TOC
注:本文很多理论参考了得物技术公众号的这篇文章 商家域稳定性建设之原理探索 ,本文是基于这篇文章的思考及近半年团队内对于稳定性建设的实践总结而成。
1 前言
系统的稳定性建设是一个庞大的话题,其贯穿了产品研发整个流程:需求阶段、研发阶段、测试阶段、上线阶段、运维阶段。从系统规模上看,小到单个系统,大到一个域的系统集,再大到支撑整个公司全业务的系统全集,都离不开系统稳定性建设。大家日常工作中可能会有一些关于系统稳定性的疑惑,比如经典三问"是什么、为什么、怎么做",今天我从一个后端研发的视角,来和大家聊一聊系统稳定性建设的总结与思考。
2 什么是系统稳定性
聊系统稳定性前,得知道到底什么是系统稳定性,让我们看看其定义。
2.1 学术定义
系统在指定边界条件下维持其服务质量(QoS)的能力,包括在预期负载、异常输入或部分组件失效时,依然能提供符合SLA约定的服务级别。
这个定义有些晦涩,大家可能有点不容易理解,来看一下工程实践上的定义,从不同维度给出具体的说明。
2.2 工程实践定义
服务持续性 :在硬件故障、网络抖动、突发流量等异常情况下保持服务可用。
性能稳定性 :99分位延迟不出现剧烈波动(如P99 < 500ms且抖动幅度<15%)。
状态可预期 :系统行为符合"墨菲定律"预期(任何可能出错的地方终将出错,但系统有预设应对方案)。
故障可降级:具备优雅退化(Graceful Degradation)能力,如购物车可独立于推荐系统运行。
2.3 量化指标定义
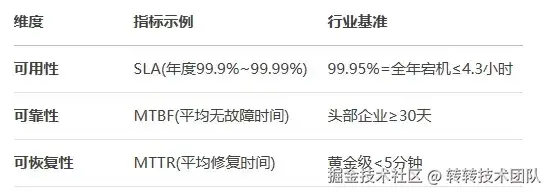
SLA :这里指可用性SLA,也就是常说的N个9,以常说的4个9为例,按全年时间计算,服务只允许4.3h不可用。
MTBF :Mean Time Between Failure,平均故障间隔时间 =总运行时长/故障次数。指系统在相邻两次故障之间的平均正常运行时间,单位为小时(h)。它反映系统的可靠性,数值越高说明故障率越低、稳定性越强。
MTTR :Mean Time To Repair,平均修复时间 =故障修复总时间/故障次数。指系统从故障发生到完全修复所需的平均时间,包括问题诊断、问题修复、测试验证、上线验证等全流程。数值越低,说明系统恢复能力越强。
从上面不同维度的定义可以知道,系统稳定性,追求的系统运行过程中少出问题,取决于两个点,一个是系统风险,另一个是风险发生后的应对能力 。也就是说,可以将稳定性简化为一个公式:稳定性 = 系统风险(概率) * 风险应对能力。
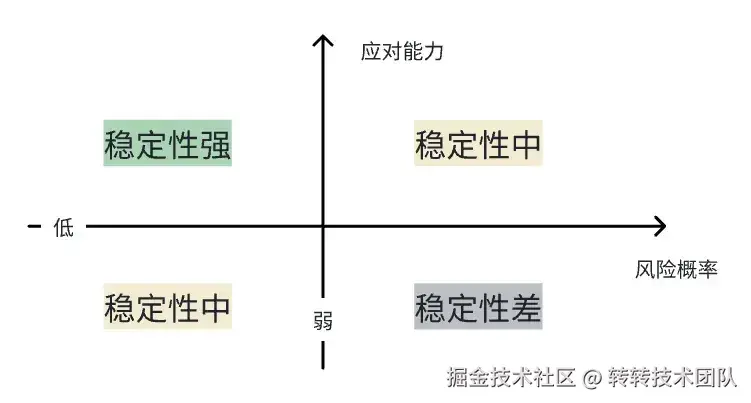
