为什么要搭建本地知识库?
难道你就不想拥有一个超级能干的AI助理管家吗?就像是贾维斯一样的助手!
那么DeepSeek的特点就是擅长理解中文,这一点比很多外国AI强大很多!
那么我们就可以把自己的工作文件、个人日记、文档笔记交给它去处理,DeepSeek能快速吃透你给的各种文档, 最关键是能装在自己电脑上,我们不用担心隐私泄露!
你要是使用公共AI处理就像把钥匙交给陌生人一样不放心,而DeepSeek就像把保险箱安在自己家!
那废话不多说,我们直接上手实操看效果吧~~
Ollama下载与安装
首先我们电脑上必须要安装Ollama并且加载一个DeepSeek模型,这个教程我们在前面也已经详细讲过了
为了方便新手,这里再给大家讲解一下~
打开Ollama官网:
如图
这里下载Windows版本
如图
下载好直接点击安装包开始安装即可~
如图
稍等一会~~
如图
注意:安装完成之后,重启一下电脑
然后我们确认一下是否安装成功!
打开cmd命令行,输入以下命令!
java
ollama -v看到以下提示,才能算你安装ollama安装成功!
如图

Ollama集成DeepSeek-R1模型
然后我们开始下载DeepSeek-R1模型
还是打开Ollama官网, 点击DeepSeek-R1链接
如图
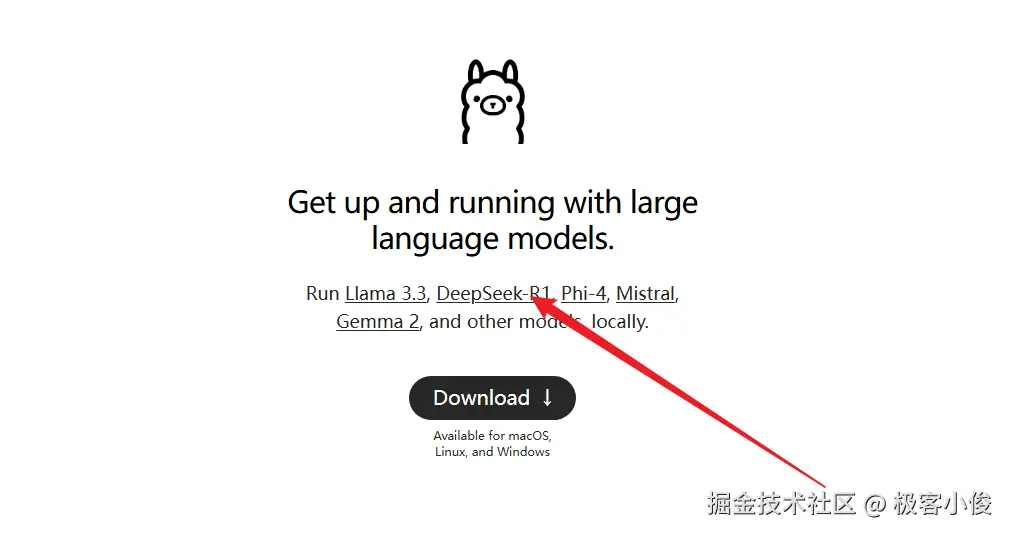
然后根据你电脑的硬件配置情况来选择蒸馏模型的安装命令!
如图
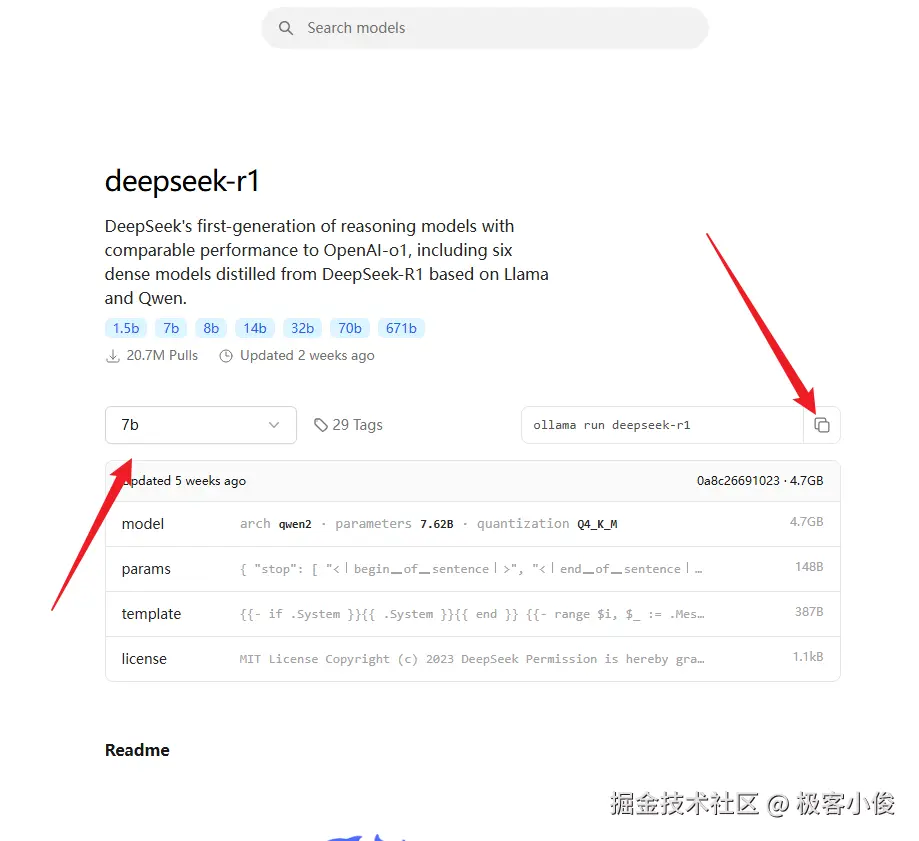
特别提醒:
这里就不要鬼扯什么满血和蒸馏的问题了,在前面的教程中,都说得很清楚了~还在找这种存在感的人应该考虑转行了
然后点击相应的安装命令,复制一下,到cmd命令行,就可以直接开始安装DeepSeek-R1
如图
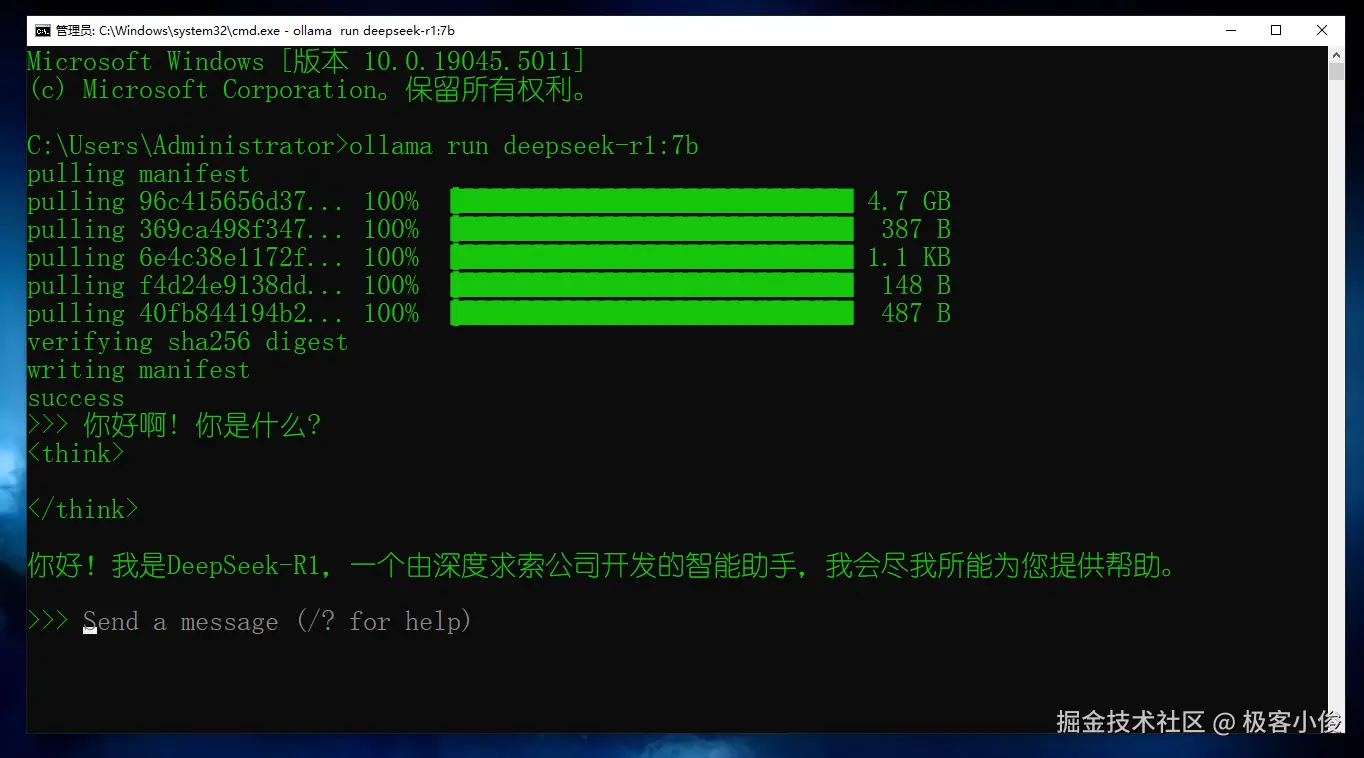
完成之后,就可以直接对话了!
如图
AnythingLLM介绍
这其实也是我们今天要说的重点~~
AnythingLLM是由Mintplex Labs Inc.开发的一款全栈应用程序,是为用户提供一个灵活而强大的工具,以便在私有环境中构建自己的ChatGPT
特点
文档转化与上下文使用
AnythingLLM能够将任何文档、资源类似于链接、音频、视频、内容片段转化为上下文,然后让其他大语言模型在聊天时作为参考进行调用!
所以AnythingLLM可以用来打造企业内部知识库的私人专属GPT,用于智能处理各种文档并进行对话!
想象一下,你有一个装满各种文档、笔记和资料的私人宝库,而AnythingLLM就是那个能帮你智能检索、理解和对话的宝库管理员, 你可以把任何文档转化成它能理解的形式,然后像聊天一样提问,它会根据你的问题从宝库中提取相关信息来回答。
这样,你就能快速、方便地获取所需知识,而且所有数据都保存在你自己的电脑上安全又私密岂不乐哉!
来吧~~开始下载安装它!
