文章目录
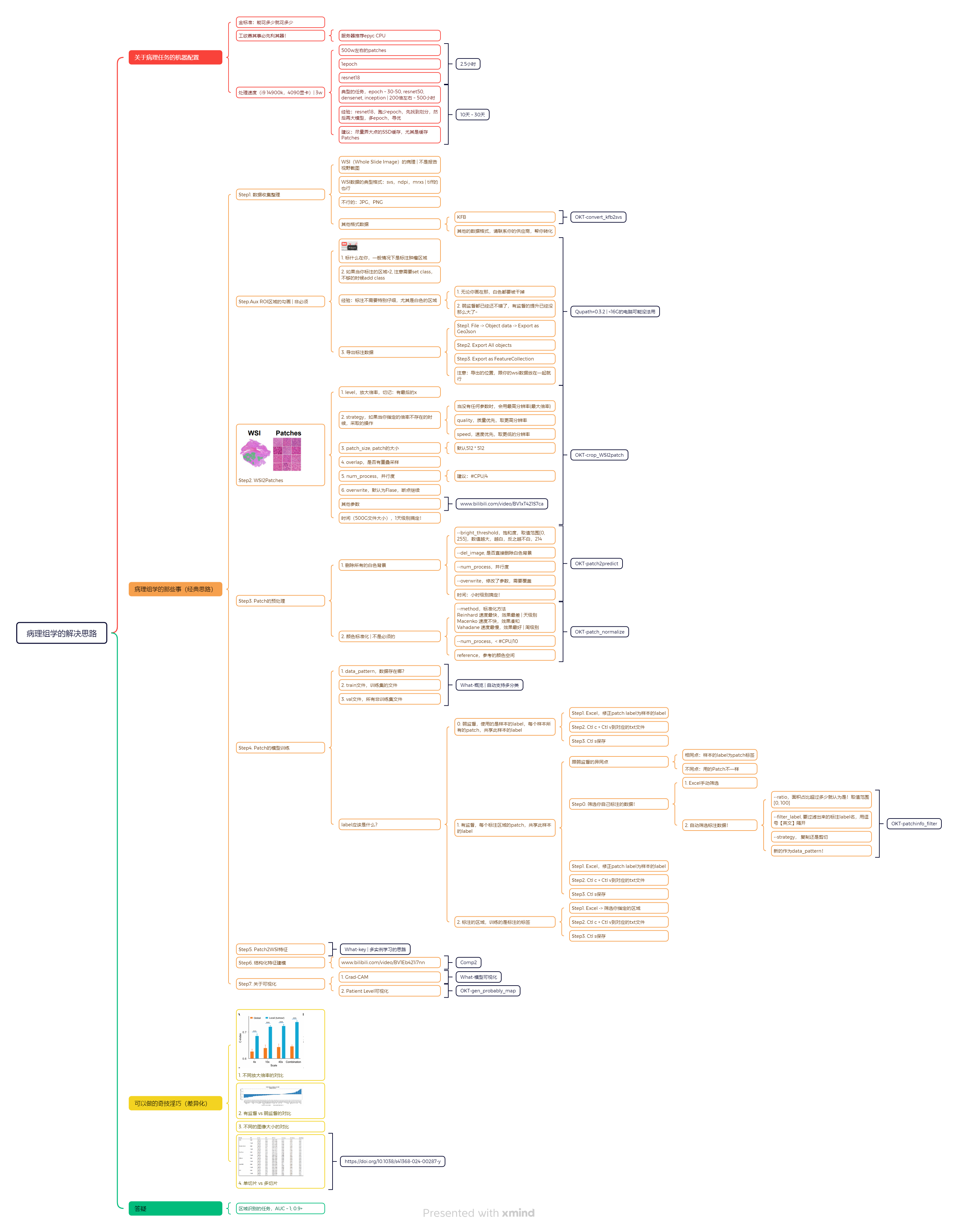
一、数据集
总结了一些常用的公开数据集,最常用的两个数据集是癌症基因组图谱(TCGA)和Camelyon数据集。这两种数据集通常用于分类和检测 。本研究还发现了两个WSI数据集TUPAC16和Kimia Path24 。TUPAC数据集应用广泛,如有丝分裂检测、乳腺肿瘤增殖预测、自动评分(分类)等。Kimia Path24常用于分类和检索。
WSI数据格式通常为svs、tiff格式
二、图像分割指标
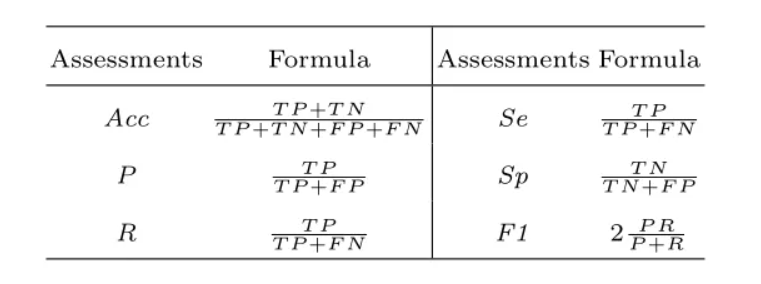
图像分割常用的评价指标有准确度、精度、召回率、F-measure、敏感性和特异性 ,其公式如表2所示。Dice系数(D)和Jaccard指数(J)是近年来比较流行的分割评价指标 。
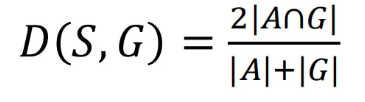
D表示两个个体相交的面积与总面积的比值,即ground truth与分割结果图的相似度。如果分割完美,则 D=1。假设S代表分割结果图,G代表ground truth。
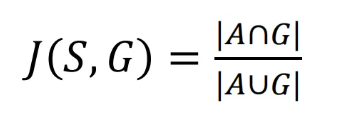
J表示两个个体的交集比,类似于D,表达式如上式所示。
三、分割方法
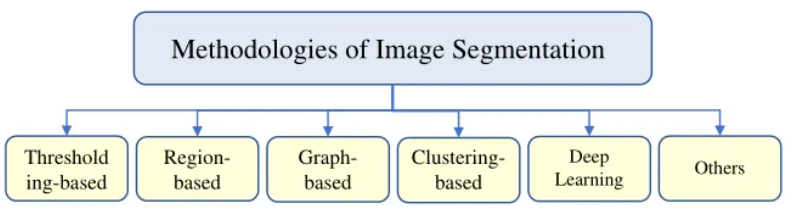
分割技术大致分为五种,包括基于阈值的、基于区域的、基于图形的、基于聚类的、深度学习和其他图像分割方法,其组成示意图如图下图所示,展示的是WSI分割方法的组成。
3.1、基于阈值的分割方法
它利用图像中要提取的目标与背景的灰度差值 ,通过设置阈值 将像素级划分为若干类别,实现目标与背景的分离。阈值分割方法计算简单,始终可以使用封闭和连通的边界来定义非重叠区域。目标与背景对比度强的图像可以提供更好的分割效果。
最优阈值的选择 是阈值分割的关键。常用的阈值选择方法有经验选择法、直方图法、最大类间方差法(OTSU)、自适应阈值法。由于阈值分割方法实现简单、计算量小、性能相对稳定,其成为图像分割中最常用的方法。作为一种基础的、应用最广泛的分割技术,它已被广泛应用于许多领域。
3.1.1、直方图法
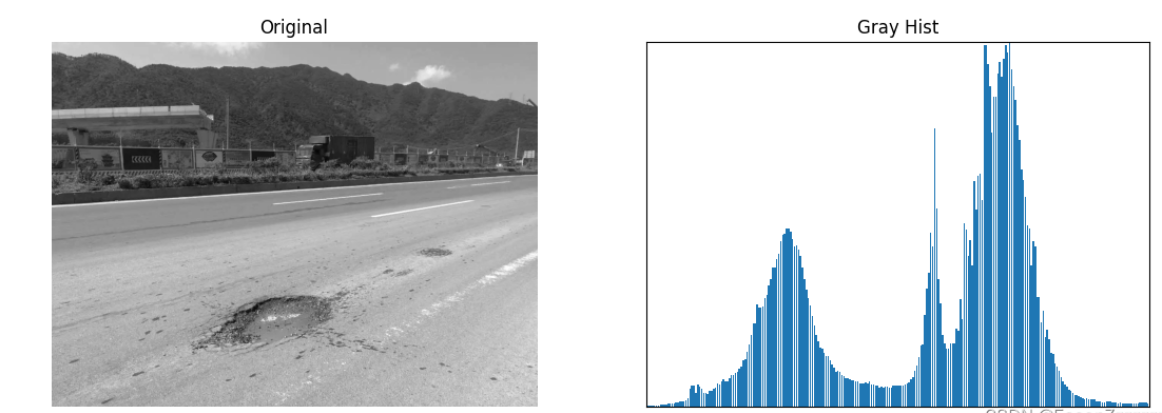
灰度直方图反映了图像中的灰度分布规律,直观地表现了图像中各灰度级的占比,很好地体现出图像的亮度和对比度信息:灰度图分布居中说明亮度正常,偏左说明亮度较暗,偏右表明亮度较高;狭窄陡峭表明对比度降低,宽泛平缓表明对比度较高。
横坐标代表灰度值的取值区间,纵坐标代表每一像素值在图像中的像素总数或者所占的百分比。
函数使用cv2.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate ]]) → hist
函数 cv2.calcHist 可以计算一维直方图或二维直方图,函数的参数 images, channels, histSize, ranges 在计算一维直方图时也要带 \[\] 号
参数说明:
- images:输入图像,用 \[\] 括号表示
- channels: 直方图计算的通道,用 \[\] 括号表示
- mask:掩模图像,一般置为 None
- histSize:直方柱的数量,一般取 256
- ranges:像素值的取值范围,一般为 0,256
- 返回值 hist:返回每一像素值在图像中的像素总数,形状为 (histSize,1)
代码:
python
import cv2
import matplotlib.pyplot as plt
import numpy as np
img = cv2.imread("./data/image.jpg", flags=0) # flags=0 读取为灰度图像
histCV = cv2.calcHist([img], [0], None, [256], [0, 256]) # OpenCV 函数 cv2.calcHist
#绘图函数
plt.figure(figsize=(10, 3))
plt.subplot(121), plt.imshow(img, cmap='gray', vmin=0, vmax=255), plt.title("Original"), plt.axis('off')
plt.subplot(122, xticks=[], yticks=[]), plt.axis([0, 255, 0, np.max(histCV)])
