前言
嗨,我又来了!
最近在做项目的时候,突然遇到一个看起来"不值一提",但实际超级麻烦的需求:通过 Markdown格式快速导入内容。
一开始我以为不过就是个输入框,贴进去Markdown,不就完事了嘛?
结果......老板一句话:希望预览的效果和编排页面的效果一致,即标题正文等需要有特定的样式效果。
好家伙,我这小心脏差点没蹦出来。这不就是想要我搞一个和掘金写文章用的编辑器一样的效果么,真是太高估我了-_-||
🧠 背景:为啥我们非得搞Markdown导入?
简单说吧,我们是做在线教学平台的,经常需要从老师写好的内容(Word、Markdown、pdf)里提取章节、段落、内容块,然后导入系统。
之前的方式是这样 👇:
- 老师发来一堆
Markdown或Word文档; - 编辑手动复制粘贴,每一小节拆成一条数据;
- 排版、加字段、配ID、设类型......过程繁琐;
- 时间长了不仅人崩溃,导入的准确率还低。
所以产品就想,是不是可以这样搞:
粘贴Markdown内容 ➜ 自动解析 ➜ 自动结构化数据(包含标题、正文等)➜ 直接导入系统真是方便你和他,苦了我的妈呀!难搞。。。
🤔 怎么搞?直接上AST解析?
你别说,我还真想过:
用markdown-it,一解析就是AST(抽象语法树),该有的信息全都有,想拆结构那不是分分钟?
但一动手我发现:
AST太复杂了!一堆token、position、open/close......- 表达简单结构还好,想保留样式、层级、嵌套,就得写一堆递归;
- 还得处理插件、扩展语法、语义匹配,累人还慢。
我直接想骂人。
而且我看了掘金所开源的编辑器,发现只开源了编辑器,相关主题没有开源呀,这就更难办了,自己写?不可能,绝对不可能!
然后无意间,我打开控制台,试着在markdown编辑器上输入一些东西,然后看到了希望。
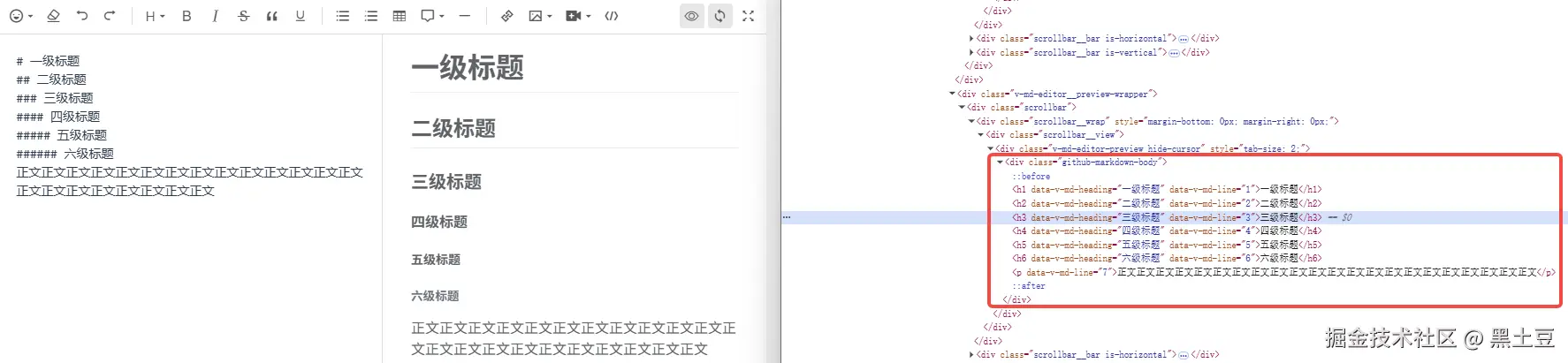
编辑器会给我生成一段有规律的HTML结构,啊?这不有戏?我只需要解析这段结构代码不就可以实现?淦,天无绝人之路啊!
所以我果断换思路:让浏览器帮我渲染Markdown,然后从DOM里提取内容结构就好了!
是不是突然感觉我有点小聪明😎
💡 技术方案设计:借助Markdown渲染 + DOM提取
总体流程长这样:
markdown
用户粘贴Markdown文本
↓
组件渲染Markdown(通过g-markdown-simple)
↓
生成DOM(包含标题、正文等标签)
↓
通过JS读取这些DOM,拆成结构化数组
↓
结构化数据就可以上传啦!是不是看着挺简单的?
但别急,坑才刚刚开始......
🛠️ 实现重点功能:从编辑器到结构化数据
1️⃣ 用户界面 ------ 用Element Plus + Vue3写个弹窗
ini
<el-dialog v-model="showDialog" title="导入 Markdown" width="900px">
<el-radio-group v-model="isRaw" @change="onToggle">
<el-radio-button :value="true">原始文本</el-radio-button>
<el-radio-button :value="false">预览效果</el-radio-button>
</el-radio-group>
...
