待补充
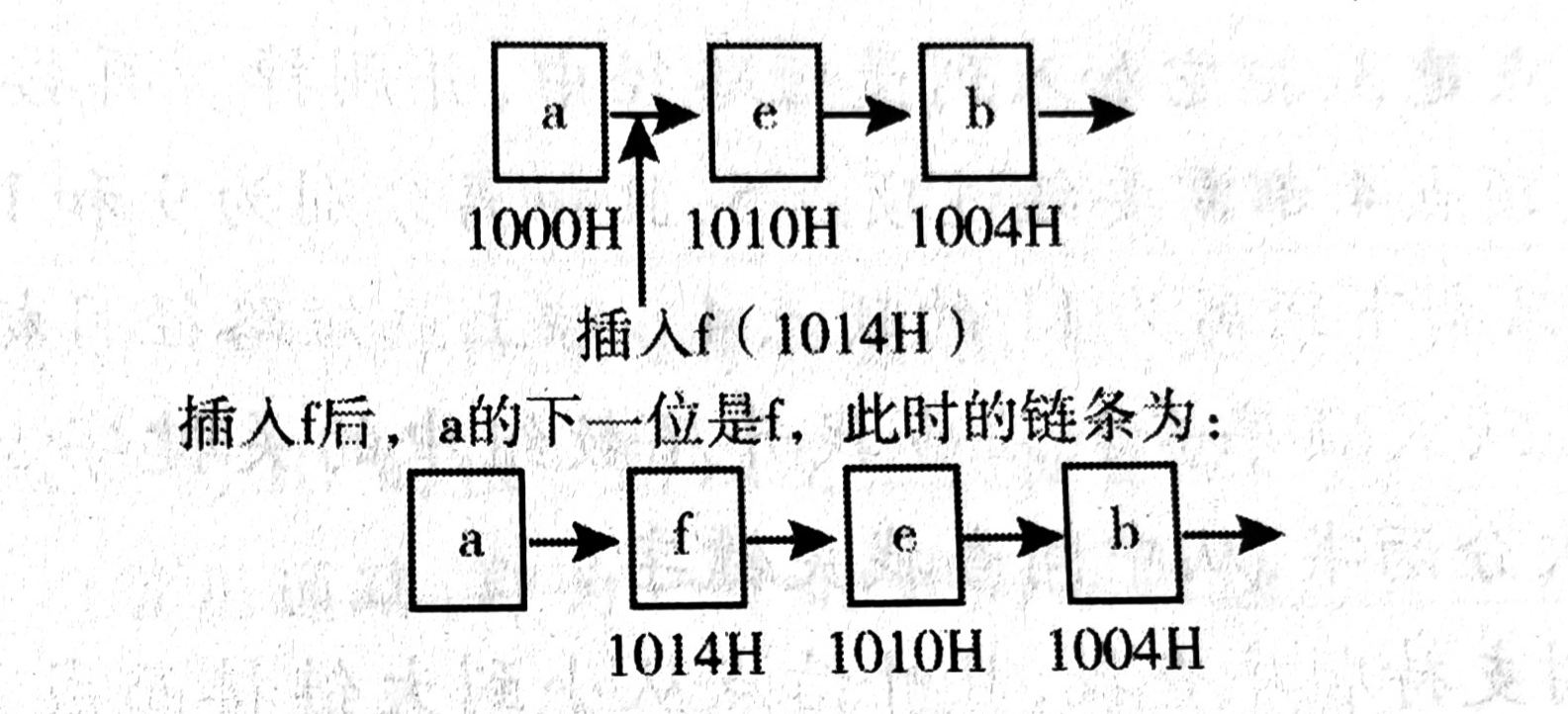
已知表头元素为c的单链表在内存中的存储状态如下表所示
|-------|----|-------|
| 地址 | 元素 | 链接地址 |
| 1000H | a | 1010H |
| 1004H | b | 100CH |
| 1008H | c | 1000H |
| 100CH | d | NULL |
| 1010H | e | 1004H |
| 1014H | | |
现将f存放于1014H处并插入到单链表中,若f在逻辑上位于a和e之间,则a, e, f的"链接地址"依次是( )。
A. 1010H, 1014H, 1004H
B. 1010H, 1004H, 1014H
C. 1014H, 1010H, 1004H
D. 1014H, 1004H, 1010H
D
l链接地址,即每一个元素的下一个地址
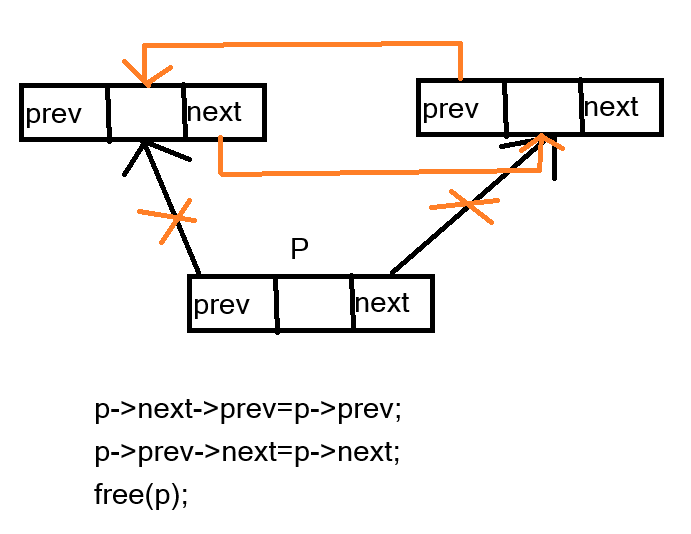
2.已知一个带有表头结点的双向循环链表L,结点结构为prev|data|next,prev和next分别是指向其直接前驱和直接后继结点的指针。现要删除指针p所指的结点,正确的语句序列是( )。
A. p->next->prev = p->prev; p->prev->next = p->prev; free(p);
B. p->next->prev = p->next; p->prev->next = p->next; free(p);
C. p->next->prev = p->next; p-> prev->next = p->prev; free(p);
D. p->next->prev = p->prev; p->prev->next = p->next; free(p);
D
3.设有下图所示的火车车轨,入口到出口之间有 n 条轨道,列车的行进方向均为从左至右,列车可驶入任意一条轨道。现有编号为1~9的9列列车,驶入的次序依次是8, 4, 2, 5, 3, 9, 1, 6, 7。若期望驶出的次序依次为1~9,则 n 至少是( )
