Hallucination of Multimodal Large Language Model: A Survey
Paper Link: https://arxiv.org/abs/2404.18930
Catalogue
- [Definition and Category of Hallucination](#Definition and Category of Hallucination)
- [Hallucination Causes and Solutions](#Hallucination Causes and Solutions)
- [Benchmark and Metrics](#Benchmark and Metrics)
- [Challenges and Future Directions](#Challenges and Future Directions)
Definition and Category of Hallucination
Definition
幻觉(Hallucination)指MLLM的输出与视觉输入不一致或生成事实错误的文本内容。
Category
幻觉的分类,主要分三种
-
Object Hallucination
即生成的内容中包含了图像输入中不存在/不正确的物体
-
Attribute Hallucination
即错误描述已存在物体的属性(这里将对象计数 / 对象事件等统一归入属性幻觉)
-
Relation Hallucination
即错误描述物体间的空间或逻辑关系
Architecture of MLLM
现代的主流 MLLM 架构主要分两种,一种是 Interface-Based MLLM ,另一种是 End-to-End的 MLLM。
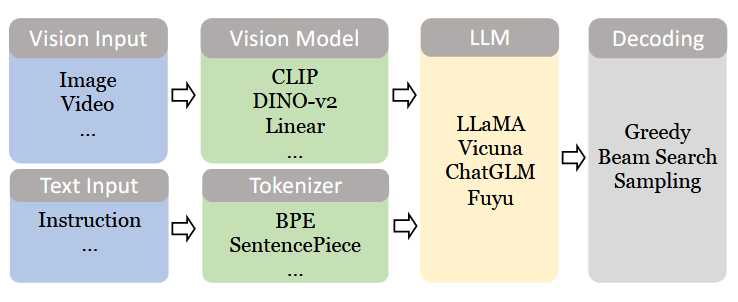
上面是 Interface-Based MLLM 的模型架构,主要有视觉部分和文本部分组成。
视觉部分负责接收视觉输入并进行视觉特征提取,然后将视觉信息通过 vision model 和 LLM 连接的 interface 映射到 LLM 的输入嵌入空间中,这一步即实现了模态转换。
文本内容处理与 LLM 的文本处理过程相同,先进行分词、向量化,在 decoder 中自回归预测下一个 token 。
Training Stage
MLLM 的训练和 LLM 的训练阶段类似,主要有两部分:预训练(pre-train)和 SFT
pre-train
预训练的主要目的是完成跨模态对齐,具体的方法是冻结vision encoder 和 LLM ,仅训练vision model -> LLM的模态转换接口,完成视觉特征到 LLM 输入embedding 空间