2.4 另一种角度的定义
稳定性 = 系统风险(概率) * 风险应对能力。
咱们继续拆解,对于系统风险,又分为固有风险 和变更风险 。固定风险一般指运维关注的网络问题、服务器问题、容器环境相关问题;变更风险指随着业务迭代对系统进行的功能上线、配置更新等人为操作引入的动态风险。运维团队更多关注固有风险,研发技术团队,更多关注变更风险部分。
继续拆解变更风险,可以得到:
变更风险 =变更频率 * 变更复杂度 * 变更爆炸半径(影响范围)
变更频率 :变更次数越多,风险越大,一般和业务需求迭代频率正相关。
变更复杂度 :包含业务本身的复杂度,代码实现的复杂度,配置的复杂度。一般来说,复杂度越高,单次变更出问题的概率也越大。
变更爆炸半径:也叫变更影响范围,表示发生问题后的影响面,直接影响实际的损失。
风险应对能力,分为风险发生前应对能力 和风险发生后的应对能力 。
风险发生前:能不能发现,以及发现后能不能及时消除风险。
风险发生后:能不能更快发现,以及发现后能不能及时修复。
风险处理能力 = 风险前置发现概率 * 前置风险处理 * 后置风险发现时长 * 风险应急处理
综上能得出一个拆解后的稳定性公式:
稳定性 =(固有风险 + 变更频率 * 变更复杂度 * 变更爆炸半径) (风险前置发现概率 * 前置风险处理)(后置风险发现时长 * 应急效果)
这个公式将作为后续问题分析和实践的理论基础,所有的稳定性建设,都会围绕着这些指标进行对应策略的制定。
3 为什么要进行稳定性建设
为什么系统稳定性如此重要呢,系统的稳定性是支撑业务发展的那个1,没有这个1,后面再多的0,都将毫无意义。
系统稳定性差,会带来的影响有:
直接的经济损失 :比如系统出现问题,导致订单减少,金额出错等,阿里前段时间出现的转账打8折问题,就造成了重大的直接经济损失,这都是最直接的真金白银损失。
专业性会受到质疑 :小到个人和团队,大到公司,形象都会受到影响。对公司而言,大的事件可能变成舆论危机,对企业品牌形象带来负面影响。
相反,稳定性好,自然就会降低直接的经济损失,也会传递出企业更专业的正面形象。除了这两点,对于业务支撑的技术团队,整体迭代效率会大大提高。为什么呢,因为系统稳定,花在堵洞上的精力就会大大降低,可以将更多精力投入到业务迭代上。
4 稳定性建设面临的困难
对于技术团队而言,每个人都知道系统稳定性的重要,但落地起来又非常难。有个词叫"bug驱动",意思是平时只关注支撑业务发展,很多问题暴露不出来,bug出现后,驱动技术人去关注代码质量、流程规范等这些。为啥需要等bug出现呢,因为很多时候稳定性建设相关事项会被评定为"重要不紧急",既然不紧急,就先缓缓再建设,缓到啥时候呢,缓到出现问题,然后bug驱动。究其核心原因,有以下方面:
4.1 资源投入难以找到平衡点
对于技术团队而言,支撑业务迭代和进行稳定性建设的资源投入,很难找到平衡点。先说第一种情况,稳定性建设投入少,那系统质量肯定无法长期保证,高速支撑业务的同时,系统各种潜在风险隐患逐渐积累,到了临界点,肯定会以bug或事故的形式出现在技术眼前。再说第二种情况,稳定性建设方向有充足的投入,短期内又很难用可量化的指标体现收益,不仅无法给业务证明其价值,甚至技术内部,短期都很难看出明显效果。业务体感上只会觉得迭代速度慢了,他们在想,为什么不能更快的进行迭代上线呢,此时在项目优先级及排期上,就很难说服业务,业务出于压力,肯定会将业务迭代优先级提高,压力自然就会透传到技术团队。
4.2 稳定性建设本身存在较高的复杂度和风险
根据第一部分的公式可知,稳定性建设核心是识别风险、治理风险、预防风险,对于这每一部分,都不简单。
4.2.1 存量风险识别的难度
如果靠上文说到的"bug驱动"当然也是一种识别风险的办法,只是比较滞后,不符合稳定性建设预期。为了能防范于未然,需要主动去发现系统的风险,并想办法解除风险。前面说了,稳定性建设覆盖的系统范围可大可小,想要评估出其中的潜在风险,这就涉及对全范围系统代码和业务的梳理,工作量和难度可想而知。
4.2.2 风险治理的难度
比如说现在风险已经识别出来了,进入到了第二步治理,也有困难,比如:
1.资源问题 :评估风险治理成本为一个月工期,能否给到正常的排期。
2.引入风险 :治理过程中,怎么保证不给系统引入新的问题。很多时候,系统的状态其实和风雨中的危房差不多,而风险治理,不是简简单单在旁边建一套新的,人搬过去就行,而是需要在维持房屋不倒的情况下,逐渐把房子各个地方修一遍,这个过程稍有不慎,可能就会砸到承重墙,后果就是房屋塌了。为了维修房子结果把房子弄塌了,这是不行的。
3.治理执行:本身执行治理方案时也会有难度,比如常说的技术债,对于一套业务迭代多个版本,代码经手N个研发之手的系统而言,不同的代码风格以及大量为了解决短时问题而写的if充斥在整个系统中,对于这样的系统,给出一套合理的治理方案本身就很难。
4.2.3 增量风险预防的难度
增量风险主要来源于系统的变更,最主要的场景就是业务需求的迭代和技术侧的系统优化。
1.发生变更时,各方理解是否能达成一致,比如研发、测试和产品,对于变更的理解如果不一致,就会引入新风险。
2.变更方案是否可控,如果保证方案最终能和预期一致,如果不一致,就会引入新风险。
