Python 的圈子越来越大,新工具层出不穷,是不是感觉脑子都不够用了?别慌。
这篇文章不谈那些虚的,只给你聊聊到 2025 年真正能打、让你的开发体验起飞的几款超现代工具。
ServBay:跟繁琐的 Python 环境说拜拜
说真的,Python 环境配置绝对是劝退新手的头号大坑,Python 2.x 和 Python 3.x 很容易在物理上打成一片。别说新手了,就连老手也经常被不同项目、不同版本的 Python 搞得焦头烂额。
现在,ServBay 来了。可以把它当作是一个给开发者准备的超级工具箱。
有了它,装 Python 就是点几下鼠标的事。更爽的是,电脑上可以同时装着 Python 3.8, 3.10, 3.12 等好几个版本,想用哪个就用哪个,它们之间互不打架,各自安好。
最关键的一点:全程不用敲一行命令。
再也不用跟 pyenv 的编译错误死磕,也不用纠结 miniconda 的环境配置了。ServBay 让你把时间花在刀刃上------也就是写代码。
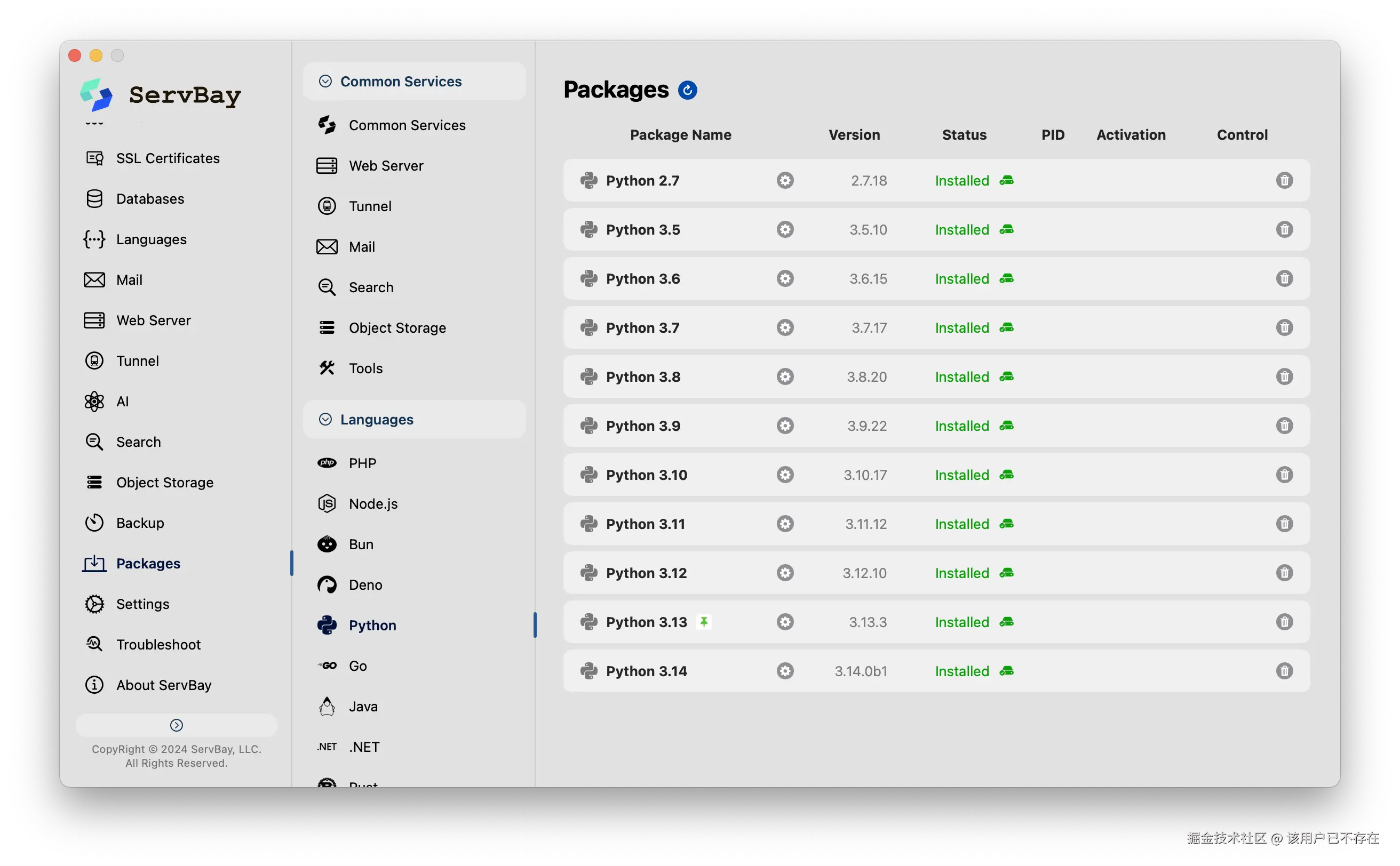
配置开发环境,5分钟之外,是ServBay快,5分钟内,是ServBay又好又快。除了这些,ServBay还有其他开发需要的工具,这就等着你自己去发现了。
Ruff:快到没朋友的代码检查器
你的代码是不是经常因为格式问题被同事吐槽?Ruff 就是来拯救你的。它用 Rust 写的,别的优点可以先不说,就一个字:快。

快到什么程度?快到你可以在编辑器里设置"保存即格式化",在你按下 Ctrl+S 的瞬间,它就已经帮你把代码整理得漂漂亮亮。
比如下面这段代码,有三个小毛病:变量名写错了、import 没在顶上、还导入了用不上的模块。
python
data = datas[0]
import collections用 Ruff 一查,问题清单立刻就出来了,明明白白:
python
$ ruff check .
ruff.py:1:8: F821 Undefined name `datas`
