1.什么是****Elastic Stack
如果系统和应用出现异常和问题,相关的开发和运维人员想要排查原因,就要先登录到应用运行所相应的主机,找到上面的相关日志文件再进行查找和分析,所以非常不方便,此外还会涉及到权限和安全问题,而ELK 的出现就很好的解决这一问题。
ELK 是由一家 Elastic 公司开发的三个开源项目的首字母缩写,即是三个相关的项目组成的系统。
2.Elasticsearch 索引是什么?
Elasticsearch 索引指相互关联的文档集合。Elasticsearch 会以 JSON 文档的形式存储数据。每个文档都会在一组键(字段或属性的名称)和它们对应的值(字符串、数字、布尔值、日期、数值组、地理位置或其他类型的数据)之间建立联系。
Elasticsearch 使用的是一种名为倒排索引的数据结构,这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。
在索引过程中,Elasticsearch 会存储文档并构建倒排索引,这样用户便可以近实时地对文档数据进行搜索。索引过程是在索引 API 中启动的,通过此 API 您既可向特定索引中添加 JSON 文档,也可更改特定索引中的 JSON 文档。
3.Logstash 的用途是什么?
Logstash 是 Elastic Stack 的核心产品之一,可用来对数据进行聚合和处理,并将数据发送到 Elasticsearch。Logstash 是一个开源的服务器端数据处理管道,允许您在将数据索引到Elasticsearch 之前同时从多个来源采集数据,并对数据进行充实和转换。
4.Kinbana的用途是什么?
是适用于 Elasticsearch 的数据可视化和管理工具,可提供实时直方图、线形图、饼状图和地图 ;包含 Canvas(允许用户基于自身数据创建定制动态信息图表 )、Elastic Maps(对地理空间数据可视化 )等高级应用程序 。
总结如下:
①Elasticsearch 是一个实时的全文搜索 , 存储库和分析引擎。
②Logstash 是数据处理的管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如Elasticsearch 等存储库中。
③Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
5.Elasticsearch集群安装
cluster.name: my-application
node.name: node-1 #不唯一。在其他主机上需要更改不一样的名字 其他的都不变
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
discovery.seed_hosts: ["10.0.0.101", "10.0.0.102", "10.0.0.103"]
cluster.initial_master_nodes: ["10.0.0.101", "10.0.0.102", "10.0.0.103"]
xpack.security.enabled: false
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
enabled: true
keystore.path: certs/http.p12
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
http.host: 0.0.0.0curl 'http://127.0.0.1:9200/_cat/health' #查看es集群状态
创建索引
curl -XPUT '127.0.0.1:9200/index1' #简单输出
curl -XPUT '127.0.0.1:9200/index2?pretty' #格式化输出
查看索引
curl 'http://127.0.0.1:9200/_cat/indices?v' #查看所有索引
删除索引
curl -XDELETE 'http://127.0.0.1:9200/index1' #删除索引index1
在索引index1上创建3个分片和2个副本的索引
curl -XPUT '127.0.0.1:9200/index1' \
-H 'Content-Type: application/json' \
-d '{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
}'调整索引index1副本数为1,但不能调整分片数
curl -XPUT '127.0.0.1:9200/index1/_settings' \