3.人员的可靠性,前两步都一致了,但是研发在开发时粗心,代码写法上有问题,测试在验证时粗心,刚好跳过了这条case,就会引入新风险。
5 怎么进行稳定性建设
上面列举了系统稳定性建设的种种困难,前面说过,系统稳定性建设本身是一件重要的事,所以不管有多少困难,该建设还是需要建设的,那么面对这种种困难,如何进行稳定性建设呢?介绍建设具体方案前,先讨论一个问题,系统稳定性建设到底建设的什么?
通过第一节的公式可以将稳定性建设分为三个方向,然后根据每个方向的具体影响因素指标,可以找到对应的建设思路。 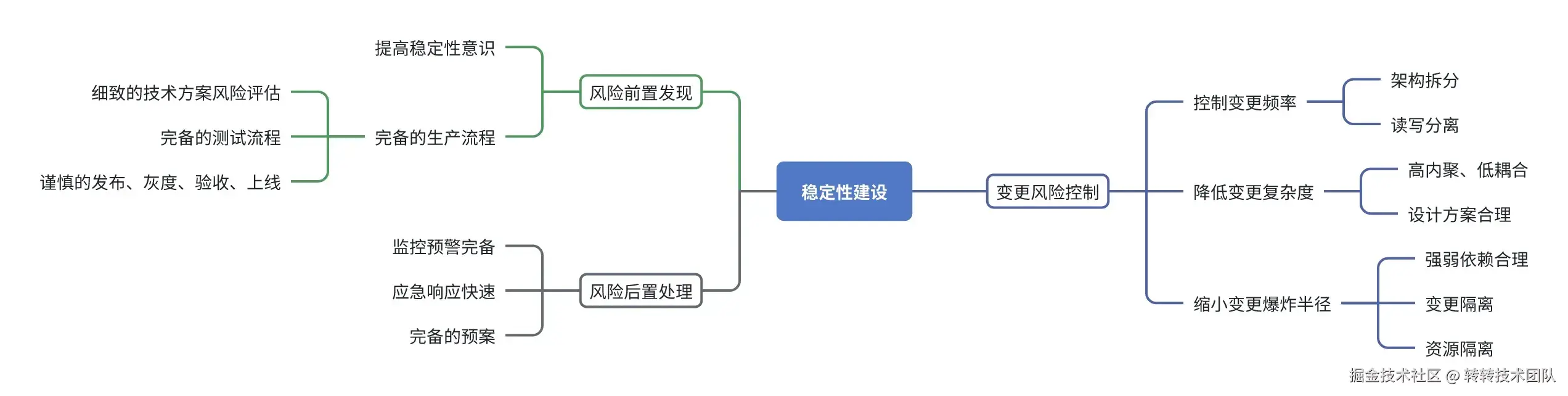
5.1 达成稳定性建设资源投入共识
从上面的分析可知,系统稳定性建设排在第一位的困难是资源问题,那么想解决稳定性建设问题,首先技术内部要对系统稳定性建设投入多少资源达成一致,比如占团队总工作量的多大百分比。这个百分比,不同的团队不同的业务阶段,都可能不一样,需要针对本团队业务的重要性、发展阶段、风险情况进行综合评估,确定稳定性建设在本团队中的重要程度,依据这个重要程度逐渐调整这个投入占比值。
现实中,很多业务开发团队,对于这个大前提是没有共识的,就是既没有相关资源的投入又想要系统稳定的结果,这个是不合理的。比如经常会遇到研发吐槽,技术设计方案、代码CR不给时间,为了上线deadline,极致压缩开发、测试排期,然后又要保证上线质量,这本质上是冲突的。
没有资源投入,一切都是空中楼阁。系统稳定性建设的投入共识,研发内部达成共识后,还要和业务团队充分沟通,取得他们的共识,在需求迭代速度和系统稳定性建设的资源分配上,共同探索一个合理的平衡点。
5.2 明确稳定性建设的目标
稳定性建设的目标,不同的阶段可能不同,选取的考量指标也可能动态变化,比如年度技术三级事故不能高于M个,月度技术online问题不超过N个,再或者直接用系统4个9作为考量指标,都可以。明确了目标后,需要根据大目标拆解为阶段性的小目标,以及根据目标制定出切实可行的落地方案。
结合稳定性建设思路思维导图会发现,其最终建设思路落地取决于"人"和"机制"两个方面,人去落地相关事项,机制用于保障和托底落地效果。接下来咱们看看各个思路如何具体的进行落地。
5.3 意识的培养
前面介绍提到系统稳定性建设依赖的是人来执行,人员的主观意识决定了建设的落地难度和最终效果。这里主要包含三个方面:认知、意愿和能力 。
1.认知 :团队成员是否充分理解系统稳定性的重要。实践建议就是,平时周期性提醒,典型问题重点强调,严重问题复盘总结,来逐渐加强大家对于稳定性重要性的认知。