AnythingLLM下载与安装
官方网站
如图
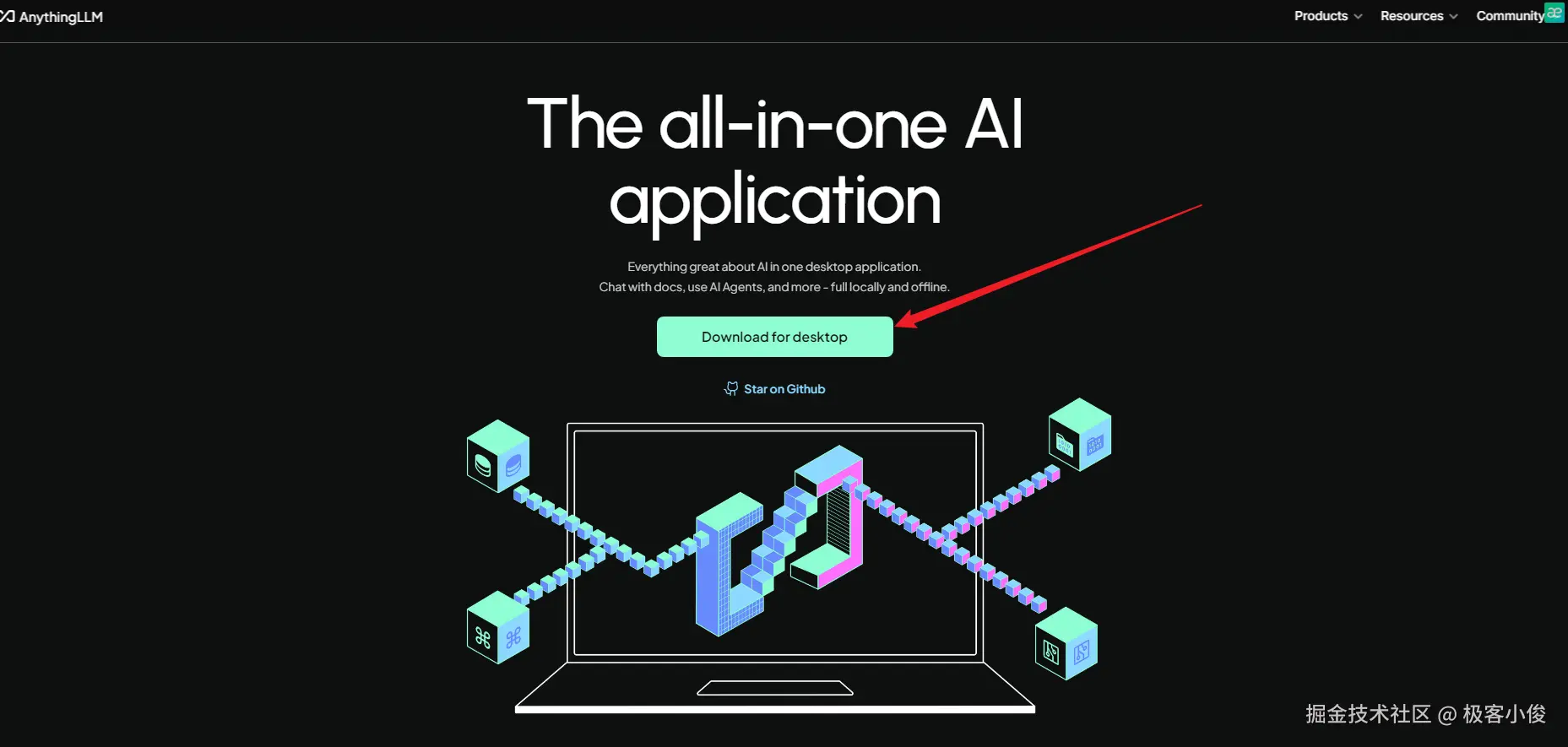
这里以Windows系统为例
如图
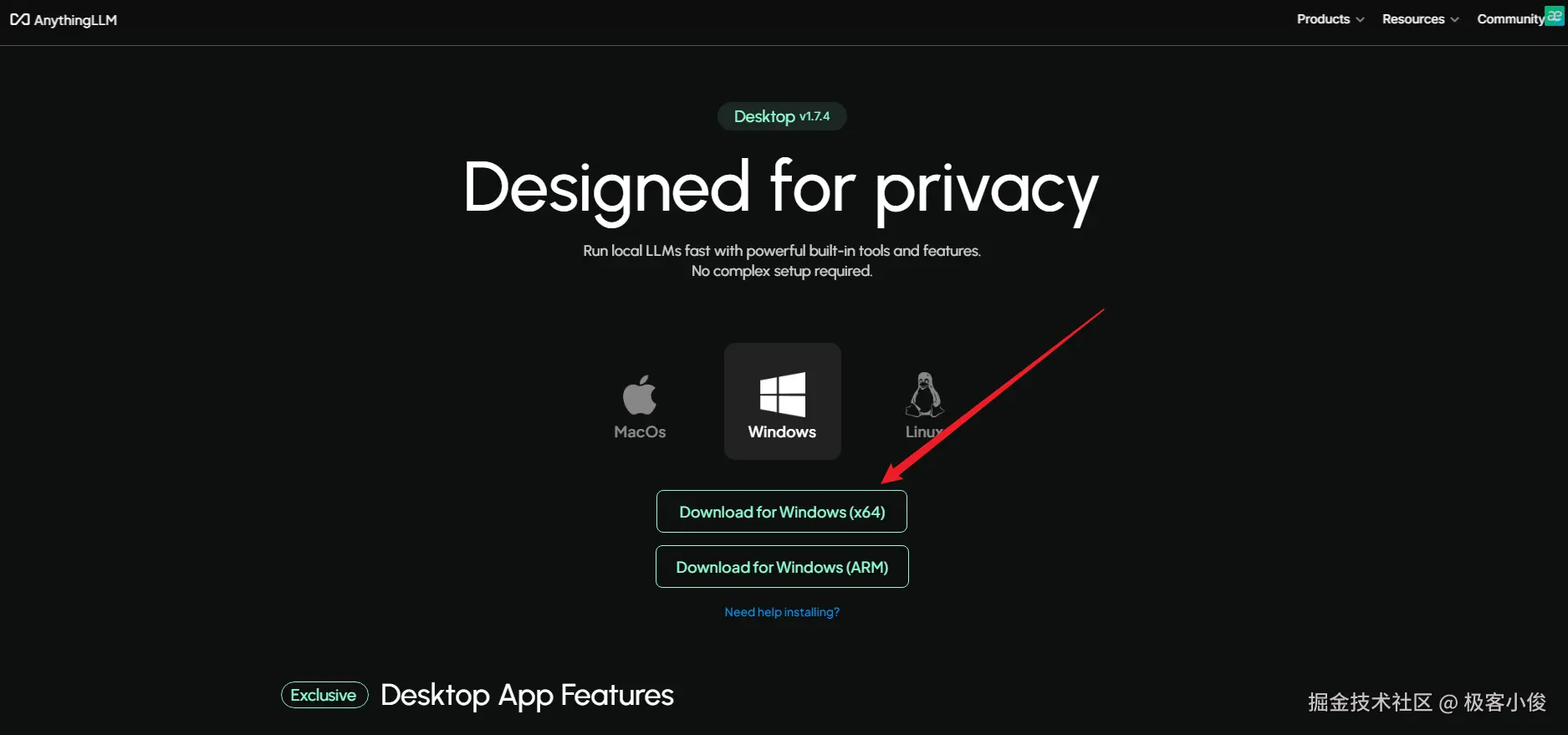
要是弹出以下这玩意,点击确认即可开始下载!
如图
同样,下载好之后,直接安装即可
如图
等待安装...这玩意还有点大可能需要多等待一会
如图
AnythingLLM部署配置本地知识库
整个过程非常简单只需几步即可完成!
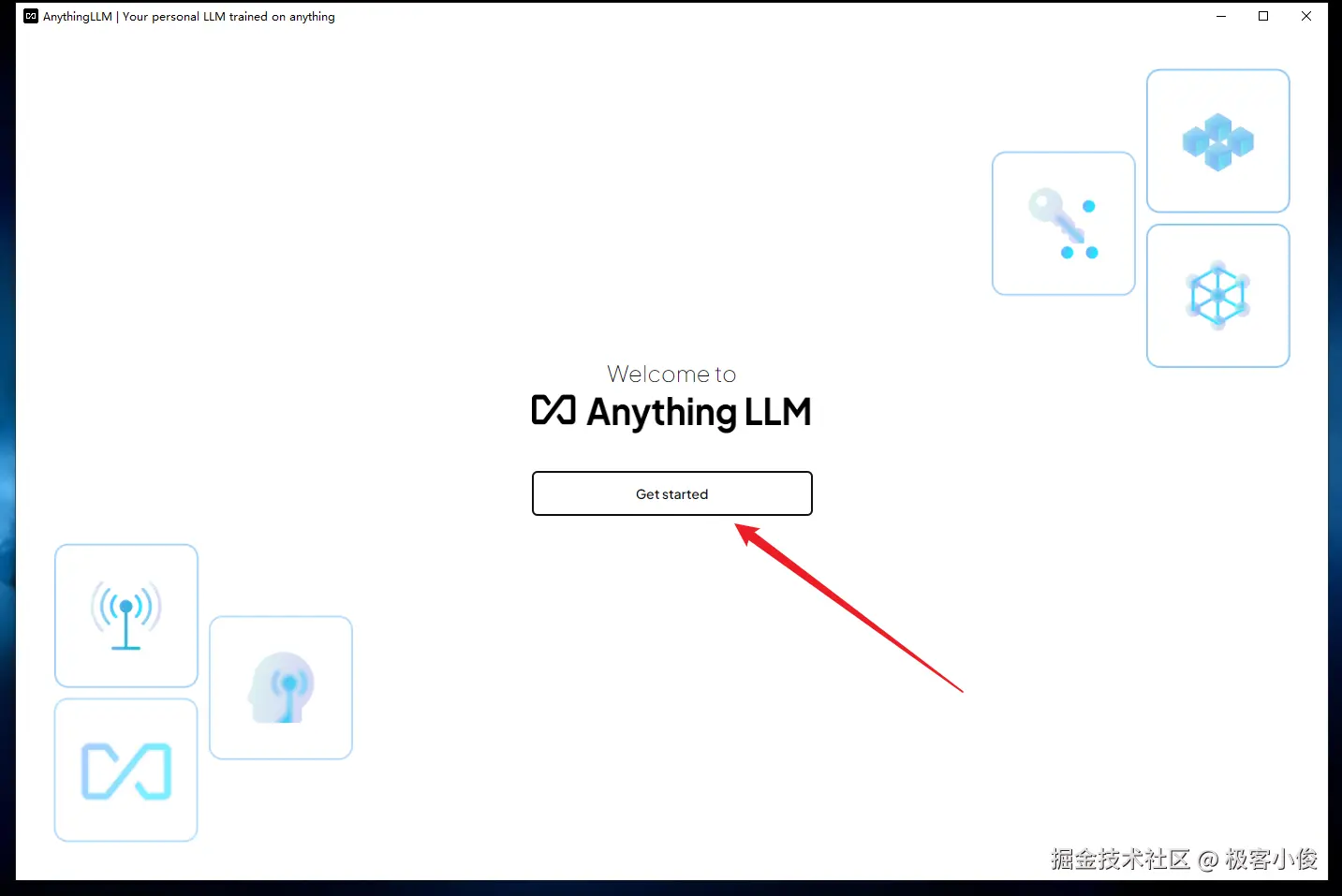
首先双击桌面上的AnythingLLM快捷方式打开它, 点击Get Started(开始)
如图