plt.bar(range(256), histCV[:, 0]), plt.title("Gray Hist")
plt.show()输出结果如下:
原理:
- 设置初始阈值T,通常可以设置为图像的平均灰度
- 用灰度阈值T分割图像:灰度值小于T的所有像素集合G1和大于等于T的所有像素集合G2
- 分别计算G1、G2的平均灰度值m1、m2
- 求出新的灰度阈值
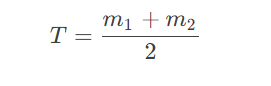
- 重复步骤(2)~(4),直到阈值变化小于设定值。
原理实现的代码如下:
python
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread("./data/image.jpg", flags=0)
deltaT = 1 # 预定义值
histCV = cv2.calcHist([img], [0], None, [256], [0, 256]) # 灰度直方图
grayScale = range(256) # 灰度级 [0,255]
totalPixels = img.shape[0] * img.shape[1] # 像素总数
totalGary = np.dot(histCV[:, 0], grayScale) # 内积, 总和灰度值
T = round(totalGary / totalPixels) # 平均灰度
while True:
numG1, sumG1 = 0, 0
for i in range(T): # 计算 C1: (0,T) 平均灰度
numG1 += histCV[i, 0] # C1 像素数量
sumG1 += histCV[i, 0] * i # C1 灰度值总和
numG2, sumG2 = (totalPixels - numG1), (totalGary - sumG1) # C2 像素数量, 灰度值总和
T1 = round(sumG1 / numG1) # C1 平均灰度
T2 = round(sumG2 / numG2) # C2 平均灰度
Tnew = round((T1 + T2) / 2) # 计算新的阈值
print("T={}, m1={}, m2={}, Tnew={}".format(T, T1, T2, Tnew))
if abs(T - Tnew) < deltaT: # 等价于 T==Tnew
break
else:
T = Tnew
# 阈值处理
ret, imgBin = cv2.threshold(img, T, 255, cv2.THRESH_BINARY) # 阈值分割, thresh=T
#绘图
plt.figure(figsize=(11, 4))
plt.subplot(121), plt.axis('off'), plt.title("original"), plt.imshow(img, 'gray')
plt.subplot(122), plt.title("threshold={}".format(T)), plt.axis('off')
plt.imshow(imgBin, 'gray')
plt.tight_layout()
plt.show()输出结果如下:

3.1.2、最大类间方差法(OTSU),也叫大津法
原理如下:
-
设置一个初始阈值T
-
用灰度阈值T分割图像:灰度值小于T的所有像素集合G1 和 大于等于T的所有像素集合G2
-
计算图像全局灰度均值m、计算G1和G2的像素数占比p1、p2以及他们的灰度值均值m1、m2
-
定义类间方差
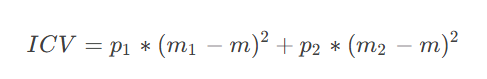
-
使类间方差ICV最大化的灰度值TTT就是最优阈值,因此只要遍历所有的灰度值,就可以得到最优阈值。
OpenCV 提供了函数 cv.threshold 可以对图像进行阈值处理,将参数 type 设为 cv.THRESH_OTSU,就可以使用使用 OTSU 算法进行最优阈值分割。
python
import cv2
from matplotlib import pyplot as plt
img = cv2.imread("./data/image.jpg", flags=0)
ret2, imgOtsu = cv2.threshold(img, 0, 255, cv2.THRESH_OTSU) # 阈值分割, thresh=T
plt.figure(figsize=(7, 7))
plt.title("OTSU binary(T={})".format(round(ret2))), plt.axis('off')
