒执行的事务数,每个事务中包含18条SQL语句。 |
| 磁盘IOPS | Input/Output Per Second | 即每秒的输入输出量(或读写次数),是衡量磁盘性能的主要指标之一 |
一、mysql高延迟排查思路
yml
1、数据库服务磁盘IO性能测试
2、数据库服务器网络测试
3、检查数据库err日志及messages日志.通过相关错误日志调整数据库配置参数
4、数据库性能测试,检查QPS、TPS
5、检查数据库进程、以及事务,根据查找出来的表查看表结构,检查是否存在索引、主键ID如果以上5步曲都没有问题,那么启动终极大招换服务器,重新搭建主从
1、sysbench工具安装
1.1、yum方式在线安装
shell
yum -y install sysbench1.2、离线安装
shell
#在可以出公网的机器上使用以下命令进行下载,将下载好的rpm包保存到本地后再上传到对应的数据库服务器上
yum -y install sysbench --downloadonly --downloaddir=/tmp/1.3、sysbench简介
yaml
sysbench 支持以下几种测试模式:
1、CPU 运算性能
2、磁盘 IO 性能
3、调度程序性能
4、内存分配及传输速度
5、POSIX 线程性能--互斥基准测试
6、数据库性能(OLTP 基准测试) #本次使用OLTP基准测试
yaml
sysbench其余相关测试方法详解可见下方地址:
https://blog.csdn.net/oschina_41731918/article/details/1280005932、主从延时过高问题排查流程
2.1、登录从库查看从库状态、事务及相关进程
sql
mysql> show slave status\G;
....
Seconds Behind Master: 4784150 #主从同步延时时间(秒)
....
sql
mysgl> select * from information_schema.innodb_trx\G; #查看是否存在大事务
trx_id: 444902200
trx_state: RUNNING #事务执行状态
trx_started: 2024-09-10 08:26:26 #事务开始执行时间
trx_requested_lock_id: NULL
trx_wait_started: NULL
trx_weight: 137910
trx_mysql_thread_id: 15
trx_query: DELETE FROM wggl_sjgdxq #事务执行的具体sql
trx_operation_state: NULL
trx_tables_in_use: 1
trx_tables_locked: 1
trx_lock_structs: 1111
trx_lock_memory_bytes: 123088
trx_rows_locked: 136799
trx_rows_modified: 136799
trx_concurrency_tickets: 0
trx_isolation_level: READ CoMMITTED
trx_unique_checks: 1
trx_foreign_key_checks: 1
trx_last_foreign_key_error: NULL
trx_adaptive_hash_latched: 0
trx_adaptive hash_timeout: 0
trx is_read only: 0
trx autocommit_ non_locking: 0
1 row in set (0.00 sec)
ERROR:
No query specified
sql
mysql> select * from information_schema.processlist where info is not null; #查看不为空的进程
sql
mysql> select count(*) from wggl_sjgdxq; #数据量大约为50万条
yaml
从上述排查看到,主从同步延时是因为这个大事务导致的,但是从这个事务开始执行的时间到问题排查时间,也远远达不到4784150秒,这个时间对不上,因此可能还存在其他问题,因此继续走排查流程2.2、查看服务器磁盘、cpu等信息
shell