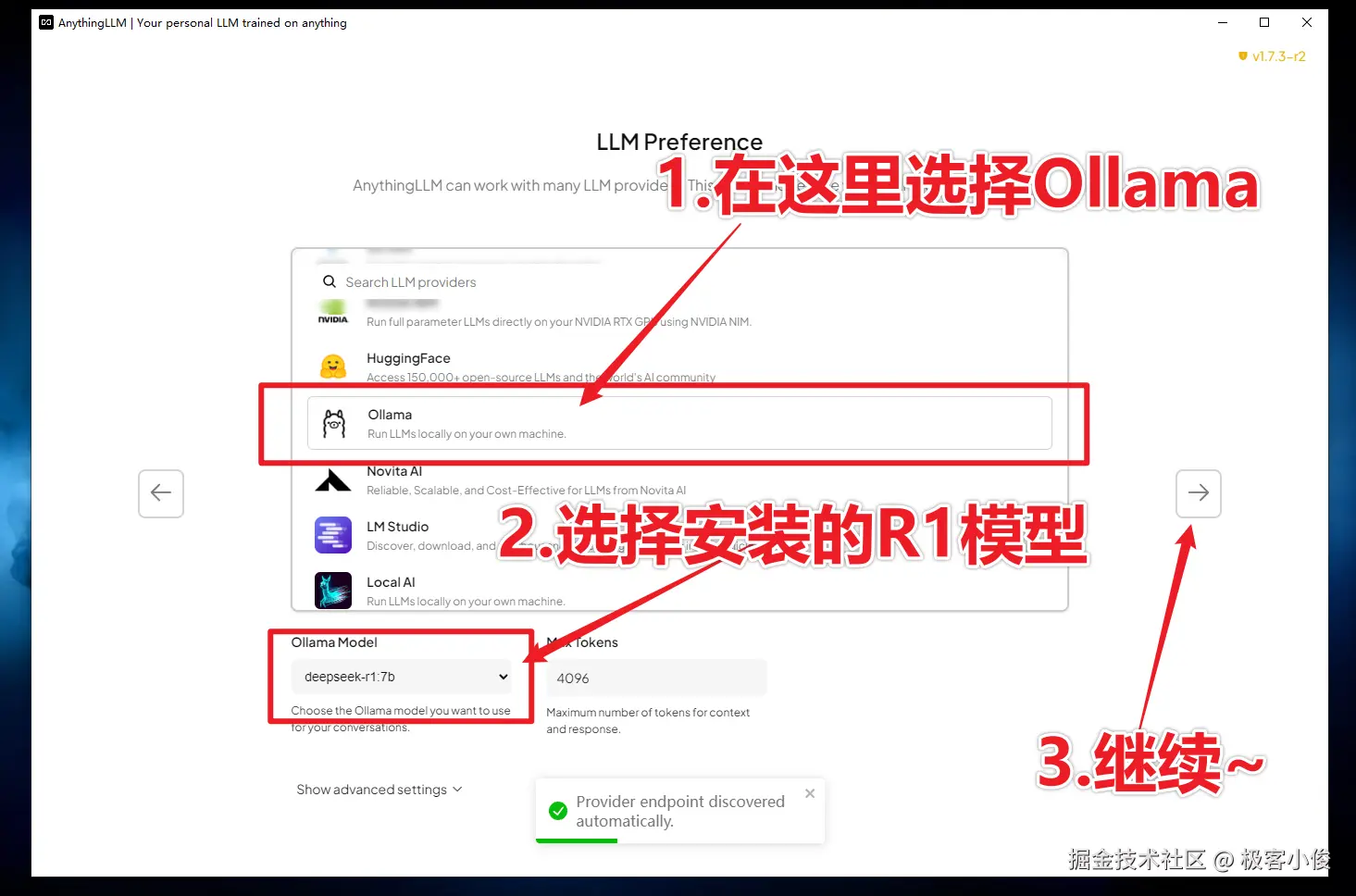
然后在列表中找到Ollama, 同时在下方的Ollama Model选项中选择我们安装的DeepSeek-R1蒸馏模型!
注意:根据你安装的模型参数类别来进行选择!
如图
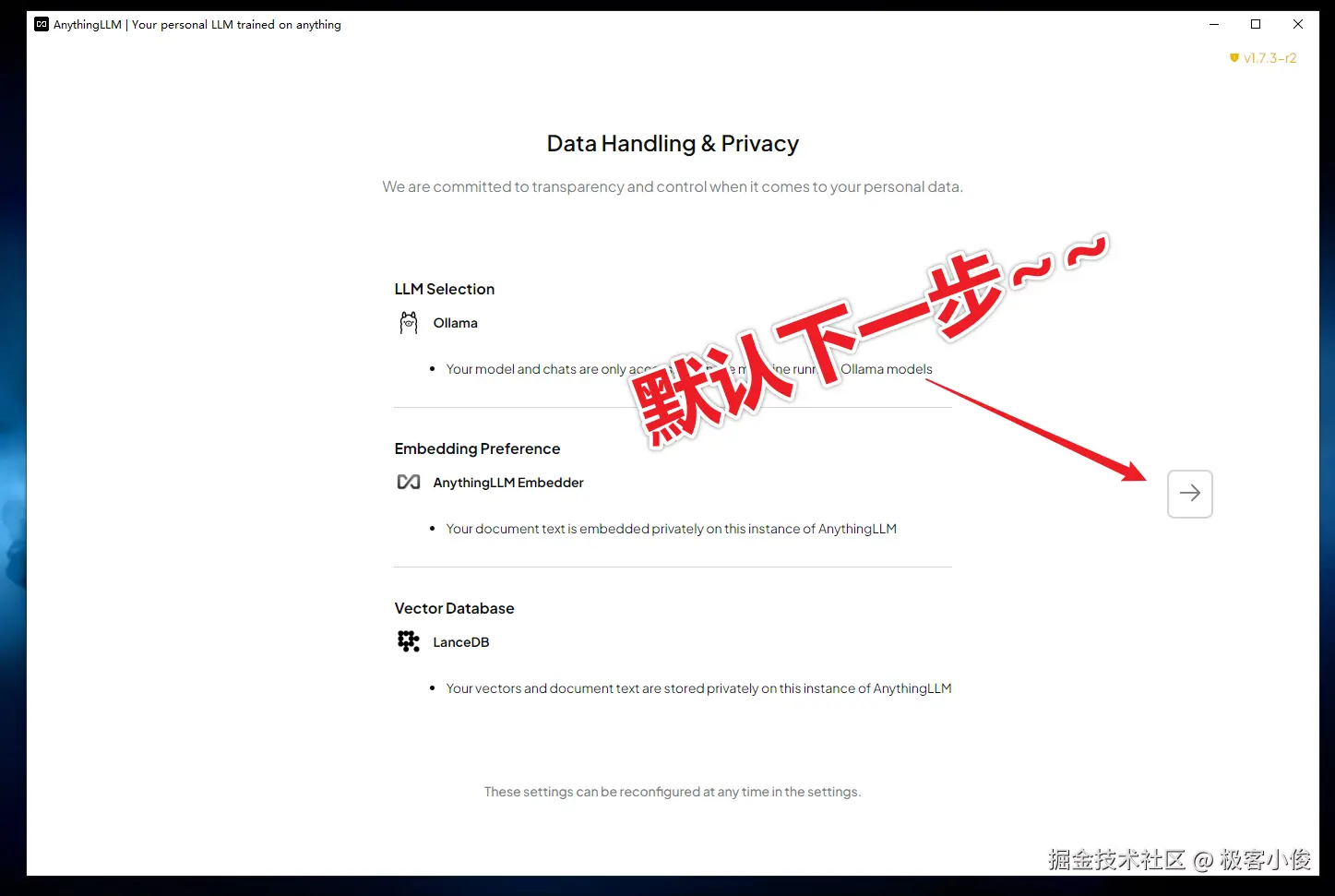
这里直接默认点击下一步即可
如图
以下可以输入一个电子邮箱,也可以直接点击跳过
这里我直接Skip Survey(跳过)
如图
然后是给工作区命名,继续点击下一步!
如图
到这里基本上就完成了模型的部署,可以和DeepSeek-R1进行对话了,类似于Chatbox
如图
设置中文
但是这里你会发现会显示一些英文,我们需要做一些设置!
点击设置按钮!