2.意愿 :团队成员是否花时间和精力去评估和解决稳定性风险(前提是有资源分配的情况下)。评估稳定性风险需要深入细致的梳理系统代码逻辑业务流程等,对耐心、细心都是考验,有时候可能觉得麻烦就简化或者不做了,就会带来潜在风险。实践建议:对表现好的,激励当榜样,对表现不好的,一方面制定适当的惩罚措施,另一方面阶段性的用二次检查机制托底,降低风险。
3.能力:团队成员是否能识别风险并找到解决方案。在认知和意愿没问题的情况下,这部分属于人员个人能力的提升范畴,方式方法很多。比如组内相互分享学习,遇到问题请教其他同学等,都可以。
5.4 完备的生产规范
一次系统变更(业务需求迭代或技术优化)一般包含:需求评审、技术方案评审、编码自测、用例评审、测试、CR、验收、上线、线上验证 等环节。在实际项目推进过程中,严格执行项目流程规范需要投入的时间可能会更多,时间成本上考虑,可能会根据项目规模、特征等因素对流程环节进行一定程度的精简。从结果上看,有时候项目也没出什么问题,久而久之,很多人会觉得流程规范价值不大,会降低整体效率。其实不然,项目流程规范是保障系统稳定性的重要措施。每一个环节都有对应的执行规范,下面着重介绍和研发密切相关的几个环节。
5.4.1 技术方案评审
技术方案评审环节分两个方向,一个是是否进行了技术方案评审,第二个是技术设计和评审的质量。
1.严格执行技术方案评审:对于开发周期大于N(根据不同团队对流程要求的实际情况定,我们团队是3人天)人天的项目,尽量有技术方案设计及评审环节,低于N人天的,可以根据复杂度、变更影响范围等评估是否需要。
很多团队只有那种大型项目,才会有详细的方案设计和评审,对于普通周级别的迭代,需求评审完后,研发简单梳理一下上下文,就直接拉分支进入开发阶段。这种做法对于某些特定情况有deadline上线日期的中小项目,可以这么做,但一直这样不重视技术方案设计,随着时间的积累,可能就会引入稳定性风险。
2.评审关注点主次分明 :技术方案的重点要放在架构的合理性、可扩展性,系统的高性能高可用这些方向上,而不仅仅是实现业务诉求需要的表和接口设计。模块最终的研发人,既需要关注宏观层面的架构合理性又需要关注业务实现中的相关细节,对于参与评审的其他人,更重点的关注点需要放到架构合理性、扩展性这些宏观层面的项上。
3.参与人要求 :关于参与技术评审的人是有要求和限制的,对本次变更模块以及关联模块比较熟悉的研发人员,尽量参加把关,能辅助更好的评估变更风险影响范围。
4.关注点清单 :对于技术评审,需要有沉淀下来的关注点清单列表,辅助评审参与人提出通用性的相关问题。