-H 'Content-Type: application/json' \
-d '{
"settings": {
"number_of_replicas": 1
}
}'6.Elasticsearch****插件
ES 集群状态 :
green 绿色状态 : 表示集群各节点运行正常,而且没有丢失任何数据,各主分片和副本分片都运行正
常。
yellow 黄色状态 : 表示由于某个节点宕机或者其他情况引起的, node 节点无法连接、所有主分片都
正常分配 , 有副本分片丢失,但是还没有丢失任何数据。
red 红色状态 : 表示由于某个节点宕机或者其他情况引起的主分片丢失及数据丢失 , 但仍可读取数据
和存储 监控下面两个条件都满足才是正常的状态。
集群状态为 green 所有节点都启动。
Cerebro 插件
Cerebro 是开源的 elasticsearch 集群 Web 管理程序,此工具应用也很广泛,此项目升级比 Head 频繁。Cerebro v0.9.4 版本更高版本需要 Java11。 基于java环境。
相关下载链接:wget https://githubfast.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro_0.9.4_all.deb
访问下面链接地址
http://10.0.0.101:9000 #我是在101主机上安装的cerebro插件
在 Node address 输入框中输入任意 ES 集群节点的地址
7.ES****文档路由
ES 文档路由原理
ES 文档是分布式存储,当在 ES 集群访问或存储一个文档时,由下面的算法决定此文档到底存放在哪个主分片中, 再结合集群状态找到存放此主分片的节点主机。
shard = hash(routing) % number_of_primary_shards
hash # 哈希算法可以保证将数据均匀分散在分片中
routing # 用于指定用于 hash 计算的一个可变参数,默认是文档 id ,也可以自定义
number_of_primary_shards # 主分片数
注意:该算法与主分片数相关,一旦确定后便不能更改主分片,因为主分片数的变化会导致所有分片需要重新分配
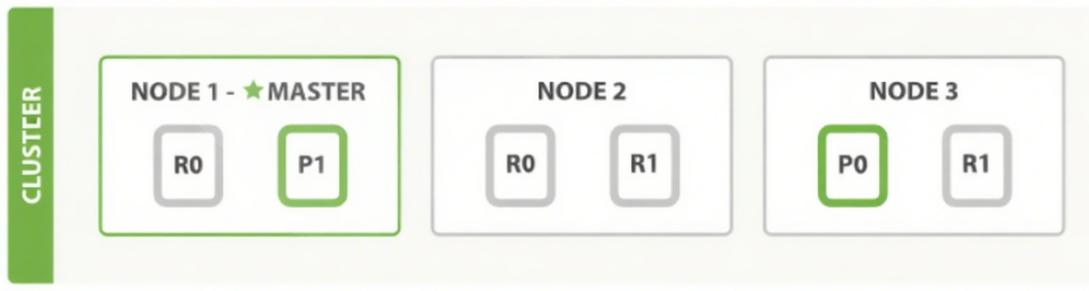
可以发送请求到集群中的任一节点。每个节点都知道集群中任一文档位置, 每个节点都有能力接收请求 , 再接将请求转发到真正存储数据的节点上
ES 文档创建删除流程
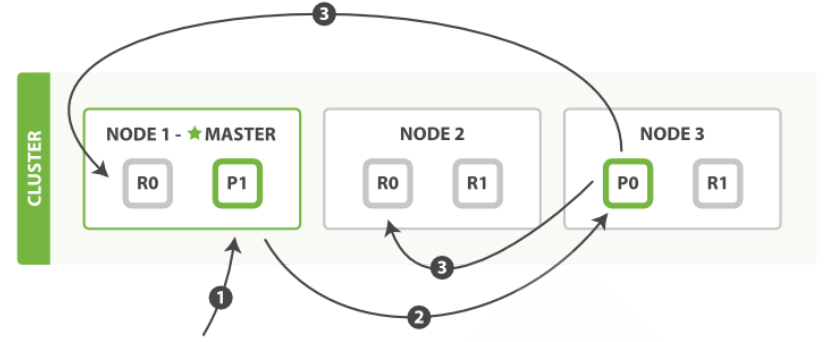
客户端向集群中某个节点 Node1 发送新建索引文档或者删除索引文档请求
Node1 节点使用文档的 _id 通过上面的算法确定文档属于分片 0
因为分片 0 的主分片目前被分配在 Node3 上 , 请求会被转发到 Node3
Node3 在主分片上面执行创建或删除请求
Node3 执行如果成功,它将请求并行转发到 Node1 和 Node2 的副本分片上
Node3 将向协调节点 Node1 报告成功
协调节点 Node1 客户端报告成功。
ES 文档读取流程
可以从主分片或者从其它任意副本分片读取文档 ,读取流程如下图所示 :
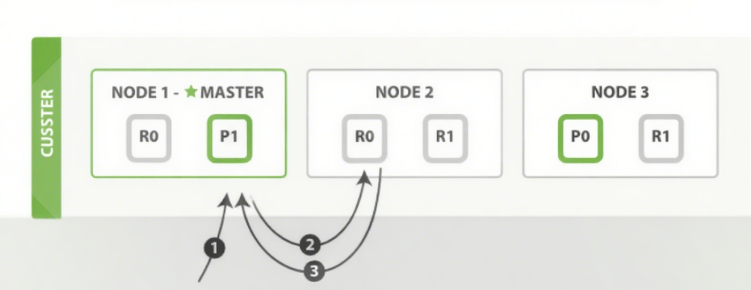
·客户端向集群中某个节点 Node1 发送读取请求。
·节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的主副本分片存在于所有的三个节点上。
·在处理读取请求时,协调节点在每次请求的时候都会通过轮询所有的主副本分片来达到负载均衡,此次它将请求转发到 Node2。
·Node2 将文档返回给 Node1 ,然后将文档返回给客户端。
8.集群的扩缩容
扩容: 在两个新主机上安装 ES。配置文件只更改 node .name和添加discovery.seed_hosts 的ip。
缩容:删除ES或者停止ES服务。
注意:停止服务前,要观察索引的情况,按一定顺序关机,即先关闭一台主机,等数据同步完成后,再 关闭第二台主机,防止数据丢失。
9.Elasticsearch****数据冷热分离
原理:在 Elasticsearch 中, 冷热分离的核心原理是基于数据的 "访问热度"(访问频率、时效性、读写需求)差异,结合硬件性能、索引特性和集群调度机制,实现数据在不同类型节点间的分层存储与管理。其本质是通过 "差异化资源匹配" 和 "自动化生命周期调度",平衡性能需求与成本控制。
-