ruff.py:2:1: E402 Module level import not at top of file
ruff.py:2:8: F401 [*] `collections` imported but unused
Found 3 errors.
[*] 1 potentially fixable with the --fix option.mypy:别等代码崩了才发现问题
动态语言一时爽,代码重构火葬场。"这话糙理不糙。mypy 能在代码运行前,就帮你做一次"体检"。
比如,你想用一个字符串除以 10,这显然是错的。
python
def process(user: dict[str, str]) -> None:
# mypy 会在这里亮红灯!
user['name'] / 10
user: dict[str, str] = {'name': 'alpha'}
process(user)不用运行,mypy 就能直接告诉你:"哥们,这儿不对劲!"
python
$ mypy --strict mypy_intermediate.py
mypy_fixed.py:2: error: Unsupported operand types for / ("str" and "int")
Found 1 error in 1 file (checked 1 source file)在大型项目中,这种提前发现问题的能力,能救你于水火。
Pydantic:别再裸奔用字典了
还在用字典(dict)传来传去吗?天知道里面到底有几个 key,又是什么类型?Pydantic 能让你像定义一个普通的 Python 类一样,清清楚楚地定义你的数据。

它不仅结构清晰,还能自动帮你检查数据。
python
import uuid
import pydantic
class User(pydantic.BaseModel):
name: str
id: str | None = None
@pydantic.validator('id')
def validate_id(cls, user_id: str) -> str | None:
if user_id is None: return None
try:
# 检查 ID 是否为有效的 UUID v4
uuid.UUID(user_id, version=4)
return user_id
except ValueError:
# 如果不是,就返回 None
return None
# 'invalid' 会被自动转换成 None
users = [ User(name='omega', id='invalid') ]
print(users[0])看,id='invalid' 被自动校验并设为了 None,代码健壮性瞬间提升。
python
name='omega' id=NoneTyper:写命令行工具,本该如此简单
想给自己的脚本加个命令行界面?忘掉 argparse 那一堆模板代码吧。用 Typer,你只需要写一个普通的 Python 函数,给参数加上类型提示就行。

python
import typer
app = typer.Typer()
@app.command()
def main(name: str) -> None:
print(f"Hello {name}")
if __name__ == "__main__":
app()一个功能完善、自带帮助文档(--help)的 CLI 就诞生了。运行起来就像这样:
ruby
$ python main.py "World"
Hello WorldRich:让你的终端输出活泼起来
受够了黑白分明的终端输出吗?Rich 能让你的终端变得五彩斑斓。
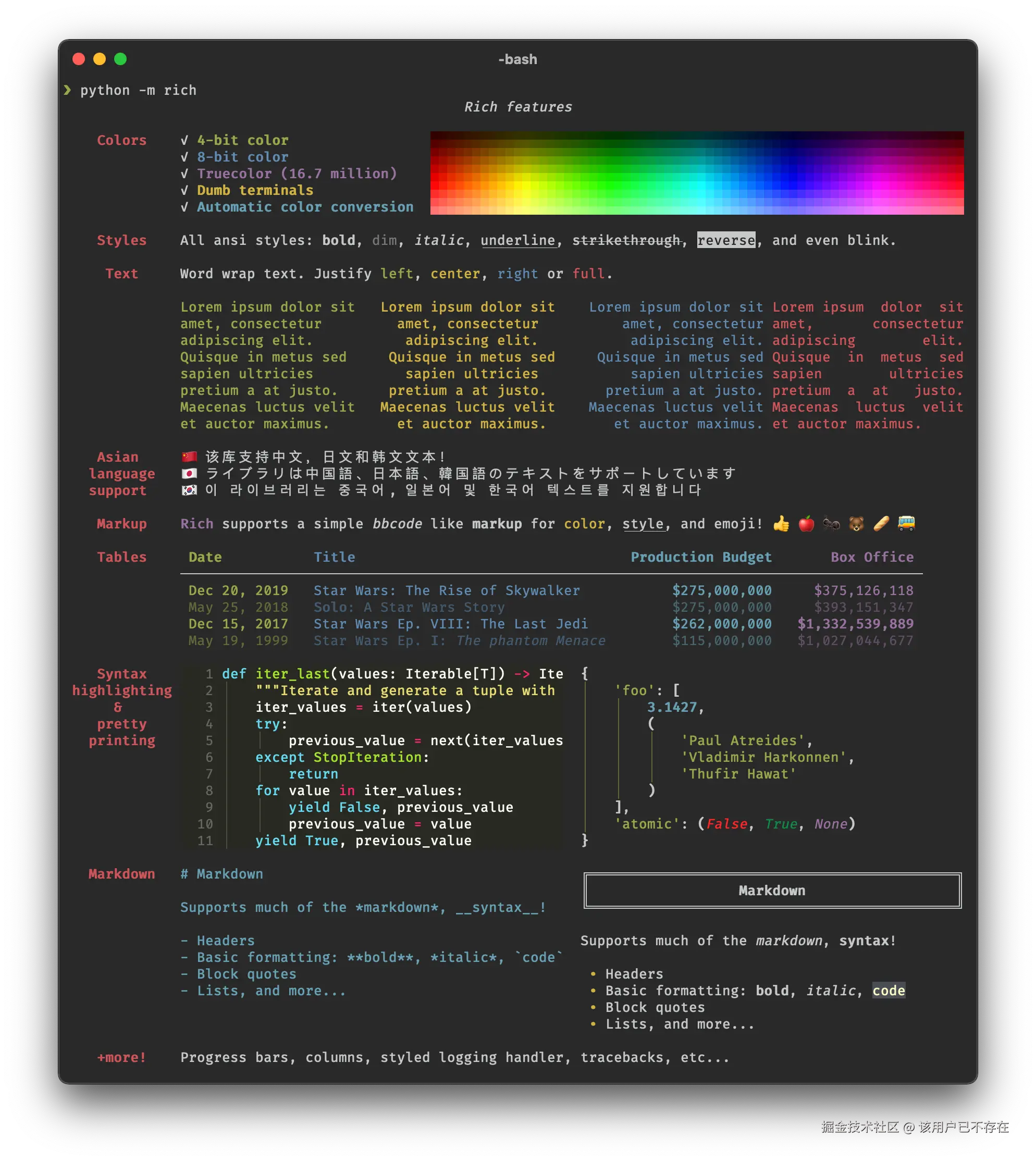
python
from rich import print
user = {'name': 'omega', 'id': 'invalid'}
# Rich 能漂亮地打印数据结构,还支持 emoji
print(f":wave: Rich 打印\nuser: {user}")输出效果会是这样,是不是比普通 print 好看多了?
