各位读者大佬好,我是落羽!一个坚持不断学习进步的学生。
如果您觉得我的文章还不错,欢迎多多互三分享交流,一起学习进步!
也欢迎关注我的blog主页: 落羽的落羽

文章目录
- 一、进程优先级的概念
- 二、查看优先级信息
-
- [1. PRI 与 NI 的理解](#1. PRI 与 NI 的理解)
- [2. 修改nice值](#2. 修改nice值)
- 三、进程调度切换
-
- [1. list_head 与 prio_array 结构](#1. list_head 与 prio_array 结构)
- [2. 活跃140队列与过期140队列](#2. 活跃140队列与过期140队列)
- 四、补充概念:竞争、独立、并行、并发
一、进程优先级的概念
CPU的资源是有限的,所以CPU的运行队列中的所有进程是不可能同时得到资源的。这就是为什么运行队列是一个"队列",而CPU分配资源的先后顺序,就是指进程的优先级。
二、查看优先级信息
使用ps -l命令,可以查看系统中更详细的进程信息:

其中,与进程优先级相关的信息是 PRI 与 NI ,它们也是存在于task_struct中的两个整型成员变量。
- PRI:代表这个进程可被执行的优先级,这个值越小越早被执行
- NI:代表这个进程的nice值
1. PRI 与 NI 的理解
PRI比较好理解,就是进程的优先级,也就是程序被CPU执行的先后顺序,此值越小进程的优先级越高。
NI,是进程的nice值,表示进程优先级的修正数值。
进程PRI值 = 80 + 进程nice值!
这是进程PRI的计算公式,nice变小,PRI会变小,进程优先级变高,反之亦然。
所以,调整进程优先级,在Linux下就是调整进程的nice值!
而优先级的变化范围是有限的!nice值的取值范围是-20~19,共40个级别。PRI的取值范围就是60, 99了!