对于业务研发而言,系统变更遇到的绝大部分问题,都是重复问题,也就是说业内其实有通用思路和解决方案的。哪些是和业务无关的具有通用属性的关注点呢,比如:接口的限流、熔断、降级、超时、重试、版本兼容,为降低变更影响范围的隔离(环境隔离、数据隔离、核心业务隔离、读写隔离、线程池隔离)等,这些关注点就需要在技术评审阶段重点关注。
5.4.2 代码Review阶段
研发环节,CR是保障稳定性的重要措施。这个环节该如何保证质量呢,有如下建议:
1.不CR不上线 :不经过Review的代码不要上线,这是行业无数线上事故教训后得出的建议,大家一定不要心存侥幸。这个可以通过流程上的规范限制进行强约束,比如我们的发布平台可以设置上线前必须CR,也可以根据系统设置定向CR的人,否则不能进入到沙箱部署。
2.代码风格统一 :要有团队自己的整体代码风格,统一一套编码规范,这样可以极大的提高CR效率。
3.善用工具 :善用工具发现代码中的基本问题,比如用扫描工具发现代码中潜在的NPE,工具比肉眼强无数倍。比如我们的发布平台就集成了Sonar扫描功能,坏味道和bug不修复完是不允许部署沙箱的。
4.不过度关注细节 :CR过程不要陷入细节,关注整体风格和写法,以及性能、安全等通用关注项。
对于很多参与CR的人而言,短时间内需要了解业务需求上下文细节,然后判断代码实现是否正确,这难度是很大的,所以大部分场景CR的是代码基础风格和通用问题。
5.时长限制 :控制单次CR时长,尽量不超过2小时,否则后半程大家精力容易分散,难以发现问题,降低整体CR质量。
6.端正CR心态:先要明确CR的目的是为了找出代码存在的隐患降低系统风险。如果作为被CR的人,放平心态,CR是一个很好的学习机会,发现不足及时学习,不要在CR时极力证明这种写法也没问题,偏离主题。作为主CR的人,也不要以挑刺和为难的心态去CR,不是为了证明谁强谁弱,只讨论方案和实现的合理性就可以了。
5.4.3 上线阶段
上线过程是线上问题爆发的高发期,为什么呢,这个过程涉及系统部署,数据更新,配置变更,以及变更过程中中间态的问题,任何一个环节出错,可能整个上线就失败了。一般上线需要做到三个点:可监控,可灰度,可回滚 。
1.可监控 :上线过程中相关指标的监控,包括业务指标和技术指标,比如订单量在上线期间是否有大的波动,接口可用率是否下降了,CPU、磁盘、网络、异常日志这些是否正常等。这个每个公司都有自己的监控平台,我们有很完善的监控系统Grafana平台,上线过程就需要观察相关指标,比如:
业务指标变化情况: 