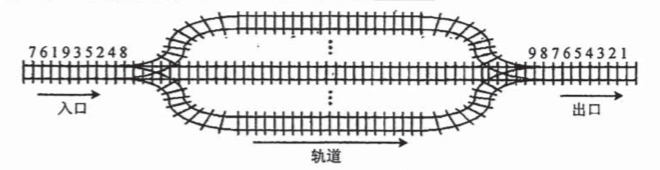
A. 2
B. 3
C. 4
D. 5
C
队列
|---------|
| 9 8 |
| 7 6 5 4 |
| 3 2 |
| 1 |
| |
4.有一个100阶的三对角矩阵M ,其元素 mi,j(1≤i≤100,1≤j≤100) 按行优先依次压缩存入下标从0开始的一维数组 N 中。元素 m30,30 在数组 N 中的下标是( )。
A. 86
B. 87
C. 88
D. 89
B
公式法 k=2i+j-3
a11 N=0=3*(1-1)
a22 N=3=3*(2-1)
a33 N=6=3*(3-1)
某元素前元素总个数=3*(元素所在的行数-1)
3*(30-1)=87
5.若森林F有15条边、25 个结点,则F包含树的个数是( )。
A. 8
B. 9
C. 10
D. 11
C
n个结点的树有n-1条边(每棵树的结点数比边数多1)
题中森林F中结点数比边数多25-15=10个,即共有10棵树
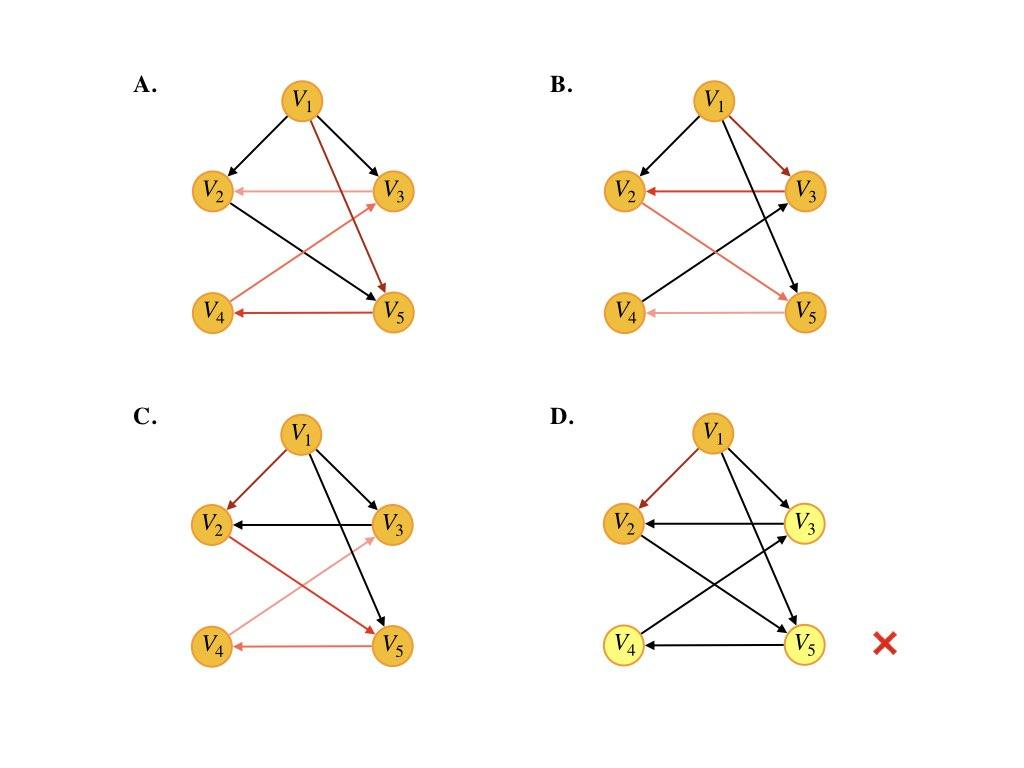
6.下列选项中,不是下图深度优先搜索序列的是( )
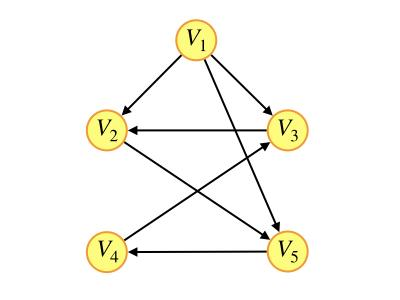
A. V1,V5,V4,V3,V2
B. V1,V3,V2,V5,V4
C. V1,V2,V5,V4,V3
D. V1,V2,V3,V4,V5
D
深度优先搜索,从V1开始,可以先访问V2(V3或V5也可以),但V2到V3与图中箭头正好相反,无法访问,D错误
深度优先搜索就是一个"一条路走到黑"的搜索策略,直到无路可走才开始回溯,找到前一个能够继续搜索的结点重复上述步骤
7.若将 n 个顶点 e 条弧的有向图采用邻接表存储,则拓扑排序算法的时间复杂度是( )。
A. O(n)
B. O(n+e)
C. O(n2)
D. O(ne)
B
