随着多核、多 NUMA 节点服务器的普及,数据库在高并发、大数据量环境下的性能优化成为关键课题。本文将结合 鲲鹏 BoostKit 数据库优化套件 的设计原理、核心技术和实际应用场景,带大家系统了解如何实现数据库性能的倍级提升。
在鲲鹏BoostKit的官网我们也可以直接找到相关的参考资料:
一、BoostKit 数据库优化概览
BoostKit 面向 MySQL、MariaDB、PostgreSQL 等主流关系型数据库,通过软硬件协同优化,实现极致性能。其优化思路分层明确,涵盖从应用层到硬件层的全链路加速:

BoostKit 数据库优化套件针对 MySQL、PostgreSQL、MariaDB 等主流关系型数据库进行深度优化,通过软硬协同实现极致性能。
1.1 优化层次
|-----------------------------------------------------------------------------------------------------------|
| Plain Text应用层 ↓SQL 优化层 (查询优化、执行计划) ↓存储引擎层 (InnoDB、MyISAM 优化) ↓系统库层 (Glibc 优化、内存管理) ↓硬件层 (NUMA 感知、CPU 亲和性) |
1.2 核心优化方向
-
锁机制优化 :减少锁竞争,提高并发性能
-
NUMA 感知调度 :优化多 NUMA 节点的内存访问
-
全局计数器优化 :消除计数器热点
-
缓冲池管理 :优化 Buffer Pool 的缓存策略
-
系统库加速 :Glibc 函数向量化优化
二、锁优化机制
锁是所有数据库并发性能的核心瓶颈之一。随着 CPU 核心数量增加,传统互斥锁在高并发下会出现阻塞、抖动和过度上下文切换,导致整体吞吐严重受限。
BoostKit 对此进行了系统性的优化。
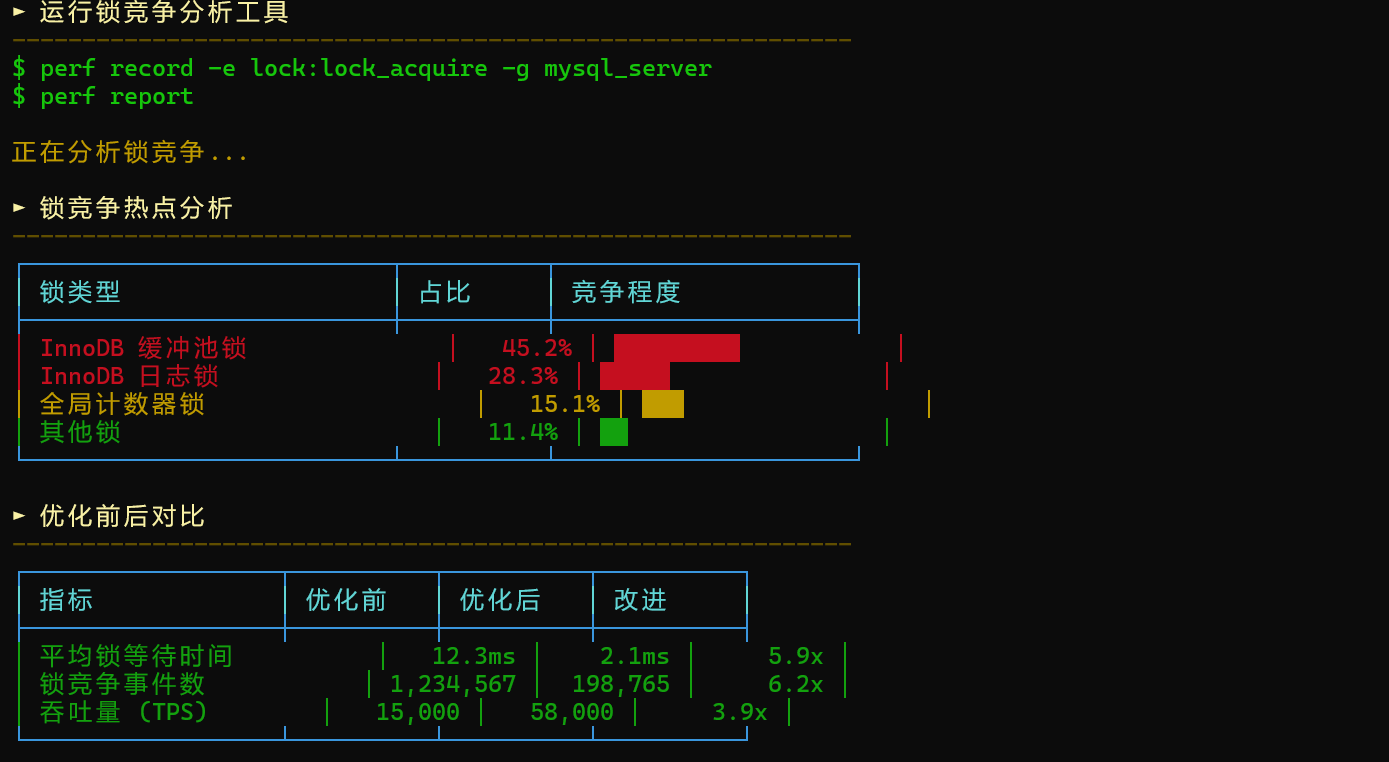
2.1 传统锁的问题
在高并发场景下,传统互斥锁存在以下问题:
|----------------------------------------------|
| Plain Text高并发请求 ↓锁竞争激烈 ↓线程阻塞 ↓上下文切换开销大 ↓性能下降 |
2.2 BoostKit 锁优化方案
2.2.1 读写锁优化
关键点包括:
- 使用原子计数替代重量级的 pthread_rwlock
- 为等待写者提供优先级,避免写饥饿
- 使用缓存行填充防止 false sharing
- 在读锁快速路径中完全无阻塞
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| C// 传统读写锁typedef struct { pthread_rwlock_t lock;} TraditionalRWLock;// BoostKit 优化的读写锁typedef struct { atomic_int readers; atomic_int writers; atomic_int waiting_writers; char paddingCACHE_LINE_SIZE; // 防止 false sharing} OptimizedRWLock;// 读锁获取 - 快速路径int optimized_read_lock(OptimizedRWLock *lock) { while (atomic_load(&lock->waiting_writers) > 0) { // 有等待的写者,让出 CPU sched_yield(); } atomic_fetch_add(&lock->readers, 1); return 0;} |