plt.imshow(imgOtsu, 'gray')
plt.tight_layout()
plt.show()输出结果图如下:

3.1.3、自适应阈值分割
噪声和非均匀光照等因素对阈值处理的影响很大,例如光照复杂时 Otsu 算法等全局阈值分割方法的效果往往不太理想,需要使用可变阈值处理。
可变阈值是指对于图像中的每个像素点或像素块有不同的阈值,如果该像素点大于其对应的阈值则认为是前景。
局部阈值分割可以根据图像的局部特征进行处理,与图像像素位置、灰度值及邻域特征值有关。
可变阈值处理的基本方法,是对图像中的每个点,根据其邻域的性质计算阈值。标准差和均值是对比度和平均灰度的描述,在局部阈值处理中非常有效。
函数说明:cv.adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize, C[, dst]) → dst
- scr:输入图像,nparray 二维数组,必须是 8-bit 单通道灰度图像!
- dst:输出图像,大小和格式与 scr 相同
- maxValue:为满足条件的像素指定的非零值,具体用法见 thresholdType 说明
- adaptiveMethod:自适应方法选择
-
- cv.ADAPTIVE_THRESH_MEAN_C:阈值是邻域的均值
-
- cv.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域的高斯核加权均值
- thresholdType:阈值处理方法
-
- cv2.THRESH_BINARY:大于阈值时置 maxValue,否则置 0
-
- cv2.THRESH_BINARY_INV:大于阈值时置 0,否则置 maxValue
- blockSize:像素邻域的尺寸,用于计算邻域的阈值,通常取 3,5,7
- C:偏移量,从邻域均值中减去该常数
代码如下:
python
import cv2
from matplotlib import pyplot as plt
img = cv2.imread("./data/image.jpg", flags=0)
# 自适应局部阈值处理
binaryMean = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 5, 3)
binaryGauss = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 5, 3)
plt.subplot(121), plt.axis('off'), plt.title("Adaptive mean")
plt.imshow(binaryMean, 'gray')
plt.subplot(122), plt.axis('off'), plt.title("Adaptive Gauss")
plt.imshow(binaryGauss, 'gray')
plt.tight_layout()
plt.show()输出结果如下:

3.2、基于区域分割方法
类似于基于边界的图像分割技术,它利用了物体的灰度分布与背景的相似性 。通常,基于区域的图像分割方法包括分水岭分割和区域生长 两大类。
分水岭算法 借鉴形态学理论,是一种基于区域的图像分割算法。该方法将图像视为地形图,其灰度值与地形高度相对应。高灰值对应山,低灰值对应谷。如果雨水落在地表,低洼地区就是一个盆地,盆地之间的山脊被称为分水岭。分水岭相当于一种自适应多阈值分割算法。
区域生长 是一种串行区域分割的图像分割方法 。区域增长是指从某个像素开始,按照特定的标准逐渐增加相邻的像素。当满足某些条件时,区域增长就终止。也就是说,区域的生长取决于起始点(种子点)、生长准则和终止条件的选择。区域生长是一种比较常用的方法,它可以在没有先验知识可用的情况下获得最佳性能,并且可以用于分割更复杂的图像。但是,区域增长方法是迭代的,空间和时间成本相对较高。
3.3、基于图的分割方法
该算法是一种基于图的贪婪聚类算法。其优点是实现简单,速度快。许多流行的算法都是基于这种方法。
图中每边的权值是像素与相邻像素之间的关系,表示相邻像素之间的相似度。将每个节点(即像素)视为一个单独的区域,然后根据区域的参数和内部差异进行合并,得到最终的分割结果。
由于WSI通常非常大,所以它们被存储为平铺图像的金字塔,这样它们就可以以分层的方式进行处理,即通过低分辨率图像确定感兴趣的区域,对高分辨率图像分类,自上而下分割。
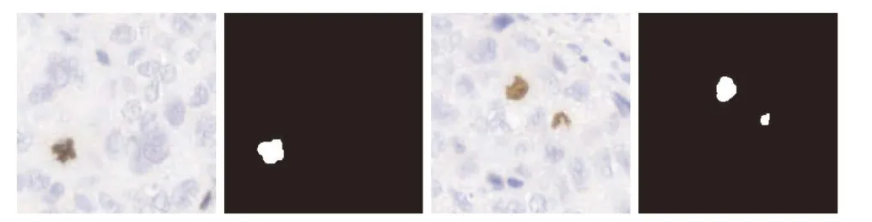