如图
找到语言设置选项,选择Chinese(中文)
如图
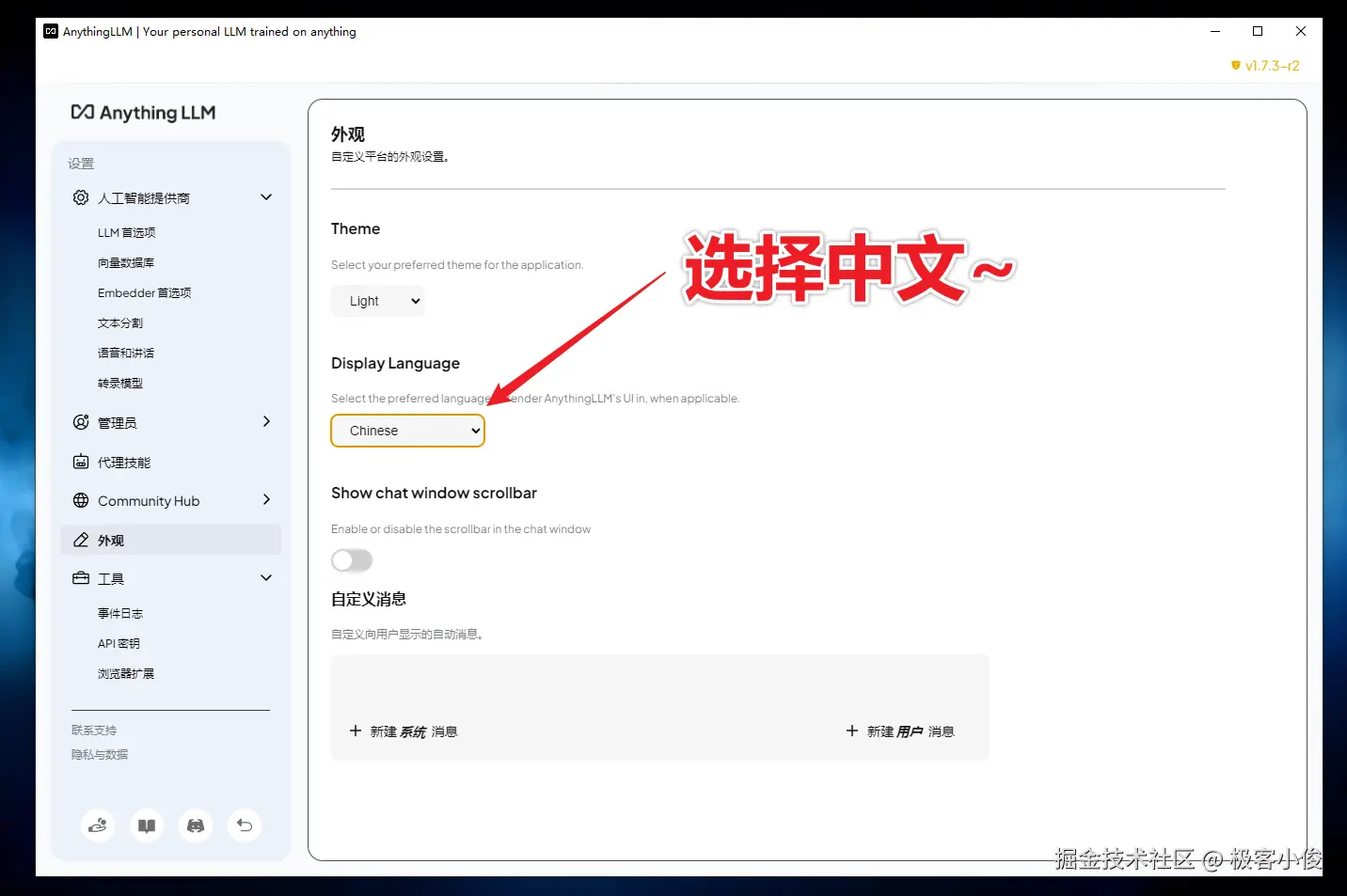
现在回过头看看是不是变成中文了
如图
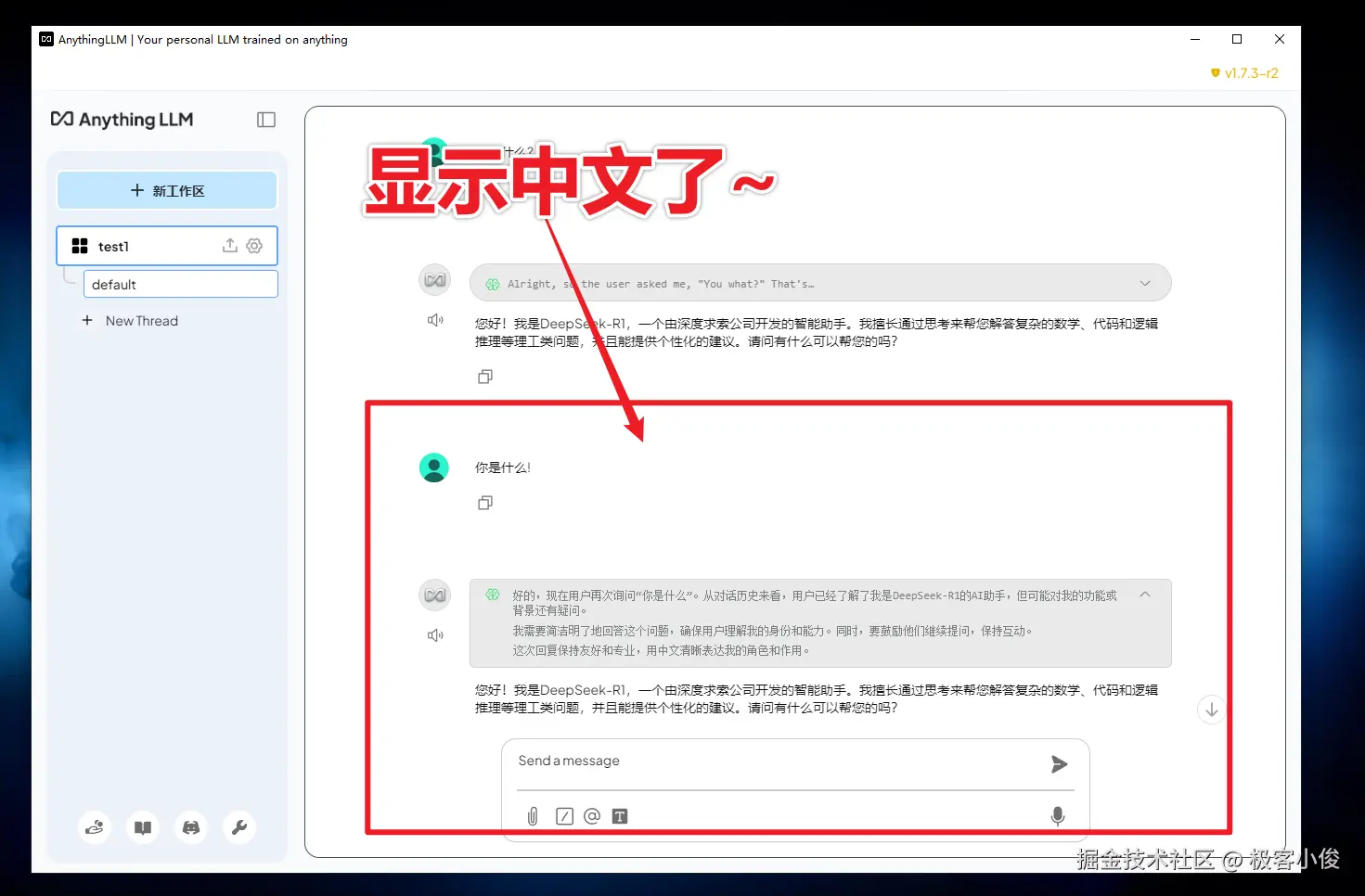
上传数据到本地资料库
接下来才是重头戏,把你的数据投喂到AnythingLLM让它使用DeepSeek给我们进行分析!
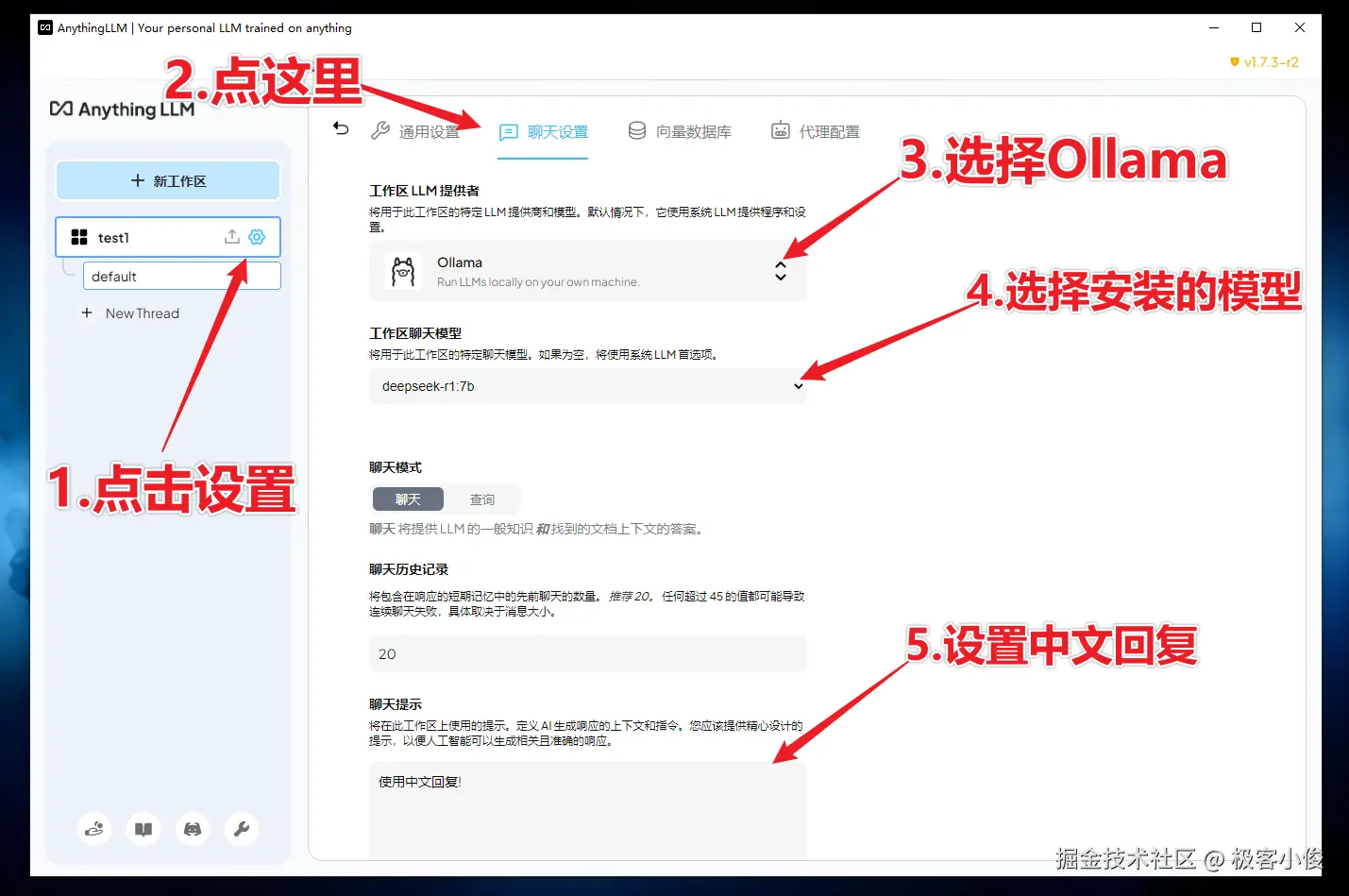
首先点击工作区右侧旁边的齿轮设置按钮, 按照图中的顺序进行配置!