这个阶段用于评估训练效果的指标仍然是 LLM 的输出,传统上使用的是交叉熵损失,现在流行使用对比损失和图文匹配损失来增强对齐效果。
SFT
和 LLM 的 Instruction Tuning 一样,目的是让 MLLM 能够遵循人类指令,从而更好的进行交互。
需要构造 视觉内容 - 指令 - 回答 格式的数据集,利用 FFT / LoRA等方法进行微调。
Hallucination Causes and Solutions
幻觉的成因主要分为四个方面:数据(Data)、模型(Model)、训练(Train)和推理(Inference),数据是幻觉的主要原因。
1. 数据(Data)

数据层面具体有三种幻觉成因,分别是数据量(Quantity)、数据质量(Quality)和统计偏差(Statistic Bias)
-
数据量不足:MLLM 的训练数据量远没有 LLM 的数据量大,所需的图片-文本对数据集和视觉问答数据集不够多,数据量不足可能会导致跨模态对齐出现问题,从而产生幻觉。
-
数据质量不高:
-
噪声数据(Noisy data)
预训练所使用的由网络上爬取的图片-文本对数据可能含有未对齐、不准确或损坏的数据,不利于进行模态对齐。
SFT阶段使用人工标注的数据相比使用 GPT-4 这种非视觉语言模型进行标注效果要更好,因此需要注意使用模型标注所带来的潜在幻觉影响。
-
缺少多样性(Lack of Diversity)
主要是 SFT 阶段,大多数的数据都是关于图像内容和理解的正例(Positive Instruction),缺少一些负例(Negative Instruction)和拒答(Rejection Instruction)。这导致在使用场景中模型对任意的指令都偏向于正例回答,即使正确的描述是错误或者拒答。基于这些内容需要平衡训练数据中的多样性。
-
开放问题(Open Question): 训练数据的细粒程度
有一些研究发现训练数据中没有完整的描述物体位置、物体属性和物间关系,导致模态对齐时有一定的偏差,模型失去定位能力;而另一些研究发现过于详细的描述信息可能超越了 LLM 的感知极限,导致一些细节难以被模型捕捉到,从而产生幻觉。
-
-
统计偏差(Statistic Bias)
有研究指出,训练数据中的实体(物体)分布对模型的表现有显著的影响,主要是频繁出现的物体(Frequent Objects)和共现物体(Objects Occurrence)两个主要的统计偏差类型。 统计偏差存在于大多的数据集中,能够通过增加数据量的形式减轻偏差,但是鉴于真实世界的长尾分布,无法完全消除偏差。
缓解方法

正负例均衡样本
引入负面数据(Negative Data)、反事实数据(Counterfactual Data)、推理数据(Reasoning Data)、数据清洗,构造 LRV-Instruction 正负例指令样本