把整个链接表都遍历一遍,遍历n个顶点和边,且n个顶点,一共e条边,逐个遍历一遍,时间复杂度为O(n+e)
扑排序需要输出图中所有顶点,也就是意味着必须要对图进行遍历,图的遍历最常用的就是深度优先搜索和广度优先搜索。
- 深度优先搜索算法是一种自底向上 (bottom up) 的算法,即按照逆拓扑排序的顺序遍历图。
- 广度优先搜索算法是一种自顶向下 (top down) 的算法,即按照拓扑排序的顺序遍历图。
而深度优先搜索和广度优先搜索都是完全遍历的具体实现,可以忽略算法实现细节,从整体入手
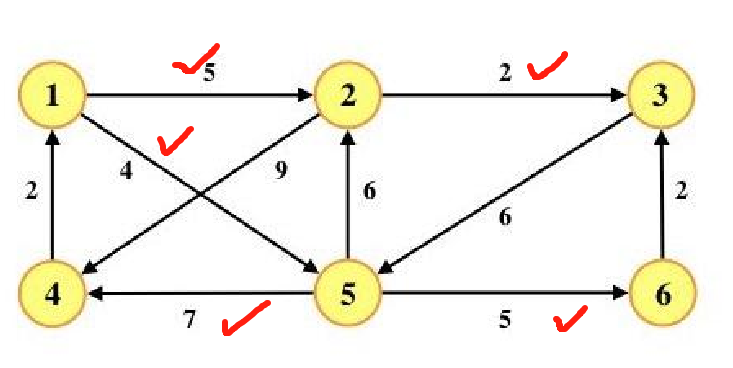
8.使用迪杰斯特拉(Djkstra)算法求下图中从顶点 1 到其他各顶点的最短路径,依次得到的各最短路径的目标顶点是( )
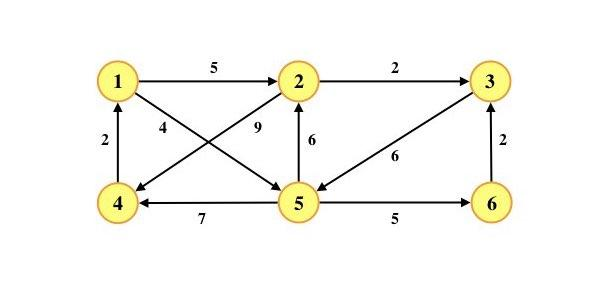
A. 5, 2, 3, 4, 6
B. 5, 2, 3, 6, 4
C. 5, 2, 4, 3, 6
D. 5, 2, 6, 3, 4
B
V1 V5 V2 V3 V6 V4
|---|--------------------------------------|--------------------------------------|--------------------------------------|--------------------------------------|--------------------------------------|---------------|
| 1 | 2 | 3 | 4 | 5 | 6 | S |
| 0 ||
| 0 | 5 |
| 0 | 5 |
| 0 | 5 | 7 | 11 | 4 | 9 | {1,5,2,3} |
| 0 | 5 | 7 | 11 | 4 | 9 | {1,5,2,3,6} |
| 0 | 5 | 7 | 11 | 4 | 9 | {1,5,2,3,6,4} |