如图
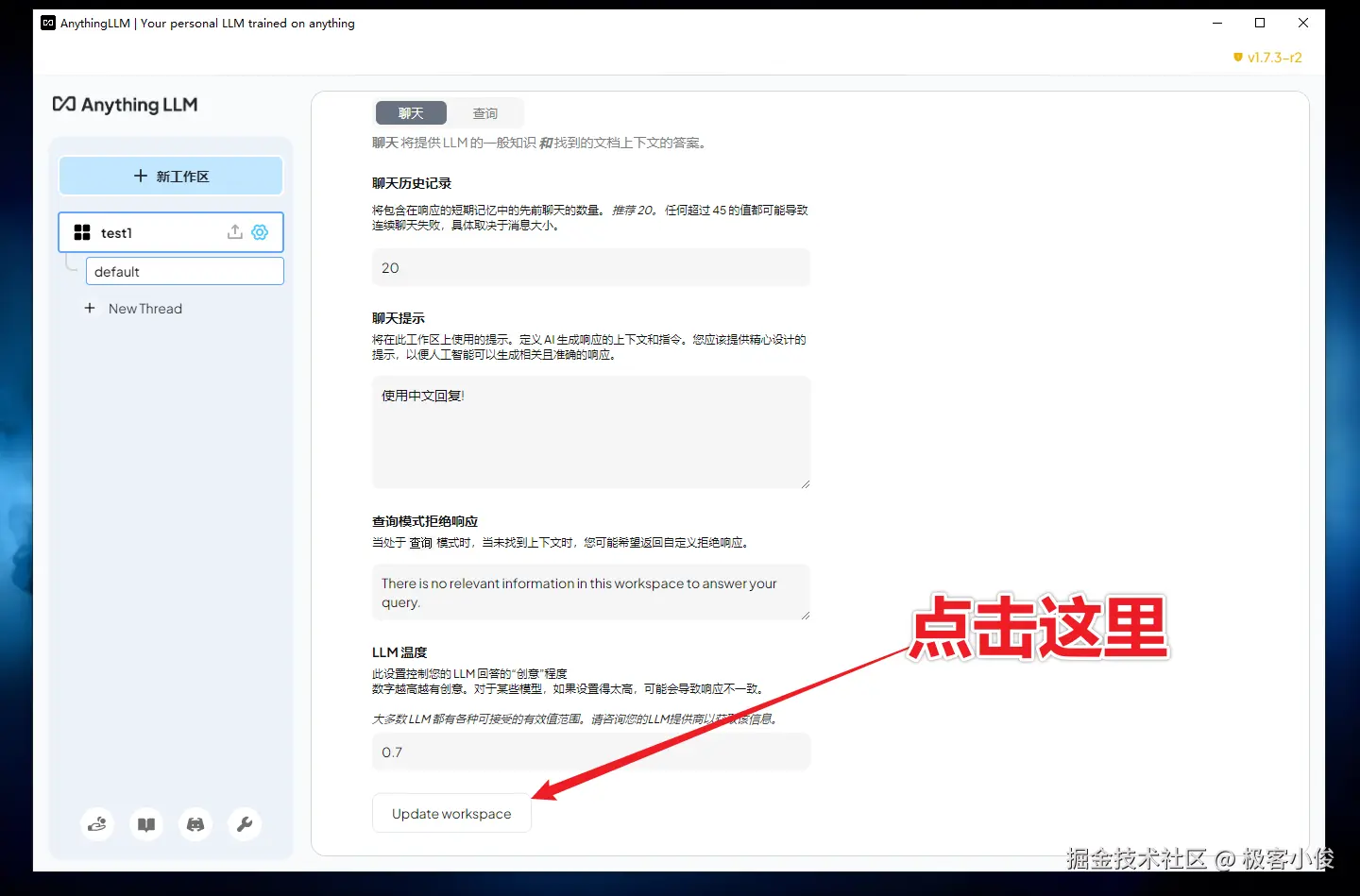
滚轮啦到底部,点击Update workspace(保存更新)
如图
然后继续在工作区右侧点击上传按钮
如图

左边是我们上传的所有数据资料,默认为空
如图
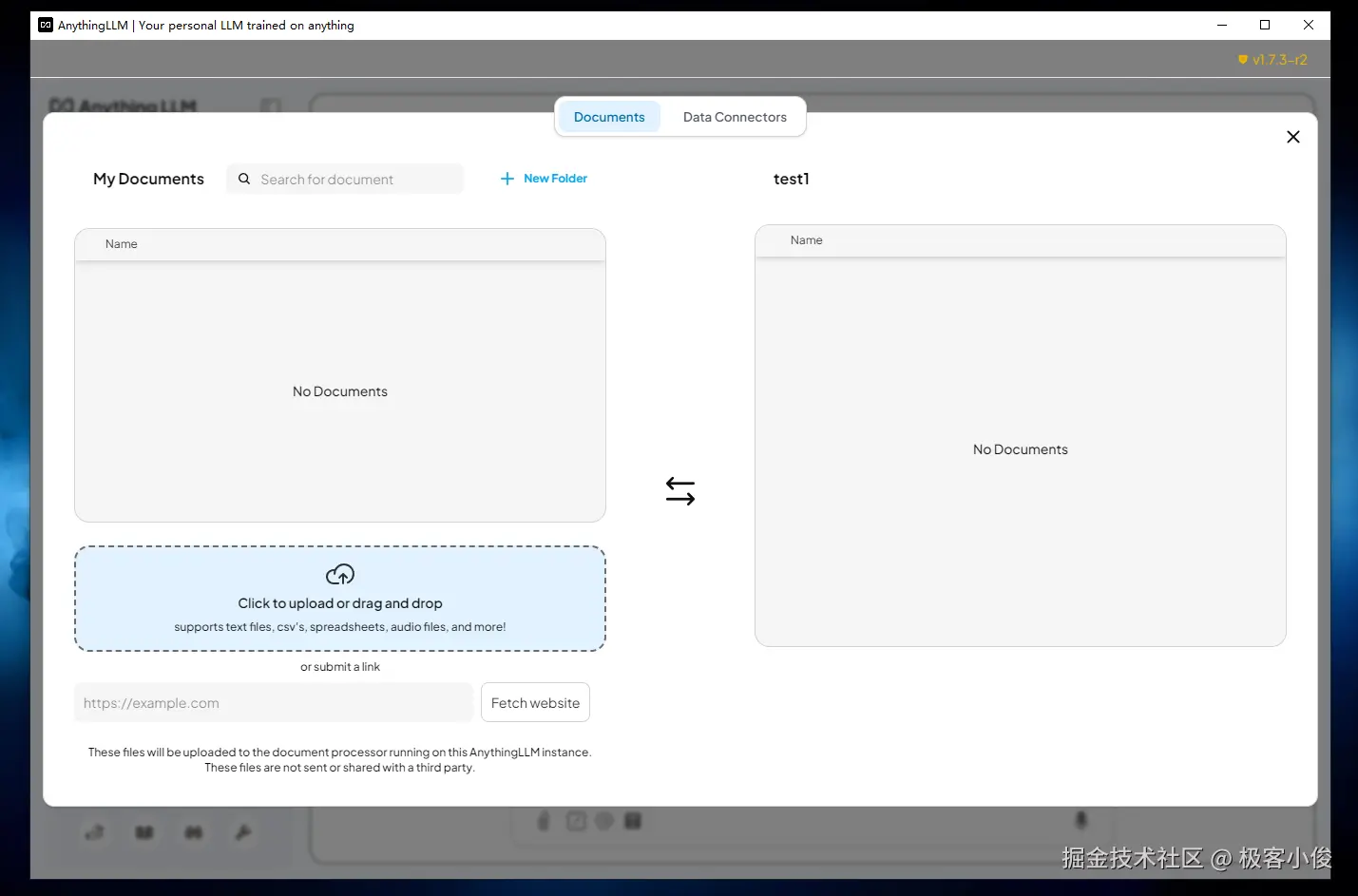
我们可以先把一些文件拖进软件,等它自动分析,这里至于是什么文件,就取决于你自己的职业
举个栗子
这里我上传一份ThinkPHP5快速入门教程的PDF文件给AnythingLLM
我们点击click to upload or drag and drop(单击上传或拖放按钮) 选择你要上传的文件!
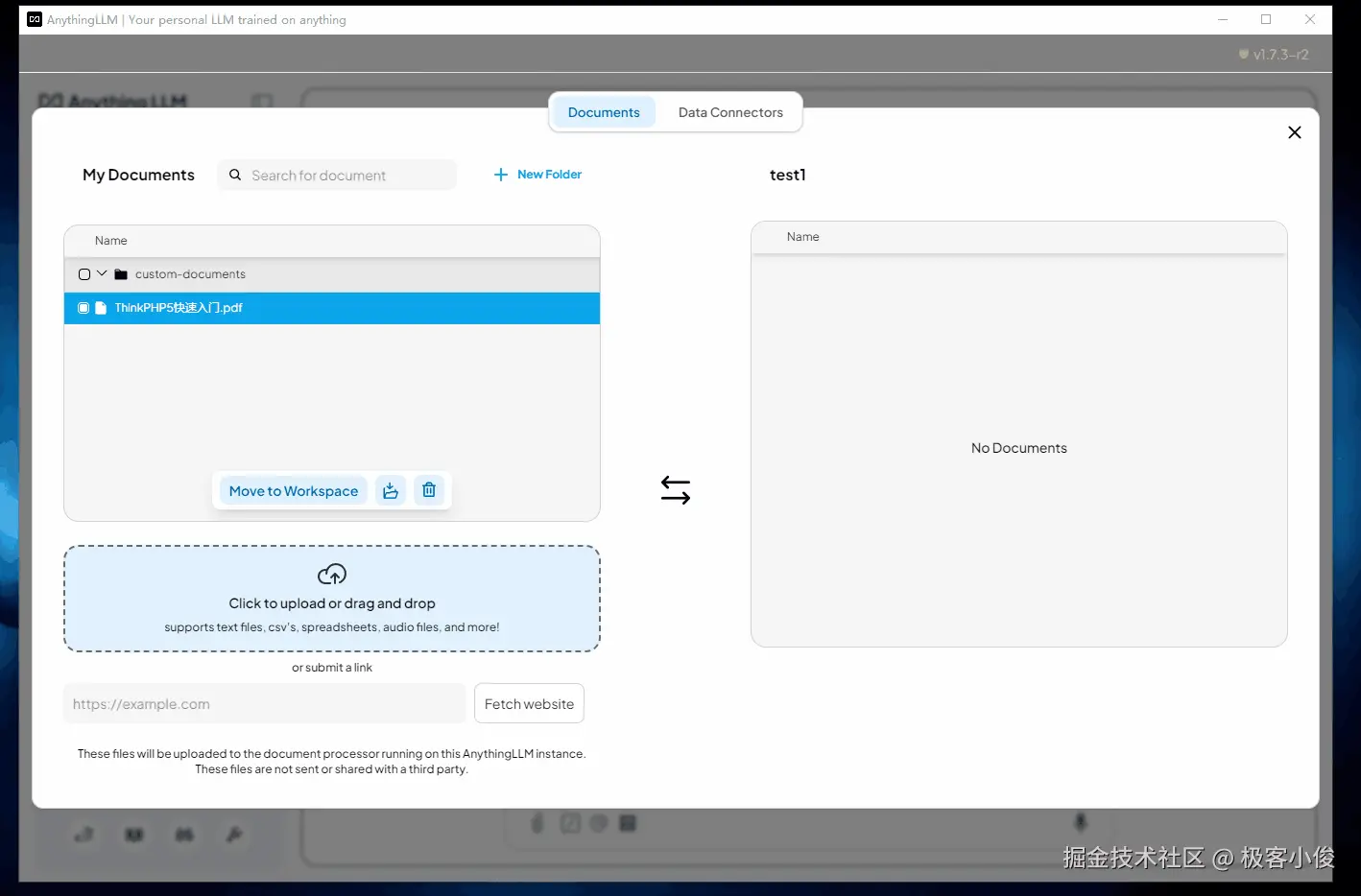