- 负面数据:包含错误或负面信息的训练样本
- 反事实数据:构造与实际情况相反的假设性数据
- 推理数据:加强模型逻辑推理能力的训练数据
- 数据清洗:减少现有的数据集中的噪声和错误
因果数据(Counterfactual Data)
引入因果数据(Counterfactual Data),建立视觉信息与文本描述之间因果对应关系,提高模型对图像内容的准确描述和理解。
推理数据(Reasoning Data)
引入推理数据,通过训练内化指令和响应之间的推理逻辑。
数据清洗(Clean Data)
ReCaption: 重写图片-文本对的文本描述,从描述中提取关键词,然后使用 LLM 基于提取的关键词重写描述句子。
EOS Decision:EOS之前的工作指出,幻觉通常声称在描述中位置靠后的对象中出现,可能超越了 LLM 的感知极限,理想情况是能够及时终止生成过程。
2. 模型(Model)

流行的 MLLM 模型架构各个组件都是分离训练的,这就导致实际应用时各个模块的幻觉可能出现累积的情况。
主要的幻觉来源有弱:视觉模型、语言模型优先、弱对齐接口。
-
弱视觉模型(Weak Vision Model)
vision model 能力弱会导致根本上的多模态能力降低,具体表现为误分类(Misclassification)和视觉概念的误解
-
语言模型优先(Language Model Prior)
现代的 MLLM 架构中 LLM 通常比 Vision Model 更大也更强,导致多模态理解时过多的选择使用语言模型的先验知识而对视觉信息的关注过少,即注意力的分配不均衡。这种语言知识先入为主的模式使得 MLLM 忽略了视觉信息,导致幻觉的发生。
-
弱对齐接口(Weak Alignment Interface)
即使 vision 部分和 LLM 部分各自都表现得很好,模态转换的对齐接口设计对整体 MLLM 的表现同样的重要。它是视觉信息向 LLM 传递的关键,弱的对齐接口会导致视觉信息在传递信息过程中丢失导致传递信息不完整,从而产生幻觉。即使能够完整的传递视觉信息,分布的差异同样也会导致跨模态交互出现问题。
缓解方法

分辨率扩展(Scale-up Resolution)
提升视觉编码器的分辨率
改进通用视觉编码器 (Versatile Vision Encoders)
与纯视觉模型相比,MLLM 的vision model 在保持视觉细节方面有所损失,尝试使用 CLIP ViT 和 DINO ViT 的特征进行融合。总目的是提升 vision model 的视觉编码能力。
改进专用模块(Dedicated Module)
在 LLM 的语义空间中对齐视觉和文本特征(改进模态转换)