热数据 :刚产生的数据(如最近 1 天的日志),需要高频写入、实时查询、快速响应,因此对存储的IOPS(每秒输入输出次数) 、延迟 (读写响应时间)和计算能力(CPU、内存)要求极高。
-
冷数据 :历史归档数据(如超过 30 天的日志),仅偶尔查询、几乎不写入,对存储性能要求低,但需要大容量、低成本 的存储介质。
通过配置节点属性(
node.attr),将集群节点划分为不同角色,明确数据存储的目标节点: -
热节点 :配置
node.attr.box_type: hot,通常搭载 SSD 存储(提供高 IOPS、低延迟),分配更多 CPU 和内存资源,优先处理写入和高频查询。 -
冷节点 :配置
node.attr.box_type: cold,通常使用 HDD 存储(大容量、低成本),CPU 和内存配置较低,仅处理低频查询。
Elasticsearch 支持给节点打标签,具体方式是在 elasticsearch.yml文件中增加:
node .attr.{attribute}: {value}
其中 attribute 为用户自定义的任意标签名, value 为该节点对应的该标签的值
查看分片分配
GET _cat/shards/hot_warm_test_index?v &h = index,shard,prirep,node &s = node
10.Beats****收集数据
关于:Beats 是一个免费且开放的平台,集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。 虽然利用 logstash 就可以收集日志,功能强大,但由于 Logstash 是基于Java实现,需要在采集日志的主机上安装JAVA环境。logstash运行时最少也会需要额外的500M的以上的内存,会消耗比较多的内存和磁盘空间,
可以采有基于 Go 开发的 Beat 工具 代替 Logstash 收集日志 ,部署更为方便,而且只占用 10M 左右的内存空间及更小的磁盘空间。
官方链接 https://www.elastic.co/cn/beats/
Github 链接 https://github.com/elastic/beats
下载链接 https://www.elastic.co/cn/downloads/beats
Beats 是一些工具集 , 其中 filebeat 应用最为广泛。这里以filebeats为例。
注意 : Beats 版本要和 Elasticsearch 相同的版本,否则可能会出错
11.Filebeat,Elasticsearch,Kibana 三者之间的关系
| 组件 | 核心角色 | 功能定位 | 在流程中的位置 |
|---|---|---|---|
| Filebeat | 轻量级数据采集器(日志为主) | 部署在产生日志的服务器 / 设备上,实时收集日志文件(如系统日志、应用日志),并转发到 Elasticsearch 或 Logstash。 | 数据入口(前端采集) |
| Elasticsearch | 分布式搜索引擎 / 数据库 | 接收并存储采集到的数据(日志、指标等),提供高效的全文检索、聚合分析能力(如按时间统计错误日志数量)。 | 数据存储与计算中心 |
| Kibana | 数据可视化与管理平台 | 连接 Elasticsearch,通过界面化工具(如仪表盘、图表、搜索框)展示数据,支持日志查询、趋势分析、告警配置等。 | 数据出口(用户交互与可视化) |
12.filebeat的一些相关配置和设置
解析文本,不能解析 json 格式文本
vim /etc/filebeat/stdin.yml
filebeat.inputs:
- type: stdin
enabled: true
tags: ["stdin-tags", "myapp"] # 添加新字段名tags,可以用于判断不同类型的输入,实现不同的输出
fields:
status_code: "200" # 添加新字段名fields.status_code,可以用于判断不同类型的输入,实现不同的输出
author: "becareful"
output.console:
pretty: true
enable: true语法检查
filebeat test config -c stdin.yml #stdin.yml 的相对路径是相对于 /etc/filebeat 的路径
执行读取
①解析文本,不能解析json 格式文本
filebeat -e -c stdin.yml (通过-e参数强制将 Filebeat 的所有日志输出到标准错误(stderr) )
.....
nihao,haha # 输入信后再回车 , 输出如下
.....