等待一会,上传完成之后继续点击Move to Workspace(移动到工作区)
如图
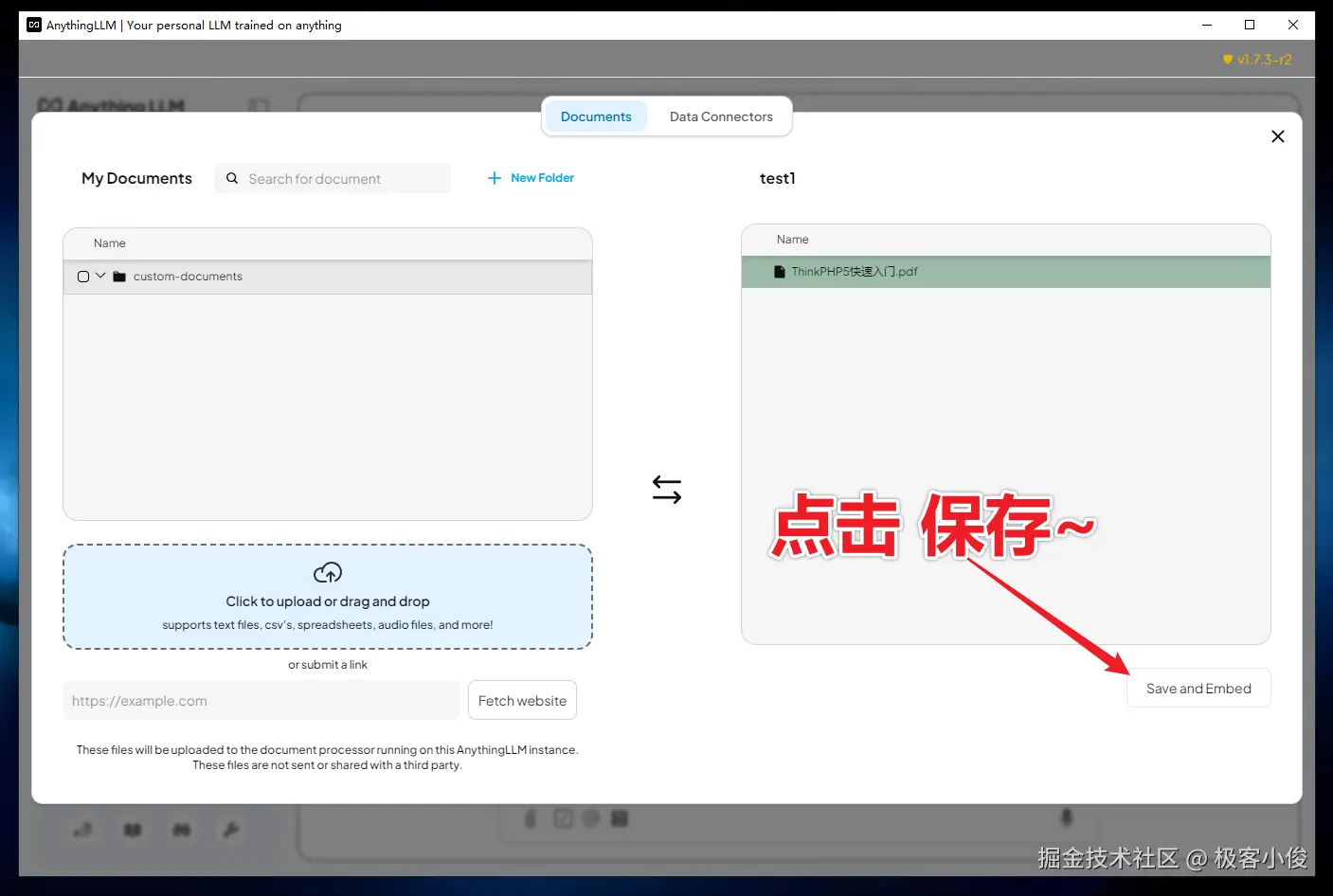
接着点击保存嵌入(Save and Embed)
如图
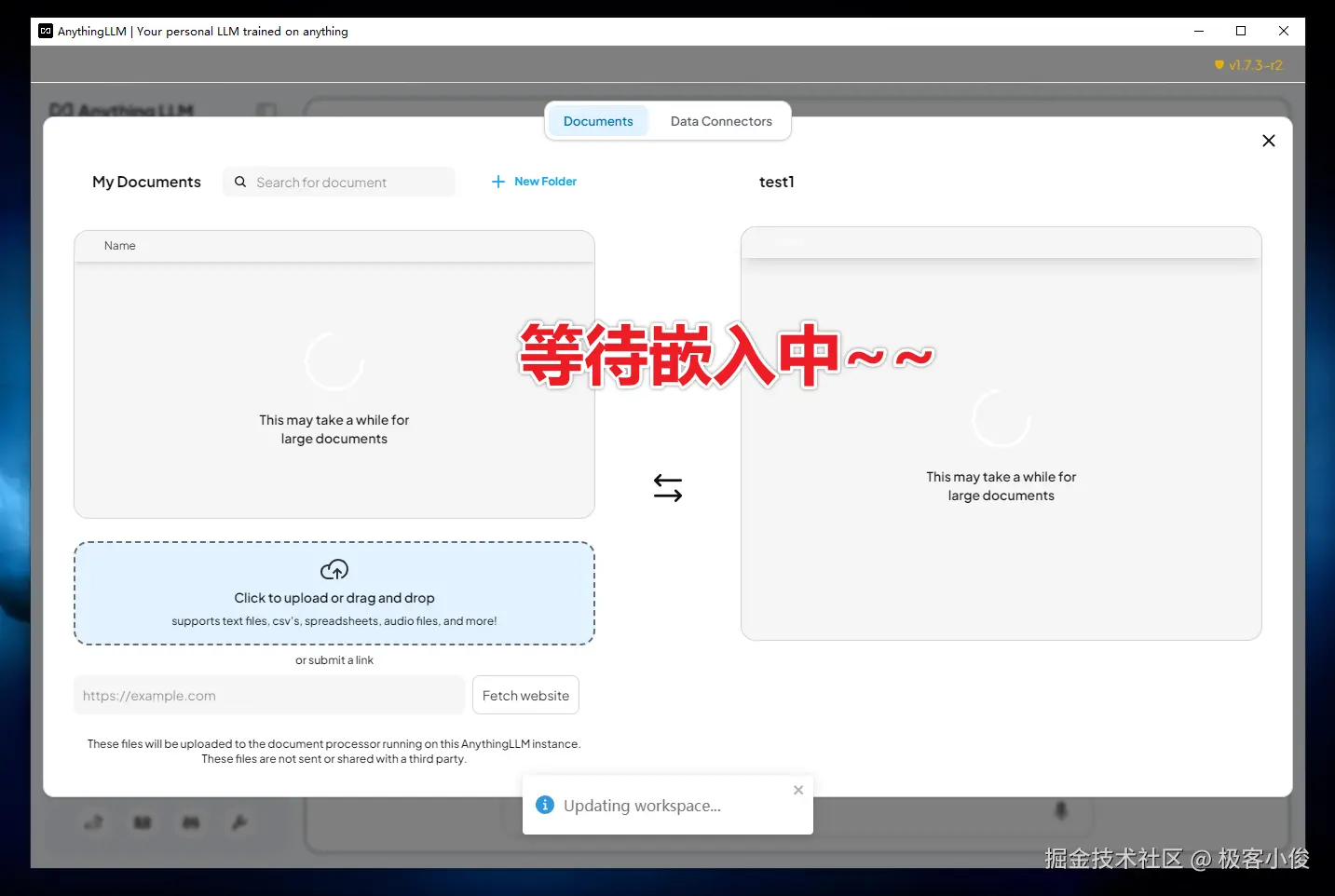
然后会进入到等待分析状态~~~
如图
加载完成之后,在工作区列表中,把上传文件的图钉点选上
如图
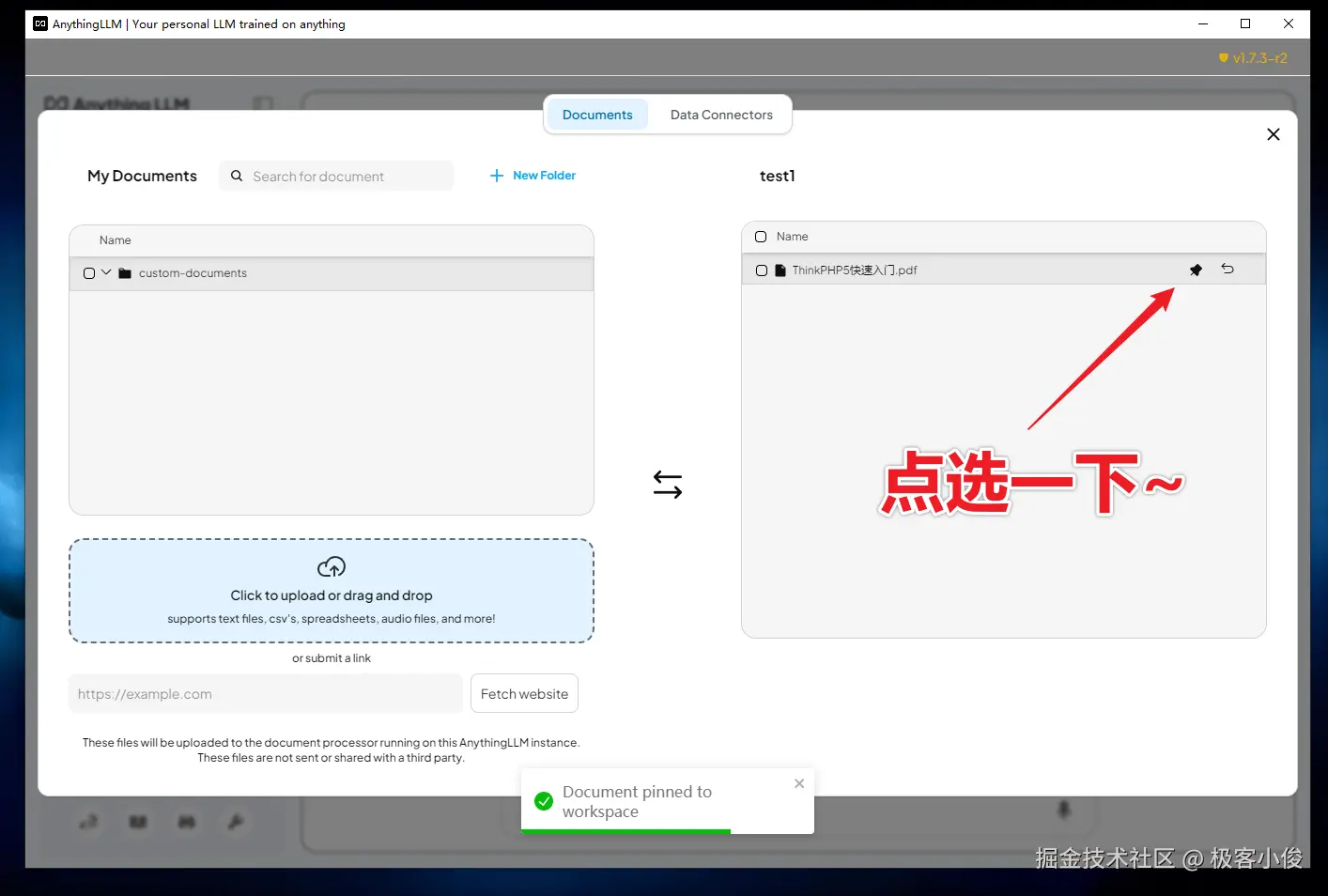
完成部署
最后你就可以开始用自然语言进行提问了,我们就来询问一下刚刚上传的文档
让AnythingLLM + DeepSeek来分析和理解,并最终给出结果!