</el-dialog>用户可以在弹窗里粘贴Markdown,然后选择「预览效果」来看看解析后的样子。
顺手加个"清空"按钮,"确定"按钮,基本上用户体验就够了。
2️⃣ 渲染Markdown:让组件帮我们生成DOM
我们项目中用的是v-md-editor,它内部会把Markdown渲染成.github-markdown-body样式的HTML。
那我们只要一切换到预览,就可以偷偷执行这段代码:
ini
const parseMarkdownAndSetData = () => {
const node = document.querySelector('.github-markdown-body')
if (node) {
const html = node.outerHTML
parseData.value = parseHtmlToData(html)
isRaw.value = false
}
}完美!现在只要搞定parseHtmlToData()就大功告成!
🧩 重头戏:如何把HTML拆成结构化JSON?
终于到了这波最有技术含量的地方。
我的目标是把这种结构:
css
<h2>第一章 入门</h2>
<p>这是正文内容...</p>
<h3>1.1 小节</h3>
<p>再来一段正文...</p>拆成:
bash
[
{ type: 'H2', content: '第一章 入门' },
{ type: 'text', content: '这是正文内容...' },
{ type: 'H3', content: '1.1 小节' },
{ type: 'text', content: '再来一段正文...' }
]于是我写出了这个杀器:
ini
const parseHtmlToData = (html: string) => {
const container = document.createElement('div');
container.innerHTML = html;
const nodes = container.firstChild?.childNodes || [];
const result: any[] = [];
let currentContent = '';
const hTypeMap = {
H1: 3,
H2: 4,
H3: 5,
H4: 6,
H5: 8,
H6: 9
}
const flushText = () => {
const text = currentContent.trim();
if (text) {
result.push({
sectionDataType: 2, // 正文
content: text,
name: null,
sectionDataId: uuid(6) // 唯一id
});
currentContent = '';
}
};
for (let node of nodes) {
const tag = (node as Element).tagName;
// H1-H6标题
if (/^H[1-6]$/.test(tag)) {
flushText();
const text = (node.textContent || '').trim();
result.push({
sectionDataType: hTypeMap[tag],
content: text,
name: text,
sectionDataId: uuid(6) // 唯一id
});
} else {
currentContent += node.outerHTML || node.textContent;
}
}
flushText();
return result;
};为什么H1-H6对应这么奇怪的枚举值,那是因为我们渲染页面就是这么定义的,所以为了保持数据结构一致,导入的时候把数据传递给编排页面能完美渲染相关的样式。
是不是不复杂?但足够实用!来看看效果吧~
🧨 开发过程中那些想打人的瞬间
❌ 问题1:预览的时候.github-markdown-body还没加载完
点完"预览",结果DOM还没渲染出来,querySelector直接空了。
✅ 解决:加个
nextTick保证DOM已经生成
❌ 问题2:某些Markdown会生成奇怪结构,比如嵌套<div>
导致解析时候顺序错乱,或者正文中夹杂一堆无效空格。
✅ 解决:在
flushContent()里加.replace(/\n+/g, '')并手动清洗空DOM节点
❌ 问题3:有时候用户输入不规范Markdown,比如标题后没有空行
解析结构就乱了。
✅ 解决:引导用户输入规范格式,或者加个「格式化预处理」工具(这块我还没搞,欢迎补充)
📊 这套方案的优缺点,你得知道
| 👍 优点 | 👎 缺点 |
|---|---|
| 实现简单,依赖已有Markdown渲染 | 无法精准识别复杂Markdown AST结构 |
| 用户体验不错,所见即所得 | DOM结构不标准会导致识别失败 |
| 容易维护,逻辑清晰 | 难以支持多层嵌套、表格、公式等特性 |
不过说实话,对于我们这种"导入章节文本"级别的需求,完全够用了!
🧠 总结:我学到/踩到的那些坑
- 能不用
AST就别用,尤其是赶项目上线的时候; DOM操作记得等nextTick(),不然抓不到;DOM字符串处理要特别小心空节点和格式问题;- 如果你愿意折腾,可以把这套解析逻辑改成
markdown-it插件形式,支持更多格式; - 最重要:写
Markdown的人最好规矩点,不然前端会哭!
如果你也在搞Markdown内容导入、章节管理、自动拆结构的事情,欢迎参考我这套办法。 用轻巧的方案,干掉大问题。
后语
小伙伴们,如果觉得本文对你有些许帮助,点个👍或者➕个关注再走吧^_^ 。另外如果本文章有问题或有不理解的部分,欢迎大家在评论区评论指出,我们一起讨论共勉。