👋 Rich 打印
user: {'name': 'omega', 'id': 'invalid'}
Polars:处理表格数据的"飞毛腿"
如果你用 Pandas 处理过稍大一点的数据集,那你一定懂那种等待的煎熬。Polars 是一个新的选择,它在很多场景下比 Pandas 快得多。
python
import polars as pl
df = pl.DataFrame({
'date': ['2025-01-01', '2025-01-02', '2025-01-03'],
'sales': [1000, 1200, 950],
'region': ['North', 'South', 'North']
})
# 链式操作,清晰明了,而且是惰性计算,性能更高
query = (
df.lazy()
.with_columns(pl.col("date").str.to_date())
.group_by("region")
.agg(
pl.col("sales").mean().alias("avg_sales"),
pl.col("sales").count().alias("n_days"),
)
)
print(query.collect())结果清清楚楚,而且计算过程被优化过,非常高效。
python
shape: (2, 3)
┌────────┬───────────┬────────┐
│ region ┆ avg_sales ┆ n_days │
│ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ u32 │
╞════════╪═══════════╪════════╡
│ North ┆ 975.0 ┆ 2 │
│ South ┆ 1200.0 ┆ 1 │
└────────┴───────────┴────────┘Pandera:给你的数据加个质检员
数据分析,80% 的时间在清洗数据。Pandera 就像一个数据质检员,你预先定义好数据规范,不合格的数据直接被拦下。
python
import pandera as pa
from pandera.polars import DataFrameSchema, Column
schema = DataFrameSchema({
"sales": Column(int, checks=[pa.Check.greater_than(0)]),
"region": Column(str, checks=[pa.Check.isin(["North", "South"])]),
})
# 这个 DataFrame 里的 sales 有负数,会校验失败
bad_data = pl.DataFrame({"sales": [-1000, 1200], "region": ["North", "South"]})
try:
schema(bad_data)
except pa.errors.SchemaError as err:
print(err) # Pandera 会告诉你错在哪这样就能保证进入你核心逻辑的数据都是干净的,避免了后续一连串的麻烦。
DuckDB:分析型SQL查询的小钢炮
别被名字骗了,它跟鸭子没关系。DuckDB 是一个超级方便的嵌入式数据库,你可以把它看作一个为数据分析量身定做的 SQLite。它能直接查询 Parquet、CSV 文件,速度飞快,而且语法就是标准的 SQL。不需要启动重量级的数据库服务,就能在 Python 脚本里享受 SQL 的强大和便捷。对于快速的数据探索和原型开发来说,简直不要太爽。

python
import duckdb
# (假设 sales.csv 和 products.parquet 已创建)
con = duckdb.connect()
# 直接用 SQL 把两个不同格式的文件 join 起来
result = con.execute("""
SELECT s.date, p.name, s.amount
FROM 'sales.csv' s JOIN 'products.parquet' p ON s.product_id = p.product_id
""").df()
print(result)Loguru:日志记录,原来可以这么省心
Python 自带的 logging 模块,配置起来有点啰嗦。Loguru 把一切都简化了。
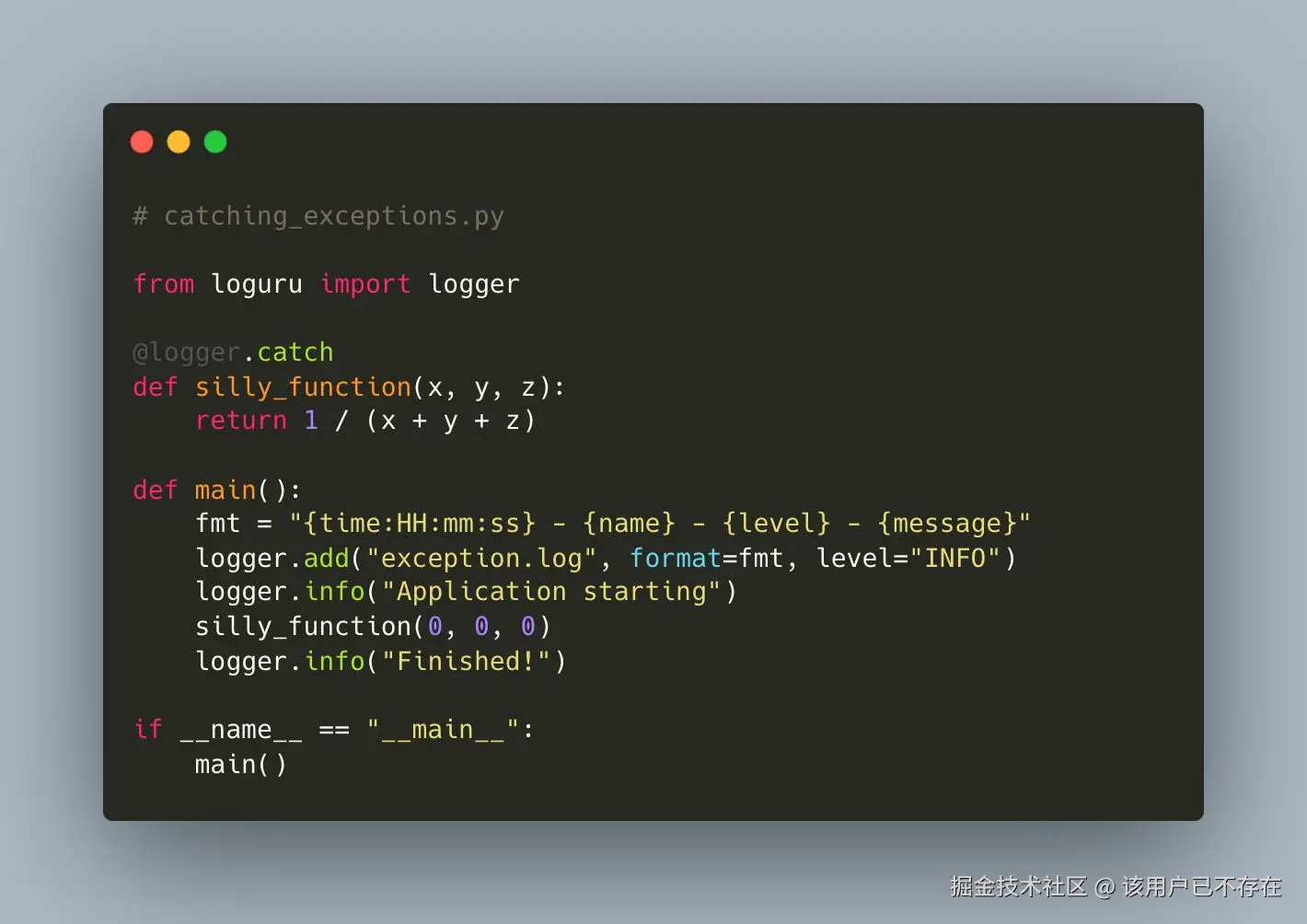
python
from loguru import logger
# 一行配置,日志就能自动轮转、压缩
logger.add("file.log", rotation="500 MB")
logger.info("这是一条普通信息")
logger.warning("警告!有事情发生了!")输出会自动带上时间、级别等信息,非常省心。
2025-01-05 10:30:00.123 | INFO | main::6 - 这是一条普通信息
2025-01-05 10:30:00.124 | WARNING | main::7 - 警告!有事情发生了!
Marimo:下一代 Python 交互式笔记本
Jupyter 好用,但也有几个老问题:单元格执行顺序一乱,状态就可能变得一团糟;.ipynb 文件做版本管理时简直是灾难。Marimo 尝试解决这些问题。它的文件就是纯 .py 脚本,Git 管理起来非常方便。而且它很"响应式",改一个变量,所有依赖它的单元格都会自动更新。
总结一下
2025 年,想让你的 Python 开发更上一层楼,试试这套工具组合:
-
环境管理:用 ServBay,动动鼠标就搞定。
-
代码质量:Ruff + mypy,又快又稳。
-
数据定义:Pydantic,让数据不再裸奔。
-
工具开发:Typer 写 CLI,Rich 美化输出。
-
数据处理:Polars 提速,Pandera 保证质量,DuckDB 灵活查询。
-
日常辅助:Loguru 简化日志,Marimo 带来新的 notebook 体验。
把它们用起来,你会发现写 Python 原来可以这么舒服!