如图
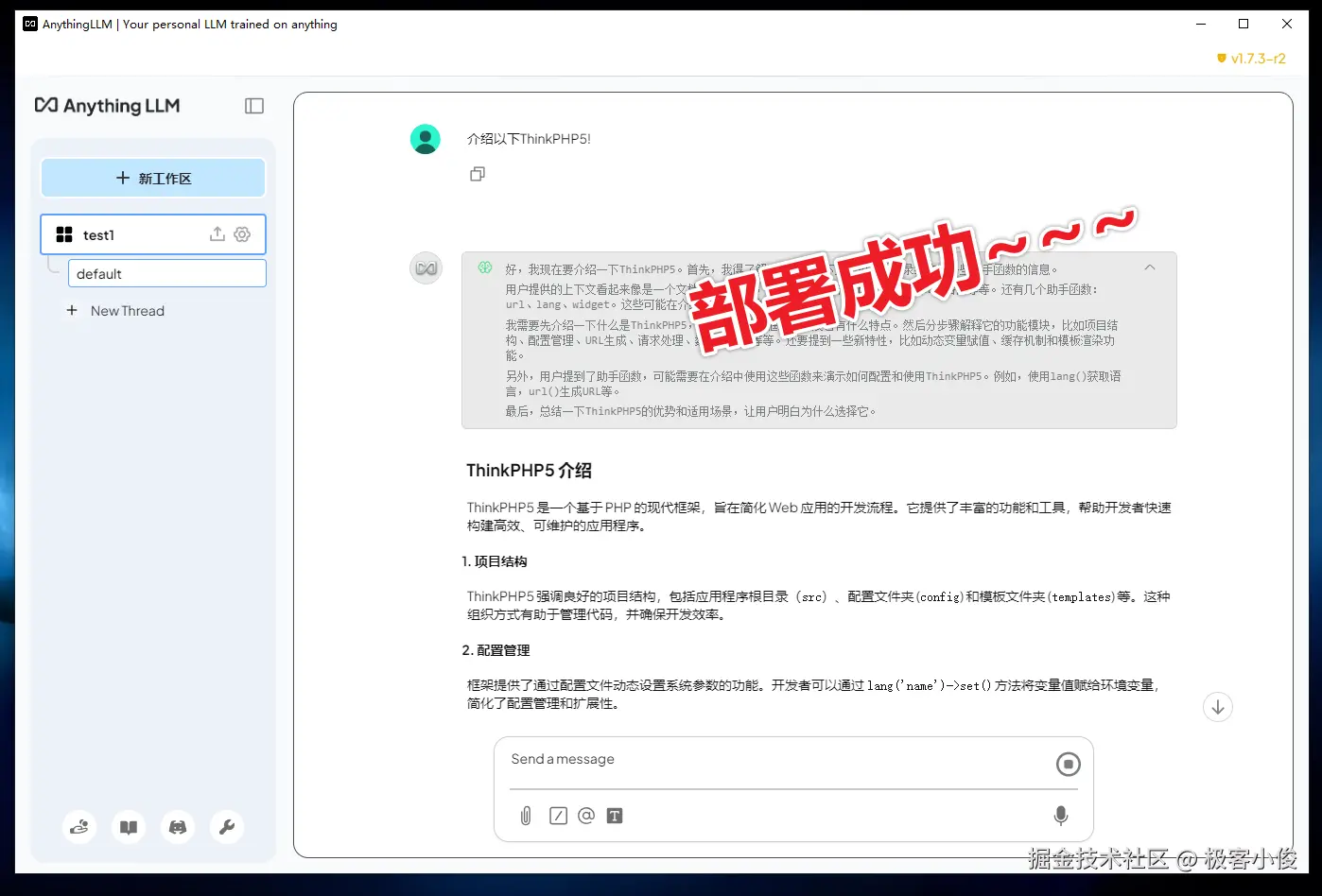
怎么样现在你的电脑就相当于一个真正的智能管家了~ 随时待命
像我们这种开发者,设计师就需要经常查文档的场景需求下,特别有用!
当然文档你可以上传很多,反正都是上传到自己电脑上,又不怕别人拿走!
本地部署AI知识库注意事项
文档类型准备
不知道你们有没有注意到一个问题,就是大家部署了本地知识库之后,可能会有回答问题不准确的情况!
首先大家要明白不是所有的文档类型都可以拖拽到知识库里面去投喂的!
特别提醒
扫描文档生成的纯图片PDF文件,这种文件你拖拽到知识库中可能就会造成无法识别的情况!
我个人建议最好拖入纯文本的形式的文件到知识库,并且是结构化清晰的纯文本格式的文件,这样拖拽到知识库中方便AI识别率会提高!
实在是想拖入这种图片扫描的PDF文件,那你就要提前先处理一下,把内容提取出来再说!
嵌入模型配置
这里简单的解释一下,嵌入模型确实可以被用来将文本信息转换为向量,从而实现内容匹配。
使用嵌入模型将知识库中的文字、文章等文本内容转换为向量表示,然后当我们查询时,也可以将查询内容转换为向量,并在向量空间中计算查询向量与知识库中`向量之间的相似度,从而找到最相关的内容
至于向量这玩意你可以把它想象成一个有方向、有大小的箭头,在数学和计算机里,它就是一串数字,能帮我们表示和计算很多东西,比如位置、速度、力这些,简单的说就是这样一个原理!
当然这里的AnythingLLM给我们默认设置了嵌入模型AnythingLLM Embedder 选项
如图
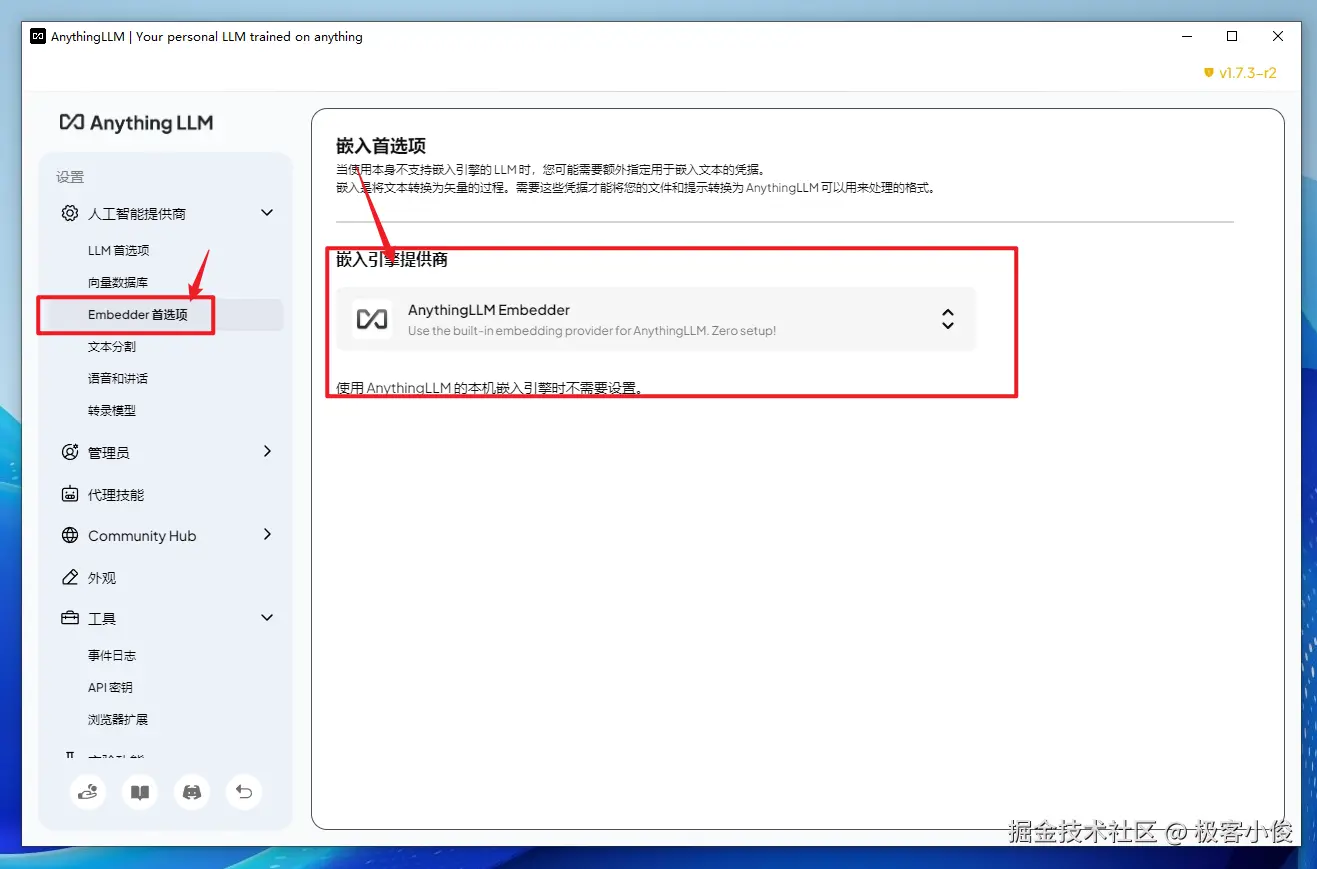
我们也可以通过Ollama命令在cmd命令行中安装其他嵌入模型
例如
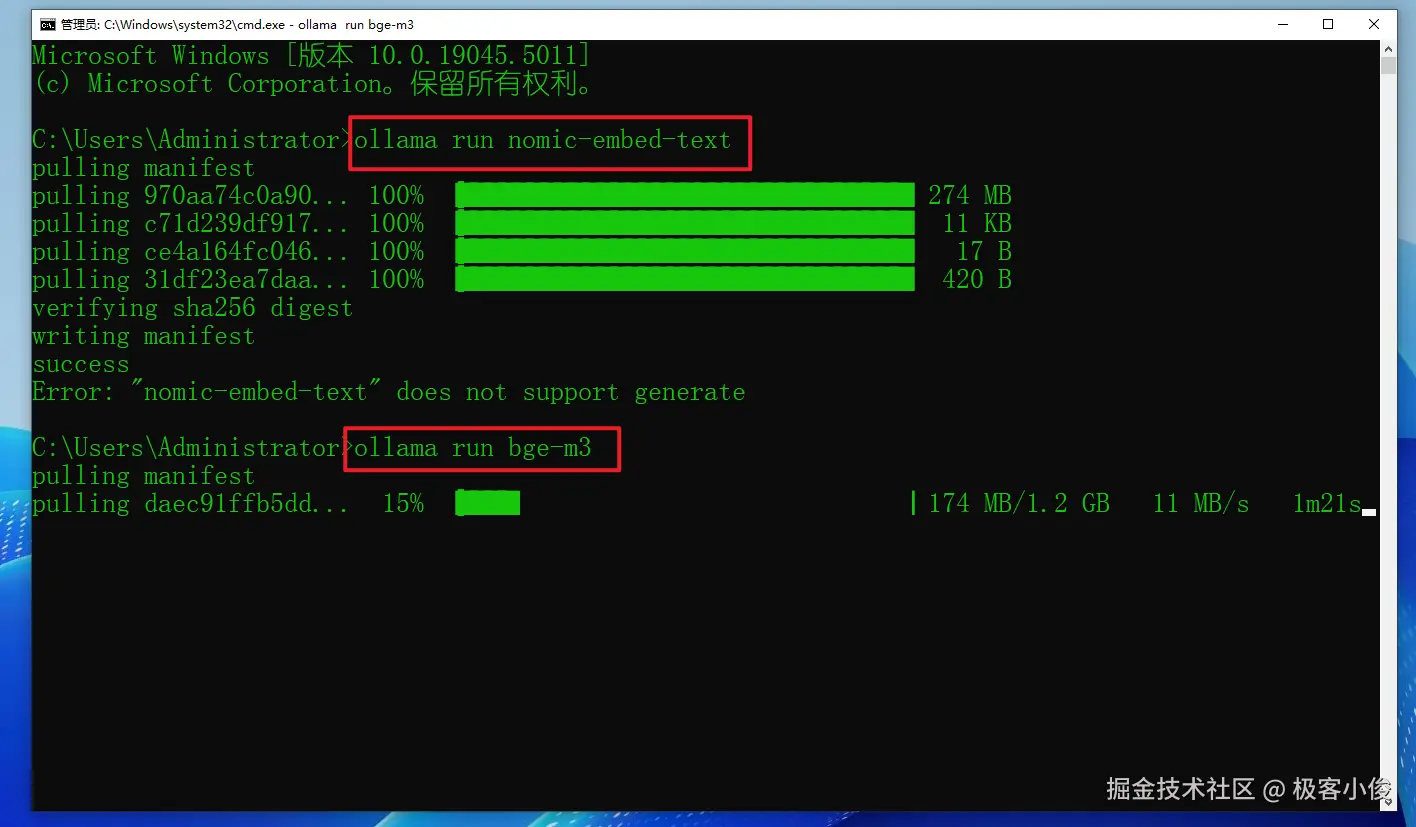
java
ollama run nomic-embed-text
ollama run bge-m3首先保证Ollama启动的状态之下,打开cmd命令行执行上面的命令,然后稍稍等待..
