一、ELK 要解决什么问题?
在分布式系统中,日志天然存在以下问题:
- 日志分散在多台机器,无法集中管理
- 日志格式不统一(纯文本 / JSON / 混合)
grep等方式不可扩展,无法全局搜索- 无法做聚合分析(趋势、占比、分布)
- 跨服务、跨节点问题定位效率极低
ELK 的本质目标只有一句话:
将"不可分析的日志文本",转化为"可搜索、可聚合、可可视化的数据资产"。
二、ELK 的整体链路
ELK 是一条完整的数据流水线,不是三个孤立组件。
应用系统
↓
日志采集(Filebeat / Agent)
↓
日志处理(Logstash / Ingest Pipeline)
↓
数据存储与分析(Elasticsearch)
↓
数据可视化与运维(Kibana)角色边界非常清晰:
- Filebeat:采集,不处理
- Logstash / Ingest:清洗、结构化
- Elasticsearch:存 + 查 + 聚合
- Kibana:查询构建 + 展示
三、Elasticsearch
1. 定位与特性
Elasticsearch 是一个 基于 Lucene 的分布式搜索与分析引擎,核心能力包括:
- 分布式存储与计算(分片 + 副本)
- 高性能全文检索(倒排索引)
- 近实时搜索(默认 1s refresh)
- 强大的聚合分析能力
- RESTful API(HTTP + JSON)
在 ELK 中:ES 不是数据库,而是"日志分析引擎"
2. 核心数据模型
|----------|----------|
| 概念 | 类比关系型数据库 |
| Cluster | 集群 |
| Node | 实例 |
| Index | 表 |
| Document | 行 |
| Field | 列 |
| Mapping | 表结构 |
索引(Index)
- 日志通常按时间滚动索引
- 示例:
log-order-2025.01.01
文档(Document)
- JSON 格式
- 每条日志一条文档
3. Mapping
Mapping 决定:
- 是否能搜索
- 是否能聚合
- Kibana 是否好用
- 性能是否稳定
最关键的字段类型区分:
|---------|------------|
| 类型 | 用途 |
| text | 全文检索(会分词) |
| keyword | 精确匹配、聚合、排序 |
| date | 时间分析 |
| numeric | 数值计算 |
日志字段 90% 应该是 keyword,不是 text
4. 分片与副本
- Primary Shard:数据写入的最小单位
- Replica Shard:高可用 + 读扩展
工程经验:
- 分片数一旦创建不可修改
- 分片过多 ≠ 性能好(常见性能杀手)
5. 查询与聚合
- 查询:解决"查得到"
- 聚合:解决"看得懂"
常用:
match:全文检索term:精确匹配bool:组合条件terms / avg / sum:聚合分析
Kibana 所有图表,本质都是 ES 聚合
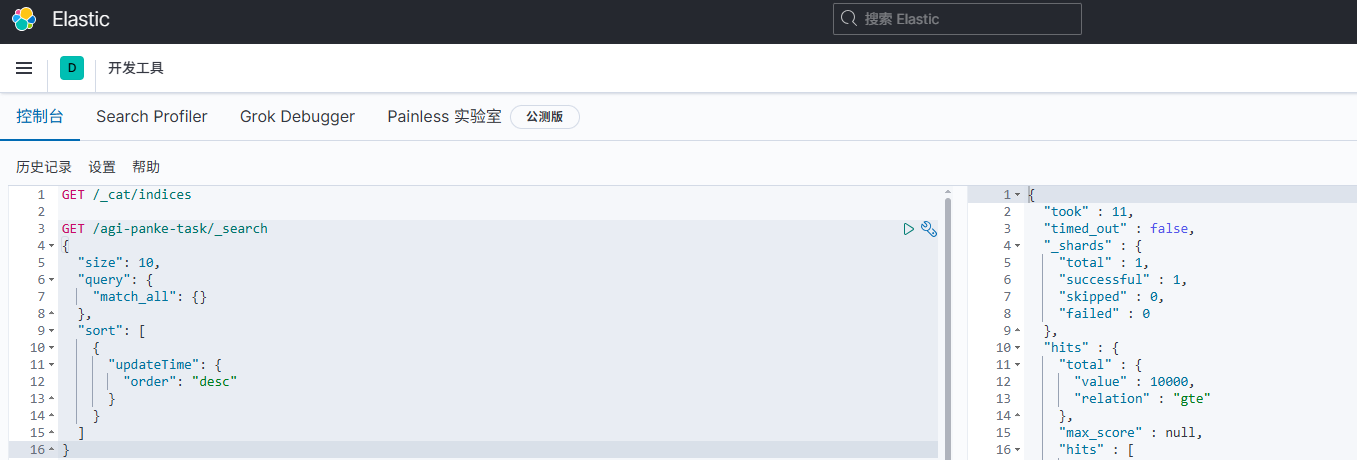
以下请求获取按账号排序的银行(bank)索引中的所有文档:
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
]
}以下的查询搜索地址(address)字段,用以查找地址包含 mill 或 lane的客户
GET /bank/_search
{
"query": { "match": { "address": "mill lane" } }
}
以下请求只匹配包含短语 mill lane 的地址:
GET /bank/_search
{
"query": { "match_phrase": { "address": "mill lane" } }
}搜索银行(bank)索引中属于 40 岁客户的账号,但排除其中住在爱达荷州(ID)的人:
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}使用一个词语聚合分组在银行(bank)索引中按州对所有账户分组,并按降序返回账户最多的十个州:
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}四. Logstash
一、Logstash概述
一句话概括:
Logstash 是日志的"ETL 引擎",负责把杂乱无章的原始日志,变成 Elasticsearch 可分析的数据结构。
在 ELK 链路中的位置:
应用系统
↓
Filebeat(采集)
↓
Logstash(解析 / 清洗 / 结构化 / 路由)
↓
Elasticsearch(存储 + 搜索 + 聚合)
↓
Kibana(分析 + 可视化)核心分工边界:
- Filebeat:只负责"把日志送出来"
- Logstash:负责"把日志变干净、变结构化"
- Elasticsearch:负责"存与算"
二、为什么需要 Logstash,而不是直接进 ES?