2. 修改nice值
我们还是跑一个循环程序进行演示,此时查看PRI和NI是默认80和0,没有问题

一种修改nice的方式是:用top命令,修改已存在进程的nice值:输入top回车,再输入r回车,再输入进程pid回车,再输入修改后的nice值:
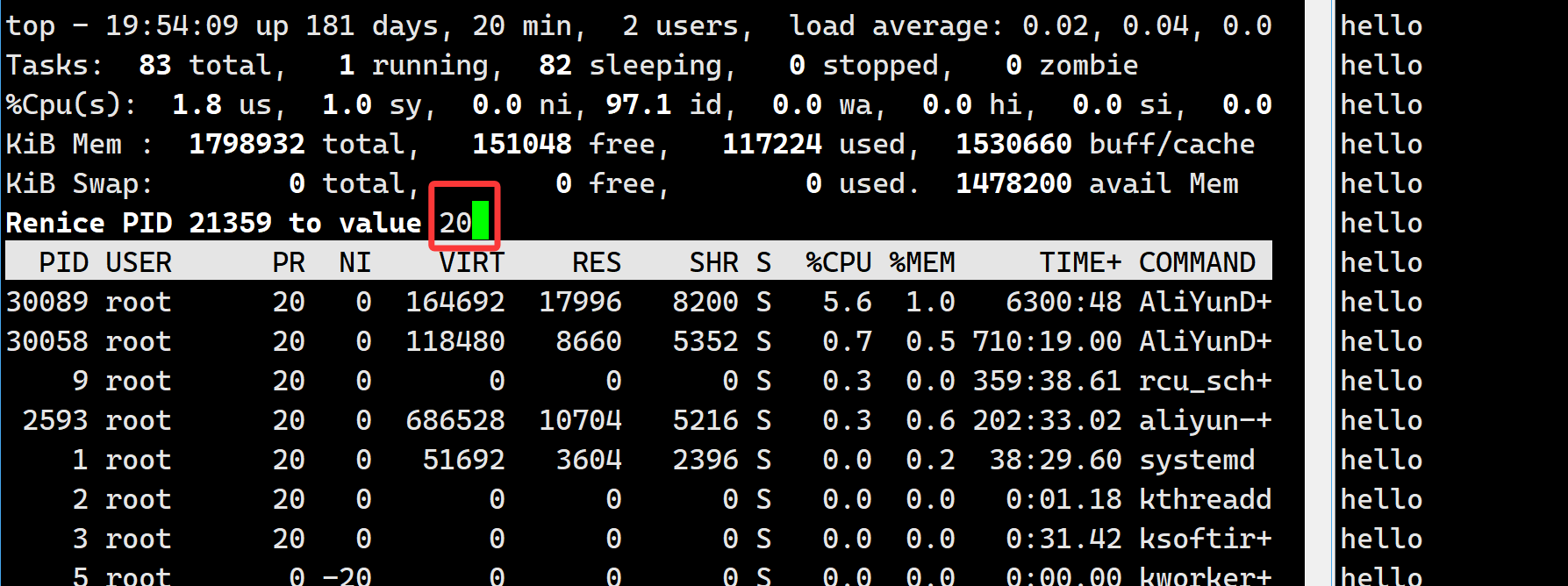
这里我将nice值修改为20。回车,按q退出top,再查询:

可以看到nice值成为了19,这是因为20超过了规定的nice值范围,最高只能修改到19。PRI值也就变成了19 + 80 = 99,没有问题。
但是,实际中我们不建议高频更改nice值。
三、进程调度切换
之前我们提到过,Linux系统会给每一个进程分配一个时间片,它的时间片执行完,就会自动让出CPU另一个进程接着执行。CPU内只有一套寄存器,由所有进程共享使用,每次保存着一个进程的私有上下文数据,它的时间结束后,这些数据转移到task_struct中的成员变量"上下文数据"中存放,寄存器中继续存放下一个进程的临时数据。再轮到这个进程执行时,临时数据再转移到寄存器中。这种操作系统,被称为分时操作系统,当代计算机大多数都是这种。
那么,系统是如何高效切换调度进程的呢?
下面讲解的,是Linux2.6内核进程的O(1)调度实现算法:
1. list_head 与 prio_array 结构
源码的task_struct定义中,有这样两个相关的成员变量:
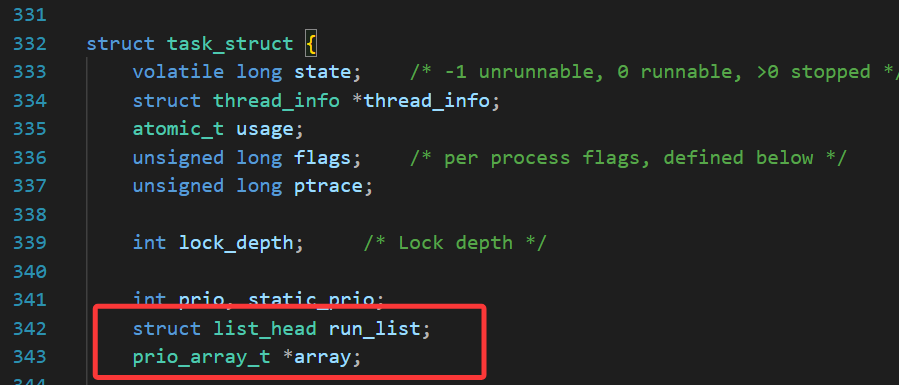
这两个成员结构的定义如下:
-
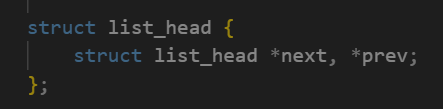
struct list_head是一个双向链表结构,run_list就是CPU运行队列的核心结构!