如图
然后我们再次进入到Embedder选项中的嵌入引擎设置,先选择一下Ollama
如图
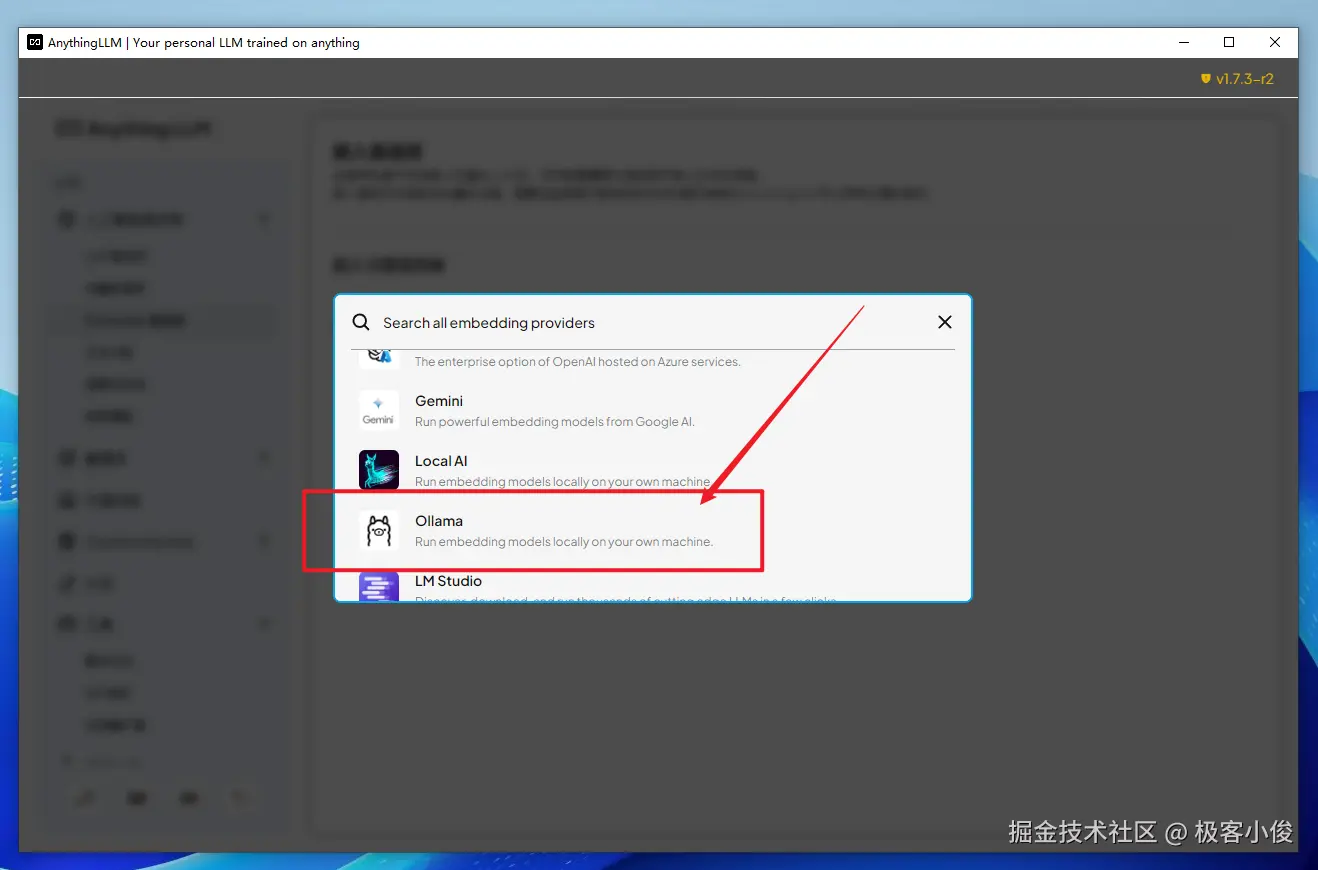
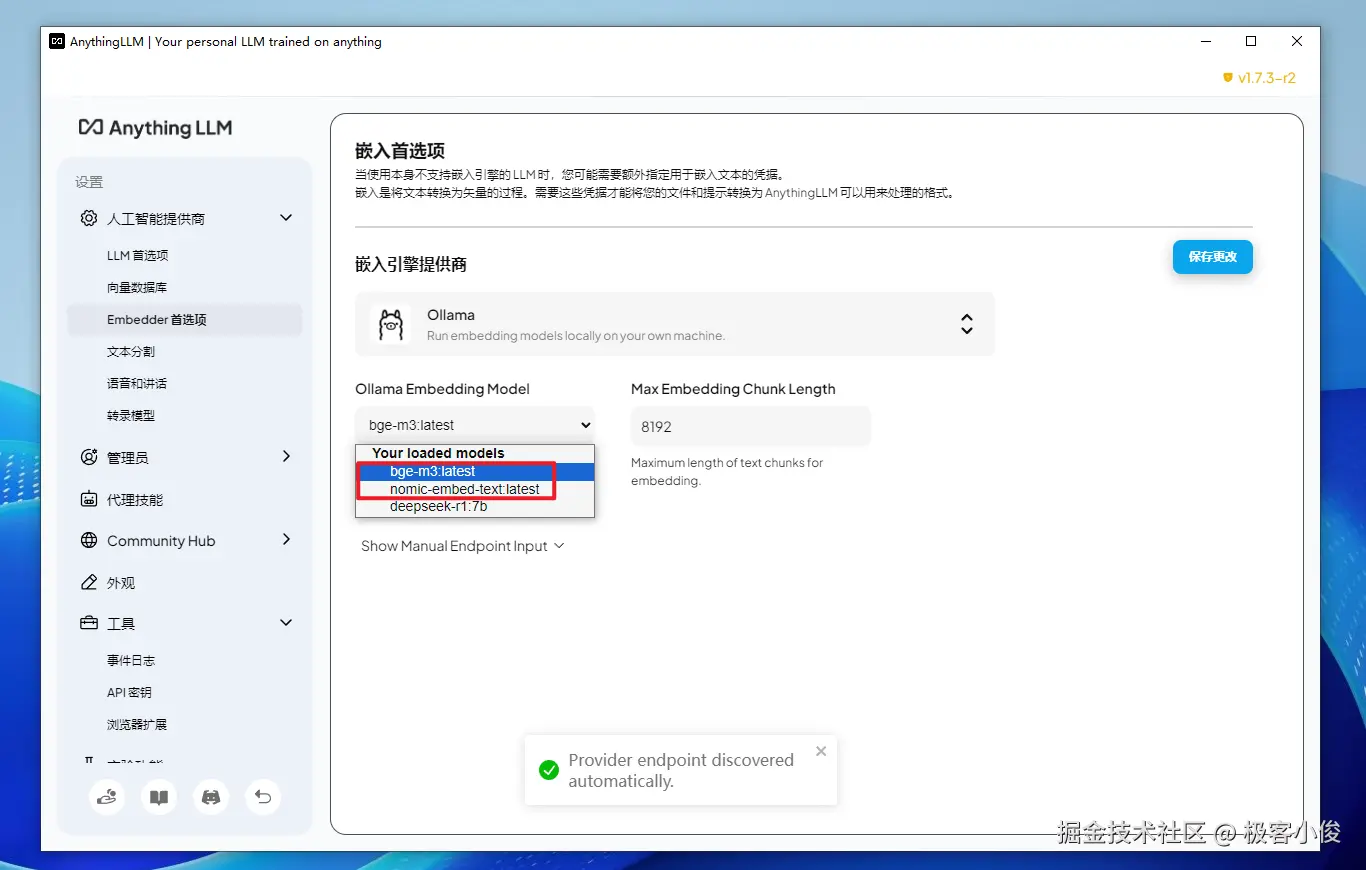
然后你会看到刚刚下载好的嵌入模型选项,选择一个自己合适文档处理的嵌入模型即可!
如图
最后
本地部署虽然爽,但对你的电脑硬件资源能不能带得动是有一定要求的!
当然如果你看到这里说明也成功运用DeepSeek+Ollama+AnythingLLM搭建起了一个功能全面的本地知识库了吧!
这不仅高效检索信息,还能智能理解和回应查询,展现了技术整合的强大力量,极大地提升了知识管理与利用的效率, 简直不要太方便~ 赶紧马上去试试看吧~