[root@mysql2 ~]# iostat -xmt 3
[root@mysql2 ~]# top
yaml
关键监控指标解析:
%util: 被I/O操作消耗的CPU百分比。理想情况下应小于80%,超过90%表明磁盘接近饱和,无法处理更多I/O请求。例如当运行高负载fio测试时,若%util持续接近100%,则表明磁盘是性能瓶颈。
await: 平均每次设备I/O操作的等待时间(毫秒)。对于SSD正常范围为0.1-1ms;对于HDD正常范围为10-30ms。如果await显著高于svctm(平均服务时间),则表明I/O队列过长,磁盘响应变慢。
r/s和w/s: 每秒完成的读/写操作数直接反映IOPS性能。r/s和w/s的总和即为TPS(每秒事务数)。
rrqm/s和wrqm/s: 每秒合并的读/写请求数。高值表明内核优化了相邻I/O请求,合并为更大的请求,这在顺序读写中常见
从服务器资源使用情况看,8C只用满了1C(因为mysql属于单线程,所以此情况也正常),cpu使用也正常,但是iostat 显示磁盘的读写为0,怀疑是磁盘问题,要不就是当前没有任何读写操作,排除了服务器cpu的问题,接着往下排查数据盘性能问题2.3、使用fio命令压测数据盘性能
2.3.1、安装fio工具
shell
#二进制安装
[root@mysql2 ~]# tar -zxvf fio-3.17.tar.gz
[root@mysql2 ~]# yum install gcc
[root@mysql2 ~]# yum install libaio-devel
[root@mysql2 ~]# cd fio-3.17
[root@mysql2 ~]# ./configure
[root@mysql2 ~]# make && make install
#yum在线安装
[root@mysql2 ~]# yum -y install fio2.3.2、执行磁盘随机读写压测命令
shell
[root@mysql2 ~]# time fio -filename=/export/test_randreadwrite.out -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=10G -numjobs=10 -runtime=60 -group_reporting -name iops_randwrite
#这个 fio 命令将执行一个性能测试,随机读写模式下的测试文件大小为 10 GB,块大小为 16 KB,测试持续 60 秒,使用直接 I/O,且每个线程会处理单个 I/O 请求。测试会以 70% 的读取和 30% 的写入比例来模拟真实的应用负载,并汇总所有线程的性能数据。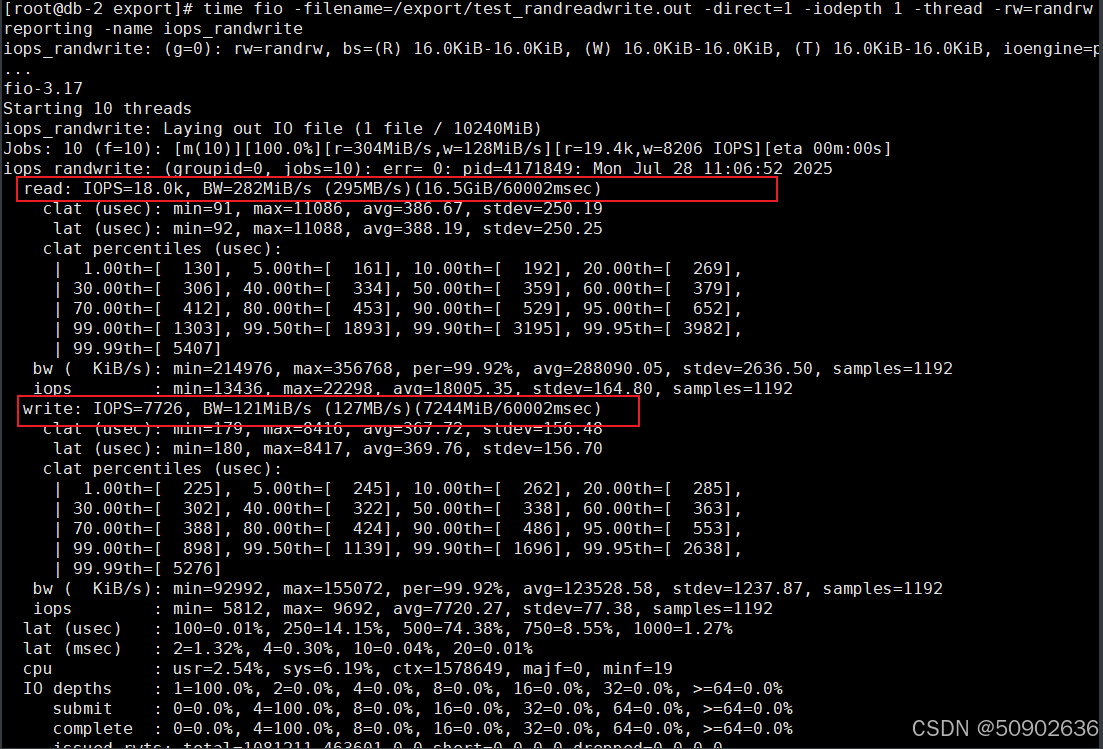
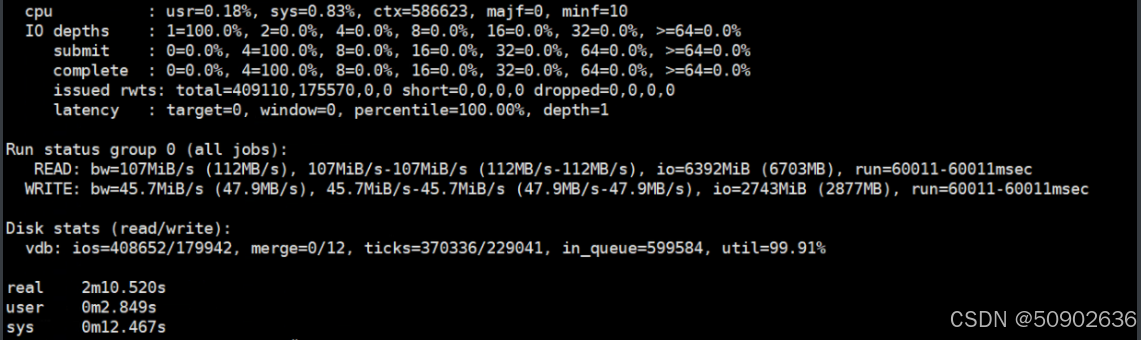
yaml
总结:
fio 结果表明:
读取吞吐量速度: 107 MiB/s (112 MB/s),总共读取了 6392 MiB (6703 MB)。
写入吞吐量速度: 45.7 MiB/s (47.9 MB/s),总共写入了 2743 MiB (2877 MB)。
磁盘利用率: 99.91%,表明磁盘几乎处于满负荷运行状态。
读取 IOPS: 从 vdb 的统计信息中可以计算读取 IOPS。总读取 I/O 操作次数为 408,652 次,运行时间为 60 秒,因此读取 IOPS 为 408562/60=6810(IOPS)
写入 IOPS: 总写入 I/O 操作次数为 179,942 次,运行时间同样为 60 秒,因此写入 IOPS 为 179942/60=2,665 IOPS
延迟: 通常不是直接从 fio 输出中获取的,但可以通过 fio 的 latency 输出或其他工具(如 iostat)来获得。由于你的测试结果中没有直接显示延迟,我们可以从吞吐量和 IOPS 间接推测:
如果吞吐量较高且 IOPS 较低,通常意味着延迟较高,因为每个 I/O 操作花费的时间较长。
如果 IOPS 高且吞吐量也高,则延迟通常较低,因为磁盘能迅速处理每个 I/O 操作。
从分析来看读取吞吐量较高,但写入吞吐量相对较低。这个不平衡可能表明写入操作的延迟较高。但是从主从同步延时的sql语句查看,执行的也是insert或update操作,而是delete操作