9.在有 n(n>1000) 个元素的升序数组 A 中查找关键字 x 。查找算法的伪代码如下所示。
k = 0;
while (k < n 且 A[k] < x) k = k + 3;
if (k < n 且 A[k] == x) 查找成功;
else if (k - 1 < n 且 A[k - 1] == x) 查找成功;
else if (k - 2 < n 且 A[k - 2] == x) 查找成功;
else 查找失败;本算法与折半查找算法相比,有可能具有更少比较次数的情形是( )。
A. 当 x 不在数组中
B. 当 x 接近数组开头处
C. 当 x 接近数组结尾处
D. 当 x 位于数组中间位置
B
采用跳跃式顺序查找法查找升序数组中的关键字x,x越靠前,比较次数越少
折半查找就是把数组每次分成两半,从中间查找关键字
10.B+树不同于B树的特点之一是( )。
A. 能支持顺序查找
B. 结点中含有关键字
C. 根结点至少有两个分支
D. 所有叶结点都在同一层上
A
B+树支持顺序查找,且叶结点从小到大链接而成,B树不能支持顺序查找,只支持多路查找
B+树和B树的区别主要有两点:
- B+树的非叶结点不存储关键字,只作为索引使用,而B树的非叶结点存储关键字,所以B+树的所有叶结点中包含了全部的关键字信息,但B树不一定
- B+树上的叶结点存储关键字以及相应记录的指针,叶结点中将关键字按大小顺序排列,并且相邻叶结点按大小顺序互相链接起来。所以B+树支持两种查找运算:一种是从最小关键字开始的顺序查找,另一种是从根结点开始的多路查找。但B树只支持从根节点开始的多路查找
11.对 10 TB 的数据文件进行排序,应使用的方法是( )。
A. 希尔排序
B. 堆排序
C. 快速排序
D. 归并排序
D
希尔排序、堆排序、快速排序都是内部排序
由题可知是要对磁盘或外存里较大的数据进行排序,使用外部排序,外部排序通常使用归并排序(将所有数据切分成多个归并段,首先对每个归并段进行内部排序得到较短的有序序列,然后将多个归并段合并得到更长的有序序列,重复合并步骤最终可以得到完整的有序序列)