"message" : "nihao,haha" , # 真正的数据只有此行,其它都是 Filebeat 添加的元数据
.....
② 解析 json 格式文本
vim /etc/filebeat/test.yml
filebeat.inputs:
- type: stdin
json.keys_under_root: true # 解析JSON并将键提升到根级别
output.console:
pretty: truefilebeat -c test.yml
nihao,shuaige
....
"message" : "nihao,shuaige" , # 非 json 不解析
....
{ "name" : "xiaoming" , "age" : "18" , "phone" : "0123456789" } # 输入 json 格式,进行解析
...
解析结果如下(部分截取):

13.案例**:从标准输入读取再输出至Json****格式的文件**
创建配置
filebeat.inputs:
- type: stdin
enabled: true
json.keys_under_root: true # 默认False会将json数据存储至message,true则会将数据以独立字段存储,并且删除message字段,如果是文本还是放在message字段中
output.file:
path: "/tmp"
filename: "filebeat.log"filebeat -e -c /etc/filebeat/stdout_file.yml #执行操作
{"name" : "xiaoming", "age" : "18", "phone" : "0123456789"} #输入此项内容
apt -y install jq #Json格式整理
cat /tmp/filebeat.log-20250729.ndjson|jq #查看生成的Json数据 8.X版本
14.案例**:**从文件读取再输出至标准输出
注意**:当前filebeat-9.X****文件读出有bug**
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-input-log.html
filebeat 会将每个文件的读取数据的相关信息记录在 /var/lib/filebeat/registry/filebeat/log.json 文
件中 , 可以实现日志采集的持续性 , 而不会重复采集
当日志文件大小发生变化时, filebeat 会接着上一次记录的位置继续向下读取新的内容
当日志文件大小没有变化,但是内容发生变化, filebeat 会将文件的全部内容重新读取一遍
创建配置 vim /etc/filebeat/file.yml
filebeat.inputs:
- type: filestream # 此指令配置json.keys_under_root: true 也不支持Json格式解析
# type: log # 旧版,将来废弃
enabled: true
paths:
# - /var/log/syslog
- /var/log/test.log
output.console:
pretty: true
enable: true执行读取
filebeat -e -c /etc/filebeat/file.yml
.....
执行生成文件内容后 echo 'hello,wang' > /var/log/filebeat.log
注意: json 格式最外层必须加单引号 '' ,否则不会解析
root@elk-web1 \~ #echo '{"name" : "xiaoming", "age" : "18", "phone" :
"0123456789"}' >> /var/log/test.log
#filebeat 记录日志文件读取的当前位置,以防止重复读取日志
cat /var/lib/filebeat/registry/filebeat/log.json
15.案例**:利用Filebeat收集系统日志到ELasticsearch**
https://www.elastic.co/guide/en/beats/filebeat/current/elasticsearch-output.html
Filebeat 收集的日志在 Elasticsearch 中默认生成的索引名称为
#8.X新版
.ds-filebeat-<版本>-<时间>-<ID>
#旧版
filebeat-<版本>-<时间>-<ID>修改配置
方法1:
cp /etc/filebeat/filebeat.yml{,.bak} #备份
vim /etc/filebeat/filebeat.yml
删除原有内容添加下面的内容
filebeat.inputs:
- type: log
json.keys_under_root: true
enabled: true # 开启日志
paths:
- /var/log/syslog # 指定收集的日志文件
# -------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
hosts: ["10.0.0.101:9200", "10.0.0.102:9200", "10.0.0.103:9200"] # 指定ELK集群任意节点的地址和端口,多个地址容错方法2:
#或者修改syslog.conf
root@elk-web1 \~#vim /etc/rsyslog.conf #收集操作系统的日志 可不修改
*.* /var/log/system.log
root@elk-web1 \~#systemctl restart rsyslog.service
root@elk-web1 \~#vim /etc/filebeat/filebeat.yml
/var/log/system.log #指定收集的日志文件 唯一不一样的地方,其他同上
root@elk-web1 \~#systemctl enable --now filebeat.service
root@elk-web1 \~ #echo '{"name" : "xiaoming", "age" : "18", "phone" :
"1234567890"}' >> /var/log/system.log
插件查看索引
测试用 ssh 登录 , 用插件查看日志
注意 :8.X 版后索引名默认为 .ds-filebeat---
通过 Kibana 查看收集的日志信息
下载安装Kibana( 注意kibana和elasticsearch的兼容性,最好是两个在同一版本)
Download Kibana Free | Get Started Now | Elastic
Past Releases of Elastic Stack Software | Elastic #以往的版本
16.案例**:自定义索引名称收集日志到ELasticsearch**
修改配置
范例:自定义索引名称收集所有系统日志到 ELasticsearch
root@elk-web1 \~ #vim /etc/rsyslog.conf
.....