在某些论文中,为提取乳腺组织WSI中的有丝分裂。采用离散正则化方法对图像进行简化,采用无监督2-均值聚类方法对图像进行聚类。聚类是在前一个分辨率划分的特定区域中执行的。所获得的聚类通过像素复制以更精细的分辨率进行扩展,并在特定区域进行细化。在最高分辨率水平提取有丝分裂图像。有丝分裂的分割结果如下图所示。
3.4、基于聚类的分割方法
聚类是基于每个像素和相邻像素 之间的关系。如果一个像素在颜色、纹理或灰度上与其相邻像素相似,那么它们将被合并到同一个类中。
k-means算法是聚类算法中比较常用的算法。
聚类中心点是通过计算样本中每个聚类中所有像素的平均值来获得的。k-means算法的基本工作原理是接收用户输入的k个参数,并将给定的n个数据样本点平均分成k组,以输入的k个点作为待收敛的聚类中心,计算其他聚类。并比较各采样点到收敛中心点的欧氏距离。通过比较欧氏距离的最小形式进行分类。然后经过反复迭代,依次得到k个聚类的均值。直到性能准则函数的聚类效果最佳,整体误差最小,得到最佳聚类效果。
3.5、基于深度学习的分割方法
某篇作者提出了一种自动端到端 深度神经网络算法来分割单个核。引入核边界模型,利用FCN同时预测核及其边界。给定颜色归一化图像,模型直接输出估计的核图和边界图。经过后期处理,最终得到分割结果。并设计了一种重叠块的提取和组装方法,实现了大型WSI中细胞核的无缝预测。最后的结果证明了数据展开方法在细胞核分割任务中的有效性。实验表明,该方法优于现有方法,能够在可接受的时间内准确分割WSI。
在另一篇论文中,提出了一种多尺度图像处理 方法来解决组织病理学图像中肝癌的分割问题。将8个网络进行比较,选择最适合肝癌分割的网络。通过综合性能比较,选择U-Net。利用病理图像的局部颜色归一化 方法解决背景的影响,然后对每个WSI建立七层高斯金字塔 表示,得到多尺度图像集。经过训练的U-Net在每个层次上进行微调 ,以获得一个独立的模型。然后,在预测过程中使用移位裁剪和加权重叠 来解决块连续性问题 。最后,将预测图像映射回原始大小 ,并提出了一种投票机制来组合多尺度预测图像。实验数据为2019年MICCAI PAIP挑战赛的验证图像。评价结果表明,该算法优于其他算法。
3.6、其他分割方法
在一篇论文中,使用了一种新的分割细胞核的算法。在通过弹性分割算法 确定细胞核的精确形状之前,提出的算法使用投票方案和先验知识 来定位细胞核。通过均值漂移和中值滤波 去除噪声后,使用Canny边缘检测 算法提取边缘。由于细胞核显式地被细胞质包围,且形状大致为椭圆形,与背景相邻的边缘被删除。使用椭圆的随机霍夫变换 找到候选核,然后通过水平集算法对其进行处理。在包含两张不同载玻片的207张图像的数据库中,对该算法进行了测试并与其他算法进行了比较,TPR结果测量值为96.15%。
在另一篇文献中,提出了一种基于WSI的快速分割方法。由于WSI的大小较大,因此使用一组遵循图像高梯度的水平和垂直最优路径对图像进行分割,从而有效地提供了图像的相关分割,然后执行其他后续步骤。分割过程示意图如图3所示。
四、理解病理切片
4.1、什么是病理图像
病理图像的基本特征
- WSI即全载玻片图像,是将不同染色的组织切片信息从玻璃到数字格式的转换;
- 图像尺寸大,通常在百兆到数G之间
- 图像呈现丰富的色彩信息,为金字塔结构,在不同的放大倍数下(多层分辨率)检索可提供多种比例的信息,比如TCGA最常见的40x,20x;
- 通常存储为.svs,.tiff,.ndpi, .mrxs格式-可通过本地软件qupath,ImageScope,Python包openslide进行可视化;
病理图像的金字塔结构
- Dimensions: 表示WSI在最高层次(level 0)的原始尺寸,如 (14000, 22312) 意味着图像的宽度是14000像素,高度是22312像素。level 0是指金字塔的顶层,代表最高分辨率的图像,相当于显微镜下的最高放大倍数。
- Level count: 表示WSI的金字塔结构中的层数。若level count是3,意味着有三个不同的分辨率级别:level 0(最高分辨率)、level 1(中等分辨率)、level 2(最低分辨率)。随着级别的增加(即level 1、level 2等),图像的分辨率会降低,图像尺寸会变小,相当于在显微镜下观察时逐渐降低放大倍数。
- Level dimensions: 这是一个元组列表,显示了每个级别的图像尺寸/分辨率。在这个例子中,level 0的尺寸是(14000, 22312),level 1的尺寸是(3500, 5578),level 2的尺寸是(1750, 2789)。