异常日志情况: 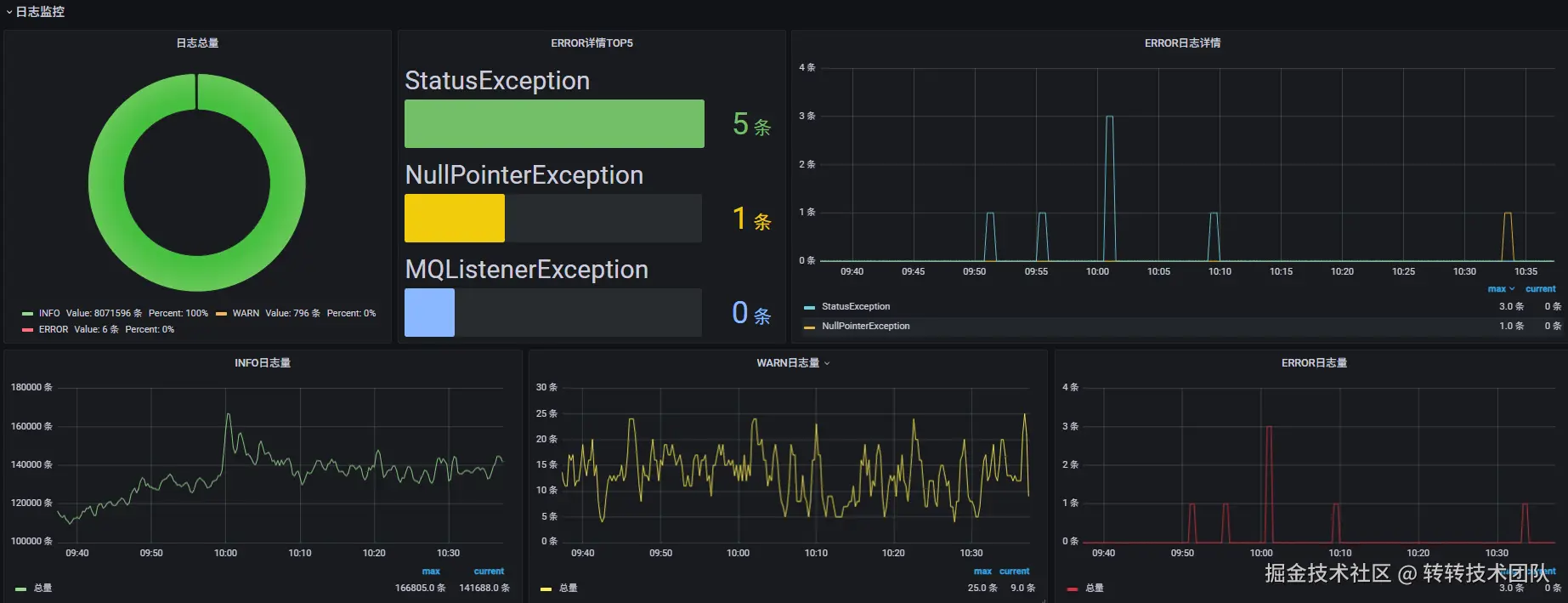
2.可灰度 :灰度主要是为了降低变更影响范围,一旦出问题,也可以将问题限定在可控范围。灰度可以从技术维度进行:机器、机房、区域等维度;也可以从业务维度进行:按用户、按商家、按品类等。
3.可回滚 :发现问题及时止损最快的方式就是回滚。回滚有两种类型:代码回滚和数据回滚 。代码回滚可以通过开关控制或者部署上一个版本的代码实现。数据回滚指上线过程中,产生了中间态的脏数据,需要将数据回滚到正确状态。
总结一下就是,灰度上线,上的过程眼睛紧盯各项指标是否有异常,发现问题,先回滚止损,再定位及修复问题。
如果系统顺利上线,就进入到了风险后置处理环节,这个阶段主要包括:发现问题、响应问题、解决问题、复盘问题四个部分。这个阶段,除了复盘问题外,其他三个环节都和时效性强关联,发现问题、响应问题、解决问题的快慢,都直接影响系统稳定性,慢就可能将影响和损失扩大。
5.5 有效的监控预警
业务反馈问题是发现问题的一种途径,但如果等到业务反馈,时效性就非常滞后了,对用户已经产生了影响,这是技术不愿意看到的。监控预警核心作用是为了及时发现风险,将风险影响范围降低。针对监控预警,有这些建议:
1.预警要全而精 。全指的是对于核心业务的核心节点,都需要有相关监控预警,不能遗漏,指标分为技术指标和业务指标。精是指监控预警不是越多越好,预警过多很可能造成预警噪音,对产生真正影响的预警产生干扰。
2.善用各种监控预警工具 。实际工作中发现,很多必要的监控缺失,这样的话,系统属于无看管状态,感知问题自然会很滞后。
3.核心业务定向监控。在监控工具不能满足诉求的情况下,要自主开发监控小工具,比如业务数据校对监控预警这种,监控平台系统层面很难有定制化的功能。
我们团队内部关于监控属于两者结合,有平台工具监控,这一类比如系统层面的日志、网络、数据库、线程池、接口响应率等。也有自定义的业务监控,针对特定业务指标进行的监控。预警方式多样:邮件、企业微信、短信。
任务执行异常监控预警 
业务操作异常预警 
服务间接口调用监控预警 
error日志及慢sql监控预警 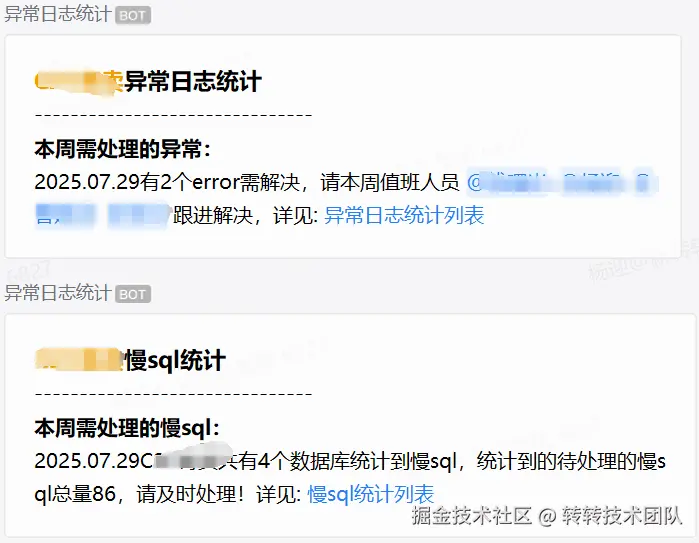
特定业务数据监控预警
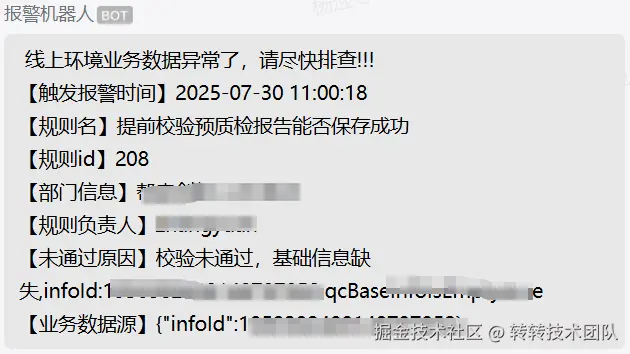
5.6 应急响应机制
对于线上问题一般有三种来源:自主发现、业务反馈、监控预警 。不管哪一种渠道发现的线上问题,都需要有一套响应机制来应对,核心就是降低影响和损失。出现问题该如何响应呢,提供以下建议:
1.响应要及时 :第一时间关注并推进问题解决,要对线上问题抱有敬畏之心。
2.保留问题现场 :方便后续排查和定位问题。
3.信息及时同步 :同步相关问题信息和跟进进度给相关人员,比如leader、业务、关联方。
4.影响评估及止损 :和业务一起评估影响,如果产生实际损失,优先恢复服务,及时止损。恢复服务常用方法:回滚,重启,扩容,禁用节点,功能降级等。尽快止损是应对线上问题的第一优先级 ,如果其他环节和这个有冲突,比如保留现场会延长影响时间继续产生损失,先牺牲掉现场,优先止损,事后再想办法复现问题进行定位。
5.二次确认 :服务恢复后,要继续关注技术指标和业务指标一段时间,确认是否正常。
如何定位问题原因呢,需要从这几个方向出发:
1.充足的知识储备 :对于相关问题,如果没有相关知识打底,是很难找出问题的,比如分析并发问题但是对并发编程并不熟悉,就很难找到问题根源,只能靠猜。
2.善于使用各种辅助工具 :比如日志平台、链路追踪、各种监控工具、JVM性能诊断工具等。
3.合适的方法:针对不同的问题,可能分析思路和方法不一样,需要根据实际场景动态决策。比如有的直接看日志就可以判断问题根源,有的需要测试环境复现,有的需要将问题逐步缩小范围再排查等。
5.7 加强日常巡检和阶段性复盘
除了上面介绍的预防和应急方法,还有一点很重要,就是日常定期检查 ,长期关注系统稳定性,比如系统的慢SQL,偶尔的接口超时,死信消息等,一定要慎重对待,持续跟进,定期治理,防范于未然永远好于临时救火。
对于典型问题和严重事故,要重点复盘,总结经验教训,避免同类型问题再犯。无事故情况下,也需要定期进行阶段性复盘总结,通过回顾目标,评价结果,分析原因,总结经验这几步,沉淀经验,变成知识库,方便后续组内分享学习。
简单总结一下,系统稳定性建设是一件任重而道远的事,要取得好结果,需要基于资源的合理投入为前提,通过提升团队稳定性意识,健全相关机制和流程,双管齐下。过程中不过于激进,平稳安全的进行螺旋式建设,重视总结和优化,逐步完善稳定性建设的各个方面。长期坚持,某一天就会发现,已经取得了明显的治理效果。
6 后记
稳定性建设是一项庞大且系统的工程,涉及生产流程的各个环节,想把系统稳定性建设做好,不是一蹴而就的,需要长期持续的付出努力。建设治理的过程是艰难和漫长的,流程机制会不停的升级进化,咱们在过程中也就慢慢成长了。对于任何一个还在持续运行和迭代的系统而言,系统稳定性建设就像是一场长期革命,革命尚未成功,同志仍需努力,任重而道远!
作者介绍
杨迎,转转寄卖后端研发工程师,目前负责综合履约方向业务开发。