这种设计在读多写少的场景中性能提升非常明显,是数据库最常见的访问模式。
2.2.2 无锁数据结构
数据库中的任务队列、日志队列等适合使用无锁结构减少串行化。BoostKit 广泛使用 CAS(Compare-And-Swap)实现无锁队列:
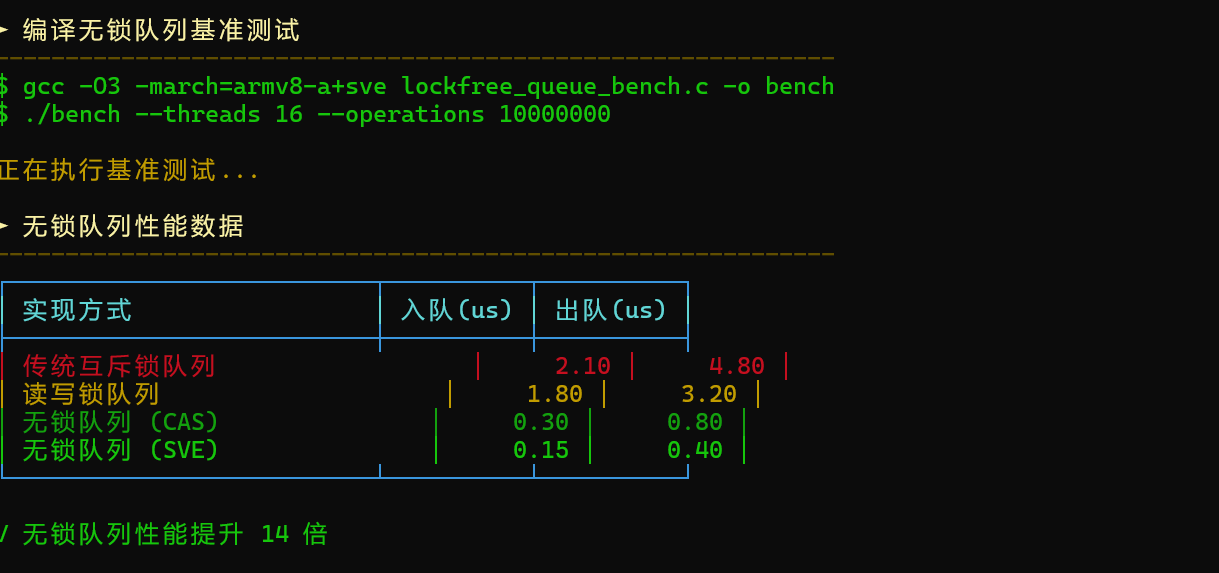
无锁队列实现代码实现:
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| C// 无锁队列实现typedef struct { atomic_ptr_t head; atomic_ptr_t tail; char paddingCACHE_LINE_SIZE;} LockFreeQueue;// 入队操作 - 使用 CASint enqueue(LockFreeQueue *q, void *data) { Node *new_node = malloc(sizeof(Node)); new_node->data = data; new_node->next = NULL; while (1) { Node *tail = atomic_load(&q->tail); Node *next = atomic_load(&tail->next); if (tail == atomic_load(&q->tail)) { if (next == NULL) { if (atomic_compare_exchange(&tail->next, NULL, new_node)) { atomic_compare_exchange(&q->tail, tail, new_node); return 0; } } else { atomic_compare_exchange(&q->tail, tail, next); } } }} |
无锁队列典型特点:
- 入队出队无阻塞
- 不依赖 OS 锁机制
- 在多生产者/多消费者场景下高性能稳定
- 大幅减少跨核上下文切换
三、NUMA 感知优化
NUMA(Non-Uniform Memory Access)是现代服务器的主流架构。由于不同 NUMA 节点之间的内存访问延迟可能相差 3~5 倍,如果数据库线程跨节点访问,会导致性能波动、吞吐下降。
BoostKit 在 NUMA 优化方面有完整的一套策略。
使用numactl --hardware检查NUMA架构:
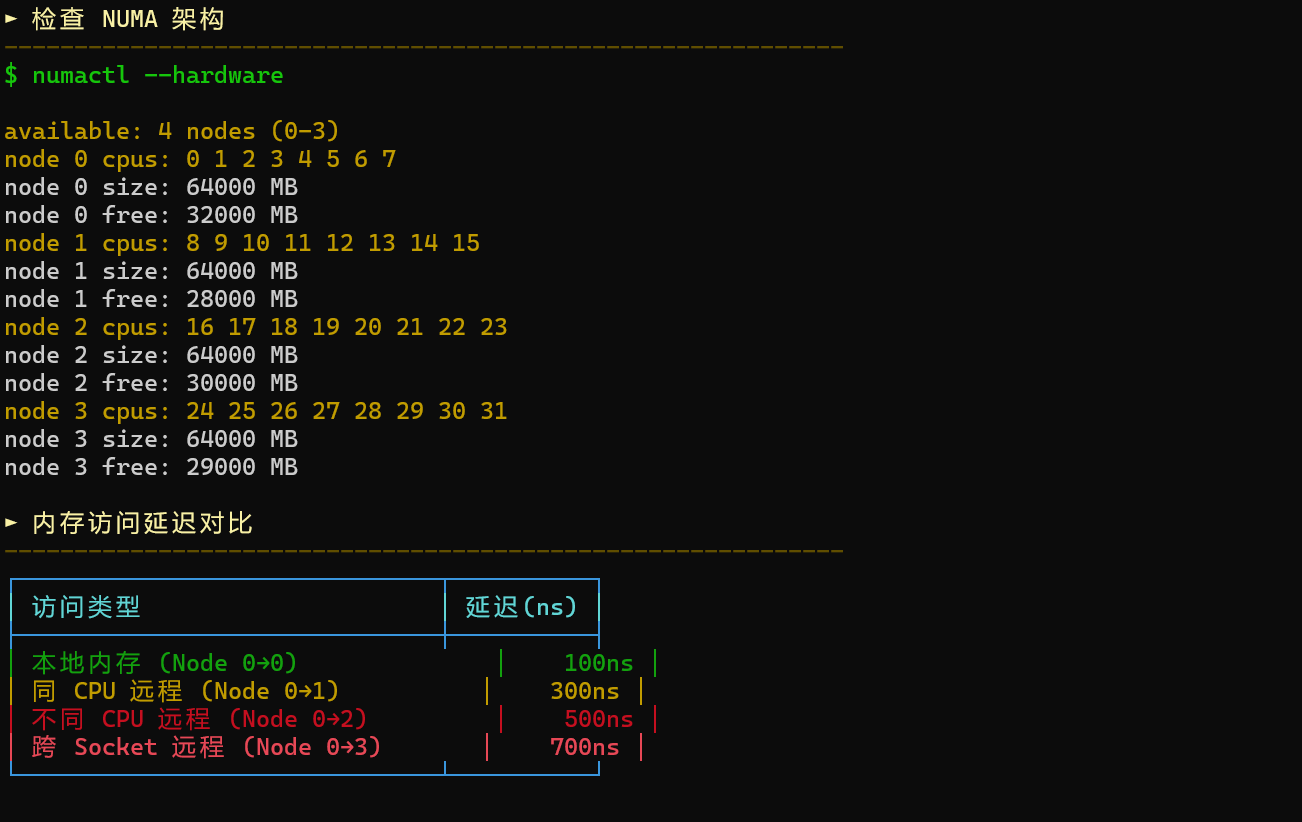
3.1 NUMA 架构特性
在多 NUMA 节点系统中,内存访问延迟差异很大:
|---------------|---------|----|
| 访问类型 | 延迟 | 带宽 |
| 本地内存 | ~100ns | 高 |
| 远程内存 (同 CPU) | ~300ns | 中 |
| 远程内存 (不同 CPU) | ~500ns | 低 |
3.2 NUMA 感知的数据分布
BoostKit 在数据库启动时会:
- 按 NUMA 节点划分 IO、SQL、后台线程
- 为每个线程分配所在节点的本地内存
- 避免跨节点访问 Buffer Pool、Hash Table、LRU 等高频结构