- Level downsamples: 每个级别的下采样因子。在这个例子中,level 0的下采样因子是1.0(没有缩小),level 1是4.0,level 2是8.0。下采样因子表示每个级别相对于第一个级别的缩放比例1/(2的n次方)。例如,从level 0到level 1,图像尺寸缩小了4倍,代表level 1的1个像素点指代level 0每四个像素点的信息。
- Magnification: 这表示显微镜下观察到的放大倍数。如,level 0的放大倍数是20x。这意味着在最高分辨率级别,每个像素代表实际组织样本中的物理尺寸被放大了20倍。而对于level1, 放大倍数为20x / 4= 5x,即level 1代表实际组织样本中的物理尺寸被放大了5倍。
代码
读取WSI图像。
python
### 通过openslie获取病理切片的相关属性
import openslide
import matplotlib.pyplot as plt
import numpy as np
# 打开 SVS 文件
svs_file_path = './input_dataset/TCGA-BA-4075-01A-01-BS1.svs'
slide = openslide.OpenSlide(svs_file_path)
# 获取 SVS 文件的基本信息
print("Dimensions: ", slide.dimensions) # 是图像的原始尺寸(最高分辨率层级)的宽度和高度
print("Level count: ", slide.level_count)
print("Level dimensions: ", slide.level_dimensions)
print("Level downsamples: ", slide.level_downsamples)
# 多种方式获取level 0的放大倍数
print("Level_0_magnification: x", int(slide.properties['aperio.AppMag']))
# print("Level_0_magnification: x", int(slide.properties['openslide.objective-power']))
# 如果存在'openslide.mpp-x'属性,也可以根据每像素微米数来推断放大倍数。
# level_0_magnification = 40 if int(np.floor(float(slide.properties['openslide.mpp-x']) * 10)) == 2 else 20
print("Level_0_magnification: x", level_0_magnification)
# 读取缩略图
thumbnail = slide.get_thumbnail((1024, 1024))
# 显示缩略图
plt.imshow(thumbnail)
plt.axis('off')
plt.show()
# 关闭 SVS 文件
slide.close()若存在不同属性的切片,如何提取20x的特征?
python
##切片属性:##
# Level_0_magnification: 40;
# Level downsamples [1, 2, 4, 8, 16, 32, 64, 128]
# set --patch_level=1, --patch_size=256, --step_size=256 --custom_downsample=1
python create_patches_fp.py --source input_dataset_eval --save_dir Split_Image_eval --patch_size 256 --seg --patch --stitch --patch_level 1 --preset my_bwh_biopsy.csv
CUDA_VISIBLE_DEVICES=0,1 python extract_features_fp.py --data_h5_dir Split_Image_eval/ --data_slide_dir input_dataset_eval/ --csv_path Split_Image_eval/process_list_autogen.csv --feat_dir Extracted_feature_eval/ --batch_size 256 --slide_ext .ndpi # 新版本无custom_downsample,所以可以更改 process_list_autogen.csvd 的seg_level?
##切片属性:##