3. 训练(Training)

MLLM 的训练损失与 LLM 的训练损失相同,都是基于token的预测进行损失计算。有研究指出 MLLM 相对于 LLM 具有更加复杂的语义结构,token层级的损失可能不适合 MLLM ,可以考虑序列(sequence)层级的损失(语义损失);另一方面,相对于 LLM , MLLM 缺少了 RLHF (基于人类反馈的强化学习)导致幻觉的出现。
缓解方法
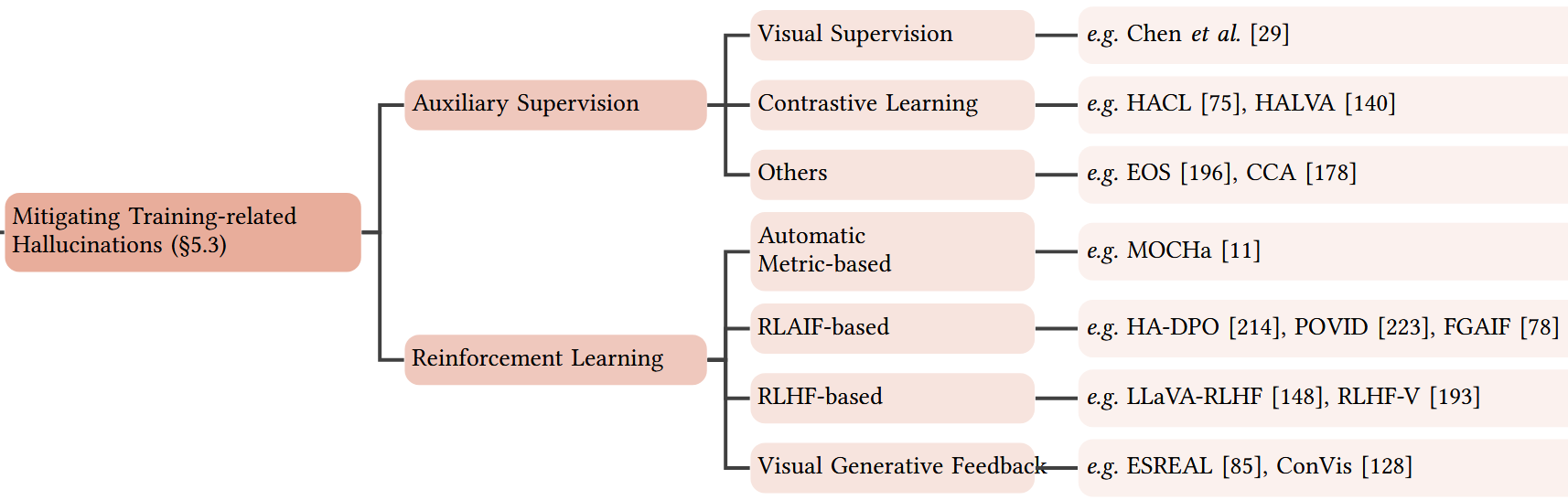
辅助监督(Auxiliary Supervision)
改进 MLLM 使用的与 LLM 相同的交叉熵语言损失,增加视觉监督
强化学习(Reinforcement Learning)
主要从三个方面入手:
-
基于指标的自动优化(Automatic Metric-based Optimization)
MOCHa:核心思路是将 token 级别的训练上升到 sequence 级别,借助 RL 的全局优化来减少幻觉
-
基于 AI 反馈的 RL (RLAIF)
HA-DPO:将幻觉问题转换成偏好选择问题,通过 RL 训练模型是模型优先选择准确回答而非幻觉回答
-
基于人类反馈的 RL (RLHF)
FDPO:通过利用个体示例的精细偏好直接减少生成文本中的幻觉,通过增强模型区分准确和不准确描述的能力
4. 推理(Inference)
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
推理阶段可能出现幻觉的原因主要有两个:视觉注意力不足 和不均衡的视觉注意力分配
-
视觉注意力不足(Visual Attention Deficiency)
自回归生成token过程中随着生成的序列变长,注意力机制会过多的关注于之前生成的文本token,视觉内容的注意力被弱化,导致输出与视觉内容无关,产生幻觉。
-
不均衡的视觉注意力分配(Trap Visual Tokens)
对于视觉 tokens 会赋予不同的注意力权重,但有时被赋予低权重的 token 往往包含着细节等关键信息,因此这些不均衡的注意力权重分配会引发幻觉的产生。
缓解方法
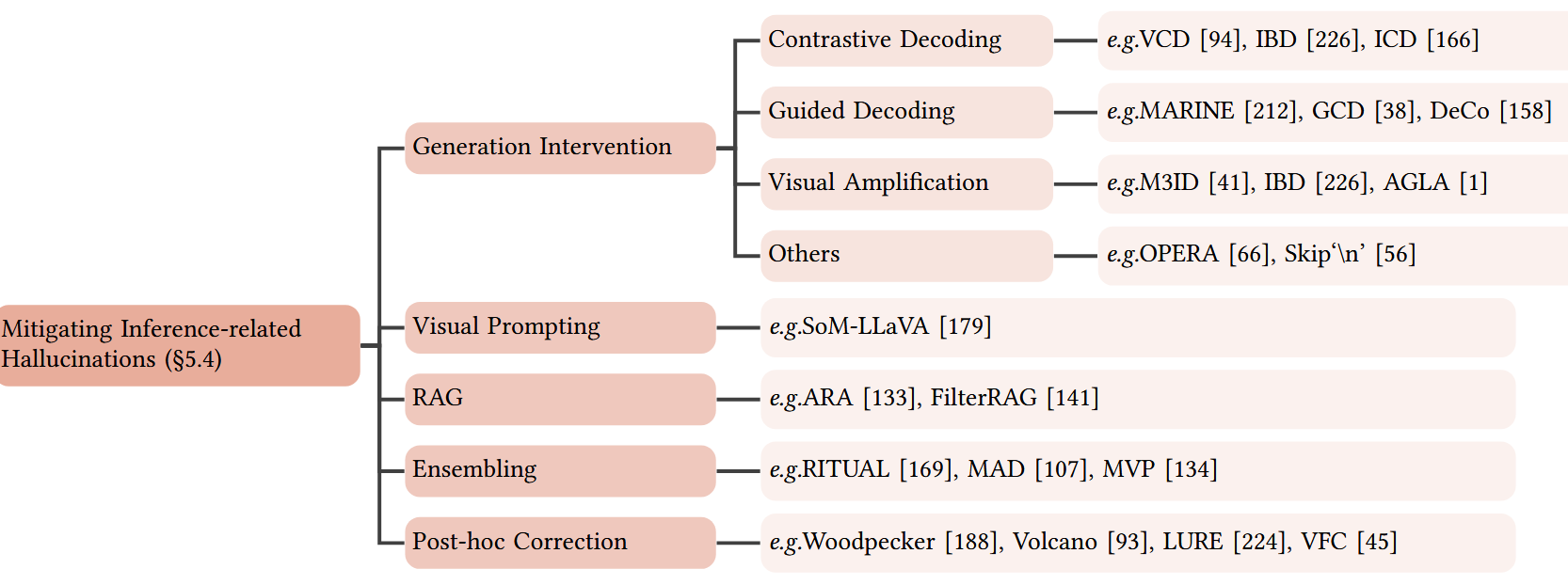
生成干预(Generation Intervention)
-
对比解码(Contrastive Decoding)
VCD(视觉对比解码):通过对比来自原始和扭曲视觉输入的输出分布,在解码阶段抑制 MLLM 的统计偏差和语言先验,解码概率分布通过参考(扭曲)分布进行校准。
-
视觉放大(Visual Amplification)
核心思路是放大自回归生成过程中对视觉信息的依赖。(残差连接???)