-
成员
prio_array_t *array,prio_array_t就是struct prio_array结构体。task_struct 里的 array 成员是当前进程所属的优先级数组指针,记录了这个进程现在是在活跃队列里,还是在过期队列里,下面讲。

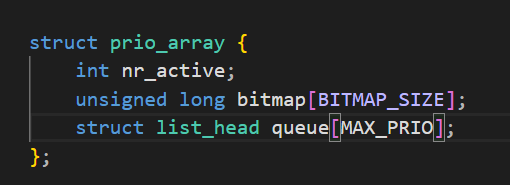
我们分析prio_array_t的结构:
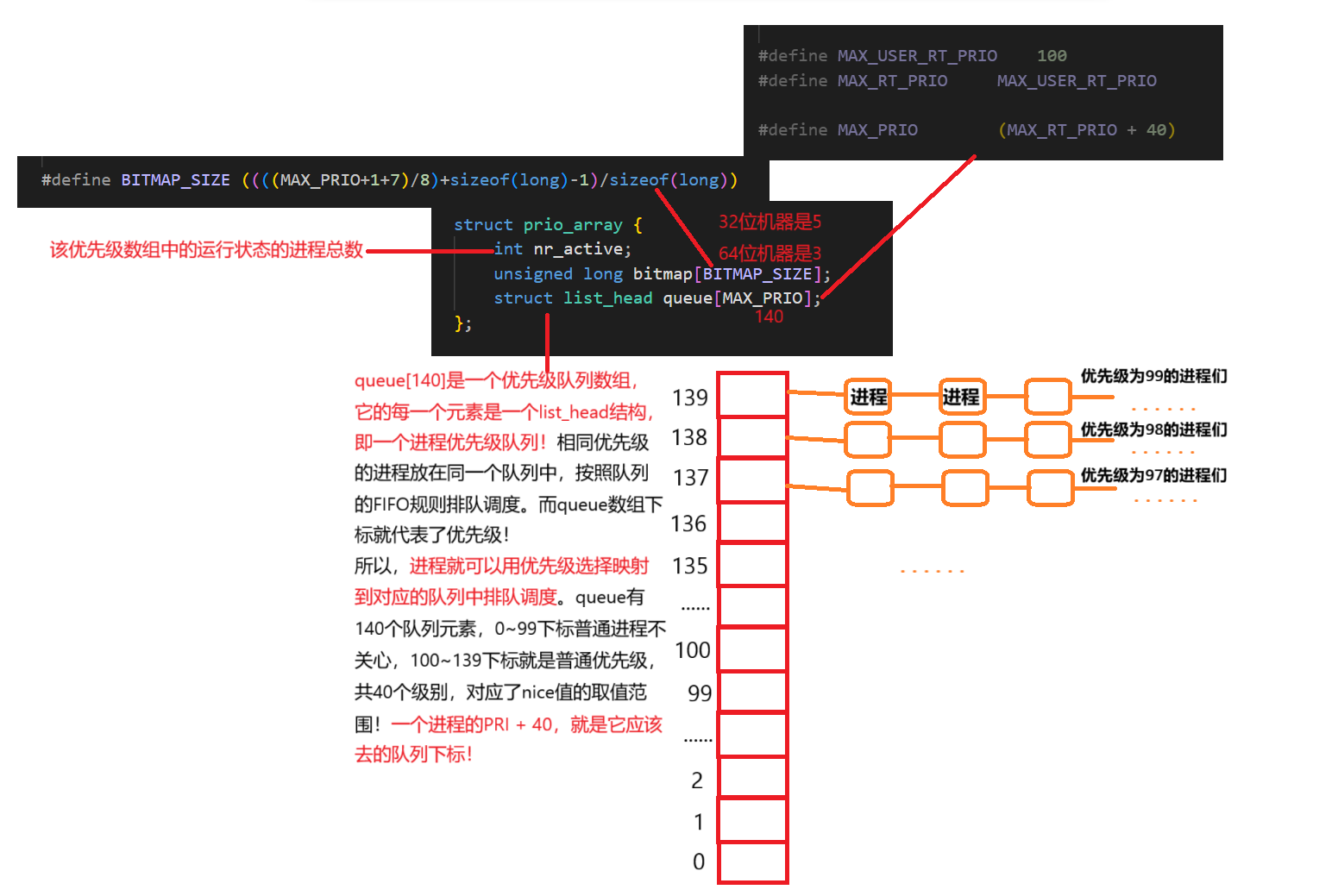
所以,根据优先级选择进程队列的过程,本质是hash!
可是,queue中存放的队列的结点是list_head类型啊,list_head中只有两个前后指针,没有进程信息啊!
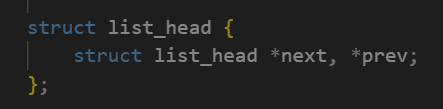
别急,一个知识点:
假设有一个结构体变量
struct A obj,它内部有一个成员变量a。如果我不知道结构体obj的地址,只知道它的a的地址。可以通过&a - &((struct A*)0->a)计算得出obj的地址!原理是结构体成员的地址偏移量是固定的,而且地址是由低到高开辟的,通过成员地址减去其在结构体中的偏移量,即可反推出结构体变量的起始地址。得到了结构体变量的地址,就能访问到其他成员了!
所以,实际上queue中的每一个list_head,就是一个进程的task_struct的成员变量struct list_head run_list!通过上述方法,就能用这个run_list的地址算出task_struct的地址了,进而能获取到进程的各种信息!