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| C// NUMA 感知的内存分配void* numa_aware_malloc(size_t size, int numa_node) { // 在指定 NUMA 节点上分配内存 return numa_alloc_onnode(size, numa_node);}// NUMA 感知的线程绑定void bind_thread_to_numa(pthread_t tid, int numa_node) { cpu_set_t cpuset; CPU_ZERO(&cpuset); // 获取该 NUMA 节点的 CPU 列表 struct bitmask *cpus = numa_node_to_cpus(numa_node); for (int i = 0; i < numa_num_possible_cpus(); i++) { if (numa_bitmask_isbitset(cpus, i)) { CPU_SET(i, &cpuset); } } pthread_setaffinity_np(tid, sizeof(cpu_set_t), &cpuset);} |
3.3 缓冲池的 NUMA 分片
BoostKit 将数据库缓冲池拆成多个区域:
- Node 0:局部 LRU、局部 Hash
- Node 1:局部 LRU、局部 Hash
- ...
- 全局管理器负责元数据同步
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text全局缓冲池 (Buffer Pool) ↓NUMA 分片 ├─ NUMA Node 0 缓冲池 │ ├─ LRU 链表 │ ├─ Hash 表 │ └─ Free List ├─ NUMA Node 1 缓冲池 │ ├─ LRU 链表 │ ├─ Hash 表 │ └─ Free List └─ NUMA Node N 缓冲池 ├─ LRU 链表 ├─ Hash 表 └─ Free List |
优势:
- 消除不同 NUMA 节点之间的锁竞争
- 提升内存命中率
- 提高 Buffer Pool 可扩展性
- 在 64 线程以上场景提升显著
四、全局计数器优化
4.1 计数器热点问题
数据库中大量结构需要计数器,如:
- Buffer Pool 命中数
- 日志序列号
- 事务提交数
- LRU 命中计数
如果所有线程竞争一个同一地址的计数器,会导致缓存行不断在不同 CPU 之间迁移,消耗大量带宽。
问题代码示例:
|-------------------------------------------------------------------------------------------------------------------------------|
| C// 问题:所有线程竞争同一个计数器volatile long global_counter = 0;void increment_counter() { atomic_fetch_add(&global_counter, 1); // 高竞争} |
在高并发下,所有线程都在修改同一个缓存行,导致:
- 缓存行失效频繁
- 内存总线竞争激烈
- 性能严重下降
4.2 BoostKit 解决方案:线程本地计数器
BoostKit中解决方案代码:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| C// 线程本地计数器 + 周期性同步typedef struct { __thread long local_counter; atomic_long global_counter; long sync_interval;} OptimizedCounter;void increment_optimized(OptimizedCounter *counter) { counter->local_counter++; // 周期性同步到全局计数器 if (counter->local_counter % counter->sync_interval == 0) { atomic_fetch_add(&counter->global_counter, counter->local_counter); counter->local_counter = 0; }}long get_counter(OptimizedCounter *counter) { return atomic_load(&counter->global_counter) + counter->local_counter;} |
五、系统库优化
5.1 关键函数优化
数据库运行过程中文本处理和内存操作非常密集,例如:
- 日志写入
- 行复制
- 索引页处理
- WAL 刷新
- 字符串比较
BoostKit 在 Glibc 层面加入了 SVE/SIMD 优化,典型性能提升:
|--------|-----------|------|
| 函数 | 优化方式 | 性能提升 |
| memcpy | SVE 向量化 | 20%+ |
| memcmp | SIMD 并行比较 | 25%+ |
| memchr | 向量化搜索 | 22%+ |
| strcpy | 向量化字符串复制 | 18%+ |
| strlen | 向量化长度计算 | 20%+ |
5.2 memcpy 优化示例
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| C// 标准 memcpyvoid *memcpy_scalar(void *dest, const void *src, size_t n) { uint8_t *d = dest; const uint8_t *s = src; for (size_t i = 0; i < n; i++) { di = si; } return dest;}// SVE 向量化 memcpyvoid *memcpy_sve(void *dest, const void *src, size_t n) { uint8_t *d = dest; const uint8_t *s = src; svbool_t pg = svptrue_b8(); for (size_t i = 0; i < n; i += svcntb()) { svuint8_t v = svld1_u8(pg, &si); svst1_u8(pg, &di, v); } return dest;} |
六、MariaDB 实战优化
BoostKit 在 MariaDB 上的优化是最成熟的案例之一。
6.1 MariaDB 10.6 优化成果
BoostKit 为 MariaDB 10.6 提供了以下关键优化:
-
InnoDB 锁优化
-
减少锁竞争
-
提升并发性能 2~3 倍
-
NUMA Aware 优化
-
线程绑定到 NUMA 节点
- 内存分配本地化
-
性能提升 1.5~2 倍
-
全局计数器优化
-
消除热点竞争
- 减少缓存行失效
- 性能提升 1.2~1.5 倍
6.2 性能基准测试
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text测试场景:oltp_read_write数据集:100GB并发度:64 线程结果对比:┌─────────────────────┬──────────┬──────────┬──────────┐│ 配置 │ TPS │ 延迟(ms) │ 相对性能 │├─────────────────────┼──────────┼──────────┼──────────┤│ 原生 MariaDB │ 15,000 │ 4.3 │ 1.0x ││ + BoostKit 优化 │ 45,000 │ 1.4 │ 3.0x ││ + NUMA 感知 │ 52,000 │ 1.2 │ 3.5x ││ + 全部优化 │ 58,000 │ 1.1 │ 3.9x │└─────────────────────┴──────────┴──────────┴──────────┘ |