-
知识聚合
大多数幻觉与 Self-Attention Matrix 中表现的知识聚合模式密切相关,即大规模语言模型倾向于通过关注少数摘要词而非所有先前词来生成新词 ,部分过度信任的倾向导致忽视图像词,并用幻觉描述图像内容。提出了一种基于过度信任惩罚和反思分配策略的MLLMs解码方法
首先,在MLLMs束搜索解码过程中,对模型logits引入惩罚项以缓解过度信任问题。此外,为了解决惩罚项无法处理的困难情况,提出了一种更为激进策略,称为回滚策略,用于反思先前生成的词中摘要词的存在,并在必要时重新分配词选择。
-
RAG(Retrieval Augmented Generation)
参考 LLM 中通过 RAG 的方法降低幻觉的思路,在 MLLM 置信度和知识不足时启动。
-
后验修正(Post-hoc Correction)
先让 MLLM 生成文本响应,然后识别并消除幻觉内容,从而减少幻觉输出。
Benchmark and Metrics
主流的 MLLM 评测 Benchmark 和 Metrics
CHAIR
CHAIR 是早期的评估传统图像描述任务中的 Object Hallucination,该方法对真实描述中 sentence / object 进行分割,在生成的所有sentence / object 中计算幻觉比例,CHAIR 度量标准有两个变体: 基于 Object : C H A I R i CHAIR_i CHAIRi 和基于 sentence : C H A I R s CHAIR_s CHAIRs。
C H A I R i = ∣ h a l l u c i n a t i o n o b j e c t s ∣ ∣ a l l o b j e c t s m e n t i o n e d ∣ CHAIR_i = \frac{|hallucination \: objects|}{|all \: objects \: mentioned|} CHAIRi=∣allobjectsmentioned∣∣hallucinationobjects∣
C H A I R s = ∣ s e n t e n c e w i t h h a l l u c i n a t i o n o b j e c t ∣ a l l s e n t e n c e CHAIR_s = \frac{|sentence \ with \ hallucination \ object|}{all \ sentence} CHAIRs=all sentence∣sentence with hallucination object∣
CHAIR 的局限性
- CHAIR 需要先生成完整的描述,再检测描述中的幻觉物体,过程高度依赖指令设计(prompt)和生成长度,难以标准化。(使用的话需要统一 prompt 规范)
- CHAIR 仅检测是否存在未出现的物体,无法评估 Attribute Hallucination
POPE
基本思想是将 Hallucination Evaluation 转换为一个二元分类任务 ,向 MLLM 提出简单的是/否回答问题来探查幻觉。与 CHAIR 相比 POPE具有更高的稳定性和灵活性,引入了负采样策略,增强了评估的全面性,分为三个子负样本:
-
random
随机选择非图中 Object --- Object Hallucination
-
popular
选择数据集中高频出现但是当前图片中未出现的 Object --- Object Hallucination
-
adversarial
选择与图中 Object 共现但图中实际不存在的 Object --- Relation Hallucination
改进的 H-POPE 支持细粒度扩展,新增的 adversarial 策略能够选择图中存在但与被问 Object 无关的属性(如苹果是金属吗?) --- Attribute Hallucination
GAVIE
全称是"GPT4-Assisted Visual Instruction Evaluation"引入大规模多样化的视觉指令调优数据集 LRV-Instruction 来缓解 MLLM Hallucination。
GAVIE 无需人工标注真实答案,可以适应不同的指令格式,以GPT-4作为智能教师,对两个标准对学生答案进行0-10的评分:1)准确性:回答是否与图像内容产生幻觉 2)相关性:回答是否直接遵循指令。
NOPE
Negative Objective Presence Evaluation,旨在通过视觉问答(VQA)评估 MLLM 中的 Object Hallucination。
将 Object Hallucination 与 Fault 进行明确区分:
a) 对象幻觉是指VQA中视觉语言模型的回答包含不存在的对象,尽管真实答案是否定不定代词(如"none"、"noone"、"nobody"、"nowhere"、"neither");
b) 错误性是指视觉语言模型未能准确回答真实答案不是否定代词的问题
AMBER
An LLM-free Multi-dimensional Benchmark,无需 LLM 即可进行多维度基准测试,用于评估生成任务和判别任务,包括存在性、属性和关系幻觉。
AMBER 收集了一批高质量的图像并进行精细化的人工标注,采用双轨评估架构。
- 判别任务
- 采用 Yes / No 问答格式进行评估
- 二元回答能够直接与预设的标准答案进行精确匹配比较
- 生成任务
- 要求模型生成图像描述
- 使用 NLP 工具包如 NLTK 来自动提取生成文本中的对象名词,与预标注的真实对象列表进行比较
A M B E R S c o r e = A v g ( 1 − C H A I R , F 1 ) AMBER\ Score = Avg(1-CHAIR, F1) AMBER Score=Avg(1−CHAIR,F1)
Challenges and Future Directions
Data
数据多样性、数据增强以获得更多的数据、数据校准(消除偏见等)
Cross-modal Alignment and Consistency
架构上的创新、额外的学习目标、多样化监督信号
Advancements in Model Architecture
更强的视觉感知模型、创新的跨模态交互、忠实于输入视觉内容和文本指令
Establish Standard Benchmark
建立统一标准的评测基准
Enhancing Interpretability and Trust
从底层上研究幻觉的成因。。。 目前还是太难了