*.* /var/log/system.log
root@elk-web1 \~ #systemctl restart rsyslog
root@elk-web1 \~ #vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
json.keys_under_root: true
enabled: true # 开启日志采集
paths:
- /var/log/system.log # 指定要收集的日志文件路径
include_lines: # 只过滤包含指定关键字的日志行
- 'sshd'
- 'failed'
- 'password'
# include_lines: ['^ERR', '^WARN'] # 可按需启用,只过滤包含指定关键字的日志行
# exclude_lines: ['Debug'] # 可按需启用,排除包含指定关键字的日志行
# exclude_files: ['.gz$'] # 可按需启用,排除文件名匹配指定规则的日志文件
output.elasticsearch:
hosts: ["10.0.0.101:9200"] # 指定 Elasticsearch 集群的服务器地址和端口
index: "wu-%{[agent.version]}-%{+yyyy.MM.dd}" # 自定义索引名称,8.X 版本生成的索引名形式如 .ds-wang-%{[agent.version]}-日期-日期-00000n
# 由于自定义了索引名称,需配置以下内容,否则 filebeat 可能无法启动
setup.ilm.enabled: false # 关闭索引生命周期管理(ILM)功能,默认开启时索引名受限
setup.template.name: "wu" # 定义模板名称,自定义索引名时必须指定
setup.template.pattern: "wu-*" # 定义模板匹配的索引名称模式,自定义索引名时必须指定
setup.template.settings:
index.number_of_shards: 3 # 设置索引分片数
index.number_of_replicas: 1 # 设置索引副本数默认情况下 Filebeat 写入到 ES 的索引分片为1,副本数为1 ,如果需要修改分片和副本数,可以通过如下实现
#方法1,修改filebeat.yml配置文件,此方式只适合直接连接ES时才有效,适用度不高
#注意:如果模板已经存在,需要先删除模板和索引才能生效,利用kibana或者cerebro(8.X不支持)插件
(more--index templates--existing templates--输入搜索的模板名wu)
vim /etc/filebeat/filebeat.yml
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
#生效后,在cerebro插件中more--index templates--existing templates--输入搜索的模板名
wu中可以看到以下的分片和副本配置,8.X不支持
#settings中number_of_shards和number_of_replication
#方法2:也可以通过修下面方式修改,8.X不支持
1.停止filebeat服务
2.在cerebro web页面修改:修改模板settings 配置,调整分片以及副本
3.删除模板关联的索引
4.启动filebeat产生新的索引例子: 自定义索引名称收集 Nginx 日志到 ELasticsearch
root@elk-web1 \~ #apt update && apt -y install nginx
root@elk-web1 \~ #vim /etc/filebeat/filebeat.yml #wu->nginx ,include_lines未添加 其他参数没变
filebeat.inputs:
- type: log
enabled: true #开启日志
paths:
- /var/log/nginx/access.log #指定收集的日志文件
output.elasticsearch:
hosts: ["10.0.0.101:9200"] #指定ES集群服务器地址和端口
index: "nginx-access-%{[agent.version]}-%{+yyyy.MM.dd}" #自定义索引名称
setup.ilm.enabled: false
setup.template.name: "nginx" #定义模板名称,要自定义索引名称,必须指定此项,否则无法启动
setup.template.pattern: "nginx-*" #定义模板的匹配索引名称,要自定义索引名称,必须指定此项,否则无法启动
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1root@elk-web1 \~ #systemctl enable --now filebeat.service #启动服务
所自定义的索引一般在 /var/log/elasticsearch目录下