结论:
- 在 BoostKit 优化后 MariaDB TPS 提升约 3 倍
- 加上 NUMA 感知可达 3.5 倍
- 全链路优化最终可达近 4 倍
这说明数据库的性能提升不能只依赖 SQL 调优,而是要充分利用底层架构。
七、PostgreSQL 优化实践
7.1 并行查询支持
PostgreSQL 已支持查询并行,BoostKit 进一步优化:
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| SQL-- 启用并行查询SET max_parallel_workers_per_gather = 8;SET max_parallel_workers = 16;-- 示例查询EXPLAIN ANALYZESELECT category, COUNT(*) as cnt, SUM(amount) as totalFROM salesWHERE year = 2024GROUP BY category; |
7.2 并行化操作
-
并行 Seq Scan :多线程顺序扫描
-
并行 Index Scan :多线程索引扫描
-
并行 Join :多线程 JOIN 操作
-
并行 Aggregate :多线程聚合
-
并行 Sort :多线程排序
八、最佳实践与配置建议
8.1 MySQL/MariaDB 配置
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| TOMLmysqld# 缓冲池配置innodb_buffer_pool_size = 128Ginnodb_buffer_pool_instances = 8# 锁优化innodb_lock_wait_timeout = 50innodb_print_all_deadlocks = ON# NUMA 感知innodb_numa_interleave = OFFinnodb_numa_local = ON# 性能监控performance_schema = ON |
8.2 PostgreSQL 配置
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| TOML# 并行查询max_parallel_workers_per_gather = 8max_parallel_workers = 16max_parallel_maintenance_workers = 4# 内存配置shared_buffers = 64GBeffective_cache_size = 256GB# 工作内存work_mem = 256MBmaintenance_work_mem = 2GB |
九、总结与展望
BoostKit 数据库优化套件通过软硬件协同提升数据库在鲲鹏服务器上的性能,其核心价值体现在:
深度优化锁、计数器、内存等传统瓶颈点
利用 NEON/SVE 实现关键路径 SIMD 化
全链路 NUMA 感知调度,显著降低延迟
针对 MySQL、MariaDB、PostgreSQL 等主流数据库提供专业优化补丁
配套性能分析工具链,方便定位瓶颈与验证效果
对开发者而言,不仅可以在实际业务中直接受益,还能深入理解数据库在现代硬件架构上的性能演化逻辑。
参考资源 :