#Level_0_magnification
40x 263
20x 14
#Level downsamples
[1, 4, 16, 32] 161
[1, 4, 16, 64] 59
[1, 4, 16] 53
[1, 4, 8] 4 ##
# 对于40x,downsamples level 1 =4:
set --patch_level =0, patch_size 512, --step_size=512, --custom_downsample 2
# 对于20x,downsamples level 1 =4:
set --patch_level =0, patch_size 256, --step_size=256, --custom_downsample=14.2、病理图像常用的存储格式
4.2.1、TIFF格式
标签图像文件格式(TIFF,Tagged Image File Format)是一种广泛使用的位图图像格式,以其灵活性和对高分辨率图像的支持而受到青睐。
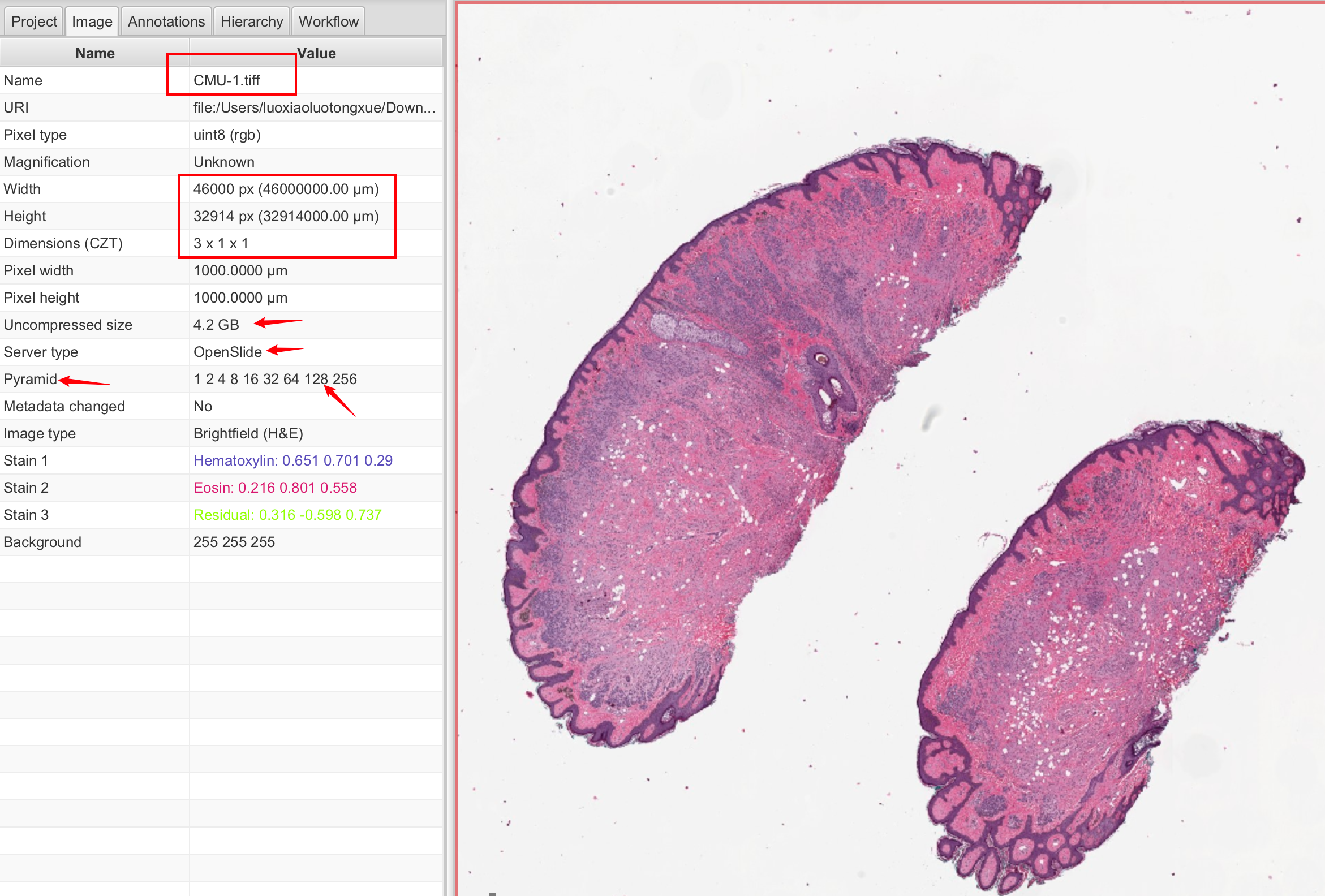
为了有效处理这些大型图像,图像平铺(tiling)和缩放金字塔(pyramid)技术 被广泛应用。平铺技术 涉及将大图像 分割成小块(tile),每块通常为256x256像素。这样,只有当前需要显示或处理的图像块会被加载到内存中,而不是整个图像,这大大减少了内存的使用并提高了处理效率。
此外,这些tile可以使用不同的编码技术进行压缩,以进一步减少存储需求和提高加载速度。在TIFF格式中,LZW(Lempel-Ziv-Welch)和JPEG是常用的压缩编码。
缩放金字塔技术 则是在图像的原始分辨率 基础上创建多个分辨率逐渐降低的副本,形成一个金字塔结构 。这些副本可以按照2的幂次(例如,1/2,1/4,1/8,1/16原图尺寸)进行下采样。在图像处理或分析时,可以根据需要选择适当的分辨率级别,从而在不同的尺度上进行操作,这在进行图像特征提取或模式识别时非常有用。
尽管TIFF格式本身不强制要求图像必须是平铺或金字塔结构 ,但在病理图像分析中,某些库如OpenSlide要求TIFF图像必须是平铺的 ,以便能够正确读取和处理。如果一个TIFF图像没有按照这些要求进行配置,OpenSlide可能会报告格式不支持的错误。因此,为了确保与这些工具的兼容性,病理图像的TIFF格式通常需要进行特定的预处理,以满足平铺和金字塔结构的要求。
4.2.2、其他格式及特点
- SVS格式:SVS(Supported Vector Graphics format)是一种Tiled TIFF图像,用于存储高分辨率的病理图像。SVS格式支持金字塔结构,可以存储不同放大倍数下的图像信息,便于病理学家进行详细观察。SVS文件通常包含主图像和附加页面,如标签、概览图像以及缩放的副本。
- DICOM格式:DICOM(Digital Imaging and Communications in Medicine)是医学图像和相关信息的国际标准。虽然DICOM最初主要用于放射医疗图像,但它也支持存储病理图像。DICOM文件包含丰富的元数据,如患者信息和扫描参数,适合在不同设备和系统之间传输和共享。
- NIFTI格式:NIFTI(Neuroimaging Informatics Technology Initiative)格式最初用于存储神经影像数据,但也适用于存储3D医学图像。NIFTI文件包含图像数据和头部信息,后者描述了图像的元数据,如像素大小和图像方向。
- Analyze格式:Analyze格式包含两个文件:一个头文件(.hdr)包含图像的元数据,一个数据文件(.img)包含图像数据。这种格式常用于医学图像处理软件。
- PAR/REC格式:这是飞利浦MRI扫描设备使用的数据格式,PAR文件包含扫描参数,REC文件包含原始图像数据。
- NRRD格式:NRRD(Nearly Raw Raster Data)是一种用于存储多维数组数据的格式,特别适用于医学图像。它支持任意维度的数据,并可以包含与数据相关的元数据。
4.3、图像金字塔
病理图为金字塔结构,level_count属性是获取svs有多少层。在svs中存储了每一层采样的tiles。一般情况下Level0为原图,也就是highest resolution,然后每一级进行下采样,level_count -1为lowest resolution。
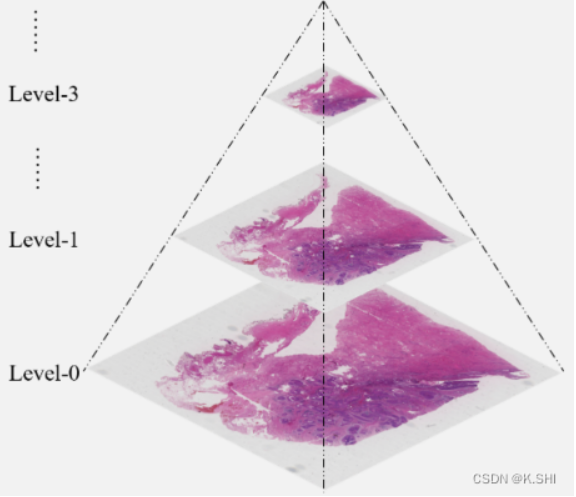
图像金字塔是一种在图像处理和计算机视觉中常用的数据结构,它为同一张图像的不同层级提供了不同分辨率的视图。