现实日志的常态是:
非 JSON(Nginx / Java / 自定义格式)
同一系统多种日志格式
字段不统一、噪声字段多
时间格式混乱
需要脱敏、补字段、打标签
Elasticsearch 不擅长做这些事情。
Logstash 专门解决:
日志格式不统一
字段抽取困难
数据清洗与转换
多数据源汇聚
数据路由(写多个 ES / index)
三、Logstash 的核心工作模型
Logstash 的设计极其清晰,只有 三段式流水线:
Input → Filter → Output1. Input(数据从哪来)
常见输入源:
- beats(Filebeat 最常用)
- kafka
- http
- tcp / udp
- jdbc(同步数据库)
示例(beats):
input {
beats {
port => 5044
}
}2. Filter(Logstash 的灵魂)
90% 的 Logstash 价值都在 Filter
常用 Filter 插件:
grok(最核心)
-
正则解析日志
-
将文本拆成结构化字段
grok {
match => { "message" => "%{IP:ip} %{WORD:method} %{URIPATH:path}" }
}
date
-
统一时间字段
-
决定 Kibana 时间轴是否可用
date {
match => ["timestamp", "yyyy-MM-dd HH:mm:ss"]
target => "@timestamp"
}
mutate
-
字段重命名、删除、类型转换
mutate {
remove_field => ["message"]
convert => { "status" => "integer" }
}
json
-
解析 JSON 日志
json {
source => "message"
}
geoip(日志分析常用)
- IP → 地理位置
3. Output
常见输出:
-
elasticsearch(最常见)
-
kafka
-
file(调试)
-
stdout(调试)
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "log-app-%{+YYYY.MM.dd}"
}
}
四、Logstash 的配置文件结构(工程必会)
一个完整 Logstash pipeline 本质就是一个 .conf 文件:
input { ... }
filter { ... }
output { ... }工程实践建议:
- input / filter / output 分文件管理
- 使用 pipeline.id 区分业务
- 复杂系统使用 multiple pipelines
五、Logstash 在生产中的关键能力
1. 日志结构化(最核心)
- 文本 → JSON
- 非结构化 → 可搜索
2. 字段治理
- 统一字段名
- 删除无用字段
- 增加环境、服务名、版本号
3. 多路输出
- 同一日志写多个 ES
- 同时写 Kafka + ES
- 按条件路由日志
4. 解耦应用与 ES
- 应用不直接依赖 ES
- ES 挂了,日志不丢(配合 Kafka)
五、Kibana
1. Kibana 的本质定位
Kibana 不是数据系统,而是:
Elasticsearch 的 查询构建器 + 可视化 UI + 运维控制台
它:
- 不存数据
- 不做计算
- 所有能力完全依赖 ES
2. 核心使用模型
Data View
↓
Discover 看原始日志
↓
Visualization / Lens 构建图表
↓
Dashboard 组合展示3. Data View 与时间字段
- Data View 是 Kibana 访问 ES 的入口
- 日志索引必须有统一时间字段
- 时间字段决定:
-
- 时间过滤
- 趋势分析
- Dashboard 性能
时间字段错误 = Kibana 基本不可用
4. Discover
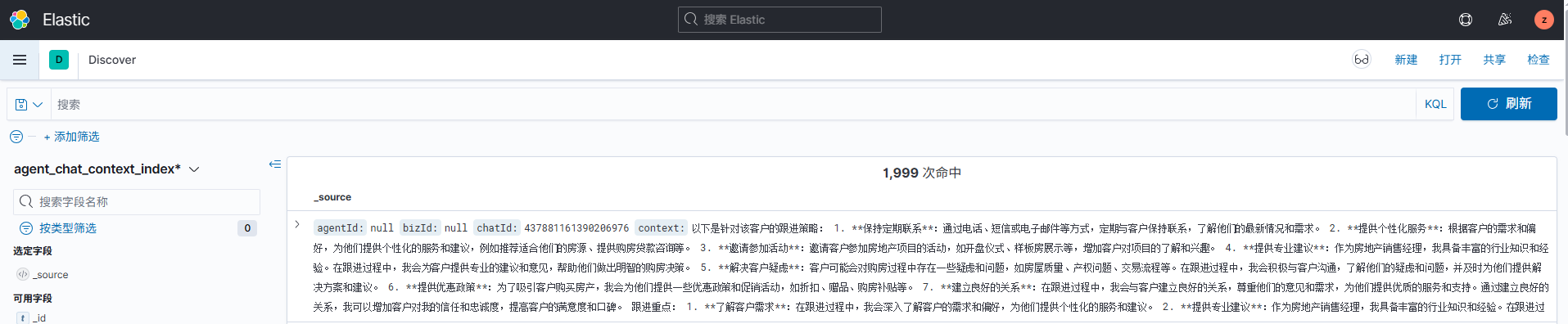
用途:
- 实时查看日志
- 错误定位
- TraceId 排查
- 验证 Logstash 解析结果
支持:
- KQL(推荐)
- Lucene Query(复杂场景)
5. Dashboard

- Lens:生产首选(拖拽 + 自动聚合)
- Dashboard:
-
- 全局时间
- 全局过滤
- 下钻分析
- 权限隔离
常见看板:
- 错误率趋势
- 接口延迟分布
- TOP N 异常接口
- 业务核心指标