这种将链表节点嵌入到目标结构体内部,把run_list作为task_struct 的成员,是 Linux 内核中经典的 "侵入式链表" 设计,好处是无需额外内存开销、灵活复用、增加链式结构管理的扩展性。甚至,你可以将不同类型的结构连接起来,只要它们都含有run_list成员!
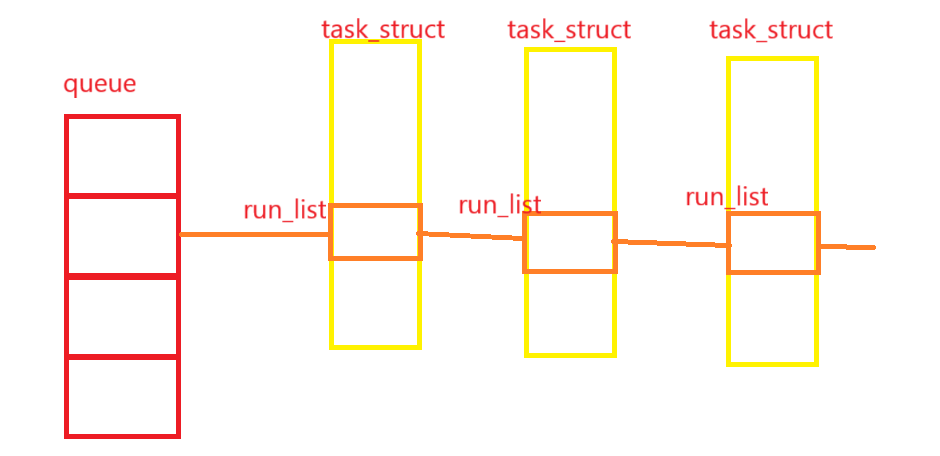
现在我们已经明确队列的结构了,那么如何从中选取一个合适的进程呢?
最简单的想法,就是按照优先级的规则,从下标0开始遍历queue,找到第一个非空的队列,依次调度其中的进程。由于queue大小固定140,这种算法的时间复杂度是O(1)。
但是,我们总是想要更好的效率。在prio_array中,还有一个bitmap数组,实际上这是一个位图!他用140个比特位表示140个进程队列是否为空,利用位运算,大大提高查找非空队列的效率!
2. 活跃140队列与过期140队列
一个CPU,拥有一个runqueue结构,即CPU的运行队列,这个结构的定义如下:

- active:称为活跃指针,指向的prio_array_t结构称为活跃140队列
- expired:称为过期指针,指向的prio_array_t结构称为过期140队列
- arrays:这个数组中,存放活跃队列、过期队列
活跃队列中,按照优先级,放着时间片还没有结束的所有进程。变量nr_active记录有多少个运行状态的进程。
过期队列中,放着时间片耗尽的进程。当活跃队列上的一个进程执行完,就放到过期队列上,重新计算它的时间片。
不难想象,随着进程不断被执行,活跃队列上的进程会越来越少,过期队列上的进程会越来越多。当活跃队列上所有进程都被执行完,直接交换active与expired指针,刚才的过期队列变成新的活跃队列,刚才的活跃队列变成新的过期队列!继续执行进程。
利用两套优先级队列调度切换进程,是非常巧妙的设计,我们会有以下特殊情况:
- 来了一个新进程,则这个进程先插入到过期队列中,等下一轮再开始执行!
- 修改一个进程的优先级,则这个进程在本轮中的位置先不变,等插入到过期队列时再计算新优先级位置,这也是为什么要有nice这个中间值的原因之一!
如果只搞一套队列,进程时间片用完或修改优先级时,需要在同一个队列里重新计算时间片、调整位置,会导致遍历队列的开销变大,新进程和过期进程混在一起,调度逻辑混乱。
有了这样一套完整的调度逻辑后,在系统中查找一个最合适的调度进程的时间复杂度就是一个常数,不随着进程增多而导致时间成本增加,我们称之为进程调度O(1)算法!
四、补充概念:竞争、独立、并行、并发
- 竞争:系统进程众多,而CPU资源较少,所以进程之间是有竞争性的。为了高效完成任务,竞争合理,就有了进程优先级。
- 独立:多进程运行,需要独享各种资源,各个进程运行之间互不干扰。父子进程之间也有独立性。
- 并行:多个进程在多个CPU下分别同时运行,这种称之为并行。不过我们目前大部分的计算机都是只有一个CPU的。
- 并发:多个进程在一个CPU下采用进程切换的方式,在一段时间内让多个进程都得以推进,称之为并发!