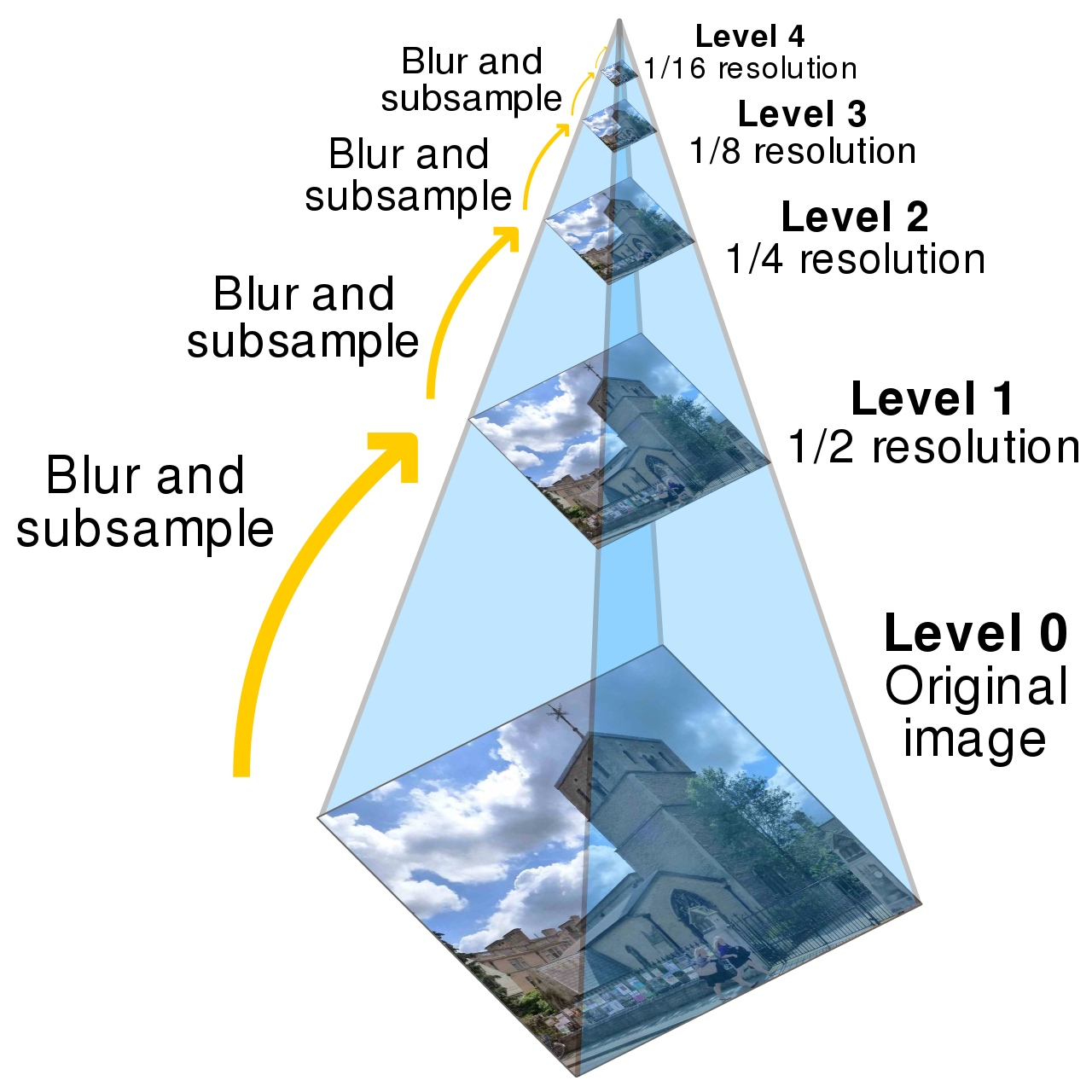
这种结构之所以重要,是因为它允许算法在多个尺度上分析图像,这在很多应用中都非常有用,比如图像识别、目标检测、图像融合等。
图像金字塔的构建
-
原始图像获取:首先,需要有一个高分辨率的原始图像作为起点。
-
降采样:通过降采样技术,如最邻近插值、双线性插值或更高级的方法,将原始图像缩小到较小的尺寸。这个过程会逐渐减少图像的分辨率,同时增加图像的层级。
-
重复过程:重复降采样过程,直到图像缩小到所需的最小尺寸或达到预设的层级数。
-
存储结构:所有这些不同分辨率的图像按照从大到小的顺序排列,形成一个金字塔结构。
图像金字塔类型
-
高斯金字塔:每一层的图像都是通过高斯低通滤波后降采样得到的,这样可以减少混叠效应,保留图像的重要特征。
-
拉普拉斯金字塔:在高斯金字塔的基础上,通过计算相邻层之间的差异来创建额外的细节层,这有助于图像重建和分析。
-
K-L金字塔:基于Karhunen-Loève变换,这种金字塔在图像压缩领域有应用。
图像金字塔的应用
-
多尺度分析:在图像中搜索特定特征或对象时,可以在不同分辨率的图像上进行,以适应不同大小的目标。
-
图像融合:在图像拼接或图像融合任务中,使用金字塔方法可以更好地处理不同图像间的接缝。
-
图像压缩:在某些图像压缩算法中,图像金字塔可以有效地表示图像在不同分辨率下的信息。
-
计算机视觉算法:在诸如SIFT(尺度不变特征变换)等算法中,图像金字塔是关键组成部分,用于检测和描述图像中的关键点。
-
实时视频处理:在视频流处理中,图像金字塔可以用于快速目标跟踪,因为它允许在不同时间尺度上分析运动。
4.4、格式转换
如果用的扫描仪是江丰的,那么图像格式是kfb,如果用的扫描仪是蔡司的,则格式为czi,这里先介绍如何将kfb的格式转换为svs,后面的推文会介绍如何将czi转换为TIFF。
配套软件
软件获取地址:https://github.com/Lxltxpku/Share
配套代码
python
import os # 引入os模块,用于操作文件和目录
import sys # 引入sys模块,用于访问与Python解释器相关的变量和函数
import subprocess # 引入subprocess模块,用于执行命令行命令
from time import time # 引入time函数,用于测量时间
from glob import glob # 引入glob模块,用于文件名模式匹配
def main():
# 设置源文件夹名称、目标文件夹名称和转换级别
src_folder_name = 'Raw' # KFB文件所在文件夹
des_folder_name = 'Raw-svs' # 保存SVS文件的文件夹
level = 9 # 设置转换级别
# 设置转换程序的路径
exe_path = r'E:\...\...\...\KFbioConverter.exe' # 下载的转换程序所在文件夹
if not os.path.exists(exe_path):
raise FileNotFoundError('Could not find convert library.') # 如果转换程序不存在,抛出异常
# 检查级别是否在2到9之间
if int(level) < 2 or int(level) > 9:
raise AttributeError('NOTE: 2 < [level] <= 9') # 如果级别不在范围内,抛出异常
# 设置当前工作目录
pwd = r'E:\...'
full_path = os.path.join(pwd, src_folder_name) # 拼接源文件夹的完整路径
dest_path = os.path.join(pwd, des_folder_name) # 拼接目标文件夹的完整路径
if not os.path.exists(full_path):
raise FileNotFoundError(f'could not get into dir {src_folder_name}') # 如果源文件夹不存在,抛出异常
if not os.path.exists(dest_path):
os.makedirs(dest_path) # 如果目标文件夹不存在,创建它
# 获取源文件夹中的所有kfb文件
kfb_list = os.popen(f'dir {full_path}').read().split('\n')
kfb_list = [elem.split(' ')[-1] for elem in kfb_list if elem.endswith('kfb')]
# 打印找到的kfb文件数量,并开始转换
print(f'Found {len(kfb_list)} slides, transfering to svs format ...')
for elem in kfb_list:
st = time() # 记录开始时间
kfb_elem_path = os.path.join(full_path, elem) # 获取单个kfb文件的完整路径
svs_dest_path = os.path.join(dest_path, elem.replace('.kfb', '.svs')) # 构建目标svs文件的路径
command = f'{exe_path} {kfb_elem_path} {svs_dest_path} {level}' # 构建转换命令
print(f'Processing {elem} ...') # 打印正在处理的文件名
p = subprocess.Popen(command) # 执行转换命令
p.wait() # 等待命令执行完成
print(f'\nFinished {elem}, time: {time() - st}s ...') # 打印完成信息和所用时间
# 程序入口点
if __name__ == "__main__":
main()病理基础模型Prov-GigaPath
在Patch层面 ,Prov-GigaPath采用DINOv2对Vision Transformer进行自监督预训练,实现对局部病理结构的高效压缩表征。
在切片层面 ,Prov-GigaPath基于长序列建模的前沿方法LongNet,实现整张切片级别的上下文融合。Prov-GigaPath基于3万名患者的171189张全切片数字病理图像进行训练,涵盖了31种主要组织类型。通过在9个癌症亚型分类任务和17个病理组学任务中的评估测试,Prov-GigaPath展现出了卓越的分析能力。
数据预处理 方面,我们可以直接调用Prov-GigaPath相关的预处理代码对切片进行转换;
特征提取 方面,我们可以利用Prov-GigaPath提供的Tile Encoder、Slide Encoder提取病理切片的局部特征、切片级特征,并基于提取的特征开展分析;
模型构建方面,Prov-GigaPath也提供微调代码,我们可以面向自身的分析任务直接通过微调来构建模型。
数据集链接
TCGA:https://portal.gdc.cancer.gov
GTEx:https://www.gtexportal.org/home/
PAIP (Pathology AI Platform):http://www.wisepaip.org/paip
PANDA:https://www.kaggle.com/c/prostate-cancer-grade-assessment
BCC:https://datahub.aida.scilifelab.se/10.23698/aida/bccc
ACROBAT:https://doi.org/10.48723/w728-p041
BCNB:https://bcnb.grand-challenge.org/
TOC:https://www.cancerimagingarchive.net/collection/ovarian-bevacizumab-response/
CPTAC:https://portal.gdc.cancer.gov
DROID-breast:https://datahub.aida.scilifelab.se/10.23698/aida/drbr
Cervix-TissueNet:https://www.drivendata.org/competitions/67/competition-cervical-biopsy/
Colon (Dataset-PT):https://github.com/CSU-BME/pathology_SSL
Prostate (Diagset-B):https://github.com/michalkoziarski/DiagSet
PAIP 2020:https://paip2020.grand-challenge.org/
MUV-GBM and MUV-LGG:https://doi.org/10.25493/WQ48-ZGX
PLCO:https://cdas.cancer.gov/plco/
医学数据集汇总大全:https://zhuanlan.zhihu.com/p/661132213
病理组学流程